
数字图书馆基于集成学习的相关反馈图像检索系统研究
2020-06-24 03:49阎循蓉
江西科学 2020年3期
阎 循 蓉
(宜春职业技术学院,336000,江西,宜春)
0 引言
本世纪以来,随着计算机技术、网络技术的发展,信息科学以惊人的速度改变着人们的思维、认知和行为方式。尤其是最近十几年,出现了物联网、大数据、区块链、深度学习、移动互联网等技术。计算机和人们生产、生活结合得越来越紧密。传统的图书馆作为人类学习技能、传播文化的重要场所,无论是信息载体还是服务体系或者检索方式,也在发生着日新月异的变化。
近20年来,数字图书馆(Digital Library)作为传统图书馆发展的必然方向,取得了长足的发展。数字图书馆是随着互联网发展而兴起的,其中数字的含义是在传统图书馆的基础上,通过计算机的数字化技术来对各类电子信息资源进行收集、整理、保存、归档、检索、查询、应用等[1]。因此通过数字图书馆,可以突破用户地理位置的限制,让不同地区(突破传统图书馆地域限制)的人可以轻松使用同一个数字图书馆提供的各种服务。因此数字图书馆是跨区域的、分布式的,可以整合不同地理位置的电子资源,将其归类、整理、存档,以便于提供相应的信息服务功能。当然也包括传统图书馆的功能,例如文献检索和书刊查询等[2]。我国自1996年开始提出“数字图书馆”的概念,到现在已经发展了20多年的时间。这期间,数字图书馆领域的研究得到了国家科技部的大力支持,各种国家级重大科技项目、国家863项目投入了大量的经费进行该领域的研究,也取得了一系列的成就。国际图书馆协会联合会(International Federation of Library Associations and Institutions,IFLA)是世界各国的图书馆协会组成的国际性组织,也是目前该领域最权威的专业机构。在计算机高速发展的今天,国际图书馆协会联合会也在紧跟时代发展的脚步,引领图书馆学的发展方向。自2014年开始,国际图书馆协会联合会加大了数字图书馆方面的研究力度,相应的研究论文数量呈现逐年递增的趋势,在2018年更是达到了研究的高峰。将大数据、物联网、移动通信技术、人工智能等新技术应用于数字图书馆领域来解决数字图书馆面临的新问题成为该领域近几年的研究热点方向。相信随着新技术的发展,数字图书馆研究领域必然呈现出更加多样化、智能化的发展趋势。
数字图书馆中存储的是分布式、多样化的电子信息,包括各种电子文档、各种视频、各种音频、各种图像等[3]。这些多媒体信息是数字图书馆信息源的基本组成部分,其中图像数据占很大比重。众所周知,人类视觉在所有感觉中(包括触觉、听觉、味觉、嗅觉等)占主要地位,因为人类获取的信息80%来自于视觉。因此多媒体信息中的图像类数据也是人类获取的最主要数据源。怎样对其进行高质量的检索势必影响多媒体信息的检索效果。换言之,数字图书馆中,图像信息的检索占重要地位(视频信息也可以看作是图像信息,因为视频由一帧一帧的图像组成)。
传统的文本检索仅限于关键字已知的应用场景,是通过输入单一或者组合关键字,来将待检索条件与文档库中既有资源进行关键字比对,从而定位到需要资源的过程。假设初次检索得到的结果并不能满足要求,则可以在初次检索的基础上,通过用户反馈来调节关键词名称、顺序、组合方式等形式,最终得到较满意的检索结果。而数字图书馆中的图像信息,属于非结构化的数据[4]。虽然可以简单通过给图像添加说明文字的方式将其转变成传统的文本检索,但一方面不符合实际情况,因为数字图书馆中的图像信息是海量的,很难组织大量专门人员对所有图像进行说明文字添加工作;另一方面人工添加说明文字具有一定的片面性、主观性、随机性等问题。不同人添加的说明文字会有差异,同一个人在不同的情绪、心态、时间段添加的说明文字也会有所差异,因此该方式很难适应现代高速发展数字图书馆的检索需求。
为此发展出专门的检索技术:基于内容的图像检索(Content Based Image Retrieval,CBIR)技术[5],这是从图像数据库中检索出和目标(待检索)图像具有最大相似特征的图像的过程[6]。该技术需要首先从图像中提取出有利于检索的信息作为图像的基本特征[7],包括从图像中提取的颜色、纹理、形状等信息。将这些信息组成一个整体,和数字图书馆的图像库中的源图像进行比对,通过一定的相似性评价技术进行彼此相似性的比对,并进行打分,从而得到和待检索图像具有最大相似度的图像。该技术的重点和难点一方面在于图像的特征提取技术,另一方面在于相似性评价技术。
1 图像特征提取技术
数字图书馆中的图像信息包含的特征有很多种(图1):1)简单的底层特征,包括颜色、纹理、形状等;2)图像中包含的对象间的空间信息特征;3)图像中蕴含的语义特征,包括场景信息、情感信息等。
可以形象地用一个层次模型来表示图像中包含的特征[8-9]。

图1 图像的分层特征
从图1中可以看出,图像特征可以大致分成3个层次。第1层也是最底层,属于物理层特征,是图像中可以直观提取的基本特征。该类特征可以通过一定的计算机技术进行提取,可以反映出图像中最表面的信息。这类特征可以作为图像检索的基本条件。因为当2幅图像差别显著时,那么其相互间的颜色等特征必然有明显的区别。可以从该类特征入手,寻找图像间的显著区别,作为图像检测的第1个必要条件。通过颜色进行区分的方式比较常见:如包含天空的图像与包含花朵的图像进行区分就可以简单通过颜色的方式:天空图像以蓝色、灰色为主,蓝色、灰色和白色占一定比例;花朵图像以红色、黄色、紫色为主,红色、黄色、紫色和绿色占一定比例。因此这2类图像即可以通过计算不同颜色值及相互间比重的方式进行区别。如图2所示。

图2 不同颜色比例的天空与花朵图像
通过纹理对图像进行区分的情况也较多:一幅冰箱图像,由于冰箱表面经过抛光等工艺,因此纹理较细;另一幅织物图像进行区分时,因为织物纹理较粗糙,因此很容易通过纹理对冰箱、织物进行区分。如图3所示。

图3 不同纹理的冰箱、织物图像
仅通过颜色、纹理等特征有的时候很难对图像进行区分,比方说斑马线和斑马、红气球和红太阳。因此需要在此基础上,从图像中提取更多的特征以辅助进行图像间的区分。
第2层特征是逻辑层特征,也是在物理层特征的基础上,可以从图像中通过较直观的方式进行提取的部分特征。具体包括图像中所蕴含的内容对象的空间关系、位置信息以及不同对象的标志信息等。这方面的特征是对图像内容[10]而言的。众所周知,图像都需要包含一定的信息。比方说,菊花图像中菊花的分布呈现出花瓣围绕中心展开的特点;羊群图像中羊群分布有一定的规律。这些信息会在具体位置上呈现出一定的空间分布的特点,比方说上下左右前后等方位信息以及位置信息。这些信息也代表了图像的部分内容,是图像所包含的主要、直接信息源,也可以作为图像检索的重要依据之一。如图4所示。
第2层特征有时也很难对图像进行区分,例如2幅狗表情图像,需要进行区分时,在第1层、第2层特征都相似的情况下,很难进行有效的区分,因此需要从图像提取更多的特征。

图4 不同空间相对位置的菊花、羊群图像
第3层是抽象层,是从图像中进行逻辑抽象和推理后得到的一些有具体语义的信息。这些信息需要对图像进行解读,并且进行理解后得到的包括图像中对象的场景、情感等特征。如给定一幅图,可以从中读出图像描述的地理位置、大致范围、大体环境、典型景观或者标志性建筑等信息,因此可以对包含不同位置特点的图像进行区分(图5);在一幅图中包含人或动物脸部信息时,可以从中读出人或动物的表情信息,从而对不同的表情进行区分。如图6所示。

图5 不同地理位置、标志性建筑图像

图6 不同的表情图像
通过以上3个层次的特征,即可从图像中提取到较充分的信息。另外,图像本身的来源、获取图像的网址、图像所在位置附近的文字提示信息都可以作为图像必要的特征帮助进行图像之间的区分。具体特征有以下几部分。
1.1 颜色特征提取
颜色作为图像的最直接、最简单特征,可以很方便地表达出图像的基本信息,对图像检索具有重要意义。图像的颜色特征具有稳定、平移不变性、旋转不变性的特点。颜色包括几个主要方面:在整幅图中不同颜色所占比例;在局部颜色的不同分布特点。其中在整幅图的颜色所占比例情况可以通过计算不同颜色所占比例进行计算,这对于区分颜色差别较大、各颜色占比例差别悬殊的不同图像比较合适。在整体颜色比例类似的情况下,可以计算局部颜色的不同分布情况,来进行进一步的区分。颜色特征提取可以通过颜色直方图技术来获取。颜色提取方法可以采用直方图加权法或者直方图相交法。
1.2 纹理特征提取
纹理特征分为局部纹理特征和全局纹理特征两类。是图像内像素点周围邻近的点灰度变化的反映。纹理揭示的是某种非随机特性,反映的是图像某一范围内不断重复出现的特点。通常不同表面粗糙度、材质、平滑度的图像具有不同的纹理特征。纹理特征在局部的重复性,可以构成其在全局的纹理特征。纹理特征有很多不同的衡量方法,如:灰度共生矩阵法、地统计学变差函数法、小波纹理提取法等。通过纹理特征提取法,可以提取图像的方差、均值、熵、对比度、能量等特征。这里可以采用灰度共生矩阵的方法进行纹理特征提取。灰度共生矩阵是统计图像上一定角度、一定方向的点与点的概率统计分布规律,从而揭示图像颜色值在方向、角度、速度上的变化。
1.3 形状特征提取
形状特征是区分不同图像的重要特征。可以采用两种特征对形状进行反映:轮廓特征和区域特征。其中轮廓特征也称为边界特征,代表了图像内不同内容的边界特点,包括:中心矩、偏心度等特征。通过轮廓特征可以很好地提取图像内所包含内容的大致轮廓信息。除了轮廓信息以外,还可以通过区域特征来反映图像的形状特点。区域特征具体包括弯曲点、转角度等特征。通过形状特征,可以很好地对颜色、纹理接近的图像进行进一步的区分和比较。
1.4 空间、位置关系、标志特征
这部分特征的提取是在颜色、纹理等特征提取的基础上,对图像进行分割操作得到图像内各部分内容后,对各内容相互之间的联系、位置、标志进行区分的结果。具体可以通过分割的方法[11],将图像分成前景和背景部分,对前景部分进行细分,得到各个主体内容的信息,对其进行位置计算、标志衡量的工作,得到不同内容相对位置、空间关系以及内容所含标识信息,将其作为图像的重要特征。
1.5 场景、情感、行为特征
该类特征属于图像抽象层次的特征,需要在常规特征提取的基础上,使用机器学习中分类和预测的技术,对图像中包含对象内容的抽象特征进行提取和分析,从而得到反映图像较高层次的特征。具体需要先对图像进行分割操作,得到前景和背景信息,分别对前景和背景信息进行分析,得到包含图像主要内容的对象,从中提取出图像产生的场景、图像中反映对象的情感、行为特征。这些特征反映的是图像内部所包含内容抽象层次的高层次信息,是对图像内容进行科学理解和分析的结果。该类特征的提取情况,反映了图像检索系统的智能化程度。也即是说,所提取的情感类特征越准确,越能反映出检索系统的智能水平,系统的检索程度也越接近于人类自然检索的结果。
1.6 图像语义特征
除了图像中包含或者提取的特征外,图像本身来源也提供了丰富的信息。这些信息很多都是对图像最好的说明,往往最能代表图像的本质特征。图像的出处,也就是图像的来源可以表示图像的部分信息。比方说来自于古代雕塑网站的图像往往反映了古代雕塑这个主题的信息;来自于现代美术网站的图像一般代表现代美术方面的信息等。图像来源地附近的文字信息很多情况下也和图像有着千丝万缕的联系,这些信息在一定程度上反映了图像所包含的语义信息。如一般论文引用图像位置下面紧跟着是图像的编号和名称信息,有时还包含图像的详细解释信息等。
以上图像特征可以较全面地反映图像所包含的内容、图像自身意义、图像内部所蕴含的情感、地理空间位置、时代背景、场景环境等信息。因此充分提取以上特征,非常有利于提高图像检索系统的性能。
2 相似性比较
在以上图像特征提取的基础上,可以采用适当的机器学习算法对待检索图像和数字图书馆中图像进行相似性比较。从而对数字图书馆中与待检索图像较接近的结果按照相似程度从大到小依次显示输出,从而完成检索过程。这里的相似性比较方法主要采用计算不同图像特征矢量间的距离方式。在所有距离中,欧式距离较通用。计算待检索图像特征向量与数字图书馆中图像的欧式距离,然后按照彼此距离从小到大排序,距离越小的图像间相似性越大。欧式距离公式为:
3 基于集成学习的相关反馈图像检索系统
在提取了足够的特征、选择了合适的相似性比较算法之后,可以通过在不同特征组成的特征矢量上采用欧氏距离比较方法进行相似性比较。
目前大多数数字图书馆图像检索系统均是基于图像的部分特征,比方说颜色特征、纹理特征来进行相似性比较从而确定图像间的相似性。这个方法固然可以进行一定的相似性比较,也可以得到图像检索结果。但由于并未充分利用图像中包含的全面特征,因此得到的检索结果不尽如人意;另外也有的检索系统将所有特征提取方法提取的特征组合在一起进行综合特征比对[12]。这个方法表面上看起来充分利用了全面的图像特征,但因为不同特征往往具有自己特点,因此将其综合在一起进行检索,得到的结果不一定更好,有时可能会适得其反。这个问题在机器学习领域早有定论,“维数灾难”就是这样产生的。也就是说,对待研究的样本进行特征提取时,并不是特征维度越高越好。因为构成待研究样本特征集的特征组合中,有的特征并不一定能够准确反映待研究样本的本质特点,有的特征之间是相互矛盾的。因此将其统一在一个特征集里,通过一定的相似性度量方法进行相似性比较,往往会得到比单一特征更差的结果。
这个问题在机器学习领域可以通过集成学习的方法进行解决。为此,在数字图书馆图像检索领域,引入机器学习的集成学习技术。合理利用各特征组成子特征集,在每个子特征集上采用一定的相似性度量方法进行相似性比较,然后通过集成学习的加权平均方法和意见一致性方法来充分利用各子特征集得出的结论,形成统一的结果作为查询结果。在人机交互的环境下,可以通过加权平均和意见一致性方法对各权值进行动态调整,从而得到更好的查询结果。
3.1 加权投票法
由于检索算法在各个特征子集上得到的检索子结果不同,势必造成不同的检索差异。这个差异可以用来对不同的检索特征子集进行最大化信息互补,从而提高单一特征子集上检索结果差的问题。根据不同检索特征子集检索结果可靠程度(人工评价),可以对不同的特征子集设置不同的权重。对于用户认为贡献较大的特征子集,权重设置相应提升(0和1之间的一个值),对于用户认为贡献较小的特征子集,权重设置相应降低(也是0和1之间的一个值)。这样可以充分利用不同特征子集的检索结果,对各结果进行最大化互补,从而得到更理想的检索结果。
3.2 意见一致性方法
借鉴物理学的共振原理。当系统被外界刺激,进行强迫震动时,当二者频率接近时,强迫震动的振幅最大。将此原理引入到图像检索领域的集成学习中。当检索算法在不同的特征子集上得到的结果近似程度较高时,可以将不同检索结果设置为接近的权重。这样这些特征子集所起的作用会得到进一步的增强,从而能够得到更加理想的检索结果。因此在人机交互进行反馈式检索的过程中,可以比较不同特征子集上的检索结果,对其中结果近似程度较高的结果,由系统设置接近的权重,从而将其作用进行放大。
在以上设计的基础上,形成基于集成学习的反馈式图像检索系统。采用加权平均法和意见一致性方法,对图像各子特征集得到的检索结果进行决策级融合。并通过人工交互的方式,由系统接收用户的反馈。以此为依据进行权重的调整,直至得到满足用户需要的检索结果。系统的架构图如图7。
4 结论
针对目前数字图书馆中信息多样化、检索需求多样化的实际问题,提出一个结合加权投票法、意见一致性方法等集成学习方法的相关反馈图像检索系统。包括颜色、纹理、形状、空间、位置关系、标志特征、场景、情感、行为特征、图像语义特征提取方法以及采用欧式距离进行计算的相似性度量方法。最后给出完整的系统的整体架构图。该系统通过引入集成学习的加权投票、意见一致性方法在相关反馈过程中进行各子查询结果优化时进行权重的调整,从而使系统得到更加理想的检索结果。
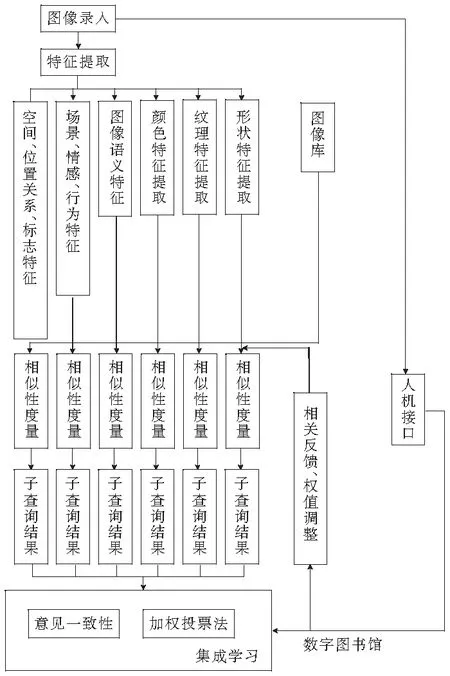
图7 数字图书馆基于集成学习的相关反馈图像检索系统架构图
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
软件(2020年3期)2020-04-20
电子制作(2019年15期)2019-08-27
摄影之友(影像视觉)(2018年12期)2019-01-28
电子制作(2018年19期)2018-11-14
Coco薇(2017年8期)2017-08-03
自动化学报(2017年11期)2017-04-04
浙江大学学报(工学版)(2016年2期)2016-06-05
Coco薇(2015年5期)2016-03-29
