
一种基于信息熵的IDS告警预处理方法
2020-06-09 08:17申国伟
计算机与现代化 2020年5期
张 羽,郭 春,申国伟,平 源
(1.贵州大学计算机科学与技术学院,贵州 贵阳 550025; 2.贵州省公共大数据重点实验室,贵州 贵阳 550025;3.许昌学院信息工程学院,河南 许昌 461000)
0 引 言
随着计算机网络和信息技术的高速发展,网络安全形势日趋严峻,大规模攻击日趋频繁。为了防范网络攻击,很多安全技术应运而生。入侵检测系统是继防火墙之后的第二道网络安全屏障,是一种主动的安全防护措施,有效弥补了防火墙的不足。虽然目前的入侵检测系统具有强大的攻击检测能力,但是多数的IDS仍然存在大量重复告警的问题,误报率偏高,告警质量低下,只能检测单步攻击行为,无法反映渗透的整体过程以及攻击者的攻击意图,使得安全管理人员难以管理和分析海量告警数据[1-3]。因此,如何减少告警数量,降低误报率,提高告警质量,从中识别出攻击意图,对于入侵路径分析以及攻击者追踪溯源具有重要意义,同时也是一个亟需解决的难题。
IDS告警预处理通常包含误告去除以及告警聚合2个方面。国内外的大量学者针对这2个方面进行了大量的研究,并且取得了一定的研究成果。
现有的误告去除方法有基于机器学习、统计分析以及筛选环境信息的方法。基于机器学习的误告去除算法使用机器学习算法对误告警进行识别。例如解男男[4]提出的采用2种典型的聚类分析算法实现误告去除等。相对于机器学习,统计的方法最突出的优点是高效,最突出的缺点是漏报和误报。统计难以精确地知道哪一条告警是误告,但是可以通过统计异常发现攻击,并且一旦发现规律后,就能大量减少误告。李思达[5]通过对告警信息进行统计发现真实告警与误告的相关告警数目存在巨大差距,因此提出了一种基于相关告警数目的误告去除方法。基于筛选环境信息的方法是根据不同的网络环境构造误告警筛选条件,以此来减少误告[6]。例如Njogu等人[7]提出的基于网络特定漏洞的误告去除方法,通过使用增强的漏洞评估数据来验证告警,从而提高告警质量。
现有的告警聚合方法主要有基于属性相似度以及基于数据挖掘的方法。基于属性相似性的方法最初是由Valdes等人[8]提出。该方法通过定义相似度隶属函数来比较各告警中某些重要属性的相似程度来将告警进行分组和归并为同一类告警,从而减少冗余告警。黄林等人[9]提出了一种改进的多源异构告警聚合方案,通过利用告警属性构造攻击模式约束条件,并在聚合中采用动态时间间隔约束,提高聚合的精确度。李洪成等[10]则提出了基于多级划分思想的告警聚合方法,根据告警属性进行分层聚合。基于属性相似性的告警聚合方法实时性好,算法计算效率高,但是对专家知识库具有较大的依赖性[11-12]。基于数据挖掘的告警聚合方法包括层次聚类算法以及人工神经网络聚类算法[13-15]。基于数据挖掘的告警聚合方法适合任意形状的聚类,但是计算复杂度较高。基于人工神经网络的聚类算法聚合速度快,但是依赖参数的设定。此外还有基于进化算法的告警聚合方法,例如Lu等人[16]提出的基于k-means和遗传算法的告警聚合方法以及白鹏翔等人[17]提出的基于模糊规则的免疫算法。该方法能有效减少告警数量,但却依赖合适的训练集。
现有的IDS告警预处理方法都存在一定的不足与缺陷,并且许多方法定义复杂,而且依赖专家知识。信息熵目前被广泛应用于异常检测[18-20],能够准确地量化真实攻击告警与误告警之间的特征差异,并且能够度量告警所含的信息量。因此本文将信息熵应用于告警关联[21-22]领域,提出一种基于信息熵的IDS告警预处理方法,主要工作如下:
1)提出一种基于互雷尼信息熵的误告去除方法,通过对IDS告警的相关告警密度、周期值、源IP对应的目的IP数以及攻击源威胁度等4个维度的特征进行提取,构造特征信息熵向量,并通过与误告警特征信息熵向量进行互雷尼信息熵计算,以此来检测误告并且予以消除。
2)提出一种基于信息熵的多维告警聚合方法,针对误告去除后的告警信息,采用IP划分、信息熵特征提取、DBSCAN聚类以及动态时间窗口划分等方式进行告警聚合,生成代表单步攻击意图的超告警。
3)在DARPA 2000数据集上进行实验测试,实验结果表明该预处理方法能够有效减少误告,聚合大量相似告警,具有较高的聚合率。
1 告警预处理方法简介
本文提出的基于信息熵的IDS告警预处理方法,包含误告去除以及告警聚合2个阶段。在误告去除阶段,针对入侵检测系统产生的原始告警数据,首先对其进行格式预处理,然后提取4个特征,构造特征信息熵向量,通过与误告警特征信息熵向量进行互雷尼信息熵计算,将计算结果与基础阈值进行比较,从而识别出误告并将其去除。在告警聚合阶段,针对剩余告警数据,按照IP对应关系将其划分为C1与C2这2种类型。分别对2类告警进行特征提取,然后采用DBSCAN聚类算法进行聚类,最后对聚出的类簇进行动态时间窗口划分,并以时间窗口为单位构造超告警。具体方法流程如图1所示。
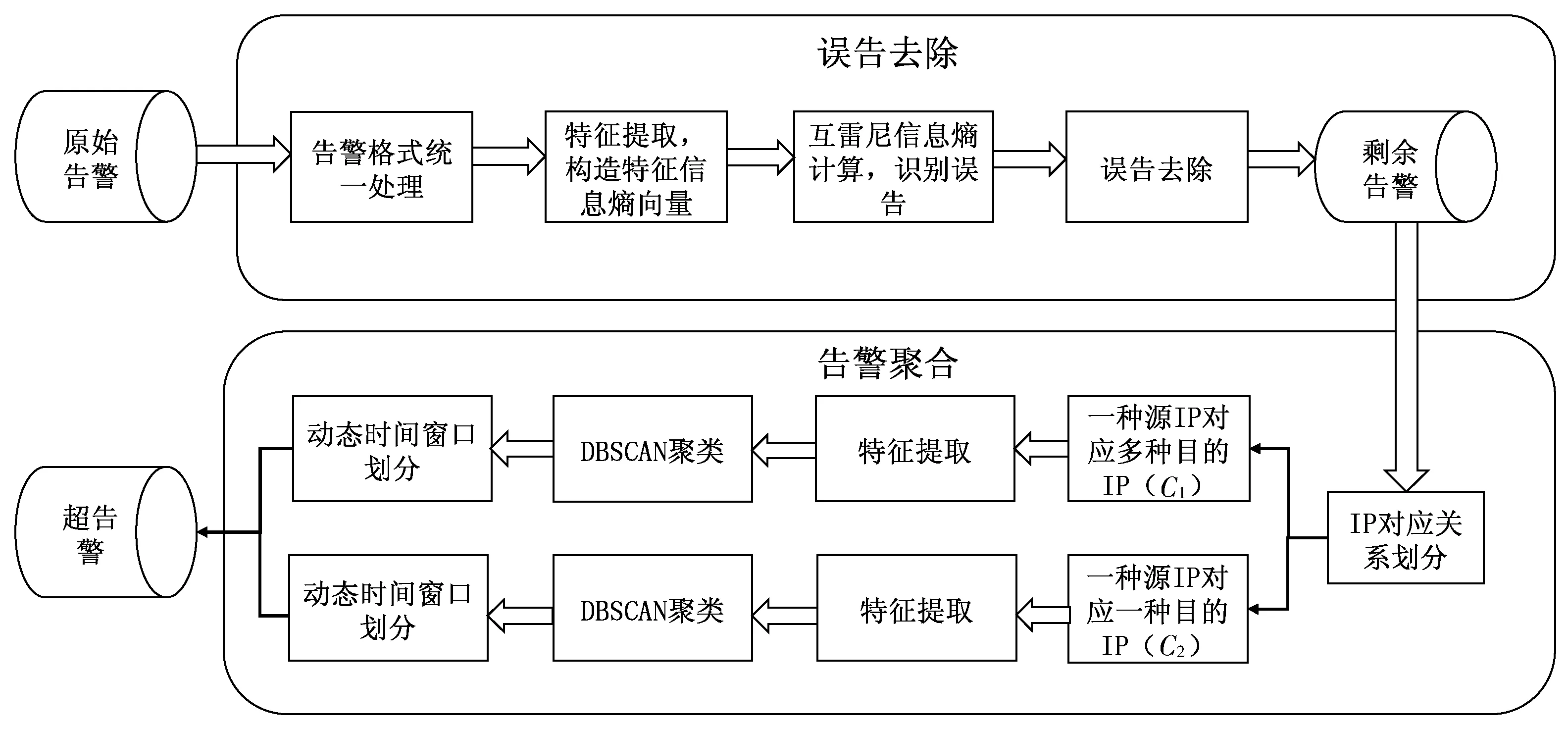
图1 基于信息熵的IDS告警预处理方法流程
定义1告警表示为:Alert={Time, ID, AlertType, Priority, Protocol, SrcIP, SrcPort, DstIP, DstPort}。其中Time表示告警产生的时间,以s为单位,ID表示告警的id, AlertType表示告警类型,Priority表示告警优先级,Protocol表示告警协议,SrcIP和DstIP分别为告警的源/目的IP, SrcPort和DstPort分别为告警的源/目的端口。
2 基于互雷尼信息熵的误告去除方法
2.1 特征提取
选取的事件特征包括:告警密度,告警周期值,源IP对应的目的IP数,攻击源威胁度。
2.1.1 告警密度
告警密度即IDS在单位时间内产生的相关告警数。通过统计大量的告警信息发现,当一个真正的攻击行为发生时,IDS往往会在较短的时间内产生大量的相关告警,而由非攻击行为产生的误告警其告警密度远不及攻击告警的告警密度。因此,将告警密度作为区分真实告警与误告警的一个特征。
定义2对于告警Ai与Aj,当满足以下任一条件时,二者互为相关告警:
1)Ai.SrcIP==Aj.SrcIP &Ai.DstIP==Aj.DstIP
2)Ai.SrcIP==Aj.SrcIP &Ai.AlertType==Aj.AlertType
3)Ai.DstIP==Aj.DstIP &Ai.AlertType==Aj.AlertType
定义3在时间间隔T内,告警Ai的告警密度Di为与其相关的告警数与它们的最大分布时间差的比值,计算方式如下:
(1)
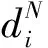
(2)
因此,告警Ai的告警密度Di(Di∈D)所对应的熵表示为:
H(D=Di)=-P(Di)log2P(Di)
(3)
2.1.2 告警周期值
攻击行为产生的真实告警往往具有突发性和随机性,而非攻击行为产生的误告警往往具有周期性,这些周期性的误告通常是由于安全设备配置不当产生的,误告警的整体周期性比真实告警的周期性更强。因此,周期值可以作为区分真实告警与误告警的特征之一。
在告警日志中,真实告警与误告交杂在一起,从时域上难以区分。而傅里叶变换能将时域信号转变为频域信号,因此,通过傅里叶变换将告警时间序列从时域转换到频域进行分析。在频域空间,周期性的告警会呈现相同频率,对频率求导即可得告警周期值。
首先将所有告警信息以二元组的形式表示:<告警名称,源IP>,然后以分钟为单位,统计各类型二元组的告警时间序列:{x(t):t∈N},x(t)表示在第t分钟内产生的同类型二元组数量,N表示统计的分钟数。
接着对告警时间序列进行自相关分析,以加强原始时间序列的周期性,自相关函数[23]定义如下:
(4)
其中,R(m)表示间隔m分钟告警发生的关系度量。对产生的自相关序列{R(m):0mn}进行离散傅里叶变换,得到各个频率的能量密度函数PSD(f):
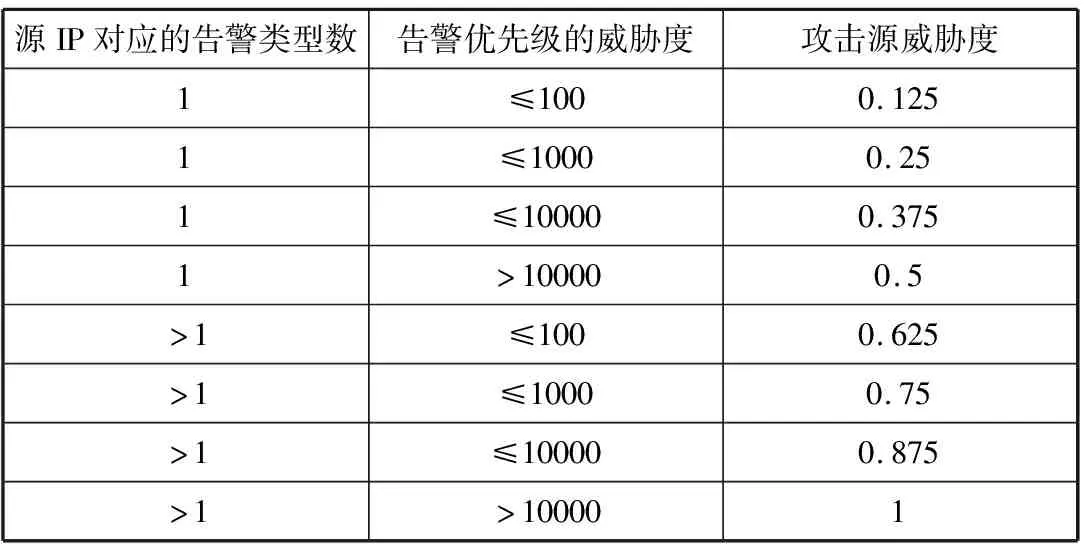
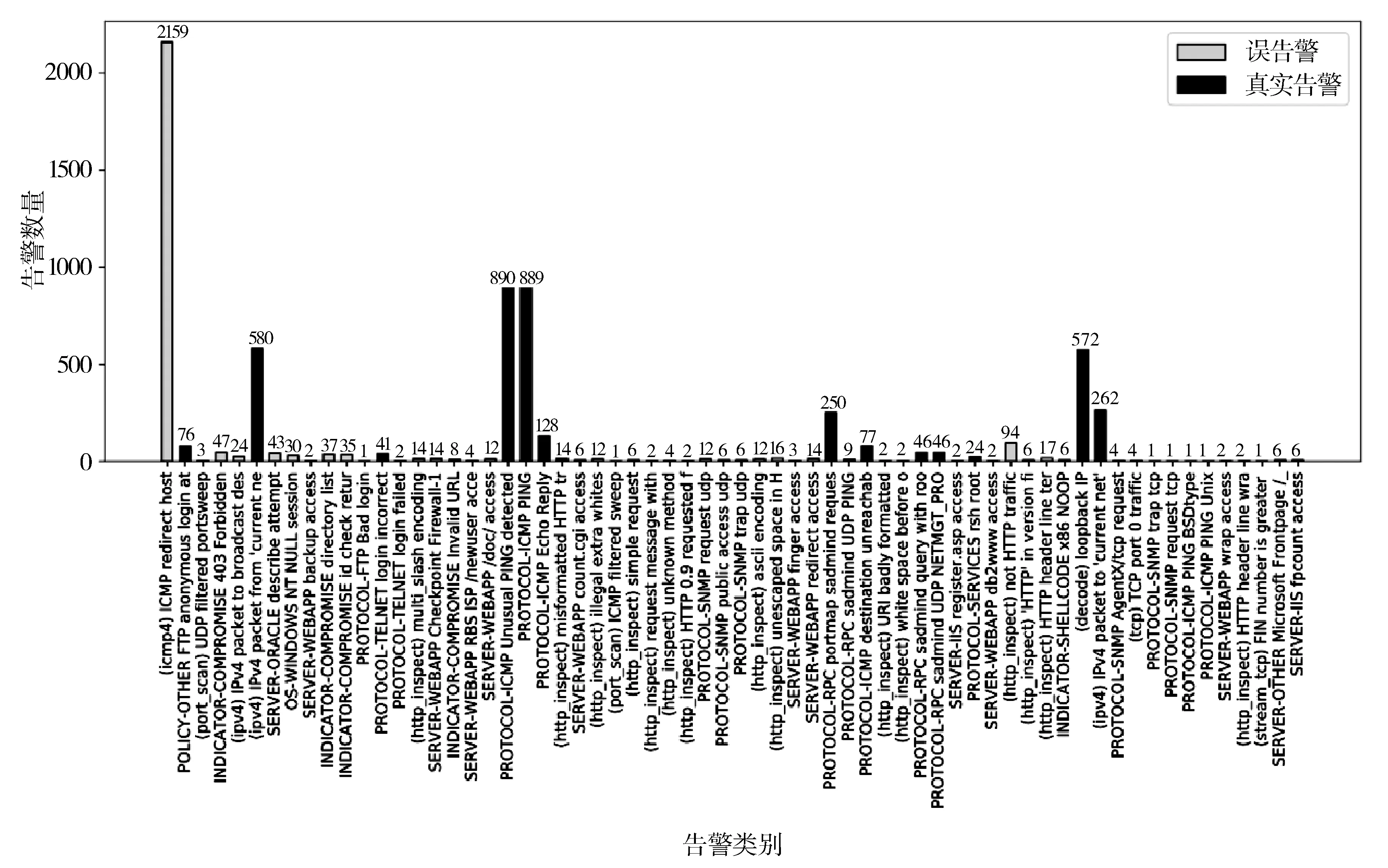
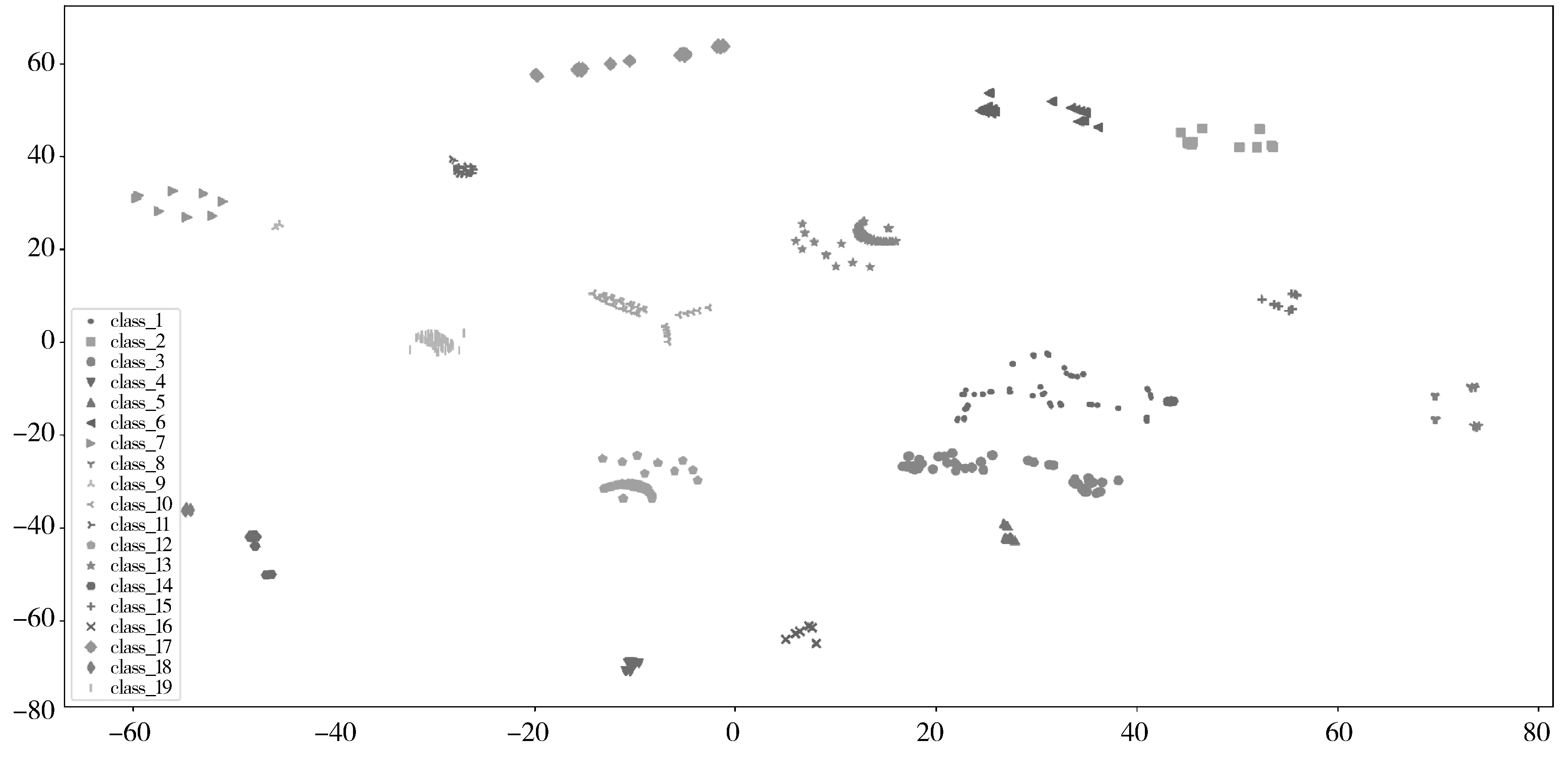
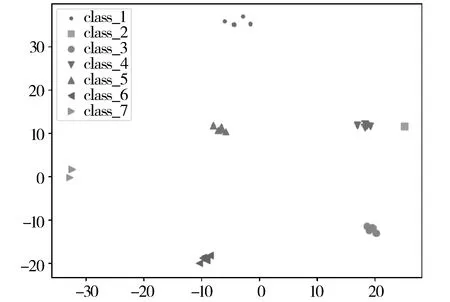
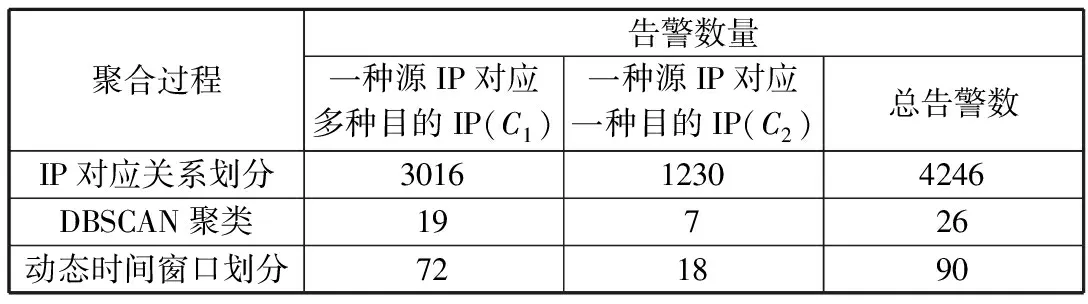
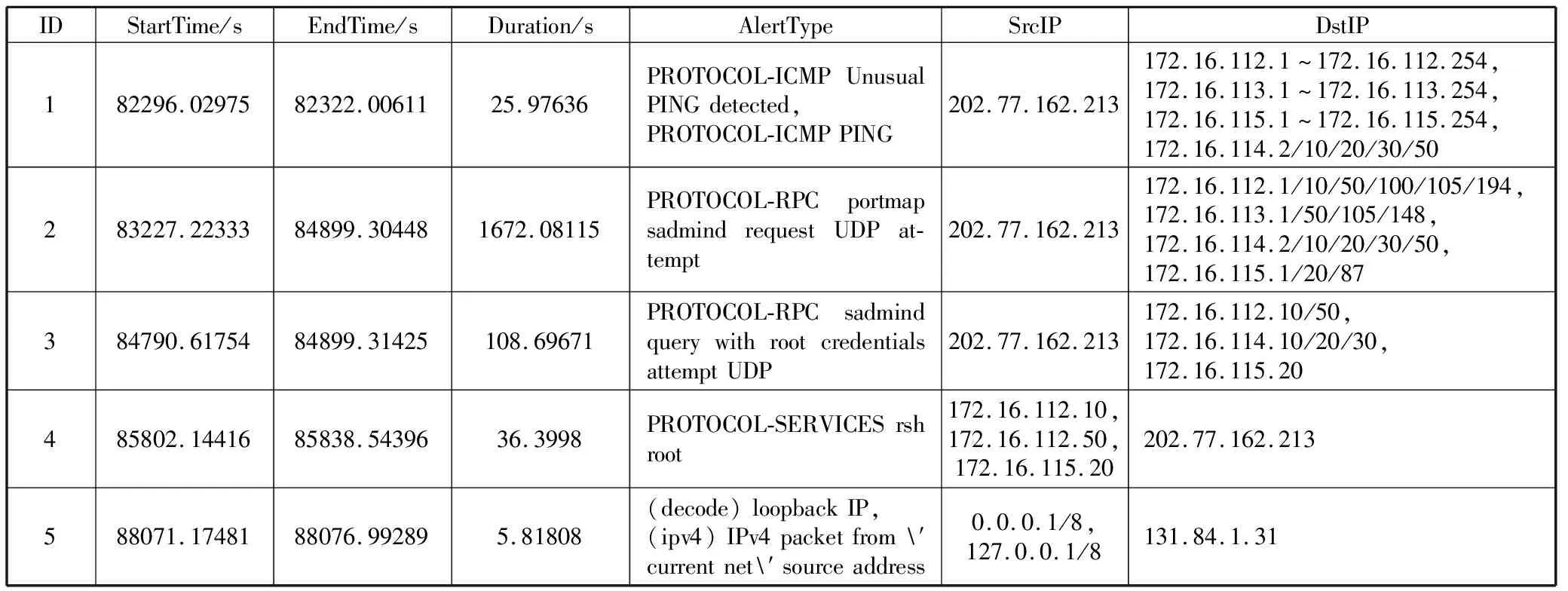
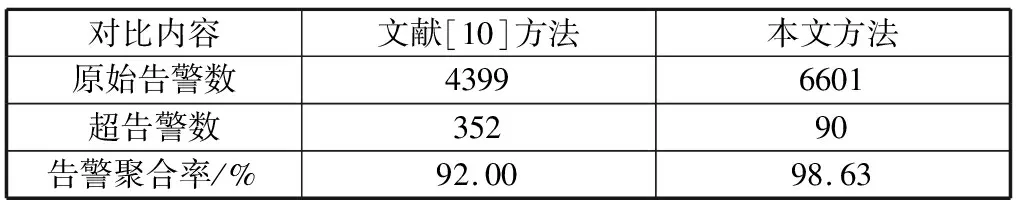
PSD(f)=|DFT(R(m),f)|, 0 (5) 最后找出能量密度值最大的频率点,利用“周期=1/频率”计算出该时间序列的周期,通过这种方法即可求出所有二元组对应告警的周期值。 (6) 因此,告警Ai的周期值Pi(Pi∈P)所对应的熵表示为: H(P=Pi)=-P(Pi)log2P(Pi) (7) 2.1.3 源IP对应的目的IP数 攻击者在进行多步攻击时,通常首先对目标网段进行主机存活性的探测扫描,在确定具体的存活主机后,会针对目标IP发动一系列的后续攻击。因此攻击行为产生的真实告警中源IP所对应的目的IP数往往超过误告警中源IP对应的目的IP数。因此,本文将源IP对应的目的IP数作为区分真实告警与误告警的一个特征。 (8) 因此,告警Ai的源IP对应目的IP数Mi(Mi∈M)所对应的熵表示为: H(M=Mi)=-P(Mi)log2P(Mi) (9) 2.1.4 攻击源威胁度 通过综合衡量一定时间间隔内,源IP对应的告警优先级威胁度之和以及源IP对应的告警类型总数,得到攻击源威胁度。引用文献[20]中的威胁度量化公式ti=5(4-qi)表示告警事件Ai的威胁度,其中qi表示Ai的告警优先级。综合度量攻击源威胁度的规则如表1所示。 表1 攻击源威胁度度量规则 源IP对应的告警类型数告警优先级的威胁度攻击源威胁度1≤1000.1251≤10000.251≤100000.3751>100000.5>1≤1000.625>1≤10000.75>1≤100000.875>1>100001 攻击者在多步攻击过程中,会针对多个攻击目标发动不同类型的攻击行为,并且产生的攻击告警威胁度往往比误告警威胁度更高,因此真实告警的攻击源威胁度比误告警的攻击源威胁度更高。因此攻击源威胁度可以作为区分真实告警与误告警的特征之一。 (10) 因此,告警Ai的攻击源威胁度Ti(Ti∈T)所对应的熵表示为: H(T=Ti)=-P(Ti)log2P(Ti) (11) 互雷尼信息熵[24]可以用来度量2条告警的特征差异程度,当2条告警的特征值相差无异时,互雷尼信息熵趋近于0,而当2条告警的特征值相差较大时,互雷尼信息熵偏离0。通过计算待检测告警与误告警的互雷尼信息熵,采用固定的阈值,便可以检测出待检测告警是否是误告警。具体步骤如下: 1)待检测告警Ai的特征信息熵向量为: F(i)=[H(Di),H(Pi),H(Mi),H(Ti)] (12) 2)信息熵向量归一化的结果表示为: F′(i)=[H′(Di),H′(Pi),H′(Mi),H′(Ti)] (13) 其中,H′=H/Hsum: Hsum=H(Di)+H(Pi)+H(Mi)+H(Ti) 3)误告警的特征信息熵向量为F(f),将F(f)进行归一化后得到F′(f),计算F′(i)与F′(f)的互雷尼信息熵,公式如下: (14) 其中,d表示告警事件的特征维数,p(i)与p(f)分别是F′(i)与F′(f)的概率分布函数。 4)判断待检测告警是否是误告警,通过将互雷尼信息熵值与基础阈值λ进行比较,如果熵值小于或者等于λ,则认为待检测告警是误告警,并将误告警删除,如果熵值大于λ,则认为待检测告警是攻击告警。公式如下: (15) 此外,对结果进行后处理,识别告警集合中源IP为“0.0.0.0”且目的IP为“255.255.255.255”或是告警类型为“(http_inspect)not HTTP traffic”及“(tcp)TCP port 0 traffic”的明显误告警。 基于互雷尼信息熵的误告去除算法如下: 算法1基于互雷尼信息熵的误告去除算法。 Input:原始告警Alert=[A1,A2,…,An],基础阈值λ,误告警特征信息熵向量f=[H_Df,H_Pf,H_Mf,H_Tf]。 Output:误告去除后的剩余告警Alert_New。 1)Begin 2)FalseAlertElimination(Alert,λ,f) 3)set Label_list=[] 4)for each i=0 to len(Alert)-1 do 5)set RS=[]#告警的特征信息熵向量 6)for each j=0 to len(f)-1 do 7)P=(Alert.F[j].count(Alert[i].F[j]))/n 8)H=-Plog2P 9)append(H)to RS 10)result=I0.5(f′,RS′)#f′与RS′为归一化向量 11)if abs(result) 12)label=1 13)else: label=0 14)end if 15)append(label)to Label_list 16)set Alert_New=[] 17)for each k=0 to len(Label_list)-1 do 18)if Label_list[k]==0: 19)append(Alert[k])to Alert_New 20)end if 21)return Alert_New 22)End 误告去除后,将特征属性相似的告警聚合,生成代表单步攻击意图的超告警。 定义4超告警的表示格式为:SuperAlert={ID,StartTime, EndTime, Duration, AlertType, SrcIP, DstIP}。其中ID表示超告警id, StartTime和EndTime分别表示攻击开始时间和结束时间,Duration表示攻击持续时间,AlertType表示攻击类型的集合,SrcIP和DstIP分别表示攻击源和攻击目的集合。 真实攻击场景中,根据攻击源与攻击目的的对应关系可将其划分为2种情况:1)单个攻击源对应多个攻击目的,例如在同一时间段内针对目标网段所发动的扫描探测类攻击,或者是对于存活性主机按照时间先后顺序所发动的一系列攻击尝试,例如非法登录、植入恶意内容、RPC服务攻击等;2)单个攻击源对应单个攻击目的,这种攻击形式多见于攻击者伪造不同的源IP向同一目的IP发动的拒绝服务攻击尝试,或者是不同源IP向同一目的IP发送的ICMP应答回复。因此根据攻击源与攻击目的的对应情况,将告警划分为2类:1)C1={count(Alerti.srcip=>dip)>1, dip∈DIP},其中DIP表示告警集中目的IP的种类,该类型告警满足一种源IP对应多种目的IP; 2)C2={count(Alertj.srcip=>dip)=1, dip∈DIP},该类型告警满足一种源IP对应一种目的IP。 对划分后的2类告警分别进行特征提取,提取的特征包括:告警类型对应的告警数、告警优先级对应的告警数、告警协议对应的告警数、源IP对应的告警数、目的IP对应的告警数。假设经过初步划分后的某类告警集合表示为: A={a1,a2,…,an} (16) 1)告警类型对应的告警数。 如果所有告警的告警类型数量为k,则告警类型的集合表示为: T={t1,t2,…,tk} (17) 如果告警类型为ti的告警事件数为mi,则每个告警类型对应的告警数分别为: M={m1,m2,…,mk} (18) 如果告警ai的告警类型为ti,告警总数为n,则ai的告警类型ti(ti∈T)所对应的熵表示为: H(T=ti)=-(mi/n)log2(mi/n) (19) 2)告警优先级对应的告警数。 如果告警ai的优先级为li,li对应的告警数量为ri,告警总数为n,则ai的告警优先级li(li∈L)所对应的熵表示为: H(L=li)=-(ri/n)log2(ri/n) (20) 3)告警协议对应的告警数。 如果告警ai的告警协议为pi,pi对应的告警数量为qi,告警总数为n,则ai的告警协议pi(pi∈P)所对应的熵表示为: H(P=pi)=-(qi/n)log2(qi/n) (21) 4)源和目的IP对应的告警数。 如果告警ai的源IP为si,目的IP为di,si对应的告警数量为gi,di对应的告警数量为ui,告警总数为n,则ai的源IPsi(si∈S)以及目的IPdi(di∈D)所对应的熵表示为: H(S=si)=-(gi/n)log2(gi/n) (22) H(D=di)=-(ui/n)log2(ui/n) (23) 告警ai的特征信息熵向量为: H(ai)=[H(ti),H(li),H(pi),H(si),H(di)] (24) 由于相同或者相似的告警具有相同或者相似的特征信息熵,因此可以采用聚类算法将特征相似的告警聚集为一类。本文采用DBSCAN聚类算法,DBSCAN是基于密度空间的聚类算法,它不需要预先确定聚类的数量,而是直接基于数据本身的紧密程度来推测聚类的数目。DBSCAN需要输入2个参数:扫描半径eps和最小包含点数MinPts。 由于不同的攻击类型攻击速度不同,导致产生的告警时间间隔不同,例如扫描类攻击通常在较短的时间内爆发大量相似的告警,相邻告警的时间间隔几乎为0。而有些攻击类型产生的相邻告警间隔时间则较长,例如使用根证书尝试UDP的远程调用sadmind请求,该类型的相邻告警时间间隔为几分钟。因此为了适应不同的攻击速度产生的告警的密集程度,引入文献[9]所提出的时间间隔相对均方差方法来动态划分时间间隔。 首先将各个类别的告警按照时间先后顺序排序,将初始时间间隔阈值设为600 s,然后计算出前600 s内的告警时间间隔阈值作为初始阈值,接着计算下一条告警与600 s时间窗口内的最后一条告警的时间间隔,如果时间间隔小于或者等于初始阈值,则将下一条告警与之前告警聚合,并更新时间间隔阈值。如果时间间隔大于初始阈值,则将下一条告警作为一个新的时间窗口的起始告警,并将当前告警时间以后600 s内的告警归入当前时间窗口。重复上述方式,直到将一个类别中的告警全部划分完时间窗口。最后以各个时间窗口为基本单位构造代表单个攻击意图的超告警。 实验采用了林肯实验室提供的公开数据集DARPA 2000[25]的LLS_DDOS1.0以及LLS_DDOS2.0这2个攻击场景,利用开源入侵检测系统snort 3对数据集进行回放,配置snort的社区规则,产生告警。这2个数据集分别包含了一个完整的DDOS多步攻击场景。 首先利用官方文档给出的攻击场景说明对原始告警进行标记(0表示真实告警,1表示误告警),LLS_DDOS1.0总共产生了6601条告警,其中真实告警为3921条,误告警为2680条,误告率达到40%。总共包含64种攻击类型,告警分类统计如图2所示。LLS_DDOS2.0总共产生了2710条告警,其中真实告警为1356条,误告警为1354条,误告率达到50%。总共包含58种攻击类型,告警分类统计如图3所示。 图2 LLS_DDOS1.0告警分类统计结果 图3 LLS_DDOS2.0告警分类统计结果 接下来将LLS_DDOS2.0攻击场景产生的告警集作为训练集,LLS_DDOS1.0攻击场景产生的告警集作为测试集,利用训练集产生误告警平均特征信息熵向量以及基础阈值。 通过对训练集进行统计分析,得到训练集中真实告警与误告警在告警密度、告警周期值、源IP对应的目的IP数、攻击源威胁度等特征上的信息熵值,然后构造特征信息熵向量,并分别求出训练集中真实告警的平均特征信息熵向量以及误告警的平均特征信息熵向量。最后对二者计算互雷尼信息熵,得到基础阈值。特征信息熵向量以及基础阈值如表2所示。 表2 特征信息熵向量及基础阈值 真实告警平均特征信息熵向量误告警平均特征信息熵向量基础阈值(λ)[0.2665,0.0384,0.3396,0.3554][0.1446,0.0480,0.3996,0.4079]-0.0337 4.3.1 误告去除实验结果 在确定了误告警的特征信息熵向量以及基础阈值后,用测试集来测试该方法的性能。首先对测试集进行特征提取,构造特征信息熵向量,然后与误告警的平均特征信息熵向量进行互雷尼信息熵计算,最后将计算结果与基础阈值进行比较,从而检测出测试集中的真实告警与误告警。定义消除率TPR、误消除率FPR以及漏消除率FNR等指标来衡量误告去除效果,公式如下: TPR=TP/(TP+FN) FPR=FP/(TN+FP) FNR=FN/(TP+FN) 其中,TP表示将误告警识别为误告的数量,TN表示将误告警识别为真实告警的数量,FP表示将真实告警识别为误告警的数量,FN表示将真实告警识别为真实告警的数量。采用互雷尼信息熵误告去除算法对测试集进行误告去除,结果如表3与表4所示。 表3 误告去除结果 原始告警数量原始告警中误告警数量误告去除后的告警数量误告减少数量6601268042462355 表4 误告去除效果 消除率/%误消除率/%漏消除率/%87.430.3112.57 4.3.2 告警聚合实验结果 首先将误告去除后的告警按照IP对应关系进行划分。然后将C1与C2这2种类型的告警分别采用DBSCAN进行聚类,根据生成的聚类图形以及轮廓系数综合评估聚类的效果。轮廓系数可以用来评价聚类效果的好坏,它结合内聚度与分离度2种因素,取值在[-1,1]区间,值越接近于1,说明同类样本相距越近,不同样本相距越远,聚类效果也越好。对于C1类型告警,设置MinPts=10, eps=6.5,聚类效果如图4所示,聚为19个类,轮廓系数为0.8378。对于C2类型告警,设置MinPts=10, eps=5.0,聚类效果如图5所示,聚为7个类,轮廓系数为0.9584。 图4 C1类型告警聚类图 图5 C2类型告警聚类图 接着对C1和C2聚类后的26个类型的告警进行动态时间窗口划分,其中C1类型聚类后的19个类别的告警划分为72个时间窗口,C2类型聚类后的7个类别的告警划分为18个时间窗口。聚合结果如表5所示。 最后将各个时间窗口内的告警构造成代表单步攻击意图的超告警,部分超告警如表6所示。 表5 聚合结果 聚合过程告警数量一种源IP对应多种目的IP(C1)一种源IP对应一种目的IP(C2)总告警数IP对应关系划分301612304246DBSCAN聚类19726动态时间窗口划分721890 表6 超告警数据 IDStartTime/sEndTime/sDuration/sAlertTypeSrcIPDstIP182296.0297582322.0061125.97636PROTOCOL-ICMPUnusualPINGdetected,PROTOCOL-ICMPPING202.77.162.213172.16.112.1~172.16.112.254,172.16.113.1~172.16.113.254,172.16.115.1~172.16.115.254,172.16.114.2/10/20/30/50283227.2233384899.304481672.08115PROTOCOL-RPCportmapsadmindrequestUDPat-tempt202.77.162.213172.16.112.1/10/50/100/105/194,172.16.113.1/50/105/148,172.16.114.2/10/20/30/50,172.16.115.1/20/87384790.6175484899.31425108.69671PROTOCOL-RPCsadmindquerywithrootcredentialsattemptUDP202.77.162.213172.16.112.10/50,172.16.114.10/20/30,172.16.115.20485802.1441685838.5439636.3998PROTOCOL-SERVICESrshroot172.16.112.10,172.16.112.50,172.16.115.20202.77.162.213588071.1748188076.992895.81808(decode)loopbackIP,(ipv4)IPv4packetfrom′currentnet′sourceaddress0.0.0.1/8,127.0.0.1/8131.84.1.31 例如ID为1的超告警表示该单步攻击的开始时间为第82296.02975 s,结束时间为第82322.00611 s,攻击持续时间为25.97636 s,攻击源202.77.162.213向攻击目标172.16.112/、172.16.113/、172.16.114/与172.16.115/这4个网段发动了ICMP PING扫描。ID为5的超告警表示从第88071.17481 s到第88076.99289 s,0/与127/网段的攻击源向攻击目标131.84.1.31发动了持续5.81808 s的分布式拒绝服务攻击。 为了衡量基于信息熵的告警预处理方法对于原始告警的聚合程度,定义告警聚合率来表示聚合的效果,即: 告警聚合率=(原始告警数-超告警数)/原始告警数×100% 采用本文提出的基于信息熵的告警预处理方法后,整体聚合效果如表7所示。 表7 整体聚合效果 原始告警数误告去除后告警数超告警数告警聚合率/%660142469098.63 将本文提出的基于信息熵的告警预处理方法与文献[10]提出的基于自扩展时间窗的告警多级聚合方法进行比较,结果如表8所示。 表8 2种聚合方法对比 对比内容文献[10]方法本文方法原始告警数43996601超告警数35290告警聚合率/%92.0098.63 从实验结果来看,针对LLS_DDOS1.0攻击场景产生的告警数据,本文方法聚合后产生的超告警更少,具有更高的聚合率。文献[10]通过配置snort为最严格模式,并不能避免误告警的产生,导致或多或少的误告被聚合,影响了聚合的准确率。同时文献[10]对5种攻击类型分别进行聚合,各种类型的聚合效果差别较大,导致最终的聚合率较低。本文采用基于信息熵的告警预处理方法,在告警聚合之前增加了误告去除这一步骤,大量减少了告警中的无关告警,避免了错误告警被聚合,增加了聚合率以及聚合的准确率,因此本文所提方法具有更好的告警预处理效果。 本文提出的基于信息熵的告警预处理方法通过采用信息熵的思想对告警信息进行误告去除以及告警聚合。在进行误告去除时,综合考虑了入侵检测告警事件中真实告警以及误告警在告警密度、告警周期值、源IP对应的目的IP数、攻击源威胁度等特征上的差异性,所提的特征能较好地区分真实告警与误告警,并利用互雷尼信息熵来量化二者的差异性,以此来检测误告并且去除误告。同时提出的告警聚合方法能按照IP对应关系将告警进行预分类,采用聚类算法能将分类后信息量相同或者相似的告警进行聚合,并在聚合后动态划分时间窗口,生成代表单步攻击意图的超告警。实验结果表明,本文方法具有较好的误告去除效果以及告警聚合效果。下一步的工作是对攻击告警进行关联方法研究,并以此来检测本文所提的告警预处理方法的有效性。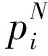

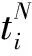
2.2 误告去除算法
3 基于信息熵的告警聚合方法
3.1 IP对应关系划分
3.2 特征提取
3.3 告警聚类
3.4 动态时间窗口划分
4 实验分析
4.1 数据集介绍

4.2 阈值确定

4.3 实验结果分析



5 结束语
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01铁道通信信号(2019年6期)2019-10-08制造技术与机床(2019年9期)2019-09-10成都信息工程大学学报(2019年5期)2019-05-21西南交通大学学报(2018年6期)2018-12-18雷达学报(2017年6期)2017-03-26雷达学报(2017年6期)2017-03-26互联网天地(2016年1期)2016-05-04智能系统学报(2015年4期)2015-12-27探测与控制学报(2015年4期)2015-12-15
