
可解释时空卷积网络的微表情识别应用
2020-06-28 01:18张钥迪
辽宁大学学报(自然科学版) 2020年2期
牛 斌,张钥迪,马 利
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引言
微表情是根据人们在日常生活中情绪变化而产生的无意识的、短暂的自发式面部表情,其最大优势是无法抑制,能够显露出人类试图隐藏的真正情感,且其持续时间短,最短仅持续1/25秒.与一般的面部表情相比,微表情发生时面部肌肉变化范围小、强度低,但却能展现出人类的真实情感,因此,微表情识别在司法审讯[1]、心理咨询[2]、交流谈判[3]等领域具有极大的应用价值.
自19世纪达尔文[4]开始,人类对面部表情的研究逐渐进步.1966年,Haggard等[5]第一次提出了微表情的概念.Ekman等[6]在1969年将面部表情分成六类:快乐、悲伤、惊讶、恐惧、愤怒、厌恶,在2002 年研制出第一个微表情训练工具(Micro Expression Training Tool,METT),并进行了日本人与高加索人短暂表情识别实验(Japanese and Caucasian brief affect recognition test,JACBART).相比于国外,国内的微表情研究起步较晚.傅小兰教授带领其团队制作了CASME和CASME2数据集,为微表情识别领域的发展作出了巨大贡献.2010年,吴奇等[7]从心理学角度对微表情的研究进行了总结,并分析了微表情的应用领域.
2015年之前,微表情识别大部分还是使用手工提取特征(Handcrafted)的方式.Liu等[8]提出一种简单而有效的主方向平均光流(MDMO)特征,基于感兴趣区域标准化统计特征,考虑局部运动信息及空间位置.Lu等[9]提出一种通过将光流差分的水平和垂直分量组合而产生的基于运动边界直方图(FMBH)融合的新特征.近几年,利用深度学习技术来解决图像问题成为研究的热点,采用深度学习方法的微表情识别研究逐步开展.Wang等[10]提出一种新的注意力机制,即Micro-Attention与残差网络的结合,并且在处理小型数据集时,利用转移学习方法来缓解过拟合风险.Reddy等[11]提出了利用三维时空卷积神经网络进行微表情识别的方法(MicroExpSTCNN).Peng等[12]提出了基于顶点帧的空间信息以及其相邻帧的时间信息分别使用CNN和LSTM进行微表情识别的方法(ATNet).但是,现阶段微表情识别的研究方法中均没有强调模型的可解释.
可解释性是模型公正性的重要考察因素.人类大多数决策是基于逻辑和推理,而由机器做出决策无疑会受到质疑,甚至在很多时候,有偏差的分类模型会产生一些负面影响,如预测潜在的犯罪、信用评分等,因此对分类模型的理解和进行解释是至关重要的.现如今的科研方面正在致力于模型的可解释性,Chakraborty等[13]概述了一些对模型可解释性有用的维度,并按照这些维度对先前的工作进行分类,在此过程中,对需要采取的措施进行差距分析,以提高模型的可解释性.Zhang等[14]提出一种将传统的卷积神经网络(Convolutional Neural Networks,CNN)修改为可解释CNN的方法,以阐明CNN卷积层中的知识表示,其可解释的CNN使用与普通CNN相同的训练数据,且无需任何用于监督的对象部分或纹理的注释.可解释的深度学习模型也被用于各行各业,如医学[15,16],喷气式飞机[17],生物学[18]等.
尽管可解释的模型运用逐渐增多,但复杂模型的内部运作仍然还是黑盒子,如果没有能力来解释这样的模型,就不能完全支持模型的决策.在微表情领域,无论其准确性如何,如果不能理解模型的决策,那么将不能保证模型决策的公正性,这种缺点会妨碍模型的实际运用,如在司法审讯中,如果不能保证模型决策的公正,那么便不能保证司法的公平公正.鉴于此,本文对应用于3D人类动作识别的可解释时间卷积网络模型进行改进,提出了基于残差单元的可解释时空卷积网络模型(Residual-Spatiotemporal Convolutional Network,Res-STCN).本文方法将原本应用于骨架特征点提取的一维卷积核调整为二维,以便更好地适应微表情识别输入的视频帧序列,除此之外,对网络模型层数进行调整并修改了卷积核尺寸,使其更好地运用在微表情识别领域,并在CASME2、SAMM和SMIC数据集上进行验证,证明了在保证Res-STCN可解释性的基础上,提高了模型在微表情识别上的准确率.
1 基于残差单元的可解释时间卷积网络
可解释性是人能够充分认知、理解模型在其决策过程中如何选择决策的方法、进行决策的原因和决策的内容.而模型的可解释性和模型的性能之间往往有一个权衡,这里的性能指模型作出分类预测的准确度.例如决策树模型,虽然它的预测原理很好直观理解,但是模型性能却比较低.所以本文在保证模型性能的基础上,使模型具有可解释性.
按照可解释性方法进行的过程可以划分为三类,即在建模之前的可解释性方法、建模本身具备可解释的模型、在建模之后使用可解释性方法对模型作出解释.本文的可解释性是在建模后通过模型结果来反向理解决策的原因,并保证模型有一个较好的性能,即在微表情识别上有一个较高的准确率.
1.1 可解释时间卷积网络
时间卷积网络(Temporal Convolution Network,TCN)是由Lea等[19]提出,其提出的TCN仅使用时间卷积、Pooling和上采样,但可以有效地捕捉长时程模式(long-term temporal patterns),并且比基于LSTM的神经网络更快地训练.TCN采用编码器、解码器结构,具体结构如图1所示.编码器有L层,表示为E(l)∈RFl×Tl,其中Fl是第l层中的卷积滤波器数量,Tl是相应时间步长的数量.每个层由时间卷积,非线性激活函数和跨时间的最大池化组成.
E(l)=max_pooling(f(W*E(l-1)+b))
(1)
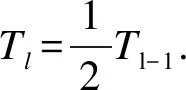
解码器类似于编码器,不同之处在于池化替换为上采样,并且操作顺序变为上采样,卷积和激活函数.
模型参数与其隐藏层之间缺乏明确的关系是当前时空模型可解释性的最大障碍,添加残差单元,通过跳跃连接与恒等映射的连接将不同层的特征进行连接,在不增加额外参数和计算复杂性的情况下,充分利用不同层的特征.通过将较深层分解为残差单元来重新设计的TCN,可以产生可解释的隐藏表示和模型参数.
1.2 基于残差单元的可解释TCN
在原始的可解释时间卷积网络中,为了提高模型的可解释性以及具有语义含义的输入,引入了跳跃连接与恒等映射的连接,即残差单元[24],并对残差单元进行了堆叠,如图2所示,其中Xl是l-1层的输出和第l层的输入,而Xl+1是第l层的输出和l+1层的输入.与传统的残差单元相比,堆叠残差单元将激活函数(BatchNorm和ReLU)放在权重层之前,这样使得训练变得更加简单,同时也提高了网络的泛化能力.
激活函数是通过在时间上卷积可学习的空间滤波器并通过ReLU单元传递输出来进行计算.在ReLU网络中,向前-向后传递的迭代之后,进行网络参数优化,这使得在下一次迭代中,卷积滤波器将获得一个正值,迫使网络学习有区别的时空特征.
2 应用于微表情识别的可解释时空卷积网络
2.1 基于Res-STCN的微表情识别过程
本文提出的Res-STCN的微表情识别方法框架如图3所示,首先采用时间插值模型(TIM)[20]将不同长度的视频帧序列调整成相同长度,然后将每张图像像素调整到相同尺寸,使每个样本的输入数据格式相同,以便更好地输入到Res-STCN网络中.接着,将调整好的微表情帧序列与相对应的微表情分类标签输入到Res-STCN网络中实现微表情分类.
2.2 改进的Res-STCN模型可解释性
对Res-STCN模型进行解释,可以在给出微表情识别结果的同时,为结果提供论据,使人们更好地接受实验结果,从而增加对模型的信任度.
为了使基于残差单元的时间卷积网络(Residual-Temporal Convolutional Network,Res-TCN)更好地运用到微表情识别领域中,将空间信息添加到Res-TCN中,提出基于残差模块的时空卷积网络(Res-STCN),同时为了使网络具有可解释性,对网络中特征的各个维度进行解释.原始的Res-TCN是在3D动作识别中,根据骨架运动过程进行识别,其输入是视频序列在时间上逐帧连接而成的骨架特征.而微表情识别是基于面部肌肉轻微变化进行识别,因此改进后的Res-STCN输入X0为经过预处理调整好的相同长度和分辨率的视频帧序列.
X1为第一层中不经过任何非线性激活函数,即仅使用滤波器进行卷积,即
X1=W1X0
(3)
X0∈P×P×T,其中P表示输入图像像素,T表示视频帧序列长度,W1为滤波器集合.
在l≥2的残差单元中,先在Xl-1上进行激活函数(BatchNorm和ReLU)操作,然后再使用Wl中的滤波器进行卷积操作.由于ReLU操作,因此梯度仅经过Xl-1的正区域,可以使网络学习有区别的时空特征.
对于第l(l≥2)层中的每个单元执行以下计算
F(Wl,Xl-1)=Wl*σ(Xl-1)
(4)
Xl=Xl-1+F(Wl,Xl-1)
(5)
其中,F表示卷积操作,Xl-1表示l层的输入,Wl为参数集合,σ表示激活函数.若σ为ReLU,则Wl*σ(Xl-1)可重写为Wl*max(0,Xl-1).在Res-STCN网络中,第一层是在经过预处理后的输入视频帧序列上运行,并将生成的映射Xl在后续层上传递.因此,在第N个残差单元上,XN可表示为
(6)
在网络的最后一个合并层之后使用全局平均运算,并增加一个Softmax层,使神经元的数量与微表情分类数相等,具体结构如图4所示.第一层通过一个8×8卷积,将输入数据X0进行卷积,结果输入到后面的残差单元中.在每层残差单元中,均使用5×5卷积,最后一层残差单元后,将合并结果通过平均池化操作后,输入到全连接层,经过Softmax函数计算,输出分类结果.
理解微表情分类预测模型背后的原因在评估模型信任度方面非常重要,如果计划将模型应用于实际的工业中,则对模型的信任是至关重要的.本文从模型的输入微表情视频帧出发,对模型的输入输出进行解释,理解模型决策原因,并对模型性能进行测试.
3 实验与结果分析
3.1 数据集
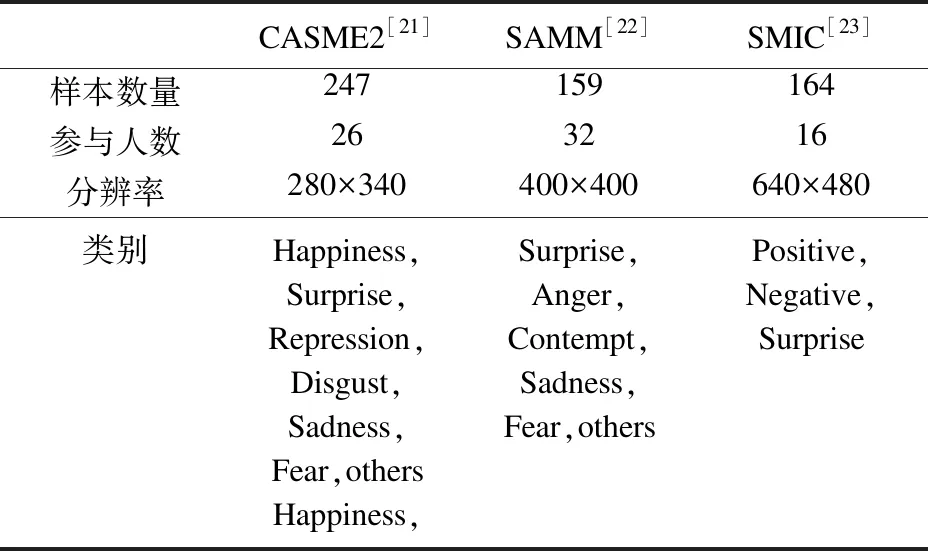
表1 微表情数据集概述
在我们的实验中使用了三个微表情数据集,分别是CASME2、SAMM和SMIC.表1总结了这三个数据集.
3.1.1 CASME2
CASME2数据集是在2014年由中国科学院心理研究所的傅小兰团队设计的,具有高时间(200 fps)和空间分辨率(面部区域约280×340像素).该数据集通过适当的实验设计和照明,在一个控制良好的实验室环境中引出参与者的面部表情.该数据集包含26个受试者(11名男性,15名女性),在近3 000个面部动作中,为数据集选择了247个微表情,是目前微表情识别最常用的数据集.
3.1.2 SAMM
SAMM数据集是2016年由英国曼彻斯特城市大学的Davison等人提出的,同样使用200fps的高速相机捕获动作信息,图像分辨率为960×650像素,包含通过情绪诱导实验获得的159个自发的微表情,其来自32名受试者,其中包括13个不同的种族,平均年龄为33.24岁(标准差11.32,年龄在19到57岁之间),女性有17名.
3.1.3 SMIC
SMIC数据集是Li等在FG2013上发布的,所有数据均由100 fps的高速相机记录,图像分辨率为640×480像素,在20名受试者中,使用了其中16名受试者的164个自发式微表情.
3.2 具体实现
本文实现过程采用的实验平台为NVIDIA GTX 1080显卡,志强4核E3处理器,使用Keras深度学习框架和TensorFlow后端.
在将图像序列输入到网络之前,需要对图像序列进行预处理.首先使用时间插值模型将视频帧长度固定为10,随后视频帧的大小调整到64×64像素分辨率,以匹配网络的输入维度.在实验过程中,为了找到更好的输入数据,将SMIC数据集的TIM分别设置为10和18,实验结果表明TIM为10时,准确率比TIM为18高3.03%,因此TIM为10时效果更好.除此之外,还将视频帧分辨率分别调整为64×64,128×128,200×200,根据实验结果发现视频帧分辨率对微表情分类准确率没有影响,因此本文采用64×64的分辨率.关于卷积核尺寸的确定,本文亦进行了多次试验选择效果最好的,如图5是Res-STCN的第一层不同卷积核处理的结果,由于微表情肌肉变化主要集中在眼睛、鼻子和嘴附近,因此可以发现8×8卷积核更适合用于64×64像素视频帧的微表情识别.
在实验中,本文将数据集分为80%的训练集和20%的测试集,进行了多次对比实验.因为在实验中epochs到达100时,loss基本稳定,故本文将epochs设置为100,由于数据样本较小,因此将batch大小设置为4,训练时使用Adam进行优化,正则化强度为0.001,在10个epoch中模型性能不能提升时,学习率减少为之前的1/10.
3.3 结果与分析
通过上述参数设置,改进后的Res-STCN可以更好地适应微表情识别.在CASME2、SAMM和SMIC数据集上分别进行微表情识别分类,结果混淆矩阵图6、图7和图8所示,矩阵的每一列代表数据集所提供的的微表情分类标准,每一行代表Res-STCN识别的表情分类结果,表中对角线为正确分类比例,其余为错误的分类比例.
图6显示了本文所提出方法在CASME2数据集上的验证结果.由于害怕(fear)样本只有2个,悲伤(sadness)样本只有7个,不能很好地表现识别的准确率,因此在训练及测试集中均不考虑该分类,仅考虑高兴(happiness)、惊讶(surprise)、厌恶(disgust)和抑郁(repression).其中厌恶表情由于数据集样本较多,因此有更好的识别准确率,而悲伤表情测试集仅有2个样本,因此准确率较低.
图7显示了本文所提出方法在SAMM数据集上的验证结果,在该数据集上验证了生气(anger)、鄙视(contempt)、高兴(happiness)和惊讶(surprise)4个类别.在该数据集上鄙视表情测试样本仅有2个,因此准确率较低,而惊讶表情虽然测试样本也较少仅有3个,但由于发生惊讶表情时面部肌肉变化与其它表情相差较大,因此有很好的准确率.
图8显示了本文所提出方法在SMIC数据集上的验证结果,在该数据集上测试了积极(positive)、消极(negative)和惊讶(surprise)3个微表情类别.在该数据集上由于微表情类别较少,且测试样本数量比较均匀,因此在该数据集上3个类别的准确率差距较小且均有不错的表现.
将本文的方法结果与一些经典手工制作的方法(如:LBP-TOP和MDMO)和最新深度学习方法进行比较,结果如表2所示.
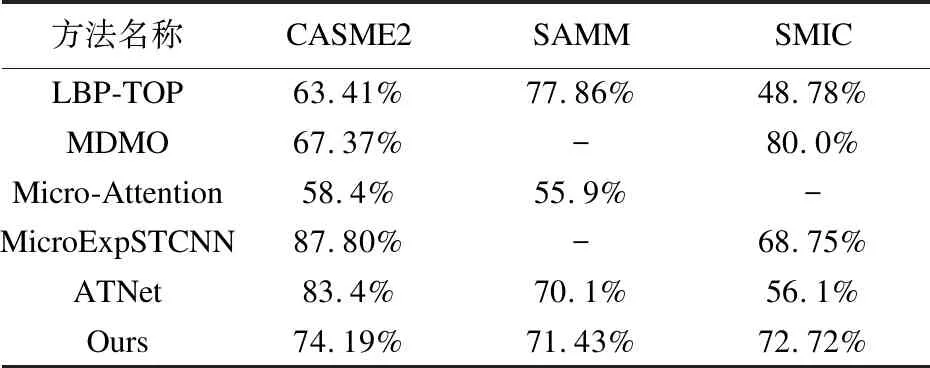
表2 本文所提出方法与经典方法及最新方法对比
LBP-TOP方法数据来自于CASME2、SAMM和SMIC数据集提供者,均采用LOSO(Leave One Subject Out)的交叉验证方法.在CASME2数据集上MicroExpSTCNN仅考虑高兴、生气和厌恶3个样本量较大的表情,因此得到了非常高的准确率,而本文方法与其他方法都是对5个微表情进行分类识别,因此准确率相对MicroExpSTCNN较低,而相较于其他方法有一定提升,仅次于ATNet,但ATNet使用CNN和LSTM相结合的双流时空网络模型,其网络较复杂,而本文网络结构简单.在SAMM和SMIC数据集上,相较于其他深度学习方法,本文提出的Res-STCN方法均有较好的准确率,而与LBP-TOP和MDMO两个手工特征方法相比,还存在一些不足,但是手工构建的特征需要耗费大量的人力成本,而深度学习方法不需要人为干预就可以选取所需的特征,节省了大量的人力资源.
4 总结
本文提出一种基于残差模块的可解释时空卷积网络模型的微表情识别方法,对于给定可解释的输入,即微表情视频帧序列,解释Res-STCN中模型参数和特征,实现了模型的可解释性.在模型性能方面,本文在CASME2、SMIC、SAMM数据集上进行了训练和测试,实验结果证明在微表情识别准确度上,本文方法与其他深度学习方法相比有显著提升.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
计算机研究与发展(2022年1期)2022-01-19
法律方法(2021年4期)2021-03-16
计算机应用(2020年12期)2020-12-31
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
文教资料(2018年30期)2018-01-15
无线互联科技(2015年23期)2016-03-05
文苑(2015年9期)2015-09-10
