
基于神经网络的棉花产量预测
2020-06-28 11:02:30
中国纤检 2020年6期
棉花是一种重要农作物,既可以用于纺织产品也可以用作工业原料。棉花产量的增减关系着人民的生产、生活、收入及国防工业的发展和社会的稳定,因此,有必要对棉花产量进行动态监测和预测,对种植量进行适时调整,以免出现供过于求或供不应求的情况。只有适时、精确地掌握棉花生产、销售、加工等环节的信息,引导产业链上各利益群体采取积极有效的措施,减小产业震荡,降低行业风险,才能让棉花产业健康持续地发展,因而有必要建立一种有效的棉花产量动态监测模型。
在农业产品产量预测方面,尹邦华等[1]以湖南省2001年至2017年间的粮食产量为基础,采用复合马尔可夫算法与灰色模型预估湖南省未来几年粮食产量,结果显示此种复合模型的预测精度优于单一的灰色模型。吴叶等[2]以2015年至2017年棉花月度平均价格为样本数据,使用MIVGA-BP模型进行预测,试验结果显示MIV-GA-BP模型的预测准确性比普通BP模型有明显提高。余焰文[3]结合江西省1990—2015年油菜年产量和气象条件预测油菜产量,并分析3种模型的准确率,结果表明辐热积模型预测精度最高。
棉花产业包括生产、销售、储藏及加工等诸多环节,要对其进行精确预测,存在很大难度。而BP[4](Back Propagation,简写为BP)神经网络[5]由于拥有很强的非线性拟合特性,已在很多领域被用于解决拟合、分类及预测等问题。因而本文使用1980—2019年全国棉花产量先训练BP神经网络,再使用训练好的BP神经网络预测2020年的棉花产量,为棉花的种植、交易及加工等环节提供数据支持。
1 神经网络预测原理
1.1 数据预处理
本文以1980—2019年国家棉花年产量为先验数据,先对历年产量进行滑动切片生成神经网络训练数据,再用训练过的网络预测2020年的年产量。各年棉花产量如图1所示,可见各年产量波动较大,但总体而言产量是增加的,1980年时年产量仅200多万吨,而到了2019年就增加到了600万吨,30年间增加了两倍。为使用神经网络预测2020年的棉花产量,首先要使用已有的1980—2019年全国棉花产量数据对神经网络预测进行训练,这就要求我们先对历史数据进行滑动切片,把前面q年的数据和当前年份的产量组成多个“q输入-1输出”的数据对,作为神经网络的输入和输出,用于训练神经网络,使其根据误差调节各神经节点的权重和偏置值,使总的误差最小。为使预测结果精度较高,q的值分别取3、6、9、12、15,表示滑动切片前面3年、6年、9年、12年、15年的数据,作为神经网络的输入,而当年的产量作为神经网络的输出。由于过大的数据会导致神经节点饱和使其拟合能力急剧降低,一般要将神经网络的输入输出数据归一化到区间(0,1)之间。由图1可见,历年棉花产量均小于1000万吨,因而本文先将数据除以1000进行归一化,将这些归一化后的数据作为神经网络的训练数据;同理,神经网络的输出需要乘以1000才能得到正确的预测值。
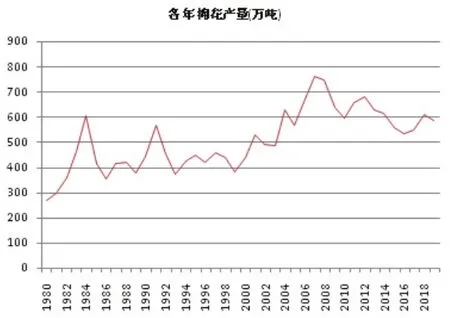
图1 1980—2019年历年全国棉花产量(单位:万吨)
1.2 神经网络原理
图2是本文所用神经网络的结构,包含两个线性层、两个非线性层及输入输出层,一共6层。图中标记为S的神经节所在的层就是非线性层,S表示该节点所用激活函数是Sigmoid函数。Sigmoid函数呈S型,在正无穷大处趋于1,在负无穷大处趋于0,具有非线性特征,神经网络的非线性拟合或分类的能力即来源于这种非线性特征。
Sigmoid函数的公式和一阶倒数分别为
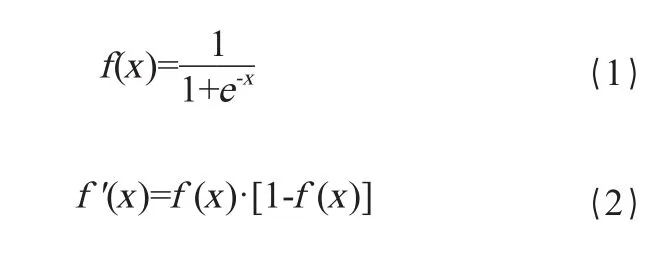
神经网络的初始输入可表示为:
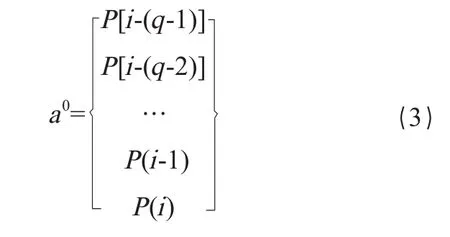
表示第0层,即神经网络的输入层。它是由第i年的产量及之前(q-1)年的产量组成的数据切片,共q个数。本文中,切片长度q拟采用3、6、9、12及15,并根据试验结果,选择最优的3个切片长度。中间各级输出
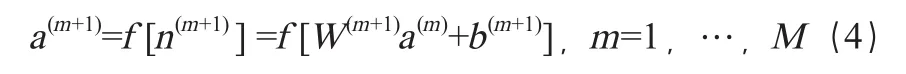
其中,M表示神经网络的总层数,因而第M层的输出就是神经网络的输出,式中的m表示第m层。
最后一层的输出用a表示,及第i+1年的产量。

正向计算完成后会得到一个结果(神经网络的输出),此结果一般与目标结果存在误差,需要将误差反向传播以调节神经节点的权重和偏置:

式(6)中t表示期望的输出,神经网络的实际输出理论上应该与期望的输出t相同,但实际上二者之间总存在一定误差,这就要反复按负梯度法调节神经节点的权重和偏置值,使它们的值越来越接近。除最后一层外,前面各层敏感性反向传播公式如式(7)所示:
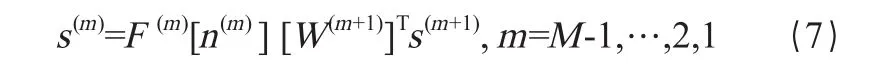
其中,W(m+1)表示第(m+1)层的权重。
最后,根据梯度下降法或共轭梯度法等算法更新各神经元的权重和偏置值:
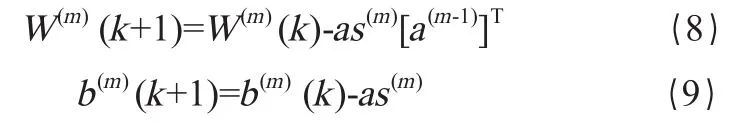
经试验,每层设置15个神经元比较合适,既能解决问题,节点数也不太冗余,如图2所示。

图2 本文所用神经网络结构
2 试验
本文中设计了两组试验,第一组是通过试验选出合适的神经网络输入个数,即训练用历史数据的年份数目q;第二组试验是先用1980—2019年产量的切片数据训练神经网络,再用此网络预测2020年的棉花产量。
2.1 选择历史年份数目
第一部分:本组试验由一步预测方案和两步预测方案组成。一步预测方案指用1980—2017年的年产量切片数据训练神经网络并预测2018年的棉花年产量;两步预测方案指用1980—2017年的棉花年产量切片数据训练神经网络并预测2019年的棉花年产量,以检验远期预测的可行性。为方便描述,当滑动切片数分别为3、6、9、12、15(即q=3、6、9、12、15)时,对应的预测方案称为3预测1,…,15预测1等。如表1所示,当切片数q由3变化到15时,相对误差先减小后增大,切片数q=3、15时预测效果较差,当切片数q=6、9、12时预测值的相对误差较小,因此优先选用切片数q=6、9、12这3种方案。
从表1中可以看出对最近年份的预测值,其相对误差较小,使用1980—2017年的棉花产量预测得到的2018年的年产量为588.93万吨,与真实值(609.6万吨)的相对误差仅为0.39%;而2019年产量的预测值为537.41万吨,与真实值(588.9万吨)相对误差达到8.74%,效果较差。对2018年5种不同方案的预测结果而言,6预测1方案的预测值为606.73万吨,与真实值(609.6万吨)的相对误差只有0.47%,预测精度最好。1980—2017年历年实际产量与对应6预测1方案预测值的对比如图3所示,可见二者基本吻合。

图3 6预测1(1980—2016年)

表1 由1980—2017年产量预测2018和2019年产量
第二部分:测试由1980—2018年的年产量训练神经网络,然后预测2019年的产量并与2019年的实际产量(588.9万吨)进行对比。由表2可以看出,当切片长度q=3、15时对应预测值与真实值的相对误差较大。对q=6、9、12时方案的预测结果求平均值,结果为574.5万吨,与真实值(588.9万吨)的相对误差为2.45%,在容许误差5%范围内,是可以接受的。
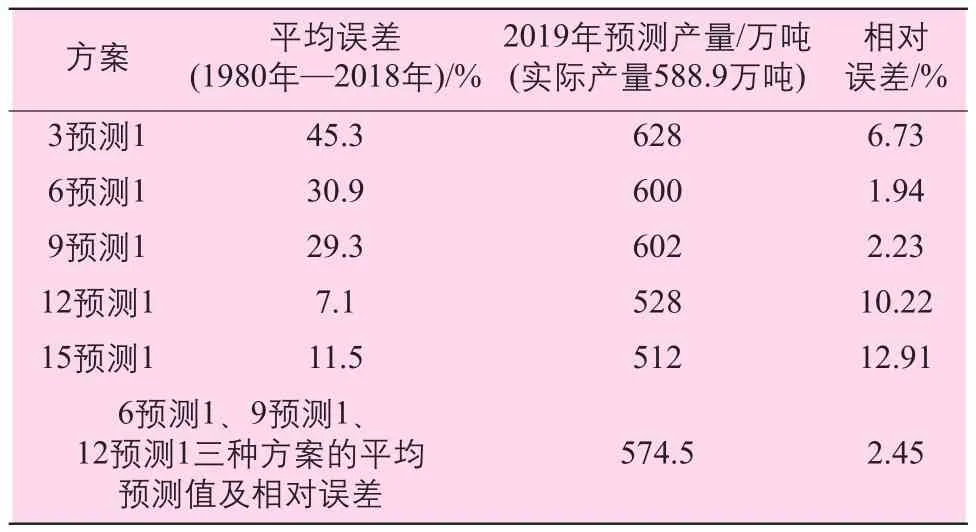
表2 由1980—2018年产量预测2019年产量
2.2 预测下一年产量
由上节中的试验可以看出,当历史数据的滑动切片长度q=6、9、12时,三种方案预测结果的平均值精度很高(相对误差小于5%),因而采用此平均值作为正式预测结果。使用1980—2019年的数据切片对神经网络进行训练,再用训练好的神经网络对2020年产量进行预测的结果见表3,切片长度q=6、9、12三种方案的平均预测值为578.8万吨,比2019年略少10万吨。
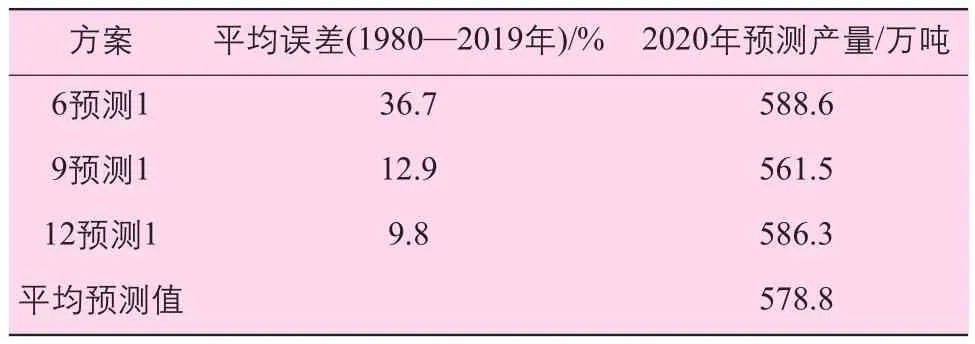
表3 由1980—2019年产量预测2020年产量
3 总结与讨论
本文以1980—2019年中国棉花产量数据为基础,通过对原数据滑动切片生成神经网络训练数据,并用此数据训练BP神经网络,再用训练好的神经网络预测2020年的国家棉花产量。试验表明,滑动切片的数据量过多或过少都会造成预测值的相对误差偏大,对2018、2019年产量的实践检验表明,当切片长度为6、9、12时取三者预测值的平均值效果较好,对这两年的预测结果与真实值的相对误差分别为0.39%及2.45%,对2020年产量的预测结果为578.8万吨,比2019年约少10万吨。
猜你喜欢
企业界(2024年8期)2024-07-05 10:59:04
当代水产(2023年2期)2023-05-19 08:23:02
当代水产(2023年2期)2023-05-19 08:22:56
今日农业(2021年19期)2022-01-12 06:16:32
今日农业(2021年3期)2021-12-05 01:46:23
环境保护与循环经济(2021年7期)2021-11-02 08:10:54
国外核新闻(2020年8期)2020-03-14 02:09:19
中国化妆品(2018年8期)2018-12-06 08:17:04
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
