
基于机器听觉的鸟声识别的中文研究综述
2020-06-29 01:06:10赵子平
复旦学报(自然科学版) 2020年3期
乔 玉,钱 昆,赵子平
(1. 天津师范大学 计算机与信息工程学院,天津 300387; 2. 东京大学 身体教育学实验室,日本 东京 113-0033)
鸟鸣声包含丰富的生态学信息,其相关的研究成果可应用于动物行为分析与监护、自然保护区信息采集、生态环境状态恢复监控等领域.鸟声识别在现实中的应用十分广泛,例如,在一些面积比较大的湿地、森林和沼泽地中,由生态保护工作者长期蹲点来观察鸟类的活动规律,这将会耗费大量的时间和成本,而基于鸟声识别技术的智能声测传感网覆盖范围广,持续时间长,即使在环境非常恶劣的野外,它也能够在无人值守的情况下进行监测,极大地节约了人力成本[1];同时,收集到的鸟声数据可供我们进行生态监测,了解鸟类的分布状态,维护生态系统的平衡.在日常生活中,我们能够通过肉眼观察鸟喙或者鸟的羽毛等形态特征来判断鸟的类别;同样地,与这些形态特征相似,鸟鸣声所蕴含的生物学信息特征也有很大的差异,这种差异可以帮助区分不同物种的鸟.因此,我们可以通过提取和分析鸟鸣声所蕴含的信息特征来鉴别鸟的物种,统计生态区的鸟类分布特点,从而帮助了解生物多样性,进而监控生态系统的平衡;与此同时,对鸟鸣声的监测有利于把握鸟类的活动范围和规律,合理地安排飞机飞行的航线和时间,防止鸟类与飞行器发生碰撞,造成不可挽回的损失[2].与国内的研究相比,加拿大、德国、英国关于鸟声识别的研究比较多.通过调研国内的鸟声识别文献,我们可以了解目前国内在鸟声识别领域的研究水平,并对未来需要努力的方向进行展望.
1 相关工作
目前,国内大多数语音识别技术都是针对音乐和语音的,对于鸟声识别这一方面的研究还是比较少的,在识别技术上一般是通过提取鸟声各方面的特征,然后使用传统机器学习的算法,构建单一的分类器来进行识别.通过对国内鸟声识别相关领域的文献进行调研和研究分析,我们发现,相对来说,国内学者做的比较多的研究还是在提取特征方面: 通过改进特征提取算法,尝试各种语音信号处理方法,或者是分析鸟鸣声的各种特征,找出对分类效果最好的特征.2013年陈莎莎[3]使用改进的基于噪声功率谱动态估计的短时谱音频增强算法来抑制背景噪音,尽可能地提取出了纯粹的有效信号,从而增加了分类的正确性;随后,陈莎莎等[4]在使用改进后的声音增强算法的基础上,进一步提取出鸟声的时频纹理特征并利用随机森林(Random Forest, RF)分类器对鸟声进行识别,不仅能达到良好的识别效果,还具有良好的抗噪性能,这种方法在一定程度上降低了背景噪音对鸟声识别结果的影响,使得在对20种鸟的识别中平均识别率能够达到95.35%.陈莎莎等的研究是在20种鸟鸣声的基础上进行训练的,但在实际生活中所采集的鸟鸣声往往包含多种鸟类的叫声,仅仅依赖于单种鸟声进行训练具有一定的局限性.2015年,魏静明等[5]在提取纹理特征的算法上进行改进,增加了和差统计法,得到的特征是抗噪性的纹理特征,之后在随机森林分类器上进行鸟鸣声识别,验证了改进纹理特征提取方法后对鸟鸣声识别的有效性.2016年,刘昊天等[6]将多标记的迁移学习算法应用于鸟声识别上,同时在局部标记关系上提出了1种新的多标记迁移算法,相对于全局标记关系来说,这种算法提高了分类的精确度.随后,刘昊天等[7]提出了基于特征迁移的多物种鸟声识别方法(Recognition of Multiple Bird Species in audio recordings based on Feature Transfer, FT-RMBS),首先训练单物种鸟声识别模型,然后再将其应用到多物种鸟声的识别中,这种方法将识别率提高了20%,这在一定程度上降低了多物种鸟声样本不足对模型训练的影响,同时有利于在鸟类分布比较多的野生湿地、沼泽地或者森林等地区进行鸟声识别.同年,程龙等[8]将提取梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients, MFCC)的算法进行改进,在进行快速傅里叶变换(Fast Fourier Transformation, FFT)之前为其增加经验模态分解(Empirical Mode Decomposition, EMD)来改进MFCC算法,改进后的算法对7种鸟声的识别率达到了70.09%,与未改进的算法相比识别率提高了3.42%.与陈莎莎的研究不同,刘钊等[9]从不同的角度对鸟声识别进行研究,他们不是去抑制背景噪声,而是将高斯白噪声和真实环境背景噪声人工加入到鸟鸣声音频中,专门对加入这两种噪声的鸟鸣声进行研究,提出了1种噪声环境下的鸟声识别的仿真方法,在人工加入高斯白噪声和真实环境背景噪声下,采用这种方法的鲁棒性比较好,对于这两种背景下的鸟声识别效果也比较好.但是,他们的研究成果也仅仅局限于这两种噪声背景下的鸟鸣声识别,而在实际生活中有各种各样的背景噪音,所以这种方法是有局限性的.以上几位学者的研究均是基于单一分类器进行的,到2018年,徐淑正等[10]提出了1种与以上几位学者均不相同的方法,他们综合鸟声的多种特征,提出了1种多分类器集成技术的方法来识别鸟声,不再是使用单一的分类器进行鸟声识别,最终对11类的鸟鸣声样本识别能实现92%的准确率.
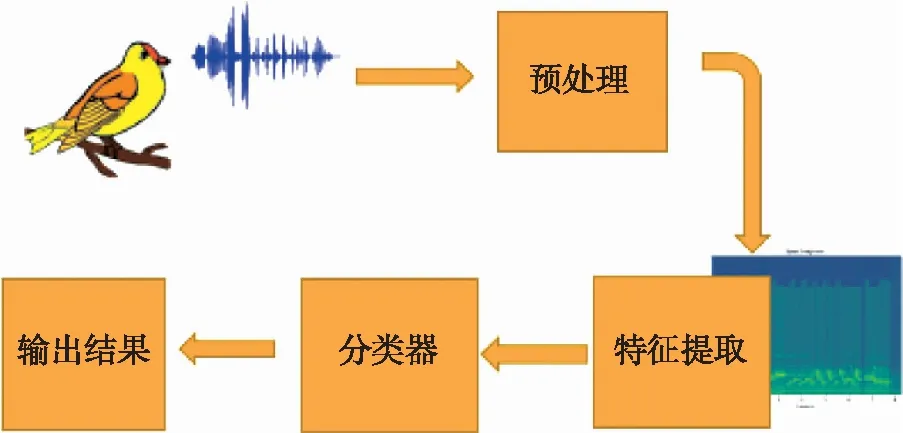
图1 鸟声识别的框图Fig.1 The diagram of bird sound recognition
综上所述,通过对国内学者在鸟声识别领域的研究成果的分析,我们可以发现他们在特征提取方面做出了尝试: 通过对某些特征提取的算法的改进,以得到较好的特征来进行鸟鸣声识别;尝试提取多种鸟鸣声特征,找出对分类效果贡献度最好的特征,并由此作为分类的有效特征放入分类器进行分类;通过改进算法来抑制背景噪音的影响,以期获得比较纯净的鸟鸣声的音频数据,提高在后期分类的准确性.同时,在分类器方面也做出了努力,提出了1种将标签进行融合的集成分类方法来进行分类,取得了比单一分类器分类效果更好的结果.目前,在鸟声识别方面,国内学者的研究方法多是基于传统的机器学习的算法来进行的,所使用的鸟鸣声特征也多是一些手工特征.在分类器算法上使用比较多的是支持向量机和随机森林算法,说明这两种算法对于鸟声识别是有一定帮助的.通过对国内鸟声识别领域相关文献的检索和研究发现,鸟声识别的一般过程如图1所示.
2 鸟声识别分类的方法
通过调查发现,目前在鸟声识别上所使用的分类方法大致都是从3个方面出发的.
第一,基于模板匹配的分类方法,比较常见的是动态时间规划(Dynamic Time Wrapping, DTW)模板算法[11],徐淑正等[10]就将此方法应用到了自己的研究当中,最终对11类的鸟声分类实现了92%的准确率.陈海兰等[12]提出的多维特征联合的鸟类分类方法中也使用到了模板匹配.但是这种方法的运算量相对来说是比较大的,所以在一定程度上会影响运算的效率.孙斌等[13]利用自适应最优核时频分布(Adaptive Optimal Kernel, AOK)方法将经过预处理的鸟鸣声音频信号转变成时频谱图,通过分析时频谱图上的能量分布,将其转化为灰度图像,利用灰度共生矩阵来提取特征,之后利用模板匹配来将待识别的鸟类模板与训练生成的训练模板进行匹配,通过对匹配值的比较来对鸟的物种进行识别.
第二,根据特征的特点来建立分类模型,所使用的分类特征多是手工提取的特征,常用的分类模型多是随机森林[9]、支持向量机(Support Vector Machine, SVM)[14]、隐马尔科夫模型(Hidden Markov Model, HMM)[15]和高斯混合模型(Gaussian Mixture Model, GMM)[16]等,通过调查国内在这方面的研究,发现目前较多使用的分类器算法是随机森林和支持向量机.
第三,利用深度学习的方法进行分类,这是目前比较热门的方法,但是通过调查发现,国内很少将深度学习的方法应用到鸟声识别领域.2018年,谢将剑等[17]利用线性调频小波变换(Linear Chirplet Transform, LCT)、短时傅里叶变换(Short-Time Fourier Transform, STFT)、梅尔频率倒谱变换(Mel Frequency Cepstrum Transform, MFCT)获得3种语谱图样本,并将这些语谱图样本输入至深度卷积神经网络(Deep Convolution Neural Network, DCNN)VGG16模型中,最后以平均识别准确率(Mean Average Precision, MAP)作为评判模型性能的标准,最终以在北京市松山国家自然保护区实地采集的18种鸟作为实验对象,使用Chirplet语图所训练出的神经网络模型的性能最好,测试集的MAP值能够达到98.71%,而且所需要的迭代次数也是最小的.

表1 用于鸟声识别研究的数据库(集)Tab.1 Databases(datasets) for bird sound recognition research
注: 数据均来自各文献.
3 鸟声识别数据库(集)
通过检索目前国内鸟声识别领域的文献,各研究使用的数据库(集)所涉及的鸟鸣声种类和样本的数量如表1所示.
4 鸟声识别算法
陈莎莎等[4]使用RF和SVM分类器,结合时频纹理特征对鸟鸣声进行分类,最终对通过实地采集和Freesound音频网站上搜集的20种鸟类的识别达到了极好的效果,其中采用RF分类器的准确度比采用SVM分类器的高出了4%;魏静明等[5]利用RF分类器算法证明通过提取抗噪纹理特征能够有效地提高分类的准确性;刘昊天等[7]在进行鸟声识别时构造了1种GMM结合Rank SVM模型,这种模型结合了从鸟鸣声中提取出来的MFCC特征来实现对多物种鸟声的识别;刘钊等[9]采用RF分类器对大规模声学特征进行分类;徐淑正等[10]提取了4种不同的声学特征,对这些特征使用SVM和RF分类器进行分类,然后做了1个标签的融合,整合各个分类器的分类结果,使得最终预测的可靠性更高.通过对目前国内鸟声识别领域的文献研究发现,在鸟声识别上多用的是RF和SVM分类器.结合对目前国内鸟声识别领域的相关文献的研究,本节将从以下几个部分对鸟声识别算法进行讨论.
4.1 音频增强算法
从自然界中收集的鸟叫声音频难免会包含环境噪音,而在进行鸟声识别时所要用到的分类特征应当是从比较纯净的鸟鸣声信号中进行提取,所以这种包含噪声的音频信号会对后期分类器的准确度造成极大的影响.为了防止这种背景噪音对鸟声识别结果的影响,在进行鸟叫声特征提取之前需要利用音频增强算法对鸟叫声音频进行前端处理.
所谓前端处理[4]就是对含有噪声的信号进行信号增强处理,从而降低背景噪声在分类时的影响.陈莎莎等[3-4]就提出了1种改进的声音增强算法,这种算法能够有效抑制背景噪音对分类结果的影响,提高分类识别的准确度.为了获得更加纯净的音频信号,一些学者也尝试通过改进算法来提高音频增强算法的效果,从而获得相对来说比较纯粹的鸟鸣声信号.
4.2 特征提取算法
要对鸟类进行分类首先需要的就是了解不同鸟类的鸟叫声特点,这就要我们恰当地采集鸟鸣声,并使用良好的语音信号处理方法对采集到的鸟鸣声信号进行处理和分析,提取最优的音频特征,根据不同物种的鸟叫声的特征来进行分类.通过研究国内一些学者的文献可以发现,主要有以下几种特征提取的方法.
4.2.1 音节长度
音节长度指音节持续的时间长度,描述了鸟鸣声的长短.音节长度的计算是在音节萃取之后进行的.一般的音节萃取方法是先计算每帧的短时能量,然后设定1个阈值从而判断有声段和无声段,得到结果后再进行中值滤波,最后将密集的有声段连接在一起,形成音节.不同的音节长度在后期进行鸟声识别分类时的准确性是不一样的.
4.2.2 梅尔频率倒谱系数
不同种类的鸟在频谱上表现出来的特征是不一样的,可以通过将同一种鸟的特征帧拼合在一起,进而利用拼合在一起的帧特征来识别不同种类的鸟.这里,梅尔频率倒谱系数(MFCC)是语音识别中使用得最好的1类特征参数.对输入的每帧语音先进行快速傅里叶变换,从频谱求得幅度谱,然后通过梅尔滤波器组平滑频谱,消除谐波的作用后,再做对数运算,经过行离散余弦变换(Discrete Cosine Transform, DCT),最后得到我们所需要的MFCC.
在分析国内这方面研究的文章的时候发现,对不平稳的音频信号可以采用经验模态分解法来对信号进行处理,而鸟鸣声正好就是这样1种非常不平稳的信号,所以在进行FFT之前添加经验模态分解法,经过这样的改进之后,鸟鸣声的识别准确率有了明显的提高.
4.3 分类器算法
在调研过程中发现大部分学者在鸟声识别的分类器部分使用的都是RF和SVM,相对来说使用RF的还是比较多的.
4.3.1 随机森林(RF)
随机森林算法是1种有监督的学习算法,所谓森林就是决策树的组合.它有利于防止过拟合,训练速度比较快,能够处理大样本的数据,优点是训练的参数比较少,具有较强的抗噪能力.“森林”的构建采用的是“bagging(bootstrap aggregating)”方法训练的,也就是在选择训练样本的时候进行随机有放回的方法,然后再构造分类器,最后通过组合所有的分类器使得整合后的分类效果更好.
随机森林的具体实现过程如下:
1) 随机有放回地从训练集中抽取训练样本作为某棵树的训练集,同样地,在为其他树抽取训练样本时也抽取相同数量的样本作为训练集,以此类推,最后每棵树都拥有相同数量但是样本种类不同的训练集,然而树与树之间却有重叠的样本部分.通过这种抽取方法抽取出样本后进行训练,最终训练完成的树会有不同的分类结果,因为训练中的样本有重复的部分,那么训练后的树之间是有相关性的,这种相关性使得最终依靠这些树进行投票表决时的分类结果更加准确.
2) 如果K为每个样本的特征维度,k≪K,那么在抽取特征的时候随机从K个特征中抽取k个特征,然后找出最优的特征进行树的分裂.
3) 每棵树都尽最大程度的生长,并且没有剪枝过程.在过程1)中的随机抽取训练样本和过程2)中的随机选取子集是影响随机森林的分类性能的两个关键因素.随机森林算法能够防止过拟合并具有很好的抗噪能力都是由于随机抽取样本和随机选取子集的引入,而随机森林的最终分类效果与特征个数k的取值有密切的关系,所以在使用随机森林分类器时选择k的1个最优值是非常关键的因素.
对待测鸟叫声样本进行预处理之后,提取特征,然后将样本放入训练好的分类器进行分类预测.用所提取的特征向量遍历森林中的树,然后将所有树的结论进行多数投票决定待测鸟声的种类.生成树的过程中是随机生成特征进行分支的,能够最小化树之间的相关性,在一定程度上增加了识别率.
4.3.2 支持向量机(SVM)算法
支持向量机算法是从样本中找出1个最好的分割超平面,将不同类别的数据完全分割开,然后最大化距离该平面两侧最近的样本,使其能够较好地泛化,从而对分类问题产生良好的泛化能力.
具体实现步骤如下: 首先,如果样本不是线性可分的,就需要用核函数来解决这个问题,使样本空间能够转换到线性可分的空间.这是因为平常我们在解决问题的时候,都是在2维或者低维来考虑问题,但是样本不是线性可分的话就会产生线性不可分的问题,此时,使用核函数就能够解决这个问题.其次,在高维的样本空间中找到超平面来分割样本,直接映射到高维的空间容易造成计算的复杂化,而这种映射方法并不是直接扩展到高维的空间,这样就降低了计算的复杂化.然后,在分割的时候用最大间隔化来获取最大间隔线,进而得出支持向量,也就是距离分类决策面最近的样本点,这些点一般是比较难进行分类的.最大间隔线可以使得不同的样本之间的距离最大,这样,在判断新的样本是属于哪一类的时候就可以直接根据它位于分割线的哪一侧来进行判断.最后,在前两步中得到最大间隔线和支持向量后就可以直接利用这两个量来预测新的样本.
5 深度学习在鸟声识别上的应用
深度学习是通过建立深层神经网络,经过连续的层的学习优化,来找到最合适地表征数据的方法,这种方法能够模拟人脑来对数据进行分析、解释.深度学习方法能够很好地对数据进行分类,因为它能够自动地获取并组合表征输入的特征信息,因此,对输入模型的特征分析选取也是非常重要的.
调查发现国内学者将深度学习的方法应用到鸟声识别领域还是极少的,谢将剑等[17]利用经典的VGG16模型,通过Chirplet变换将鸟鸣声信号转变为语谱图的形式,从而将音频的分类转变为对图像的分类问题,将VGG16模型的softmax层的神经元个数改为18,最终实现了对北京松山国家级自然保护区18种鸟类的识别,使得识别的平均准确率达到了98.71%.相对来说,国外学者在这方面的研究就比较多了,Koops等[18]通过提取鸟鸣声信号的梅尔频率倒谱系数(MFCC)及其均值和方差的组合,将其作为输入到神经网络中的特征,通过对神经网络的训练,最终使得该模型对于鸟类物种识别的平均准确率达到了73%.Tóth等[19]将鸟叫声信号转变为语谱图,利用经典的AlexNet神经网络模型对其进行改进,从而实现对鸟类物种的识别.虽然国内学者极少利用深度学习的方法来进行鸟声的分类,但是国内学者在提取鸟声特征方面却也取得了一些成果.例如陈海兰等[12]提出多维特征联合的鸟类鸣声识别的方法,这种方法将不同音节长度特征与多段式平均频谱法相结合,利用鸟声音频文件建立标准样本数据库,并利用模板匹配的方法,将要分辨的鸟声音节与标准模板音节进行匹配,最终在湿地常见的17种鸟类的识别中实现了极高的准确率.
6 结论与展望
通过检索文献,调查国内学者在鸟声识别领域的研究成果,我们发现目前国内鸟声识别技术主要集中在传统机器学习算法的分类技术,多是提取鸟叫声的一些音频特征,然后利用随机森林或者支持向量机分类器进行分类,而国外Koops等在2014年就已经开始使用神经网络进行鸟声分类,Tóth等使用经典的AlexNet模型来实现对鸟声物种的分类,同时国内目前也没有比较成型的数据库,所使用的鸟鸣声样本种类也比较少.在未来的研究工作中,期望能够采集更多种类的鸟鸣声样本进行训练,进而增加鸟声识别的多样性;随着深度学习算法的迅速发展,未来也可以利用深度神经网络来提取一些鸟鸣声的更高级特征,使用一些深度学习的技术来对鸟鸣声进行识别,或许会有更好的分类效果.
猜你喜欢
草堂(2023年1期)2023-09-25 08:44:48
学与玩(2022年9期)2022-10-31 02:54:08
文苑(2020年12期)2020-04-13 00:54:14
江南诗(2020年1期)2020-02-25 14:12:56
小太阳画报(2019年1期)2019-06-11 10:29:48
电子测试(2018年1期)2018-04-18 11:52:35
诗潮(2017年12期)2018-01-08 07:25:20
小学生必读(低年级版)(2017年5期)2017-08-12 03:47:07
文苑(2016年14期)2016-11-26 23:04:39
光学精密工程(2016年4期)2016-11-07 09:05:00
