
基于梯度增强决策树算法的纸张质量软测量模型
2020-06-23 05:32李继庚洪蒙纳孟子薇朱小林
中国造纸 2020年5期
江 伦 满 奕,2,* 李继庚 洪蒙纳 孟子薇 朱小林
(1.华南理工大学制浆造纸工程国家重点实验室,广东广州,510640;2.深圳新益昌科技股份有限公司,广东深圳,518000)
产品质量是制造业发展的生命线,是支撑经济转型升级的基石。在造纸企业中,在高产量高车速下纸张生产时引发各种质量问题,如依靠上浆定量对于纸张松厚度的控制,依靠刮刀起皱对于纸张吸水性的控制等变得更加具有挑战性,间接导致产品质量问题日益突出,同时消费者对于纸张质量要求的不断提高也给企业生产带来了巨大挑战。在“中国制造2025”坚持以创新驱动、质量为先、绿色发展、结构优化、人才为本的基本方针[1],以及我国在制造业的数字化、网络化和智能化取得明显进展的大背景下,基于数据驱动的智能制造将是企业未来质检以及提高产品质量、优化生产过程、节能降耗的重要方向[2-3]。
目前,造纸企业采取的质检方式为先产后检和抽检两种相结合的方式。其中,先产后检基于仪器质检。该检测方式存在滞后性,不仅会导致产品质量得不到及时的反馈,且生产过程无法实现闭环控制,基于数据驱动模型的优化控制将无法实施[4]。该检测方式严重依赖人工经验,致使产品质量波动,生产原材料资源浪费[5]。抽检的方式使得企业对纸张质量的检测达不到100%覆盖(目前某企业原纸质检覆盖率约在25%),存在大量质检遗漏而导致潜在的原纸质量问题。因此,对造纸企业纸张质量进行精确的在线预测是亟需解决的问题。
影响产品质量的因素有很多,如浆料的纤维形态对纸张质量影响较大,张美娟等人[6]研究表明细小纤维含量影响纤维间的结合力,进而影响纸张的抗张强度;彭金勇等人[7]指出纤维粗度对纸张的松厚度有重要影响;Trepanier[8]指出纤维长度、扭结纤维百分比对纸张抗张强度、柔软度和松厚度影响较大。制浆过程中的磨浆工艺对纸张质量影响也较大,Samira等人[9]概述了磨浆对纤维结构和性质的影响,主要表现在纤维润胀(包含纤维内部润胀和外部润胀)、细小纤维化、纤维变短以及纤维表面的结晶度和化学成分的变化,最终影响纸张的物理指标。纸机工艺过程中的流送、成形等流程,通过影响纤维之间的结合力和纤维的排列分布,来影响纸张的抗张强度、柔软度等[10]。其中浆料纤维形态又是影响纸张质量的关键变量[11],且长纤维和短纤维的用量直接关系到原料成本[12]。但在企业实际生产过程中无法实时在线获取浆料纤维形态。
决策树是机器学习中最流行的分类和回归方法之一[13],其中,梯度增强决策树(GBDT)不仅在实际应用取得了很大的成功,同时在各种机器学习和数据挖掘挑战中也取得了很大的成功[14]。GBDT 对于异常值的鲁棒性强,可高效地处理噪声,且泛化能力强,模型灵活性高,由于其灵活的损失函数机制使得GBDT 可以处理任何数据驱动任务,且处理速度快,效果好,模型有很好的解释性[15]。因此越来越多地用于解决非线性、多参数估计和预测问题[2]。造纸过程是典型非线性、时变性、不确定性、复杂性和滞后性的过程工业[16],采用GBDT 建立纸张质量软测量的数据模型,不仅可以解决上述问题,还可以克服机理建模的困难,有效地对产品质量进行预测。
为解决对造纸企业离线质检工作量大,纸张关键物理指标无法在线实时软测量的问题,本课题利用基于机器学习的数据驱动算法,建立精确的质量在线软测量模型。模型以原料纤维形态数据、浆料配比数据、磨浆工艺参数为初始输入,利用纤维形态软测量模型预测磨后纤维形态数据[17],然后结合关键纸机工艺参数,建立纸张质量软测量模型,实现对纸张抗张强度、柔软度及松厚度的实时在线软测量。不仅能够提前预测产品质量、降低产品不合格率、减少质量波动,并在此基础上节约原材料,降低企业生产成本;还可以省去人工检测费用及设备成本,并克服生产上质检工作的滞后性问题,对以后基于数据驱动优化生产工艺下的智能制造有极为重要的现实意义。
1 方法原理
1.1 建模技术路线
对纸张抗张强度、柔软度和松厚度进行软测量,主要包括利用磨后纤维形态软测量模型[17]对磨后浆料纤维形态进行软测量,然后结合造纸过程工艺数据,基于GBDT 算法,建立纸张质量软测量模型。该方法主要包括数据准备、数据预处理、磨后浆料纤维形态软测量、建立质量软测量模型及模型验证。建立纸张质量软测量模型的技术路线如图1所示。
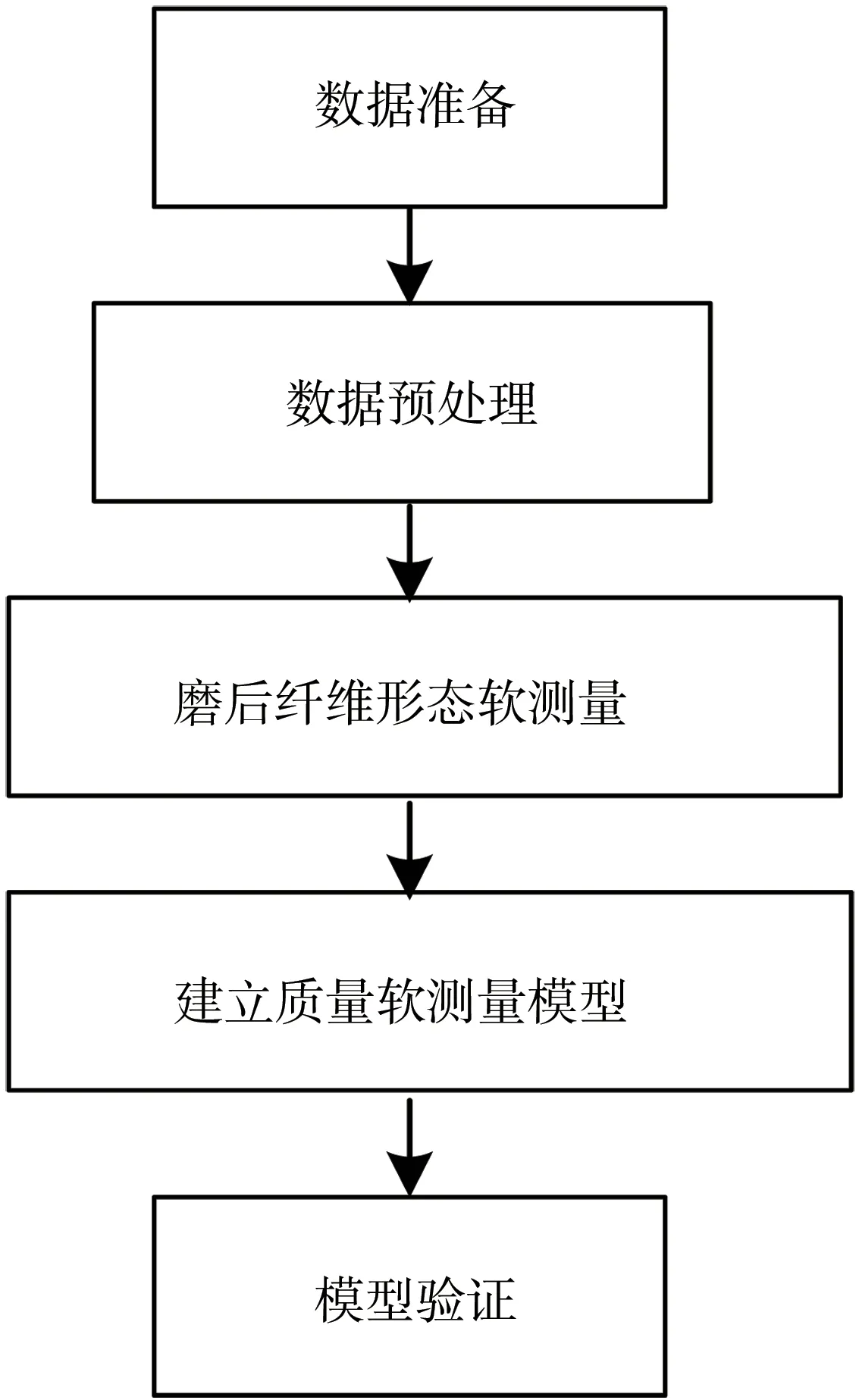
图1 质量软测量模型技术路线图
本研究首先获取某造纸企业实际生产中每轴原纸的浆料配比、质量检测数据(抗张强度、柔软度及松厚度)以及生产周期内的磨浆机工艺数据和纸机工艺数据。然后进行数据的预处理,即先剔除缺失值、恒定值等不真实的数据,再将质检数据与造纸工艺数据匹配。接下来利用磨后纤维形态软测量模型[17],输入模型所需要的浆料配比、磨浆机通过量、浓度及功率,来软测量磨浆后的纤维形态。最后结合特征选择纸机工艺数据,基于GBDT 算法建立纸张质量软测量模型,实现对纸张抗张强度、松厚度和柔软度指标的软测量。为了验证所建纸张质量软测量模型的真实有效性,再次提取现场数据对所建模型进行验证,可表明本研究最终所建立的纸张质量软测量模型精度高且泛化能力好,具有良好的应用性。
1.2 GBDT算法
考虑到纸张生产过程中存在间歇性设备(如磨浆机)、间歇性容器(如上浆池),导致其是一个非常复杂的非线性、时延性和不确定性过程,普通的模型难以准确对该过程进行较好拟合。GBDT 算法结合了回归树和增强算法框架,通过迭代降低模型的残差,有很强的非线性处理能力和预测能力[18]。另外模型拥有强大的损失函数,对于输入变量的异常处理能力和鲁棒性强,可高效地处理噪声[19],因此本研究采用GBDT算法对纸张质量进行预测,具体步骤如下。
(1) 确定目标函数。首先确定输入变量X =[x1,…xp]n·p和输出变量Y。

查找裂变特征j和裂变节点s的目标公式如公式(1)所示。
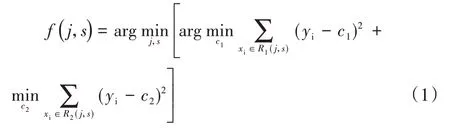
式中,yi为实际输出变量,c1、c2为拟合输出变量。


式中,F(x,P)为总体模型函数,h(x,αm)为第m个基础回归树函数,m = 1,2…M 为回归树棵树,βm为第m棵回归树权重,αm是第m棵回归树内的参数。


式中,m = 1,2…M为回归树棵树,α1是第1棵回归树内的参数,βm为第m 棵回归树权重,h(x,αm)为第m 个基础回归树函数,Fm(x)为前m 个模型函数,Fm-1(x)为前m - 1个函数。
GBDT 算法采用梯度下降法求极小值,最大下降梯度方向是损失函数在当前模型Fm-1下的负梯度方向,计算如公式(6)所示[14]。

2 结果与讨论
2.1 数据准备
本研究采集了某造纸厂实际生产数据作为建模的数据基础(来自企业MES 系统数据)。主要包含从业务数据库提取浆料配比数据、磨浆工艺数据及质检数据,采集频率为每轴纸的相关数据,从生产过程数据库提取造纸工艺数据,采集频率为每分钟的相关数据。本研究所展示的数据均为脱敏处理后的数据。
由于在造纸实际过程中,当生产出现停产(如突发断纸)或者停机状态及制造执行系统(MES)网络通信异常时,大部分数据是零值或者空缺值,一些计量仪器还会显示最终时刻的计量值(即出现恒定值异常)。故本研究首先剔除这些非真实有效数据,以提高数据的可利用性,保证不会影响后期数据建模的模型精度。另外对于企业而言,不可能做到对生产的全部原纸产品进行所有质量指标的检测,而是对部分原纸产品轴纸末端采样进行全检和非全检混合的模式。在生产上,生产一轴纸约需1~2 h,针对轴纸末端的检测仅是下轴时刻1 min 内的质检指标值,故还要匹配到这1 min 内的纸机工艺参数,即根据质检数据中每一轴纸的轴号信息,结合卷纸长度指标,对采样原纸质检数据进行生产时序上的匹配,以完成纸机工艺参数与质检数据的逐一匹配,为后续建模做数据基础。
本研究具体的数据预处理方式如下:对于存在缺失的数据(如磨浆机功率缺失、非全检数据)进行删除;对于工艺参数与质检数据的匹配,首先导出卷纸长度数据,剔除缺失值及恒定值,然后从中提取所有最大值即所有卷纸末端时刻点的卷纸长度值,该时刻点就是质检点时刻,最后匹配上该时刻的纸机工艺参数值,即得到同一时刻上质检数据与工艺数据的完整建模数据。本研究建模数据和验证数据分别采集于某造纸厂2018 年4 月1 日至2018 年10 月31 日和2018 年12 月15 日至2019 年2 月11 日两个时间段内的生产数据,经上述预处理、数据匹配后共计建模有效数据580组64维,验证数有效数据123组64维。
2.2 纸张质量软测量模型建模
在建立纸张质量软测量模型之前,还需要先通过磨后纤维形态软测量模型[17]软测量磨后纤维形态数据,即将预处理好的原料纤维形态、浆料配比及磨浆功率、流量和浓度数据输入到该模型,模型输出磨后纤维形态数据。接着针对获取的预处理过的纸机工艺特征,作建模前的相关性分析和排序,选取对质量指标影响较大的纸机工艺特征,避免特征太多增加模型的复杂度,同时剔除无关变量影响。相关性分析选择结果如图2所示。相关性分析可以发现两个变量之间的相关性程度,相关系数在[-1,1]上,正值表示正相关,负值表示负相关,且绝对值越大相关性越强,相关系数大于0.4,则表示关系紧密。本研究均选取相关系数绝对值大于0.4 的纸机工艺特征,即图2 中各纵坐标所示的特征变量。
针对特征选择后的580组数据,划分80%训练数据集和20%测试集,训练集用来训练模型参数,测试集用来测试所训练的模型精度。基于GBDT 算法,分别建立纸张抗张强度软测量模型、柔软度软测量模型和松厚度软测量模型,抗张强度软测量模型输入包含7种磨后浆料纤维形态(纤维平均长度、纤维平均宽度、扭结纤维百分比、断尾纤维百分比、纤维平均粗度、细小纤维含量(按长度)和分丝帚化率)及上述特征分析所选的图2(a)中特征,模型输出为纸张抗张强度值。柔软度软测量模型输入为上述7种磨后浆料纤维形态及图2(b)中特征,模型输出为纸张柔软度值。松厚度软测量模型输入为上述7种磨后浆料纤维形态及图2(c)中特征,模型输出为松厚度值。
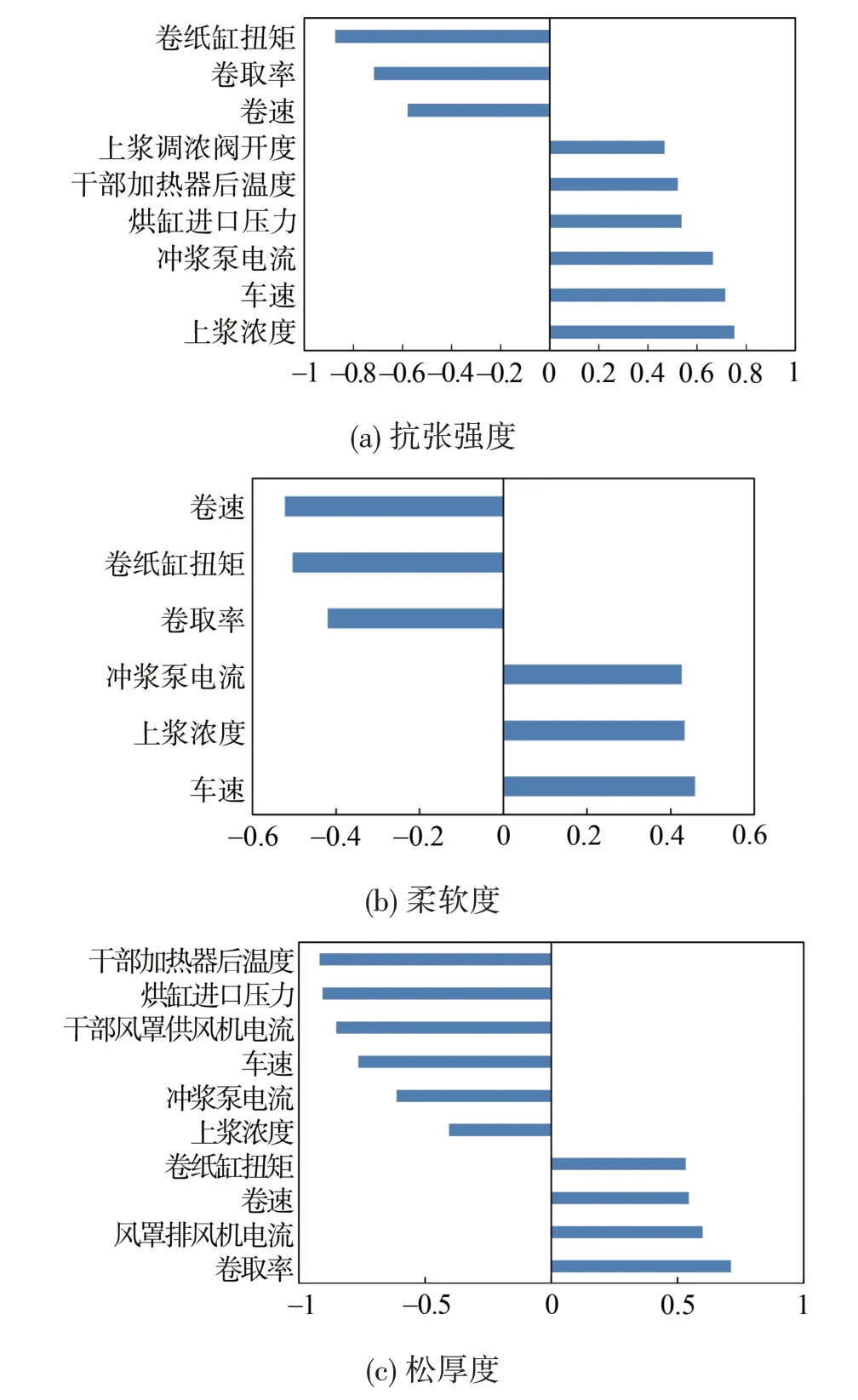
图2 纸张各指标相特征选择结果
对于模型参数,GBDT 算法主要有损失函数、每棵树深度、弱回归树棵树和学习率4 个参数需要选择。损失函数常用的主要有最小二乘、最小绝对值差值、Huber 损失和分位数损失,结合本研究数据波动较大,而Huber 损失函数对异常值的抗干扰能力强,因此本研究选用Huber损失函数。然后确定每棵树深度,在数据量不大的情况下,树深度一般在3~6之间选取,树深度较高很容易导致模型过拟合[18],即模型过度学习训练集特征导致对新数据的预测效果变差,表现在训练误差降低而测试误差反而增加。接着确定弱回归树棵树,在10、100、1000 三个数量级上选取范围,为了找到最佳值,使用网格搜索方法[20],以10(或50) 为增量搜索确定。最后确定学习率,在0.001、0.01、0.1 数量级上选取,然后逐步缩小范围,直至在保证模型没有过拟合的前提下测试误差最低,即为模型最佳参数。3 种质量软测量模型参数的最佳值如表1所示。模型的测试结果如图3所示。
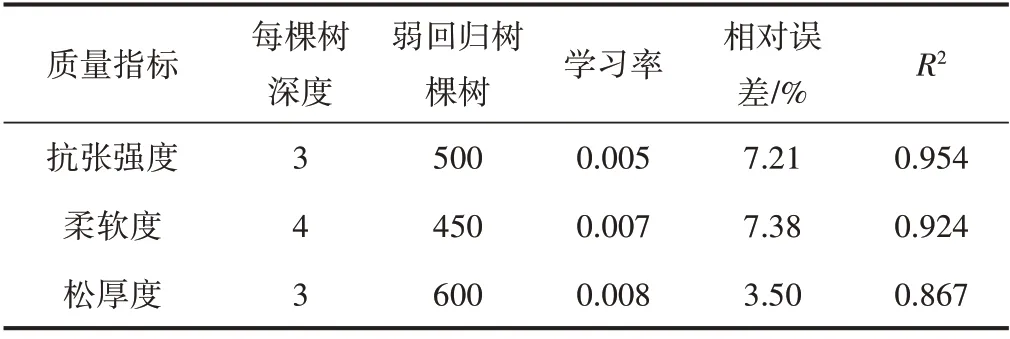
表1 GBDT算法模型参数的最佳值

图3 纸张各指标质量软测量模型测试结果
由表1 及图3 可知,测试数据中预测值与实际值拟合的R2非常高,模型对实际数据的波动性呈现较好的预测能力。另外,抗张强度、柔软度、松厚度模型的平均相对误差分别为:7.21%、7.38% 和3.50%,模型精度良好。
2.3 模型验证
为验证模型的稳定性和泛化能力,本研究选用了现场的不同数据,来验证模型的有效性。所以再次从上述造纸企业MES 上采集另一时间段内数据进行模型的验证,按照建模时数据的处理方式得到对应123组数据,输入到模型,输出为原纸的抗张强度、柔软度和松厚度指标,验证结果如图4所示。

图4 纸张各指标质量软测量模型验证结果
由图4 可知,纸张抗张强度的平均相对误差为6.87%,相比建模时精度提高4.71%;柔软度的平均相对误差为6.88%,相比建模时精度提高6.77%;松厚度的平均相对误差为3.12%,相比建模时精度提高10.86%。模型对新验证数据的预测结果精度高,泛化能力强,表明本研究所建模型真实有效,且满足生产上的实时质检误差需求,可以用于实际生产中。
3 结 论
本研究针对造纸企业纸张关键物理指标进行软测量,基于机器学习的梯度增强决策树(GBDT)算法,采集造纸企业实时生产过程数据,建立造纸企业质量在线软测量模型及验证。结果发现,基于GBDT算法建立的质量在线软测量模型精度良好,满足质检误差需求。在采集新数据验证后,纸张抗张强度、柔软度、松厚度的平均相对误差分别为6.87%、6.88%和3.12%,表明模型精度泛化能力良好,且有较高的应用价值,可以为生产上监督异常、稳定产品质量及优化操作工艺提供价值依据。
猜你喜欢
再生资源与循环经济(2022年9期)2022-11-20
化工设计通讯(2022年5期)2022-05-25
造纸信息(2021年3期)2021-04-19
造纸信息(2021年2期)2021-03-08
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
陶瓷学报(2020年5期)2020-11-09
初中生世界·九年级(2020年2期)2020-04-10
山东陶瓷(2020年1期)2020-01-08
科学大众(中学)(2019年3期)2019-05-17
电子制作(2018年17期)2018-09-28
