
基于ReLU稀疏性的MAXOUT卷积神经网络的数据分类算法
2020-07-02 00:05:56赵馨宇黄福珍周晨旭
上海电力大学学报 2020年3期
赵馨宇, 黄福珍, 周晨旭
(1.上海电力大学, 上海 200090; 2.上海市政工程设计研究总院(集团)有限公司, 上海 201900)
图像特征的提取与分类一直是计算机视觉领域的重要研究方向。卷积神经网络提供了一种端到端的学习模型,模型中的参数可以通过传统的梯度下降方法进行训练,经过训练的卷积神经网络能够学习图像中的特征,完成对图像特征的提取和分类。近年来,卷积神经网络不断得到改进,应用领域进一步扩展,而在各个领域中不断涌现出来的研究成果更使其成为了当前研究热点之一[1]。
卷积神经网络雏形可以追溯到1980年,由日本学者福岛邦彦提出多层的人工神经网络。这个网络层与层之间釆用十分稀疏的局部连接,对数据的轻微缩放和旋转具有不变性,但是缺少对其训练的学习算法。之后涌现出对简单卷积神经网络进行训练的反向传播算法。到了1998年,由LECUN Y等人[2]提出了真正意义上的卷积神经网络——LeNet-5卷积神经网络。该网络由于采用了局部连接、权值共享和子釆样操作,在手写字符识别中的成功应用引起了广泛的关注。同一时期,卷积神经网络在语音识别、物体检测、人脸识别等方面的研究也逐渐开展起来,卷积神经网络进入了广泛研究时期。2012年,由KRIZHEVSKY A等人[3]提出的Alex Net,牛津大学的 VGG(Visual GeometryGroup)、Google的 GoogLeNet、微软的ResNet等都在图像分类等方面取得了成功。
在卷积神经网络中,起着决定性作用的是激活函数的选择,不同的激活函数对于网络的性能具有很大的影响。激活函数不同,所适用的网络类型,甚至应用领域也不同,而激活函数的选择一般通过经验或实验来确定。如若通过经验来选择,则可能出现不准确或者无先验知识可寻的情况。若通过实验来选择,由于训练算法等的参数需要一一确定最优参数,往往会出现工作量大且实验时间较长的情况,所以激活函数的选择成为了难点。
2013年,GOODFELLOW I J等人[4]提出了MAXOUT神经网络,取一系列线性函数的最大值作为激活函数的激活值,利用多条线性函数拟合成局部线性的激活函数,且当线性函数数量趋于无穷时,可以拟合成任意的函数,MAXOUT神经网络的提出解决了激活函数选择困难的问题。但是MAXOUT卷积神经网络也存在着明显的缺点,即激活值不稀疏。
针对该问题,有研究者提出将稀疏性引入MAXOUT卷积神经网络来改进的方法:MIAO Y等人[5]提出可以采用非最大值掩码,在保留最大值的情况下将其他值设为零;另一种方法是SRIVASTAVA R K等人[6]提出在pooling的局部区域中,除最大值以外其余设置为零。虽然这两种方法引入了稀疏性,但是丢失了MAXOUT降维的优点。线性修正单元(Rectified Linear Unit,ReLU)可以同时保留稀疏性和降维的优点。
本文将通过ReLU对MAXOUT卷积神经网络引进稀疏性并探讨其改进后的效果。
1 MAXOUT卷积神经网络及其稀疏性改进
1.1 卷积神经网络
卷积神经网络是一种特殊的具有深度学习能力的人工神经网络,能自动学习图像信号内容的内在特征[7]。它的特殊性体现在:一是相邻两层神经元是局部连接而非全连接;二是同一层的部分神经元的权值是共享的。基于这两方面,卷积神经网络与其他的算法相比,减少了权值量,降低了复杂度;尤其在视觉方面优势显著,大大提高了运算效率。
1.2 MAXOUT卷积神经网络
作为前馈神经网络模型的一种,MAXOUT卷积神经网络与其他卷积神经网络不同之处在于激活函数上的选择,不是选择一般的激活函数,而是采取MAXOUT单元的方式。对于给定的输入x∈Rd(可见层或隐藏层的状态),MAXOUT隐藏层实现的功能如下
hi(x)=max(zij),j∈[1,k]
(1)
zij=xTWij+bij
(2)
式中:hi(x)——输出;
Wij——权值;
bij——偏置值。
Wij∈Rd×m,bij∈Rm是通过学习得到的。
MAXOUT卷积神经网络的特征图是在k张仿射特征图上按神经元依次在对应位置取最大值的方式得到的,具体如图1所示。

图1 MAXOUT卷积神经网络的特征图
1.3 基于ReLU稀疏性的MAXOUT卷积神经网络
机器学习领域中,稀疏性的研究[8-9]一直都是热点,尤其在图像识别方面,稀疏性相对来说具有更理想的分类效果。尽管MAXOUT神经网络在激活函数的选择上有了很大的进步,但是激活值一直存在不稀疏的缺点,从而限制了分类精度,所以通过引入ReLU函数来提高稀疏性。
ReLU是一个分段函数,若输入值小于或者等于零,则结果为零;若输入值大于零,则输出值保持原值不变。定义式为:f(x)=max(0,x)。这种方法操作简单,只需要一个阈值获取激活值,整个过程中会使得一些数据强制为零,但增加了训练之后网络的稀疏性,更加符合神经元信号激励原理。这种操作不但使得参数间减少了相互依赖,而且对于过拟合问题的发生具有极大的缓解作用。
利用ReLU对k张仿射特征图进行映射,在得到的k张特征图中采取MAXOUT卷积神经网络的方法,按元素依次取最大值,最终将得到的特征图中负值元素全置为零,其余元素保持不变。采用该方法优点如下:相对于MAXOUT卷积神经网络引入了稀疏性;相对于非最大值掩码的方法,保留了降维的优点;ReLU激活值大于零时,其导数为1,基于ReLU的MAXOUT卷积神经网络算法相对于原始MAXOUT卷积神经网络在采用梯度下降法进行学习时区别不大,所以非零元素的激活值没有太大的差异。ReLU稀疏性原理如图2所示。
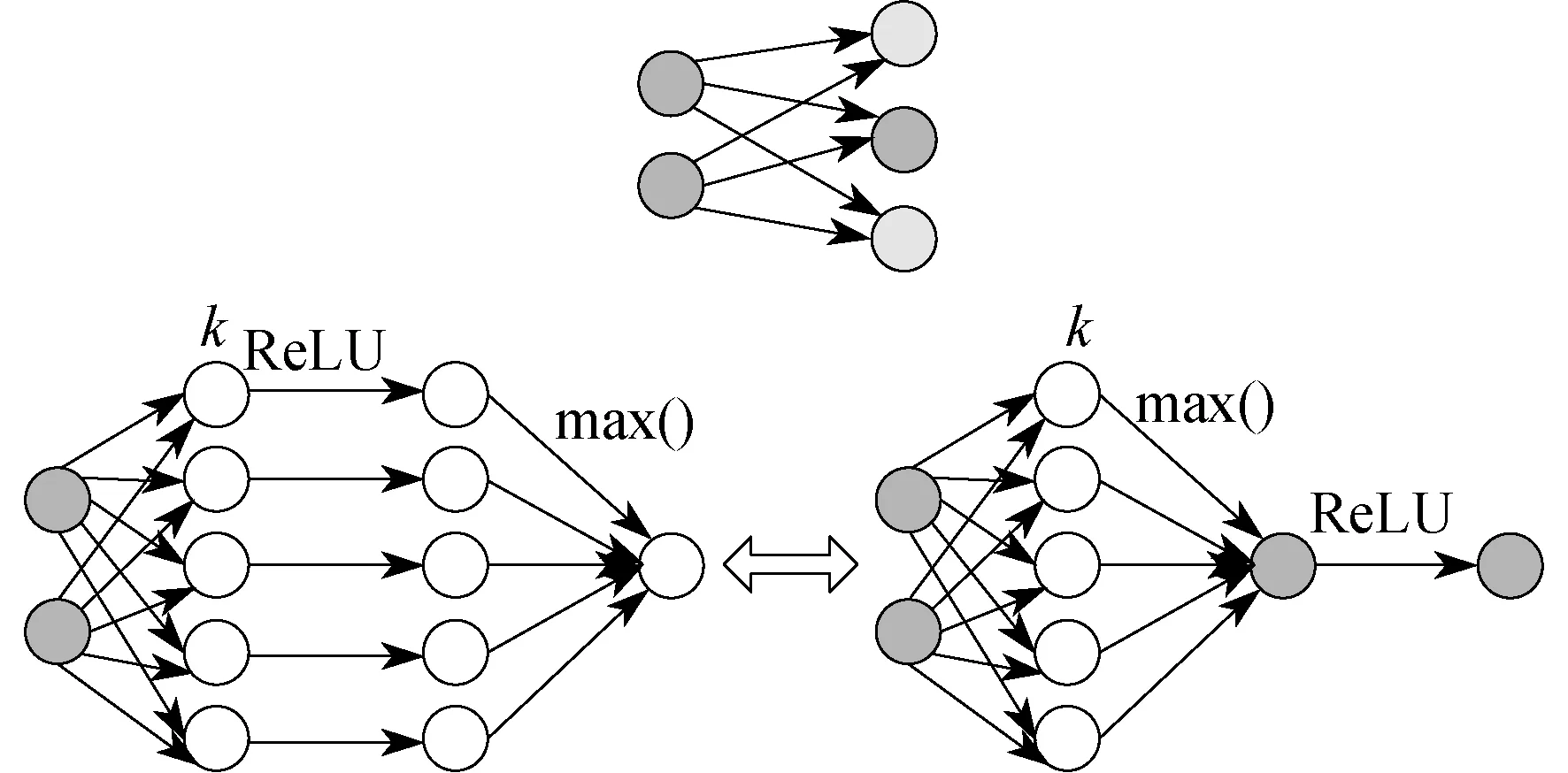
图2 ReLU稀疏性原理
2 数据分类的实验过程及结果分析
2.1 实验数据集介绍
本文实验数据集采用应用广泛的数字识别库MINST和CIFAR-10数据集。
2.1.1 MINST
MINST数据集属于NIST数据集的子集,是一个包含阿拉伯数字0~9手写字体的数据集。NIST数据集训练集的作者来自于美国人工调查局员工,测试集的作者则来自于美国高中生,因为两者的作者不同,所以训练集和测试集是完全独立,没有任何关联的。MINST数据集的训练集与测试集有一半来自于NIST数据集的测试集,另一半来自于NIST数据集的训练集。MINST数据集共包括70 000张,其中训练集60 000张,测试集10 000张。该集合经过了统一处理,数字均位于图像中央,并且均为28×28的灰度图像,像素值域为[0,255]。MINST数据集的部分数据样本如图3所示。由图3可以看到,同一个数字因为手写作者不同,有着不同的形态。

图3 MINST数据集的部分数据样本
2.1.2 CIFAR-10
CIFAR-10数据集属于8千万张小图数据集的子集,包括60 000张32×32的彩色图像,分为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车10个种类,每种图片6 000张。60 000张图片中训练图像50 000张,测试图像10 000张。CIFAR-10数据集的部分图像样本如图4所示。图4中,每行图像虽然是同一类物品,但是形状、颜色、拍摄角度等方面存在较大的差异。

图4 CIFAR10数据集的部分数据样本
2.2 实验过程及结果分析
本文通过研究基于ReLU稀疏性的MAXOUT卷积神经网络在MINST数据集和CIFAR-10两个数据集中的分类情况,分别研究了感受野和池化层对于分类情况的影响,采用控制变量的方法,即其余变量不变,分别改变两者之一的值来研究对于分类的影响。
2.2.1 感受野的影响
为了研究感受野(卷积核)对于稀疏性MAXOUT卷积神经网络的分类影响,在其他条件不变的情况下,取感受野的值分别为7×7,5×5,3×3,2×2,对比分析在MINST数据集和CIFAR-10数据集中的表现来判断其影响。实验结果分别如图5所示。
由图5可以看出,理论上当其他条件一致的情况下,感受野越小,分类错误率越小,分类特性越好。但在实际情况下,感受野为1×1时,即卷积比较小时,卷积噪声影响会很大,所以结合实际来看,感受野为3×3时结果比较理想。
2.2.2 池化层的影响
池化层的影响分为池化方法和池化大小的影响。
一是池化方法的影响。池化方法主要包括 mean pooling,max pooling和stochastic pooling 3种,分别测试这3种方法对于MINST数据集和CIFAR-10数据集的分类影响。实验结果中最好的数据分别如表1和表2所示。
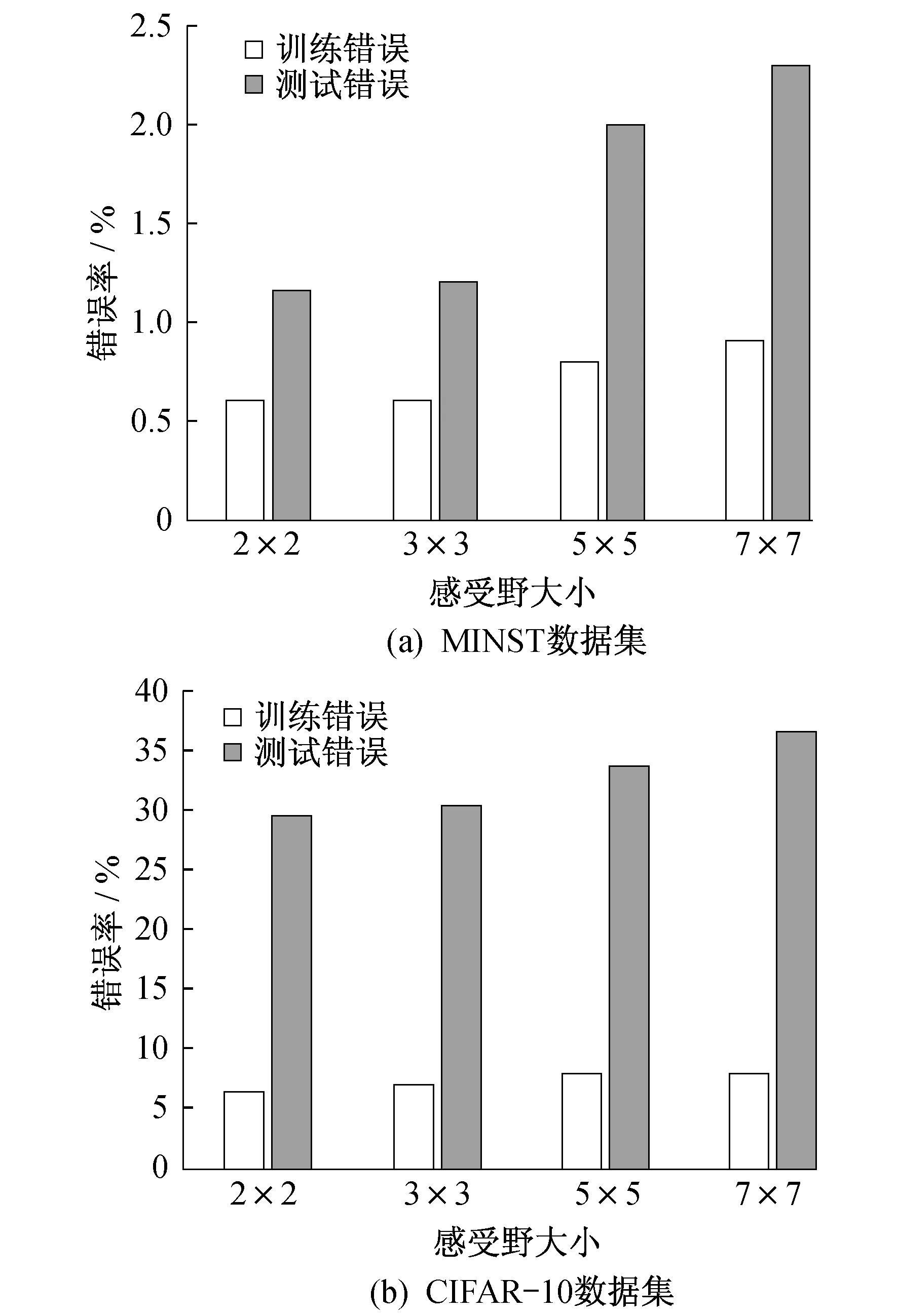
图5 MINST和CIFAR10数据集中不同感受野的结果
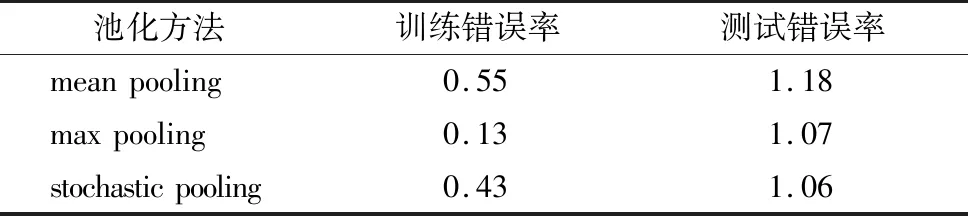
表1 MINST数据集中不同池化方法的实验结果 单位:%

表2 CIFAR10数据集中不同池化方法的实验结果 单位:%
由表1和表2可知,整体来看,3种池化方法中mean pooling的错误率较高,分类性能较差;max pooling的错误率较低,分类性能较理想。比较两种数据集中3种池化方法的实验结果,差异较大。这是由于CIFAR-10数据集中的数据为色彩丰富的图像,而MINST数据集中的数据为比较简单的数字,所以表2中错误率远高于表1。
二是池化大小的影响。为了研究池化大小对于分类的影响,接下来选择2×2,3×3,4×4,5×5这4种不同的池化尺寸来进行比较。实验结果分别如图6所示。

图6 MINST和CIFAR10数据集中不同池化大小的分类结果
由图6的实验结果可得,对于max pooling和mean pooling,池化的大小越小,错误率越小,分类效果越好;而对于stochastic pooling,存在一个适当的池化尺寸,最理想的池化大小为3×3,因为池化尺寸太小的话,会引起过拟合,而池化尺寸太大的话,会因为噪声过多而增大误差。
3 结 语
本文提出了通过ReLU函数对MAXOUT卷积神经网络引入稀疏性的方法,并在MINST数据集和CIFAR-10数据集上进行性能测试实验,主要从感受野和池化层两方面进行讨论分析。实验结果表明,感受野越小,分类特性越好;而池化层的影响需要根据池化方法和池化尺寸的具体情况来具体分析。但是对于如何减少过拟合问题,仍需要进一步的研究。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
