
基于大数据云平台的深度学习预测模型研究
2020-06-22 13:15陈亮亮邵雄凯高榕
软件导刊 2020年5期
陈亮亮 邵雄凯 高榕
摘 要:近年来,随着云计算、大数据等技术的迅猛发展,如何快速、有效地从纷繁复杂的数据中获取有价值的信息成为当前大数据应用的关键问题。为此,对基于大数据云平台的深度学习预测模型进行研究,以对未来序列数据走势进行有效预测。首先对几种基于深度学习的长短序列预测模型进行对比分析,分析其与传统预测模型的区别及优势,提出一种加入dropout的轻量级GRU预测模型。采用代表性天气数据作为实验对象,实验结果表明,该方法的实验预测指标MAE(平均绝对误差)的平均值相比传统预测方法有所提高,从而有效验证了轻量级GRU预测方法的正确性与有效性。
关键词:大数据;云平台;深度学习;预测模型;数据仓库
DOI:10. 11907/rjdk. 191883 开放科学(资源服务)标识码(OSID):
中图分類号:TP306文献标识码:A 文章编号:1672-7800(2020)005-0042-06
0 引言
随着大数据时代的到来,如何处理海量数据对于如今的数据处理技术提出了更高要求,因此大数据管理平台、数据仓库技术以及BI(Business Intelligence)工具等应运而生。其中,etl(抽取,转换,加载)是BI和数据仓库的核心与灵魂,能够按照统一规则集成并提高数据价值。这些数据管理工具可为商务决策分析提供支持,使人们从海量数据中挖掘出所需的信息。但由于数据体量庞大,容器技术又为云计算的发展开辟了新的道路,使系统资源的利用效率越来越高。传统大数据分析模块能对平台数据作基本的挖掘与分析,但数据中通常还包含一些深层次信息,因此需要对数据作更深入的处理。区别于传统机器学习方法,深度神经网络是一个逐层提取特征的过程,并且是由计算机从中自动提取数据,而不需要人类干预提取过程。特别是在预测领域,深度学习能够更精准地预测未来趋势。
针对预测算法及相关模型,特别对于天气序列数据方面的预测,很多学者进行了大量研究。传统预测方法主要包括惩罚线性回归方法和集成方法。一些学者提出利用机器学习方法进行预测,如张鑫等[7]针对随机森林的强度和相关度对其进行剪枝,使得剪枝的随机森林算法在所应用的数据上表现出优于传统随机森林算法的性能;王定成等[12]提出一种多元时间序列局部支持向量回归的日气温预测方法,以日最高、最低气温为例,使用C-C方法与最小预测误差法构造日最高、最低气温的多元时间序列,并将分段提取最近邻点方法应用于局部支持向量回归,建立提前1天的每日最高、最低气温局部预测模型。之后还有学者提出采用集成方法进行预测模型构建,集成方法的关键是通过结合这些弱学习器的偏置和或方差,从而创建一个强学习器(或集成模型),从而获得更好的性能。底层算法又称为基学习器,基学习器是单个机器学习算法,上层算法通过对基学习器进行巧妙的处理,使模型相对独立。有很多算法都可作为基学习器,如二元决策树、支持向量机等。
之后深度学习也逐渐进入预测领域,主要有基于CNN与RNN神经网络的预测模型等,也能达到较好的预测效果。如杨函[16]提出通过滑动时间窗手段改造,使普通神经网络也能学习到历史时序特征;邓凤欣[4]利用LSTM神经网络研究股票时间序列的可行性。以上文献都为本文研究提供了思路。
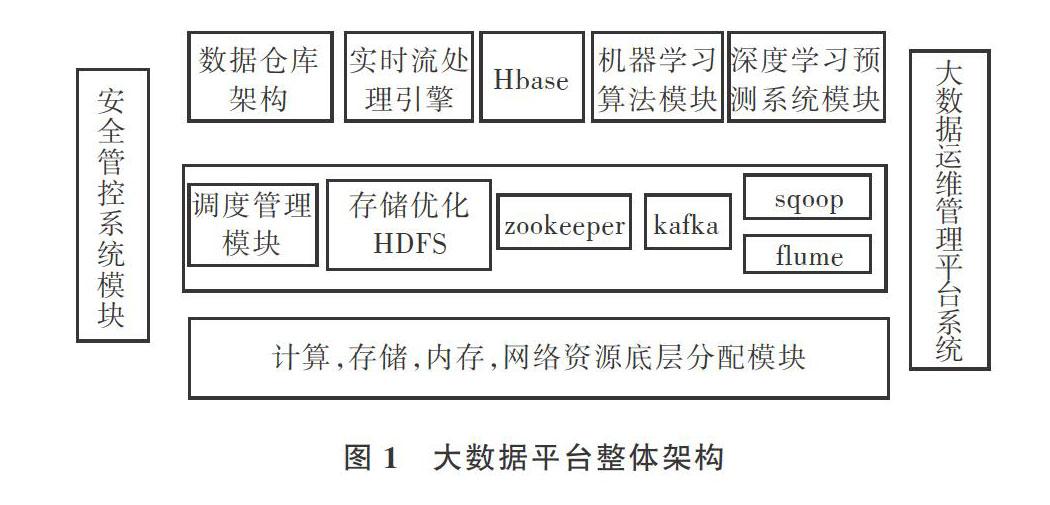
1 大数据平台架构介绍
大数据平台包含了大数据处理整套流程,平台整体架构如图1所示。
首先数据来源于数据仓库架构,具体为db2本地数据接口,通过传感器采集到天气数据信息并传入本地数据库作初步处理;之后通过sqoop、flume组件进行数据的采集抽取,可以根据维度进行汇总划分;上传到hdfs后,再次进行相关的etl操作,如码值转换、merge等。
大数据平台还有HBase和kafka等数据存储组件,以应对海量数据存储。HBase位于结构化存储层,Hadoop HDFS为HBase提供了可靠性较高的底层存储支持,Hadoop MapReduce为HBase提供了高性能计算能力;Zookeeper为HBase提供了稳定的服务和failover机制;kafka满足了日志处理以及高吞吐量的需求;Zookeeper则用于分配集群资源,同时负责组件间的通信;调度模块方便人们对数据仓库中的etl程序、shell脚本运行状态进行管理,同时了解程序运行状态。
算法模块包括spark的MLlib传统机器学习模块和深度学习模块。本文主要讨论深度学习模型在大数据平台上的应用,以及如何与大数据运维管理模块进行交互。大数据运维管理平台是整个集群的灵魂所在,能够保障集群的稳定性及高效性。主要表现在以下几个方面:①保障各数据节点的可用性;②保障计算、存储网络等资源的合理分配以及集群资源利用率,方便集群中程序的顺利执行;③对shell脚本进行管理,大数据集群与Linux系统密不可分,很多时候为了实现集群运维管理的自动化,需要定时采用shell脚本处理一些问题,或开启守护进程监控部分关键位置;④每天能及时统计一些关键指标点,并进行报表展现;⑤对相关etl程序以及存储过程程序进行监控,保障程序正常运行。
2 LSTM与GRU原理
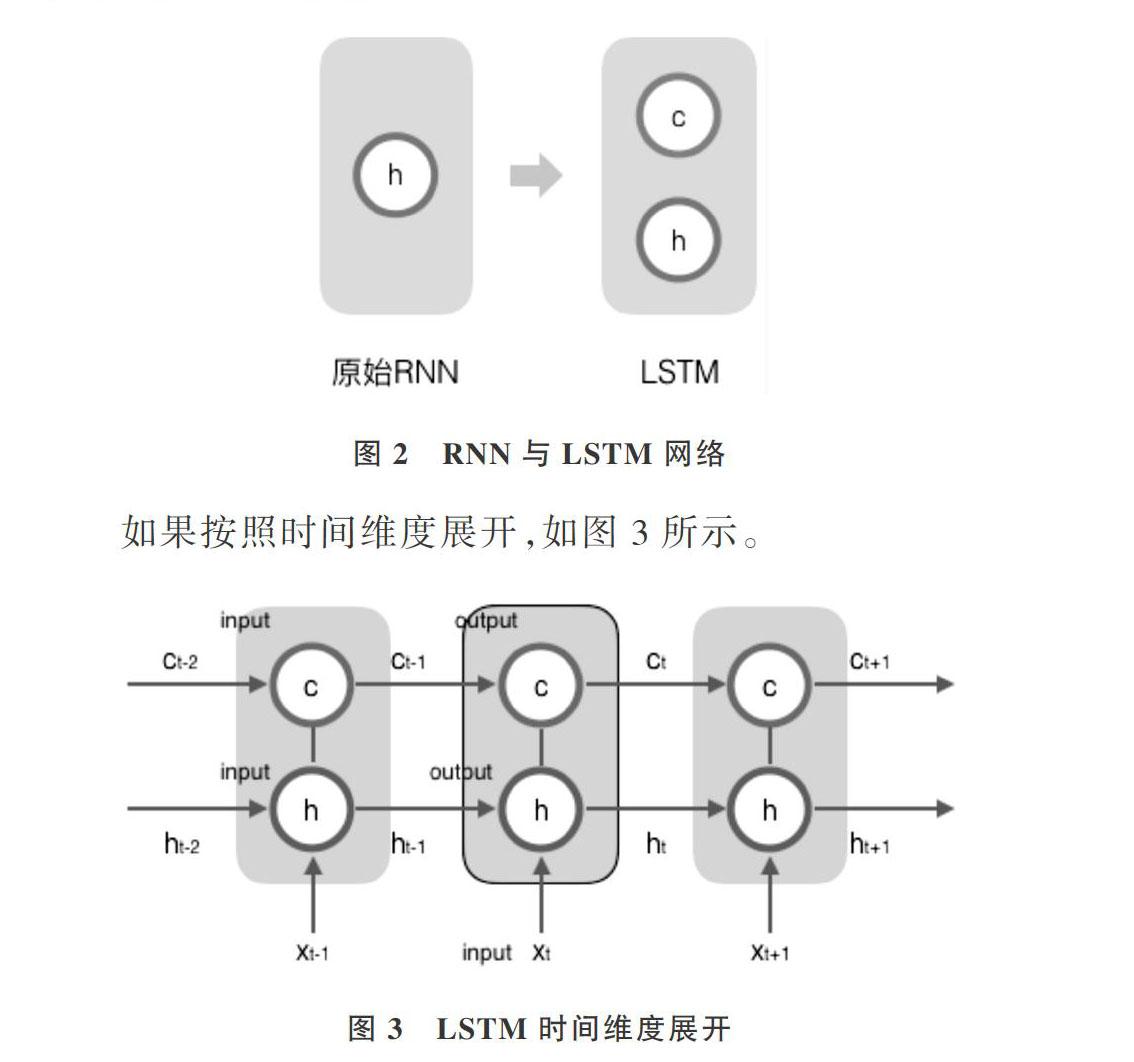
传统线性模型难以解决多变量或多输入问题,而RNN解决了这一问题。RNN 是包含循环的网络,当时间间隔不断增大时,RNN 则无法学习到连接较远信息的能力,而神经网络如LSTM擅长处理多个变量的长连接问题,该特性有助于解决长时间序列预测问题。LSTM模型是对RNN卷积神经网络进行改进得到的(见图2),由于存在梯度消失或梯度爆炸问题,传统RNN在实际中很难处理长期依赖关系,而LSTM绕开了这些问题,依然可以从数据语料中学习到长期依赖关系。
在t时刻,LSTM的输入有3个:当前时刻网络输入值x_t、上一时刻 LSTM输出值h_t-1,以及上一时刻单元状态c_t-1;LSTM 的输出有两个:当前时刻 LSTM 输出值h_t与当前时刻单元状态c_t。
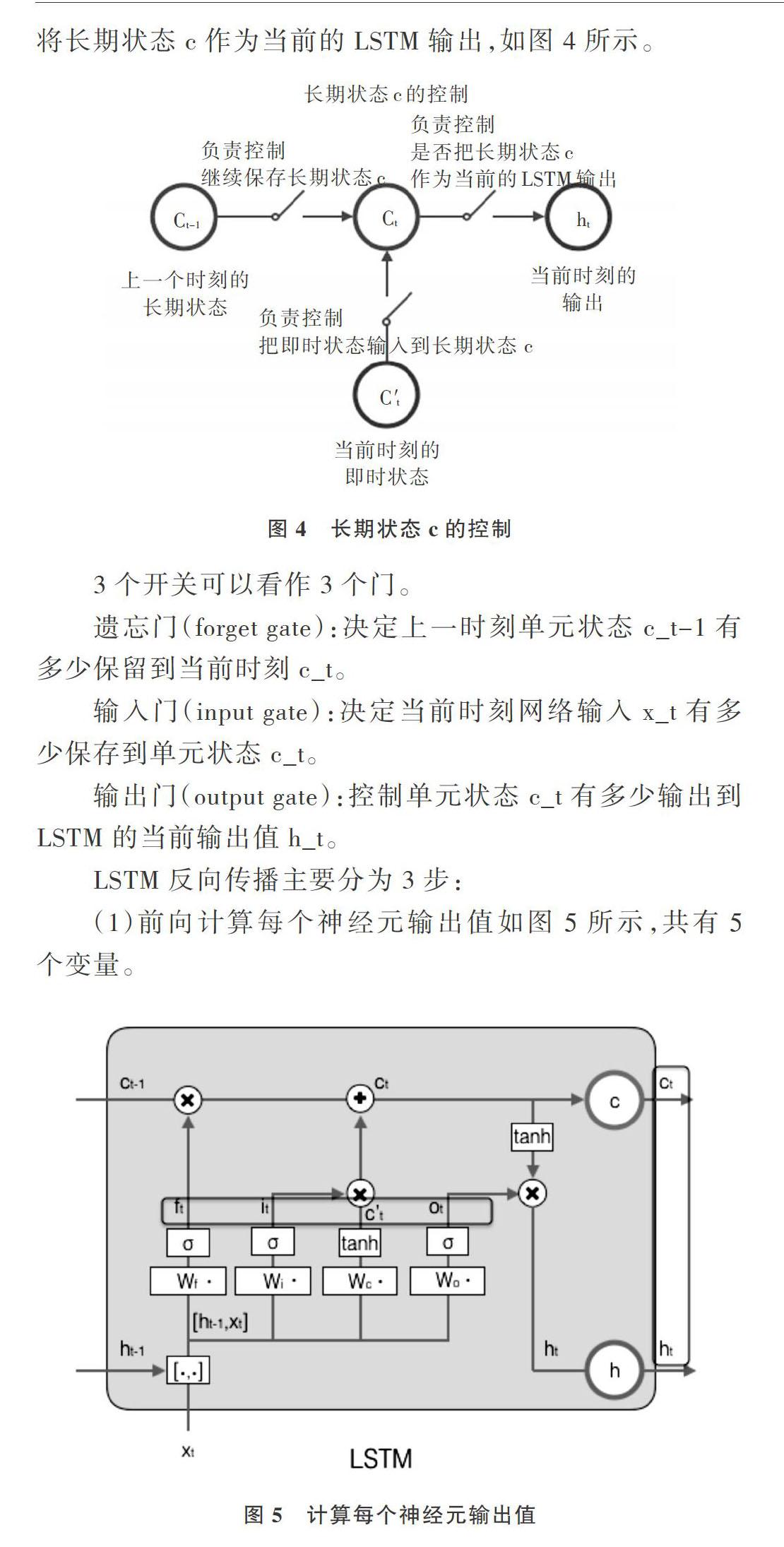
为了控制长期状态,这里设置3个控制开关,第一个开关负责控制继续保存长期状态c,第二个开关负责把即时状态信息传递给长期状态c,第三个开关负责控制是否将长期状态c作为当前的LSTM输出,如图4所示。
(1)前向计算每个神经元输出值如图5所示,共有5个变量。
(2)反向计算每个神经元的误差项值。与 RNN 一样,LSTM 误差项反向传播也包括两个方向:一个是沿时间的反向传播,即从当前 t 时刻开始,计算每个时刻的误差项,一个是将误差项向上一层传播。
(3)根据相应误差项,计算每个权重梯度。调参目标是要学习8组参数(W分别代表权重矩阵和偏置项),如图6所示。
为了提升训练效率以及简化模型架构,一个基于LSTM的改进版模型GRU应运而生。GRU是LSTM网络的变体,其较LSTM网络结构更加简单,而且效果很好,因此也是当前非常流行的一种网络。
GRU可以解决RNN网络中的长依赖问题,在GRU模型中只有两个门:更新门和重置门,如图7所示。更新门决定有多少过去信息可用来利用,重置门决定丢弃多少过去信息。zt代表更新门操作,ht代表重置门操作。一般来说,GRU计算速度较快,计算精度略低于LSTM。
候选隐藏状态只与输入以及上一刻的隐藏状态 h(t-1)有关。这里的重点是,h(t-1)与 r 重置门相关,r取值在 0~1 之间,如果其趋近于 0,候选隐藏状态上一刻信息即被遗忘。当前隐藏状态取决于 h(t-1)和h~,如果 z 趋近于 0,则表示上一时刻信息被遗忘;如果 z 趋近于 1,表示当前输入信息被遗忘。
3 加入dropout的轻量级GRU预测模型在序列数据上的应用
通常增加网络容量的做法是增加每层单元数或增加层数。循环层堆叠(Recurrent Layer Stacking)是构建更强大循环网络的经典方法,例如,目前谷歌翻译算法就是7个大型LSTM层的堆叠。在 Keras 中逐个堆叠循环层,所有中间层都应该返回完整的输出序列(一个 3D 张量),而不是仅返回最后一个时间步的输出,这可以通过指定return_sequences=True实现。但由于数据量以及网络规模过大,会产生过拟合现象。于是引入dropout正则化方法降低过拟合,dropout不同的隐藏神经元就类似训练不同网络(随机删掉一半隐藏神经元导致网络结构已经不同),整个dropout过程则相当于对多个不同神经网络取平均,而不同网络产生不同的过拟合,一些互为“反向”的拟合相互抵消即可达到整体上减少过拟合的效果。
(1)采用Web前后端知识体系搭建大数据管理平台基本框架,基本模块主要包括数据量指标管理模块、程序管理模块、脚本管理模块与日志管理模块。
(2)循环 dropout(recurrent dropout)。这是一种特殊的内置方法,在循环层中使用 dropout降低过拟合,并堆叠循环层(stacking recurrent layers)提高网络表示能力(代价是更高的计算负荷)。
(3)训练测试数据准备。使用的数据主要是由德国马克思·普朗克生物地球化学研究所气象站记录的天气时间序列数据,本文使用的是2009-2016年的数据。
(4)将数据预处理为神经网络可以处理的格式。数据中的每个时间序列位于不同范围(比如温度通道位于-20~+30之间,气压为1 000mb左右)。因此,需要对每个时间序列分别作标准化处理,让其在相似范围内都取较小的值。
(5)算法模型搭建。主要有基于机器学习的密集连接模型、使用dropout正则化的LSTM长短记忆模型和GRU模型,以及 dropout 正则化的堆叠 GRU 模型。
(6)数据集划分。本文创建一个抽象的generator函数,并用该函数实例化3个生成器:一个用于训练,一个用于验证,还有一个用于测试。每个生成器分别读取原始数据的不同时间段:训练生成器读取前200 000个时间步,验证生成器读取随后的100 000个时间步。
(7)假設温度时间序列是连续的(明天温度很可能接近今天温度),并且每天具有周期性变化。因此,一种基于常识的方法就是始终预测24小时后的温度等于现在的温度。本实验使用平均绝对误差(MAE)作为评估指标。
(8)构建模型。本文准备了一个轻量级网络,最简单的数据模型Sequential是由多个网络层线性堆叠的栈。对于更复杂的结构应该使用Keras函数式,其允许构建任意的神经网络图。
(9)将网络训练历史轮次数据通过图表形式表现出来,可以清楚、直观地看到各轮次训练情况,以便对训练轮次及权重进行调整。
(10)在LSTM模型中,隐藏层有50个神经元,输出层有1个神经元(回归问题),输入变量是一个时间步(t-1)的特征,损失函数采用Mean Absolute Error(MSE),优化算法采用Adam,模型采用40个epochs,并且每个step大小为500。
(11)本实验3种模型都采用Mean Absolute Error对整个训练轮次平均值进行评估。
(12)将最终训练结果通过图表形式展现出来,参考Validation loss以及Training loss的图形变化情况,对比模型训练效果。
(13)评估模型预测效果,以选取最好的模型。
4 实验与分析
4.1 数据集
数据集主要是由德国马克思·普朗克生物地球化学研究所气象站记录的天气时间序列数据集。在该数据集中,每10分钟记录14个不同的量(如气温、气压、湿度、风向等),其中包含多年的记录。原始数据可追溯到2003年,但本文仅选用2009-2016年的数据。
4.2 数据生成器
猜你喜欢
自然资源信息化(2019年4期)2019-03-29
电子制作(2016年15期)2017-01-15
商情(2016年43期)2016-12-23
山东工业技术(2016年15期)2016-12-01
中国新通信(2016年16期)2016-10-18
中国教育信息化(2015年10期)2015-08-23
