
基于改进YOLOv2算法的交通标志检测①
2020-06-20 07:32张传伟李妞妞岳向阳杨满芝丁宇鹏
计算机系统应用 2020年6期
张传伟,李妞妞,岳向阳,杨满芝,王 睿,丁宇鹏
(西安科技大学 机械工程学院,西安 710054)
随着社会生活的发展,汽车已然变成人们日常生活中重要的组成,但交通事故死亡率却一直居高不下[1,2].高级辅助驾驶的提出对降低交通堵塞,避免交通事故发生以及对无人驾驶应用都有着重要的意义.交通标志的实时识别也是无人驾驶不可缺少的一部分[3-5].因此无论对交通标志检测理论研究和实际研究都有着很高的价值.
交通标志的研究即使已经普遍进行,能否达到准确、快速检测交通标志仍然是一个值得深究的问题[6,7].对交通标志识别最早展开的研究可回归到上个世纪80年代.日本大阪大学推出一套交通标志自动识别系统[8],但对路况多样化环境下的交通标志识别准确率仍需提高.Trăsnea 等[9]采用思路简单,计算量小的模板匹配来实现交通标志的识别,但是在实际场景应用中实时识别性不强.Armingol 等[10]提出基于HIS 的红色分割方法.王洋[11]提出基于HSV 的多阀值分割方法.Gao 等[12]提出了一种在鲁棒性上较优的CIECAM97颜色空间分割方法,但不足之处是运算量大.随着无人驾驶的发展,交通标志检测的研究已经取得众多成果,但是实时性和准确性仍然有很大提升的空间,因此进行研究很有必要.
交通标志的检测需要对图像进行预处理,使得图像增强,为检测提供高质量的图像[13,14].本文先对图像采用了直方图均衡化、BM3D 预先处理的方法,再基于YOLOv2 算法,对网络顶层卷积层输出特征图划分更细,得到高细粒度的特征图来检测小尺寸的交通标志,网络结构及损失函数优化得到R-YOLOv2,并通过实验验证了R-YOLOv2 的准确性以及实时性.
1 交通标志的预处理
在具有多因素影响的自然场景下取得的交通标志,例如:不同光照条件的问题,背景复杂、遮挡、运动模糊等,为了尽可能提高检测效果.所以对图像进行预先处理来增强图像品质是非常有必要的.
(1)彩色图像的直方图均衡化
在众多的图像增强处理方法中,图像直方图均衡化是被应用最广泛的,也是效果最突出的,原因在于其简易性和高效性,很好的提高图像的亮度和清晰度[15].RGB 图像可以拆分为3 个灰度图像,彩色图像直方图均衡化即为对模型的三分量R,G,B 分别进行处理.
将原图的每个灰度等级根据灰度变换表变换成一个新的灰度等级,再将这些变换后的灰度级组合起来,即完成R 分量的均衡化图像,G 分量和B 分量的灰度化同R 分量的灰度化,将三者单独处理的结果组合成彩色图,得到彩色图像均衡后的效果图[16].如图1所示.

图1 彩色直方图均衡化
(2)图像降噪
NLM 算法采用的是inter-patchcorrelation,但Wavelet shrinkage 采用的却是intra-patch correlation[17].由于两种算法的去噪效果都不错,所以本文使用的是将两者结合起来的去噪算法BM3D.如图2所示是算法BM3D 的去噪步骤.
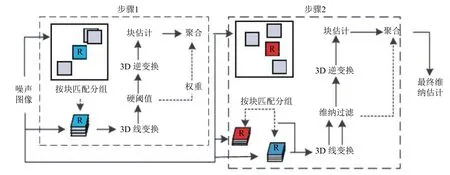
图2 BM3D 的去噪步骤
BM3D 算法主要通过2 个步骤实现图像去噪:步骤1 先在噪声图像中寻找相似块,运用硬阀值定义相似性,然后叠加成不同的块.再对不同的组块做3D 线性变换,以及变换谱的收缩,最后逆变换得到块估计.根据前面得到的补丁质量对所有块输入不同的权值,其次对其加权平均操作.聚合是利用图像的冗余性进行复原.步骤2 和步骤1 类似,不同之处有两点,步骤2 对比的是过滤后的补丁而不是原始补丁,在处理新的3D 组块时将硬阀值处理换成维纳过滤.步骤2 相比较步骤1 恢复图像细节更多,去噪性能更好.
常用去噪算法有中值滤波、均值滤波、BM3D 滤波,运用Matlab 对3 种去噪方法进行比较,去噪结果如表1所示.

表1 3 种算法信噪比
从表1的数据可以看出BM3D、均值滤波、中值滤波的信噪比提高量依次递减.其中,BM3D 滤波的信噪比提高量最大,BM3D 的滤波效果最好.BM3D 去噪效果对比如图3所示.
(3)实验验证
为了表明直方图均衡化和去噪算法对检测结果的影响,利用控制变量法对YOLOv2 和R-YOLOv2 模型进行预处理前后的对比实验,检测结果如表2所示.
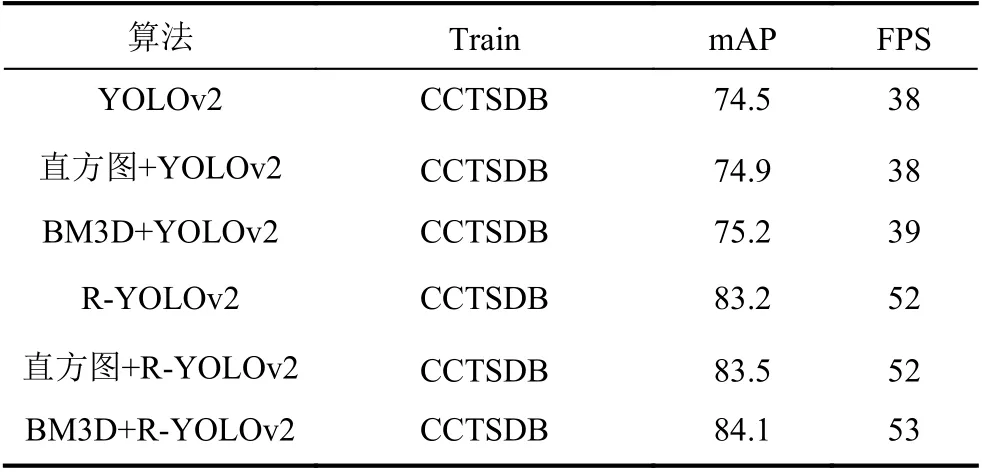
表2 去噪算法对检测效果对比
由于噪声和光照不均衡都会对图像造成影响,从上表可以看出加入直方图均衡化预处理对YOLOv2和R-YOLOv2 的mAP 分别提高0.4 和0.3,FPS 均未改变,BM3D 预处理对YOLOv2 和R-YOLOv2 的mAP 分别提高0.7 和0.9,对FPS 都提高了1,验证了加入预处理对检测算法有着一定程度的提高,因此在检测前进行预处理是很有必要.
2 交通标志的识别
交通标志识别出现频率较高的检测算法有两个大的方向(图4),即传统目标检测算法和回归的深度学习算法.对于利用候选区域来检测交通标志的准确度较高,而基于深度学习的回归法对目标检测速度更快,两者各有优势[18].
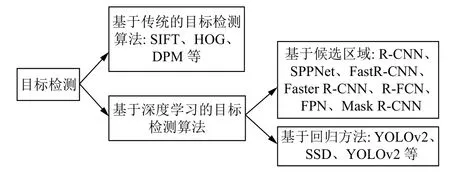
图4 目标检测算法分类
两大算法主体想法大都相同,即都是利用算法将原始图像分割成许多有关或者无关候选区域,再将特征向量提取、输入、分类.由于交通标志的实时识别是无人驾驶的核心部分,因此两者算法对比,为了达到实时性要求,基于回归的目标检测算法更具有优势.
(1)基本原理
YOLOv2 算法借鉴了R-CNN 系列算法采用候选区域搭建检测框架,把目标检测问题处理成回归问题,用网络模型实现端到端的目标检测,其网络结构如图5所示.
YOLOv2 算法模型是将输入图片划分为S×S的网格,且S为划分的网格数,目标中心的检测由所划分的每个格子来负责,所有格子所含目标的边界框(bounding boxes)、定位置信度(confidence)以及所有类别概率向量(class probability map)通过一次预测来对图像进行目标分类,结合多次训练,找到最优权值,最后得到图像的目标边框.但是YOLOv2 算法存在以下两个缺点:①在尺度上的泛化能力较差.由于网格单元是固定的正方形,对于相同种类目标显露崭新、少见的长宽关系时,标准的变化相较于推测的框线来更为敏锐.②对于小型的目标,由于实践中大型目标和小型目标的损失值存在不一样的效果,YOLOv2 的损失函数对小尺寸的检测和大尺寸的检测结合在一起计算,使得小型目标损失一部分精度,检测失败.针对这两个缺点,在此提出R-YOLOv2 模型:①在YOLOv2 浅层结构中加入多个1×1 卷积层,以进一步简化网络结构以及减少参数数量,以此增加网络的泛化能力和跨通道学习能力;②改进原网络的损失函数,采用归一化及根据各自的损失部分情况给定权重值使网络适用于小目标检测.
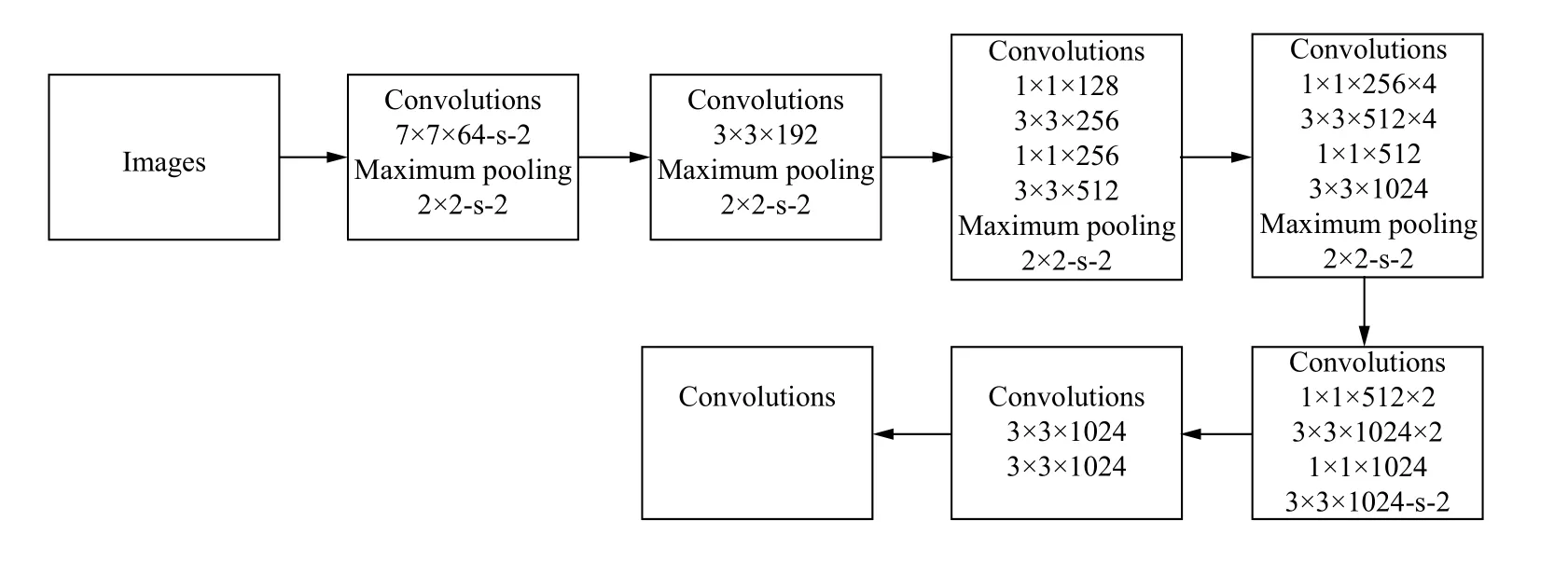
图5 YOLOv2 网络结构图
(2)网络结构
整个交通标志识别网络模型如表3所示.
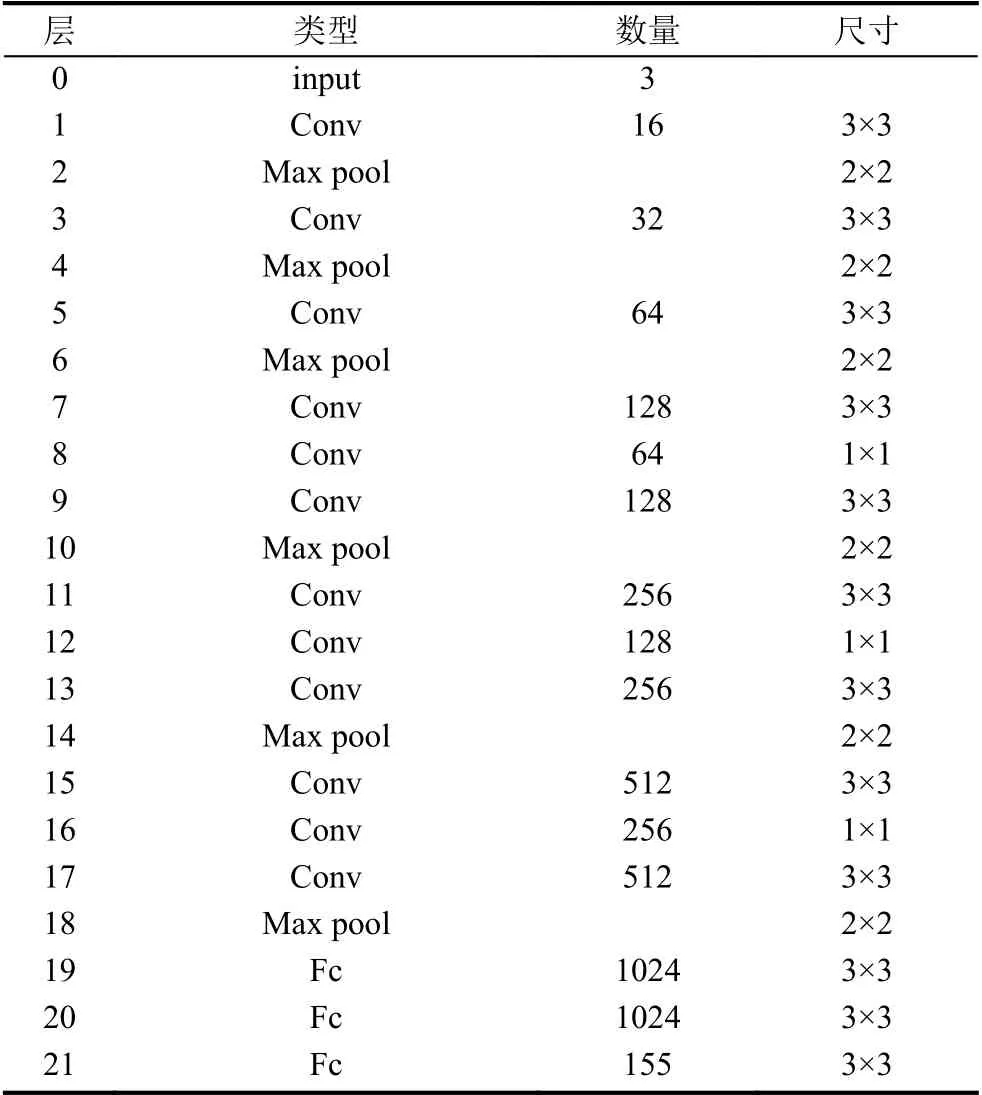
表3 交通标志识别网络模型
对R-YOLOv2 模型,该网络结构使用12 个卷积层,而相对应的卷积核尺寸采用3×3 和1×1 这两种尺寸,设计将网络顶层卷积层输出特征图划分更细,以得到高细粒度的特征图来检测小尺寸的交通标志,提高对小目标的检测率.对每个卷积层后接着池化层,1×1 的卷积层以及无量纲化层,对特征图利用无量纲化层提升网络学习新样本能力.利用3 层全连接完成交通标志的类别判定以及定位.模型中passthrough 层是把之前高解析度的特征图注入,再连结到之后的低解析度的特征图上.前面的特征图维数相当于之后的2 倍,passthrough 层挨个抽取上一层2×2 的特征图,接着将特征图维数转变成通道维数,passthrough 层的池化处理变成拆分处理,然后对此处理后的特征图做卷积预测,提高网络的精度.整个交通标志识别网络模型如表3所示.
(3)损失函数
YOLOv2 原损失函数分为3 部分,即位置损失函数计算公式:
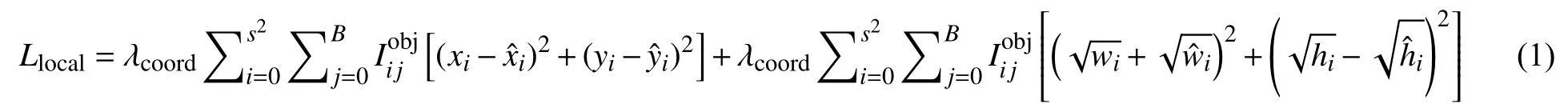
预测损失函数公式:
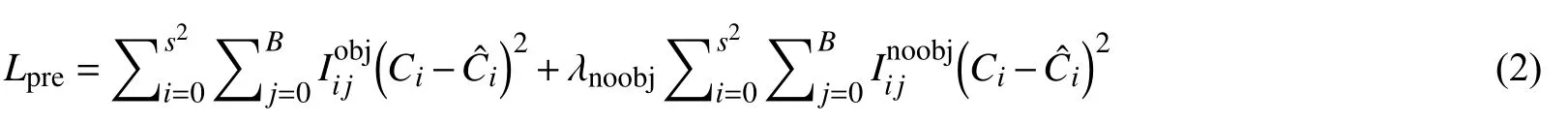
类别损失函数公式:
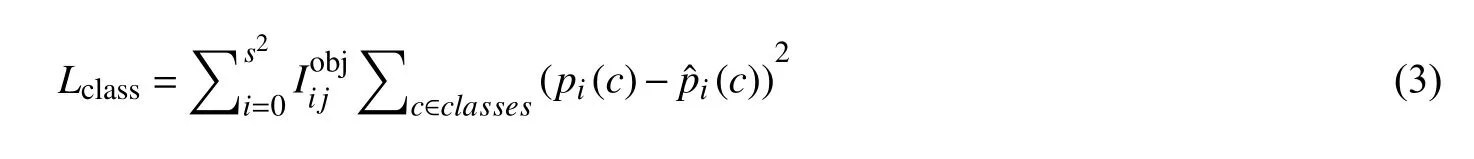
YOLOv2 的损失函数即为:
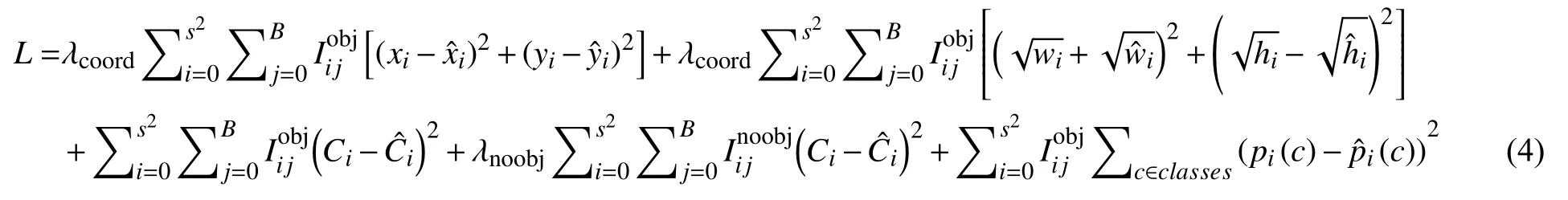
表示为第i个网格对第j个出现目标对象做出的预测,(xi,yi,wi,hi)表示目标当前位置相应的坐标,wi,hi表示边框的宽度和高度,表示预标注目标的坐标,Ci为第i个网格预先得到的目标种类,为第i个网格预标注所预先得到的目标种类,B为的单个网格预先得到的边框量,S为未定义网格个数.
但YOLOv2 损失函数有3 个问题:(1)对小目标的损失置信度相比较大目标检测容易被忽略;(2)定位损失和分类损失权重相同,而实际检测其实并不相同;(3)不包含目标对象网络对梯度更新的贡献度将远大于包含目标对象网格对梯度更新的贡献度,这会使网络训练十分不稳定.
解决这3 个问题的方法:(1)采用归一化可以提高对小比例的宽度w和高度h的关注度;(2)在目标预测时,令置信度评分的损失比例λ1为5;(3)当要检测的边框内未有目标时,则令损失比例λ2为0.5.同时,包含目标对象边框和类别预测的损失权重为1.因此改进后的损失函数如式(5)所示.

3 实验结果分析
(1)网络模型训练过程
通过带标签的数据集对模型进行多次训练从而使得网络模型具有高识别性能,此过程为网络模型的训练.实验环境硬件采用的是CPU:i7,试验平台:Tensorflow,OpenCV,Python.
对于交通标志识别迄今为止还没有开放源代码标示注明的交通标志数据集合,因此需要对其进行标示注明,方便后续的识别.结合CCTSD 数据集[19]和TT100K 数据集制作新的数据集,针对不同模型训练测试.数据集13 748 张训练集,3072 张做测试集,采用Labellmg 进行标注,生成XML 文件.XML 文件内的信息统一记录到csv 表格,从csv 表格中创建TFRecords格式.将标注好的图片作为训练样本,模型训练时每隔10 批训练样本改变输入图片大小,进行多尺度训练.
由于数据集中仅标注了3 类交通标志,因此在损失函数中类别取3.训练中设置边界框数k=5,S=19,输出19×19×40 的特征图.在训练过程中学习率初始值为0.0001,观察损失的下降率,当损失值稳定在大于1的时候将学习率改为0.001,使得网络模型的收敛速度提升.通过设定阈值t,来评定是否采用这些图像的候选框,t则是结合位置信息和类别的总置信度分数.表4所示为不同阈值t下R-YOLOv2 模型的精度和召回率,可知在阈值和精确率成正比,和召回率成反比,且在t=0.4 或0.5 时,模型性能较优.

表4 不同时间阈值下的精确度和召回率数值
采用相同网络结构除却loss 模型,且采用相同数据集对模型进行训练测试.YOLOv2 采用的原损失函数,R-YOLOv2 采用改进的损失函数,YOLOv3-tiny 模型就是在YOLOv3 的基础上去掉了一些特征层,只保留了2 个独立预测分支,且相对简化,因此采用YOLOv3-tiny 作为对比模型,其损失函数变化如图6所示.
对两个损失函数模型进行训练,初训练时前面的损失值偏大是由于刚开始训练学习到的准确率不高,随着训练次数的增加,模型的性能越来越好.如图7所示是YOLOv2、YOLOv3 和R-YOLOv2 模型训练损失函数变化曲线图,由图6可以看出对损失函数的改进使得模型性能有一定程度的提升,即R-YOLOv2 的损失函数模型优于YOLOv2,且优于YOLOv3 的损失函数.
(2)网络模型的测试
为了测试模型的准确性,使用训练好的模型对3072 张从实景中选取的图片进行识别,目标检测以研究重点不同而有多种评价指标,在此采用平均精度均值(mean Average Precision,mAP)来描述检测精度,每秒帧数(Frames Per Second,FPS)描述检测速率,统计检测的结果如表5所示,准确率的变化曲线见图7.
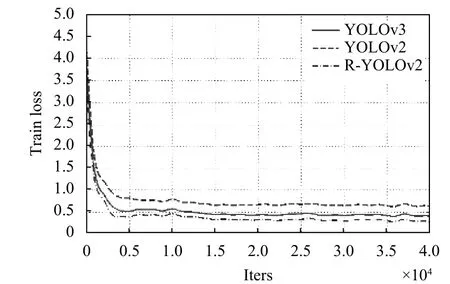
图6 模型训练损失函数对比变化曲线图
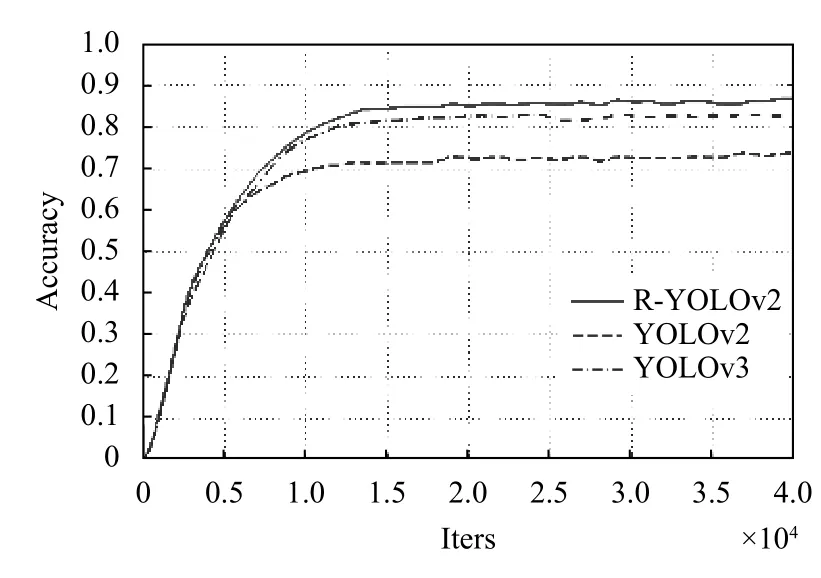
图7 准确率变化曲线图

表5 模型性能比较
由表5可以看出R-YOLOv2 模型性能优于现有算法YOLOv2,YOLOv3,且较于YOLOv2 准确率提高了8.7%.检测速率提高了15 FPS.较于YOLOv3 准确率提高了4.2%.检测速率提高了3 FPS,表明网络结构的改进对mAP 和FPS 有着提升.
由于刚开始学习率低,图7可以看出改进后的模型R-YOLOv2 较YOLOv2 在初始准确率都不高,且基本一致,在迭代值达到6000 时,R-YOLOv2 与YOLOv2差距出现,达到15 000 次时两者的准确率变换趋于平缓.在改进后的网络模型R-YOLOv2 较于YOLOv2,YOLOv3 的准确率有一定程度的提高,验证了网络结构的改进对准确率的提升.
如图8所示是部分图像检测结果,图8(a)、8(c)两图是采用原始模型检测的结果图,图8(b)、8(d)两图是采用改进后的模型检测的结果图.结果表明由于RYOLOv2 将网络顶层卷积层输出特征图划分更细,损失函数加入归一化和权值的改变,且使用高细粒度的特征图来检测小尺寸的交通标志,因此较于YOLOv2模型,R-YOLOv2 模型对小目标的检测更优.

图8 部分图像测试结果
为更好的分析测试结果,设定阈值t=0.5,以保证较高的准确精度.如表6所示即为3 种方法的分类结果对比,时间为检测单张图片时间的均值.
从表6和可以看出得到的指示标志和警告标志的召回率最好,达到了75.23%和83.41%,且可以看出改进的模型R-YOLOv2 比YOLOv2 和YOLOv3 都检测速率都快,YOLOv2 模型识别每张图片需0.161 s;YOLOv3 模型识别每张图片需0.041 s,而R-YOLOv2模型识别每张图片仅需0.016 s,上述结果显示在网络结构中加入1×1×64 卷积层,以及简化网络结构以及减少参数数量,使得网络的泛化能力和检测速率都有所提升.
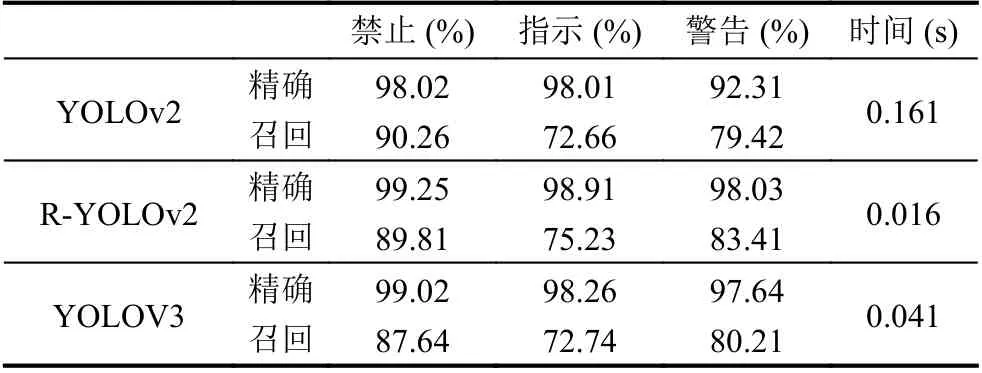
表6 3 种方法分类结果比较
为了进一步具体的表明3 种模型的性能,进行精准率(P)和召回率(R)曲线图绘制来对实验结果进一步评价,因此3 个超类别的P-R 曲线如图9所示.
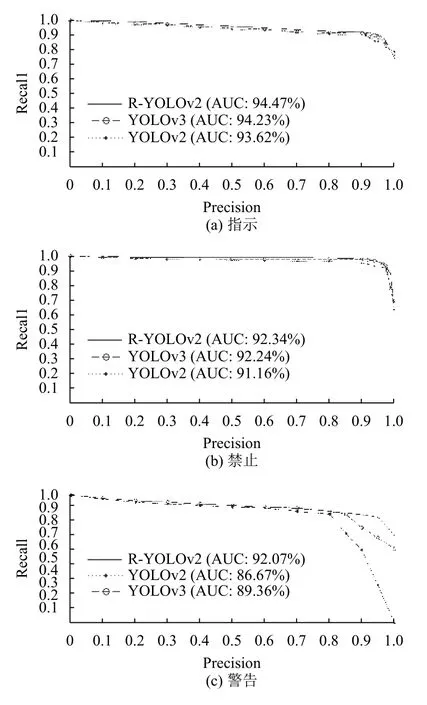
图9 3 个超分类P-R 曲线图
AUC 值表明的是线下面积值,从图9可以看出RYOLOv2 模型较于YOLOv2 模型和YOLOv3 模型在指示、禁止、警告中的AUC 值最大,表明R-YOLOv2模型的性能比YOLOv2 模型和YOLOv3 模型更稳定.
从以上结果分析验证了对模型的改进有效提升了模型检测的准确率和速率.
4 结论
本文先对目标采用了直方图均衡化、BM3D 等一系列预处理,再改进了YOLOv2 模型以及其损失函数,提高了模型的检测性能,主要是对网络顶层卷积层输出特征图划分更细,利用高细粒度的特征图来检测小尺寸的交通标志,模型损失函数加入了归一化处理提高泛化能力和对小目标的检测,以及将passthrough 层的池化处理改为拆分对准确率提高了8.7%,并简化了网络结构,运算速率提高了15 FPS.本文通过将训练好的模型通过Ttensorflow 进行实验,结果表明该模型识别率和实时性优于现有模型.但有些工作仍需完善,未能通过对视频的实际操作测试,以及实车实验,后续将其重点研究放在与实车结合部分上.
猜你喜欢
今日农业(2022年15期)2022-09-20
汽车实用技术(2022年9期)2022-05-20
小天使·二年级语数英综合(2019年10期)2019-11-08
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
小天使·一年级语数英综合(2016年8期)2016-05-14
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
读者·校园版(2015年19期)2015-05-14
小天使·一年级语数英综合(2014年7期)2014-06-26
海外英语(2013年8期)2013-11-22
