
基于强化学习的煤层气井螺杆泵排采参数智能决策
2020-06-16 05:23:42檀朝东蔡振华邓涵文刘世界秦鹏王一兵宋文容
石油钻采工艺 2020年1期
檀朝东 蔡振华 邓涵文 刘世界 秦鹏 王一兵 宋文容
1.中国石油大学(北京);2.中海油能源发展股份有限公司工程技术分公司;3.新疆中泰集团有限公司;4.北京雅丹石油技术开发有限公司
煤层气开采是通过持续排出煤层(或是侵入煤层)中的水,降低储层压力,使储层压力降低至甲烷的解吸压力后,吸附在煤基质孔隙中的甲烷气体解吸,经过扩散、渗流进入井筒中[1]。因此,煤层气井排采要以井底流压控制为核心,实现流压平稳下降。流压精细控制的主要目的是防止由于管理不善导致储层煤粉伤害、速敏伤害或应力敏感性伤害,保持煤储层渗透率,使压降漏斗有效扩展[2]。在20世纪80年代中期,螺杆泵在美国首次用于煤层气排采,并取得了良好效果。90年代中期,澳大利亚昆士兰进行首次螺杆泵试验[3]。螺杆泵用于煤层气开采比其他人工举升方式具有更多优势:处理大量生产固体的能力、本身不会发生气锁、相对较高的系统效率等。由于螺杆泵有较高排水和处理煤粉的能力,其在中国的煤层气开采中也有较广的应用,如鄂尔多斯盆地韩城区块有14%的井应用了螺杆泵,沁水盆地樊庄区块有44口水平井应用了螺杆泵进行排采[4]。因此研究螺杆泵的排采机理,优化螺杆泵排采参数,对中国煤层气井提高单井产量具有重要意义。
目前调整煤层气井排采参数需要地质技术人员凭经验对生产状况进行动态分析,不定时进行人工现场调参,这种方法依赖于工程师的经验知识,并受时间、地理位置及气候的影响。机器学习可以预测煤层气螺杆泵的运行寿命和优化运行参数,典型的机器学习(ML)算法需要数百万个数据点才能成功发现和预测煤层气螺杆泵排采优化模式[5]。但如果环境发生变化,不能迅速做出调整会使储层受到不同程度的伤害,使解吸过程受到阻碍,排采效果降低。并且由于环境问题的多变和复杂,建立好的控制模型随时面临变化,经常需要进行更改以适应新环境,不符合智能控制的根本需求。
针对以上问题,应用机器学习中的强化学习方法,通过控制螺杆泵的转速,建立煤层气某生产周期内产气量最大的强化学习模型。该方法通过与环境的交互式学习,对动态环境进行灵活的奖惩,实现智能体在复杂环境下智能决策和参数优化,在煤层气井螺杆泵排采参数优化控制问题上具有实时调整参数设置、自适应环境变化和无需大数据进行训练的优势。该方法能提高螺杆泵排采效率,使煤层气井按照生产规律长期、连续、高效地进行开采,并提高整体开发效果和经济效益。
1 煤层气井螺杆泵排采强化学习模型框架
从优化控制角度,利用套压、动液面、井底流压、产水量、产气量的耦合关系,通过优化变频器的频率来调整它们之间的关系以得到一个合理的生产压差,实现煤层气井高产稳产的目标。
1.1 强化学习原理
强化学习的基本过程是一个马尔科夫决策过程,马尔科夫决策过程可以用状态(State)、动作(Action)、状态转移概率(Possibility)、状态转移奖励或回报(Reward)构成的四元组{s,a,p,r}表示[6]。对于离散时间MDP,状态和动作的集合称为状态空间(State Space)和动作空间(Action Space),分别用S和A表示,si∈S,ai∈A。根据第t步选择的行动,状态根据概率 P(st+1,st,at)从st转移到st+1,在状态转移的同时,决策主体得到1个即时奖励 R(st+1,st,at);其中,st为t时刻的状态,at为t时刻的动作。该过程结束时的累积奖励(Reward)为
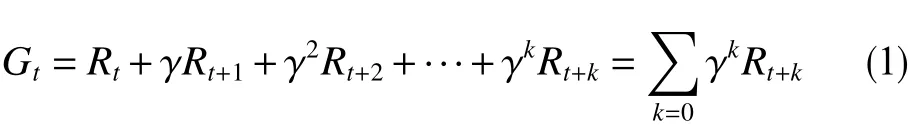
式中,Rt为时间t内累积的奖励;γ为折扣因子(discount factor),取值范围在0~1之间,用于削减远期决策对应的奖励权重。决策的最终目标是在抵达目标状态的同时实现累积奖励最大化。
近年来,强化学习算法由于决策能力强、环境适应度高,被较多学者用于工业自动化领域[7]。采用Q学习等算法,可有效实现控制策略的在线学习和动态优化决策,实现信息共享、交互协作,可追踪、协调自身行为,动作自寻优等[8-10]。
1.2 煤层气井螺杆泵排采的强化学习模型框架
控制合理的生产压差是煤层气井排采控制的重要因素之一。煤层气井的生产压差与套压、动液面、产气速率、产水速率等参数紧密相关。如图1所示,通过改变变频器的频率可以调整螺杆泵转速进而改变产水速率,从而控制动液面高度;调节气油嘴大小可以改变产气速率进而改变套压的大小,动液面和套压最终决定着井底流压的大小。
螺杆泵排采的强化学习模型架构如图2所示。状态st(state)是指煤层气井螺杆泵排采系统的排采参数(如动液面高度、套压、电参数)、产气量、产水量、井底流压等,在此次简化模型中只考虑产气量,在图中用RTU 数据采集装置表示;智能体(agent)可以理解为“神经中枢”,不仅能够感知当前状态以及在先前状态选择的动作效果,还具有调节频率以及和环境交互的能力,智能体负责做出决策,如增大频率、保持频率不变、减小频率等,即为模型中的动作at(actions);变频器在接收到智能体的动作信号后会及时调频,反映在螺杆泵上就是使其转速增大、减小或不变,在做出动作之后会得到环境的反馈,这里的环境是指包括储层在内的整个排采系统;环境的功能是输出执行动作后系统的状态以及该动作产生的效果,比如频率增大会使日产气量增大,频率减小会减缓储层能量的衰减速度等,这些反馈数值量化之后,就是模型中的奖励(rewards)。以上4个要素构成了煤层气井螺杆泵排采系统的基本框架。
2 螺杆泵排采参数优化的强化学习模型
2.1 动作集
煤层气井螺杆泵排采过程的主要控制量包括动液面和套压,这2个量与电机频率和油嘴的大小直接相关。由于在现场油嘴大小的改变不像变频器一样实时调整,因此研究只对单井的变频器建模。设系统中一共有n口煤层气井,控制动作设置为n维的列向量,其中第0 维到第n−1维的特征量分别井1到井n的变频器频率控制v1,v2,…,vn,即动作空间为

按照智能系统的调控方式,规定变频器的动作特征量为(i =1,2,···,n)

每当智能体给1口井的变频器1个反馈(1,0或−1),则该井的变频器会在原来的频率上增加、不变、减少∆v赫兹,则其中∆v大小的设置应根据实际运行情况确定。参数过小会导致收敛速度缓慢,参数过大则会导致系统运行不稳、无法收敛等问题。
2.2 状态集
该模型主要基于煤层气产能最大化的目标,因此需要选择与产量直接相关的属性作为状态空间,其中包括每口单井的产气量q1,q2,…,qn。因此,煤层气井螺杆泵排采系统的运行状态量是一个n维的列向量,则状态空间为
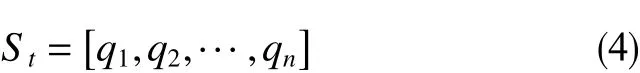
2.3 动作选择策略
在与环境交互的初始阶段,智能体对系统没有清晰的认识,也不知道如何表现才能使奖励最大化。因此,它应该在最初的回合中探索环境以获得所需的知识和经验,在训练的最后回合,智能体有足够的经验去利用所获得的知识。任何行动选择策略都应该提供这种探索/利用权衡的特性。
2.3.1 玻尔兹曼分布(Boltzmann Distribution)策略
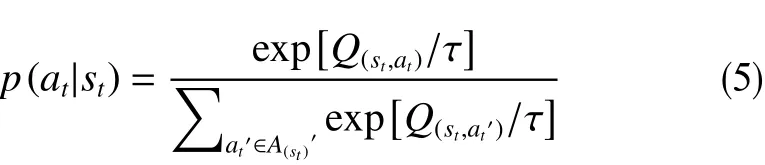
式中,p(at|st)为智能体在状态st采用动作at的概率;Q(st,at)为 动作状态的价值;A(st)′是状态st下可做动作A(st)的一个子集,根据先前状态st−1中选择的动作at−1而确定。
该策略的含义是,动作值函数大的动作被选中的概率大,动作值函数小的动作被选中的概率小。在实际应用中,将任何一系列输入动作应用于系统是不实际的,因此输入值的推导应受到限制。因此,状态st中选择的动作,应位于动作at−1的附近,由集合A(st)′表示;而不是来自A(st)的任何动作。这里,利用温度系数τ(τ>0)控制探索/利用特征。高温导致更多的探索,动作选择更加随机。低温导致更多的利用,动作选择更加贪婪。也就是说低的温度系数会使智能体选择价值最高或相应奖励最高的动作。此外,在每个回合的学习过程中,温度系数都会按照以下更新规则进行更新。

式中,ζ为学习率,取值范围在0~1之间,决定了智能体从环境探索到获取经验知识进行利用的速率。
在学习过程结束时,策略是完全贪婪的,在每个状态下,智能体会选择状态-动作价值最高的动作。参数ζ决定了从环境探索到获取经验知识进行利用的过渡阶段。ζ应以一种柔和的方式进行调整,使智能体在学习过程中有足够的探索/利用的时间。
2.3.2ε-greedy 贪婪策略
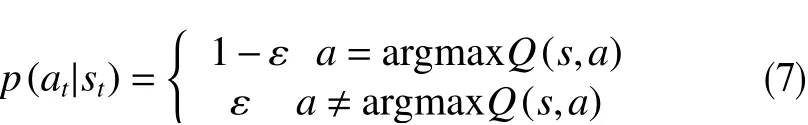
式中,ε为贪婪因子,取值范围在0~1之间,决定了模型随机选择一个动作来获取奖励的概率;argmaxQ(s,a)为在状态s下价值最大的动作。
该策略的含义是,智能体在采取动作的时候,会有1−ε的概率选择使得Q值最大的动作,随着训练时间变长,ε的值逐渐减小,在后期智能体选择最大Q值对应的动作会增大。这种策略使模型将会有一定概率随机选择1个动作来获取奖励,保证模型更新的可行性。ε-greedy 是强化学习中最常见的随机策略,研究将采用ε-greedy 作为动作选择策略。
2.4 奖励
煤层气螺杆泵排采系统在一定的排采运行状态下会对不同的动作产生反馈,这种反馈体现在对系统的奖励或者惩罚上。系统的最终目标是通过对动作决策的优化,达到最大化奖励的目的,实现最优化控制的效果,而奖励的规则应使其最大值与主要问题的优化等价。
设定奖励值R为控制动作a和煤层气螺杆泵排采运行状态s的函数为

式中,R(a,s)为控制动作a和煤层气螺杆泵排采运行状态s的函数。在每个回合的开始,将随机产生一系列的状态值si=1,si=2,…,si=n;每当走到i=n个时间步时,将环境产生的状态值si=n'相同时间步长的随机状态序列的值进行对比,如果si=n'大于si=n,则智能体会给出一个正向的奖励,R(a,s)=1;如果si=n'等于si=n,智能体给出的反馈是不奖励也不惩罚;如果si=n'小于si=n,则R(a,s)=−1。奖励值的设定不是既定的,可以根据实际问题进行调整。如果奖励函数的设定不合理,则会导致模型不收敛等问题。
2.5 更新规则
不同强化学习方法主要根据不同的更新规则来区分,这些更新规则影响学习率、收敛率、稳定性和最优获得奖励等特性。例如,虽然大多数经典学习方法,如蒙特卡罗或时间差被认为是奖励平均方法,但不同方法的平均过程中存在的差异会导致不同的特征以及不同的计算复杂度[11]。
采用Sarsa 机制进行更新。与Q学习相比,Sarsa机制无须对新状态的动作价值函数(即Q值)做最大评估,而是直接利用当前选择的策略执行,更适用于煤层气螺杆泵排采的运作特征,具备较好的收敛性和反馈效果。设Q(s,a)是智能系统在状态s下采用控制动作a的价值,Q0(s,a)为先前价值,Qn(s,a)为更新后的价值,Sarsa 采用的更新机制为
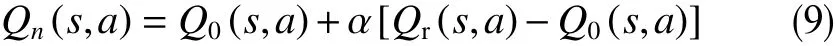
式中,Q0(s,a)为先前价值;Qr(s,a)为现实价值,即执行动作后的环境反馈;α为学习速率(learning rate),取值范围在0~1之间,决定了Q表更新的速率。
假设系统在状态s1执行了控制动作a1,智能系统状态由此转移到状态s2,之后系统执行动作a2,而现实价值Qr(s1,a1)是 奖惩值R(s1,a1)和先前价值Q0(s2,a2)的叠加作用为

其中,γ表示状态s1采用控制动作a1的价值与下一状态和动作(s2,a2)的关联性衰减了。可以看出,系统每次执行控制动作,都可以对上一个状态下的执行动作进行价值的更新。
3 煤层气井螺杆泵排采的强化学习算法
3.1 Q 学习
Q学习是一种经典的基于价值的强化学习算法,Q即Q(s,a),指的是动作效用函数(action-utility function),用来评价特定状态下采取某个动作的优劣,即为智能体在某一时刻的s状态下采取动作a能够获得的“分数”。算法的主要思想就是将状态与动作构建成一张Q表来存储Q值(表1)。对于不同的状态而言,采取不同动作会得到不同的结果,记录某个状态和动作二元组的分数能够让智能体在无数次试验和错误后记住当前的最优决策,即最大Q值的决策。训练到一定程度后,智能体会根据Q值来选取能够获得最大收益的动作。

表1 Q 表框架Table 1 Framework of Q meter
Q值的更新公式为
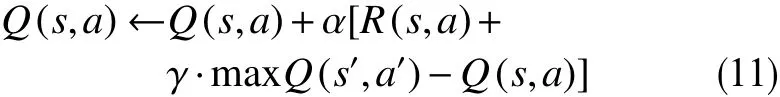
式中, maxQ(s′,a′)为在状态s′下的最大价值。α学习速率越高,意味着保留过去记忆的程度越低;γ折扣因子越大,意味着m axQ(s′,a′)对结果的影响越大。
该公式的含义:智能体在状态s下执行动作a后转移到状态s′,然后从状态s′中选取最大的Q(s′,a′)乘以折扣因子γ加上获得的奖励,并将它作为Q现实,而根据过往Q表里面的Q(s,a)作为Q估计,而新的Q(s,a)就等于Q现实与Q估计的差值乘以学习率α再加上Q估计。综上可得煤层气井螺杆泵排采的Q学习算法流程如下。
(1) 初始化Q={};
(2)While Q未收敛;
(3) 在螺杆泵变频器频率调节的阈值里随机选择一个频率,并将该频率下对应的产气量作为初始状态s,然后进行新一轮控制;
(4)While s!=控制结束/系统损坏;
(5) 使用基于ε-greedy 的策略π,获得调频动作a=π(s);
(6) 使用调频动作a进行控制,获得系统的新状态s′,与奖励R(s,a);
(7) 更新Q,Q(s,a)←Q(s,a)+α[R(s,a)+γmaxa′Q(s′,a′)−Q(s,a)];
(8) 更新s,s←s′。
3.2 Sarsa 和Sarsa(lambda)
Sarsa 算法在Q学习的基础上进行了改进,是相较于Q学习而言更为保守一种算法,Q学习和Sarsa 分别属于离线学习(off-policy)和在线学习(on-policy)的范围。在线学习是根据每一步决策进行优化,类似于说到做到的效果,而离线学习可以从过去的经验和他人的决策中进行学习,不完全依赖于实时反馈的更新,所以两者产生的效果也不同。
Sarsa 的更新Q表的公式为
鬼子军官说声有戏。挥手让一个站着的鬼子端来把椅子,然后以手拄刀坐了,一边用手在刀把打着拍子,一边盯着汪处长几个说,你们的什么的干活,自己说了的有。

煤层气井螺杆泵排采的Sarsa 算法流程如下。
(1)初始化Q={};
(2)While Q未收敛;
(3) 在螺杆泵变频器频率调节的阈值里随机选择一个频率,并将该频率下对应的产气量作为初始状态s,然后进行新一轮控制;
(4) 使用基于ε-greedy 的策略π,获得智能体调频动作a=π(s);
(5)While s!=控制结束/系统损坏;
(6)使用调频动作a进行控制,获得系统的新状态s′,与奖励R(s,a);(7) 使用基于ε-greedy 的策略π,获得动作a′=π(s′);(8)更新Q,Q(s,a)←Q(s,a)+α[R(s,a)+γQ(s′,a′)−Q(s,a)];
可以看出Sarsa 的整个循环都在一个路径上,取行动a后在s′估算的动作也是接下来一定执行的动作。而Q学习只会在s′观察接下来的动作哪个奖励最大,其实智能体的下个一个状态-动作在算法更新时是不确定的。在实际中,如果比较在乎机器的损害,使用保守的Sarsa 算法在训练时能减少损坏的次数。而Sarsa(lambda)算法与Sarsa 的不同则是它增加了矩阵E来保存在路径中所经历的每一步,引入λ来控制衰减幅度。煤层气井螺杆泵的Sarsa(lambda)算法流程如下。
(1) 初始化Q={};
(2)While Q未收敛;
(3) 初始化E={};
(4) 在螺杆泵变频器频率调节的阈值里随机选择一个频率,并将该频率下对应的产气量作为初始状态s,然后进行新一轮控制;
(5) 使用基于ε-greedy 的策略π,获得调频动作
a=π(s);
(6)While s!=结束;
(7) 使用调频动作a进行控制,获得系统的新状态s′,与奖励R(s,a);
(8) 使用基于ε-greedy 的策略π,获得动作a′=π(s′);
(9) 更新δ,δ ←R(s,a)+γ[Q(s′,a′)−Q(s,a)];
(10)更新E,E(s,a)←E(s,a)+1;
(11)对所有的s和a,更新Q和E;
(12)更新Q,Q(s,a)←Q(s,a)+αδE(s,a);
(13)更新E,E(s,a)←γλE(s,a);
(14)更新s和a,s←s′;a←a′。
其中,δ是中间变量,用来暂时存放Q现实和Q估计的差值;E(s,a)为关于s,a的矩阵,用于保存在路径中所经历的每一步,应用于Sarsa(lamda)算法中;λ为衰减系数,取值范围在0~1之间,用于控制衰减幅度,应用于Sarsa(lamda)算法中。该算法使状态优化变得平滑,越靠近奖励的步骤越重要。这种改变使得智能体能够更加快速有效地学习到最优策略。
4 煤层气井排采的强化学习模型实验分析
为验证煤层气井螺杆泵排采强化学习模型的可操作性,开展了编程和计算分析研究。实验不直接对煤层气的地层环境建模,而是通过产气量的变化间接反映出储层能量的变化规律。已知煤层气产气量的变化是一个先增加后减小、维持最大产气量生产时间较短的过程,将依照此规律构建一个随机环境。由于本文通过最简单的强化学习思路来初步塑造煤层气排采参数优化的结构,为了避免内部计算的复杂性,以单井为研究对象,只考虑变频器的动作而不考虑气嘴调节阀的动作,产气量和生产周期的设定都被简化,其值的大小只为了反映其变化趋势。
4.1 实验准备
(1) 先令生产周期T=365,时间步长∆t=1,则T=[1,2,3,···,365]。令产气量Q和T的关系满足Q=−k(x−a)2+b这样一种二次函数的关系,其中k,a,b等 3个系数的设定应使Q在T∈[1,160]恒定大于0。通过增加噪声,使曲线的走向由平滑变成震荡,使之更符合实际的变化趋势。通过python 编程,可以得到产气量和时间的变化趋势,如图3 所示。
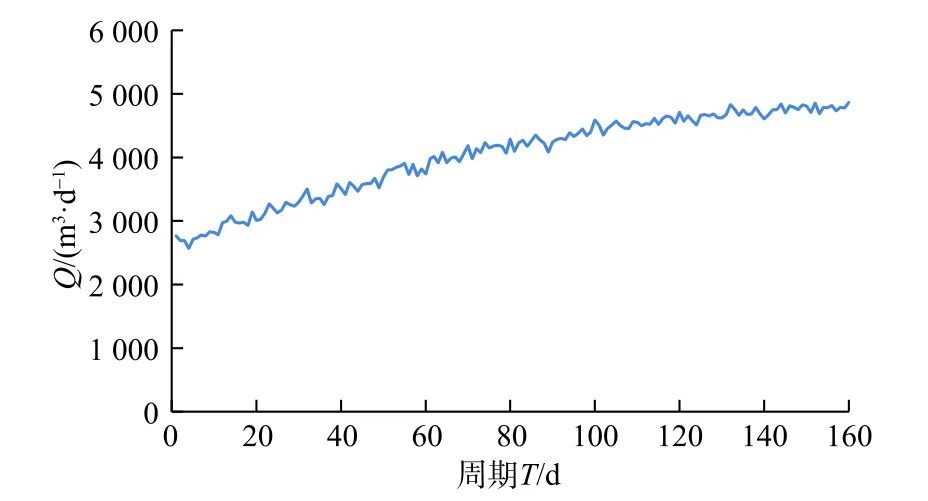
图3 Q 和T 的变化趋势Fig.3 Change trend of Q and T
(2) 引入高斯函数,令每个T对应的Q为均值,随机产生符合正太分布的n个数值,即当T1=1,令μ=Q1,δ=1,如图4所示。
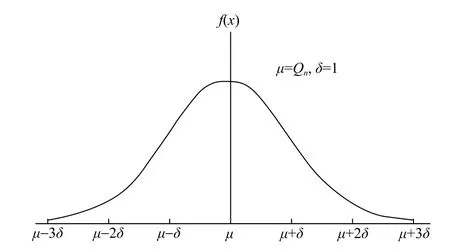
图4以Q 为均值的正态分布Fig.4 Normal distribution with Q as the mean value
(3)实验中令n=33,于是便产生了n×T个产气量值。至此可以将环境构建成一个33×160的表格,每一列表示以Qn为均值产生的33个正态分布随机数,以从小到大的顺序放入格子,如图5所示。
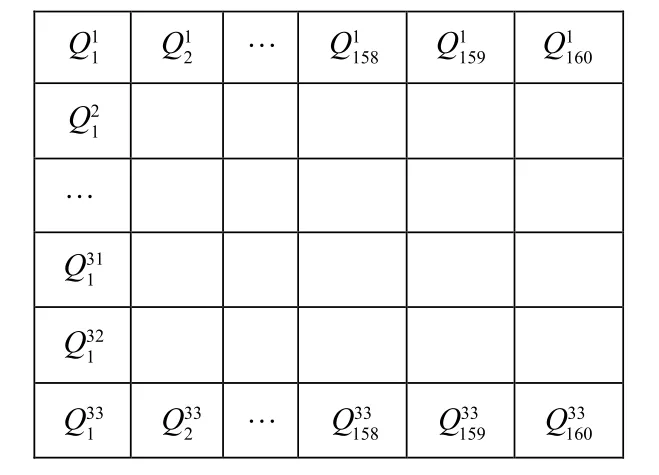
图5格子环境Fig.5 Lattice environment
(4)每次智能体执行使螺杆泵频率增大的动作后,环境反馈给智能体的状态落在产气量较大区间的概率更大,但是该动作也会增大地层能量的衰竭速率,因此引入一个衰减系数β,使智能体不会一直选择使螺杆泵频率增大的动作。衰减系数β取值范围在0~1之间,使智能体不会一直选择使螺杆泵频率增大的动作不同的动作对应的β值不同,实验的状态空间a=[−1,0,1],β的取值应满足 βa=−1<βa=0<βa=1。因此Q表更新公式变为

4.2 实验结果分析
实验开始时,令贪婪因子ε=0.1,使智能体每次选择动作时,有90%的概率会选择Q值最大的动作,10%的概率会随机探索。令∆t=1,即智能体每次从动作空间选出一个动作,则变频器的频率会相应的增加或减少1 Hz,或者保持原来的频率不变。设变频器的初始频率为75 Hz,阈值为[60, 90]。经编程运行,基于Q学习的煤层气螺杆泵优化控制模型的训练奖励值变化如图6所示,其累积产气量随训练轮数的变化曲线图7所示。
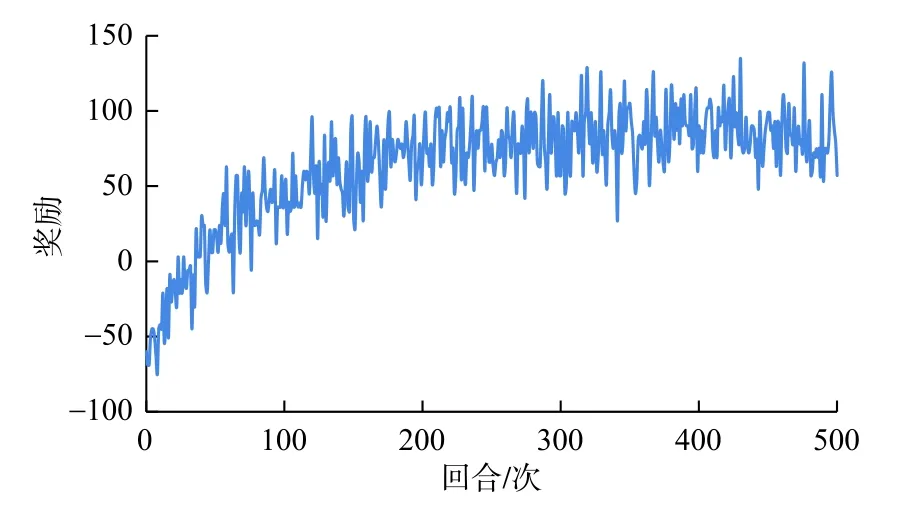
图6 RL 模型奖励值变化曲线Fig.6 Reward of RL model
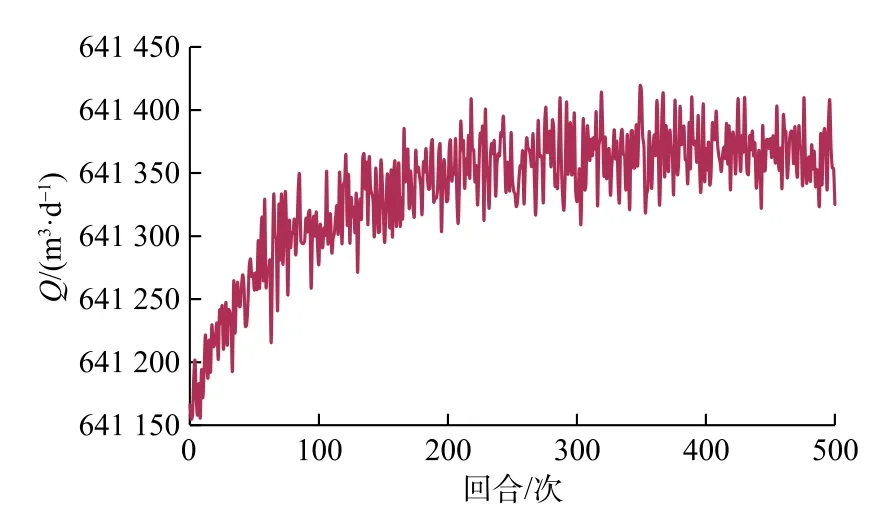
图7产气量变化曲线Fig.7 Gas production rate
图6、图7的横轴表示总的训练回合数,实验一共训练了500回合,纵坐标表示每一个回合累积的奖励值。从图中可以看出当训练到400回合左右的时候,智能体已经学会了一系列控制动作,使得目标值达到最大。这也证明了基于Q学习强化学习模型在状态空间较小的情况下可以较好的收敛。奖励值变化曲线呈现一种震荡的效果是因为,始终保持了一定的探索/利用概率。
为了具体反映智能体的学习过程,实验做出了智能体动作选择曲线以及相应变频器频率变化的曲线。如图8所示,出当智能体进行400回合的学习后,智能体已经学到了如何选择动作使得总产气量最大,此时累积奖励基本稳定。如图9所示,该图反映了智能体还在进行学习,Q表在构建过程中,很多动作—状态的值还未被探索或更新,奖励值还在增大。
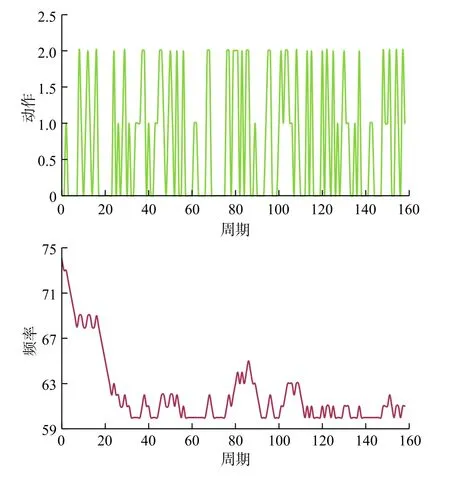
图8第100回合的学习曲线Fig.8 Learning curve of the 100th round

图9第400回合的学习曲线Fig.9 Learning curve of the 400th round
5 结论
(1) 基于强化学习的煤层气排采优化控制方法,通过自动优化变频器的频率来调整排采参数之间的关系可以得到一个合理的生产压差,实现煤层气井高产稳产的目标,解决了传统方法不能根据环境变化迅速做出调整而降低排采效果的问题。
(2)采用强化学习模型框架和Q学习、Sarsa、Sarsa(lambda)等算法,可有效开展煤层气螺杆泵排采控制策略的在线学习和动态优化决策,实现信息共享、交互协作,可追踪协调自身行为,动作自寻优。实验分析表明,应用Q学习模型可快速得到指定产气量变化曲线的螺杆泵排采变频控制的策略。
(3) 强化学习目前仍处于兴起阶段,属于人工智能的新兴研究领域,在石油工程领域拥有广阔的发展空间和美好的应用前景。在后继模型框架设计时,可以考虑结合基于大数据的神经网络深度学习算法。通过多智能体框架可以增加模型复杂度,优化控制动作,增加状态空间,优化奖励设计机制,使排采控制更加智能、快捷、精准。
猜你喜欢
设备管理与维修(2021年12期)2021-07-28 02:40:04
西南石油大学学报(自然科学版)(2019年5期)2019-12-20 07:00:56
意林·全彩Color(2019年8期)2019-11-13 09:23:32
中国煤层气(2019年2期)2019-08-27 00:59:38
中国煤层气(2019年2期)2019-08-27 00:59:30
测控技术(2018年12期)2018-11-25 09:36:58
录井工程(2017年3期)2018-01-22 08:39:56
中国设备工程(2017年16期)2017-08-30 10:23:42
领导文萃(2017年10期)2017-06-05 22:27:01
中国煤层气(2015年6期)2015-08-22 03:25:29
