
基于cw2vec与BILSTM的 中文商品评论情感分类
2020-06-19 08:45高统超张云华
软件导刊 2020年4期
关键词:注意力机制
高统超 张云华
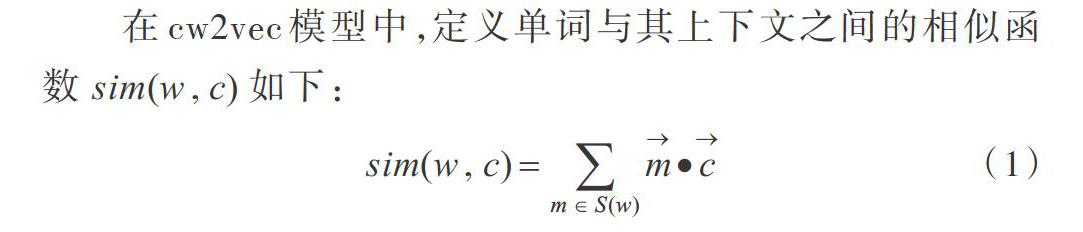
要:针对方面级情感分类算法在中文领域商品评论中性能不佳的问题,从实际应用场景出发,基于cw2vec模型并结合BiLSTM模型,进行中文商品评论方面级情感分类。通过对数据进行预处理,训练中文词向量,提取评论语句文字笔画信息特征;然后对评论语料构建基于注意力机制的BiLSTM模型进行情感分类,计算注意力向量权重,利用双向网络结构特点捕捉语义依赖信息。实验结果表明,当训练语料分布合理时,该方法准确率达到83.2%,比Skip-gram模型提高了3.3%。该方法在中文方面级情感分类任务上能获取中文语义信息,分类效果更好,有效提高了分类准确率。
关键词:情感分类;cw2vec模型;BiLSTM模型;注意力机制
DOI: 10. 11907/rjdk.191 800
开放科学(资源服务)标识码(OSID):
中图分类号:TP301
文献标识码:A
文章编号:1672-7800( 2020)004-0079-05
Sentiment Classification of Chinese Product Reviews
Based on cw2vec and BiLSTM
GAO Tong-chao, ZHANG Yun-hua
(Sch.ool of Inform ation , Zh.e.jiang Sci- Tech UrLiver.sity , Harzgzhou 3 1 00 1 8 . C^ ina )
Abstract: Aiming at the poor performance of aspect level sentiment classification algorithm in Chiiiese comruodity review. based onthe actual application scenario. we combine the BiLSTM ruodel ivith the cw2vec model to classif'y Chinese commodi'y revie,vs. The datais pre-processed. the Chinese word vector is trained. and the feature inforruation of' the corument sentence text is extracted. Then. theBiLSTM model based on the attentionmechanism is constructed to classify the annotation corpus, calculate the weight of the attentionvector. and capture the semantic dependence information hy using the characteristics of' the bidirectional network structure. The experi-mental resulfs show that u-hen the training corpus distribution is reasonable. the accuracy rate of' this method is 83.2% . which is 3.3%higher than that of the Skip-gram model. This method can obtain Chinese senlantic inf'ormation on the Chinese aspect level sentimentclassif'ication task . and the classification effect is better. which effectively improves the classification accuracy .Key Words : sentiruent classification; cw2vec model; BiLSTM model; attention mechanism
O 引言
《中国互联网络发展状况统计报告》显示,截至2018年12月,我国网络购物用户数量是6.10亿,网上零售交易额达到90 065亿元,同比增长23.9%[1]。用户进行网络购物后给出商品评论,数量成千上万,复杂多样。对评论语句采用情感分析,能够帮助商家调整销售策略,指导潜在用户合理选择商品。情感分析也被称为意见挖掘、倾向分析,是白然语言处理领域的一个基础任务[2]。目前,研究者广泛认同根据情感极性分类对象的粒度大小,将情感分类分为3个层面:文档级、句子级、实体与方面级(aspect)[3]。2016年Wang等。[4]利用英文数据集SemEval-2014 Task4,提出基于注意力(Attention)机制的LSTM,并在模型的输入和隐藏层中添加方面词语义向量,保证方面情感信息获得更多注意力,使情感分类结果更加准确;2018年王新波[5]基于英文数据集,引入依存关系等外部信息解决长距离信息捕获不充分问题,提高特定方面级情感分类的准确率,但无法利用中文数据集进行分类。汉字表意丰富,博大精深,比英文單词表达的内容更加复杂,汉字之间的多重组合形成的语义信息比英文单词更复杂多样。由于中英文的差异性,许多英文研究成果无法直接运用于中文语义分析。
以上方法在中文商品数据集上还没有进行过有效研究。鉴于此,本文在现有词向量模型和文本情感分类方法基础上,利用网络爬虫技术[6]获得原始实验数据,通过cw2vec模型训练的词向量作为BiLSTM模型的输入数据,进行中文商品评论方面级情感分类,在实验中取得了较好的实验结果,对于研究中文领域文本情感分析具有重要价值。
1 cw2vec模型
在自然语言处理领域,词向量模型扮演着举足轻重的角色,在许多任务中都发挥着至关重要的作用,比如机器翻译、情感分类等。传统词向量研究方式是单点表示(One-hot representation)法。根据分类词典[7]对所有单词进行排序,每个单词都有对应的位置,用一个与单词数量等长的数组表示某单词,单词所在的位置值为l,其余位置的值用0表示。这种方法的优点是比较直观,然而存在的问题是需要对大量语料数据进行整理,无法计算单词之间的相似度。2013年谷歌提出基于神经网络的word2vec[8-9]工具,用于运算词向量。在随后的发展过程中,该算法在实际实验中取得了良好效果,同时也在不断改进。2014年基于矩阵分布式表示的GloVe模型。10。被提出,通过分解“词一词”矩阵得到词表示,但是相关算法只适合用在由罗马字母构成的单词中。对于中文而言,汉字由许多笔画构成,字与词都包含着丰富的语义。在自然语言处理相关任务中,中文语料处理起来比较困难。此外,对于中文汉字的词向量研究比英文晚,本文使用较先进的基于Skip -gram模型改进的cw2vec模型。该模型利用汉字一笔一面的结构信息和联系,获得分布式词向量,能够保证不损失词向量语义信息。cw2vec模型以负采样进行计算。
在cw2vec模型中,定义单词与其上下义之间的相似函数sirri(W,c)如下:
其中,m表示当前词语的。元笔面向量,c表示上下文词语的词向量,S(w)为当前词语w的n元笔画集合,m是集合S(w)的n元笔画元素。基于当前词语w对上下文词语c的预测进行建模,给定词语w的概率计算,采用soft-max函数进行模拟预测,如式(2)所示。
其中,c是词汇表V中的单词。采用负采样方式,用基于分布的“负面”抽样的上下文单词集合替换复杂分母。目标函数计算如式(3)所示。
其中,w是当前词语,c是上下义词语, 是Sigmoid函数,T(w)是当前词语划窗内的所有词语集合,D是训练语料的所有文本,c是随机选择的词语,作为负样例,^是随机选择词语的个数P[]是负样例c 7按照词频分布进行的采样。
2 BiLSTM模型
2.1 注意力机制
注意力( Attention)机制以将当前任务目标相关的关键信息从各种信息中挑选出来为主要目标,本质上看注意力机制和人类的选择性视觉注意力机制相似…。注意力机制早先用于NLP领域的机器翻译,如图1所示,在Encod-er-Decoder模型[12]中运用注意力机制。
模型中上下文( Contex)向量cI是权重化之后的值,用于当前时刻f输入序列的向量。其表达式如式(4)所示。
其中,i是Encoder端的第i个词语,H,是Encoder端第J个词语的隐向量,A是Encoder端第/个词语与Decoder端第i个词语之间的权值。n ,的计算如式(5)所示。 其中,e表示Encoder端位置上第i个词语对Decoder端位置上第i个词语产生的影响,e。的计算方法如式(6)所示。
其中,a是一个函数,利用Decoder网络最新的隐藏层状态s,及编码器端第1个单词的隐藏层输出h作为输入,计算得到e。。
在时刻f,Decoder解码出的词语yt取决于所有Encod-er端隐藏状态根据注意力权重的加权组合。并且,注意力权重的计算取决于Encoder单元的最新状态与Encoder端隐藏层状态集合的相互作用,即模型可以利用已解码序列信息有选择地对源语言序列进行编码,从而生成更准确的译文。
2.2 基于注意力机制的BiLSTM模型
长短期记忆网络(ISTM)是单向神经网络结构,是一种特殊的RNN,它的m现可以用来解决RNN在训练中不能够处理长期依赖的问题[13]。从网络结构看,存在的问题是在计算当前神经单元状态时可以很好地利用前序序列信息,而后序序列信息无法得以有效利用。在进行更细粒度的分类任务时,需要关注情感词、否定词和副词等之间的关联交互作用,但是单向LSTM在词语的表示学习过程无无法充分利用文本全局信息,无法有效捕捉更微弱语义信息[14]。此外,利用最后时刻的长序列隐藏层输出作为句子序列的向量表示,其受序列头、尾部的影响会不一致。为了解决以上问题,本文将信息反向输入给模型,将单向LSTM网络结构模型设计成双向长短期记忆网络(BiLSTM)结构模型。模型网络结构如图2所示。
可以看出,BiLSTM模型是双向LSTM,增加了反向层部分,在前后序列学习过程中,对于第t个单词而言,在时刻f输出的前馈层向量和反向层向量分别用矗.∈Rd和h∈Rd表示,其中d是隐藏层向量的维度。前馈层向量h.和反向层向量h进行拼接,用 标记隐藏层输出向量。BiL-STM通过捕获文本中远距离的依赖关系[15],即使网络经过多层合成计算,也仍然能够将文本的主要语义信息保存下来。
BiLSTM模型结合注意力机制能够有效利用给定的不同方面信息,关注评论语句中的不同位置,判断语句的主观情感倾向。模型结构如图3所示,模型最下面一层是输入层,将经过词向量训练的输入序列输入到模型中,用 表示隐藏层的输出矩阵,Ⅳ表示序列长度,d表示隐藏层输出的向量维度。模型中的方面向量用v。表示。
将组合隐藏层出向量与方面向量,利用双曲正切函数进行非線性激活,如式(7)所示。
式(7)中, 和 均为参数矩阵,eN是数值全为1、长度为Ⅳ的列向量, 表示复制Ⅳ份v。并进行组合。向量矩阵M包含序列信息和方面信息,对其进行映射,利用Softmax函数输出概率分布 ,如式(8)所示。
式(8)中, 。模型的重点是注意力权重向量计算。a表示一个Ⅳ维注意力向量,每个维度的值代表相应位置隐藏层输出的权重数。对隐藏层输出进行加权,可以得到对应给定方面的输入序列的语义表示r∈Rd,如式(9)所示。
为了更好地提升模型的实验效果,将序列尾部的隐藏层输出h。加入到语句序列的表示中[16],如式(10)所示。
其中, 是最终输入语句序列,w和w均为映射参数矩阵,然后利用Softmax函数作出情感倾向判断。
3 实验验证及实验分析
3.1实验环境
本文实验环境配置如表1所示。
3.2实验框架
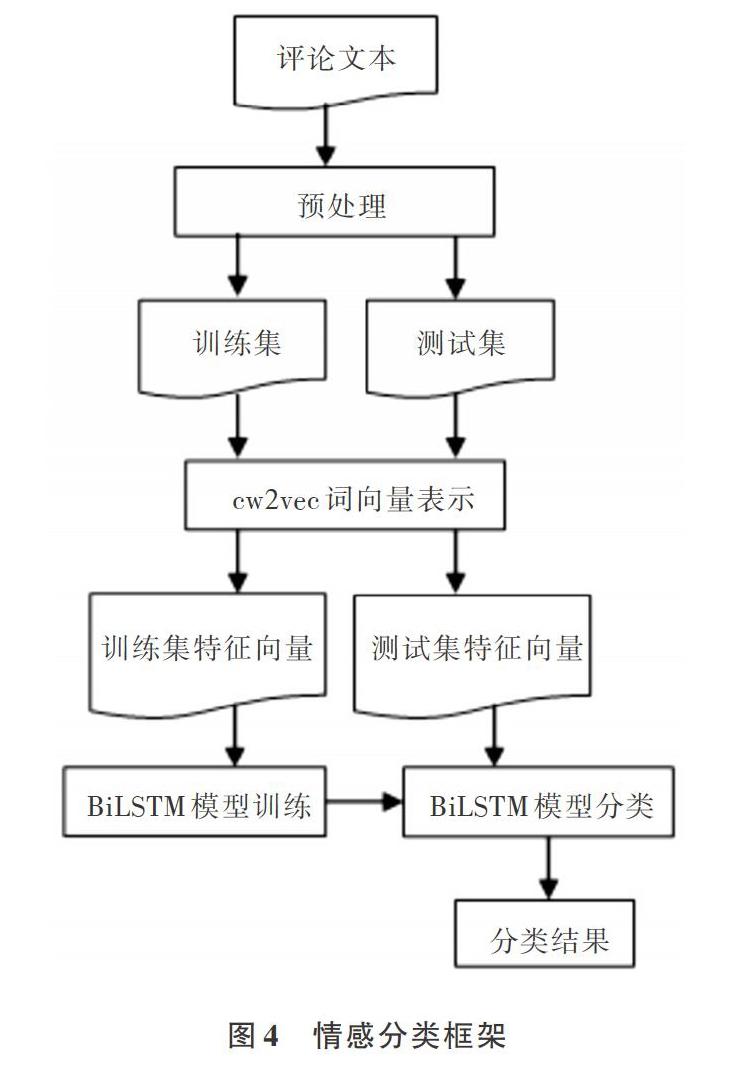
cw2vec模型利用中文汉字笔画之间的联系,更好地融合词与词的语义关联信息,训练中文词向量,改善了词向量的质量,再将词向量作为BiLSTM模型输入层传人,利用BiLSTM模型的特点,使得情感分类任务上的分类效果进一步得到提高。实验框架如图4所示。
(1)数据预处理。对于中文数据集而言,用于方面级商品评论情感分析的语料库较少。本文利用Scrapy框架技术爬取文本数据,采用中文分词组件工具Jieba精确模式[17]进行分词和词性标注,手动分配方面信息词语。
(2)特征向量。在利用cW2vec模型提取中文汉字笔画信息的特征向量时,需要对汉字进行笔画拆分,本文利用Pvthon脚本从汉典获取笔画信息。
(3)情感分类。目前,情感分类方法主要是基于词典的情感分析和基于机器学习的情感分析,相关算法研究有很多种,如人T神经网络(RNN)、支持向量机(SVM)、K紧邻(KNN)等[18]。本文对BiLSTM网络模型进行训练,然后进行情感分类。
3.3实验数据
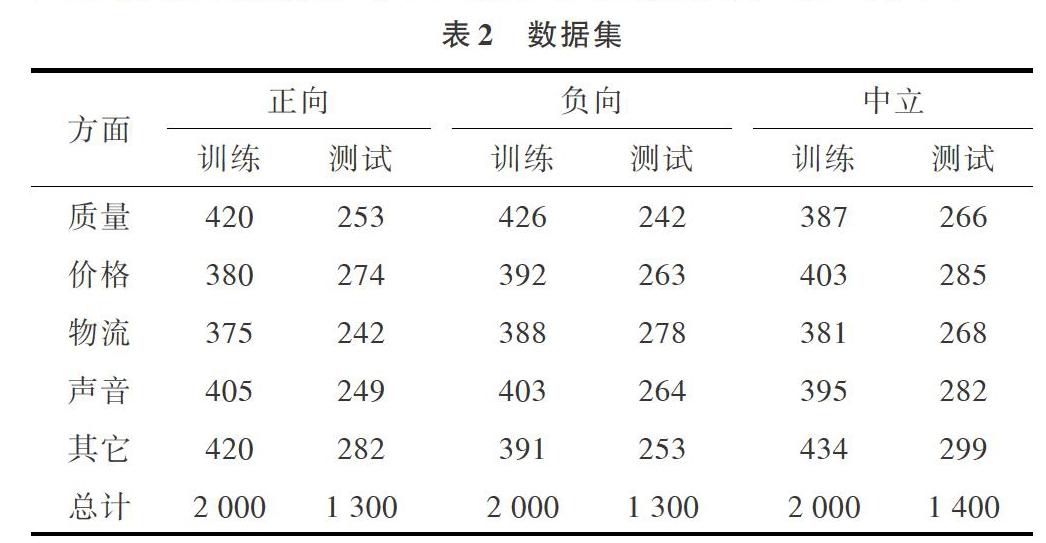
目前,用于方面级情感分类的数据集是英文的SemEval-2014 Task4[19],包含餐馆和笔记本电脑两个领域的用户评论数据。每个领域的数据集分成正向、负向和中立3种不同的情感粒度。本文利用爬虫技术在某商城网站上获取了50000条关于冰箱的客户评价数据,但是获取的商品评论中正负类评论语句差异比例不平衡,同时也存在很多过短评论语句和特殊表情符号语句,这样的语料会导致实验结果与真实结果出现偏差,不适合进行分类实验。为了解决这些问题,本文实验时在众多语料中选取其中的10000条语句,分成正向、负向和中立3种情感极性语句。训练其中的6000条评论语句,将其余4000条评论用作测试语句,这样可以保证分类的正确性。此外,每条评论语句包含了相应的方面信息和极性判断。本文目标是识别具有相应方面信息句子的极性。数据统计如表2所示。
3.4参数设置与评价指标
实验数据处理完成后,通过cw2vec模型进行词向量训练,参数设置会影响词向量的质量以及最终分类模型训练结果。本文词向量维度选择150,词窗口大小为5。BiL-STM模型中方面向量维度和隐藏层大小为300,学习率为0.01,L2正则化权重为0.01。在评估方面级情感分类任务的表现时,采用常用评价标准,用accuracv[20]作为方法评估标准.T是正确预测的样本数,N是样本总数,准确度是测量所有样本中正确预测样本的百分比。计算如式(12)所示。
3.5 实验结果与分析
在相同数据上,本文选择基于CBOW模型和基于Skip-gram模型的word2vec作为参照实验,实验结果如表3所示。在实验过程中,为了减轻由于随机初始化产生的性能波动,运行10次训练算法。表3报告了平均准确度,可以看出,平均而言本文模型优于其它组合模型方法。采用CBOW模型和Skip-gram模型,基于英文字母进行词向量训练,对于中文汉字而言,没有利用汉字的结构信息。cw2vec模型表现较好,能够有效捕捉汉字特征信息,鲁棒性好。
4 结语
中文文本情感分析研究是目前计算机领域研究的热点,具有很高的商业价值和科学研究价值。本文将提取汉字笔画特征的cw2vec模型和一种基于神经网络的BiLSTM模型进行组合并用于中文商品评论情感分类,对输入的文本进行词向量训练,通过分析中文汉字表达特点获取分布式向量,根据BiLSTM网络结构特点,将前后单词语义信息保留下来进行情感分类。通过实验比较,结果表明,本文方法在情感分类任务上拥有良好表现,具有重要的技术参考价值。在后续研究中,将着重分析句法结构并探索词汇之间的依存关系,进一步提高情感分类精度。
参考文献:
[l]CNNIC.中国互联网络发展状况统计报告[EB/OL]. 2018-08-[1].http://www.cnnic.net.cn/hh'fzyj/hlwxzbg/hlwtjb g/201902/P020190228510533388308.pdf.
[2]劉晓彤,田大铜融合深度学习与机器学习的在线评论情感分析[J].软件导刊,2019.18(2):1-4.
[3]LIU B.Sentiment anah- sis and opinion mining[M]California: Morgan&Claypool Publishers, 2012.
[4]WANC W,PAN S J,DAHLMEIER D. et al. Recursive neural condi-tional random fields for aspect-based sentiment analysis[DB/OLl.arxiv.org/pdf/1603.06679.pdf
[5]王新波用户评论方面级情感分析算法研究[D]北京:北京邮电大学,2018.
[6] 刘宇,郑成焕.基于Scrapy的深层网络爬虫研究[J].软件,2017,38(7):111-114
[7]黄仁,张卫.基于word2rec的互联网商品评论情感倾向研究[J].计
算机科学,2016, 43(SI):387-389
[8]KANDOLA E J,HOFMANN T. POGCIO T. et al.A neural prohahilis-tic. language model [J]. Studies in Fuzziness and Soft Computing,2006. 194:137-186
[9]MIKOLOV T. CHEN K. CORRADO G,et al. Efficient estimation ofword representations in vector space[J]. Computer Scienc.e, 2013.
[10]PENNINGTON J, SOCHER R,MANNINC C Glo,'e: global vectorsfor word representation[C]. Proceedings nf the 2014 Conference onEmpirical Methods in Natural Language Processing(EMNLP), 2014.
[11]BAHDANAL D. CHO K, BENGIO Y. Neural mac.hine translation bvjointly learning to align and translate[J].Computer Science, 2014
[12]SUTSKEVER I, VINYALS 0,LE Q V. Sequence to Sequence Learn-ing with Nreural Networks[Z]2014.
[13] 黄磊,杜昌顺基于递归神经网络的文本分类研究[J].北京化工 大学学报(自然科学版),2017,44(1):98-104
[14]何原野基于深度学习的多标签文本分类方法[D].昆明:云南大学,2017.
[15]张应成,杨洋,蒋瑞,等基于BiLSTM-CRF的商情实体识别模型[J].计算机工程,2019(5):308-314.
[16]ROCKTASCHEL T, CREFENSTETTE E, HERMANN K M. et al.Reasoning ahout entailment with neural attention[DB/OL]. arxiv.org,pdf/1509.06664.pdf
[17]黎曦.基于网络爬虫的论坛数据分析系统的设计与实现[D].武汉:华中科技大学,2019
[18] 彭三春,张云华.基于RNTN和CBOW的商品评论情感分类[J].
计算机工程与设计,2018. 39(3):861-866
[19]KHALIL T, ELBELTAGY S R hrileTMRG at semeval-2016 task 5:deep conrolutional neural networks for aspect category and sentimentextractionEC].Internatinnal Workshop on Semantic Eraluation, 2016.
[20]陳颖熙,廖晓东,苏例月,等.基于CDBN网络的文本情感倾向分类算法[J].计算机系统应用,2019,28(1):165-170.
(责任编辑:孙娟)
收稿日期:2019-06-11
作者简介:高统超(1994-),男,浙江理工大学信息学院硕士研究生,研究方向为智能信息处理;张云华(1965-),男,博士,浙江理工大
学信息学院教授、硕士生导师,研究方向为软件架构、软件工程、智能信息处理。本文通讯作者:高统超。
猜你喜欢
计算机应用(2019年3期)2019-07-31
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
