
利用门控循环编解码网络的语音增强方法
2020-06-12 11:43:06常新旭寇金桥徐冬冬
计算机工程与设计 2020年6期
常新旭,张 杨,杨 林,寇金桥,王 昕,徐冬冬
(中国航天科工集团第二研究院 北京计算机技术及应用研究所,北京 100854)
0 引 言
语音增强是研究如何抑制噪声影响提升被污染语音的质量与可懂度的技术,在语音识别、移动通信和人工听觉等诸多领域有着广泛的应用前景[1]。近年来,研究人员将深度学习技术应用在语音领域,相较于谱减法,维纳滤波法等方法明显改善了恶劣噪声环境下的语音增强性能[2,3]。
从监督学习的角度看,基于深度学习的语音增强方法主要关注3个部分:特征、优化目标和网络模型。幅度调制谱、傅里叶对数幅度谱和梅尔倒谱系数是常用的语音增强特征。通常用于语音增强任务的优化目标可分为基于映射[2-4]的目标和基于时频掩蔽[5]的目标。语音增强领域也引入各种网络模型用以改善增强语音的质量,如深度前馈神经网络(deep feedforward neural network,DFNN)[3,5]、循环神经网络(recurrent neural network,RNN)[4,6,7]和卷积神经网络(conventional neural network,CNN)[8,9]。
为提升语音增强性能,该文从网络模型角度出发,结合人类在噪声环境中听觉感知的原理,在语音增强任务中引入编解码器架构,利用循环神经网络对带噪语音信号进行建模,以充分利用当前待增强语音帧和相邻帧之间的上下文关系,并且通过实验在包含700位不同说话人的语音数据集上验证了该方法的有效性。
1 相关研究
RNN是一类专门用于处理序列数据的神经网络。目前,循环神经网络已经被成功应用在语音识别的声学模型当中,大幅提高了语音识别的准确率,大量相关工作表明RNN在处理语音信号方面具有很大的优势[10,11]。虽然RNN在处理序列化数据方面具有强大的优势,但是传统RNN在实际应用时候会出现长期依赖问题。在传统循环神经网络中,当时间步过大或者过小时,使用通过时间的反向传播算法会使得循环网络的梯度出现衰减或者爆炸的现象。为了解决这一问题,门控循环网络(gated RNN)应运而生,通过加入门控单元来有选择地保留或者遗忘历史信息,有效解决了梯度衰减或爆炸问题。
常见的门控循环网络包括两种,分别是长短期记忆网络(long short-term memory,LSTM)和门控循环单元(gated recurrent unit,GRU)[12]网络。
LSTM是一种RNN的变体网络,通过3个门的控制巧妙地解决了传统RNN中存在的梯度消失问题。受到RNN在语音识别领域成功应用的启发,LSTM开始被应用在语音增强领域。Liu等使用基于LSTM-RNN的语音增强系统用作语音识别的前端,小幅提高了语音识别的准确率[6]。Sun等[4]注意到基于映射的语音增强方法在低信噪比的情况下具有较好的可懂度,基于预测IRM(ideal ratio mask)的语音增强方法在较高信噪比的情况下具有更好的表现,提出一种多目标学习的语音增强方法,相较于深度前馈神经网络方法提升了语音增强性能,但是其对算力有一定要求并且所需训练时间较长。而Wang等[13]则应用LSTM-RNN来解决说话人泛化问题,实验结果表明LSTM-RNN具有更加强大的对说话人的建模能力。然而,他们实验使用的训练集仅包含78位说话人,远少于常用语音增强实验timit数据集中的630位,并未充分挖掘RNN对不同说话人的建模能力。
GRU网络是另外一种变体的RNN,不同于LSTM有3个门来控制信息传输,在GRU中将遗忘门和输入门合成为一个单一的更新门。相较于LSTM,GRU的网络结构更为简单,需要的参数更少,所需的训练时间更短,同时也可以解决长期依赖问题。与LSTM类似,目前GRU也开始被应用在语音增强领域。Wichern等[14]以时频掩蔽为训练目标,通过使用GRU实现lookahead模型,解决了双向RNN语音增强方法无法满足实时应用低时延要求的问题。但是基于时频掩蔽的方法对语音与噪声有独立性假设,而这种假设并不满足实际需求。
为进一步提升深度学习语音增强方法在说话人未知场景下的语音增强性能,该文提出基于门控循环编解码网络的语音增强方法,并通过实验度量增强语音的质量与可懂度,从而客观评价该方法的语音增强性能。
2 基于深度学习的语音增强
假设含噪声的语音信号为y,其是由不含噪声的干净语音信号s和加性噪声d组成,即
y=s+d
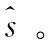
该文按照文献[3,4,15]的方式,选取含噪语音和干净语音的对数功率谱作为训练特征和训练目标,信号的对数功率谱可以由时域信号经过短时傅里叶变换和对数运算计算得到。网络使用小批量梯度下降法训练,本文中使用的损失函数定义如下
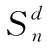
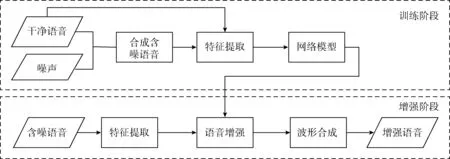
图1 基于深度神经网络的语音增强系统
3 门控循环编解码网络
3.1 上下文信息在语音增强中的利用
通常为更好地利用上下文信息,基于深度学习的语音增强方法会采用由相邻多帧语音信号特征所组成的特征矩阵作为网络输入[15]。然而,DFNN在处理矩阵输入的时候,会将其拉平为一维向量。对于具有时序特性的语音信号而言,这样做无法对相邻帧之间的时频关系进行清楚的建模[4]。RNN具有短期记忆的特点,隐藏状态能够捕捉到输入序列的历史信息,相较于DFNN语音增强方法,进一步提升了语音增强性能。当前使用RNN的语音增强方法,是将网络对输入特征序列的建模直接作为当前待增强帧的干净语音信号估计,没有充分利用当前帧信号和上下文信息之间的联系,其模型如图2所示(图2以两层网络为例)。但是,对于语音增强任务,噪声类型会影响增强语音的效果,特别是噪声信号与干净语音信号十分相似或者背景噪声中包含语音成分的条件下,如咖啡馆、电视机和广场等噪声环境,基于深度学习的语音增强方法容易把噪声信号误认为是干净语音信号[8]。事实上,人类听觉中枢在噪声环境下可以依据背景信息修复被噪声污染的音素或音节,这一现象被称为音素恢复(phonemic restoration)[16]。依据这一现象,在对当前帧进行语音增强时,考虑到上下文背景信息的影响,能够提升语音增强性能。因此,笔者提出在语音增强任务中引入编解码器架构,使用编码器对相邻多帧语音信号建模以提取上下文信息,利用解码器挖掘当前待增强语音帧和上下文信息之间的联系。

图2 普通循环神经网络语音增强模型
3.2 网络结构
该文所提出的语音增强网络整体上采用编码器解码器架构。编解码器最早运用于神经机器翻译领域以实现源语言句子到目标语言句子的转换。其中,编码器用于提取源语言句子的编码表示,解码器根据编码器输出逐步生成目标端字符。通过应用编解码器架构可以更有效地处理不定长的输入和输出。
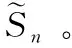
C=Eencoder(X)

rt=σ(Wrxt+Urht-1+br)
zt=σ(Wzxt+Uzht-1+bz)
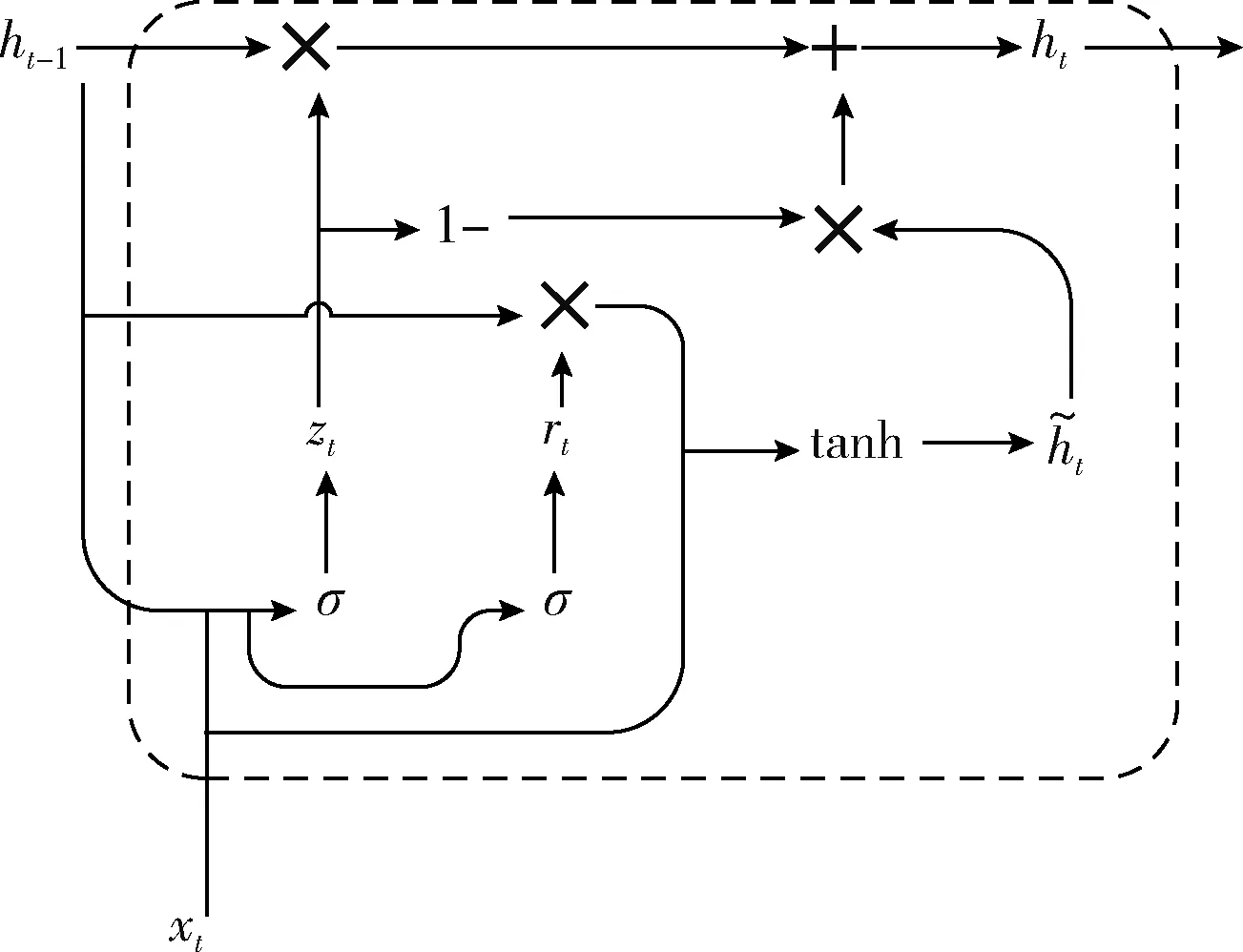
图3 GRU单元结构
此处删除了参数的说明。GRU的网络层数与网络节点数的设置取决于问题的规模,针对本文所使用的数据集规模,本文通过实验比较不同架构的语音增强性能,提出编码器GRU层数为2层,解码器部分层数为2层,每层的节点数目为1024,整体结构如图4所示。
编码端GRU-RNN每个时间步的输入依次为相应帧的对数功率谱特征,GRU-RNN层通过更新门和重置门的控制捕捉带噪语音特征的序列信息,并且逐层抑制背景噪声的影响,最终输出一个包含整个输入序列语音信息的高层特征表示向量。解码端不同于神经机器翻译中的“多对多”的输出,语音增强系统是逐帧进行语音增强,因此文中解码器最终只输出当前待增强语音的干净语音特征估计,即只输出一帧。解码器将当前待增强语音信号特征和解码器的输出作为输入,经过GRU运算以充分挖掘上下文信息与当前帧之间的联系,输出对当前帧的干净语音特征估计。这一过程类似于人类在复杂听觉环境中结合上下文信息处理所收到的语音信息。
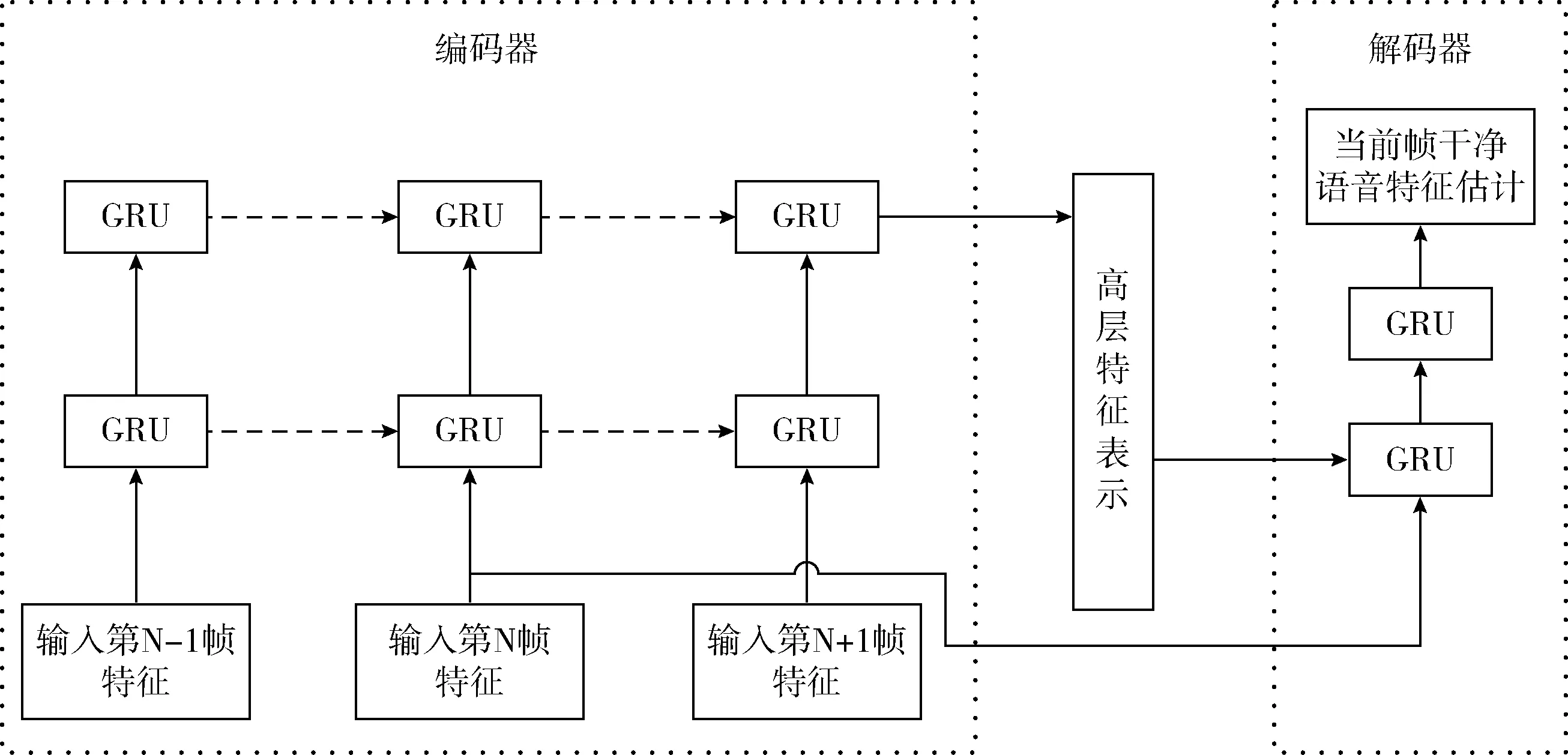
图4 深度门控循环编解码网络
4 实验设置与结果分析
4.1 实验基本设置
为合成实验需要的训练集数据,该文按照每人10条语音的标准,从中文语音数据集FREE ST Chinese Mandar in Corpus随机抽取700名说话人的语音,共计7000条语音作为干净训练语音。噪声数据使用文献[19]中的100种噪声。针对每条干净语音,随机选取两种不同噪声,并随机从-10 db,-5 db,0 db,5 db,10 db当中随机选取一种作为全局信噪比,将语音与噪声数据合成,得到14 000条数据。测试集语音数据按照每人5条语音的标准,随机选取不同于训练集数据的30位说话人的语音,得到150条干净语音数据。测试集噪声数据使用noisex-92数据库[20]中的babble、m109、leopard,volvo和machinegun噪声。将选取的语音数据和噪声数据按照-6 db、0 db和6 db 这3种信噪比进行合成,构成2250条测试集带噪语音数据。
实验所提取的特征是256维的对数功率谱,对数功率谱特征是语音增强实验提取的常用特征。为验证所提出方法的性能,实验选取DNN语音增强方法[3](简记为DNN)和无编解码架构的GRU(简记为GRU)方法,对比所提出的门控循环编解码网络语音增强方法(简记为EN-DE-GRU-X,X代表解码器层数)。DNN网络层数为4,激活函数为ReLU,每个隐藏层包含2048个节点,并且每个隐藏层之后接一个dropout层,dropout层的比例为0.2,网络输入为相邻连续7帧对数功率谱特征。GRU网络层数为2,每层包含1024个节点,网络输入为相邻连续15帧对数功率谱特征。该文基线方法、数据的具体设置与文献[21]的实验设置相同。感知语音质量感知语音质量(perceptual evaluation of speech quality,PESQ)[22]和短时客观可懂度(short time objective intelligibility,STOI)[23]是该文使用的评价指标。
4.2 实验结果分析
表1列出了使用DNN、GRU和GRU编解码网络在3种不同信噪比和6种不同噪声情况下进行语音增强的平均PESQ和平均STOI值。可见,在信噪比、噪声和说话人失配的情况下,经GRU和GRU编解码网络增强的语音平均PESQ值和STOI值均要明显优于经DNN增强的语音平均PESQ值和平均STOI值。这表明DNN对语音序列信号建模能力有限,无法对相邻多帧语音特征中所包含的上下文信息进行有效建模,GRU和GRU编解码网络均可以更好利用上下文信息。
对比GRU和GRU编解码网络,解码器网络为两层的GRU编解码网络,在绝大多数情况下均取得了最佳的语音增强效果。这表明在语音增强的过程中,在充分利用上下文信息的同时,通过引入编码器解码器架构深入挖掘当前待增强帧和上下文信息的联系,可以有效提升语音增强性能。
对比GRU编解码网络解码器的层数。实验最初设置解码器层数为1,发现其语音增强效果相较于GRU方法在多数情况下有所下降。表明,1层解码器的语音增强性能有限。这是因为解码器的输入为当前待增强语音帧,其中包含有噪声信息,而通过堆叠网络层可以逐层消除其中噪声信息的干扰。因此,对解码器网络进行堆叠,并发现当解码器层数大于两层时,网络会出现过拟合现象,所以最终设置解码器层数为两层。
直观比较不同方法的语音增强性能。图5和图6分别给出了,第3号说话人的原始语音,和被0 db m109污染后的含噪语音,以及经不同方法处理后的时域波形图和语谱图。将图5(c)~图5(f)分别与图5(a)和图5(b)对比,可见使用GRU和GRU编解码网络处理后的语音失真,优于经过DNN增强得到的语音的波形失真。对比图5(a),图5(f)、图5(e)、图5(d)表明经解码器层数为2层的GRU编解码网络增强得到的语音波形图与干净语音的波形图最为接近。对比图6各图,GRU和GRU编解码网络相较于DNN更能有效处理含噪语音中的噪声部分,解码器层数为2层的GRU编解码网络具有最佳的抑制噪声和保存含噪语音中语音成分的能力。实验结果充分表明,经过GRU编解码网络增强的语音相较于经过DNN增强和直接应用GRU增强的语音更接近原始的干净语音。

表1 不同方法的语音增强结果
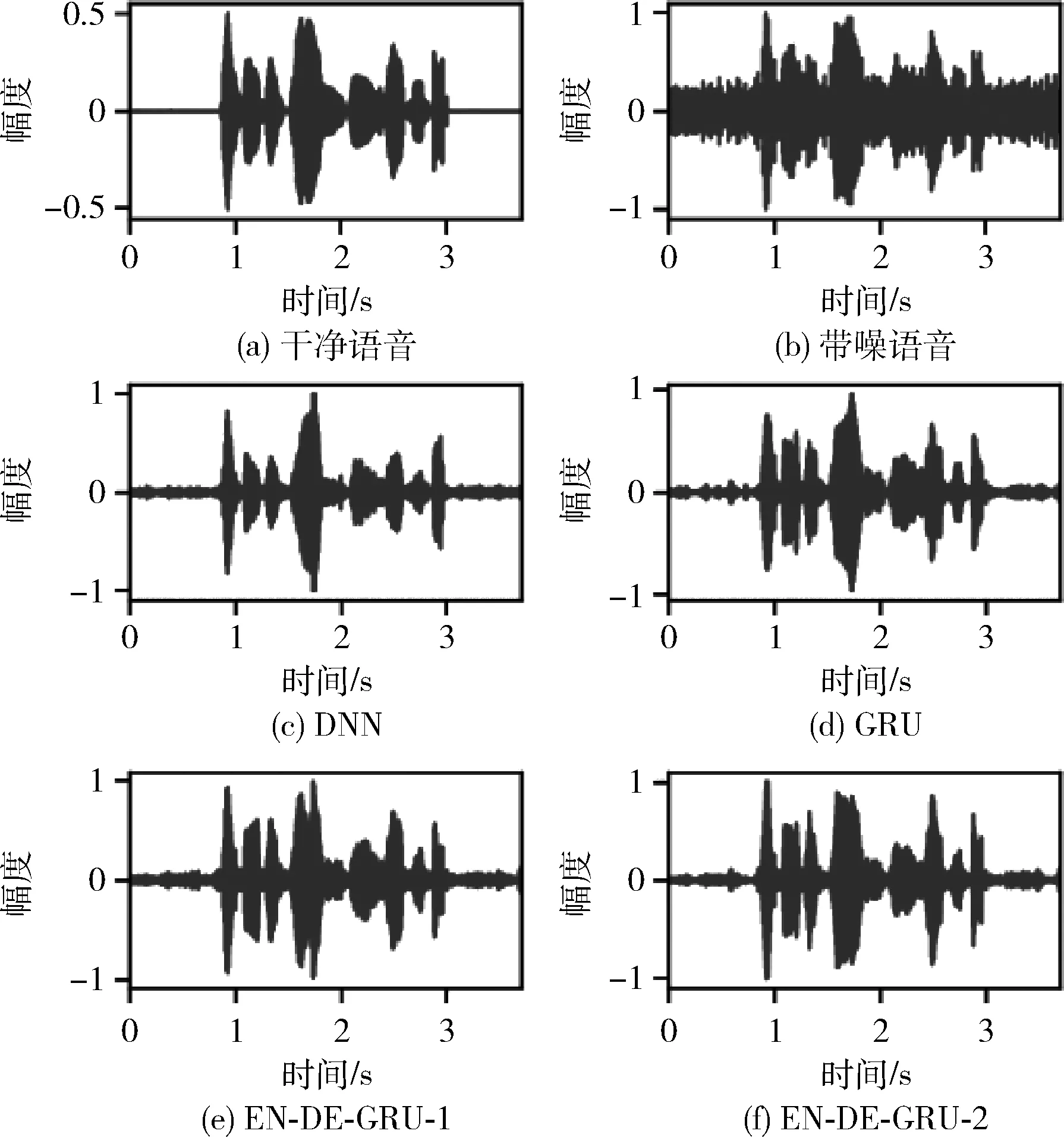
图5 时域波形图比较

图6 对数功率谱比较
5 结束语
该文借鉴人类听觉感知的原理,采用编解码器架构,通过深入挖掘当前帧与上下文信息之间关联,以类比人类在听觉环境中处理语音信号的过程,提出利用门控循环编解码网络的语音增强方法。实验结果表明,文中所提出的方法相较于基于DNN的语音增强方法和直接应用GRU-RNN的语音增强方法,增强语音的质量与可懂度更高,语音增强的性能更好。在接下来的工作中,笔者将更多地关注人类听觉处理的相关机制,并结合深度学习方法的优势,设计更优秀的语音增强网络模型。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
空间科学学报(2020年4期)2020-04-22 01:17:38
家庭影院技术(2019年8期)2019-12-04 14:43:19
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
民用飞机设计与研究(2019年2期)2019-08-05 01:33:26
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
