
基于改进IPSO-BP算法的CAM编程切削参数预测*
2020-06-21 08:17:02李俊铭吴居豪龙耀武陶建华
机电工程技术 2020年5期
李俊铭,吴居豪,何 轩,龙耀武,陶建华※
(1.广州大学机械与电气工程学院,广州 510006;2.广州市德慷软件有限公司,广州 510620)
0 引言
计算机辅助制造(CAM)是指在计算机上对零件进行编程加工,生成数字控制指令(NC)使机器进行自动加工的软件系统,是机床加工不可或缺的部分。使用CAM软件进行编程加工时,除了根据模具特征编写合适的加工策略,还需依据各类机床、刀具等加工信息选用合适的切削参数[1-2]。由于制造业高级技术人才缺乏,人员流动加剧,技术水平参差不齐,影响制造企业的生产效率和产品质量[3]。近年来,对自动计算机辅助加工规划(ACAPP)的需求不断增加,加工参数预测是重要环节之一[4]。传统的参数预测通过试切实验结合专家规则进行参数推荐,时间和经济成本大,难以适应模具行业多变的加工需求。近年来,有不少研究基于支持向量机(SVM)、BP(Back Propagation)等算法通过采集机床运行过程中震动、电流及声音等信号,对加工参数实时调整[5-7]。由于硬件兼容性问题,这类方法对机床型号有严格限制,难以大范围推广。
本文采用基于历史加工数据进行参数预测的技术解决方案。收集并筛选满足企业加工要求的CAM历史项目文件,对CAM软件进行二次开发获取相关加工信息,包括选用机床、策略、刀具相关信息及对应的切削参数。用IPSO-BP算法建立并不断更新参数预测模型,实现针对不同加工信息的切削参数(轴切深、径切深、转速、进给)预测。在复杂加工编程的应用场景中,上百条刀路对应的切削参数自动由软件生成并输入CAM系统中,编程人员只需要检查数据的合理性,从而提升加工编程的效率和编程质量。
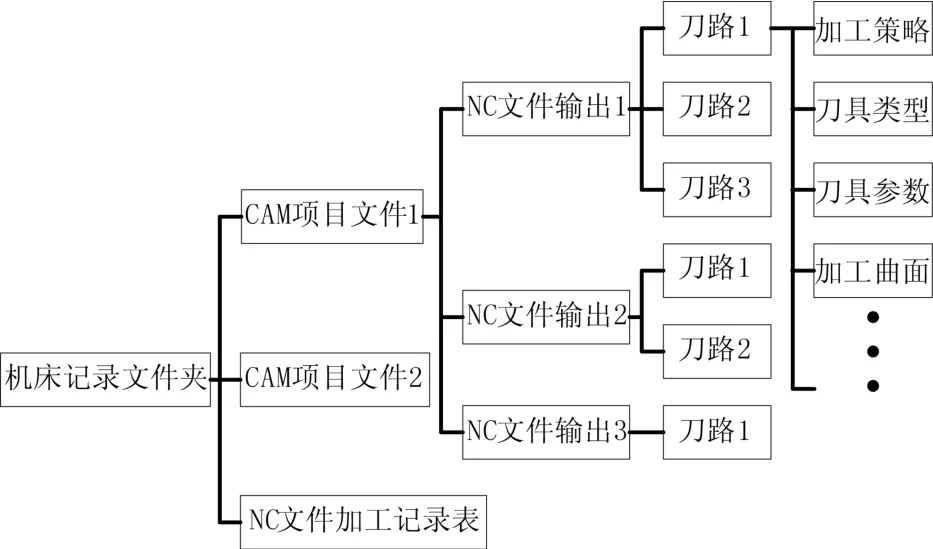
图1 CAM项目文件数据结构
1 CAM软件数据提取与处理
1.1 数据提取
为了获取加工数据信息与对应的切削参数,选用模具行业中常用的CAM软件Power MILL结合VB语言进行二次开发[8],调用CAM软件的应用程序接口(API)运行宏命令提取刀路中包含的信息。CAM项目文件的数据结构如图1所示。由图可知CAM项目文件中保存多条NC文件信息,存在不同NC包含相同刀路的情况,通过过滤重复刀路避免采集重复数据信息。当数据样本中出现切削参数不同,其他加工信息均相同时,只保留数值最大的切削参数,从而保证样本中的切削参数是可靠而且高效的。具体提取步骤如图2所示。
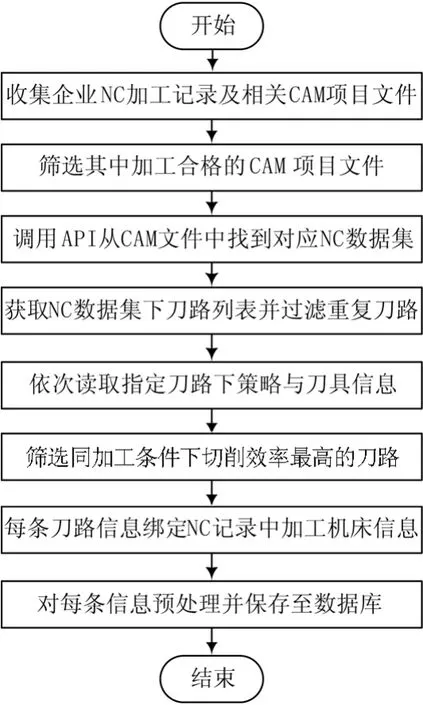
图2 CAM项目数据采集流程
1.2 信息提取及参数选择
从CAM软件中采集数据时,既要保证数据能够客观反映影响切削参数(轴切深、径切深、转速、进给)的各种条件,又要控制特征数量防止数据稀疏导致训练模型过拟合。拟合历史项目的切削参数设置需要从加工编程的角度出发。针对CAM编程特点,提出加工特征评价体系,具体分为加工类型、策略类型、机床性能、刀具类型和刀具参数5个大类影响因素[9],如图3所示。

图3 加工特征评价体系
针对评价体系中各特征的数据结构和相互联系,将特征分为离散型数据和连续型数据进行数据预处理。其中加工类型、策略类型和刀具类型均为离散型数据,使用独热编码(one-hot)对特征进行向量化分析[10]。考虑到一般企业将刀具参数作为公式进行处理,将各刀具参数作为连续型数据,分别进行归一化操作,保证数据量纲一致[11]。
2 预学习IPSO-BP网络训练模型
切削参数预测是一个多维特征的非线性拟合问题。BP具有高度的非线性和优秀的拟合能力,非常适合解决这种多维非线性问题。但由于BP网络自身缺点,提高精度会导致拟合速度下降,并更容易陷入局部最小值点[12]。IPSO粒子群算法具有很强的全局寻优能力,并且运算效率高,适合与BP网络两者优势互补。
2.1 训练BP神经网络
对于一个切削参数预测模型,输入层和输出层需要体现不同加工特征与选用切削参数的关联。输入层以加工特征评价体系为标准,将预处理后的加工类型、策略类型、机床性能、刀具类型和刀具参数5类共18维数据特征作为输入的18个神经元X=(X1,X2,…,X18);输出层以对应的轴切深、径切深、转速、进给作为输出的4个神经元Y=(Y1,Y2,Y3,Y4)。考虑到输入维数较多,中间设置两层隐含层学习特征,通过多次前向传播和后向传播的学习过程训练合适的权重ω=(ω1,ω2,…,ωN)预测切削参数。网络的模型结构如图4所示。

图4 网络模型结构
前向传播的计算过程如式(1)所示:
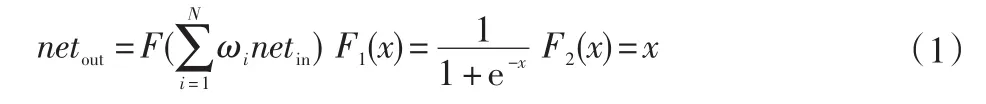
式中:netin代表网络中每个节点上一层节点的输出值;netout节点进行计算后的输出值;对隐含层1,netin=X,对于输出层,netout=Y′,代表切削参数在这次前向传播的预测值;在隐含层1、隐含层2的计算过程中F=F1(X);输出层的计算过程中F=F2(X)。
反向传播的计算过程如式(2)和式(3)所示:

式中:通过对模型预测的切削参数y′与历史数据中切削参数y2和误差E求导,获取最小的梯度方向,更新各单元间权重ω′i;lr为更新的学习率。
2.2 改进IPSO粒子群算法
为了快速找到全局权值最优值,运用IPSO粒子群算法。先初始化一定数量的BP网络权重值 ω=(ω1,ω2,…,ωn)作为粒子。将粒子输入进BP网络前向传播中计算网络权重为当前粒子的权重值时对应误差E,并依据结果寻找每个粒子的历史损失最小的权重 pbest和种群中最小的权重gbest,从而计算权重变更速度矢量并更新权重值[13]。粒子权重值更新流程如图5所示。
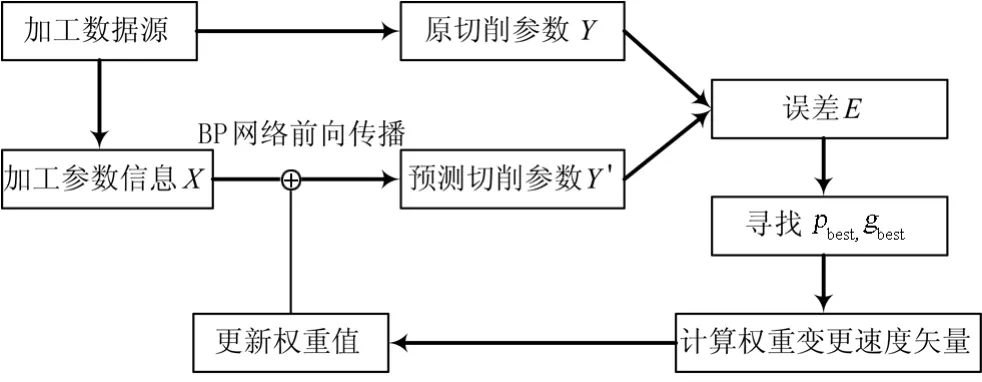
图5 粒子权重值更新流程
训练方式如下:
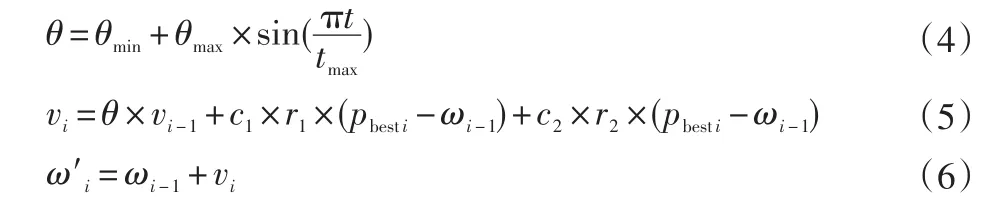
式中:vi、ωi分别为第i个粒子在迭代t+1次后的权重变化速度矢量和权重值;pbesti为迭代t次后的粒子最佳位置;gbesti为迭代t次后的种群最佳位置;θ为惯性权重;θmin为基本惯性权重;θmax为衰减惯性权重;tmax为最大迭代次数;t为当前学习次数;c1和c2为学习因子;r1和r2为0~1之间的随机数。
2.3 限制权重范围改进IPSO
由于IPSO与BP训练原理不同,IPSO训练出来的权重数值分布有较大差异。对切削参数预测模型进行更新的过程中,可能权值范围发生较大改变,部分切削参数预测准确率下降。所以在第一次训练时需要进行一次预学习探索ωIPSO合理分布范围,对IPSO的速度矢量和权重值按BP网络结构分层限制。公式如下:

式中:ni对应BP不同层之间的权重,n1对应输入层与隐含层1的权重,n2对应隐含层1与隐含层2的权重,n3对应隐含层2与输出层的权重;ωˉni为该组权重的平均值;ωnimax与ωnimin分别对应该组权重的最大最小值;vnimax与vnimin分别对应该组权重对应速度矢量的最大最小值;tmax为IPSO最大迭代次数。
权重范围的训练结果如表1和表2所示,同一数据集和超参数下不同算法损失误差变化曲线如图6所示。
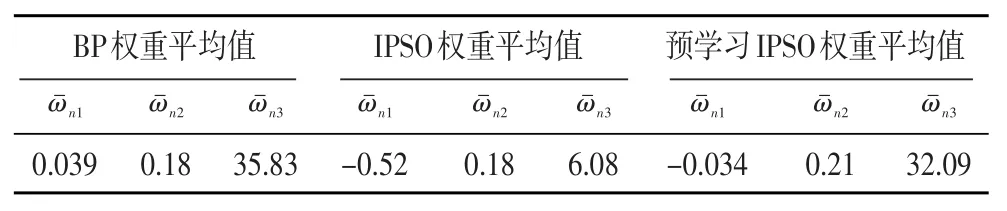
表1 权重平均值

表2 权重标准差
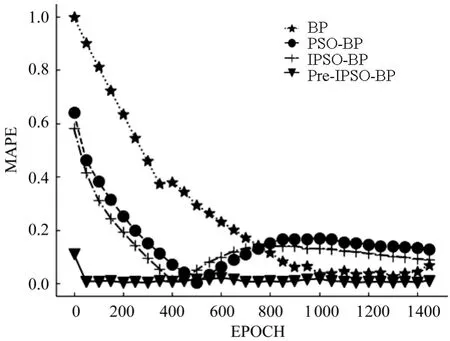
图6 训练损失误差变化曲线
从表1和表2可看出,经过预学习环节后BP网络各层权重的平均值与标准差均与单纯训练BP网络得到的结果更为接近,说明预学习能有效提高IPSO权重计算的性能。从图6对比也证明经过预学习环节后模型收敛速度大幅提高,也避免误差反弹的情况。
2.4 模型训练流程
模型训练具体训练步骤如下:
(1) 在第一次训练时,先将BP权重 ω=(ω1,ω2,…,ωN)初始化为均值为0,方差为1。对加工特征信息X=(X1,X2,…,X18)和对应切削参数Y=(Y1,Y2,Y3,Y4)分别用不同的超参数进行测试,通过减少循环次数控制学习时间。由此找到损失最小的超参数组合和各层权重的分布范围。
(2)根据权重分布情况限定粒子群算法中权重的分布范围。随机生成一定数量的权重作为粒子,依次代入BP前向传播中计算损失E。每次训练中对单个粒子历史损失最小的权重更新 pbest,对种群中最小的的权重更新gbest,并更新速度矢量和权重。

图7 预测模型训练流程图
(3)将BP的权重设为IPSO算出的最佳权重值再进行训练,只调整学习率lr,不改变隐含层节点数量。直到预测误差满足要求后保存切削参数模型。
预测模型的整体训练流程如图7所示。
3 仿真结果与分析
仿真数据集采用从收集模具企业2018年保存的CAM项目文件中提取2 000组数据。选择其中1 600组作为模型的训练数据,200组作为模型验证数据,200组作为模型测试数据。训练结果如表3所示。
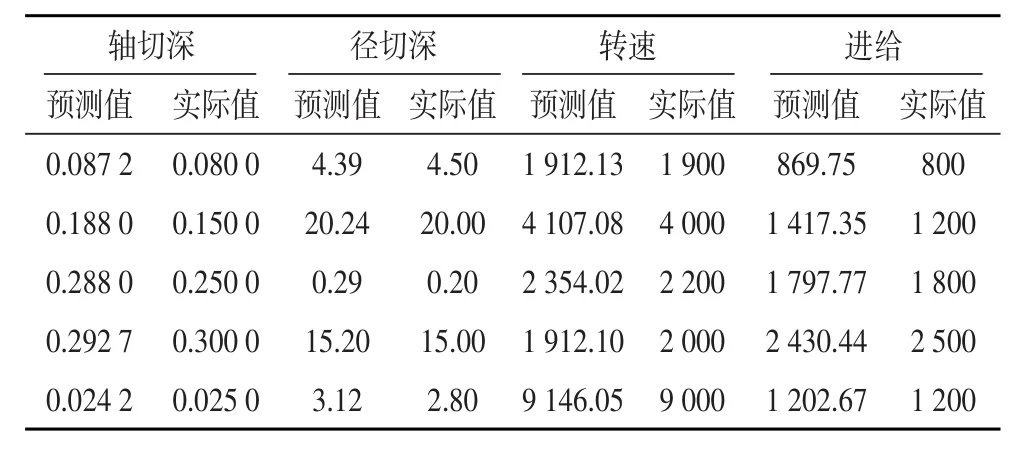
表3 预测结果表
从预测参数对比可知,各项的预测值与经验判断出来的切削参数基本一致,平均相对误差在2%~5%之间,满足加工的参数要求,可导入CAM中进行刀路编程。也有极少局部点出现较大误差,其相对误差最高在20%左右。虽然满足加工安全条件但可能影响加工质量,需要编程人员适当调整。通过采集更多的历史项目数据,可以进一步提高预测精度。
4 结束语
针对切削参数预测问题,本文提出一种基于改进IPSO-BP的切削参数预测方法。通过对CAM项目文件进行数据采集,提取历史加工特征及切削参数。利用改进IPSO算法优化BP神经网络参数,并与其他预测模型的测试结果对比,该方法可以取得更高的预测精度和稳定性。在自动计算机辅助加工规划的参数规划领域具有一定的应用价值。
猜你喜欢
我爱学·幽默大王(2025年3期)2025-02-24 00:00:00
我爱学·幽默大王(2024年11期)2024-10-10 00:00:00
我爱学·幽默大王(2024年6期)2024-06-17 00:00:00
我爱学·幽默大王(2024年7期)2024-06-17 00:00:00
当代陕西(2020年17期)2020-10-28 08:18:18
制造技术与机床(2019年11期)2019-12-04 05:50:14
人大建设(2018年5期)2018-08-16 07:09:00
制造技术与机床(2017年7期)2018-01-19 02:29:55
电信科学(2017年6期)2017-07-01 15:44:57
发明与创新(2016年5期)2016-08-21 13:42:48
