
利用流挖掘和图挖掘的内网异常检测方法*
2020-07-10 12:29孙伟,张羽
计算机与生活 2020年7期
孙 伟,张 羽
1.北京交通大学 计算机与信息技术学院,北京100044
2.中国科学院大学 网络空间安全学院,北京100049
3.中国科学院 信息工程研究所,北京100093
1 引言
在情报界,越来越多的共识认为,内网恶意人员可能是大多数组织中信息保障最有力的威胁[1-4]。内网异常检测问题的一种传统方法是监督学习,其从训练数据构建数据分类模型。不幸的是,监督学习方法的训练过程往往耗时且昂贵,并且通常需要大量的平衡训练数据才能有效。在本文的实验中,观察到该问题的实际数据集中不到3%的数据与内网异常(少数类)相关联;超过97%的数据与非威胁(大多数类)相关联。因此,根据这种不平衡数据训练的模型可能在测试数据集上表现不佳。
另一种方法是无监督学习,它可以有效地应用于未标记的数据,即没有明确地将点识别为异常或非异常的数据。基于图形的异常检测(graph-based anomaly detection,GBAD)是无监督学习的一种重要形式[5-7],但传统上仅限于静态有限长度数据集。这限制了其应用于与内网异常相关的流,这些威胁往往具有无限长度和随时间演变的威胁模式。因此,将GBAD应用于内网异常问题需要一个足够自适应和高效的模型,以便可以从大量不断发展的数据构建有效模型。
本文将内网异常检测作为流挖掘问题进行影射,并提出了一种有效的解决方案,用于应用无监督学习来检测流中的异常。本文方法将多个GBAD模型组合在一个分类器集合中。该集合旨在提高相对于任何单个模型的分类准确性。随着恶意代理和非恶意代理的行为随时间变化,这种进化能力提高了分类器概念普适性。在实验中,使用基于Unix 的多用户系统的大型系统调用数据记录作为测试数据。
本文工作做出了以下贡献:首先,展示了如何有效地应用流挖掘来检测内网异常;其次,提出了一种无监督学习算法,可以应对基于GBAD 的变化;然后,通过有效地将两者结合起来,利用流挖掘和基于图的挖掘的力量;最后,将本文方法与传统的无监督学习方法进行比较,并展示其卓越的有效性。
2 相关工作
内网异常检测工作应用了入侵检测和外部威胁检测的思想[8-11]。在本文中,内网异常主要指当前或曾经雇员、承包商或商业伙伴,他们现在或曾经被授予一定权限,并且以给组织的信息或信息系统的保密性、完整性和可用性带来负面影响的方式,故意过度地访问组织的网络、系统或数据。监督学习方法收集包含正常和异常行为记录的系统调用跟踪日志[12-15],从收集的数据中提取n-gram 特征,并使用提取的特征来训练分类器。文本分类方法将每个系统调用视为词袋模型中的一个单词[16]。系统调用的各种属性,包括参数、对象路径、返回值和错误状态,已被用作各种监督学习方法中的特征[17-18]。这些监督方法需要大量标记的训练数据,并且仅适用于静态的、非演进的流。
过去的工作也探讨了内网异常检测的无监督学习,但仅针对所知的静态流[19-21]。静态GBAD方法[5-7,22]将威胁和非威胁数据表示为图形,并应用无监督学习来检测异常。GBAD 的最小描述长度(minimum description length,MDL)方法已应用于电子邮件、手机流量、业务流程和网络犯罪数据集[23-24]。本文的工作建立在GBAD 和MDL 之上,以支持动态、不断发展的流数据。
流挖掘[25]是一种相对较新的数据挖掘研究类型,适用于连续数据流。在这样的设置中,监督和无监督学习必须是自适应的,以便处理其特征随时间变化的数据。有两种主要的适应方法:增量学习[26]和基于集成的学习[25,27-28]。过去的工作表明,基于集成的方法在两者中更有效,激励了本文的方法。
过去使用集合来增强正/负分类的有效性[28-29]。通过维持共同对最终分类进行投票的K模型的集合,可以减少测试集的假阴性,即漏报(false negative,FN)和假阳性,即误报(false positive,FP)。随着更好的模型被创建,较差的模型被丢弃以维持大小恰好为K的整体。这有助于整体随着流的变化特征而发展并且使分类任务易于处理。表1 总结了上述相关工作的比较。文献[30]提供了更完整的调查。

Table 1 Comparison of related work表1 相关工作比较
3 基于集成的内网异常检测
与内网异常相关的数据通常在组织和系统操作的多年中累积,因此最佳地表征为无界数据流。这样的流可以被划分为一系列离散的块。例如,每个块可能包含一周的数据。
图1 说明了当这样的流观察概念漂移时分类器的决策边界如何变化。图中的每个圆圈表示数据点,未填充的圆圈表示真阴性(true negative,TN)(即非异常),实心圆圈表示真阳性(true positive,TP)(即异常)。每个块中的实线表示该块的决策边界,而虚线表示前一个块的决策边界。

Fig.1 Concept drift in stream data图1 流数据中的概念漂移
阴影圆圈是那些体现了相对于前一个块漂移的新概念的圆圈。为了对这些进行适当分类,必须调整决策边界以考虑到新概念。存在两种可能的误解(错误检测):(1)块2 的决策边界相对于块1 向上移动。结果,一些异常数据被错误地分类为非异常,导致FN(漏报)率上升。(2)块3 的决策边界相对于块2向下移动。结果,一些非异常数据被错误地分类为异常,导致FP(误报)率上升。
通常旧的和新的决策边界可以相交,导致上述两种情况同时发生在同一块上。因此,FP和FN计数都可能增加。
这些观察结果表明,从单个块或任何有限的块前缀构建的模型不足以对流中的所有数据进行适当的分类。这促使采用本文的集成方法,该方法使用不断发展的K模型对数据进行分类。
集成分类程序如图2所示。首先使用静态的、受监督的三种GBAD 方法来训练来自单个块的模型。GBAD识别块中的所有规范子结构,每个子结构表示为子图,选择其中最优的N个子结构作为最终的规范子结构。为了识别异常,将测试子结构与整体中的每个模型进行比较。每个模型基于其与模型的规范子结构的差异对测试子结构进行分类。一旦所有模型投票,加权多数表决将做出最终的分类决定。通过集成演化来保持分类器中模型数量恰好为K。当每个新块到达时,从新块创建K+1模型,并丢弃这些K+1 模型的一个受害者模型。可以通过多种方式选择丢弃受害者。一种方法是计算在K+1块上的每个模型的预测误差并丢弃最差的预测器。这要求最近的块可以立即获得真实值,以便可以准确地测量预测误差。如果没有真实值,就会依赖多数投票;与多数决策最不一致的模型被丢弃。从而保证集成中的K模型最符合当前概念。

Fig.2 Ensemble classification图2 集成分类
算法1 总结了集成分类和更新算法。第1、第2行从最近的块构建一个新模型并暂时将其添加到集成中。接下来,第3~第9行应用集成中的每个模型来测试图t以寻找可能的异常。为每个模型使用3 种GBAD(P、MDL 和MPS(maximum partial substructure)),每种都在第4章中讨论。最后,第10~第18行通过丢弃加权多数意见中最不一致的模型来更新集成。如果多个模型具有最多的分歧,则丢弃任意性能最差的模型。
算法1集成分类和更新算法

加权多数意见使用公式:

在第11行计算,其中Mi∈E是从块i训练的集成E中的模型,是由模型Mi报告的一组异常,λ∈[0,1]是一个恒定的衰落因子[31],并且ℓ 是最近的一块的序号。模型Mi的投票接收权重为λℓ-i,最近构建的模型的权重则为λ0=1,从前一个块接收权重λ1训练的模型(如果它仍然存在于整体中)。当λ<1时,这具有加权当前模型的投票高于可能过时的模型的投票的效果。然后将加权平均值WA(E,a)四舍五入到第11行中最接近的整数(0或1)以获得加权多数表决。
例如,在图2中,模型M1、M3和M7分别对输入样本x投正和负。如果ℓ=7 是最近的块,则这些投票分别加权λ6、λ4和1。因此加权平均值为WA(E,a)=(λ6+λ4)/(λ6+λ4+1),如果λ≤0.86,则在这种情况下,负多数意见获胜;但是,如果λ≥0.87,则新模型的投票结果超过了两个较老的反对意见,结果是正类。因此可以调整参数λ以平衡大量旧信息与较少量新信息的重要性。
本文方法使用以前的GBAD迭代的结果来识别后续数据块中的异常。也就是说,在先前的GBAD迭代中发现的规范子结构可能在每个模型中持续存在。这允许每个模型引入所有数据,而不仅仅是当前块的数据。当流观察到概念漂移时,这可以是显著的优点,因为模型集合可以识别整个数据流或大量块而不是当前块中的规范模式。因此,仍然可以检测到罕见的内网恶意行为。
重要的是要注意,集成的大小随着时间的推移保持固定。表现不佳的过时模型将被更适合当前概念的更好的新模型所取代。这使得每轮分类都易于处理,即使流中的数据总量可能无限制。
4 基于图的异常检测
算法1 使用3 种GBAD 来推断使用每种模型的潜在异常。GBAD是一种基于图的方法,通过搜索3个因素来查找数据中的异常:顶点和边的修改、插入和删除。每个独特因子都运行自己的算法,找到规范的子结构,并尝试找到与发现的规范子结构相似但不完全相同的子结构。规范子结构是顶点和边的重复子图,当合并为单个顶点时,大多数压缩整个图。图3 中的矩形标识了所描绘图的标准子结构的示例。

Fig.3 Graph with canonical substructures and exceptions图3 具有规范子结构和异常的图
使用SUBDUE[32-34]来查找规范的子结构。最佳规范子结构可以表征为具有最小描述长度(MDL)[35-37]的子结构:

其中,G是整个图;S是被分析的子结构;DL(G|S)是被S压缩后的G的描述长度;DL(S)是被分析的子结构的描述长度。描述长度DL(G)是描述图G[38-39]所需的最小位数。
内网异常与规范子结构的差异很小。这是因为内网异常试图严密模仿合法的系统操作。应用3 种不同的方法来识别这种异常[40-41],如下所述。
4.1 GBAD-MDL
在找到最佳压缩规范子结构后,GBAD-MDL 在随后的子结构中搜索与该规范子结构的偏差。通过分析与标准尺寸相同的子结构,识别边缘和顶点标签以及边缘的方向或端点的差异。最异常的是那些子结构,其中需要最少的修改来产生与标准结构同构的子结构。在图3 中,标记为E的阴影顶点是GBAD-MDL发现的异常。
4.2 GBAD-P
相反,GBAD-P搜索插入操作,如果删除,则产生标准子结构。对图形的插入被视为规范子结构的扩展。GBAD-P 基于边缘和顶点标签计算每个扩展的概率,因此利用标签信息来发现异常。概率由下式给出:

其中,A表示边或顶点属性,v表示其值。
概率P(A=v|A)可以通过高斯分布生成:

其中,μ是平均值,σ是标准偏差。较高的ρ(x)值对应于更多的异常子结构。
因此,使用GBAD-P 可确保本文算法将图中实际数据(而不仅仅是其结构)反映的恶意内网行为可靠地识别为异常。图3中,标记为C的阴影顶点是GBAD-P发现的异常。
4.3 GBAD-MPS
最后,GBAD-MPS 考虑删除,如果重新插入,则产生规范的子结构。为了发现这些,GBAD-MPS 检查了父结构。父级中大小和方向的变化表示子图之间的删除。最异常的子结构是使父子结构相同所需的转换成本最小的子结构。在图3中,由于阴影矩形标记的B和D之间缺少边缘,因此GBAD-MPS 将A-B-C-D顶点的最后一个子结构识别为异常。
5 实验
在2018 年林肯实验室入侵检测数据集[42-47]上测试了本文算法。此数据集由每日系统日志组成,其中包含所有进程执行的所有系统调用。它是使用基本安全模式(basic security model,BSM)审计程序创建的。每个日志都包含使用图4 中举例说明的语法表示系统调用的令牌。

Fig.4 Example of system call record from MIT Lincoln dataset图4 来自MIT Lincoln数据集的系统调用记录示例
令牌参数以标题行开头,以拖车行结束。标题行以字节为单位报告令牌的大小、版本号、系统调用以及执行的日期和时间(以ms为单位)。第二行报告执行进程的完整路径名。可选属性行标识所有者、文件系统和节点以及设备的用户和组。下一行报告系统调用的参数数量,后跟下一行的参数本身。主题行报告审计ID、有效用户和组ID、真实用户和组ID、进程ID、会话ID、终端端口和地址。最后,返回行报告系统调用的结果和返回值。
由于许多系统调用是与任何特定用户无关的自动过程的结果,因此对于内网异常检测,将注意力限制在用户附属系统调用上。这些包括调用exec、execve、utime、login、logout、su、rsh、rexecd、passwd、rexd和ftp。所有这些都对应于用户执行的登录/注销或文件操作,因此与内网异常检测相关。限制对此类操作的关注有助于减少数据集中的外来噪声。通过以这些令牌为源点,提取关键属性作为有向边的标签,对应属性的值为顶点,而产生的令牌子图如图5所示。
由于不同的原因,图5 中的每个属性都很重要。例如,路径值可以指示正被访问的信息的重要性或安全级别。文件路径访问位置的更改或给定用户正在执行的系统调用类型可能表示应调查的异常行为。exec 和execve 调用的文件路径显示每个用户执行的各种程序。进程ID允许跟踪任何给定进程所做的所有系统调用,指示该进程随时间的行为。终端信息为用户提供了一种地点数据形式。如果用户从意外位置登录或显示某些位置的异常行为,则可能表示使用了被盗凭据或其他恶意活动。
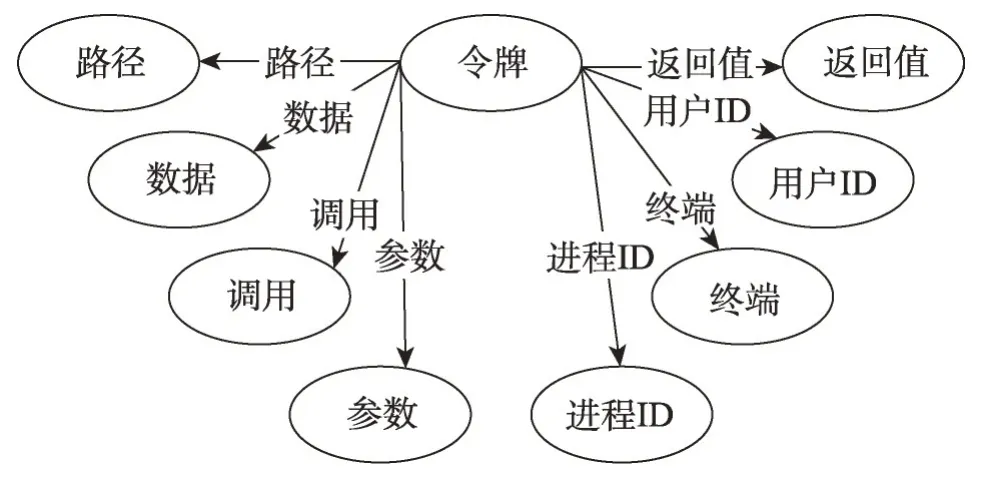
Fig.5 Token subgraph图5 一个令牌子图
表2 显示了在过滤掉所有不相关的令牌并且已经提取了图5 中的属性数据之后数据集的统计数据。预处理提取了跨越500 000 顶点的62 000 令牌。这些反映了9 个星期以来所有用户的活动。将集成学习算法应用于此数据,其中模型(K)的数量分别设置为1、3、5、7 和9,在令牌子图中找到规范子结构的集合。在每次集合迭代期间,每个模型选择最佳的5 个规范子结构用于异常检测。可以将算法配置为使用5 个以上,但是此默认值产生了良好的结果,因此保持不变。
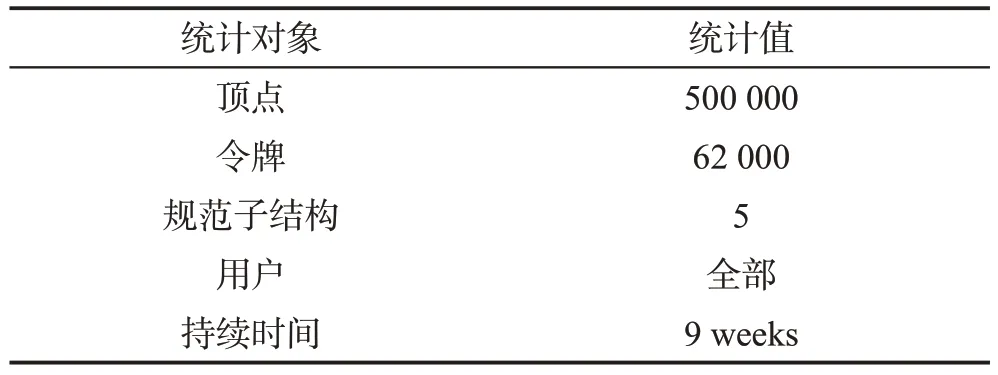
Table 2 Data set statistics after filtering and attribute extraction表2 过滤和属性提取后的数据集统计
性能以总误报(FP)和漏报(FN)来衡量。之所以选择林肯数据集是因为它的体积很大,并且因为它的异常集是众所周知的,所以通过计数来促进准确的性能评估。表3总结了结果,以及异常(true positive,TP)的计数。全部模型实现了零漏报。K=1 的线反映了非整体单模型GBAD方法的性能。当集成规模K在3 以上时,误报均在200 以下,相对于使用单模型,误报率大大下降。并且,K=9 模型的集成学习可以减少84%的误报率,虽然系统误报的异常数相对于真正的异常较大,但合适地选择集成大小,可以实现一个很好的平衡,既实现低漏报,又可以保证发现的异常规模是可处理的,因为相比于待识别的异常规模,内网异常危害更大。因此,有理由相信利用图挖掘的无监督优势同时,融入了对流变化性的考虑,可以有效地识别内网中的异常活动。
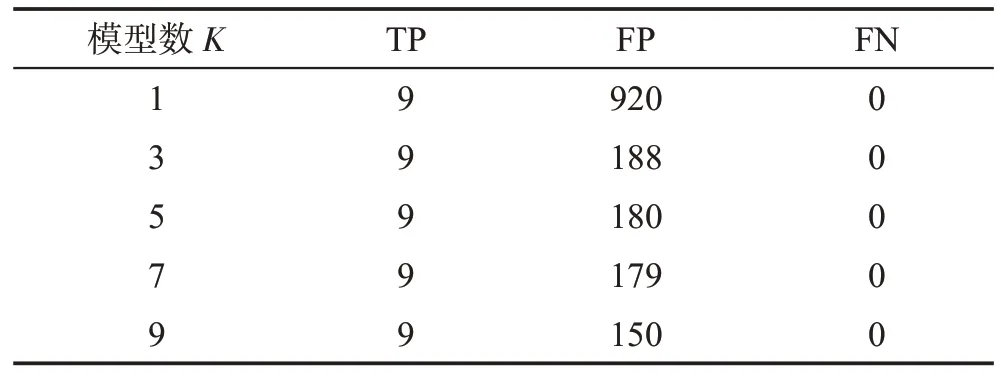
Table 3 All integrated TP and FP count表3 全部集成的TP和FP计数
从K=1 到K=3 观察到增加模型计数的最大影响。这表明即使集成中模型数很小比如K=2,也比单模型方法K=1提供了显著的改进。它还揭示了当计算时间非常宝贵时,小型集成可以在合理的运行时间内提供高分类精度。在本文实验中,使用K=3模型比K=9 的情况下实现误报减少(减少了80%),但运行时间不到10。
图6 显示了每个集成随时间推移而产生的误报的分布。在此数据集中,所有真正的内网异常活动都发生在第6周,导致该周的误报率激增。在前5个星期,随着它们学习合法的行为模式,集成方法逐渐改善,而单一模型的方法激烈振荡。当恶意内网行为出现在第6 周时,两种方法的误报率都在上升,因为它们试图学习新概念。集成方法在很大程度上取得了成功,在接下来的几周内产生了低误报率,但单一模型方法已经被破坏。它无法充分编码同一模型中与合法行为和非法行为相关的概念,导致第9周误报率急剧上升。
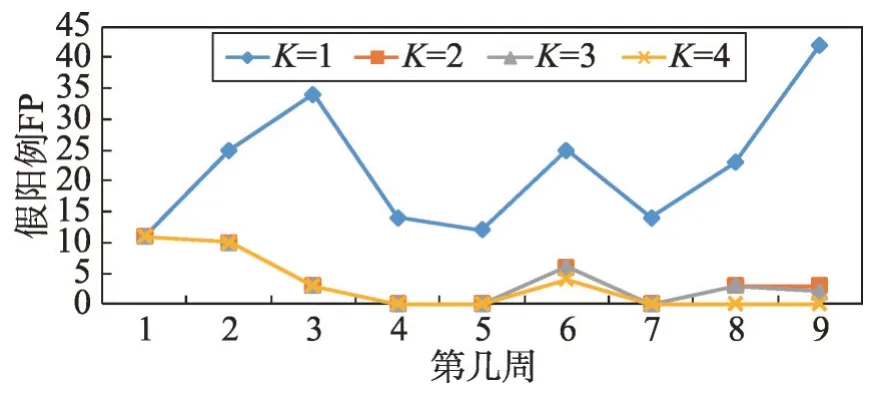
Fig.6 Distribution of false positives图6 假阳(误报)的分布
接下来研究参数K(集成大小)和q(每个模型的规范子结构的数量)对分类精度和运行时间的影响。为了更容易地执行绘制这些关系所需的大量实验,使用表4中总结的较小数据集进行这些实验。数据集A 包括在第2~第8 周期间与用户Donaldh 相关联的活动,数据集B 在第4~第7 周期间用于用户William。这些用户中的每一个在相应的时间段内显示恶意内网活动。这两个数据集都表明了今后讨论的所有关系的类似趋势。因此,仅报告数据集A的详细信息。
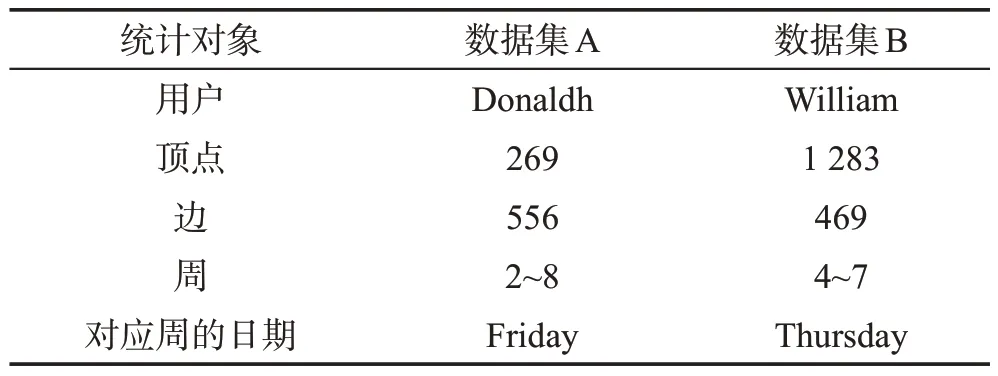
Table 4 Summary of data set A and data set B表4 数据集A和数据集B的总结
图7 显示了规范子结构数量q与数据集A 中的运行时间之间的关系。由于数据集A 中只有4 个规范结构,因此时间增加近似线性,直到q=5。因此,对第5个结构的搜索失败(但是会影响运行时间),而较高的q值则没有进一步的影响。
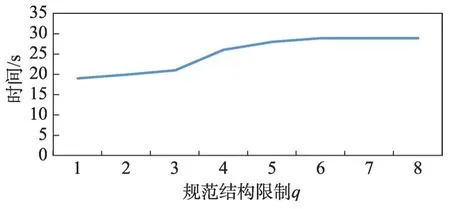
Fig.7 Effect ofq on running time of fixedK=6 on data set A图7 K=6 时q 对数据集A上运行时间的影响
图8 显示了集成中总体模型数K对数据集A 的运行时间的影响。正如预期的那样,运行时间随着模型的数量逐渐增加(在该数据集中平均每个模型2 s)。
增加q和K也有助于提高TP。图9和图10分别通过显示q和K与TP 的正关系来说明。当q和K增加到一定数量时,分类器可靠地检测数据集A中的所有7个真阳性。因此,q和K的这些值在对内部威胁的覆盖率和高响应性所需的有效运行时间之间达到了最佳平衡。

Fig.8 Effect ofK on running time of fixedq=4 on data set A图8 q=4 时K 对数据集A上运行时间的影响
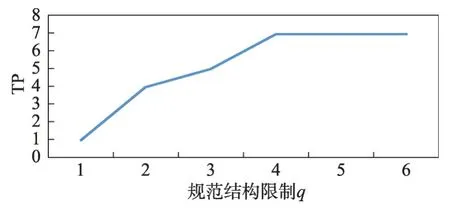
Fig.9 Effect ofq on true positive count of fixedK=6 on data set A图9 K=6 时q 对数据集A上TP计数的影响

Fig.10 Effect ofK on true positive count of fixedq=4 on data set A图10 q=4 时K 对数据集A上TP计数的影响
表5 考虑了加权与未加权多数表决对固定q=3的分类精度的影响。未加权列是λ=1 的列,加权列使用衰落因子λ=0.9。数据集包含与用户donaldh 相关联的所有令牌。加权多数表决在这些实验中没有影响,除非K=4,其中FP率从124(未加权)降低到85(加权)并且将TN 率从51(未加权)增加到90(加权)。然而由于这些结果可以在K=3时没有加权投票的情况下获得,得出结论,加权投票仅用于减轻K的不良选择;当明智地选择K时,加权投票与否几乎没有什么影响。
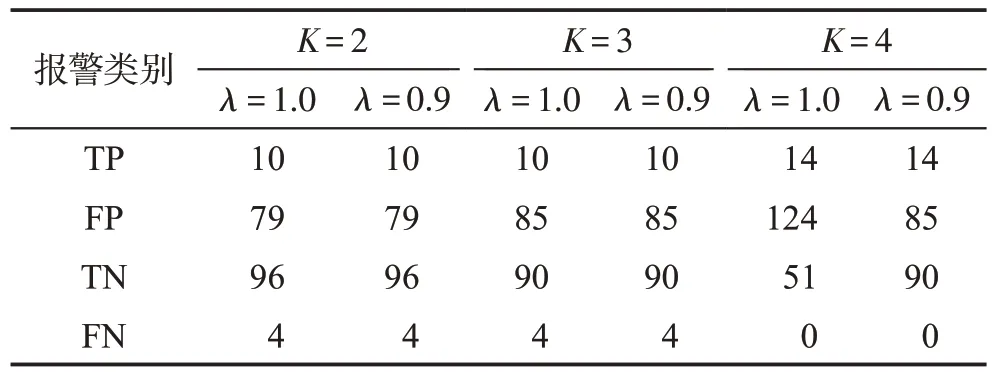
Table 5 Effect of fading factorλ (weighted voting)表5 衰落因子λ 的影响(加权投票)
实验证明,本文提出的集成方法在累积的系统日志中可以有效地识别内网异常。在现实世界中,恶意内部人员的活动往往极力模仿正常人员的活动方式,因此本文结合图挖掘算法,在发挥其无监督优势的同时,通过规范子结构可以有效地发现偏离正常行为的活动。并且本文所提方法通过集成分类和更新,可以有效识别随时间变化的内网异常,同时使用投票提高了分类准确率,避免了单一模型的分类准确率低的性质。因此,对于隐藏在大量数据流中的内网异常且无标记的数据时,本文所提出的基于流挖掘和图挖掘的集成方法是十分有意义的。
6 结论和未来工作
基于集成的内网异常检测方法成功识别出林肯实验室入侵检测数据集中的所有异常,其漏报为零,误报率低于相关的单模型方法。该方法将基于图挖掘的异常检测的非监督优势与流挖掘的自适应性相结合,以实现内网异常检测。
未来的工作应该考虑可调参数以及在其他场景中的参数选择问题,以进一步降低误报率和提升方法的扩展性,为此仍有很大的改进空间。此外,更复杂的轮询算法可以对更好模型的投票进行加权,这可能具有显著的准确性优势。
减少分类器运行时间对于快速检测和响应新出现的内网异常也很重要。本文中的实验是使用纯串行实现进行的,但是整体算法包括大量的并行化空间。因此,未来的工作应该研究分布式和云计算技术的应用,以提高效率。
最后,尽管实际的内网异常检测机制必须现实地假设标记数据点形式的真实值通常是不可用的,但如果这些标签随着时间的推移变得可用则利用这些标签将是有益的。因此,未来的研究应该检查在集成内用监督学习更新模型的技术,以提高部分标记流的分类准确性。
猜你喜欢
计算机系统应用(2019年3期)2019-03-11
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
科技资讯(2017年5期)2017-04-12
科技创新与应用(2016年35期)2017-02-21
少儿科学周刊·少年版(2015年3期)2015-07-07
中国信息化·学术版(2013年1期)2013-05-28
智能计算机与应用(2007年4期)2007-08-25
