
基于双孪生网络的自适应选择跟踪系统
2020-06-18 03:41张腾飞周书仁
计算机工程 2020年6期
张腾飞,周书仁,彭 建
(长沙理工大学 a.综合交通运输大数据智能处理湖南省重点实验室; b.计算机与通信工程学院,长沙 410114)
0 概述
目标跟踪是计算机视觉和模式识别领域的研究热点之一,得到了广泛关注与应用。在智能交通系统中,相机与无人机的自动跟踪拍摄、人机智能交互系统都需要应用目标跟踪方法。虽然近年来目标跟踪方法取得了快速的发展,但是物体被遮挡、目标发生严重形变、目标运动速度过快、光照尺度变化和背景干扰等因素导致的目标跟踪系统鲁棒性低和实时性差等问题依然存在[1]。
现有目标跟踪方法可以分为生成模型方法和判别模型方法两类[2]。生成模型方法在当前帧对目标区域进行建模,运用生成模型描述目标区域的表观特征,在后续帧中进行目标预测,从而寻找到与目标最为相似的区域。该类方法的典型代表有卡尔曼滤波[3]、粒子滤波[4]和Mean-Shift算法[5]等。判别模型方法通过训练分类器来区分背景和目标,这种方法也被称作检测跟踪模型。判别模型由于旨在区分一帧中的目标和背景,因此,其具有更强的鲁棒性,得到了广泛应用。经典的判别模型方法有CT[6]和TLD[7]等算法。文献[8]通过多次连续蒙特卡罗采样得到最优目标区域,利用子块遮挡比例自适应调节学习速率,从而解决了时空上下文跟踪易漂移和遮挡敏感的问题。目前,多数基于深度学习的方法均在判别式框架的范畴内。文献[9]提出了全卷积的孪生网络SiamFC。SiamFC的优点在于将跟踪任务转化为检测匹配的过程,通过比较目标帧和模板帧图片的相似度,计算出相似度最大的位置,从而得到目标在模板帧中的位置。CFNet[10]通过为低级别的CNN引入相关滤波,将相关滤波看作CNN网络中的一层,以提高跟踪速度并保证跟踪精度。文献[11]提出的SINT结合光流信息,取得了更好的跟踪性能,然而,其引入光流信息导致了跟踪速度缓慢,不能达到实时的要求。文献[12]提出的SA-Siam双孪生网络,在SiamFC的基础上加入了语义分支,其能够提高跟踪精度但降低了跟踪的速度。
为进一步提高跟踪速度,本文提出一种基于双孪生网络的自适应选择跟踪方法ASTS。系统自动判断目标帧信息,在简单帧中只运用外观信息进行判断,复杂帧权重确定则结合语义信息和外观信息。在OTB2013/50/100[13]和VOT2017数据集上进行实验,以验证该方法的跟踪性能与鲁棒性。
1 孪生网络
全卷积孪生网络的提出在跟踪领域具有重大意义。孪生网络在训练集ImageNet2015上进行离线训练,得到相似度匹配函数,在跟踪过程中,通过模板相似度比较得到相似度最大的位置。具体地,以第1帧为模板图像,用以在后续255×255的搜索图像中匹配定位127×127的模板图像z。通过离线训练出的相似度函数将模板图像z与搜索图像x中相同大小的候选区域进行比较。经过卷积得到最后的得分图,其中,目标区域会得到高分,非目标区域会得到低分。相似度函数为:
Fl(z,x)=φl(z)*φl(x)+v
(1)

2 自适应选择跟踪网络
ASTS方法的总系统框图如图1所示。ASTS由外观信息与语义信息2个分支组成。系统网络的输入是视频第1帧经人工标记的目标真实位置和当前帧裁剪出的目标搜索区域。其中,z和zg分别表示目标和目标周围环境,x表示搜索区域。x和zg尺寸相同,都为Wg×Hg,z的尺寸为Wt×Ht×3,其中,Wt 图1 基于双孪生网络的自适应选择跟踪系统 系统外观分支的输入为目标区域z和搜索区域x。系统外观分支并非一个简单的孪生网络,而是加入了深度Q学习网络[14]。和EAST不同的是,外观分支P中最后2层卷积层covn4和covn5没有Q网络则不会提前停止,原因是covn4和covn5层属于深层的网络信息,语义分支会较好地处理,因此,网络不会在最后2层提前停止。 在外观分支P中执行提前停止的过程被认为是一个马尔可夫决策过程(Markov Decision Process,MDP)。本文通过深度强化学习训练一个有效的决策网络(Agent)[15]。通过训练决策网络能够学习动作(Action)和判断状态(State),得到提前停止标准从而提前停止网络。决策网络可以跨过特征层进行一系列的操作,比如判断将何时执行停止或者进入下一层,以及如何有效地对边界框进行变形。 在强化学习过程中,马尔可夫决策过程分为一组动作A、一组状态S和奖励函数R。在第n(n<4)层,决策网络检查当前状态Sn,然后决定动作An是停止并输出还是对边界框进行移动变形以进入下一层,同时获得正面或负面的反馈奖励并反映当前框对目标的覆盖程度,以及动作停止前所执行的步骤。 1)动作:动作集A通过验证设置为6个不同的缩放动作和一个停止动作,如图2所示。缩放动作包括整体缩小和整体放大2个全局动作变换以及4个改变宽高的局部动作变换。每个边界框由坐标b=[x1,x2,y1,y2]表示,每次转换动作都会通过式(2)对边界框进行离散变换。 图2 马尔可夫决策中的动作说明 αw=α*(x2-x1) αh=α*(y2-y1) (2) 通过对x坐标(y坐标)加上或者减去αw(αh)来进行变换,与文献[15]相同,本文取α=0.2。 2)状态:状态是当前层的得分图和历史层得分图的平均值Fn和采取动作的历史向量hn组成的二元组,这种结构将会使系统更加鲁棒。历史向量跟踪hn包含了3次历史动作,每个动作又是7维的矢量,则h∈R21。 3)奖励:奖励函数R在采取特定动作后,该机制定位物体的提升为正反馈。所设定的提升标准通过计算预测的目标矩形框与手动标记的目标矩形框的交叉联合(Intersection-over-Union,IoU)来衡量。IoU定义为: (3) 其中,b为预测的目标框面积,Rg为目标实际所在的位置。奖励函数通过一个状态到另一个状态的IoU差别来估计,即当决策网络执行动作A、状态从Sn转到Sn+1时,每个状态S都有一个相关的矩形框b,则奖励函数为: R(Sn,Sn+1)=sign(IoU(bn+1,Rg)-IoU(bn,Rg)) (4) 从式(4)可以看出,若IoU变大,则奖励为正(+1);反之,奖励就为负(-1)。式(4)适用于所有转换矩形框的动作,通过这种方式奖励正向的变化,直到没有更好的动作来使定位更精确或者到达卷积层第3层。停止动作拥有异于其他动作的奖励函数。根据文献[14]可得: (5) 最后,本文应用文献[14]的深度Q强化学习网络来学习行动值函数。 系统语义分支的输入为目标周围环境zg和搜索区域x,本文直接使用在图像分类任务中已经训练好的AlexNet[16]作为语义分支,在训练和测试期间确定所有参数。网络中用conv4和conv5最后2个卷积层的特征作为输出,并在特征提取后插入一个1×1的卷积层进行特征融合,这样做的目的是使语义分支网络能够更好地进行相关操作,并且提高跟踪精度。外观分支G的输出表示为: Fg(zg,x)=corr(f(φg(zg)),f(φg(x))) (6) 其中,corr(·,·)表示相关操作,f(·)表示特征融合,φ(·)表示级联的多层特征。 训练期间2个网络完全单独分开训练,互不干扰,跟踪时才对2个网络进行选择性叠加。跟踪期间,在一串连续的跟踪序列中,帧与帧之间存在大量的相似帧,相比目标帧,这些帧图片的目标形变较小、周围环境语义信息变换不明显。这些帧只利用外观分支较浅层的特征信息跟踪器就能很好地对目标进行跟踪,这时如果完全考虑2个分支,则会使跟踪速度减慢,因此,针对变换不明显语义信息的简单帧,语义分支完全可以忽略。同时在较浅层的网络中,空间的分辨率较高,但特征的语义信息较少,随着网络的加深,从深层网络中提取到的特征语义信息会比较丰富,但是会导致空间的分辨率降低,不利于目标定位与跟踪。因此,在外观分支上浅层的信息能够更好地跟踪目标,定位出目标所在位置。 在外观分支中,让网络通过训练好的深度强化学习Q网络来选择合适的停止层,既能够增加跟踪器的跟踪速度,又能很好地利用浅层网络空间分辨率高的特性定位出目标,提高跟踪性能。在变化较大的复杂帧中,外观分支不会提前停止,能够提取到目标更丰富的特征信息,得到的特征与语义分支提取到的特征进行叠加能够更准确地定位出目标的位置,使跟踪器在速度与性能之间得到平衡。当外观网络提前停止时,则外观分支对整体网络作反馈,语义分支的占比为0,完全由外观分支输出;当外观网络没有提前停止时,将上述2个网络得到的相关系数得分图按一定比例进行叠加,即: (7) 其中,τ代表外观分支对整体网络的反馈,λ是平衡2个分支重要性的加权参数,其可以通过实验来取值,F(zg,x)表示被跟踪的目标位置。 本文在MatConvNet库[17]上进行仿真,实验环境为Ubuntu 4.8.2 系统,Intel(R) Xeon(R) CPU E5-2670 v3 @ 2.3 GHz四核处理器,配备有NVIDIA GeForce GTX TITAN X GPU,在OTB50、OTB100、OTB2013和VOT2017基准上分别进行实验。 采用2015年版Imagenet大规模视频识别挑战(ILSVRC)[18]的视频数据集进行训练,该数据集包含约4 500个视频,接近一百万个注释帧。具体地,在训练过程中,随机地从数据集同一个视频中选取两帧,对其中一帧裁剪出以z为中心的zg,从另一帧中裁剪出以人工标注目标为中心的x。目标图像z大小为127×127×3,对大小为255×255×3像素的搜索区域图像x进行搜索,并且外观分支网络的zg与x具有相同的大小,最终的输出都为17×17维。学习率设定为10-4。经过实验得出,当外观网络没有提前停止,即返回值τ为1时,当λ为0.36时系统性能最佳。 OTB包含OTB50、OTB100、OTB2013 3个数据集[13]。OTB数据集中的序列分为遮挡、比例变化、快速运动和平面内旋转等11个不同的注释属性,OTB一般有2个评估标准,分别是成功率和精确度。对于每一帧,计算跟踪矩形框与人工标注的目标框边界的IoU以及它们中心位置的距离,采用跟踪成功率与精确度来评估跟踪器。 本文在OTB50、OTB100、OTB2013 3个基准数据集上对SiamFC[9]、CFNet[10]、SINT[19]、Staple[20]、EAST[21]及本文系统6个跟踪器进行评估,结果如表1所示,最好的结果用加粗表示。从表1可以看出,在OTB2013基准下,ASTS具有最佳的性能,其AUC(Area-Under-Curve)达到了0.657,超出孪生网络SiamFC跟踪器0.050。虽然SINT的AUC也达到了0.655,但是SINT并非一个实时的跟踪器,其跟踪速度只有4.0 FPS。在OTB50基准下,EAST跟踪器虽然达到了高速的148 FPS,ASTS的AUC也只比其高出0.001,但在OTB2013和OTB100中,ASTS跟踪器的AUC分别高出EAST约0.019和0.013。OTB100是OTB50的扩充,因此,其更具有挑战性。本文ASTS跟踪器在OTB100基准中AUC依然保持在0.644,比OTB50基准中更高。而在OTB2013中表现良好的SINT跟踪器,在更多的测试中其AUC不够稳定。 表1 OTB基准下的评估结果 VOT测试基准拥有多个不同的版本,最新的版本有VOT2015[22]、VOT2016[23]和VOT2107[24]。VOT2015和VOT2016拥有相同的序列,但是VOT2016中的人工标注标签比VOT2015更加准确。由于VOT2016中的部分标签已经能够被多数跟踪器准确跟踪,因此VOT2017将VOT2016中的10个序列替换为新的序列,但依然保持总体序列属性分布不变。本文应用VOT2017作为评测基准。VOT基准主要的评测指标为平均重叠期望(Expected Average Overlap,EAO)、准确率(Accuracy,A)、鲁棒性(Robustness,R)。一个性能良好的跟踪器应该有较高的准确率和平均重叠期望分数,但鲁棒性较低。 在VOT2017基准下对ECOhc[25]、Staple[20]、SiamFC[9]、SA-Siam[12]和ASTS进行比较,结果如表2所示,其中量化展示了5个跟踪器的平均重叠期望、准确率、鲁棒性和跟踪速度。从表2可以看出,ASTS的平均重叠期望为0.227,略低于ECOhc,但ASTS具有速度优势,准确率达到0.527,高于ECOhc跟踪器。在准确率方面,ASTS跟踪器表现最优异,高于SA-Siam约0.02。在跟踪速度方面,ASTS最高达到了97.0 FPS。在鲁棒性方面,ASTS表现不如ECOhc,同样是因为ECOhc在速度方面做出了巨大牺牲,但本文方法的鲁棒性均优于其他跟踪器。 表2 VOT2017基准下的评估结果 图3所示为均值漂移算法[5]、SiamFC、CT、Staple和ASTS的跟踪实验结果,可以看出,除本文ASTS方法外,其他方法都发生了不同程度的漂移现象。 图3 5种跟踪器的跟踪结果比较 本文提出一种基于双孪生网络的自适应选择跟踪方法ASTS。2个孪生网络分别负责语义信息和外观信息,在外观分支上加入自动停止操作,当在简单帧时自动停止网络向前传播,此时不再与语义信息相结合从而提高跟踪速度,在复杂帧时,孪生网络的速度优势使得ASTS方法同样取得了较高的跟踪速度。实验结果验证了ASTS方法的高效性与高准确率。下一步将探究更好的注意力机制,并将深度特征与HOG特征进行融合,以提高本文方法的跟踪性能。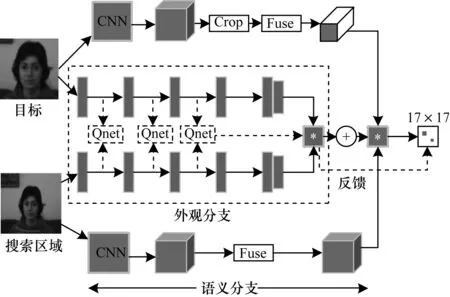
2.1 系统外观分支

2.2 系统语义分支
2.3 双孪生自适应网络
3 实验结果与分析
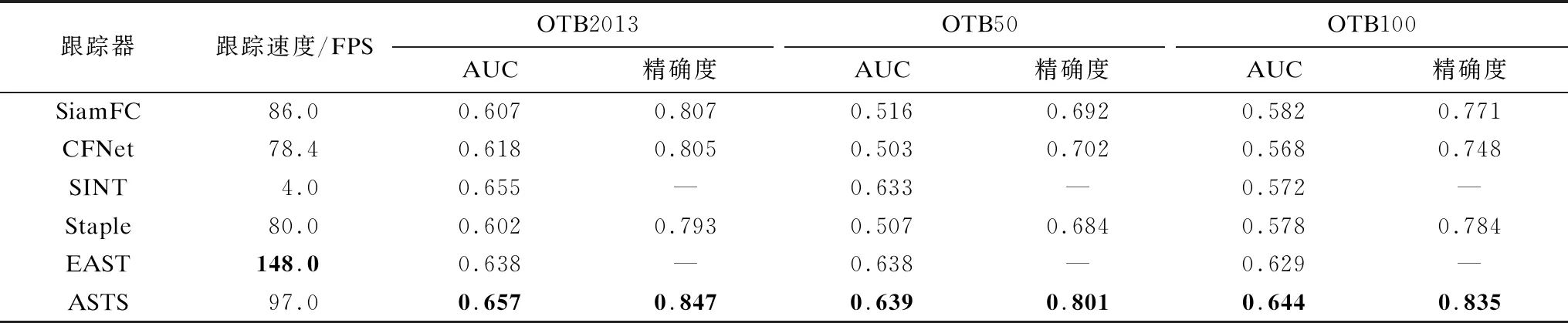
3.1 OTB基准实验
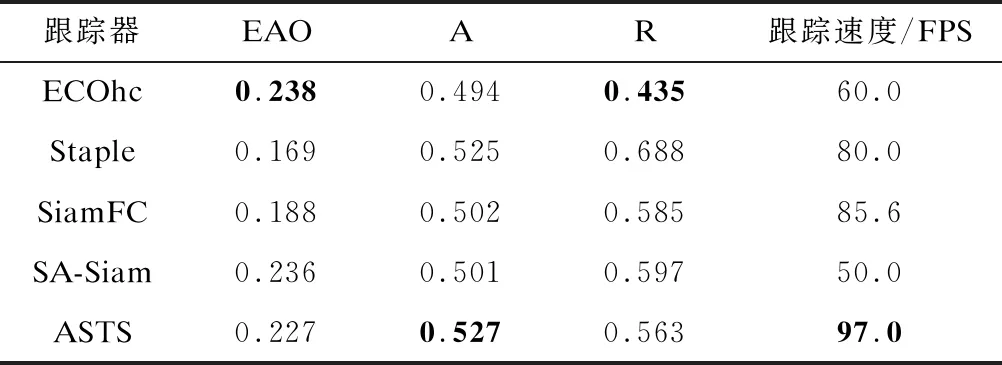
3.2 VOT基准实验

4 结束语
猜你喜欢
太阳能(2022年3期)2022-03-29
黑龙江大学自然科学学报(2022年1期)2022-03-29
数学物理学报(2021年4期)2021-08-30
科技研究·理论版(2021年22期)2021-04-18
太阳能(2020年3期)2020-04-08
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
学生天地(2019年28期)2019-08-25
当代工人·精品C(2019年2期)2019-05-10
计算机应用与软件(2017年7期)2017-08-12
