
基于序列模型的作战文书知识抽取技术研究∗
2020-06-19 06:14
舰船电子工程 2020年4期
(江苏自动化研究所 连云港 222006)
1 引言
随着指挥信息系统智能化的发展,指挥文书信息数据化的概念被提出。指挥文书信息数据化是解决如何将指挥文书信息的内容转变为智能化数据的问题,其核心任务是知识抽取。作战文书作为指挥信息的一种重要载体,面向作战文书的知识抽取对于军事知识图谱建立[1]、军事标图系统的自动标绘[2]以及智能辅助决策等应用都具有重要的研究价值。
知识抽取技术分为两部分,分别是实体识别与关系抽取。对作战文书的知识抽取,目前通用的技术是使用流水线模型。流水线模型是首先对作战文书进行实体识别,然后利用实体识别的结果开展关系抽取的任务。对作战文书中军事命名实体的识别开展的比较早,姜等[3]利用CRF模型学习文本特征;冯等[4]采用CRF结合词典和规则的方法从作战文书中提取文本特征,比仅用CRF识别效果更好。近年来,深度学习的方法被广泛应用在各个领域,在作战文书的实体抽取中也得到了比较好的应用。王等[5]提出的基于BiLSTM-CRF模型利用预训练的字向量作为输入,实现了军事命名实体识别;张等[6]提出的改进的CNN-BiLSTM-CRF模型实现了军事命名的细分类实体识别。对作战文书的关系抽取也有相应的研究。单等[7]通过结合词语规则与SVM模型实现了一种作战文书实体关系抽取的方法;朱等[8]使用深度学习中的BiLSTM模型实现了军事领域的关系分类方法。
以上关于军事知识抽取的模型均属于流水线模型。然而流水线模型有一些共同的问题:由于关系抽取是建立在实体识别的结果上的,所以实体识别的误差会传递到关系抽取中,对关系抽取造成较大的影响。另外,现有的关系抽取模型大多侧重于在一个句子中处理单个关系的场景,但在一个句子中实体之间通常会存在多个关系。而这种多关系现象在作战文书中出现的更多,比如“陆军第7师从张庄(43,27),李庄(22,76)地段正面突破防御。”,在这句中共出现了四个实体,三个关系,如图1所示。
本文将序列生成模型[9~10]应用到了知识抽取的任务中,将实体识别与关系抽取任务完全转换为文本生成任务,从而解决了流水线模型中的误差传递问题。文中通过在序列生成模型中引入了位置注意力机制[11]结构,并通过控制生成概率来选择当前解码时间是从原始输入中复制单词还是从词汇表中生成单词,实现了实体和关系的联合提取并且实体可以在多个三元组中重复,解决了重叠实体关系三元组的提取问题。

图1 重叠实体关系示例
2 本文模型描述
本文模型的目标是生成一个或多个关系三元组,同时允许重复输出实体。本模型给定训练数据[x,y],其中x表示模型的输入文本,y表示目标输出。本文模型可以通过指针从源文本中复制单词,也可以从预定义的词汇表中生成单词。模型的整体结构如图2所示。

图2 本文模型结构图
2.1 序列生成模型
1)Bi-LSTM编码层
首先将给定句子转化为词向量矩阵x=[x1,x2,...,xn],其中xt∈Rd表示第t个单词的嵌入向量。对于编码层本文使用了Bi-LSTM[12]对序列进行编码,它由两个独立的LSTM层组成。前向LSTM层将输入序列从x1到xn进行编码,后向LSTM层输入序列从x到x进行编码。然后我n1们将连接起来表示第t个单词的最终编码信息,记为,这样每一步的编码向量就可以得到其上下文的语义信息。
2)解码机制
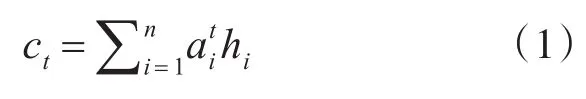
式(1)中hi为编码器第i个词的隐藏状态向量。
本文将上下文向量与解码器状态st连接,并通过线性层进行反馈,生成词汇表分布概率Pvocab。
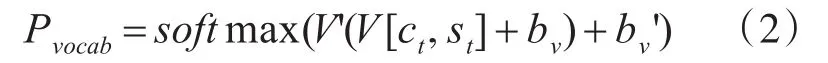
其中V',V,bv和bv'是可学习的参数,Pvocab是预定义词汇表中所有单词的概率分布。

在式(3)中P(w)是输出词典中的概率,其中输出词典包括两部分内容:一是事先定义的词典其中包含有关系词以及训练词向量时的词汇表,二是输入序列中的词。所以为了保证本模型有从预定义词汇表中生成关系词的能力,又有从源文本中复制单词的能力,本文引入一种软开关机制,即在每个解码步骤中计算生成概率pg。

其中Wc、Ws、Wy、bg为可学习参数,δ为Sig⁃moid函数,pg由上下文向量ct,解码器状态st,解码器输入yt。pg的作用是用来决定当解码器在解码时选择单词输出从源文本复制的可能性更大还是预定义词汇表生成的可能性更大。基于软开关机制本文模型得到最终的概率分布:

通过式(5)可以得到输出词典中的概率分布,输出词典包含输入序列词以及预定义关系词。通过这种软开关机制能够使模型具有复制命名实体同时又能生成关系词,从而实现实体与关系的联合抽取。
2.2 位置注意力机制
本文对序列模型中的注意力机制进行了改进,目前的序列模型的注意力机制是通过语义信息反馈输入序列的重要程度。本文受到了Zhang等[11]以及Zeng等[13]的启发对位置向量进行处理。由于作战文书中比较固定的句式,部队名称这种命名实体一般会出现在句子的开头,军事任务这种命名实体一般会出现在句子的末尾,因此词语在句子中的全局位置就带有一定规律,通过加入词语的全局位置向量可以增强模型中注意力机制的效果。另一方面,对于关系抽取来说,句子中词语的相对位置也有一定的规律,在作战文书中,军事任务这种命名实体的附近一般会出现时间,军事任务和时间的相对距离就会比其他词语要小。通过加入词语的相对位置向量可以增强序列生成模型中的注意力机制的效果。如图3所示,第一行表示句子的全局位置,第二行为“20日18时”与其他词汇的相对位置。本文结合全局位置向量与相对位置向量来改善序列模型中的注意力机制。
句子在输入到编码器时,本身就有一个前后关系,因此通过输入序列中词的索引就能得到句子中每个单词位置编码向量。对于一组输入序列x=[x1,x2,...,xn],其中它的全局位置向量为,对于某个词的相对位置向量为。根据图3中所示,注意力机制的权重大小由编码器的隐藏层向量hi和解码器的状态向量st以及位置嵌入向量所决定。其中解码器的状态向量st是由位置注意力机制层的计算公式如式(6)、(7)所示。

图3 输入语句的全局位置与相对位置

3 实验验证与分析
3.1 数据集与模型训练过程
本文根据作战文书的特点[14~15]预定义了作战文书中7种军事命名实体分别是部队番号、作战编成、武器装备、军事人员、时间、地点、军事任务。预定义了8种实体关系类别分别是实体与作战编成的编成关系,部队与军事任务的执行关系、部队与地点的地理位置关系、任务与地点的目标关系、任务与部队的目标关系、任务与时间的时间属性关系、部队与武器装备的配置关系、军事人员与部队的指挥关系、部队与部队的敌对关系。
本文收集了248篇作战文书作为数据集,其中总共含有18480个句子。在对数据进行标注时,关系词的形式是将命名实体名称与关系词按三元组的形式进行标注,从而在提取关系时,对应的头实体与尾实体同时被提取出来。最终共标注关系数35209。本文将训练集和测试集按8:2的形式进行实验验证。本文的测试指标使用了准确率P、召回率R以及F1值。在进行测试时,由于输出序列是以三元组的形式进行输出,输出得三元组的顺序可能不与真实序列完全一致,但在输出序列中有部分三元组可能是抽取正确的,因此为了使得测试方法更加合理,本文将输出序列的三元组与真实序列进行匹配来得到各项指标。
在模型进行训练过程中,根据一般的编码器解码器模型的经验,本文模型使用的隐藏层的维度为128维,词向量的维度是200维,位置向量的维度是20维,根据本文的硬件条件将Batchsize的大小设置为128,模型使用Adam梯度下降算法来对数据进行训练,学习率设为0.005,epoch的大小为50。
3.2 本文模型测试结果分析
本文将使用了位置注意力机制的序列生成模型与未使用的序列生成模型进行比较,分别测试比较了每种关系的测试指标,结果如表1所示。

表1 本文模型测试结果
从表1可以看出,其中位置注意力机制对于部队编成关系、军事任务时间关系、部队位置关系以及军事任务执行关系有比较好的提升效果,对于这几种关系它们对应的头实体与尾实体都能有比较固定的位置,作战编成这种实体一般都是在句子的开头,以及时间一般都会在军事任务附近,因此语句中这种隐含的位置信息能够被位置注意力机制所捕获。另外结果还表明不管是否使用位置注意力机制,部队的地理位置关系以及军事任务执行关系都没有其他几类关系的得分高,最终的F1值都没有超过0.6。通过分析测试集的输出序列结果发现,位置关系与执行关系一般存在于具有重叠实体关系的句子中,如而且对于部队番号来说,部队番号与其他的实体形成的关系最多,如表2所示为各个实体所参与的关系数。

表2 命名实体构成三元组数量对比
从表2中可以看出部队番号实体能够与其他五种实体构成三元组,并且由于它所在的三元组多出现在重叠实体关系句中。因此对地理位置关系以及执行关系抽取时会导致召回率比较低的情况出现。
为了验证本文模型抽取重叠实体关系的能力,本文将测试集中具有重叠实体关系的句子进行细分类,根据每个句子中包含的重叠关系数将测试集划分为5个子类,其中这5个子类分别包含1、2、3、4以及大于等于5的重叠实体关系数。最终测试结果如图4所示。

图4 抽取重叠实体关系测试
从图4中可以发现随着一个句子中包含关系的数量的增加,关系抽取的性能也就逐渐下降。但是当句子有重复的一到三个关系三元组时,本文模型仍能保持一定的准确率,当重复关系数大于4时,关系抽取的能力会逐渐下降。图4的实验结果也说明了本文模型具有一定的识别重叠关系实体的能力。
3.3 本文模型与其他模型的对比
为了验证本文联合抽取模型与其他流水线模型的区别。本文选择了两种流水线模型进行对比,流水线模型将三元组抽取任务分为实体识别与关系抽取,由于一般的实体抽取任务所用到的模型需要使用BIOSE标注的办法进行重新训练,本文数据集的标注形式是直接按照三元组形式进行的标注,并不能直接用在实体抽取任务中。所以本文将实体抽取任务的准确率设定为100%,在流水线模型中不将实体识别误差引入后续的关系抽取模型。对于关系抽取任务本文选择了两种模型。其中一种是在中文文本关系抽取领域应用比较广泛的PCNN模型[16],PCNN模型是通过CNN提取句子的特征,并且结合句子中实体的相对位置特征将其与文本特征进行拼接后送入分类器中。另一种是朱等[8]使用的BiLSTM-ATT模型,该模型通过BiLSTM层提取句子特征,经过语义注意力机制层后输入到分类器中实现了军事文本关系抽取。由于这两种模型都是关系分类模型,没有识别重叠实体关系的能力,因此本文将作战文书数据集中的非重叠实体关系句作为训练和测试集。在非重叠实体关系句中主要包含有三种关系:指挥关系、配置关系以及目标关系,因此本次实验主要统计这三种关系的指标。本文对这三种模型使用相同的词向量,并且使用相同的训练集与测试集进行实验。最终实验结果如表3所示。总体指标如图5所示。

表3 非重叠实体关系能力对比
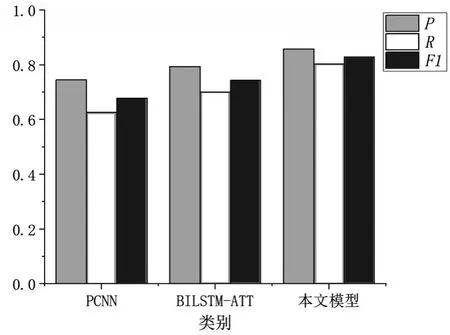
图5 总体指标对比
由于本文并未将实体识别的误差引入到关系抽取中,因此实际流水线模型的抽取结果会低于文中的结果。但即使按照实体识别的准确率达到100%,本文模型的总体指标仍能高于现有的关系抽取模型。这也就证明了本文的联合抽取模型的对作战文书有较好的抽取效果。并且其中对于流水线模型中的PCNN与BiLSTM-ATT模型对配置关系和目标关系的召回率不高,通过分析测试结果发现非重叠关系句子中有一部分句子包含多种关系,虽然这多种关系的实体不重叠,但对于分类器模型来说只能识别出其中一种关系,所以召回率相对较低。
4 结语
本文针对作战文书知识抽取的问题,改进了军事领域词向量的训练方法,并提出了一种基于序列模型并结合位置注意力机制的实体和关系联合抽取模型。通过实验验证,本文模型具有一定的识别作战文书中的重叠关系实体的能力,并且能够直接输出三元组,避免了流水线模型中误差传递的影响,对于非重叠实体关系的抽取,本文模型也有一定效果的提升。同时未来的工作会对本文模型在抽取复杂重叠实体关系时的准确率较低的问题进行更深入的研究。
猜你喜欢
计算机应用与软件(2022年5期)2022-07-07
计算机应用与软件(2021年4期)2021-04-15
河北科技大学学报(2020年4期)2020-09-10
当代工人(2020年4期)2020-05-11
儿童故事画报(2019年8期)2019-08-14
小天使·一年级语数英综合(2018年6期)2018-06-22
留学(2018年18期)2018-05-14
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
中国质量万里行(2016年9期)2016-11-11
