
基于生成对抗网络的长短兴趣推荐模型
2020-06-16 00:24:26康嘉钰苏凡军
计算机技术与发展 2020年6期
康嘉钰,苏凡军
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引 言
目前在推荐算法领域,数据为驱动的推荐系统受到越来越多的关注。这些系统会引导用户从大量可能的选项中发现与用户兴趣相关度高的产品或服务[1-2]。随着用户对推荐技术依赖的加强,推荐系统如何为用户提供精准的推荐成为亟待解决的重点,在许多算法中往往都会忽视用户的兴趣漂移问题[3]。比如一部电影的受欢迎程度会随着时间变化而变化,用户喜欢的电影类型也会受到短期的流行影响而变化。因此,在推荐系统中如何利用长短期兴趣变化达到精准推荐显得尤为重要。
针对推荐系统的长短兴趣问题,文献[4]描述了基于长短期兴趣的协同过滤方法的优点,并介绍了一种基于循环神经网络(recurrent neural network,RNN)的长短期兴趣预测方法。文献[5]将MF模型与RNN模型相结合来进行推荐,其通过MF模型来挖掘用户长期兴趣特征,利用RNN模型来挖掘用户一段时间内的兴趣变化,同时考虑到了用户长短期的变化。文献[3]提出了一种使用RNN来负责短期兴趣,前馈神经网络负责长期兴趣的推荐模型。这些模型均采用一般的训练方法训练,Szegedy等人[6]发现在模型训练中添加一些轻微的干扰就可以轻易改变模型的预测结果。深度学习模型遭遇干扰时所表现的脆弱性,给推荐系统带来了极大的风险。并且会使模型对历史信息的利用不充分,对隐层特征的挖掘不精确。
最近,文献[7]将对抗训练策略应用于图片解读任务中,效果十分优秀。文献[8]提出了一种基于生成对抗网络的序列生成方法,使用强化学习的策略梯度来实现序列数据生成。文献[9]提出了基于IRGAN框架的新生成检索模型和判断模型,使IRGAN在搜索项目、推荐项目方面得到了较大的提升。文献[10]提出了一种GAN框架的流式推荐模型。由此可见,生成对抗网络在各种任务中都具有有效性,且在推荐系统中同样具有有效性。对于提升深度学习模型对干扰的鲁棒性,使用对抗生成网络也是行之有效的解决方法。
基于上述综述,文中提出了一种基于生成对抗框架(GAN)的Top-N推荐模型L-GAN。采用对抗训练的策略优化LSTM推荐模型,重点考虑用户和项目之间的兴趣漂移问题。L-GAN模型使用生成器产生推荐列表,并用判断器区别推荐列表与真实数据,通过判断器与生成器不断对抗训练,使生成器最终产生的推荐列表与真实数据极为相似。提出的基于生成对抗网络的L-GAN推荐算法,主要有几点贡献:
(1)使用对抗训练策略来训练LSTM推荐模型,使用用户行为周期数据作为输入,由生成器生成推荐列表,判断器来识别推荐列表是否合理;
(2)在判断器中使用孪生神经网络来判断生成列表的合理性;
(3)通过将数据分割为行为周期数据,同时考虑了数据长期与短期的兴趣偏好变化,使数据的隐层特征获取更加准确。
1 LSTM模型
提出的模型主要使用LSTM模型来有效利用长短期兴趣漂移变化。LSTM模型是一种改进的时间循环神经网络,可以学习时间序列长短期依赖信息,由于神经网络包含时间记忆单元,比较适合于对时间序列中的间隔和延迟事件进行处理和预测[11]。每一个时刻t的LSTM单元由输入门it、遗忘门ft、输出门ot、细胞记忆单元ct和隐层状态ht组成。这些门是根据先前的隐藏状态ht-1和时刻t的输入xt计算出来的。
it=sigmoid(W[ht-1,xt])
(1)
ft=sigmoid(W[ht-1,xt])
(2)
ot=sigmoid(W[ht-1,xt])
(3)
通过遗忘部分存在的细胞记忆和增加新的细胞记忆内容来更新时刻t的细胞记忆。可以用公式(4)表示遗忘过程,公式(5)表示细胞记忆更新过程。
It=tanh(W[ht-1,xt])
(4)
ct=ft⊙ct-1+it⊙It
(5)
当更新完LSTM单元的记忆内容后,时刻t的隐层状态为:
ht=ot⊙tanh(ct)
(6)
每一个LSTM单元的更新可以由简式ht=LSTM(ht-1,xt)表示。在利用长短期兴趣做预测时,输入量xt应该来自于用户时刻t的行为周期,行为周期可以理解为一段时间内用户评价项目的评价记录合集。
2 L-GAN推荐模型框架
假设行为周期中的矩阵R为用户-项目评价矩阵,由用户集U与项目评分集M组成,使用符号rij,t来表示时刻t时,用户i对项目j的评价。rij,t的数值越大,表示用户i对项目j的兴趣越大。文中提出的L-GAN模型主要是将LSTM模型应用于GAN的框架中。

图1 L-GAN模型结构
GAN[12]是由生成器G和判断器D构成的。文中模型中的判断器D用来区分训练集中的真实高评分项目与生成器G预测的高评分项目或推荐列表;生成器G使用预测出的高评分项目或推荐列表来欺骗判断器D。生成对抗训练策略的目的是,通过生成出的推荐列表不断地与用户真实历史评价对抗训练,使推荐列表中的项目与用户历史喜欢的项目特征达到高度接近或重合。结构如图1所示。
具体的目标可以用如下公式表示:
Ez~P(z)[log(1-D(G(z)))]
(7)
其中,x为来自训练集的真实数据,G(z)表示由生成器生成的高评价项目或推荐列表,z也是来自训练集的真实数据。为了使生成器G产生更加真实的推荐列表且判断器D的判断结果更加准确,将LSTM模型运用于生成器G与判断器D中,加强对数据长短期兴趣偏好的敏感度,以提高对隐层特征的挖掘。
2.1 生成器G
生成器将一个行为周期的用户-项目评价矩阵R作为输入,生成用户i的推荐列表。但是用户-项目评价矩阵一般为高维稀疏的,不利于模型的训练。可以先通过矩阵分解降维的方法预处理矩阵R。文中使用具有自编码器的编码网络对矩阵进行预处理[13],将其降维拆分为向量xi,t和向量xj,t,xi,t为用户i在一定时间内对所有评价过的项目的评价向量,xj,t为在一定时间内所有评价过项目j的用户对项目j的评价向量。在时刻t,评分rij,t取决于用户时间状态hi,t和项目时间状态hj,t。因为用户的时间状态变化依赖于用户评价向量的变化,同理项目的时间状态变化也是由项目评价向量变化决定的。所以可以使用两个LSTM模型分别输入两个向量,分别得到用户时间状态hi,t和项目时间状态hj,t。为了同时考虑用户与项目的变化,文中将它们的内积作为预测时刻t用户i对项目j的评分rij,t。
xi,t,xj,t=Encoder(R)
(8)
hi,t=LSTM(hi,t-1,xi,t)
(9)
hj,t=LSTM(hj,t-1,xj,t)
(10)
rij,t=hi,t⊙hj,t
(11)
通过这样的方法,按照时间戳的顺序,依次将行为周期的评价矩阵输入,对一定时间段内用户i没有评价过的项目进行预测评分,预测评分最高的前几个项目按预测评分从高到低排序,即可视为生成出的推荐列表。生成器的模型如图1所示。生成器的目标函数可以表示为:

(12)
其中,M为项目集,D(xi,t,xm,t,xn,t)为判断器的模型,xn,t为生成器产生的推荐列表中的高评分项目向量。训练生成器是为了与判断器对抗,从而使判断器无法区分出推荐结果与真实数据,即为使G(z)产生的结果更接近真实数据,则目标是使判断器判断的相似度D(G(z))最大,为了便于计算可求得log(1-D(xi,t,xm,t,xn,t))最小化结果。
2.2 判断器D
判断器使用孪生神经网络框架(siamese network framework)。孪生神经网络可以很好地区分隐层特征,常用于特征之间的对比任务。该框架分为特征提取网络和相似度计算两个部分[14]。为了更精准地识别项目间基于长短兴趣偏好的隐层特征的区别,孪生网络框架中的特征提取网络使用类似于生成器中LSTM模型的用法,这时的输入应该使用用户向量xi,t,用户历史评价高分项目向量xm,t和生成器预测的高分项目向量xn,t,如图1所示。通过对比时刻t用户评价过的高分项目与推荐出的项目状态的相似度来判断生成器推荐是否准确。特征提取网络的公式可表示为:
xi,t,xm,t=Encoder(R)
(13)
rim,t=LSTM(hi,t-1,xi,t)⊙LSTM(hm,t-1,xm,t)
(14)
rin,t=LSTM(hi,t-1,xi,t)⊙LSTM(hn,t-1,xn,t)
(15)
在孪生网络内特征提取网络中使用的权重是共享的[15]。文中模型选用了对比损失函数(contrastive loss)[16]作为求得相似度的方法。根据其计算出的相似度,可以判断生成器预测结果是否准确。判断器模型可以表示为:

max(1-d,0)2
(16)
d=‖rim,t-rin,t‖2
(17)
其中,d为对比样本的欧氏距离,y表示两个样本是否相似,y为1时表示两个样本相似,为0则表示不相似。需要注意的是,在训练优化判断器的阶段,需要使用用户评价过的其他项目向量xl,t代替预测项目向量xn,t。目的是为了用真实的数据来更新优化判断模型中的共享权重。因此判断器的目标函数表示为:

(18)
其中,U为用户集。公式中的第一项,来源均为真实数据,得到的相似度概率D(x)越大越好。而第二项是判断生成器的推荐列表与真实数据的相似度,判断器的作用是鉴别它们的区别,所以其鉴别的相似度结果D(G(z))应越小越好,为了统一形式方便计算,第二项改为1-D(G(z)),这样整个公式不会出现矛盾。
2.3 训练算法流程
算法训练流程总结如下(在训练模型的时候,判断器与生成器通过对抗训练的策略交替进行更新优化):
算法:算法训练流程。
输入:训练集S
初始化:使用随机数来初始化生成器G与判断器D的权重,预处理训练集S
训练生成器G:
(a)生成时刻t用户i的项目推荐列表
(b)从推荐列表中选出预测高分项目样本集N
(c)forn∈{1,2,…,N}:
用户i的历史高分项目m来自训练集S
使用判断器D来区分k,m
End for
(d)通过生成器的目标函数(12)来更新生成器G
训练判断器D:
(a)用户i的历史高分项目m与评价过的其他项目l均来自训练集S
(b)判断器D判断m,l的相似度
(c)通过判断器的目标函数(18)来更新判断器D
until两个模型均收敛
3 实 验
3.1 实验数据集
为了验证文中算法的推荐效果,选择了两个公开的数据集(MovieLens-100K(http://grouplens.org/datasets/movielens)和Netflix-3M(https://www.kaggle.com/netflix-inc/netflix-prize-data))进行实验。这两个数据集均有用户对电影的评级,评价等级为从1到5,5为最高评分。并且它们还提供了电影的发行时间以及详细的用户信息。对每个数据集,去掉没有明显信息的用户及电影,按照时间戳粒度随机分为若干个训练集与测试集。其中MovieLens-100K的时间戳粒度设为5天,Netflix-3M的时间戳粒度设为1天。两个数据集的详细信息如表1所示。

表1 数据集信息
3.2 实验评估标准
为了对推荐效果进行定量的评价,使用推荐精度(precision)、NDCG、MRR作为推荐算法的度量标准。这些评价指标的值越大,推荐算法的效果越好[17-18]。
推荐精度可以表示用户喜欢项目在推荐列表中的比例,对于推荐列表大小为k的推荐精度公式为:

(19)
其中,R(k)为生成推荐列表的数量,T(k)为实现正确推荐的推荐列表数量。
NDCG(normalized discounted cumulative gain)广泛作为对Top-N推荐系统的推荐列表的评价指标。用公式可以表示为:

(20)

(21)
其中,reli为推荐列表位置i的推荐结果的相关性。如果排名i的项目相关性好,reli=1,否则等于0。IDCG为理想情况下的DCG,即为DCG的最大值。
MRR(mean reciprocal rank)是将推荐列表中一个预测准确的结果的位置的倒数作为准确度,再对所有准确度求平均值。

(22)
其中,Q为推荐项目的数量,rankq为第q个推荐项目第一次出现在推荐列表中的位置。
3.3 实验对比模型
实验选用TimeSVD++[19]、R-RNN[20]和IRGAN[9]模型进行对比。TimeSVD++推荐算法是一种对于静态的基于矩阵分解技术的推荐算法的改进算法。R-RNN模型采用与文中生成器类似的推荐算法,并通过Adam算法对其参数进行优化。IRGAN用于信息检索领域,可以生成出按偏好相关的推荐列表。
3.4 实验结果
在实验中进行Top-N推荐时,对推荐列表长度k取不同值分别进行实验,以k为3、6、9时的实验结果作为样本,各项实验结果如表2和表3所示。
实验结果表示,文中提出的L-GAN模型相对于对比模型在推荐精度和准确度上都有较明显的提升。TimeSVD++推荐算法和R-RNN模型推荐效果明显低于使用GAN训练的模型,证明通过生成对抗训练可以更好地获取隐层特征。L-GAN虽采用与R-RNN模型类似的推荐列表生成方式,但在训练时通过判断器的反馈会提升推荐列表的精度。L-GAN在各个指标对比中均略微高于IRGAN,显示了L-GAN较好的推荐效果。这是因为L-GAN模型的优势在于能够考虑用户和电影之间短期和长期联系,尤其是模型中LSTM部分明确考虑了用户行为的动态性。在实验结果中,当推荐列表容量大小增加时,三个模型的推荐效果均呈现不同程度的下降。
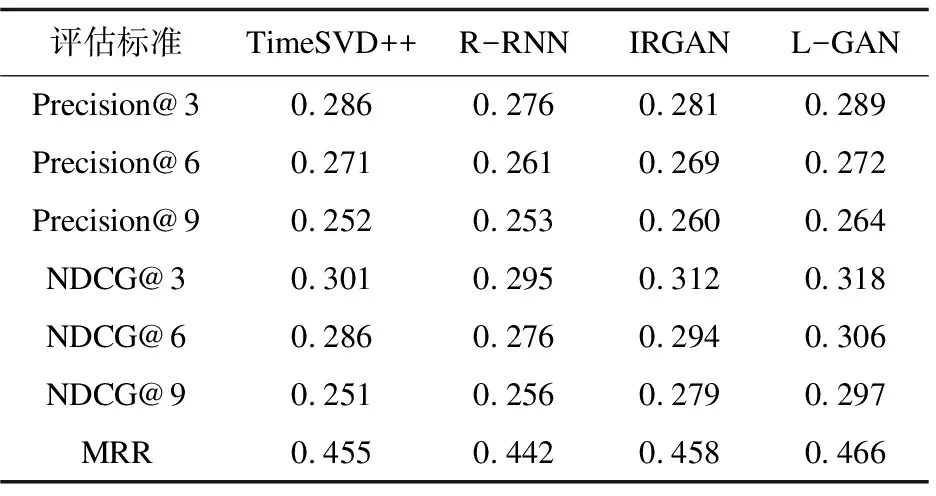
表2 推荐结果(MovieLens-100K)

表3 推荐结果(Netflix-3M)
4 结束语
在生成对抗网络框架的基础上,提出了一种L-GAN推荐模型,通过生成器产生推荐列表,判断器区分真伪评分项目的方法,准确挖掘数据基于长短期兴趣偏好变化的隐层特征,使推荐列表更加精准。在两个大型开源数据集上的实验,证明了该模型推荐效果的有效性与准确性,且对数据的隐层特征挖掘更精准。实验结果也显示了随着推荐列表增加,推荐效果出现降低的问题,因此今后会针对这一问题展开研究。
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
现代防御技术(2016年1期)2016-06-01 12:13:27
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
