
基于改进粒子群算法的RBF神经网络磨机负荷预测研究
2020-06-29 12:47
计算机测量与控制 2020年6期
(西安建筑科技大学 信息与控制工程学院,西安 710055)
0 引言
磨矿是选矿生产流程中十分重要的环节,它是将矿石碎磨至使有用矿物满足产品合格的细度,再经过分级过程后供浮选,磨矿工序产品质量的好坏直接关系着整个选矿厂的经济和技术指标。磨矿过程是选矿生产中的耗能大户,通常该工序成本占总生产费用的 40%~60%[1]。在当前大力倡导节能减排的大背景下,最大限度地降低电耗、降低生产成本,已是势在必行[2]。因此,科学、准确地预测磨机内部运行状态是选矿行业实现节能降耗、提质提量的根本任务之一[3]。
国内外学者对磨机负荷进行大量研究时,提出了许多关于磨机负荷的预测模型,J.Tang等[4]应用主成分分析和支持向量机(support vector machine,SVM)建立球磨机负荷的软测量模型。罗小燕等[5]采用网格搜索与交叉验证相结合的方法对 SVM 参数进行优化,建立基于SVM的磨机负荷预测模型。冯雪等[6]采用核主元分析的方法根据球磨机振动频谱建立磨机负荷参数的极限学习机(extreme learning machine,ELM)预测模型。汤健等[7]采用递归核主元分析建立基于最小二乘支持向量机的磨机负荷软测量模型。虽然这些模型对磨机负荷预测具有一定的作用,但由于影响磨机负荷的因素众多且复杂,各影响因素之间相互耦合,导致预测的结果不够准确,不能够反映实际中磨机负荷的变化情况。
本文采用IPSO-RBF神经网络模型对磨机负荷进行预测,通过改进后的PSO算法优化RBF的中心向量、宽度向量和连接权值,再利用经过样本训练后的RBF神经网络对数据进行预测,为验证IPSO-RBF预测模型的可行性,采用水泥厂信息监控系统中的实时运行数据进行实验,并与其他预测模型进行对比,证实提出的 IPSO-RBF 模型具有较好的拟合性和准确性。
1 RBF神经网络
RBF神经网络是一种性能良好的三层前馈型神经网络,除输入输出层外仅有一层隐含层,通常隐层的神经元越多,预测的精度越高,利用在多维空间中进行插值的传统技术,可对几乎所有的系统进行辨识建模,不仅在理论上拥有最佳逼近的特性,在应用上还具有收敛速度快、抗噪与修复能力强等优势,其结构如图1所示,输入层起到传输信号的作用,由信号源节点组成,隐含层采用非线性的优化策略,其单元数根据应用的具体情况而定,输出层采用的是线性输出,对输入模式做出响应。如图RBF有n个输入,m个隐层节点,p个输出节点,隐层节点基函数由高斯函数h(j)的辐射状作用函数构成,每个隐含层节点包含一个中心向量C。Cj为隐含层中第j个节点的中心向量,Cj=[cj1,cj2,…,cji,…,cjn]T,i=1,2,…,n。隐含层作用函数h(j)表示如下:
(1)
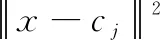
RBF网络隐含层到输出层的线性映射表示为:
(2)
式中,yk为输出层第k个节点的输出;wkj为隐含层到输出层的加权系数;p为输出层节点数。
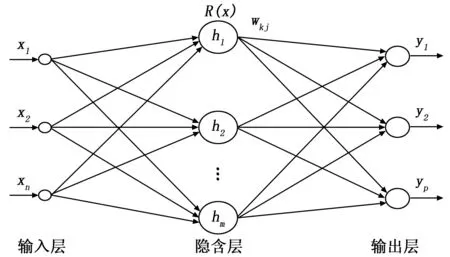
图1 RBF网络结构图
2 粒子群优化算法及改进
粒子群优化算法的每个粒子为解空间的一个解,所有粒子构成群体并随机分布在一个维度为D∈Rd的空间中[8]。群体X由N个粒子构成,即为X=(X1,X2,…,XN)。在搜索过程中,第i个粒子表示的D维向量Xi=[xi1,xi2,…,xiD],第i个粒子的速度为Vi=[vi1,vi2,…,viD],第i个粒子迄今位置搜索到的最优位置称为个体极值,记为Pbest=(pi1,pi2,…,piD),整个粒子群迄今为止搜索到的最优位置为全局极值,记为[9]gbest=(g1,g2,…,gD)。在每一次的迭代过程中,粒子通过个体极值和全局极值更新自身的速度和位置,更新公式如下:
vij(t+1)=wvij(t)+c1r1(t)
[pij(t)-xij(t)]+c2r2(t)[pgj(t)-xij(t)]
(3)
xij(t+1)=xij(t)+vij(t+1)
(4)
其中:i=1,2,…,N,w表示惯性权重,决定着算法的开发和探索能力,N为粒子总数,d为优化的目标变量数,r1和r2均为[0,1]区间的随机数,c1和c2为学习因子,它们分别决定着粒子的个体经验和群体经验对粒子运行轨迹的影响,反映粒子群之间的信息交流,因此一般把c1、c2设置为相同的数值。vij为粒子的速度,xij为粒子的位置,t为当前迭代次数,为了避免粒子的盲目搜索,一般将其位置和速度限制在一定区间[-Xmax,Xmax]、[-Vmax,Vmax]。
惯性权重w的大小体现了对粒子先前速度的继承能力,Y.Shi提出了线性递减惯性权重,如公式(5),较大的惯性权重有利于全局搜索,不利于局部的精确搜索,而较小的惯性权重则与之相反[10]。
(5)
式中,Wmax和Wmin分别为惯性权重w的最大值和最小值;t为当前迭代次数;tmax为最大迭代次数。
针对传统PSO算法容易陷入局部最优、收敛精度低且不能满足实际搜索过程中复杂非线性情况等缺点,本文提出了一种非线性变化的惯性权重递减策略,用来增强算法的局部和全局搜索能力,可表示为:
(6)
式中,Wmax、Wmin、t、tmax含义同式(5),在搜索前期迭代次数t较小时,惯性权重w接近Wmax,w的递减速率较慢,粒子以较大的飞行速度遍布整个搜索空间从而确定全局最优解的大致范围,此时PSO算法的全局搜索能力较强;而在搜索后期随着迭代次数t的增大,惯性权重w非线性递减且递减速率逐渐增加,粒子获得的飞行速度较小,粒子的搜索空间逐渐减小,集中在最优解的邻域范围内,可以更加精确地搜索最优解,此时PSO算法的局部搜索能力较强,该方法可以平衡局部搜索能力与全局搜索能力之间的矛盾,使得算法能快速准确地找到最优解。
3 IPSO-RBF模型的建立
由于粉磨机的磨机负荷易受到给料量、磨主机电流、磨机进口与出口的压力差等众多因素的影响,粉磨机会出现负荷不稳定的情况,对于此类不规则数据通过传统模型实现高精度的预测是非常困难的。RBF神经网络具有以下优点:非线性拟合(逼进任意非线性函数得到相应拟合结果)和良好的自主学习能力,RBF通过以上两种特性实现预测磨机负荷中非线性数据的目标。融合粒子群算法与RBF神经网络,利用 PSO 算法优化RBF神经网络的中心向量、宽度向量和权值,通过输入样本完成对RBF的训练,这样,融合了PSO与RBF的预测算法既拥有粒子群全局搜索能力强的优点,又不失RBF高效的收敛速度,避免在磨机负荷预测过程中,算法易陷入局部最优的情况。优化RBF具体步骤如下:
Step1:采集影响粉磨机磨机负荷的相关样本数据,将实验数据分为两部分,一部分为训练数据,另一部分为测试数据,并对数据进行归一化处理,处理后作为RBF神经网络的输入样本。
Step2:初始化粒子群的种群规模N,最大迭代次数tmax,速度区间[-Vmax,Vmax],位置区间[-Xmax,Xmax],学习因子c1和c2,随机初始化粒子的速度v和位置x,并根据PSO算法优化的RBF神经网络的参数个数确定粒子群的维数D。
Step3:确定粒子的适应度函数,通过计算输入样本在该神经网络下的输出,求出与目标输出的均方误差,将其值作为粒子群的适应度函数。适应度值越小表示PSO算法的优化效果越好,同时确定初始种群的个体极值Pbest和全局极值gbest,将每个粒子经迭代后的最好位置记录下来作为其历史最佳位置。
Step4:重新计算粒子种群每个粒子的适应度值,将当前粒子的适应度值(Ppresent)与当前粒子位置的历史最佳适应度值(Pbest)进行比较,如果当前粒子适应度值(Ppresent)更小,则用当前粒子进行替代,反之则保持历史最佳适应度值(Pbest)不变。然后将当前粒子的适应度值(Ppresent)与全局最佳粒子(gbest)的适应度值进行比较,如果当前适应度值(Ppresent)更小,则用其粒子位置进行替代,反之则保持全局最佳粒子(gbest)不变;
Step5:按照式(3)和式(4)对种群粒子的速度和位置进行更新。
Step6:验证是否达到最大迭代次数。如果是,则执行下一步,否则返回步骤4,重新更新粒子群体的个体极值Pbest与全局极值gbest。
Step7:经过PSO算法的优化,输出种群粒子的全局最优位置,赋予RBF神经网络中心向量、宽度向量和连接权值,得到最佳的磨机负荷预测值。其流程如图2所示。
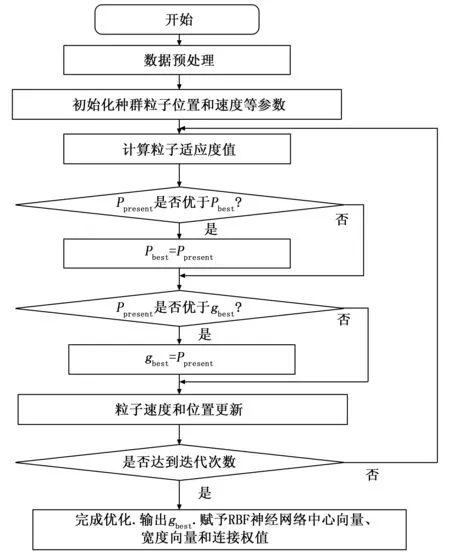
图2 IPSO-RBF神经网络模型的流程图
PSO算法中的详细参数设置如下:种群规模N=100;最大迭代代数tmax=1 000;学习因子c1=c2=1.494 45;最大惯性权重Wmax=0.93;最小惯性权重Wmin=0.4;粒子速度的取值上限Vmax=3.5;粒子位置的取值上限Xmax=5;
根据隐节点经验公式划分出节点数范围,再选取不同的样本节点数输入到预测模型中,比较不同样本预测结果,采用拟合效果最好的样本作为模型最佳节点数,经验公式见式(7)。RBF神经网络的各层节点数设置:输入层节点数为4,输出层节点数为1,当隐节点数为12时效果最佳。
(7)
其中:h为隐含层节点数目,m为输入层节点数目,l为输出层节点数目,α为1~10之间的调节常数。
4 实验结果与分析
4.1 评价性能指标
模型的性能评价准则是预测模型不可或缺的部分,对不同预测模型误差的适当估计并相互比较能评价不同模型的准确性[11]。本文选取均方根误差(RMSE),均方误差(MSE),平均绝对误差(MAE),平均绝对百分比误差(MAPE),以及决定系数(R2)作为评价指标对不同模型的预测效果进行评价。其中RMSE,MSE,MAE,MAPE的数值越小,表示模型的预测值与实际值偏差越小,结果越准确;决定系数(R2)能够反映模型的拟合优度,其值越接近1,表示拟合优度越大,模型的预测效果越好。具体公式定义如下:
(8)
(9)
(10)
(11)
(12)
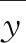
4.2 实验数据的选取
以下结合实际数据讨论在上述方法下建立的IPSO-RBF模型的预测效果,本文选取陕西省安康市某水泥厂的磨机负荷运行数据,通过对磨矿过程磨机运行状态的分析研究,对磨机负荷的主要影响因素和磨机负荷数据进行预处理,其中主要影响因素包括给料量、磨音信号、磨主机电流和出磨提升机电流。为了能够取得较好的预测效果,较真实地反映实际粉磨机的运行状态,需要对大量的输入、输出样本进行训练,本次实验共选取180组实验数据,其中140组作为训练样本,另外40组作为测试样本,用来检测磨机负荷的预测精度,实验样本数据如表1所示。

表1 磨机运行状态的部分实验数据
4.3 预测结果及分析
为了验证文中提出的IPSO-RBF预测模型的有效性,利用不同模型对40组测试样本进行预测效果对比,结果如图3所示。
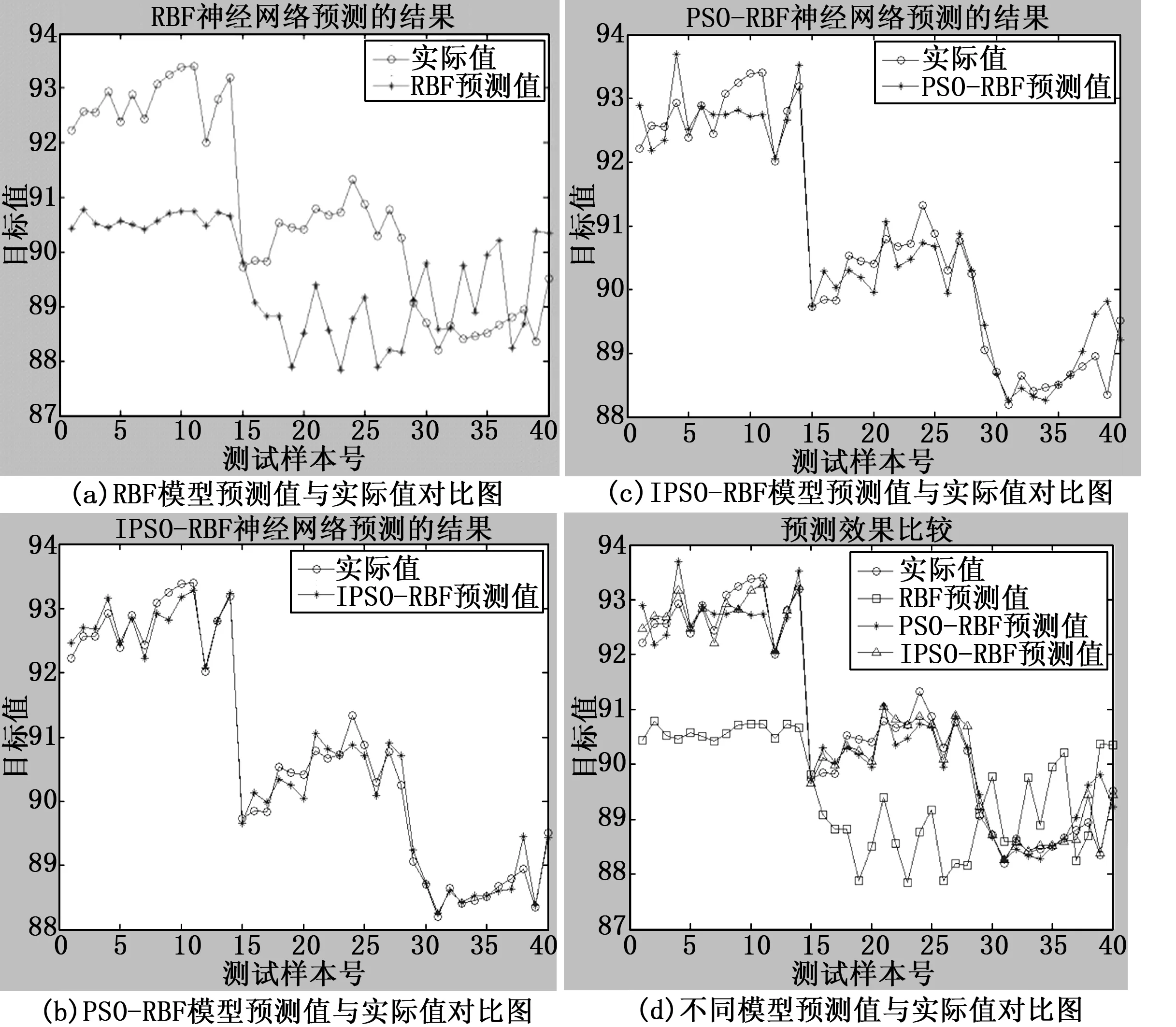
图3 预测效果对比图
由图3可知,RBF模型预测值偏离实际值较大,PSO-RBF以及IPSO-RBF模型的预测准确度均远远超过RBF。PSO-RBF模型预测值比较接近于实际值,而IPSO-RBF模型的预测值与实际值几乎保持一致,误差较小。3种模型的测试样本相对误差曲线如图4所示,从图中能够看出,IPSO-RBF模型的相对误差率比其它两种模型都低,且曲线的幅度变化不大,说明IPSO-RBF模型的预测情况比单一的RBF预测模型或PSO-RBF预测模型好,能够准确地判断磨机负荷量的变化。
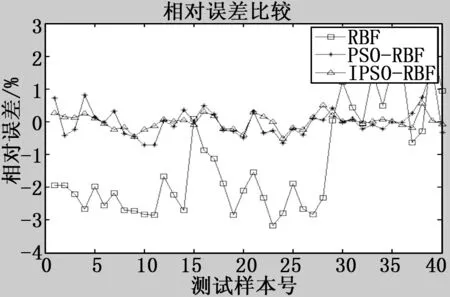
图4 不同模型相对误差对比图

表2 各模型评价指标对比
由表2可知,IPSO-RBF模型的预测精度最高,RMSE、MSE、MAE、MAPE和R2分别为0.210 2、0.044 2、0.161 7、1.778%和0.978 2,与PSO-RBF模型相比,R2提高了0.079 5,RMSE、MSE、MAE和MAPE分别降低了50.1%、75.1%、48.1%和48.1%;相对于RBF模型,利用PSO优化RBF可以得到更小的预测误差,说明 PSO 可以提升 RBF的预测效果。综上所述,利用本文提出的IPSO优化RBF可以进一步提高磨机负荷的预测精度,充分证实了算法的有效性。
5 结束语
本文针对磨机负荷的预测精度问题,综合考虑磨机负荷的影响因素,在PSO算法与RBF神经网络预测模型相结合的基础上,提出了一种非线性变化的惯性权重递减策略,实现了对PSO算法的改进。通过Matlab软件对RBF预测模型、PSO-RBF预测模型和IPSO-RBF预测模型的仿真对比分析,发现IPSO-RBF预测模型不仅避免了RBF模型带来的理论误差,而且通过改进避免了传统PSO算法容易陷入局部最优且无法平衡粒子在局部和全局空间搜索能力的缺点,减少了因为训练样本的随机性对建模精度的干扰。此外,由于该模型具有自适应、自
组织、预测精度高的特性,能够精确预测粉磨机的磨机负荷情况。实验结果表明,该模型的预测结果优于单个RBF或PSO-RBF神经网络模型,同时该模型的预测方法具有较好的拟合性,适用于对粉磨机磨机负荷的预测,可以为后续粉磨机磨机负荷的理论研究和工程实践提供参考与指导。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
昆明医科大学学报(2022年1期)2022-02-28
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
金桥(2018年4期)2018-09-26
分析化学(2018年12期)2018-01-22
当代旅游(2016年10期)2017-04-17
飞碟探索(2015年8期)2015-10-15
财经理论与实践(2015年2期)2015-04-16
