
多特征融合的鸟类物种识别方法*
2020-06-08 02:29:24谢将剑邢照亮
应用声学 2020年2期
谢将剑 杨 俊 邢照亮 张 卓 陈 新
(1 北京林业大学工学院 北京 100083)
(2 林业装备与自动化国家林业和草原局重点实验室 北京 100083)
(3 先进输电技术国家重点实验室(全球能源互联网研究院有限公司)北京 102211)
0 引言
鸟类鸣声具有一定的稳定性和明显的物种鉴别特征,是鸟类物种识别的主要方式之一[1]。利用鸟鸣声语图中鸣声区域的图像特征可以区分鸟类物种[2-3],进而应用于鸟类物种的调查与监测,具有高效率、非损伤、低干扰、大范围等优势,应用前景巨大[4]。基于鸣声的鸟类物种识别的关键在于提取合适的鸟鸣声差异特征、选择高性能的分类器对差异特征进行分类。深度学习具有较强的自动学习特征和进行分类的能力[5-6],在基于鸣声的鸟类物种识别方法中得到了广泛的研究。Chakraborty 等[7]利用深度神经网络(Deep neural network,DNN)采用音频信号的梅尔滤波能量系数作为输入,实现了基于鸣叫的鸟类识别,最佳识别准确率达到98.48%。Piczak[8]以音频信号的梅尔频域谱图为输入,对比了3 种不同结构的深度卷积神经网络(Deep convolutional neural network,DCNN)的识别效果,结果表明输入谱图的大小、网络的层数以及网络结构都会对识别效果产生影响。Martinsson[9]利用18层的深度残差神经网络(Deep residual neural network,DRNN)对BirdCLEF竞赛的鸣声样本进行识别,平均识别精度达到53.8%,相比官方提供的深度卷积网络识别方法低2%。谢将剑等[10]研究了3 种不同语图作为输入时,利用VGG16 模型进行鸟类物种识别的性能,结果表明基于线性调频小波变换生成的语图作为输入,相比其他语图作输入时,识别准确率和效率都得到了改善。以上研究表明,选择合适的语图作为输入、DCNN 作为识别模型,可以得到较好的识别性能。
通过多特征融合可以提高模型的分类性能[11],本文提出一种基于深度卷积神经网络的多特征融合模型,该模型利用短时傅里叶变换(Short-time Fourier transform,STFT)、梅尔倒谱变换(Mel frequency cepstrum transform,MFCT)和线性调频小波变换(Chirplet transform,CT)分别计算得到鸣声信号的语图,基于3 种语图样本集分别训练3 个基于VGG16 迁移的单一特征模型,并利用自适应线性加权对3 种特征进行融合,最终基于融合特征实现鸟类物种的识别。以鸣声库ICML4B的鸟鸣声为研究对象,通过对比实验验证了本文提出模型的优越性。
1 鸟鸣声语图样本集
1.1 鸟鸣声信息
本文采用的鸣声库是法国国立自然博物馆提供的ICML4B 鸣声库。该鸣声库共包含35 种鸟类鸣声,具体的物种信息如表1所示。每种鸟类各包含1 个音频信号。每个鸣声音频信号均为持续时间30 s、采样频率44.1 kHz、16 bit 输出、WAV 格式的数字信号,信噪比在20~60 dB之间[12]。
1.2 鸣声信号的处理
鸣声信号的预处理主要包括预加重、分割、分帧以及加窗。预加重用于补偿鸟鸣声在传播时高频成分的衰减,采用一阶高通滤波器来实现,预加重系数取0.95。
ICML4B 鸣声库中鸟鸣声信号的信噪比较高,采用能量阈值法对鸣声进行分割。分割前需要对信号进行无重叠的分帧,为了最大限度保留鸣声信号,帧长选择为50 ms。计算每帧信号的能量后,将能量大于最大能量60%的帧认为是鸣声区域,予以保留,去除其他非鸣声区域,实现鸣声信号的分割,使各有效鸣声段连续,同时可以降低背景噪声的影响。
鸣声信号是一种典型非平稳随机信号,在对分割后的信号进行时频变换前,需要对信号分帧。同时对每帧信号加窗,以避免分帧后信号两端可能造成的不连续性。本文选择帧长为50 ms,重叠30%,窗函数为汉明窗。

表1 ICML4B 鸣声信号的信息Table1 Detail information of ICML4B bird vocalization signal
1.3 鸣声语图的计算
语图中的鸣声区域可以看成是图片中的特殊“物体”,通过识别鸣声区域的特征,可以实现鸟鸣声的分类[3]。为了得到不同的语图特征,选择了3 种时频变换方法计算语图:
(1)短时傅里叶变换
STFT 是最常用的一种时频分析方法,它通过时间窗内的一段信号来表示某一时刻的信号特征。计算得到每一帧的时频矩阵,便可以画出对应的语图。
(2)梅尔频域倒谱变换
人耳听到的声音高低与声音的频率并不成线性正比关系,通常采用Mel 频率尺度来模拟人耳的听觉特性[13]。鸣声信号经过快速傅里叶变换之后,通过一系列三角形Mel 频率滤波器组,然后对所有滤波器输出进行对数运算,再进一步做离散余弦变换便可得到梅尔倒谱系数(Mel frequency cepstrum coefficient,MFCC)。本文计算得到32 维梅尔倒谱系数后,去掉表征平均值的第0 维,选择余下的31维系数转换成梅尔谱图。
(3)线性调频小波变换
CT 是一种线性时频表示,可以看成是短时傅里叶变换和小波变换的综合,在表征短时平稳信号时具有明显优势[14]。对每一帧信号进行线性调频小波变换,利用快速Chirplet 分解算法计算得到小波系数[14],然后利用小波系数生成语图。
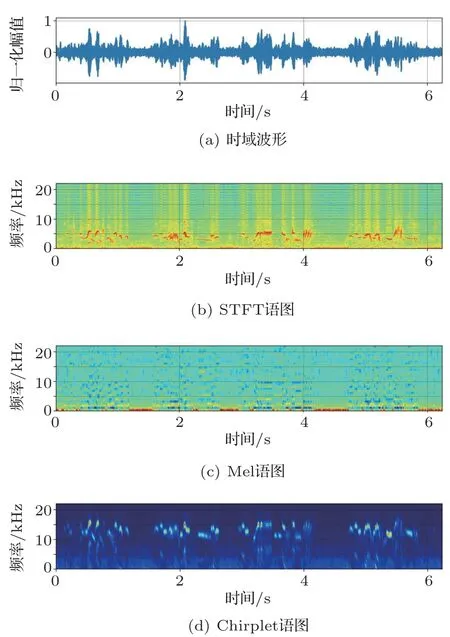
图1 棕柳莺的鸣声语图Fig.1 Spectrograms of Phylloscopus collybita
对鸣声进行预处理后,分别采用以上3 种时频变换方法生成语图,图1为棕柳莺的鸣声信号及计算得到的语图,从上到下依次为鸣声信号的时域波形、STFT语图、Mel语图以及Chirplet语图。
1.4 语图样本集的建立
利用语图特征进行分类时,选择音节特征作为输入比选择鸣唱特征的分类效果更好[15]。因此,本文将分割后的鸣声信号继续分帧,得到持续时间为500 ms 的鸣声信号,计算其对应的语图,保存成大小为224×224 的彩色图像,作为模型的输入,以通过语图图像特征的差异,实现鸟类物种的识别。最终计算得到35 种鸟类的鸣声语图数量如表1所示。利用3 种不同的时频变换对鸣声信号进行计算,便可得到3个不同的鸣声语图样本集。
2 多特征融合的鸟类物种识别模型
2.1 基于VGG16的特征迁移模型
DCNN 利用多层卷积层和池化层的组合自主学习图像特征,配合全连接层对特征进行分类,进而实现图像的识别。DCNN 可以通过局部连接、权值共享及池化操作等有效地降低网络的复杂度,减少训练参数的数目[5,16]。VGG16是一种典型的DCNN,由于其在ImageNet 图片分类中的优异性能,在图像识别领域得到了广泛的应用[17-19]。DCNN 的模型的参数随着深度的增大而增加,训练过程需要输入更多的己标注样本。如果缺乏足够的已标注样本,训练时容易导致过拟合,无法得到有效的识别模型。
基于迁移学习的思想,利用预训练好的模型作为特征提取器,冻结特征提取模型的参数,训练时不再参与更新,只更新用于分类器的参数,可以大大减小对已标注样本的需求量[20-21]。本文将鸟鸣声的识别等效成对鸣声语图的识别,基于VGG16 模型将图像识别问题迁移到基于鸣声语图的鸟类物种识别中。选择ImageNet预训练好的VGG16模型参数作为特征提取模型参数的初始值,通过训练对模型参数进行微调,可以提高训练效率,同时有利于样本数据量小的情况下的模型训练。
2.2 多特征融合模型
由不同的时频变换方法计算得到的不同语图,可以表征鸟鸣声的不同特征。采用不同的语图样本集作为输入时,模型的识别效果不同[15]。对同一对象的不同特征进行融合,得到的特征更全面,有利于提高分类的效果。多特征的融合方法直接影响融合特征的表达能力,目前,常用的多特征融合方法有直接叠加、串行或者并行连接以及加权求和等[11]。前两类方法不能体现不同特征的差异性,同时还扩大了特征的维数,增大了计算量。因此,采用加权求和的方式,引入权重的概念,表征不同的特征在识别过程中的贡献度。
为了充分利用3 种语图特征,进一步提升识别性能,首先构建3个不同的基于VGG16的特征迁移模型,分别提取3 种语图的特征。然后,将提取的3种特征进行自适应线性加权,一方面实现基于特征的融合,另一方面保持特征维度,可以不增加模型参数。融合后的特征F如式(1)所示:
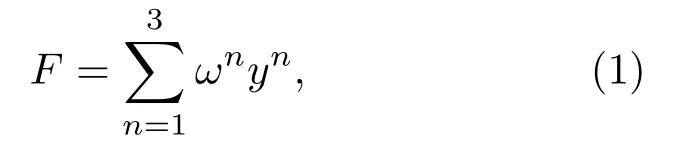
其中,ωn和yn分别表示特征n相应的权值和特征向量。不同的权值可以表征不同的特征在识别过程中的贡献度,且满足条件。该权值参与训练和更新过程,通过迭代自动获得最优的权值。
最后,将融合后的特征输出到2个全连接层和1个Softmax 输出层组成的分类器中,基于多特征融合模型的鸟类物种识别流程如图2所示。
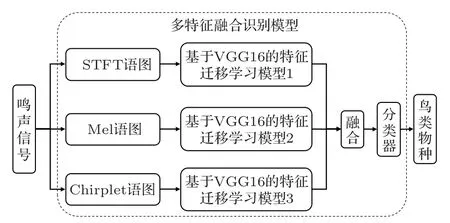
图2 基于多特征融合模型的鸟类物种识别流程Fig.2 Procedure of bird species recognition based on multi-feature fusion
在训练时,先利用3 种不同的语图分别作为样本集,训练出3 个基于VGG16 的特征迁移模型;在多特征融合模型中,这3个基于VGG16的特征迁移模型的参数不再参与更新,以克服由于模型增大后带来的参数数量增大进而对样本数量需求增大的缺陷。
3 实验结果与分析
3.1 模型训练设置
实验在Ubuntu16.04 64 位系统下,基于深度学习框架Tensorflow1.4.1 完成,采用的硬件平台为E5-2620CPU (6×2.1 GHz,32 GB 内存)和GTX1080ti GPUs (11 GB内存)的工作站。
实验时,3 个鸣声语图样本集均按照8:1:1 的比例被随机划分成训练集、验证集和测试集,用于本文提出的识别模型的训练、验证以及测试,具体的实验流程如图3所示。
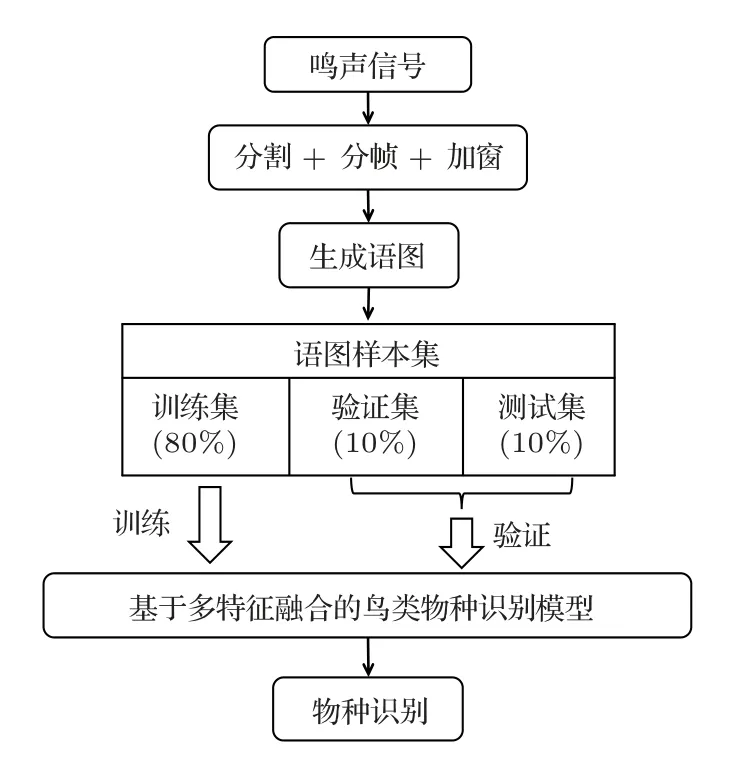
图3 识别模型训练流程图Fig.3 Train flow of recognition model
在训练过程中,为了加快数据的处理速度,将数据集分成多个分区(Batch),适当增大分区大小(Batchsize)可以提高训练的效率。综合考虑到实验用的电脑内存有限,选择分区大小为32。模型训练的参数如表2所示。
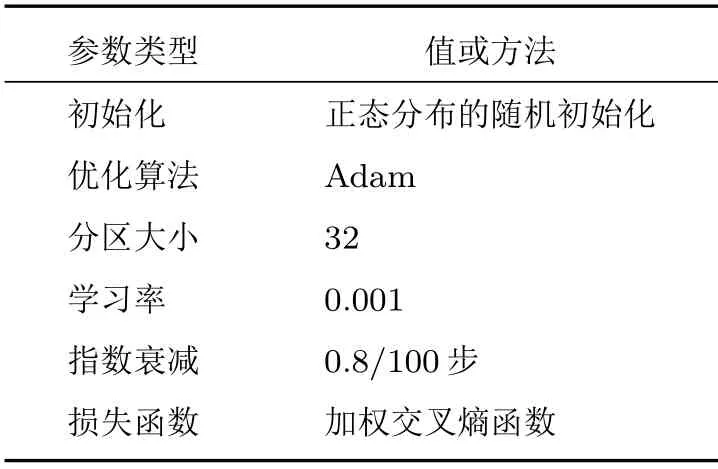
表2 训练参数Table2 Train parameters
从表1可以看出不同鸟类的语图数量相差较大,属于不均衡样本集,不利于DCNN 模型的训练。为了克服样本不平衡的问题,引入加权交叉熵损失函数作为模型的损失函数,该方法通过提高少样本类别在损失函数中的权重,进而解决不平衡数据的问题。对于多类别分类时,改进后每个batch中第j(j= 1,2,···,32)个样本属于第i(i= 1,2,···,35)类时的交叉熵损失函数值如式(2)所示:
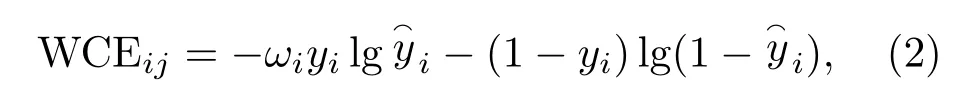
式(2)中,ωi是类别i的权值;yi为该样本是否属于类别i的实际标签,属于则为1,不属于则为0;为该样本预测为类别i的概率。类别i的权值ωi可由式(3)计算得到:

式(3)中,βi是所有训练样本集中属于类别i的样本数占总样本集大小的比例。
进一步得到代价函数为
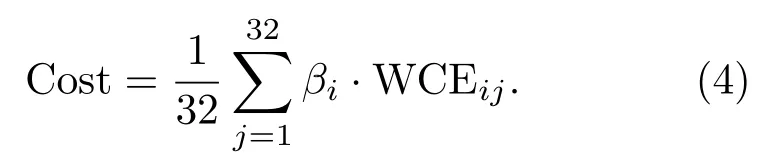
3.2 单一特征模型和融合模型性能对比
选择持续时间为500 ms 的语图作为语图样本集,首先分别训练3 个基于VGG16 的特征迁移模型,然后将3 个模型的特征提取部分进行冻结,通过全连接层组合形成融合模型,再训练融合模型的分类器部分的参数,得到最终的融合模型。
通常利用平均识别准确率(Mean average precision,MAP)来评价识别模型的好坏,本文提出模型的MAP计算公式如式(5)所示:
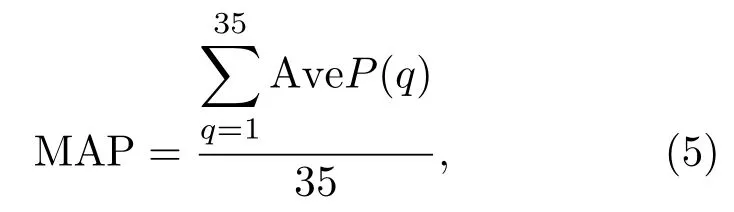
式(5)中,q为鸟类物种的编号,AveP(q)为对应物种的识别正确率。
图4为不同模型在验证集上的MAP 随着迭代次数增加的变化,Ch 代表Chirplet 语图特征模型,Mel代表梅尔语图特征模型,Spe代表STFT语图特征模型,Fuse代表融合模型。
从图4中可以看出,融合模型在76 次迭代中达到最大MAP值,而其他模型要到250次以后才趋于最大MAP 值。融合模型相比单一特征模型达到最大MAP 值的时间要更短,说明融合模型的训练效率要更高。而且对比单一特征模型,融合模型的最大MAP值也最大。
图5为4 种模型的平均识别准确率对比,图中的MAP值均为5次运算的MAP平均值。
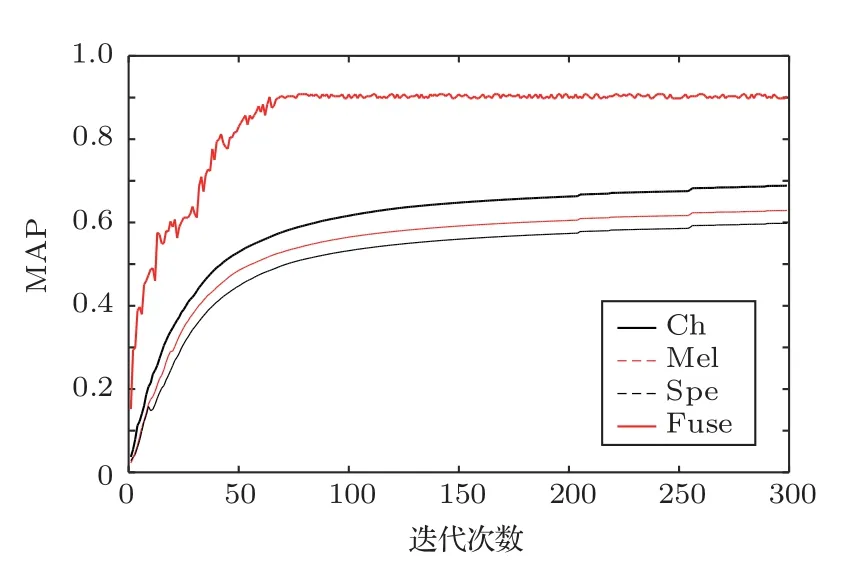
图4 不同模型的验证MAP 随着迭代次数的变化Fig.4 Variation of validation MAPs with epochs increasing
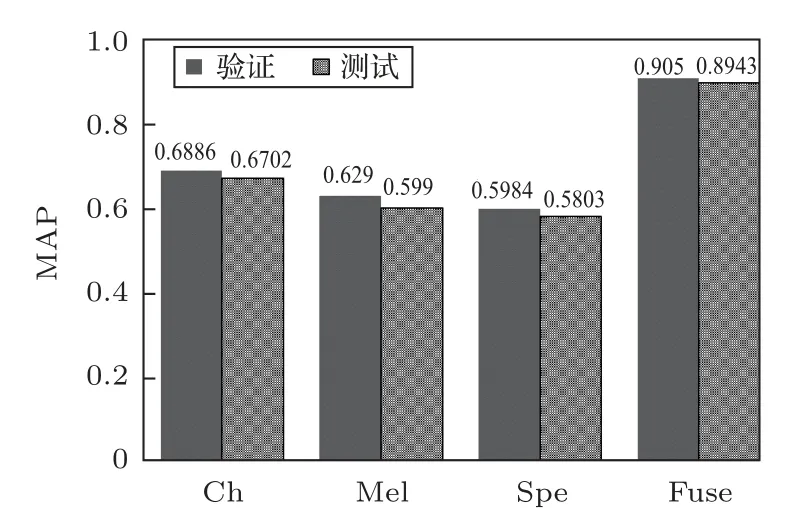
图5 不同模型的验证MAP 和测试MAP 对比Fig.5 Comparison of validation MAP and test MAP with different model
从图5可以看出:(1)单一特征模型中,Chirplet语图作为输入时的MAP 时最大,STFT 语图的MAP 最小,和文献[14]相吻合;(2)通过多特征融合后,融合模型的MAP 较单一特征模型提升较大,相比STFT语图的提升了30%左右。
综上所述,将不同特征进行融合,再利用分类器来进行分类的方法可以大大提高模型的识别能力,说明本文提出的多特征融合模型是可行的。同时本文提出的融合模型中,待训练的参数只包含分类器的参数,参数数量相对于VGG16 模型大大减少,可以降低对样本数量的需求。
3.3 语图不同持续时间的性能对比
输入DCNN的图像大小是固定的,选择不同的语图持续时间,会改变语图中鸟鸣声区域的特征,进而影响识别模型的性能。为了研究语图持续时间对识别性能的影响,选择持续时间为100 ms、300 ms和500 ms,分别计算得到3 个语图样本集。按照本文提出的建模方法得到不同持续时间下的单一特征模型和融合模型。
图6为不同持续时间时,不同模型的测试MAP对比。
从图6可以看出,语图持续时间不同时,对于同一个模型,持续时间为300 ms 的MAP 值最大,100 ms 的最小,而且4 种模型的变化规律一致。进一步对35 种鸟类鸟鸣声的音节持续时间进行了统计分析,得到了不同持续时间的音节数量分布如图7所示,71.7%的音节持续时间在100~300 ms之间。
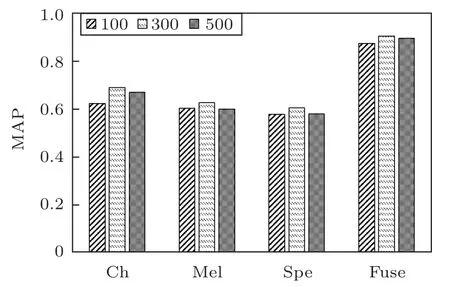
图6 不同持续时间语图下不同模型的测试MAP对比Fig.6 Comparison of test MAP with different model and duration
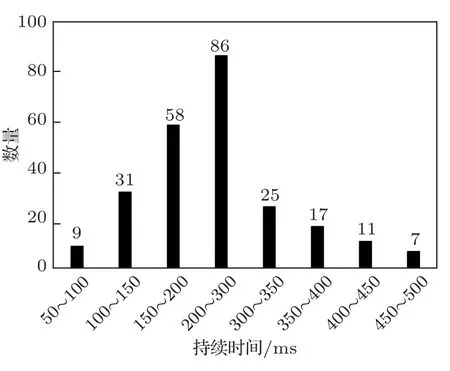
图7 不同持续时间的音节数量分布Fig.7 Distribution of syllable quantity with different duration
依据统计结果分析可得,持续时间为300 ms时效果最佳的原因在于:本文提出的方法是基于语图中鸟鸣声区域的图像特征实现语图的分类,达到识别鸟类物种的目的。因此图像当中鸟鸣声区域的完整性对于准确识别鸟类物种影响较大。鸟鸣声的音节持续时间各不相同,当音节的持续时间小于语图持续时间时,在语图中能够完整显示音节的特征,可以提高识别的准确率。而在完整性保证的基础上持续时间更长时,得到的语图数量减小,等效于训练样本数量下降,导致训练的效果下降。
综上所述,不同语图持续时间会影响模型的识别性能。在数据量足够大时,可以尽量选择较长的持续时间,使每幅语图中的鸣声区域保持完整。如果数据量有限,则需要根据鸟鸣声音节持续时间的分布,选择合适的持续时间。
3.4 不同信噪比时模型的性能对比
为了对比不同信噪比下不同模型的识别性能,重新整理语图持续时间为300 ms 时在测试集上的实验结果。按照信噪比大小重新整理成3个子集,为了保证每个集样本数均衡,分为强噪声集(信噪比在20~35 dB)、中噪声集(信噪比在35~45 dB)以及低噪声集(信噪比在45~60 dB)。计算得到不同子集的识别准确率如图8所示。
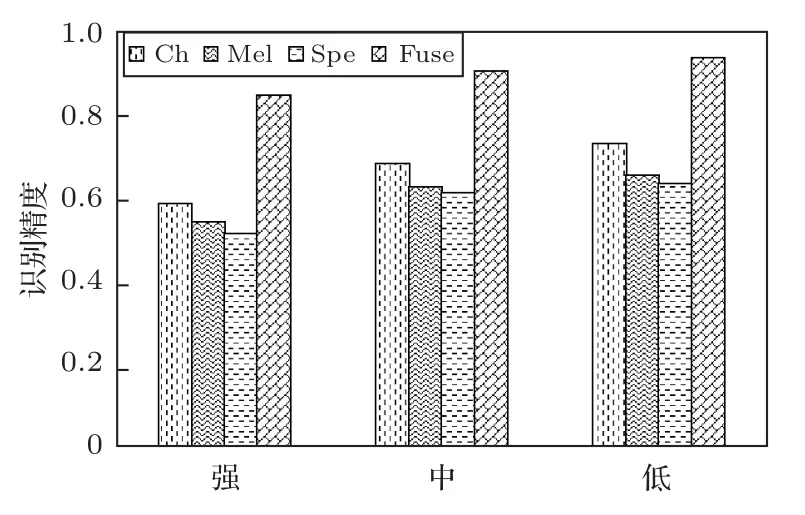
图8 不同信噪比下的模型的识别精度Fig.8 Precision under different SNR
从图8中可以看出,随着信噪比的升高,4 种模型的识别精度都在下降。进一步计算得到强噪声集和低噪声集上识别精度的相对误差:Ch、Mel、Spe和Fuse的分别为19.64%、17.15%、18.81%和9.73%,3 个单一特征模型的下降的数值更大,说明多特征融合模型的抗噪能力较其他3个模型更强。
4 结论
为了进一步提高识别的准确率,本文提出一种基于Chirplet 语图、Mel 语图以及STFT 语图3种语图特征融合的鸟类物种识别方法。该方法首先建立3 个不同语图输入时的基于VGG16 特征迁移的单一特征模型,然后将其进行加权求和融合得到特征融合模型。以ICML4B 鸣声库的35 种鸟类为研究对象,对比了持续时间为500 ms 的语图作为输入时4 种模型的MAP 值,特征融合模型较前3 个模型在MAP 值和训练效率上均有较大的提升,验证了本文提出的多特征融合模型的可行性及优势;为了研究语图持续时间的影响,选择持续时间分别为100 ms、300 ms 以及500 ms 的语图作为输入,对比不同模型的MAP 值,结果表明持续时间300 ms 的MAP 值最高。对比了不同模型识别不同信噪比鸣声的识别效果,结果表明多特征融合模型抗噪声的能力最强。因此,根据鸟鸣声的音节持续时间分布,选择合适的语图持续时间,利用本文提出的多特征融合可以提高鸟类物种识别的准确率。而且该融合模型的训练参数少,适合于样本数量小的鸣声数据集的分类和识别,这对于有些珍稀鸟类的识别具有较高的应用价值。
猜你喜欢
东坡赤壁诗词(2023年2期)2023-05-30 15:02:14
学与玩(2022年9期)2022-10-31 02:54:08
诗歌月刊(2021年8期)2021-08-25 18:54:10
小天使·二年级语数英综合(2021年6期)2021-08-09 10:25:54
文苑(2020年12期)2020-04-13 00:54:14
小太阳画报(2019年1期)2019-06-11 10:29:48
安徽师范大学学报(自然科学版)(2018年5期)2018-12-11 03:32:00
小学生必读(低年级版)(2017年5期)2017-08-12 03:47:07
第二课堂(课外活动版)(2015年5期)2015-10-21 19:37:04
电测与仪表(2015年12期)2015-04-09 11:44:40
