
基于持久同调的三维模型检索方法
2020-06-12 09:18:14况立群幸嘉诚谌钟毓
计算机工程与设计 2020年6期
况立群,李 丽,幸嘉诚,谌钟毓,韩 燮
(1.中北大学 大数据学院,山西 太原 030051;2.南昌大学 软件学院,江西 南昌 330047;3.华东交通大学 软件学院,江西 南昌 330013)
0 引 言
面对数量众多、种类繁杂的三维模型,如何及时有效地获取到用户所需模型,成为三维建模领域的研究热点[1]。根据特征描述子的不同提取方式,三维模型检索方法可分成统计特征获取、投影视图计算和拓扑结构描述3类。基于统计特征的检索方法研究每个个体特征组成的总体分布情况,在描述模型内部结构方面有所欠缺,使得检索效率不高[2]。基于投影视图的检索方法将三维模型投影为多个二维视图[3],在降维时会丢失三维模型的部分信息[4]。以上两类检索方法主要是对模型的几何结构进行分类,忽略了模型的本质拓扑特征,而基于拓扑结构的检索方法则通过描述三维模型的骨架结构来获取模型的拓扑特征[5],但难以应用于无明显骨架结构的三维模型检索。
近年来,国际上兴起了基于持久同调理论的拓扑数据分析方法,适用于研究任意形状物体的拓扑特征,已广泛应用于大数据[6]、脑影像特征分析[7]等领域,然而在三维模型检索中的应用不多,且国内鲜有相关研究报道。因此,本文提出一种基于持久同调的三维模型检索方法。该方法关注三维模型在多尺度下的拓扑结构,从本质上获取三维模型内部的拓扑特征,可刻画一些无明显骨架结构的三维模型的拓扑特征,具有旋转平移和尺度不变性。
1 相关工作
1.1 持久同调
持久同调(persistent homology)是拓扑数据分析中的一个重要研究方向,关注的是三维模型结构中点与点之间的拓扑不变量,用于研究多个尺度下的定性特征[8]。本文运用持久同调理论提取三维模型的特征描述子,其中的重要一步是为三维模型构建复形过滤流(filtered complex),其主要过程为:在三维模型中,每个点被一个直径为d的球体所包围,该球的直径d从0开始逐步增大,当三维模型中任意两点的间距小于该时刻的直径d时,便将这两点连在一起。在该过程中使用单纯复形(simplicial complex)去填充整个变化的结构,最后形成一系列嵌套的单纯复形,如图1所示。
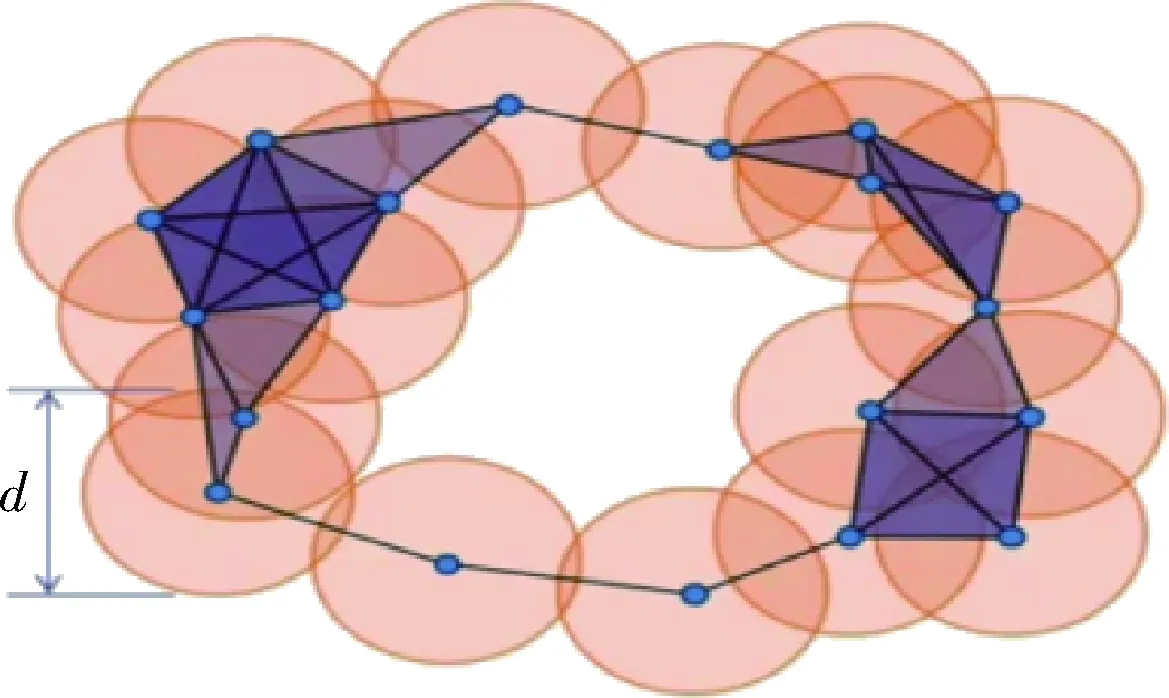
图1 复形过滤流构建
在构建复形过滤流过程中获取到三维模型在多尺度范围上的拓扑结构,一些拓扑结构短暂出现之后被填充,被认为是噪音和扰动;另外一些拓扑结构长时间持续存在,被认为是稳定的拓扑特征,这些稳定的拓扑特征描述了三维模型内部本质的特征,将其作为特征描述子来表征三维模型,这便是持久同调的全过程[9]。
常构建的复形过滤流有Cech复形、Alpha复形、Witness复形、Vietoris-Rips复形。本文中构建的是Vietoris-Rips复形,即在高维空间中有一点集P,在过滤尺度λ下生成变化的P的子集σ,且子集中任意两点之间距离都小于λ[10],Vietoris-Rips复形的形式化如式(1)所示,其构建过程如图2所示[11]
VλP=du,v≤λ,∀u≠v∈σ
(1)

图2 Vietoris-Rips构建过程
1.2 特征描述子
为了通过比较三维模型间的差异来实现检索,需要为三维模型生成一个特征描述子。在持久同调过程中,产生了一些持续时间长的稳定拓扑特征,通常用贝蒂数(Betti number)的变化来量化这些特征[12]。
令K为一个原始的单纯复形,可在某一时刻添加其子单纯复形,构建变化的复形过滤流,建立单纯复形间的嵌套关系
K0⊂K1⊂K2…⊂Kn=K
(2)
因为Ki-1⊂Ki,在单纯复形之间引入同态f:Hp(Ki-1)→Hp(Ki),使嵌套的复形序列与同态连接的同调群序列一一对应,其中每个维度对应一个不同的p,则同调群秩的序列如下[8]
Hp(K0)→Hp(K1)→Hp(K2)…→Hp(Kn)=Hp(K)
(3)
同调群Hp(K)的秩叫作单纯复形K的p维贝蒂数,它是代数拓扑中定义在同调群上的拓扑不变量,0维贝蒂数表示连通分支的个数,1维贝蒂数表示一维下孔洞的个数,可用条形码[11]和持久性[13]来表示贝蒂数的变化,如图3和图4所示。在条形码图中直线的起始点表示孔洞的产生时间,直线的终止点表示孔洞的消失时间;持久性图中横坐标表示孔洞的产生时间,纵坐标表示孔洞的消失时间。条形码图与持久性图可以相互转换,本文采用持久性图来表征三维模型特征,作为三维模型的特征描述子。
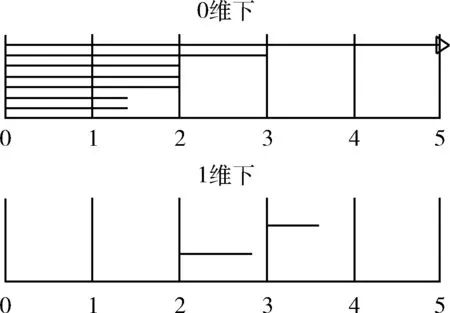
图3 条形码

图4 持久性
1.3 Wasserstein距离
由于持久性图是二维散点的集合,难以在一维空间直接度量持久性图之间的相似性。最传统的度量方法当属瓶颈距离法,近年来有研究表明Wasserstein距离[14]具有更好的度量性能。Wasserstein距离最早被用来比较两个直方图的差异,之后被用来刻画两个分布之间的距离,可以通俗理解为将一堆物体移动到另一个位置的最小成本,它的定义为
(4)
其中,X和Y分别为满足μ和ν概率分布的d维空间集合,p表示Lp范数,inf表示下界,本文方法中p值取1。
2 基于持久同调的三维模型检索方法
本文提出一种基于持久同调的三维模型检索方法,整个检索框架如图5所示。首先,采用Ripser软件包来构建Vietoris-Rips复形,计算得到三维模型的拓扑特征(1维贝蒂数),并将其表示在持久性图中,形成特征描述子;然后利用分段Wasserstein距离计算两个持久性图之间的相似性;最后,检索相应模型,通过获取到的评价参数来评价检索效率。
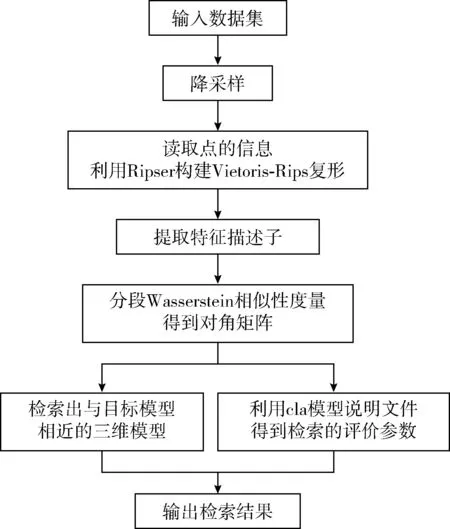
图5 总体检索框架
2.1 数据预处理
本文采用Vietoris-Rips复形构建三维点云模型的拓扑结构,该结构比传统的三角网格化模型的结构复杂得多,嵌套复形的信息量异常庞大,难以对其直接拓扑化,需预先对三维模型数据集进行简化。本文利用meshlab中的插件meshlabserver进行批处理降采样,通过减少面的个数来减少点的个数,同时在降采样前设置“保留拓扑特征”等参数。这样不仅保留了三维模型内部的拓扑特征,又减少了模型的稠密度,缩短了计算时间。实验中考虑到时间和设备的限制,将模型降为800个面,400多个点。
2.2 提取特征描述子
构建Vietoris-Rips复形的软件包有Javaplex、PHAT、GUDHI、DIPHA、Ripser等,其中Ripser是用于计算Vietoris-Rips持久性条形码的精简C++代码,与其它软件包相比,Ripser的运行速度超出40倍,内存效率超过15倍,且没有外部依赖,可以大大提高计算的时间和效率[11]。因此,本文选用Ripser软件包来构建复形结构,编程环境为Python语言的Pycharm。
在读取简化后三维模型点的信息后,调用Ripser库中的ripser函数为每个三维模型构建Vietoris-Rips复形,获取到复形过滤流下的一维贝蒂数,它比零维贝蒂数能更好地表征三维模型内部本质的拓扑特征。图6为对三维模型数据集中的一个杯子模型构建Vietoris-Rips复形后,得到零维和一维下的贝蒂数,将其表示在条形码图(左图)和持久性图(右图)中,形成特征描述子。
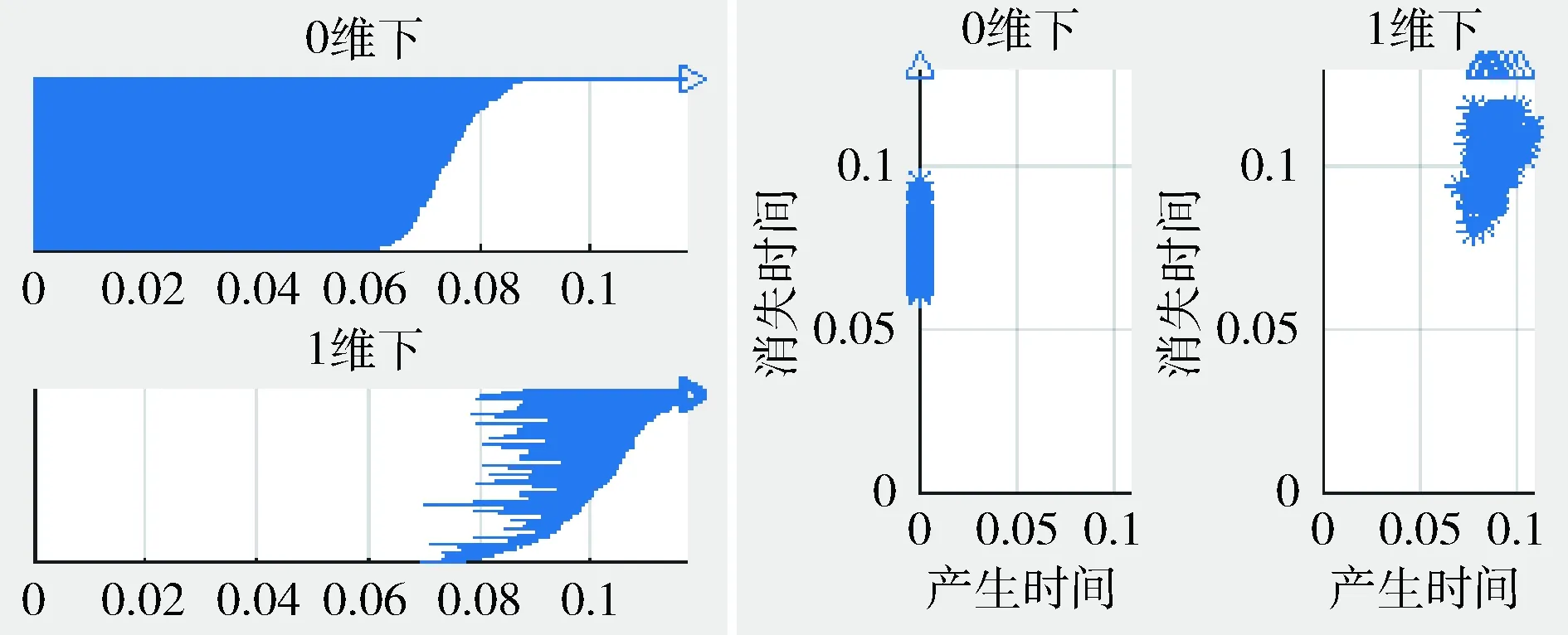
图6 杯子的特征描述子图
2.3 相似性度量
Wasserstein距离在数值上只能计算一维高斯分布的情况,而本文计算的是二维持久性图间的相似性,故此提出一种分段的Wasserstein距离来度量持久性图之间的相似性。分段的Wasserstein距离是对Wasserstein距离的一个改进,其基本原理为:让通过原点的多条线去划分持久性图的平面,将二维的点投影到每条线的方向上,从而将二维点集投影为一维点集,然后再计算两个一维点集间的Wasserstein距离,最后将各个方向上Wasserstein距离累加求和再平均,即为最终距离。本方法将提取到的拓扑特征以点的形式记录在持久性图中,在第一象限内的多个方向上进行多次迭代,得到分段Wasserstein距离。计算过程分为对角线投影、Wasserstein距离计算、迭代求平均这3个步骤。
(1)投影到对角线
假设有两个持久性图dg1和dg2,其中dg1为m个点构成的特征集合,dg2为n个点构成的特征集合,将dg1的点投影到y=x这条对角线上,并将投影后的点加入到dg2中。同理,将dg2的点投影到y=x这条对角线上,将投影后的点加入到dg1中。投影到对角线保证了两个持久性图在进行相似性度量时特征向量个数一致,并且仍保留各自的特征分布,原始的持久性图表示如下
(5)
投影到对角线后得到
(6)
(2)计算Wasserstein距离
计算Wasserstein距离的示意图如图7所示。从原点射出的某条直线与X正半轴成θ角,且满足sinθ2+cosθ2=1,由式(7)依次计算dg1中每个点和这个方向的点积
(cosθ,sinθ)·(xi,yi)=xicosθ+yisinθ=Xi,i=1…(m+n)
(7)
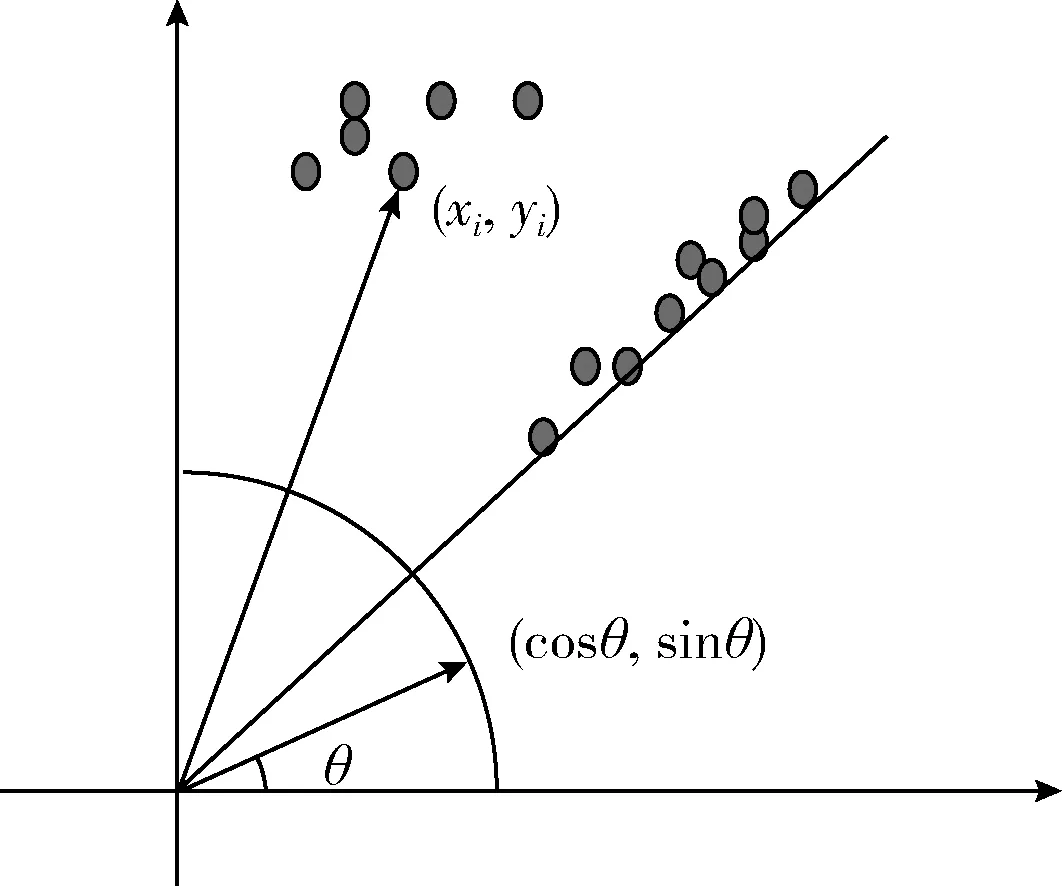
图7 计算Wasserstein距离
将结果计入V1数组并排序,同理计算dg2中每个点与该方向的点积,将结果计入V2数组并排序
(8)
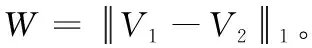
(3)迭代求平均
将第一象限平均分成M个方向,即迭代次数为M。为了加快计算过程,可以设置较小的迭代次数,实验结果表明迭代次数较少时也能得到较好的检索效果。从0开始以s=π/2/M的角度递增,在每个方向上计算出一维数据的Wasserstein距离,之后累加求和再平均得到分段Wasserstein距离(式(9))。以此作为两个持久性图之间的差异值,该值越小表示两个持久性图的分布越近似,说明两个三维模型越相似。迭代的目的是使两个持久性图在多个方向上计算差异,通过迭代求平均使实验结果更准确,更具有稳定性
(9)
3 实验结果及分析
3.1 实验环境及数据
本研究实验硬件环境为Intel(R)Xeon(R)CPU E5-1603 v3 @ 2.80 GHz 2.80 GHz,内存为16 GB,软件环境为64位的windows 10、matlab2013b、PyCharm Community Edition 2018.3.2。实验数据集来源于2011年的三维模型检索竞赛(SHREC TRACK 2011)的标准数据库[15],本数据集包括600个三维模型,共分为30个类,每类20个三维模型。
3.2 评价标准
为了衡量检索效果的好坏,本文使用检索领域常用的评价参数NN(nearest neighbor)、F-T(first tire)、S-T(second tire)、E(e-measure)、DCG(discounted cumulative gain)来进行评估。假设目标类模型个数为C,K为需检索出的模型个数,则NN表示当K=1时正确检索到的目标模型的比例;F-T表示当K=C-1时正确检索到的目标模型的比例;S-T表示当K=2*C-1时正确检索到的目标模型的比例;DCG表示根据检索结果的排列顺序来评价检索优劣;E为查全率和查准率的综合评价参数。为了更好地表征三维模型检索的效果,通常还采用P-R图表示数据集整体的查全率和召回率。
3.3 实验结果
本文实验结果分为两部分,第一部分是本文方法的检索结果,第二部分是本方法与其它方法的实验数据对比。
(1)采用本文方法对“蚂蚁”、“钳子”三维模型进行检索,这两类三维模型在本数据集中各有20个,所以本实验检索出与目标模型最相近的前20个三维模型,以评价检索的准确性,检索结果如图8所示。由图8可以看出,除个别三维模型外,其余模型与目标模型同属一类,由此得出,本文方法可以有效地检索出目标模型,准确率较高。
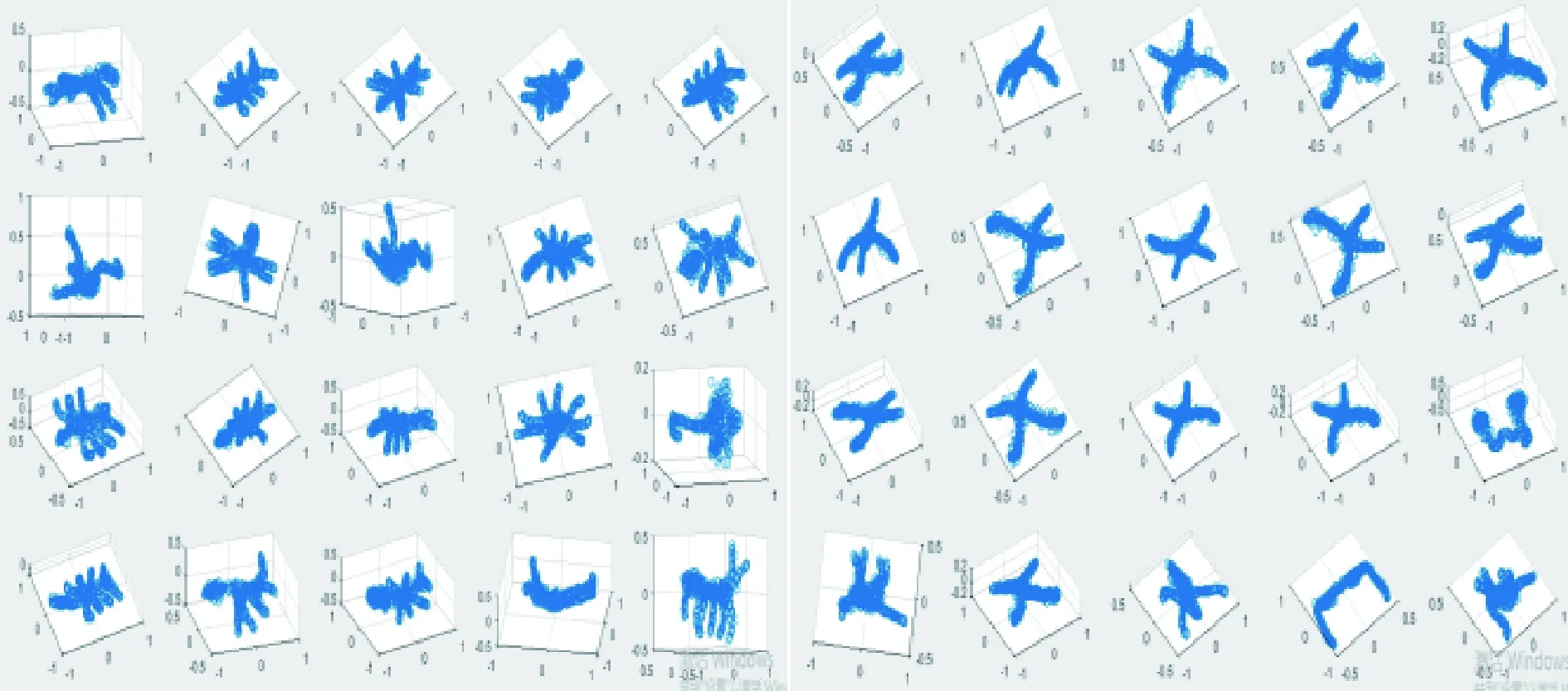
图8 检索结果
(2)本文实验与Osada等的形状概率分布方法(shape distribution,D2)、Sun等的热核特征方法(heat kernel signature,HKS)[16]、Sipiran等的角点检测方法(Harris 3D geodesic map,Harris3DGeoMap)[17]和焦世超等的多特征融合流行排序方法(multi-features fused manifold ran-king,M-F FMR)[18]进行了对比。D2方法首先计算所有点之间的距离,然后将所有距离值作为特殊分布表示在直方图中。HKS方法对模型上每个点的热量变化曲线离散化,之后获取全部点的特征,进而得到整个模型的热核特征。Harris3DGeoMap方法采用3D Harris算法选取原始模型小部分的显著兴趣点,用特征分布直方图表示兴趣点间测地线距离的差异。Harris3DGeoMap16和Harris3DGeoMap32分别表示直方图区间数目为16和32条件下的Harris3DGeoMap实验。M-F FMR方法采用融合特征对二维视图提取特征,然后利用深度学习对草图进行语义标注,再使用流行排序算法实现二维草图到三维模型的检索。
这几种方法都是在SHREC TRACK 2011的三维数据集上进行实验,实验结果具有可比性。对NN、F-T、S-T、E、DCG参数进行实验对比,结果见表1,这些值越接近于1表明检索效果越好,从表中看出本文的全部参数优于所有对比方法。同时绘制P-R曲线图进行对比,结果如图9所示,该图走向越趋向于右上方说明检索效果越好,从图中可以看出本文方法的曲线均高于其它方法。

表1 6种检索方法的评价参数

图9 6种检索方法的P-R曲线
综上,实验结果表明,本文提出的基于持久同调的三维模型检索方法具有较高的准确率,在检索结果(图8)中可以看到准确检索到了待查询的模型;此外,本文方法的评价参数和P-R曲线图均优于其它方法。
4 结束语
本文将持久同调理论应用于三维模型检索,提出了一种基于持久同调的三维模型检索方法,能够在不降维的情况下提取出三维模型的全局特征描述子,该描述子具有旋转、平移和尺度不变性,在数据扰动的情况下具有很好的稳定性,可全面有效地表征任意拓扑结构的三维模型的特征。另外提出了区分性更好的分段Wasserstein距离,对持久性图之间进行了更为准确的相似性度量,进一步提高了三维模型检索的查准率和查全率。本文研究结果对今后三维模型检索提供了一种新的研究思路和设计方法。鉴于时间与空间上的计算资源限制,本文未能将三维模型的全部点计算在内,而是进行了降采样处理,客观上降低了检索效率。在今后的研究中将利用并行计算资源来完善实验环节,提高检索准确率。
猜你喜欢
阅读(快乐英语中年级)(2024年6期)2024-10-14 00:00:00
舰船科学技术(2022年20期)2022-11-28 08:23:02
化工管理(2021年7期)2021-05-13 00:44:56
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:26
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
自动化学报(2017年4期)2017-06-15 20:28:54
电测与仪表(2015年3期)2015-04-09 11:37:56
