
基于集成学习的图像垃圾邮件过滤方法*
2020-06-22 12:29赵俊生王鑫宇尹玉洁
计算机工程与科学 2020年6期
赵俊生,候 圣,王鑫宇,尹玉洁
(内蒙古工业大学信息工程学院, 内蒙古 呼和浩特 010080)
1 引言
据 The Radicati Group 集团发布的数据分析显示,2016 年全球电子邮箱用户人数已达到 26 亿,并且预计至 2020 年,全球电子邮箱用户人数将突破 30 亿大关。据华经情报网的调查报告显示,截止2018年6月,中国网民规模达到8.02亿,2018上半年中国邮件用户规模及使用情况的数据显示,中国邮件用户规模为3.06亿,与2017年末相比增长了2 134万,在整体网民数量中邮件用户数比例达到38.1%。由于邮件发送的简便性,只要有目的邮箱地址就可以进行邮件发送,如此方便的交流方式也为一些恶意用户提供了方便。目前中外用户每日收到的垃圾邮件数量日益增长。由文献[1]可知,这些垃圾邮件来源于公司或个人,在接收方未知情时,随意向邮箱传播不良信息,这些信息可能是一些接收方并不关心的广告、诈骗信息或者病毒。垃圾邮件占用了网络带宽,也占用了邮箱的存储空间,这类邮件会影响我们利用邮箱进行交流,同时也隐藏着巨大的安全隐患,极有可能会严重侵犯用户的个人权益。垃圾邮件不仅会影响个人,也是全球各大企业和诸国面临的巨大难题。垃圾邮件给企业及国家带来的损失令人震惊,全球每年因垃圾邮件带来的损失近4 000亿元,其中我国也是垃圾邮件大国,因此造成的损失占据相当大的比例[2]。
中国权威的互联网协会给出了垃圾邮件的定义:在收件人不是出于个人要求或是同意情况下接收的各种形式的具备宣传性的邮件,无法拒收的邮件,含有虚假或是隐藏诈骗信息的邮件,都称之为垃圾邮件。垃圾邮件的危害有以下几个方面:其一,耗费了收件人的时间和精力;其二,占据了有限的空间和带宽;其三,可能会侵犯人们的个人隐私,存在安全隐患。垃圾邮件可分为2类:文本垃圾邮件和图像垃圾邮件。把含有不良信息的图像嵌入邮件中称为图像垃圾邮件。图像垃圾邮件带来的危害更为严重。因为图像与文字相比,占据了更大的存储空间和网络带宽,而且图像中可能含有更多的不良信息[3 - 6]。所以,图像垃圾邮件更加严重危害了网络安全,反图像垃圾邮件的研究具有更深远的社会意义。
国外的垃圾图像多为肖像、商标商务、卡通动漫、游戏、暴恐和政治等画面,而国内的垃圾图像以广告、宣传和诈骗为主,且图像多使用醒目的颜色。这2类图像都是由电脑软件生成,但图像的颜色、纹理和形状特征差别较大。图像特征是分类的初始依据,目前多数文献采用国外20年前的标准图像垃圾邮件样本库Spambase为数据源进行实验[7 - 11],问题一是不适应当前垃圾邮件图像的变化,二是使国内的图像垃圾邮件过滤针对性不强,削弱了过滤性能。同时,由于目前图像垃圾邮件过滤的误报率仍然较高,准确率和召回率仍有待提高[12 - 14],所以对于图像垃圾邮件过滤技术的改进研究有着极其重要的意义。
图像垃圾邮件过滤的本质是对垃圾图像和正常图像的识别分类。本文针对图像垃圾邮件的图像分类问题进行研究,利用适合于图像分类的色调/饱和度/亮度HSV(Hue,Saturation,Value)颜色直方图特征、颜色矩特征、纹理特征和形状特征;采用K近邻算法K-NN(K-Nearest Neighbor)等个体分类算法和集成学习(Integrated Learning)算法[15 - 17],对图像垃圾邮件的图像分类进行讨论;通过实验选择最佳的特征,改进图像的分类方法,并对参数结构进行优化和确定;最终针对国内的垃圾邮件图像集得到了较高的准确率和召回率,降低了误判率。
2 图像特征
2.1 HSV颜色直方图特征
(1)HSV颜色空间。
HSV颜色空间也称为HSV颜色空间模型,该模型从3个角度对图像的颜色进行统计。H表示色调,取值为[0°,360°],由暖色调逐渐转向冷色调,再逐渐转变回来。S表示光的饱和度,取值为[0.0,1.0],表示在光谱中接近程度的大小。V表示图像中的明度,即颜色的明亮程度,取值也为[0.0,1.0]。HSV颜色模型如图1所示。
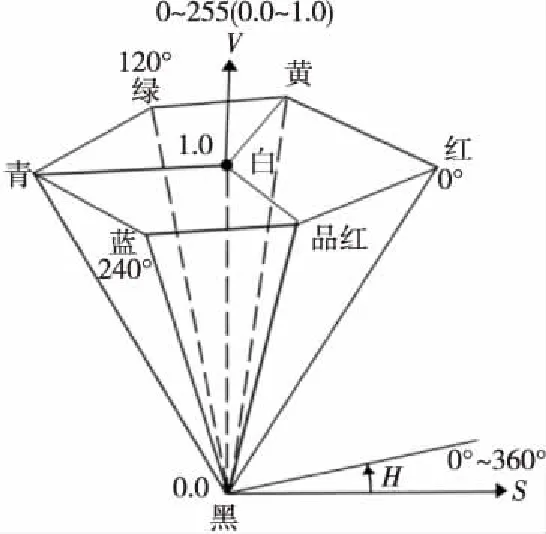
Figure 1 HSV color space model图1 HSV颜色空间模型
在图1中,利用圆锥底面圆的半径所在的直线S来表示某一种颜色的饱和程度。由图1可以看出,直线越靠近圆锥表面,颜色混入的白光就越少。通过底面圆心的垂线表示V值,由图可见,越接近底面圆的颜色越明亮。
任何一种颜色都可以看作是由光谱中的颜色与白光混合得到的,白光混合得越多,颜色与原光谱的差异也就越大,颜色饱和度越小。如果不混入白光,S值可以达到最高。值得一提的是,在S值为0时,只有灰色,不混杂任何其他颜色。
HSV颜色空间模型中,在考虑光源的V值时,例如电灯这类物体,认为该物体的明度与其原有光的亮度有关。如果考虑的是其他不会发光物体的明度,那么V值与物体表面的粗糙程度和对光源的吸收能力有关,但是该值与光的强度并没有直接关系。
(2)HSV颜色直方图。
HSV颜色空间模型对图像中颜色的不同方面进行了统计,但一般不直接选择HSV颜色空间模型的原始值使用。这是因为原始值维度较高,要从3个维度对颜色信息进行说明。再者,即使颜色实际上很接近,颜色模型利用具体的数值进行表示时也会存在差异,所以本文利用颜色直方图来表示颜色信息。
颜色直方图在图像处理中得到了极为广泛的应用。颜色直方图可以描述不同的颜色值在某一幅图像中颜色信息的比例,但是它无法对图像中的具体事物进行描述。颜色直方图不仅可以建立HSV颜色空间,也可以建立其它几种颜色空间。其中基于LUV(Luminosity表示明度,U,V表示色度)空间和LAB(Luminosity表示明度,A,B为2个色彩通道)空间以及HSV空间的颜色直方图更符合人们对颜色的直观感受,由此建立颜色直方图也就更有意义,而HSV是这几种空间中最常用的。对于RGB(Red,Green,Blue,红色,绿色,蓝色)颜色空间,同样可以对其建立颜色直方图,该颜色空间也是较为常用的。本文研究的大部分图像都是用RGB的3个颜色通道来表示的,但是该颜色空间与人的主观判断并不相符,而且现在已有多种从RGB颜色空间转换到其他颜色空间的转换方法,所以可以直接使用更符合人们直观感受的颜色空间进行图像处理。
在由颜色空间生成颜色直方图时,需要对颜色空间进行划分,得到若干个子区间作为直方图的bin,bin是直方图中的一个竖条区域,用这种方法对颜色空间上的数值进行量化。通过对每一个bin中包含颜色的像素个数进行统计,得到颜色直方图。虽然对直方图进行量化的方式有多种,但是其中最为常见的还是直接对各个通道的数值进行等分。在建立颜色直方图时,其中最为重要的,也是唯一需要讨论的参数值就是bin的个数。选择合适的直方图的个数与具体的应用有关,需要结合实验来讨论。一般来说,直方图分得的bin越多,统计就越精确,但是如果bin少的话,可以使统计计算较为方便,同时,如果与其他的特征进行结合使用,也要考虑到数据之间的干扰情况。
(3)HSV应用领域。
HSV颜色空间模型是一种极为符合人们直观判断的颜色空间模型,在图像编辑工具中得到了广泛的应用。但是,又因为该模型与光照强度之间没有直接关系,所以在需要进行光强运算或者在某些光照模型应用时不会选取HSV颜色空间模型。由HSV颜色模型建立的直方图特别适用于难以分割或难以对图像中的事物进行识别的图像处理。对于垃圾邮件中的图像来说,广告类信息中混杂了大量的商品或是价格标签,如果对图像中的具体事物加以识别会浪费大量的时间和存储空间。但是,多数广告类信息会用较多的色彩或较鲜艳的颜色来引起人们的关注,所以在进行基于图像内容的垃圾邮件过滤中使用HSV颜色直方图是十分必要的。
(4)HSV颜色直方图特征提取。
初始获得的邮件图像一般为RGB真彩色图像,首先将图像读入为RGB真彩色图像,再利用Matlab中封装好的RGB颜色空间到HSV颜色空间的转换函数,对已经读到的颜色信息进行转换,得到图像的HSV颜色特征信息。然后进行颜色直方图的转化,转化过程如图2所示。在HSV颜色特征中只选用H通道和S通道来进行描述,V通道描述的是图像的明度情况,在进行垃圾邮件过滤时,不论是常规邮件图像还是垃圾邮件图像,每幅图像的明度都可能不同。在建立直方图时,实验不选用图像的明度信息,即V通道的值,只选取H通道和S通道进行信息统计。

Figure 2 Flow chart of color feature conversion to color histogram图2 颜色特征转换为颜色直方图流程图
对于H通道和S通道需要进行不同等级的划分,这种分级划分相当于对H与S通道建立给定区间范围的直方图。得到分级表示的颜色直方图后,对2个通道的直方图进行合并,最终得到归一化的N维颜色直方图表示。
因为H通道是用角度值来进行统计的,所以其值为[0°,360°]。将其区间划分为均等的16个子区间,即16个bin,并对落入每个区间上的H通道的像素个数进行统计。又因为S通道是利用比率值进行表示的,所以其取值为[0.0,1.0],也对S通道值在该范围内进行划分,划分为4个均等的区间,并对落在每个区间上的像素个数进行统计,至此,HSV颜色直方图训练完毕。按照不同的bin的划分可以得到不同维度的通道直方图,再按照对应的维度进行合并,可以得到不同维度的HSV颜色直方图。通过对不同维度的直方图特征进行实验,来确定在垃圾邮件过滤中图像分类的最佳直方图维度。
2.2 颜色矩特征
(1) 颜色矩特征表示。
颜色矩的根本思想是利用矩阵来表示图像中各种尺度、类型的颜色分布。根据实验以及理论推导,最终得出的结论就是绝大多数的颜色分布都集中在阶数非常低的几阶之中。这些结论都得到了数学的证明,因此在大多数的颜色矩的应用场景中,使用颜色矩时只需要计算图像颜色分布的一阶矩(也就是图像像素的平均值信息)、颜色分布的二阶矩(也就是图像像素的方差信息)以及颜色分布的三阶矩(也就是图像像素的偏斜度信息),就能够很好地表示出图像的多个角度的颜色分布。
颜色矩和颜色直方图相比还有一个优势,就是颜色矩不需要像直方图那样在统计之后还要对数据进行向量化。利用颜色矩表达图像信息只需要计算9个分量即可,这在HSV和RGB这2种颜色空间上都适用,因为这2种颜色空间都含有3个颜色分量,每个分量上只需要计算3个低阶矩。因此,颜色矩特征是一种轻量级的、计算快速的颜色分布表示特征。
(2) 颜色矩特征提取。
颜色矩特征具有运算量小、提取特征速度快等特点,本文设计了颜色矩的提取方法,并将其提取出的颜色矩特征输入K-NN分类器来测验其分类效果能否达到最优。实验对训练集和测试集的邮件图像数据都提取其三阶的颜色矩特征。在颜色结构方面,采用HSV作为基础,提取其3个通道的颜色矩特征,特征相似度的比较采用的是曼哈顿距离计算方法。图像在颜色方面的信息主要能够由低阶的颜色矩表示,因此为了高效地提取颜色矩特征,主要对邮件图像的一阶、二阶和三阶颜色矩进行计算,这三阶颜色矩分别代表了图像的均值、方差和斜度,可以有效地表示图像中的颜色分布。实验中提取颜色矩特征主要有如下3个步骤:首先将邮件图像由RGB颜色空间转换到HSV颜色空间,并对HSV颜色空间的图像数据进行计算,求出其均值、方差和斜度;然后对求出的3类矩信息进行归一化处理;归一化后将数据拼接成一维的向量。
2.3 纹理特征
(1) 纹理特征表示。
纹理特征是一种图像中的视觉特征,该特征体现了图像中物体表面的组织结构,也能给人带来直观的物体粗糙度的感受。纹理特征具备3大标志性特征:(1)存在某种不断重复的局部性序列;(2)该序列是一种非随机的排列;(3)具备纹理的部分大多是均匀的。与颜色特征不同的是,对于某一像素的纹理特征是根据该像素与其相邻区域的灰度情况进行表示的,这说明纹理信息可以表示局部性信息,而局部纹理信息在全局的重复构成了全局的纹理信息。
纹理特征的表示方法较多,例如基于局部统计特性的特征、基于随机场模型的特征、基于空间频率的特征和基于灰度共生矩阵的特征等,其中最为常见的是基于灰度共生矩阵的特征。
灰度共生矩阵纹理特征是利用概率统计方法对图像上的纹理进行二阶数据统计得到的。灰度共生矩阵纹理特征对像素灰度的空间情况进行描述,对相隔n个单元像素的每一像素的几种灰度值出现的概率进行统计。这种纹理特征具备较高的时间复杂性,但是通过研究人员的不断改进,已经可以通过熵、能量等共计8维信息,对一幅图像中的纹理特征进行描述。本文选用的就是这种改进了的灰度共生矩阵纹理特征。如图3所示,图3a为原图,图3b为不同尺度下的原图,图3c为不同灰度级下提取出的纹理特征。由图3可知,纹理特征可以直观地描述人们对图像的粗糙程度的感受,并且可以对同一图像、不同尺度下的纹理情况进行区分。

Figure 3 Texture feature example图3 纹理特征示例
灰度共生矩阵纹理特征需要在图像方向上进行定义,并对像素的灰度级进行预划分,利用矩阵来对2种不同的灰度级出现在一个像素和相隔的另一个像素上的概率进行统计,得到的矩阵被称作为共生矩阵。该矩阵可以用以描述不同灰度之间的依赖关系,体现了灰度在空间上的分布特性[18]。
(2) 纹理特征提取。
本文选取基于灰度共生矩阵的纹理特征作为图像垃圾邮件过滤中图像分类的第2种图像特征。该特征的提取流程如图4所示。
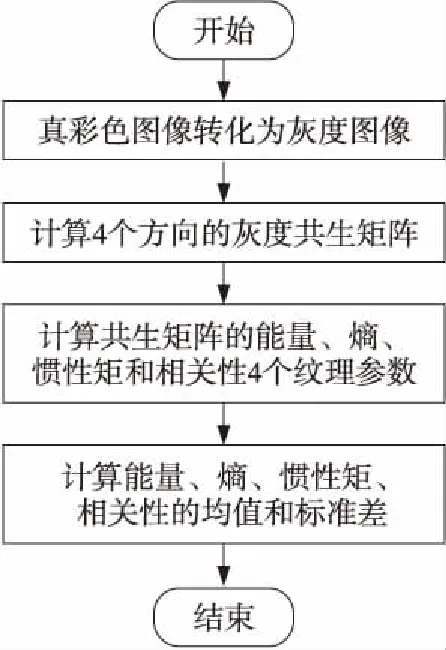
Figure 4 Flow chart of texture feature extraction图4 纹理特征提取流程图
实验选用了颜色直方图来描述图像中的颜色信息,但在对图像的纹理信息进行描述时,不需要考虑图像上的颜色信息,所以在进行纹理特征的处理之前,要先将真彩色图像转化为灰度图像。这时将真彩色图像看作是利用RGB颜色空间进行描述的,将原本的256级颜色通道划分变化为16级。
灰度共生矩阵是在4个方向上建立的,这4个方向分别是图像的水平方向、垂直方向、对角线方向和反对角线方向,相应的方向用角度表示为0°,45°,90°和135°。利用以上4个方向可以构造出基于灰度共生矩阵的特征向量。特征矩阵中的一列存储的是一幅图像的信息,而图像的特征向量是由每幅图像的4个共生矩阵计算出来的。
由于纹理特征是利用欧氏距离来进行相似度比较的,所以可以利用K-NN分类器来将纹理特征进行分类。在K-NN分类器中对特征的每一维进行欧氏距离计算。2个特征之间的欧氏距离如果在阈值内,则认为这2个特征是一类特征。所以,利用纹理特征在K-NN分类器中进行训练时,也需要对邻域的阈值进行讨论。
在使用纹理特征时,实验选用基于共生矩阵的纹理特征。因为图像中的颜色信息已经使用HSV颜色直方图进行了全面的描述,而且纹理特征描述的是图像的粗糙程度,所以不需要从彩色图像中提取纹理特征,因此要将真彩色图像转为灰度图像。不仅如此,因为纹理特征是一种在图像全局进行计算的特征,使用原始图像大小进行计算时,具有相当大的时间复杂度,所以需要对灰度图像进行压缩。图像灰度值为[0,255],采用类似于建立颜色直方图的方法,将该区间的值等分为16级,可重新表示灰度图像。之后,在压缩后的灰度图像上计算灰度共生矩阵。灰度共生矩阵能从方向、距离间隔等角度反映出图像的灰度信息,计算如式(1)所示。
P(i,j)=size{(x1,x2∈[1,M]),(y1,y2∈
[1,N])|Gray(x1,y1)=i,
Gray(x2,y2)=j}
(1)
其中,灰度图像Gray一行的像素个数为M,一列的像素个数为N;x1、x2、y1、y2分别为像素的坐标值,i,j对应像素点的灰度值。对应方向角取0°,45°,90°,135°时可分别得到4个灰度共生矩阵。
依照式(1),如果设定了4个方向,并将间隔距离设为1,即可求得4个灰度共生矩阵。实验在求得共生矩阵后,又对4个共生矩阵分别进行了归一化处理。
利用归一化之后的共生矩阵,求得其对应的能量、熵、惯性矩和相关性数值,最后计算以上4个量的平均值和标准差,共计8维数据来表示图像的纹理特征。
2.4 形状特征
(1) 形状特征表示。
图像中的形状主要有2种组成形式,第1种是针对图像特定目标的整体轮廓的特征,这种形状特征主要考虑的是形状的几何特性、边缘信息等;第2种形状特征是图像的区域特征,区域特征主要表现的是图像特定目标的整个区域之内的信息。这2种特征的关注点不同,因此在某种程度上也可以联合这2方面的信息来更全面地表示图像中的形状特征。形状特征表示方法主要有边界特征法、傅里叶形状描述符法、几何参数法和形状不变矩法。
(2) 形状特征提取。
形状不变矩与颜色矩有相似之处,是通过计算描述形状分布的矩阵来实现形状特征的表示。由于不变矩是一种浓缩的图像特征,具有平移、灰度、尺度和旋转不变性,所以矩和矩函数可应用于图像的模式识别、图像分类、目标识别和场景分析中。
实验采用HU不变矩来表示邮件图像的形状信息。一幅灰度图像可以用二维灰度密度函数f(x,y)来表示,则一幅M×N的邮件图像f(x,y)的p+q阶几何矩mpq和中心矩μpq如式(2)和式(3)所示:
(2)
(3)

(4)
最后根据二阶与三阶归一化后的中心矩构造HU的7个不变矩如式(5)~式(11)所示:
I1=z20+z02
(5)
(6)

(7)
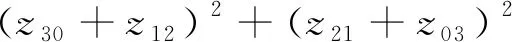
(8)


(9)
4z11(z30+z12)(z21+z03)
(10)
(11)
根据以上公式可编程求出每个图像的7个不变矩,并将其直接拼接为一维向量后就得到了实验中应用的图像形状特征。
3 K-NN分类器及集成学习过滤器模型设计
3.1 K-NN分类器设计
本文使用的K-NN算法是基于粗糙集属性约简的。其主要原理和传统K-NN并没有很大的不同,但是由于图像的特征维度较高,需要去除冗余无用的属性维度,因此引入了粗糙集属性约简算法。K-NN算法是数据处理中十分常见的算法,该算法实现简单、计算效率较高,但是在数据量较大或样本的属性较多时,该算法的效率就会受到极大的影响,计算的时间复杂性会大幅上升。所以,将粗糙集方法与K-NN算法相结合,在保证粗糙集方法的约简性能的情况下,利用K-NN算法对样本集进行分类不失为一种高效的方法[19,20],如图5所示。

Figure 5 Flow chart of K-NN classification algorithm based on rough set图5 基于粗糙集的K-NN分类算法流程图
对于输入算法的特征,首先要进行基于粗糙集方法的属性约简。本文采用的图像特征,其中一种为HSV颜色直方图,该特征根据分级设定的不同可以有多种不同的维度,但是其维度依然较高,如果逐个维度进行计算会浪费大量的时间,且很多属性值可能是冗余的,没有必要进行计算,属性约简是一个十分重要的步骤。
将通过邮箱收集到的图像邮件中的图像进行人工标记分类,分为垃圾邮件图像和常规邮件图像,并利用这2类图像得到测试样本集和训练样本集。具体的步骤如下所示:
(1)对从图像中提取的特征进行属性约简;
(2)根据样本标记值以及样本预测值的异同来计算分类器准确率和召回率;
(3)通过设置不同的粗糙集属性约简方法和分类器内部参数来改变实验结果;
(4)重复步骤(3),最终确定最佳的图像特征属性约简方案和K-NN分类参数。
3.2 集成学习过滤器模型设计
在图像垃圾邮件过滤的研究中,由于国外和国内的垃圾邮件发送者的目的不同,垃圾图像的内容和特征就不同,图像特征数据是图像分类判别的初始条件,特征数据不同致使图像分类的效果不一致。文献中大都采用国外学者收集的具有一定规模的垃圾图像数据集作为实验验证的基础数据,这些数据缺乏有效的实时更新,且在进行垃圾图像过滤时采用的分类算法单一。而我国国内的大部分垃圾邮件图像为商业广告类图像,这与原有的图像数据集不相匹配,那么用国外的图像数据集训练分类器,来测试国内的垃圾邮件图像,过滤效果必然不佳,且过滤的方法有待改进,过滤的综合性能仍有待提高。在二元分类问题上,虽然一些个体分类器也具有一定的过滤效果,但过滤的准确率和召回率很难同时提高,且误报率仍然较高。
本文在建立国内垃圾邮件图像数据库的基础上,改进了图像垃圾邮件过滤的框架结构,将多种性能较好的个体分类器取长补短进行结合,通过集成学习算法形成一个强分类器来优化图像垃圾邮件过滤的性能。具体过滤器框架结构如图6所示。
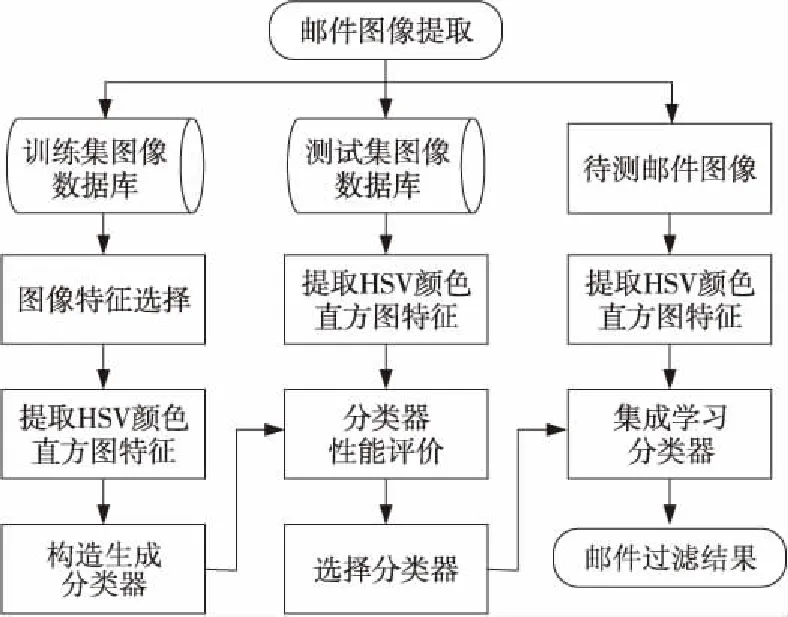
Figure 6 Framework of integrated learning filter图6 基于集成学习的过滤器框架结构图
基于集成学习的过滤器首先从训练集图像中提取不同的图像特征进行优选,选择最适合国内邮件图像集分类的HSV颜色直方图特征作为输入各种分类器的数据集参数,在构造生成的各种个体分类器中进行训练,训练好的分类器再通过测试集图像的HSV颜色直方图特征数据进行测试,并评价各个分类器的性能优劣。然后选择较好的个体分类器结合构成集成学习分类器来进一步提升和优化分类性能,最终对待测邮件图像的类型做出更加准确的判定,得到图像垃圾邮件的过滤结果。
为优化过滤性能,本文提出将K-NN、Naive Bayes和支持向量机SVM(Support Vector Machine)3种基分类器基于串行迭代提升的方法,改变基分类器分错样本的概率分布构成新训练集,即提高前一轮个体分类器错误分类的样本权重,降低正确分类的样本权重,使得错误分类的样本受到更多关注,从而在下一轮学习中可以正确分类,最终训练一个更强的学习器。对于迭代得到的一系列个体分类器,再调整相应的权值合并个体学习模型,构造一个强大的集成学习模型,即采用加权多数表决的方法,加大分类误差率小的个体分类器的权值,减小分类误差率大的个体分类器的权值,从而调整他们在表决中的作用。由于垃圾邮件过滤属于二元分类问题,所以可以采用AdaBoost算法来实现[15],具体算法流程如下所示:
二元分类数据集如式(12)所示:
T={(x1,y1),(x2,y2),…,(xN,yN)}
(12)
其中,(x1,x2,…,xN)为图像特征向量,yi∈Y={-1,1}。
将数据集T输入个体学习分类器,最终输出强分类器G(x),x∈X=(x1,x2,…,xN)。
(1)训练数据的权值分布初始化,如式(13)所示:
D1=(w1,1,w1,2,…,w1,N)
(13)
其中,w1,i=1/N;i=1,2,…,N。
(2)k=1,2,…,M(个体分类器个数M=3):
①用具有权值分布Dk的训练数据集学习,得到基本分类器,如式(14)所示:
Gk(x):X→{-1,1}
(14)
②计算Gk(x)在训练数据集上的分类误差率,如式(15)所示:
(15)
其中,P(Gk(xi)≠yi)是满足条件的概率,I(Gk(xi)≠yi)是满足条件的信息量。
③计算Gk(x)的权重系数,如式(16)所示:
(16)
④更新训练数据集的权值分布,如式(17)所示:
Dk+1=(wk+1,1,wk+1,2,…,wk+1,N)
(17)
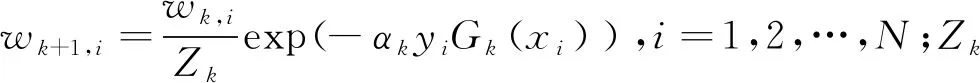
(18)
使Dk+1成为一个概率分布。
(3)构建基本分类器的线性组合,如式(19)所示:
(19)
(4)得到最终强分类器,如式(20)所示:
(20)

4 实验结果分析
4.1 不同特征作用于K-NN分类器的比较分析
本文通过收集得到的常规邮件图像1 120幅和垃圾邮件图像1 518幅,进行了基于粗糙集K-NN的垃圾邮件图像分类算法的实验,实验采用随机抽取的办法将数据分为训练集和测试集,训练集和测试集的数据比例为3∶1。在本文改进的K-NN分类器K值取3,5,7,9时分别测试不同维度下的HSV颜色直方图特征、颜色矩特征、纹理特征和形状特征的分类性能。分类指标为垃圾邮件图像分类的准确率、召回率、误判率和综合平衡指标F值。
准确率评价指标如式(21)所示:
(21)
其中,P是准确率(Precision),反映了过滤系统找对垃圾邮件的能力;Ts表示被正确分类的垃圾邮件图像数目;Fn表示非垃圾邮件图像被误判为垃圾邮件图像的数目。
召回率评价指标如式(22)所示:
(22)
其中,R是召回率(Recall),反映了过滤系统发现垃圾邮件的能力;Ts表示被正确分类的垃圾邮件图像数目;Fs表示垃圾邮件图像被误判为非垃圾邮件图像的数目。
误判率评价指标如式(23)所示:
(23)
其中,FR是误判率(Failure Rate),表示将非垃圾邮件图像判定为垃圾邮件图像的概率;Ts表示被正确分类的垃圾邮件图像数目;Fn表示非垃圾邮件图像被误判为垃圾邮件图像的数目。
F值评价指标如式(24)所示。
(24)
其中,F值是准确率与召回率之间的一个综合平衡指标,它反映垃圾邮件过滤的综合效果;β是平衡因子。
在测试集上进行实验验证,对不同维度HSV颜色直方图特征、颜色矩特征、纹理特征和形状特征作用于本文改进的K-NN分类器的分类准确率结果如表1所示。
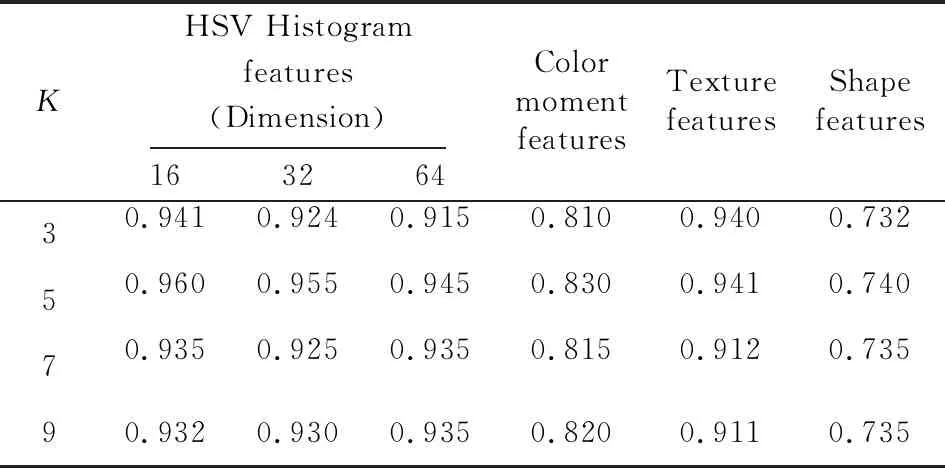
Table 1 Precision comparison of different features表1 不同特征准确率的实验结果比较
准确率是算法判定的垃圾邮件图像样本数与经检测的图像实际为垃圾邮件图像的样本数的比例,是对垃圾邮件图像是否检测正确进行的评判,这一指标反映了垃圾邮件过滤时图像分类算法的正确程度。
同样在测试集上进行实验验证,对不同维度HSV颜色直方图特征、颜色矩特征、纹理特征和形状特征作用于本文改进的K-NN分类器的分类召回率结果如表2所示。

Table 2 Recall comparison of different features表2 不同特征召回率的实验结果比较
召回率是实际检测出的垃圾邮件图像样本数与所有垃圾邮件图像样本数的比例。这一评价指标极为直观地反映了垃圾邮件过滤时图像分类算法的查全能力。
准确率和召回率能够很好地说明算法的性能。从表1和表2可以看出,以上4种不同特征的K值实验,在K值变化时分类准确率和召回率的变化趋势大致相同,取K=5时的分类准确率和召回率最佳。再从不同维度HSV直方图特征、颜色矩特征、纹理特征和形状特征的分类准确率和召回率数据可看出,分类效果最好的是选择HSV颜色直方图特征,其次是纹理特征,再次是颜色矩特征,最差的是形状特征,且选择HSV颜色直方图维度为16维时分类准确率和召回率最高。由此可以确定采用16维的HSV颜色直方图特征,在本文改进的K-NN算法的K值取5时,垃圾邮件图像的分类识别效果最好。
4.2 HSV颜色直方图特征在不同分类算法中的比较分析
从表1和表2实验结果可看出,K-NN算法确实是一个比较有效的识别垃圾邮件图像的方法,但还有一些常用的分类方法如Naive Bayes算法、SVM算法、判别分析(Discriminant Analysis)算法、随机森林(Random Forest)算法等是否会有更好的实验效果呢?
Naive Bayes算法是一种典型的监督学习方法,其基本原理是通过某对象的先验概率,利用贝叶斯公式计算出后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类[21]。
SVM利用数学模型构建出一个超平面,这个超平面能够最大程度地将2类数据分割出来,确保很低的分类错误率[22,23]。当SVM处理的数据线性可分时,即存在一个超平面能够将2类数据分割开的情况下,SVM能够找到最佳的一个超平面,经过这个超平面分割的数据能够保证每一类数据距离超平面的平均距离都是最大的。
判别分析主要是利用历史的数据进行建模,根据预测数据和历史数据模型的差别来得出预测的结果。
随机森林是从原始训练样本集中有放回地重复随机抽取定量的样本,生成新的训练样本集合,然后根据新的样本集生成多棵分类树组成随机森林。测试数据通过多棵分类树得到输出,再将输出结果进行组合投票得到最终的分类结果。
集成学习算法是集成多个不同的相互独立的学习模型来提高自身决策结果的适应能力和决策准确率的一种算法。由于能够集成多种特性各不相同的算法,因而集成学习算法有更强的适应性,可以处理更加复杂的任务。集成学习算法的核心优势在于集成,也就是如何将不同模型返回的结果集成为最优的结果。
本文在自己收集到的图像数据库上,选择不同维度的HSV颜色直方图特征,应用于以上分类算法进行实验验证,实验结果如表3所示。
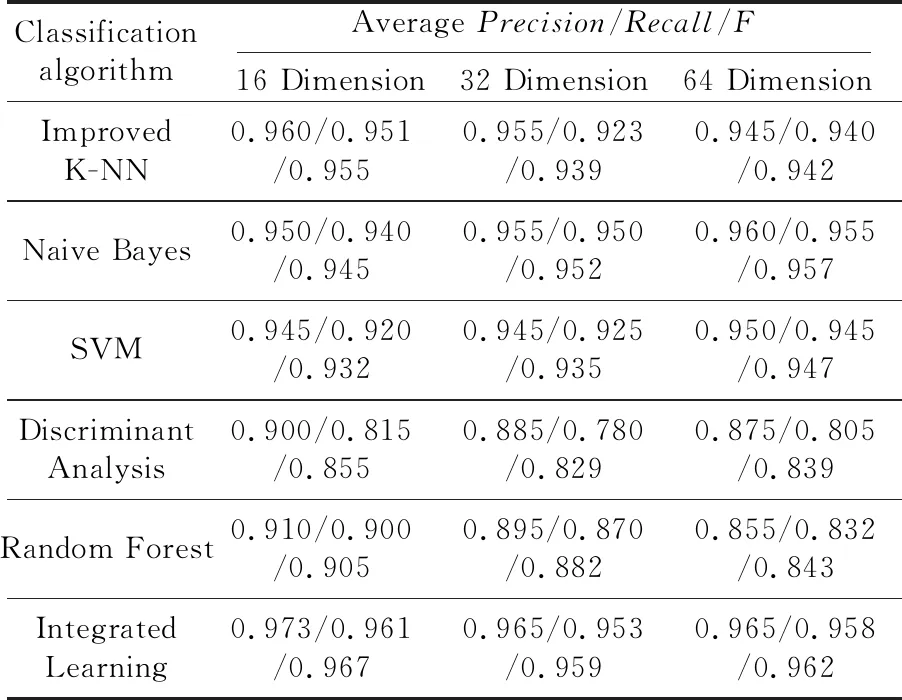
Table 3 Comparison of different dimension color histograms with different classification algorithms表3 不同维度颜色直方图特征在不同分类算法中的实验结果比较
从表3中可以看出,本文改进的K-NN算法、Naive Bayes算法和SVM算法的分类指标相近,具有近似的较好的过滤效果,而判别分析算法、随机森林算法的过滤效果相对较差。
实验表明,本文通过集成学习算法得到的强分类器G(x)的分类指标明显优于其他个体分类器,使准确率和召回率同时得到了提升,进一步提高了过滤的综合性能,因此在实际的图像垃圾邮件过滤应用中可以广泛使用。
5 结束语
本文以基于粗糙集的K-NN算法为例证,从HSV颜色直方图、颜色矩、纹理和形状特征中,优选出最有利于图像垃圾邮件过滤的图像分类特征是16维的HSV颜色直方图,并得出最佳的K值为5。本文提出了将基于粗糙集的K-NN算法、Naive Bayes算法和SVM算法的个体分类器采用AdaBoost集成学习算法结合的过滤方法,针对国内的垃圾邮件图像数据库,使图像垃圾邮件过滤的准确率和召回率同时得到了提升,分别为97.3%和96.1%,误判率降低到了2.7%,达到了更好的图像垃圾邮件过滤效果。
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
英语文摘(2021年10期)2021-11-22
潍坊学院学报(2020年2期)2021-01-18
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
计算机与网络(2020年4期)2020-04-20
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
初中生世界·八年级(2017年3期)2017-03-24
