
基于FasterRCNN的行人及车辆类型检测
2020-07-04 02:27邵丽萍魏相站李春红唐志英白忠臣张正平
智能计算机与应用 2020年3期
关键词:特征提取
邵丽萍 魏相站 李春红 唐志英 白忠臣 张正平

摘要:随着汽车数量与日俱增,交通事故的发生频次也在增加,针对车辆类型和行人的检测问题,本文在原始Faster RCNN的基础上,首先使用残差网络RES101代替传统的VGG16网络作为共享卷积层,进行图像特征的提取,然后改变原来的锚框尺寸方案,使用锚框尺寸为4、8、16代替原来锚框尺寸,得到行人及车辆类型检测模型。通过在KITTI测试集上的测试结果表明,使用本文模型平均检测准确率可达86.5%, 相比原始Faster RCNN平均准确率提高了3.65%,相比于使用残差网络RES101作为卷积层的Faster RCNN平均准确率提高了2.06%。
关键词: Faster RCNN; 残差网络; 特征提取; 锚框选区
【Abstract】 With the increasing number of vehicles and frequent traffic accidents, aiming at the detection of pedestrians and vehicle types, based on the original Faster RCNN, firstly, the residual network RES101 is used instead of the traditional VGG16 network as the shared convolutional layer to extract the image features. Then, the original anchor frame size scheme is changed, and the size of the anchor frame is 4, 8 and 16 instead of the size of the original anchor frame, and the pedestrian and vehicle type detection model are obtained. The test results on the KITTI test set show that the average detection accuracy of the proposed model is 86.5%, 3.65% higher than the original Faster RCNN, and 2.06% higher than the original Faster RCNN using residual network RES101 as the convolutional layer.
【Key words】 Faster RCNN; residual network; feature extraction; anchor frame selection
0 引 言
目前,隨着城市汽车数量的增多,道路交通流量在不断地增加,对汽车驾驶的安全性也提出了更高的要求。而自动驾驶作为汽车辅助驾驶的系统,能够确保汽车在行驶途中的安全,现已成为当下的热门实用研发技术之一。自动驾驶的主要技术分为行人检测、碰撞检测及夜视辅助等,而碰撞检测与行人检测的实现依赖于计算机视觉技术中的图像识别技术对汽车行驶途中的车辆和行人进行识别。在汽车行驶过程中,计算机只能识别到目标图像的RGB像素矩阵,为了得到较好的识别效果,本次研究中使用了Faster RCNN[1-2]算法对汽车行驶路线中的车辆和行人进行识别[2-4]。基于此,文中提出了一种改进Faster RCNN的目标检测方法,使用ResNet-101深度残差网络代替传统的VGG16网络作为特征提取网络,并且调整锚框尺寸大小来提高检测的准确率,最后在KITTI数据集上进行测试。
1 Faster RCNN模型简介
1.1 Faster RCNN结构
为了使检测算法能够对车辆类型进行快速有效地定位和检测,使用ResNet-101代替传统的VGG16作为共享卷积层,并且对区域建议网络中最终生成的感兴趣区域数量进行调整,使算法在保证准确率的基础上进一步提高检测速度。模型整体结构如图1所示。由图1可知,该模型结构中的各主要部分的功能描述具体如下:对数据集图像进行特征提取生成特征图;使用RPN区域来调整候选框并得到调整好的候选框;通过ROI池化层得到固定大小的兴趣区域;送入全连接层和softmax[5]计算求得每个候选框的所属类别,输出类别的得分;同时再次利用框回归获得每个候选区相对实际位置的偏移量预测值,用于对候选框进行修正,得到更精确的目标检测框。
1.2 RPN网络
RPN网络是Faster R-CNN的核心,是一种全卷积网络,用来对目标检测网络进行选择性搜索。经过卷积神经网络进行特征提取的特征图输入到RPN网络,先进行一次3*3的卷积运算,再分别进行2次1*1的卷积运算。其中,一个是计算检测区域是前景或背景的概率,用来给softmax层进行前景或背景分类;另一个是用于给候选区域精确定位[6]。RPN网络使用滑动窗口,可同时预测多个候选区,滑动每一个滑动窗口后都会产生一个特征向量,将产生的特征向量传送到全连接层即可判断检测目标的位置和类别[7]。RPN网络的结构如图2所示,RPN网络共有K个锚框、K个区域建议框、2K个对应分类层输出及4K个对应回归层输出,其中的分类层输出用来指示非目标与目标的概率,回归层输出用来标注区域建议框的位置。
2 改进部分
2.1 锚框尺寸调整
由于车辆类型和人的检测受建筑物和树木遮挡等的影响,导致车辆和人的显示尺寸差异比较大,其长宽比也是复杂多样。原始的Faster RCNN模型包含9种锚框,其长宽比分别为0.5,1,2,尺寸分别为8,16,32。如果按照原始Faster RCNN模型的锚框方案,输入图像在经过池化后,特征图中的各点对应的感受野尺寸为 16×16。使用最小尺度映射的锚框尺寸都达到128,而实际中存在一些距离较远的行人以及车辆,进而其占有的尺寸也比较小,由于这些较小尺寸的目标在测试时可能会出现一定的定位偏差,进而造成检测错误,准确率也会随之降低。因此,根据人和车辆尺寸差异比较大、长宽比更加复杂多样的特点,即可调整原始FasterRCNN模型中的RPN网络的锚框尺寸。调整后锚框的种类保持不变,只是将锚框尺寸改成4,8,16,有助于增强对距离远的行人以及车辆的检测。测试结果表明,经过调整后的锚框尺寸可以使得检测准确率提高。锚框尺寸对比见表1。
2.2 ResNet网络
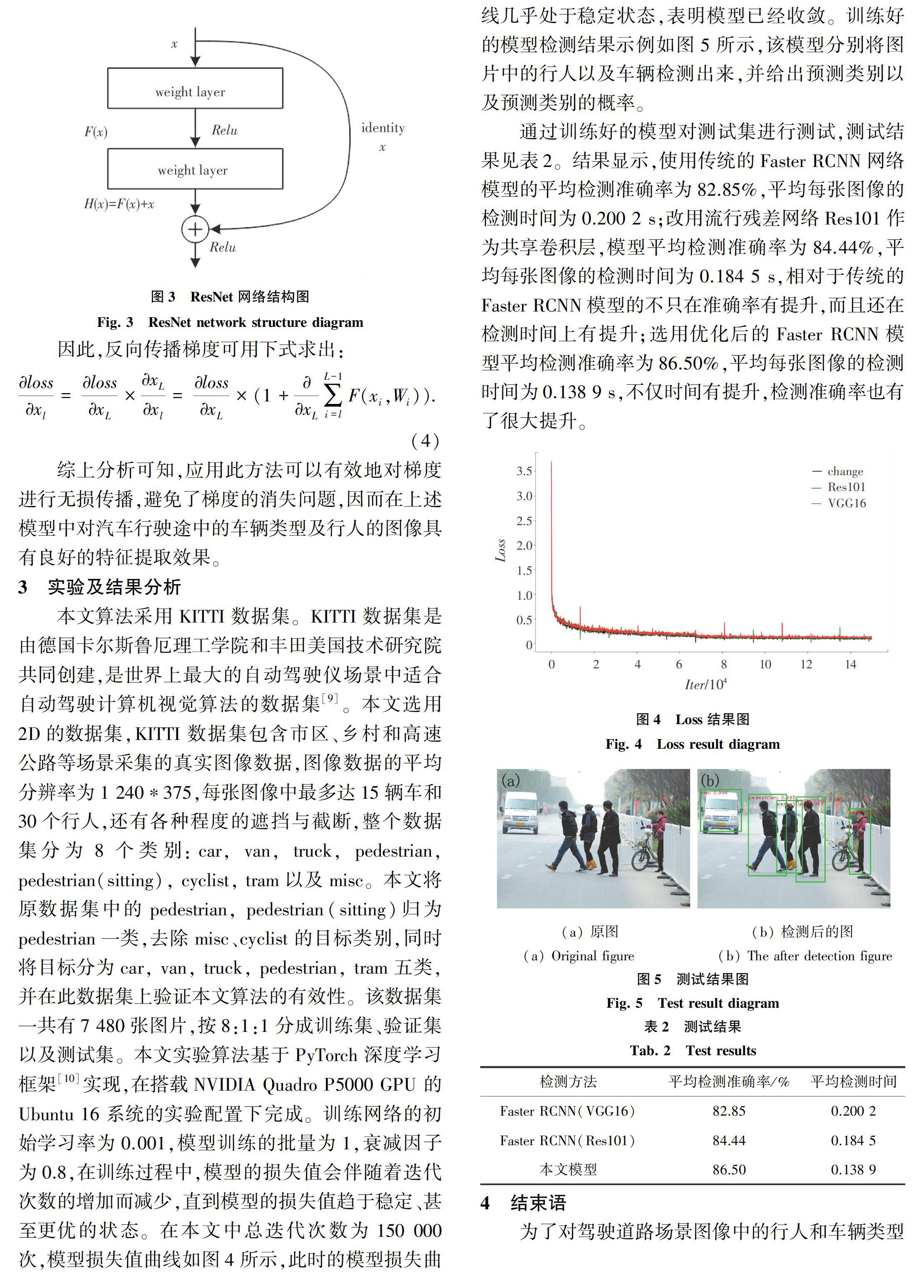
在深层网络提取的特征图中,远距离的检测目标特征提取量很少,这就需要对特征提取网络做出改进,让改进后的特征提取网络获取图像中更多的小尺寸物体的特征。由于残差网络[8]在网络卷积中加入大量的跳跃连接,使其能够在训练较深的网络中提取更多小尺寸物体特征。ResNet网络已经成功训练出了152层神经网络,还加入了残差模块(Residual block),在网络深度增加的同时,有效地保证了模型的准确度。ResNet网络结构如图3所示。由图3可知,在网络结构中添加了直连通道来实现隔层连接,将初始的输入数据传递到后面的网络层中。对于输入的x期望,假设所要求的映射关系为H(x),在求解过程中,H(x)比F(x)复杂得多,因而研究可以通过求出H(x)的残差形式,也即H(x)=F(x)-x来实现。
综上分析可知,应用此方法可以有效地对梯度進行无损传播,避免了梯度的消失问题,因而在上述模型中对汽车行驶途中的车辆类型及行人的图像具有良好的特征提取效果。
3 实验及结果分析
本文算法采用KITTI数据集。KITTI数据集是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院共同创建,是世界上最大的自动驾驶仪场景中适合自动驾驶计算机视觉算法的数据集[9]。本文选用2D的数据集,KITTI数据集包含市区、乡村和高速公路等场景采集的真实图像数据,图像数据的平均分辨率为1 240*375,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断,整个数据集分为8个类别:car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc。本文将原数据集中的pedestrian, pedestrian(sitting)归为pedestrian一类,去除misc、cyclist的目标类别,同时将目标分为car, van, truck, pedestrian, tram五类,并在此数据集上验证本文算法的有效性。该数据集一共有7 480张图片,按8:1:1分成训练集、验证集以及测试集。本文实验算法基于PyTorch深度学习框架[10]实现,在搭载NVIDIA Quadro P5000 GPU 的Ubuntu 16 系统的实验配置下完成。训练网络的初始学习率为0.001,模型训练的批量为1,衰减因子为0.8,在训练过程中,模型的损失值会伴随着迭代次数的增加而减少,直到模型的损失值趋于稳定、甚至更优的状态。在本文中总迭代次数为150 000次,模型损失值曲线如图4所示,此时的模型损失曲线几乎处于稳定状态,表明模型已经收敛。训练好的模型检测结果示例如图5所示,该模型分别将图片中的行人以及车辆检测出来,并给出预测类别以及预测类别的概率。
通过训练好的模型对测试集进行测试,测试结果见表2。结果显示,使用传统的Faster RCNN网络模型的平均检测准确率为82.85%,平均每张图像的检测时间为0.200 2 s;改用流行残差网络Res101作为共享卷积层,模型平均检测准确率为84.44%,平均每张图像的检测时间为0.184 5 s,相对于传统的Faster RCNN模型的不只在准确率有提升,而且还在检测时间上有提升;选用优化后的Faster RCNN模型平均检测准确率为86.50%,平均每张图像的检测时间为0.138 9 s,不仅时间有提升,检测准确率也有了很大提升。
4 结束语
为了对驾驶道路场景图像中的行人和车辆类型进行准确、快速的检测定位,本文提出了一种改进的Faster RCNN检测算法用于行人和车辆类型检测,使用ResNet-101残差网络代替传统VGG网络作为共享卷积层,用来提取图像特征,再改变原来的锚框选区方案,使用锚框尺寸为4、8、16代替原来锚框尺寸,得到行人及车辆类型检测模型,使得算法在 KITTI数据集上有较为先进的表现。本文对行人和车辆类型检测能够得到较高的检测精度,在检测速度上比同类算法更快,更具备应用到自动驾驶系统的价值。
参考文献
[1] REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 39(6):1137.
[2] 王林, 张鹤鹤. Faster R-CNN模型在车辆检测中的应用[J]. 计算机应用, 2018,38(3):666.
[3] 楚翔宇. 基于深度学习的交通视频检测及车型分类研究[D]. 哈尔滨:哈尔滨工业大学,2017.
[4] 胡葵, 章东平, 杨力. 卷积神经网络的多尺度行人检测[J]. 中国计量大学学报, 2017,28(4):69.
[5] JANG E , GU Shixiang, POOLE B . Categorical reparameterization with Gumbel-Softmax[J]. arXiv preprint arXiv:1611.01144v5,2017.
[6] 吴帅, 徐勇, 赵东宁. 基于深度卷积网络的目标检测综述[J]. 模式识别与人工智能, 2018,31(4):45.
[7] 李明攀. 基于深度学习的目标检测算法研究[D]. 杭州:浙江大学,2018.
[8]刘敦强, 沈峘, 夏瀚笙, 等. 一种基于深度残差网络的车型识别方法[J]. 计算机技术与发展, 2018,28(5):42.
[9]曾俊东. 基于卷积神经网络的监控视频车型识别系统设计与实现[D]. 成都:西南交通大学, 2017.
[10]郭爱心. 基于深度卷积特征融合的多尺度行人检测[D]. 合肥:中国科学技术大学, 2018.
[11]黄一天, 陈芝彤. Pytorch框架下基于卷积神经网络实现手写数字识别[J]. 电子技术与软件工程, 2018(19):147.
猜你喜欢
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
软件导刊(2016年12期)2017-01-21
现代电子技术(2016年23期)2017-01-12
计算技术与自动化(2016年4期)2017-01-11
无线互联科技(2016年13期)2017-01-10
科技传播(2016年19期)2016-12-27
新媒体研究(2016年21期)2016-12-19
电脑知识与技术(2016年25期)2016-11-16
