
基于图熵极值理论的领域概念聚类方法
2020-06-18 03:41安敬民李冠宇
计算机工程 2020年6期
安敬民,李冠宇
(1.大连东软信息学院 计算机与软件学院,辽宁 大连 116023; 2.大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 概述
在构建领域本体的过程中,需要设计本体自学习机制以便在后期可以自动补充和扩展本体。而在本体自学习过程中,同领域概念的聚类是关键步骤,其决定所构建领域本体在实际应用过程中所提供领域概念的准确性。
同领域概念聚类的传统方法主要有基于划分、基于层次、基于形式概念分析以及基于语义距离的方法。基于划分的方法需要人为设定划分的个数和穷举所有可能的划分情况,并给定递归算法将概念从一个划分移到另一划分来提高划分结果的准确性,典型算法为K-means[1-2]。基于层次的方法是将复杂概念网中每一个概念节点视为一个独立的聚类,利用领域一致度计算公式,迭代合并同领域概念,最终将复杂概念网分为多个领域的概念网,其中基于分布密度计算[3]的方法为主要代表。基于形式概念分析的方法主要采用概念格将对象分层,模糊概念格[4]和模糊K-means[5]是其中的代表方法。基于语义距离的方法主要通过计算领域概念在概念树中的距离进行聚类,目前有基于遍历树的蚂蚁聚类算法[6]和百科词条的本体概念聚类方法[7]等。文献[1-2]采用优化后的K-means方法选取并优化聚类中心,结合设定的聚类阈值实现同领域概念的聚类。文献[3]利用层次的耦合内聚比得到类数目的分布密度,通过密度聚类实现最终的概念聚类。文献[4-5]利用形式概念分析对概念的模糊处理能力,扩大了概念聚类范围,增强了聚类效果。文献[6]通过计算领域概念间的谷歌距离以及Wikipedia的距离和相似度实现聚类。文献[7]利用马氏距离得到概念向量间的语义距离,并通过多次迭代完成百科词条中的概念聚类。
上述方法是目前对于领域概念聚类处理的主要方法,但在聚类过程中均未考虑概念重叠问题,即一个概念(节点)可能同时属于多个领域,如“古董”一词,可以理解为“陈旧的事物”,同时也可以理解为“具有守旧思想的人”,因此,其同时属于两个领域的概念,而因为基于K-means划分和基于距离的方法所产生的概念集合总是不相交的,所以无法解决概念重叠问题。基于计算密度的方法和形式概念分析可以解决该类问题,但前者需要先选择初始种子概念作为聚类核心点,结合各概念周围的密度和设定的阈值,递归纳入新的概念并迭代循环执行(根据阈值会不同程度地在不同聚类结果中出现相同概念词汇),而在此过程中有较多的主观因素涉及其中(如选取初始概念),也是影响聚类效果的主要原因;后者虽然可以通过隶属模糊和上下位近似的方法保留更多的概念信息,解决概念重叠问题,但同样需提供若干个选定的聚类中心,仍然受到人为因素的影响。
本文提出以图熵最大化实现初始节点随机选择代替质心法,以图熵最小化保证聚类结果的准确性。基于中文WordNet[8]多角度计算概念间的语义相似度同时构建相似度矩阵,并将其转化为以概念为节点的无向图,利用图熵最小化计算公式[9]结合最大信息熵理论[10],使图中概念节点能够在无需选取聚类质心的情况下实现最优同领域概念聚类,同时解决领域概念重叠问题。
1 问题描述与定义
现代汉语中有许多词语具有一词多义的特点,即一个词语同时具有多个领域概念。所以,在对该类词语进行同领域概念聚类时,其结果应同时出现在不同领域,如图1所示(以概念领域Di和Dj以及其中的概念c1c8和ck为例),多个领域在概念上具有交集,而目前的概念聚类方法并不能很好地适用于该问题的处理(关于概念重叠问题的具体解释,此处不再赘述)。
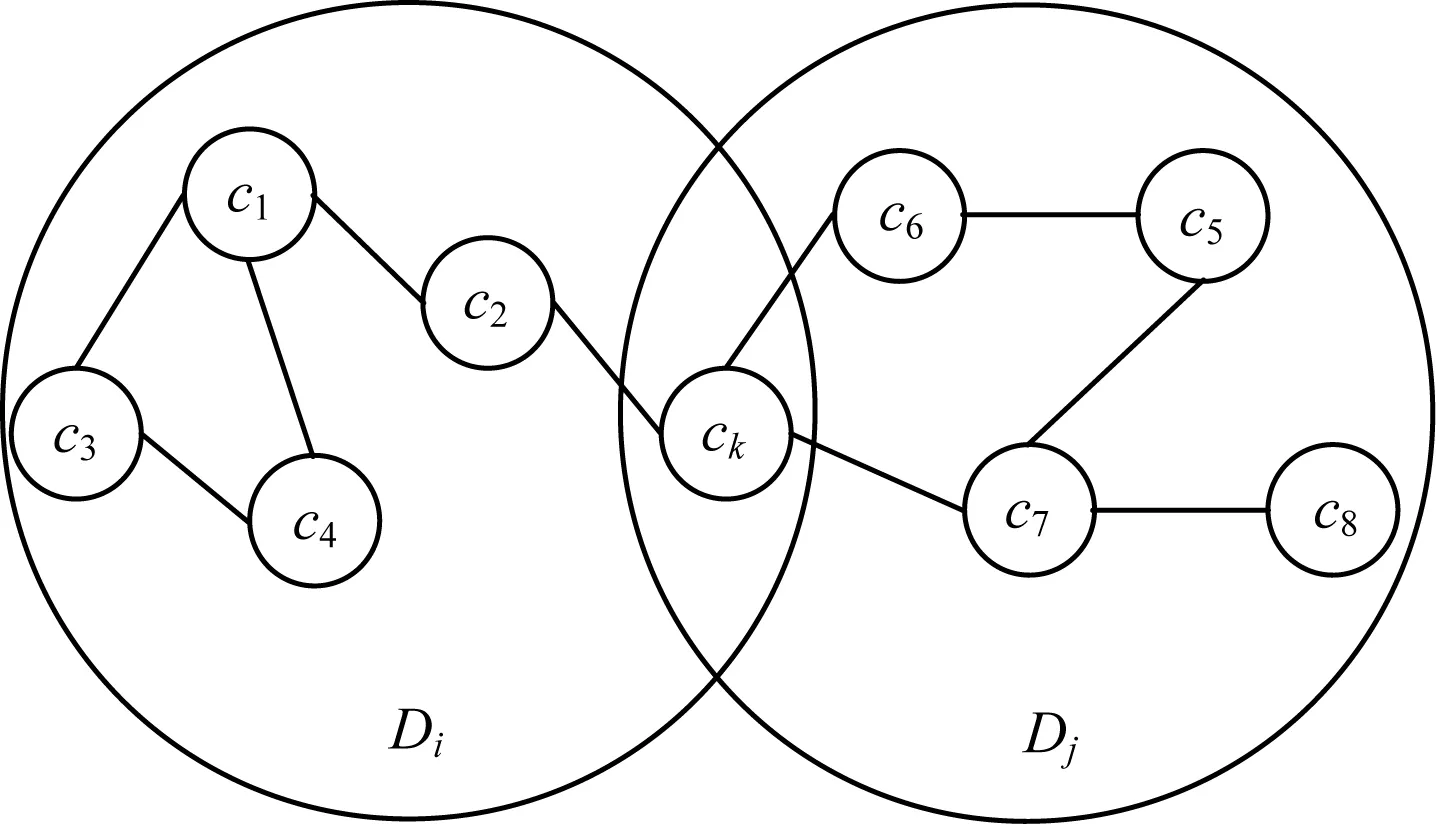
图1 领域概念聚类重叠示意图
从非结构化数据(如文本文档等)角度出发,对某个文本文档中的概念进行同领域聚类时,若ck被归类在Di中,则ck不会出现在Dj中,造成Dj中的概念缺失而使查全率和查准率降低,本文针对此问题进行研究。
定义1ck表示某个概念的词语,若ck使得ck∈Di且ck∈Dj,i≠j,则对ck进行概念归类时会产生概念重叠现象。
2 基于WordNet的概念相似度综合计算
在对同领域概念进行聚类之前,要将概念间的相似度量化,根据概念与概念间的相似度判断聚类的方式,同时相似度的精度也直接影响聚类结果的准确性。本文通过结合中文WordNet多角度计算概念间的相似度,提高相似度计算的准确性。
2.1 概念间相似度计算方法
目前基于WordNet计算概念间相似度的方法有从概念在WordNet中的语义距离[11]、深度及密度[12]角度出发,或者考虑概念的语义重合度和概念包含的语义信息内容[13]等方面相似度。本文结合文献[14]的设计思想,对各角度语义相似度计算方式进行综合考量,以提高概念相似度的精度。
基于WordNet中语义距离D(c1,c2)的概念间相似度表示为CS(c1,c2),计算公式如式(1)所示:
(1)
其中,a是c1、c2对中文WordNet中概念集合的平均语义距离。
以Hmax(c1)和Hmax(c2)分别表示c1、c2所在语义树的最大深度,H(c1)和H(c2)分别表示c1、c2在树中的深度,则基于WordNet中语义树及概念深度的概念间相似度计算公式如式(2)所示:
(2)
用n(c)表示语义树中以c为根节点的直接子节点数,nmax(O)表示与c所在同一语义树O中的所有节点的直接子节点最大值,结合文献[12,14]计算概念相似度的方法,给出基于WordNet中语义树及概念密度的概念间相似度计算公式如式(3)所示:
(3)
若将从c出发到语义树根节点所经过的节点个数记为S(c),则c1、c2基于WordNet语义树的语义重合度计算公式如式(4)所示:
(4)
将式(4)结合文献[15-16]中的概念信息内容相似度计算方法,得到式(5):
(5)
其中,I(c)的计算公式见文献[13-14]。
2.2 概念间相似度综合计算
为提高概念间相似度计算的精确度,本文从多角度考虑对概念相似度有影响的因素,并将其以权重加和的形式作为综合计算结果。为使综合计算结果更具客观合理性,引入主成分分析法[17]代替人为设定影响因子的方式。
构建矩阵α=(xi1,xi2,xi3,xi4,xi5)T,i=1,2,3,4,5。其中xi由形如β=(CS,HS,PS,SS,IS)的向量组构成。利用主成分分析法将α降为一维矩阵γ=[x′1,x′2,x′3,x′4,x′5],并利用降维过程中得到的特征值计算主成分贡献率(q1,q2,q3,q4,q5),最终得到概念间相似度综合计算公式为:
KSIM(c1,c2)=q1x′1+q2x′2+q3x′3+q4x′4+q5x′5
(6)
3 同领域相似概念结构图
3.1 概念相似度矩阵
根据本文2.2节中两个概念间的同领域综合相似度KSIM,按照对应概念ci和cj两个维度来构建概念相似度矩阵:
RSIM(ci,cj)=
其中,1≤i≤n,1≤j≤n。
在矩阵RSIM中,对角线部分是同一概念的相似度值,有KSIM(ci,ci)=1,但由于在实际的领域概念聚类过程中强调不同概念的聚类,因此该值并无应用意义。为简化聚类操作,令KSIM(ci,ci)=0。
3.2 同领域相似概念的图构建
设定阈值λ,当矩阵RSIM中KSIM(ci,cj)大于λ时,将该值重新设定为1;反之,若小于λ,则设定为0。经过化简后的矩阵R′SIM为一个只含有元素0、1的矩阵。
将简化得到的概念相似度矩阵R′SIM转化为概念间的关系无向图G(V,E),其中,V表示图中的概念节点(顶点),E表示概念节点间的边。若在相似度矩阵R′SIM中KSIM(ci,cj)=1,则概念ci、cj对应的顶点Vi、Vj间存在无向边Eij;反之,若KSIM(ci,cj)=0,则说明概念间不存在无向边。最终形成同领域相似概念的图结构,如图2所示(以c1c7和cn为例)。
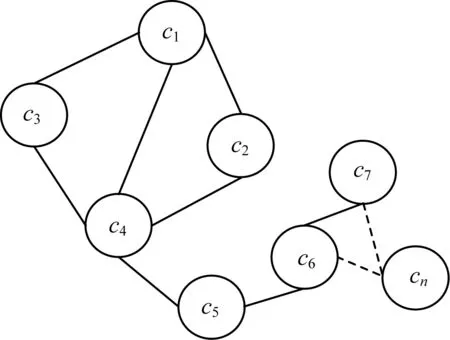
图2 领域Di中的相似概念结构图
4 基于图熵的领域概念聚类优化
从信息论的最大信息熵理论角度出发,将图中的各个节点视为一个整体,而没有主客之分,即在本文的聚类过程中,区别以往传统的以聚类质心为主的聚类方法,而是将已聚类的节点作为整体,通过图熵最小化理论计算出下一步的最优聚类结果。利用图熵的聚类方法可以在每次聚类结果输出后保留原文本文档中已被聚类到某领域的概念,从而解决概念重叠问题。
设已构建的同领域相似概念结构图G(V,E)的子图G′(V′,E′),对G′的内连接节点和外连接节点定义如下:
定义2在G′(V′,E′)和G(V,E)中,vi∈V′,vj∈V,且
在图G′(V′,E′)和G(V,E)中,点vi的内连接率表示为Pin(vi),外连接率表示为Pout(vi),计算公式分别为:
(7)
Pout(vi)=1-Pin(vi)
(8)
其中,n表示vi的内连接节点数,N(vi)表示vi的内外连接节点数之和。
4.1 相似概念结构图的图熵处理方法
若设同领域相似概念结构图中某概念节点ci的熵值[18-19]为e(ci),结合信息熵[20]公式和ci的内外连接节点,有:
e(ci)=-Pin(ci)lbPin(ci)-Pout(ci)lbPout(ci)
(9)
文献[9]指出,图熵可定义为所有节点的熵值之和,即:
(10)
若每次聚类后得到的e(G)最小,则此时同领域相似概念聚类为最优。图3中虚线框内为经过若干步聚类后得到的最优聚类集合,以加入c4概念节点为例,判断当前e(G)的变化情况。结合上文公式可知:加入c4前,计算得到e(c1)=0.92,e(c2)=e(c3)=1,e(c4)=0.81,e(c5)=e(c6)=e(c7)=e(cn)=0,则e(G)=3.73;加入c4后,e(c1)=e(c2)=e(c3)=0,e(c4)=0.81,e(c5)=1,e(c6)=e(c7)=e(cn)=0,此时e(G)=1.81。由此可见:加入c4可使图熵减小,聚类结果优化;反之,若使图熵e(G)增大,则拒绝加入c4。
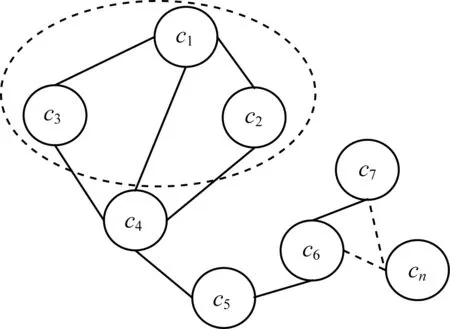
图3 聚类过程中图熵e(G)变化示意图
4.2 基于图熵的领域概念聚类优化算法
从给定的图G中任意选取一个概念节点ci作为起始点,结合最大信息熵原理和图熵最小化计算公式,最终形成一个满足同领域Di最优概念聚类的子图G′ (概念集合),具体算法如下:
输入含有各领域概念的文本文档
输出领域Di的概念聚类集合表
1.根据领域Di给定的概念,抽取文本文档中的同领域相似概念,构建领域的相似概念结构图G(V,E)
2.令V′=∅
3.For 在G中任意选取一个节点ci∉V′作为聚类起始点 do
4.{遍历ci的所有邻居节点,并与ci形成一个聚类子图G′
5.For G′中的V′≠∅ do
6.{If 删除G′中的cj后e(G′)变小
7.G′.Delete(cj)
8.Else Continue}
9.For G′外存在V′的邻居节点 do
10.{If 加入G′外的ck后e(G′)变小
11.G′.Add(ck)
12.Else Continue}
13.Return List(G′)}
在给定具有各领域概念的文本中,利用文献[2]提出的领域概念相关度和一致度计算公式抽取领域概念,并结合概念相似度综合计算公式,构建同领域相似概念的相似度矩阵,并将其转化为对应的图关系,通过图熵理论优化聚类结果。由于在此过程中聚类的对象是由文本文档构建的同领域相似概念结构图,因此聚类后原文档中的概念并未删除,使再次聚类某领域概念时仍可以抽取已被聚类过的概念,从而解决领域概念重叠问题。
该算法首先任选图G中的某个节点ci并遍历其邻居节点构建子图G′,此过程时间复杂度为O(n);然后计算影响G′中图熵值增大的节点,并做删除操作,此过程时间复杂度为O(n×m);最后增加G′外使图熵减小的邻居点,此过程时间复杂度为O(n×p)。所以,算法总的时间复杂度为O(n×m+n×p),即O(n2)。
5 实验与结果分析
本文设计基于图熵极值化理论的领域概念聚类方法,旨在对传统概念聚类方法在聚类查准率(Precision)上的优化以及对概念重叠问题的处理,从而提高查全率(Recall)。所以,本文从领域概念的查准率和查全率以及综合评估指标F值3个方面将其与传统领域概念聚类方法进行对比。
本文实验环境是在Windows10下搭建的实验平台,主要包括Microsoft.NET framework和SQL Server 2012 database,使用C#语言实现。选择由全国科学技术名词审定委员会审定公布的领域概念集合(http://www.cnctst.cn/)作为实验数据集,从中选取12个不同的领域概念各500个,将其混合后再以逐次增加数据的方式分为4组实验数据集,分别为800个、1 200个、1 800个和2 200个领域概念。
由于本文贡献点在于处理中文领域概念聚类和聚类过程中的概念重叠问题,因此与文献[1,3,7]方法在领域概念查准率、查全率以及综合评估指标F-Measure值3个方面进行对比,并使用文献[2]中的计算公式,如式(11)~式(13)所示:
(11)
(12)
(13)
其中,N为聚类后属于领域Di的概念个数,M为聚类后领域Di中的概念个数,A表示所有文档的概念中属于Di的概念个数。
通过实验获得的聚类结果以及Precision和Recall指标计算公式,得到表1和表2所示的对比结果。
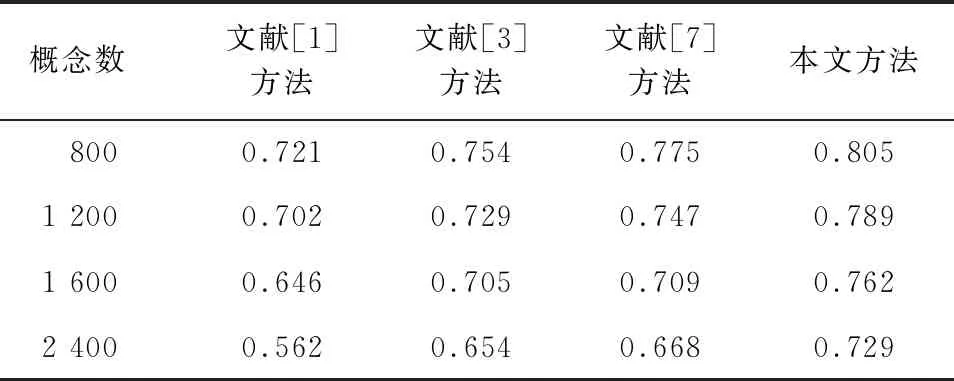
表1 4种方法的查准率对比
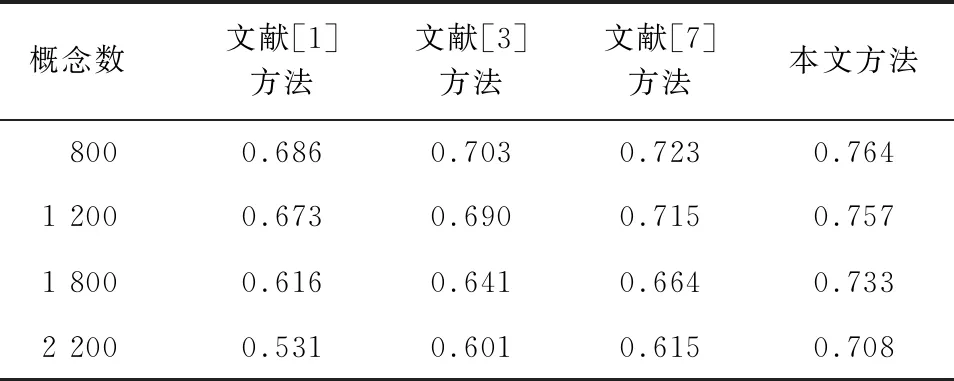
表2 4种方法的查全率对比
为减小实验比较误差,将表1和表2中的查准率与查全率数据结合式(13)计算出4种方法在混合领域概念聚类上的F值,比较结果如图4所示。
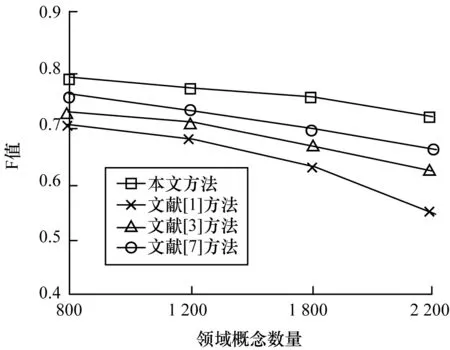
图4 4种方法的F值对比
从图4可以看出,4种方法在第一次实验时,相互间的F值差距不明显,最低的文献[1]方法为0.703,而最高的则是本文方法达到0.784。随着实验的进行,本文方法相比其他方法优势逐渐明显,在数据量为2 200的第4次实验中,本文方法优势最为明显,与基于传统K-Means划分方法的文献[1]方法相比F值提高近30%,同时基于密度计算的文献[3]方法和基于距离计算的文献[7]方法相较于本文方法F值下降幅度也较为明显。
经分析每组实验数据可知,随着概念数据量增加,概念重叠情况也随之增多,文献[1]方法对于该问题无法处理,文献[3,7]方法对其稍有作用,但文中并未提及和考虑该问题,没有提出有针对性的解决方案。本文方法在概念聚类过程中能够在保证原有聚类效率的前提下解决重叠问题,提高了概念聚类性能。
6 结束语
本文针对领域概念聚类过程中的概念重叠现象,提出基于图熵极值理论的领域概念聚类方法。利用图熵原理和在生成概念聚类的过程中不删除原文本领域概念的方法,优化聚类结果,提升查全率、查准率及F值。实验结果验证了该方法的有效性。但本文方法中阈值的选取仍为人工设定,受到主观因素影响,因此,下一步将研究不同阈值的选取对聚类性能的影响,并设计阈值自动生成机制。
猜你喜欢
防爆电机(2022年4期)2022-08-17
开放教育研究(2020年2期)2020-03-31
中国眼镜科技杂志(2019年9期)2019-11-11
现代电子技术(2018年20期)2018-10-24
现代情报(2018年11期)2018-01-07
高中生学习·高二版(2017年9期)2017-10-25
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
中国工程咨询(2014年3期)2014-02-16
