
民航空管大数据处理平台架构研究
2020-06-16 10:40潘卫军刘铠源王润东左青海
计算机应用与软件 2020年6期
潘卫军 刘铠源 王润东 左青海
(中国民用航空飞行学院 四川 广汉 618300)
0 引 言
大数据是近年来受到各行业普遍关注的新概念,大数据技术指通过新的数据处理分析技术对体量大、类型多、来源复杂的结构化、半结构化和非结构化数据进行高速采集、传输、分析,挖掘潜藏的数据价值。
空管行业具有应用大数据技术解决业务需求的天然环境,空管业务过程中涉及到的人员机构职能众多,据实地统计,一个典型的民航空管单位(空管分局(站))一年收集到的数据就超过20 TB,全国民航空管一年运行产生的数据至少在PB级别以上[1]。空管业务过程中的参与单位既是空管数据的生产者和使用者,又能够收集、维护运行过程中产生的海量数据,具备构建空管大数据处理平台的数据资源。
空中交通管理过程涉及的海量数据除了业界普遍认可的大数据4V特征[2],Volume(数据量大)、Velocity(速度快)、Variety(多样化)、Value(价值密度低),还具有以下两个新的特征:
(1) Veracity(真实性)。不同于其他行业大数据的来源普遍带有主观性,空管数据直接采集自各业务单位数据系统,数据是真实有效的,数据的处理分析结果也是更加精准的,在管制决策应用中是安全可靠的。
(2) Complexity(复杂性)。空管数据来源多、种类多、格式多、非结构化数据占比大、对数据处理和分析的难度大。
随着空管行业信息技术水平的发展,通信、导航、监视新技术涉及到的智能终端在空管系统中被快速推广应用,空管业务产生的数据量必将快速增长,数据类型、来源将不断增多。空管系统中落后的数据处理应用能力,导致数据分析挖掘受限、非结构化数据缺乏有效利用等问题,制约了空管行业向信息化智能化的发展。
美国在空管大数据建设方面处于领先地位,20世纪90年代开始FAA针对空管运行过程的不同阶段和业务需求,建设了美国国家飞行数据中心(NFDC),研发了全域信息管理系统(SWIM)、FAA运行与效能数据系统、增强型交通管理系统(ETMS)、NAS语音系统等多种空管大数据处理系统,并对运行过程中产生的数据进行数据挖掘、二次开发,以此来应对日益增长的航空运输压力,并提升空管运行安全能力和效率[3-10]。
国内在空管大数据的应用方面开展了相关研究。在空管智能化技术[11]、民航机场协同决策系统[12]、空管运行安全数据[13-14]方面有一些研究,但没有形成支撑空管大数据处理平台的相关技术体系,在空管系统数据处理挖掘方面也没有自身的大数据平台。随着空管行业信息化技术水平的提高,对数据实时处理、数据挖掘方面需求越来越迫切。空管大数据应用与其他行业大数据应用在存在很大差异,现有大数据处理平台并不能在容错性、可靠性、实时性上完全适用于空管行业,因此针对空管大数据处理开发平台显得非常必要且迫切。
本文针对空管业务需求,对空管大数据处理平台总体架构、功能、基础平台组成以及数据处理技术进行了研究,为空管大数据平台的开发与应用奠定基础。
1 平台总体架构
空管大数据处理平台架构设计主要包括硬件层、资源层、数据层、处理层及应用层设计。

图1 空管大数据处理平台架构
空管大数据处理平台的底层为硬件层,硬件层为大数据处理平台提供物理硬件支撑,主要由防火墙、文件服务器、数据库服务器、网络资源、存储阵列等组成,为上层数据存储处理平台提供通信、网络、存储、计算等资源。采用虚拟化基础平台和硬件基础服务平台组成,完成对虚拟资源、业务资源、用户资源的集中存储和计算,同时通过统一的接口,对虚拟资源进行集中调度和管理,从而降低了空管大数据处理业务的运行成本,保证了系统的安全性和可靠性,构建安全、绿色、节能的大数据处理中心。
资源层设计主要目标为通过统一的数据平台对空管业务数据进行集中汇集存储,并通过建立定性或定量的数据分类、安全分级标准和政策,剔除其中的无效数据,仅对完整、存在潜在价值的数据进行处理,对涉密数据进行严格安全管理,提升数据的有效性、规范性、安全性,为数据交换、数据处理、挖掘预测类等子平台提供全面、一致的数据基础。打破现有空管系统数据来源多、格式多、数据处理复杂的现状,提升处理平台建设和运行效率。确保空管业务各级部门均在保证数据隐私和安全的前提下使用数据,充分发挥数据作为空管行业重要资产的潜在价值。
数据层采用开放式X86架构的PC服务器搭建Hadoop分布式系统集群架构[15],基于Hadoop的HDFS集群主要解决了空管大数据的存储问题,随着空管运行数据的爆炸式增长,一味地靠增加硬件数量来提高存储量和计算能力,不仅成本高,而且效率低。Hadoop的搭建只需要普通的PC机,分布式文件系统HDFS,分布式计算引擎MapReduce,两大组件都屏蔽了分布式及并行底层技术细节问题,使用起来简单方便。
数据层设计包括数据交换设计和数据存储索引设计,数据交换设计包含结构化数据交换组件、半结构化数据交换组件、非结构化数据交换组件三类数据交换组件。数据交换的设计目标有以下几点:保证数据在平台内高速流转;保证数据交换过程中不失真;保证数据交换过程中不丢失;保证数据交换过程安全可靠。
结构化数据交换组件通过Perl+Hive Load技术实现,面向空管业务系统产生的结构化数据进行处理,包括存储在Oracle、SQLSever、MySQL和MongoDB等传统数据库中的空域信息、航班计划、雷达监视数据等。半结构化、非结构化数据交换组件通过SFTP协议批量进行数据传输,并开发JAVA应用调用资源层API,将抽取到的数据加载到分布式数据存储平台HDFS指定目录,面向空管业务中产生的陆空通话语音、监控视频、音频、office文件等数据。数据交换采用NAS网络存储设计,如图2所示。数据交换存储设计中元数据区用来存储大数据平台各个Hadoop集群的元数据信息,如HDFS文件系统元数据;数据导入导出临时数据区用来暂存数据资源层推送平台每日推送的管制、通信、导航、监视、气象等提供的业务系统变化数据以及暂存数据处理层处理计算结果;ETL(Extract-Transform-Load)数据处理程序区将数据加工处理程序(数据压缩、数据加载、数据处理等)统一存储在NAS集群指定目录。

图2 数据交换存储设计
数据存储索引设计将Elasticsearch与Hadoop中HDFS分布式文件系统深度集成,Hadoop的两大核心HDFS和MapReduce为大数据存储和分析提供了解决方案,但在实时搜索分析方面Hadoop还仍有欠缺。ElasticSearch是一个开源的分布式搜索引擎,将全文检索、数据分析以及分布式技术设计用于大数据检索,能够进行实时搜索、交互式数据探索,并且可与Grafana、Kibana等数据可视化工具集成,提供给平台应用层进行数据可视化展示。Elasticsearch-HDFS将Hadoop海量的数据存储和深度加工能力与Elasticsearch实时搜索和分析功能进行连接,能够在Elasticsearch和Hadoop之间轻松地双向移动数据。通过数据交换组件的数据首先存入HDFS,然后与Hive结合来实现对数据的实时访问、实时结构化、全文检索,从而减少筛选数据量,同时借助HDFS作为存储库进行长期存档,并依托Hadoop API的动态扩展构建动态嵌入式搜索应用来检索HDFS数据,执行深度低延时分析,弥补了HDFS不能执行低延时数据访问的不足。
数据处理包括数据批处理和数据流处理两种方式。将存储在HDFS中空管业务产生的结构化、半结构化、非结构化数据,通过MapRedurce进行结构化处理,并按照主题数据模型整合数据并生成汇总,将数据通过批处理和流处理计算引擎加工后,结果交付到应用服务层。
应用服务层设计主要将处理层的数据,通过Office集成、仪表盘、静态报表、Web展示等可视化方法,针对空管业务一线单位,以及运行监控中心等业务需求提供定制化服务,为一线空管部门正确决策提供支持,保证管制服务安全有序,提升管制指挥、运行智能化水平。
2 基础平台组成
空管大数据处理基础平台采用基于Hadoop集群架构,Hadoop的分布式文件系统HDFS具有高容错性、高吞吐量的特点,适合超大数据集的应用程序,满足了处理平台对大型数据集存储分析的应用需求。HDFS由Java开发,可以在支持Java的机器上部署,并通过多副本机制,自动保存多个副本,某一个副本丢失以后,可以自动恢复,提高了空管大数据处理平台的可靠性和容错性。HDFS的“一次写入,多次读取,只能追加,不能修改”机制,保证了空管大数据的一致性,并且支持空管一线单位及机场运行监控中心多用户的高吞吐量访问。
HDFS放宽了可移植操作系统的要求,能实现以流的形式访问存储系统中的数据。空管业务中管制指挥涉及到的飞行数据、航路航线情况数据、实时天气数据是以流的形式存储在大数据处理平台中。一个HDFS集群通常包含名称节点和数据节点。名称节点管理着文件系统的名称、空间,并规范客户端对文件的访问权限,以及对各个数据节点进行统一调配。数据节点主要对空管业务产生的相关数据进行存储。HDFS架构如图3所示。

图3 HDFS架构
2.1 名称节点
名称节点在空管大数据处理平台作为Master服务器,提供集中式的集群管理功能,主要用于管理HDFS文件系统命名空间,执行文件系统命名空间操作,如文件打开、关闭,目录结构等集群管理功能,并调节客户端对文件的访问,还确定块到DataNodes的映射。若名称节点终止,则对应的Hadoop集群服务也会停止,名称节点对稳定性要求高,因此空管大数据处理平台的名称节点应使用稳定的小型服务器,保证集群工作的可靠性和性能。
2.2 数据节点
数据节点是一个通常在HDFS架构中的单独机器上运行的组件,管理连接到运行的节点的存储和读写。HDFS将一个文件分割成很多块,这些块可能存储在一个数据节点上或者是多个数据节点上。数据节点响应来自名称节点的创建、删除和复制块的命令。空管运行的数据在数据节点上是分布式存储的,可以通过HDFS在集群数据节点进行数据平衡分配和备份,在故障的情况下也能可靠地存储数据,保证集群计算效率和安全。
3 平台计算引擎
3.1 批处理计算引擎
批处理计算引擎应用于流量预测、冲突预测、跑道侵入预测、尾流间隔缩减等空管业务模块。流量预测功能采集每天所有机场的航班计划,通过大数据技术分析航班的飞行时间、航线、高度、结合空域、天气、机场运行状况等信息预测未来某一时段管制空域或机场的流量,从而合理安排航班进离场顺序、绕滑行道使用安排、管制人员值班计划等,有效提升管制运行安全水平和效率。同时通过对飞行时间、飞行高度进行大数据分析,完成对航路潜在冲突的预测功能。批处理计算引擎主要面向航司、空管部门提供的航班时刻表、飞行计划报、空域信息等历史积累数据。
空管大数据处理平台采用Apache Spark批处理计算引擎应对空管生产业务过程中积累的PB级历史数据。Apache Spark与Hadoop中MapReduce引擎基于相同原则开发而来。不同于MapReduce数据处理流程中每一步都需要一个Map和一个Reduce阶段,Apache Spark采用内存迭代计算模型,加快了批处理的运行速度,在处理完一个阶段以后,可以继续处理多个阶段,消除了MapReduce的有限处理限制,提供了更强的计算功能。但Apache Spark在分布式存储方面本身并没有自身的分布式文件系统,因此磁盘存储大多依赖于处理平台的文件存储系统。空管大数据处理平台将Apache Spark集成在Hadoop的分布式文件存储HDFS中,与Hadoop深度集成并取代MapReduce引擎,为处理平台提供了更强大的计算功能。Apache Spark运行架构如图4所示。

图4 Apache Spark运行架构
Apache Spark支持Standalone、Spark on Mesos和Spark on YARN三种分布式部署方式,并支持HDFS、Cassandra、AmazonS3等接口的连接,为空管大数据处理平台提供多种数据存储解决方式,并允许用户将数据加载至存储器中,支持对其多次查询,并集成了多种算法,支持交互式查询、数据挖掘、统计分析、深度学习等常见的空管大数据处理场景,为空管大数据处理平台提供了有力的支撑。
3.2 流处理计算引擎
空管业务对大数据处理平台的实时性、快速性、准确性要求非常高,需要实时获取飞机在飞行过程,场面运行过程中的各类数据信息,进而实时监控管制空域内飞机的运行状态。实时监控模块的数据来源通常是ADS-B、ACARS报文、场面运行等,包含飞机的位置、高度、速度、航向、识别号等重要信息[16],对空管指挥、现场运行等业务来说,这些数据的价值随着时间的流逝而迅速降低。大数据处理平台迅速的流数据处理能力能辅助管制员对飞机的运行状态进行实时监控,意味着管制人员可通过实时监控来判断飞机或者机长的行为是否正当。当特情发生时,管制人员可迅速分析判断特情原因,组织调度相关技术人员、地面工具等,一旦飞机降落,迅速进行故障解决,提高效率。目前,应对实时流计算引擎主要包括:Apache Flink,Yahoo的S4,Twitter的Storm和Facebook的Puma。空管大数据处理平台对数据处理的实时性、准确性、容错性要求极高,对比目前主流的流计算引擎性能,空管大数据处理平台采用Apache Flink流处理计算引擎。
Apache Flink是一个开源的分布式的高容错大数据流处理引擎,面向数据提供流处理(无边界数据流)和批处理(有边界数据集)两种数据处理方式,并支持多种编程语言,既能兼容空管大数据处理平台中相关的传统数据库、各类文件系统等数据源,也可以作为独立集群运行,还能与所有常见的集群资源管理器(如Hadoop YARN、Apache Mesos和Kubernetes)集成,从而针对不同管制业务部门需求开发实时计算系统。Apache Flink运行在大数据处理平台数据层搭建的开源Hadoop集群上,采用Hadoop的YARN作为资源管理器,以HDFS作为数据存储。因此,Flink可以和空管大数据处理平台实现无缝对接。
Flink在运行中主要有三个组件组成:工作端,主节点和从节点。用户首先提交Flink程序到工作端,经过工作端的处理、解析、优化提交到主节点,最后由从节点运行工作单元。Flink处理架构如图5所示。
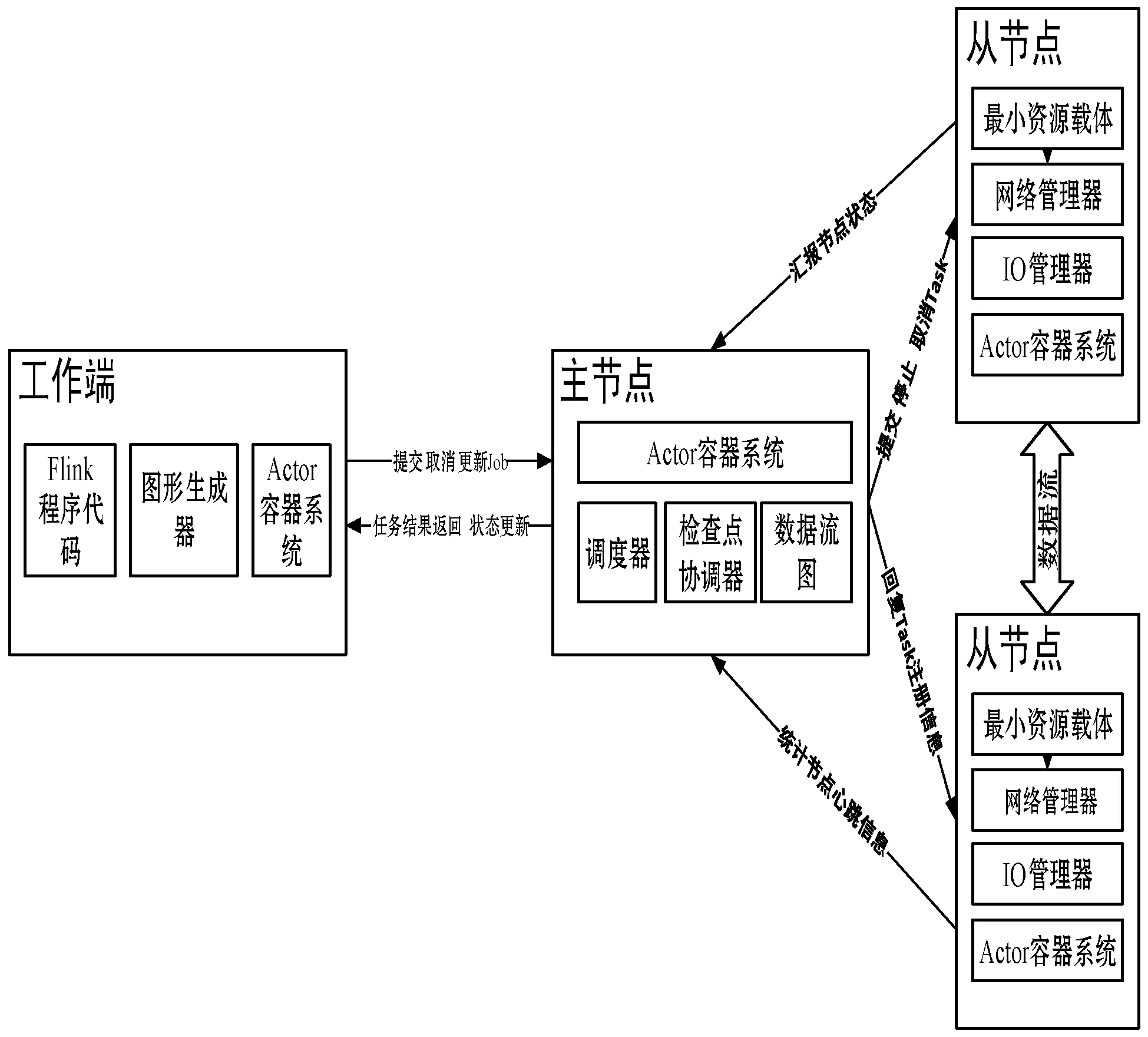
图5 Flink处理架构
在实现流处理和批处理时不同于现有的开源计算方案把流处理和批处理作为两种处理类型,而是将批处理也作为流处理的一种,只是它的输入被定义为有界数据集。Flink以数据缓存块为单位进行数据传输,不同于别的执行引擎数据记录必须填满缓冲器才会被发送到缓存区,Flink可以通过指定缓存块的超时值来决定数据的传输时机。流处理一般需要低延迟支持,Flink在进行流处理时将超时值设置为0,此时系统的处理延迟最低,但吞吐量也降低,可以通过调节缓存块的超时值来调节系统延迟和吞吐量的冲突,达到在高吞吐量的同时实现毫秒级的数据分析处理,符合空管大数据处理平台对吞吐量和低延时性的高要求,为实时性要求极高的空管业务提供支撑服务。
4 平台应用分析
通过搭建空管大数据处理平台为空管大数据提供存储、计算、分析能力,将通信、导航、监视、气象、空域信息、航线情况、陆空通话、广播报文、电子进程单等数据通过相应工具采集到大数据分析平台中,存储到Oracle、SQLSever、MySQL和MongoDB等数据库中,并通过不同的数据交换组件存储在分布式文件存储系统中对各类空管数据进行有效地融合。通过批处理和流处理计算引擎,对空管业务数据进行快速处理,并依托不同的可视化工具,提供给空管业务部门,对实时性要求极高的空管业务进行支持。为空管大数据分析者提供各类数据分析的工具,让空管大数据的应用者不需要关注底层大数据开发技术,只需要专注于业务开发,解决空管一线业务单位面临的问题。最终验证了本平台架构的可行性。
5 结 语
伴随着民航业的快速发展和空管行业信息化建设的深入开展,智慧空管已经成为空管行业发展的方向和趋势,智慧空管的最终目标是建设成为覆盖空管系统整个生产过程的全景实时系统。而支撑智慧空管安全、高效、可靠运行的基础是空管系统数据实时采集、传输、存储,以及在运行过程中对累积的海量多源异构数据快速准确处理分析。基于大数据技术的空管数据处理平台为智慧空管的建设提供了平台技术支持,空管大数据处理平台为流量预测、冲突探测、侵入告警等空管业务提供支撑,有助于空管行业打破信息孤岛,实现行业数据共享,满足行业数据需求,对我国空管行业迈向智慧空管有着重要的意义。
猜你喜欢
学习与科普(2022年17期)2022-04-23
大飞机(2021年7期)2021-09-05
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
中国新技术新产品(2020年1期)2020-11-28
科学导报·学术(2020年84期)2020-11-08
福建基础教育研究(2020年3期)2020-05-28
电脑爱好者(2019年1期)2019-10-30
劳动保护(2019年3期)2019-05-16
电脑爱好者(2017年18期)2017-11-03
