
基于三尺度嵌套残差结构的交通标志快速检测算法
2020-06-08 09:00李旭东张建明谢志鹏
计算机研究与发展 2020年5期
李旭东 张建明 谢志鹏 王 进
(长沙理工大学计算机与通信工程学院 长沙 410114)(综合交通运输大数据智能处理湖南省重点实验室(长沙理工大学) 长沙 410114)
近年来,依靠计算机视觉与人工智能等相关技术的发展,自动驾驶呈现出接近实用化的趋势.利用前端相机采集的图像进行交通标志、车道线、信号灯的检测与识别是自动驾驶的重要研究内容.交通标志检测属于特定目标的检测,不仅具有通用目标检测的难点,同时还会因特殊环境造成交通标志的遮挡、污损、模糊、褪色、变形等;同一类的交通标志在不同时间、天气、角度、光照以及分辨率的情况下会呈现不同的检测效果.实时的交通标志检测作为自动驾驶的重要组成部分,是难度较大的实景目标检测,同时对于准确性和稳定性也有很高要求.
目前按照不同的检测手段,将交通标志检测主要分为传统方法和基于深度学习的方法.传统方法中,以颜色、形状等特征以及多种特征相结合的检测为主;基于深度学习的方法分为2阶段检测方法R-CNN(region-convolutional neural networks)系列检测算法和1阶段检测方法YOLO(you only look once)系列检测算法,SSD(single shot multibox detector)系列检测算法.现有的针对真实场景下交通标志的检测算法大多只注重于准确率的提升,而忽略了应用场景中算法所需要具备的高实时性.实时性越高,检测速度越快,能为驾驶者及自动驾驶系统提供更好的预警.YOLO系列检测算法以速度为首要标准,其中YOLOv3检测算法中利用多个尺度预测大幅提高小目标的检测能力,而YOLOv3-tiny检测算法则是以其更快的检测速度著称.因此,我们以YOLOv3-tiny检测算法为基础网络,在不影响检测速度的条件下,设计嵌套残差结构和多尺度预测机制,构建了一个改进的YOLOv3-tiny检测算法,从而训练出一个高实时性和高鲁棒性的交通标志检测模型.
本文的主要贡献有4个方面:
1) 在YOLOv3-tiny检测算法的基础网络Darknet-19中,将中间层特征采用逐像素相加方式进行跨层连接,不会增加特征图通道数,形成1个较小的残差结构;
2) 将浅层特征跨层连接至深层特征进行逐像素相加,构成1个较大的残差结构,并设计增加1层输出预测层,使得该层能包含更丰富的空间细节信息,提高模型对小目标的检测能力;
3) 将小残差和大残差结构进行嵌套,形成三尺度嵌套残差结构,使得Tiny检测算法的部分主网络位于这2个残差结构中,其作用是在训练过程中能对其进行3次调参,进一步提高了模型的泛化能力;
4) 在2个不同国家的交通标志检测数据集德国交通标志检测数据集(German traffic sign detection benchmark, GTSDB)和长沙理工大学中国交通标志检测数据集(CSUST Chinese traffic sign detection benchmark, CCTSDB)上,我们对提出算法的每个创新点进行验证,并与当前主流的交通标志检测算法进行了全面的对比.实验效果表明:提出的方法不仅具有较高的检测鲁棒性,更具有高效的计算能力,单张图像的检测时间仅为5 ms.
1 相关工作
传统的交通标志检测算法:交通标志具有鲜明的颜色特征,通常在诸如RGB,HIS,HSV等不同颜色空间中获取交通标志信息.Le等人[1]对RGB设置阈值,筛选出交通标志的红色和蓝色区域,对2×2的像素块采用SVM进行分类,得到1个较为准确的快速交通标志检测系统.Zhang等人[2]通过归一化RGB到RGBY颜色空间,并针对不同颜色提出了一种新的颜色阈值约束方案,提高了检测效果.同时交通标志也具有显著的形状特征,谷明琴等人[3]根据直线间顶点处的曲率关系,利用转向角对顶点进行分类,并提出无参数形状检测子,使用该算子来检测图像中的警告、禁令和指示标志.但是,单一的颜色或形状特征无法满足真实场景中的高精度检测,将两者相结合的方法精度相比于单一特征会有较大提升.Xu等人[4]结合自适应颜色阈值分割和形状对称性假设检验可以有效提取交通标志候选框.张静等人[5]使用HSI空间特征与形状特征结合,很大程度上解决了其他颜色分量对检测目标的影响,提高了检测精度.
基于深度学习的2阶段检测方法:2014年,Girshick等人[6]提出了R-CNN目标检测算法,使用从选择性搜索和边缘框中生成的建议区域来训练卷积网络,生成了基于区域的特征,并采用SVM(support vector machine)进行分类.随后,SPPNet[7]引入空间金字塔池化层,在不考虑输入图像分辨率大小的情况下,允许分类模块重用卷积特征.Fast R-CNN[8]检测算法结合SPPNet并利用分类和位置回归损失值进行端到端的训练.Faster R-CNN[9]检测算法则是用区域建议网络(region proposal network, RPN)替代选择性搜索,RPN用于生成候选边界框并过滤背景区域,此外还利用了另一个小网络进行分类和位置的回归.Yang等人[10]基于Faster R-CNN检测算法进行改进,使用注意力网络代替RPN网络用于交通标志建议区域的生成,其模型在TT100K[11]数据集以及BTSD[12]数据集上分别取得96.05%和98.31%的准确率.
基于深度学习的1阶段的检测方法:为了克服2阶段检测方法实时性差的问题,YOLO[13]检测算法将输入图像划分为若干网格,并对每个网络进行定位和分类,大幅提升了目标检测的速度,但精度却不够理想.YOLOv2[14]检测算法是基于YOLO检测算法的增强版本,通过移除全连接层来改进YOLO检测算法.我们针对中国交通标志的特征,改进了YOLOv2检测算法,并且公布了中国交通标志数据集CCTSDB,该改进方法在CCTSDB和GTSDB[15]两个数据集上分别获得很高的准确率[16].YOLOv3[17]检测算法对YOLOv2检测算法进行改进,增加了网络层数,在Darknet-53基础网络上引入多尺度预测实现了更好的分类和检测效果.YOLOv3检测算法在Titan XP上的处理速度能达到20f/s,在COCO测试集上分类精度达到57.9%.YOLOv3检测算法的模型较于原先的模型提高了复杂度,可以通过改变模型结构的大小权衡速度与精度.
SSD[18]检测算法是另一种典型的1阶段目标检测方法.SSD检测算法通过2个卷积层来分别预测边界框的类别置信度和位置偏移量.为了检测不同尺度的目标,SSD检测算法增加了一系列逐渐变小的卷积层生成金字塔特征图,根据各层的感受野大小设置相应的锚点,并利用非极大值抑制对最终检测结果进行处理.为了提高精度,DSSD[19]检测算法提出了将反卷积层来增强浅层的大尺度背景,其模型较为复杂,检测速度较慢.Tian等人[20]基于DSSD检测算法加入了注意力网络,将相邻层的相关上下文细节结合到检测体系结构中,其提出的检测模型在GTSDB检测数据集上取得了很高的精度.RSSD[21]检测算法通过引入彩虹连接,充分利用了特征金字塔中的各层之间的关系,尽管提升了精度,但损失了部分的计算时间.
2 算法基础
YOLOv3[17]检测算法是当前速度和精度比较均衡的目标检测算法之一.YOLO系列检测算法算法每个版本都有对应的Tiny版本.Tiny版本以原始算法为主框架,通过精简得到快速检测网络,速度是原始算法的3倍以上,但由于过于精简卷积操作,其精度并不理想.真实场景的交通标志检测中更加注重实时性能,因此我们以YOLOv3-tiny检测算法为基础网络,在不影响检测速度的条件下,结合残差结构与多尺度预测的思想,构建一个改进的YOLOv3-tiny检测算法,从而训练出一个高实时性和高鲁棒性的交通标志检测模型.
2.1 YOLOv3系列检测算法
YOLOv3检测算法采用全新的网络来实现特征提取,通过残差块来加深网络,达到106层,在多个尺度的特征图上进行检测,能显著提升小目标的检测效果.
YOLOv3-tiny检测算法是一个在YOLOv3检测算法基础上精简而来的轻量级网络模型,具有23层网络,只包含卷积层和最大池化层,相比于YOLOv3检测算法大大减少了网络层数,这使得它的检测速度是YOLOv3检测算法的3倍之多.在YOLOv3-tiny检测算法主干网特征提取部分,一共有16层,其中卷积层有10个,最大池化层6个.在YOLOv3-tiny检测算法主干网检测部分,只使用了2个尺度的特征图进行检测框回归和分类,分别是13×13的特征图,以及它经过上采样后与26×26的特征图通过通道串接形成的特征图.相比YOLOv3检测算法少了一个尺度预测,其每一个网格的预测框数量也从9个变成6个.YOLOv3-tiny检测算法中的检测框回归和分类任务与YOLOv3检测算法保持一致,且损失值计算的原理相同.
2.2 残差块思想
深度神经网络中随着网络深度的增加,训练会变得愈加困难.这主要是由于在使用随机梯度下降的网络训练过程中,误差信号的多层反向传播极易引发梯度消失或梯度爆炸.针对这个问题,He等人[22]在网络中构建了恒等映射,可以在增加网络层数的同时不增加训练误差.
如图1(a)所示,假设网络输入为X,输出为H(X):
H(X)=F(X)+X,
(1)
残差是实际观察值减去拟合的预测值.网络只需要在训练的时候不断调整F(X)的参数来学习残差F(X),这会比直接学习H(X)更简单.
F(X)=H(X)-X,
(2)

Fig. 1 Residual module图1 残差模块
例如当期望输出H(X)就是输入X时:对于没有跨层连接的结构,需要将其优化成H(X)=X;对于残差结构,只需将F(X)=H(X)-X优化为0即可.
这里是使用特征图逐像素相加的方式来得到的H(X).在ResNet结构中会用到2种残差模块,图1(b)所示的是常规残差模块,由2个3×3卷积堆叠而成.图1(c)的结构称为“瓶颈残差模块”,依次由1×1,3×3,1×1这3个卷积层构成,其中每层之间均有线性整流函数(rectified linear unit, ReLU)进行激活连接.
3 基于三尺度嵌套残差结构的快速检测算法
3.1 改进思想
YOLOv3-tiny检测算法的网络结构与YOLOv2-tiny检测算法类似,增加了1层多尺度预测输出,而其和YOLOv3检测算法的结构又有差别,没有采用YOLOv3检测算法中的残差块来加深网络.Tiny版本更加注重检测时间,增加网络层的数量会提高检测精度,但过多的增加层数又会导致更多的时间损耗,因此不能仅仅依靠增加网络深度来提高Tiny版本的检测精度.首先,我们结合残差网络中特征图逐像素相加的跨层连接思想,在Tiny网络中构建1个小残差结构,即二尺度残差结构;在此基础上,将浅层特征跨层连接至深层特征进行逐像素相加,构成1个较大的残差结构,并设计增加1层输出预测层;最后,将以上2个残差结构进行嵌套,形成了三尺度嵌套残差结构.
本文中所涉及的定义和操作说明有5项:
1) 第m层.文中描述所涉及的“第m层”为表1算法检测流程中操作的序号,并非图2中所对应的层数,图2中的层数只用作结构展示.
2)Route1(m).Darknet框架中用函数Route进行跳转操作.Route1(m)表示从当前层跳转至第m层.
3)Route2(m,n).Darknet框架中用函数Route还可以进行通道串接操作.Route2(m,n)表示将第m层和第n层特征图进行通道串接,输出1个与输入特征图宽高相同、通道维度更高的新特征图,此操作要求第m层与第n层特征图的对应宽、高必须相等,而通道数可以不相等.
4)Shortcut(m).函数Shortcut在Darknet框架中是进行逐像素相加操作.其表示当前操作层的输入(即上一层输出特征图)与第m层的特征图进行逐像素相加,输出1个与输入特征图空间尺度完全一致的全新特征图.此操作要求当前层的输入与第m层特征图对应的宽、高以及通道数必须相等.
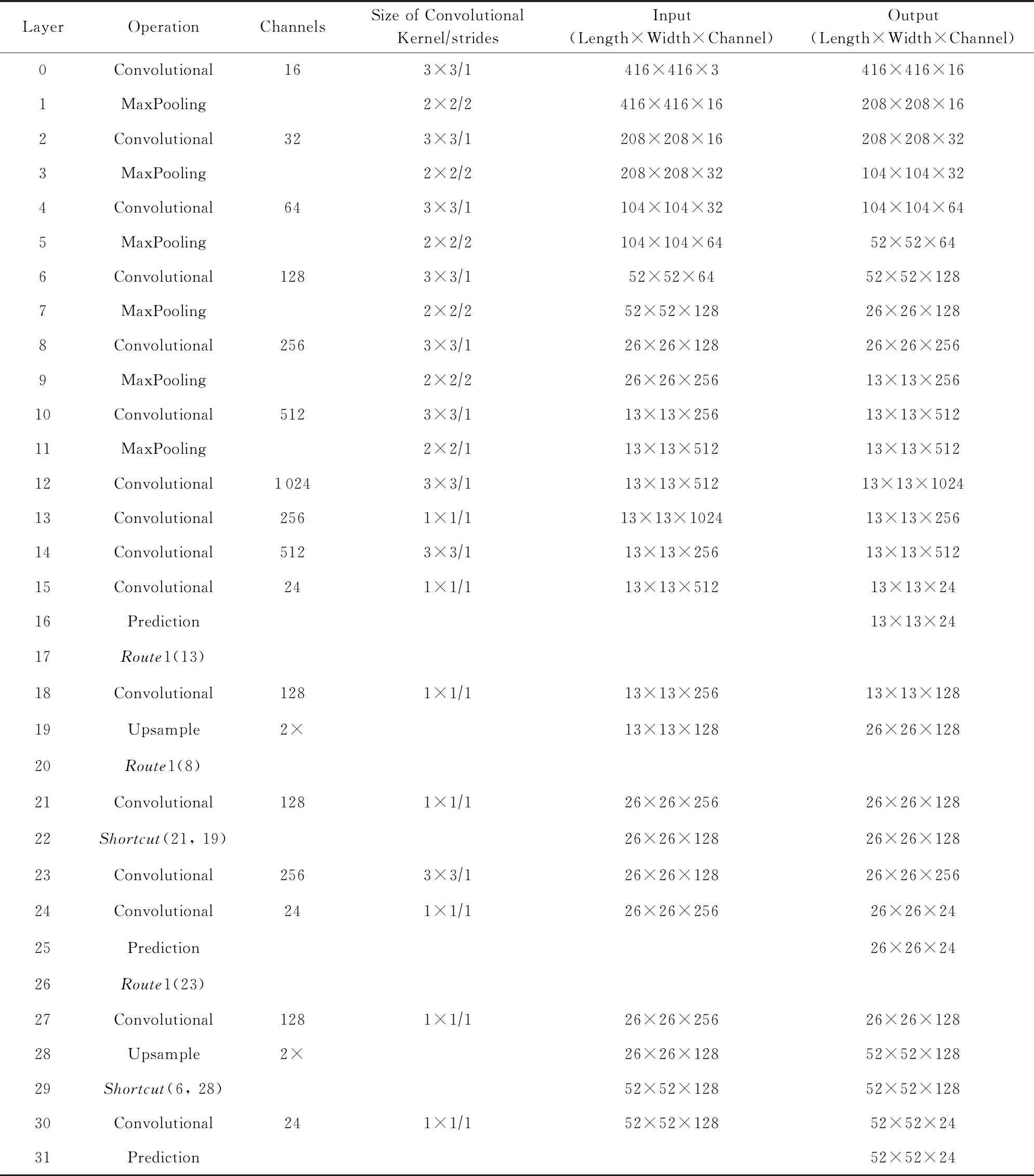
Table 1 The Process of Our Rroposed Algorithm表1 我们的算法流程

Fig. 2 Framework of our proposed algorithm图2 本文算法的结构图
5) 嵌套.与普通残差网络中残差块相互串联或并联不同,嵌套残差由小残差结构与大残差结构共同组成,小残差结构嵌套于大残差结构中,且小残差结构是大残差结构的一部分,大残差结构是主网络的一部分.
3.1.1 二尺度残差结构
如图2所示,黑色实线和虚线部分为YOLOv3-tiny检测算法的结构图,黑色虚线部分为Tiny原有的通道串接操作.与YOLOv3系列检测算法中的跨层连接操作不同,残差块结构中采用的是对应像素相加的方式来实现F(X)+X.
我们将YOLOv3-tiny检测算法中的跨层连接操作进行改进,采用逐像素相加操作代替通道串接操作.如图2所示,红色实线部分为改进的跨层连接方式.将跨层连接的输入向后移1层,虽然使用原黑色虚线部分的操作可以减少1次卷积从而直接进行逐像素相加,但在后期增加三尺度模块时发现,蓝色逐像素相加操作与黑色虚线相隔太近,两层之间仅进行了最大池化操作,这导致2个特征图之间的差异性不够大.因此我们使用后一层经过卷积的特征图,这与之前的特征图在尺寸以及通道数上不同,使输出更加丰富.但由于逐像素相加操作要求输入空间尺度完全一致的特征图,因此还需要先进行1次降维操作.此时,相加后输出的特征图大小为26×26×128,相比于改进前的输出特征图(26×26×256)在通道维度上减少了128维,将这128维的信息通过对应像素相加的方式融合到了新的输出特征图中.由于通道维度的降低,使得下一个卷积层中卷积操作的时间消耗减少了一半.同时,图2中粉红色区域块形成了小残差结构.当采用逐像素相加进行连接后,按照残差网络的基本原理,我们将把Tiny主网络中被跨层区域作为残差网络中的F(X)部分,红色实线则是引入了浅层更具有细节信息的特征图,最后将深层与浅层的特征图进行融合,达到提高检测精度的效果.在网络训练时,整个网络会按照YOLO系列检测算法进行训练调参,同时也会按照残差网络的方法不断调整F(X)区域中各个卷积层的参数,实现2次优化调参.在图2中黑色实线与红色实线部分组成了二尺度残差结构.
3.1.2 三尺度嵌套残差结构
为了进一步提高对小尺寸目标的检测精度,我们设计并输出了多层特征图,这些特征图在空间细节和语义上具有互补性,算法可以在不同尺度大小的特征图上进行预测.由于已经通过减少1层卷积层操作数量降低了时间消耗,我们对Tiny版本增加1层尺度的预测输出,检测时间变化不大.如图2所示,蓝色实线部分为增加的预测层,增加的预测层输出大小为52×52×24,这一层较其他2个预测层的空间分辨率更高,特征图中包含的空间细节信息越多,就有助于算法对小目标的检测.同时,将增加的这一预测层也采用逐像素相加的跨层连接,融合浅层中的丰富细节信息.与之前的小残差结构类似,图2中粉蓝色区域块组成了大残差结构.将小残差和大残差结构进行嵌套,形成三尺度嵌套残差结构,此时小残差结构位于大残差结构中的F(X)部分,在训练过程中,处于主干网络的小残差结构F(X)部分将会进行第3次优化调参.在图2中除黑色虚线部分,其他结构所构成的就是三尺度嵌套残差的YOLOv3-tiny检测算法.
3.2 算法流程
基于三尺度嵌套残差结构的YOLOv3-tiny检测算法流程如表1所示.网络可以接受任意尺寸的RGB彩色图像输入,然后将大小重置为416×416进行操作.整个网络共16个卷积层、6个最大池化层、2次上采样和3个预测输出层.网络层0~11为卷积层与最大池化层组合,是为了进行快速的下采样降低特征图尺寸;网络层12~15为卷积层,是为了增加网络拟合能力,同时最后一个卷积层可以降低特征图维度;网络层8~22构成了图2中粉红色区域的小残差结构,网络层6~29构成了粉蓝色区域的大残差结构;层16,26,31为预测输出层,其输出尺度大小分别为13×13×24,26×26×24,52×52×24.
3.3 损失函数
基于三尺度嵌套残差结构的YOLOv3-tiny检测算法中的检测框回归和分类任务与YOLOv3-tiny检测算法保持一致,且损失值计算的原理相同.不同的是,在YOLOv3-tiny检测算法中只有2个分支预测,而提出的算法中有3个分支预测,因此后者需要分别计算3个尺度分支相应的定位损失值、IOU损失值以及分类损失值.提出的算法中对每个预测的包围框(bounding box)通过逻辑回归计算一个目标的得分,若该预测的包围框与真实的包围框大部分重叠且比其他所有预测要好,则该值将会被保存,若重叠比例没有达到IOU阈值,则该预测包围框将会被忽略.YOLOv3系列检测算法只为每个目标选取一个IOU值最高的预测包围框,结合真实(ground truth)的包围框,计算该预测包围框的损失.总损失函数计算:
LN=Lcoord+LIOU+Lclasses,
(3)
其中,N表示YOLO预测分支所在的主网络输出的层数位置,LN代表不同尺度的预测输出的损失值.在原版YOLOv3中N∈{82,94,106};在原版YOLOv3-tiny中N∈{16,23};我们提出的改进算法中N∈{16,25,31}.
Lcoord为定位损失值,计算的是预测包围框的坐标误差,即左上角点坐标与宽高的误差值:
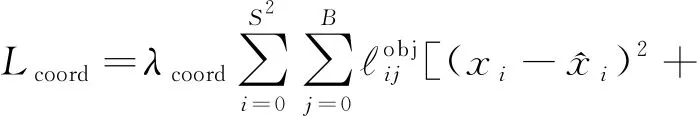
(4)
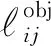
LIOU为IOU损失值,计算的是IOU值最大的预测包围框与真实包围框的误差:
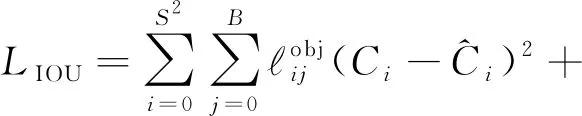
(5)
式(5)等号右边第1项表示包含目标的预测包围框的置信度预测值,第2项表示不包含目标的预测包围框的置信度预测值.其中Ci为目标类别,λnoobj是未含目标的预测包围框的约束系数.
Lclasses为分类损失,计算的是预测类别与真实类别间的误差:
(6)
4 实验与分析
4.1 实验设置
本实验的训练环境与测试环境硬件不同.训练需要耗费大量的GPU资源与磁盘空间,因此训练使用的是性能更佳的CPU为Intel Xeon E5-2670 v3,GPU为TITAN X,显存为12 GB的服务器.测试选取的环境是CPU为Intel Core i7-6700K,GPU为GTX980Ti,显存6 GB的普通主机.所有的训练以及测试模型使用的均在Linux环境下.
我们在GTSDB和CCTSDB两大数据集上进行了多组对照实验.GTSDB是德国交通标志图像检测数据集,也是交通标志检测中最广泛应用的数据集之一.CCTSDB[16]是我们提出的中国交通标志数据集,包含图片近15 000张、交通标志近60 000个.目前的标注数据有三大类:指示标志、禁令标志、警告标志.CCTSDB的测试数据集使用的是重新标注过的CTSD[23]的400张测试图像.
我们设置了模型1与模型2为对照实验中的实验组,其中模型1是二尺度残差的Tiny检测算法,共25层,主网络结构与YOLOv3-tinys检测算法相同,跨层连接中采用特征图对应像素相加代替YOLOv3-tiny检测算法的特征图通道串接,一共有2个预测层,分别在第16,25层输出大小为26×26,52×52的预测特征图;模型2是三尺度嵌套残差结构的Tiny检测算法,共31层,网络结构与模型1相似,在模型1的基础上增加了1个YOLO预测输出层,一共3个预测层,分别在第16,25,31层输出大小为13×13,26×26,52×52的预测特征图.对比实验将选取对照实验中性能最佳的模型与现有的主流交通标志检测算法进行对比.
我们使用了多个标准来评价不同算法的性能,包括精确率(precision,P)、召回率(recall,R)、F1值、平均绝对误差DMAD等.精确率是被预测成正的样本中预测正确的比例;召回率是正样本中被正确预测的比例;F1值是精确率和召回率的调和均值.为了衡量模型在不同IOU阈值下的稳定程度,我们引入了平均绝对误差,平均绝对误差是所有单个观测值与算术平均值偏差的绝对值的平均值,它可以避免误差相互抵消的问题,因而可以准确反映实际预测误差的大小,通常该值越小表示模型越稳定.
我们对以上变量进行定义:将正样本预测正确,记该类样本数为TP;将正样本预测错误,记该类样本数为FN;将负样本预测为正样本,记该类样本数为FP;n表示在不同IOU阈值下P或R的数量;xk表示第k个P或R的值;m(x)表示该组P或R的平均值,计算这些度量标准:
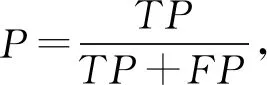
(7)
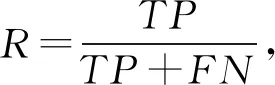
(8)
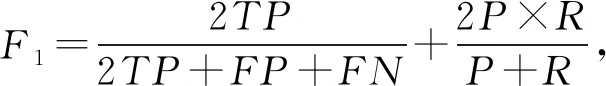
(9)
(10)
4.2 参数设置
各模型实验中具有较多的预设参数,这些参数在训练时会极大程度影响实验效果.为了保证变量的单一性,我们固定其他参数,只改变网络层相关参数,来证明每个创新点加入网络中的效果.所有对照实验中输入网络的图像大小为416×416、学习率为0.001、每批次样本数为64、每次送入训练器的样本数为8、迭代次数为200 000、每1 000次迭代输出一个网络模型.选定初始IOU阈值θ=0.5时,使用均值平均精度mAP来筛选出200个结果中最佳的模型作为此网络结构的训练结果.
4.3 实验结果与分析
4.3.1 GTSDB数据集上的评估
首先,我们将对照实验的3个模型在GTSDB数据集上一起进行评估,德国交通标志检测数据集是目前应用最广泛的检测标准之一,在此标准下我们会选取一个最优的检测模型.
表2列出了3个模型在GTSDB数据集上使用不同IOU阈值的三大类交通标志P,R值,其中我们设定IOU阈值的范围是0.1~0.9,阈值间隔为0.1.从表2中可知,对于每一个模型来说,当IOU阈值增加时,模型的精确率会增加,而召回率会随之降低.这是由于增大的IOU阈值会使得模型筛选出来的预测框更加少,从而极大程度上保留了正确的预测框,但同时也会剔除一些正确的预测框.从表2可以看出,对于每一类标志来说,模型1的指示标志与禁令标志的精确率可以达到91.43%和100.00%,模型2上禁令标志精确率及三大类mAP达到了98.68%和90.94%;模型2的指示标志、警告标志以及Tiny检测算法的禁令标志的召回率分别可以达到87.76%,93.65%,96.89%.
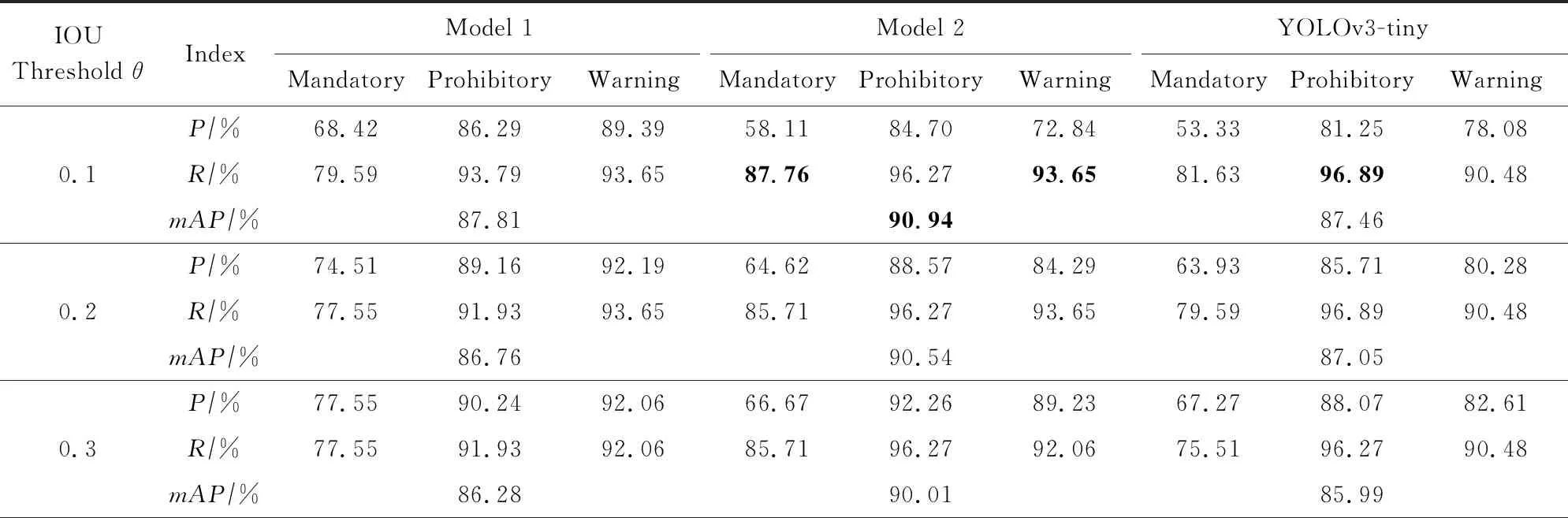
Table 2 P,R Values of Three Models Using Different IOU Thresholds in Three Kind of Traffic Signs on GTSDB表2 3个模型在GTSDB数据集上使用不同IOU阈值的三大类交通标志P,R值

Continued(Table 2)
Note: Boldface indicates the best performance of the corresponding classification; Underscores indicate that the optimal performance of the corresponding algorithm is initially selected by threshold.
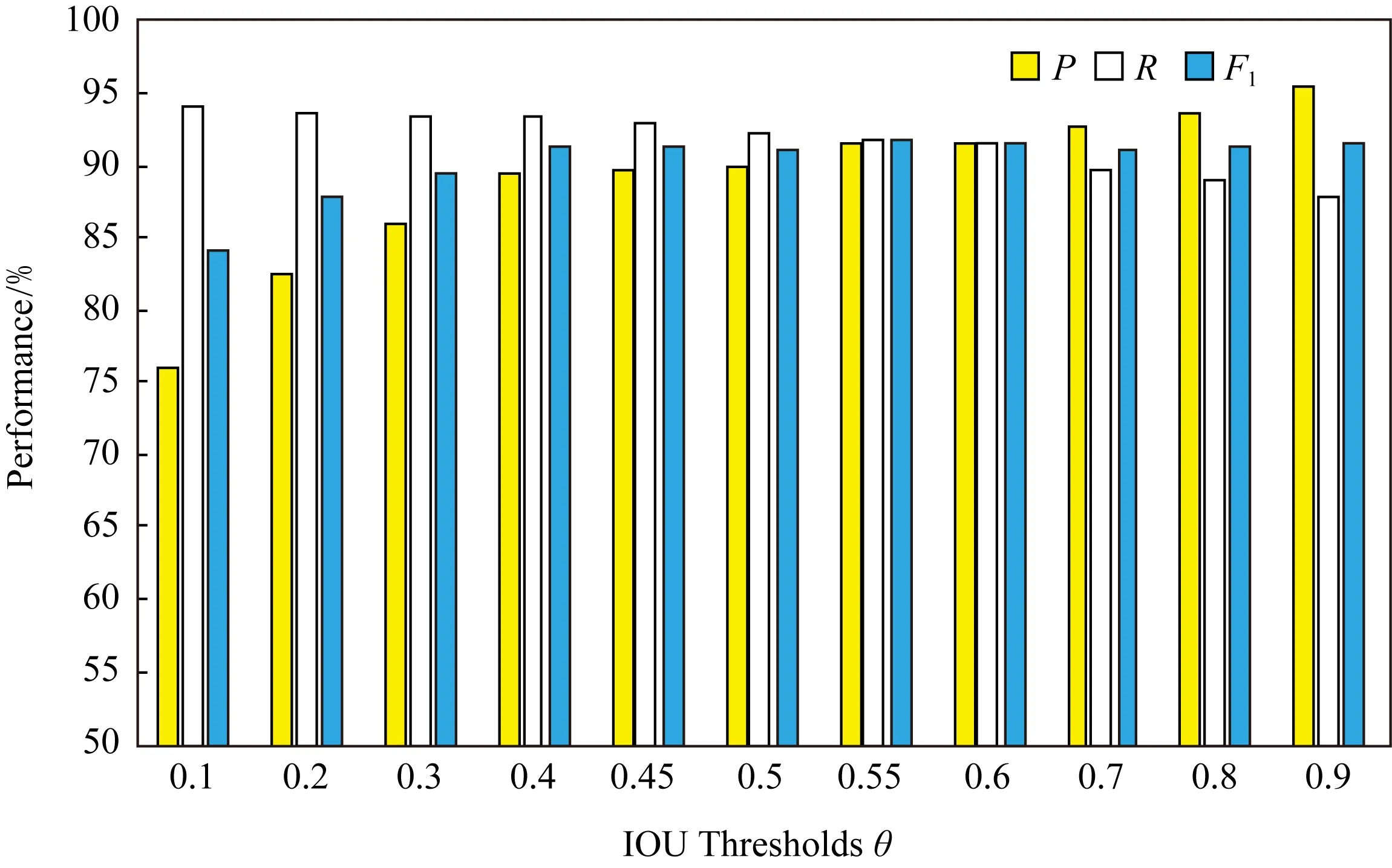
Fig. 3 Total P,R,and F1 values of model 2 using different IOU thresholds on GTSDB图3 GTSDB数据集上模型2在不同IOU阈值下的总P,R,F1值
根据各模型的mAP值、细分类别中P,R值不小于70%以及各模型取得峰值数量最多等原则综合考虑,模型2在IOU阈值θ=0.4时可以获得单类别的精确率以及召回率总体相对较高的性能.但这仅仅是初步筛选阈值,接下来会进行细化区间筛选.
分析各模型在不同阈值下P,R值的波动情况,模型2的DMAD值并不是最小,甚至比Tiny原版的稳定性还要低,我们猜测这是由于GTSDB数据集样本数量偏少造成的,当数据集数量偏少时模型1更加稳定,当数据集数量增加后,模型2更加稳定.我们将在4.3.2节中使用更大数量的训练集验证这个猜想.
图3为模型2在GTSDB数据集上不同IOU阈值下的总P,R值和F1值.由表2可知,模型2在θ=0.4附近可取得单类别最佳性能,所以在测量总P,R值时,我们在0.4~0.6之间细化区域,以找到检测性能最好的区域.从图3我们可以看出,在θ=0.55时,F1取得了91.77%.这代表着此时的P,R值可以达到较高且相对平衡的状态.
在GTSDB数据集上的对比实验中,我们选取了10个算法进行对比.如表3所示,精确率、召回率和F1值最好的是ConvNet算法[24],虽然模型2以上指标不是最高的,但排名靠前,其精确度、召回率和F1值分别排在第3位、第2位和第2位.模型2比文献[24]稍差主要是因为我们是以检测速度为首要指标,在不影响检测速度的情况下尽可能地提高算法的精确率和召回率.所以我们的网络没有构建得很深,这会使得检测速度很快,也会给算法带来检测精确率上的瓶颈.模型2的F1值相较于文献[24]下降了6.39%,但检测速度却提高了81.48%,模型2的检测耗时只需要5 ms,在所有对比算法中是最快的.值得一提的是,对比算法的P,R值均参考的是原论文实验中的结果,对比算法的F1值是根据其论文中P,R值计算得出的.

Table 3 Comparison of Experimental Results on GTSDB表3 GTSDB数据集上对比实验结果
Note: Boldface indicates the best performance of the corres-ponding classification; * Indicates that the algorithm does not disclose code, and we do not have the same hardware environment, so the detection time comparison is only for reference. The hardware environment of the algorithm is GeForce GTX Titan XP with better performance, while we use NVIDIA GTX980ti.
图4为模型2和原版Tiny模型在GTSDB数据集上的检测效果图,绿色框为模型2检测结果,红色框为YOLOv3-tiny检测结果.从图4(a)(b)中可以看出,模型2在图像背光整体偏暗时还能够检测出较小、较偏的交通标志.图4(c)中Tiny算法把穿着蓝色雨衣骑自习车的人误检成交通标志.如图4(d)所示,模型2能够更加准确地定位交通标志的边缘.

Fig. 4 The detection examples on GTSDB图4 GTSDB数据集检测效果图
4.3.2 CCTSDB数据集上的评估
由于GTSDB数据集仅仅只有600张训练图片、300张测试图片,且还存在少量负样本数据,数据偏少,这对于深度神经网络的训练是非常不利的.因此我们还在CCTSDB这种大型数据集上进行了评估,同时验证4.3.1节最后的猜想是否正确.
在CCTSDB数据集上的实验方法及流程与GTSDB数据集上相同,表4是3个模型在CCTSDB数据集上使用不同IOU阈值的三大类交通标志P,R值.由于算法相同,P,R值、mAP值与θ之间的变化规律和在GTSDB数据集上相同.加粗字体为各类别的较高值,下划线代表初步筛选的阈值及较佳性能.
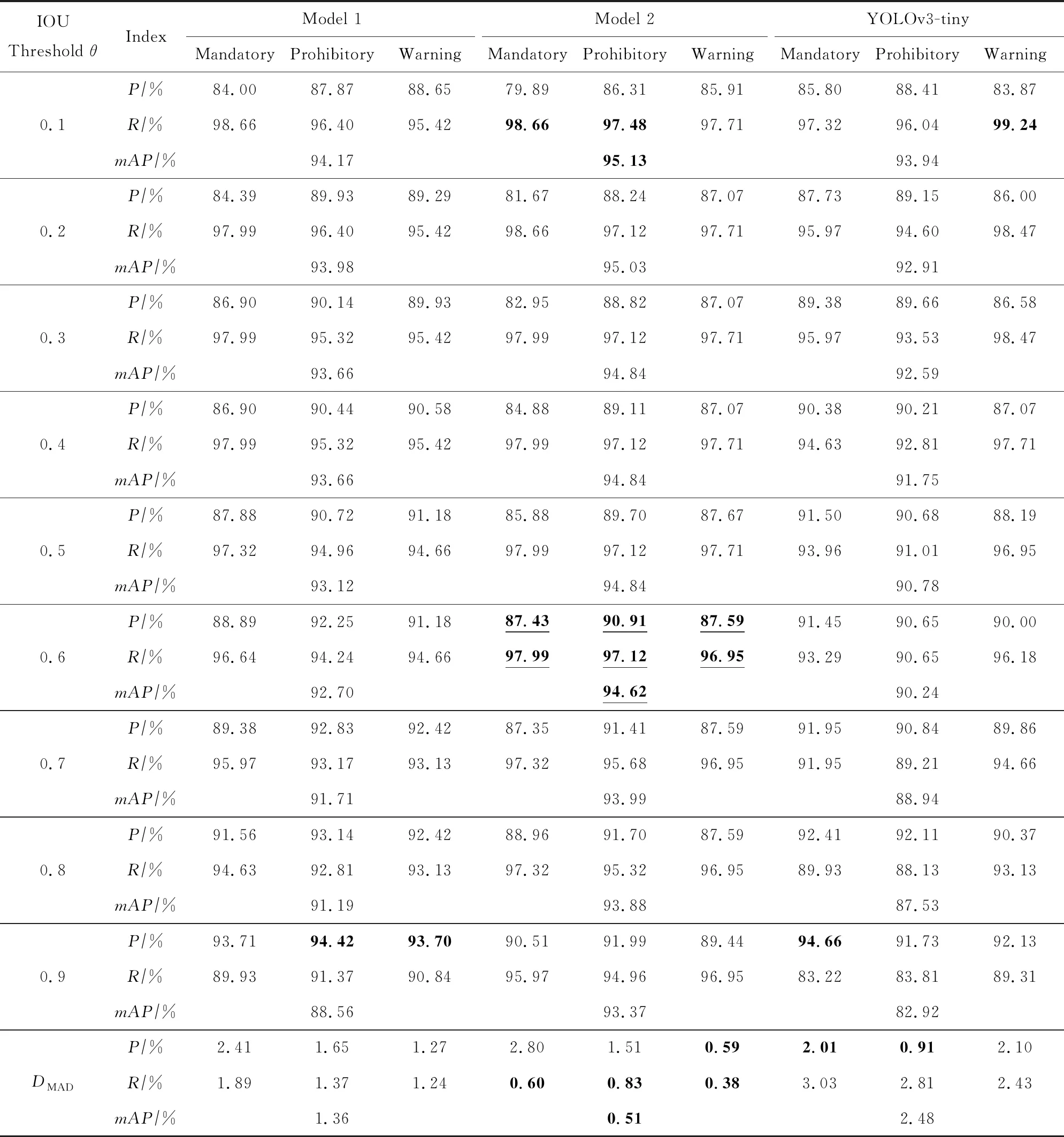
Table 4 P,R Values of Three Models Using Different IOU Thresholds in Three Kind of Traffic Signs on CCTSDB表4 3个模型在CCTSDB数据集上使用不同IOU阈值的三大类交通标志P,R值
Note: Boldface indicates the best performance of the corresponding classification; Underscores indicate that the optimal performance of the corresponding algorithm is initially selected by threshold.
值得一提的是,由于CCTSDB数据集中训练数据数量高达15 000张,这使得模型2的稳定性得以突显出来.模型2在各IOU阈值下的单类别最稳定数量最多,且总体模型DMAD值最小,这表明在具有大型数据集的情况下,模型2结合残差思想与多尺度预测思想不仅具有较高的检测精确率和召回率,同时在不同IOU阈值下的预测框相对一致,更加稳定,因此模型2具有更高的鲁棒性.
图5所展示的是模型2在CCTSDB数据集上使用不同IOU阈值的总P,R值与F1值.从图5我们可以看出,模型2的精确率在各个阈值下都不是很高,但是召回率高达97%.这是因为我们在模型2上增加了一个预测输出层,使得预测框更多,从而增加了召回率.经过细化区间实验证明,在θ=0.6时,模型2在CCTSDB数据集上的精确率、召回率及F1值取得最高值.
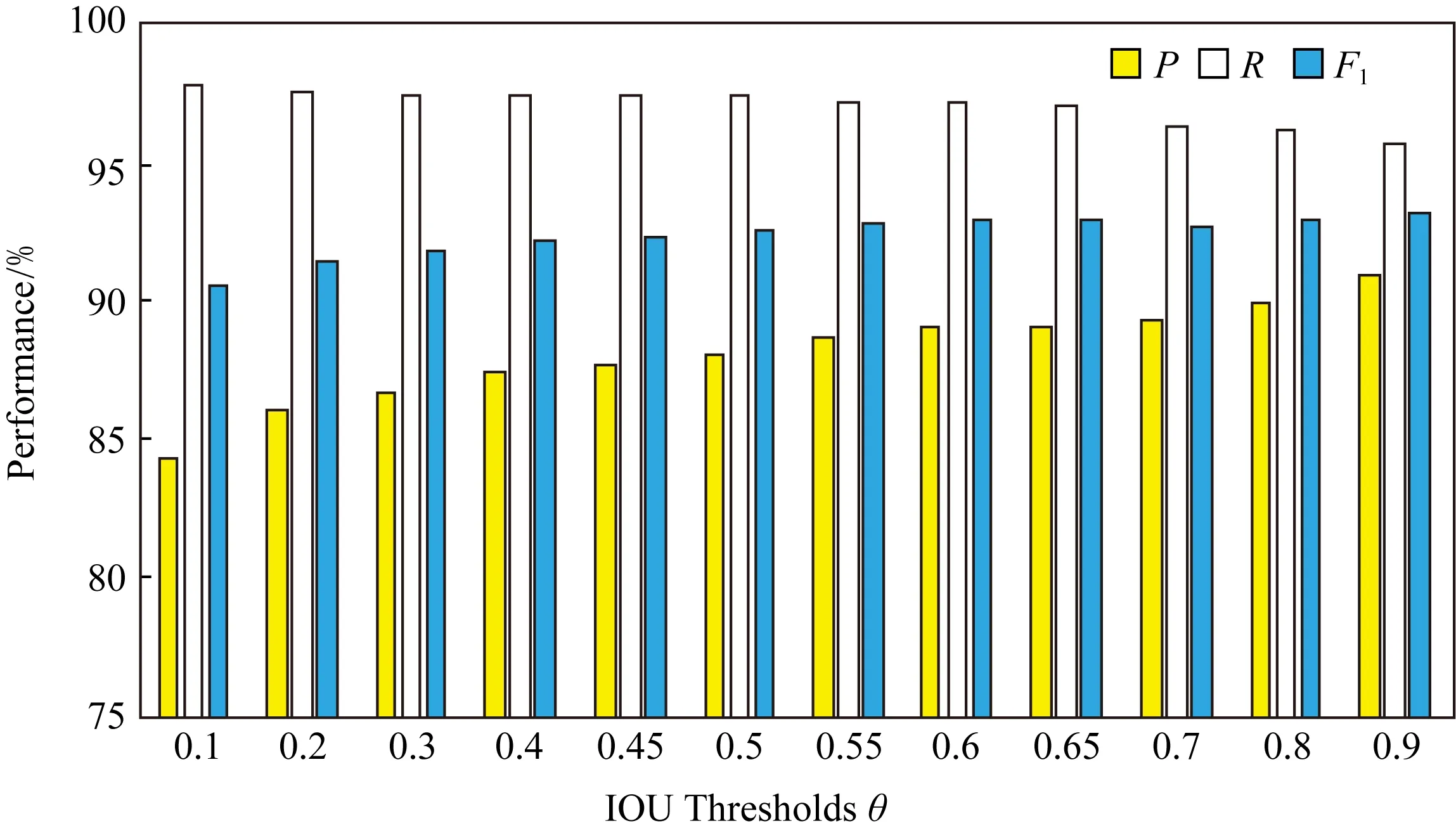
Fig. 5 Total P,R,and F1 values of model 2 using different IOU thresholds on CCTSDB图5 CCTSDB数据集上模型2在不同IOU阈值下的总P,R,F1值
我们将在CCTSDB数据集上与文献[16]中所提出的模型进行每一类别的详细比较,结果如表5所示.表5中Model-A,Model-B,Model-C为文献[16]中提出的各种改进模型,模型2为本文提出的最佳模型.由表5可知,对于准确率来说,YOLOv2的指示标志、Model-A的禁令与警告标志有最高值,这是因为文献16的基础网络是YOLOv2,而我们使用的是精简版的YOLOv3-tiny检测算法,在YOLOv3系列中Tiny算法均是以减少卷积层、牺牲精确率来提高检测速度;但是对于召回率来说,我们的模型2均取得最高值,相比文献[16]中最佳模型Model-B的三大类召回率分别提高了18.56%,24.38%,2.21%,这是因为文献[16]中的算法都是基于YOLOv2检测算法实现的,该算法有且只有一个预测输出层,而我们的模型2具有3个预测输出层,这能提高算法的召回率.但是准确率与召回率往往相互对立,无法同时取得最高值.因此,为了综合评估算法的水平,所以我们在P,R值的基础上计算了F1值.
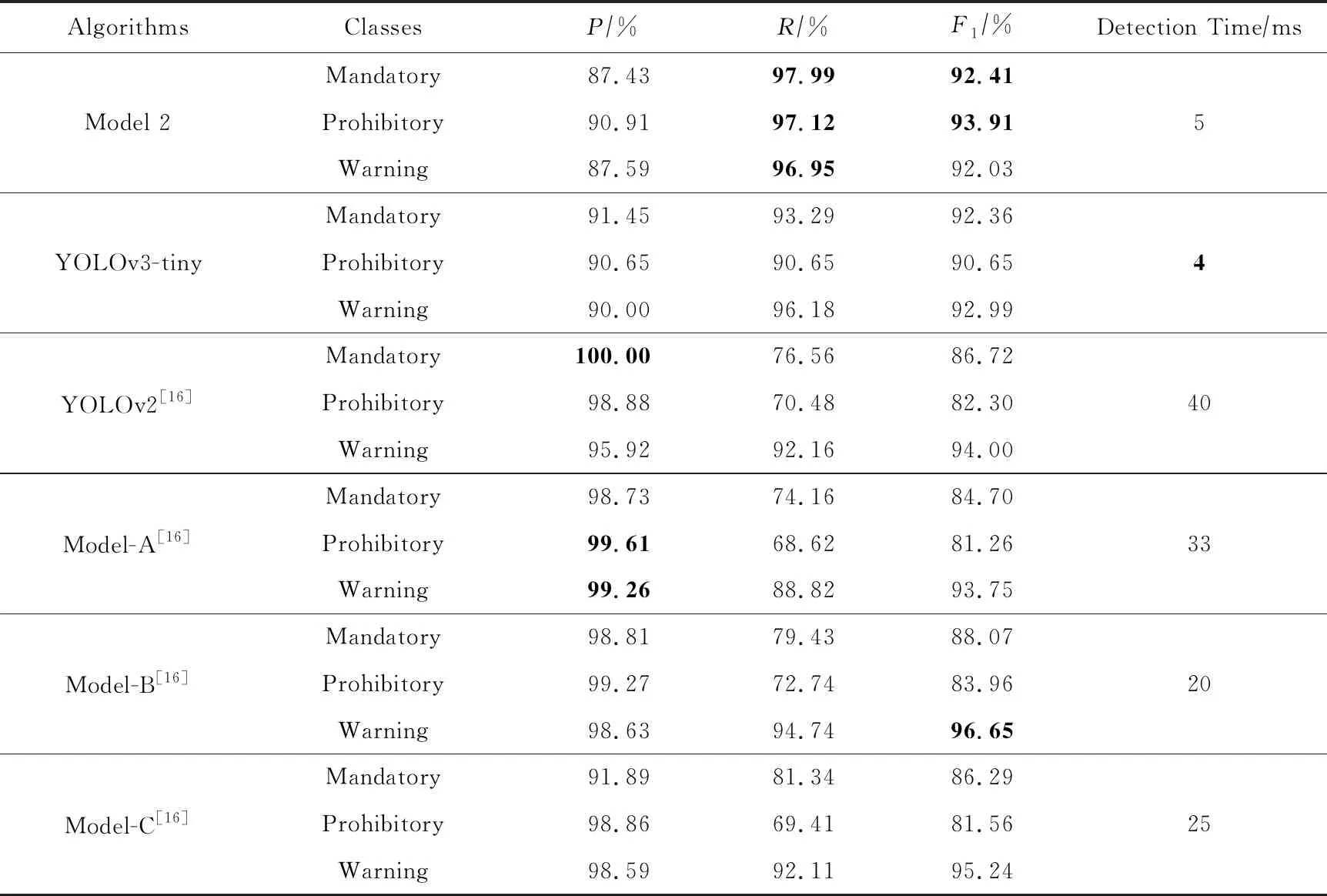
Table 5 Comparison of Experimental Results on CCTSDB表5 CCTSDB数据集上对比实验结果
Note: Boldface indicates the best performance of the corresponding classification.
我们的模型2在指示标志与禁令标志的F1值分别取得了最高的92.41%和93.91%,同时检测单张图片速度是文献[16]检测算法的4~8倍.模型2的检测时间略低于YOLOv3-tiny检测算法,是因为我们在模型2上增加1个尺度预测以及嵌套残差结构,这会使得检测时间略有增加,不过仅仅是增加了1 ms,最终检测时间与原版算法处于同一数量级,所以我们认为模型2算法是基本上不影响检测时间的情况下提高了鲁棒性.
图6为模型2和原版Tiny模型在CCTSDB数据集上的检测效果图,绿色框为模型2检测结果,红色框为YOLOv3-tiny检测算法结果.图6(a)(b)为小目标检测对比,Tiny检测算法均未检测出真实场景中距离较远、尺寸较小的交通标志;图6(c)(d)为预测框位置对比,模型2的检测框可以很好地外切交通标志四周,在有相近颜色的背景干扰时也能够准确地定位交通标志.

Fig. 6 The detection examples on CCTSDB图6 CCTSDB检测效果图
5 总 结
现实场景中交通标志的实时检测一直是研究者重点关注的话题.本文对此进行了研究,综述了目前交通标志检测的方法,并在YOLOv3-tiny检测算法的网络基础上提出了一种基于三尺度嵌套残差结构的交通标志快速检测算法.
首先,我们在Tiny检测算法上采用逐像素相加的跨层连接改进通道串接的跨层连接,使得连接操作输出的特征图大小相比之前在通道数上大大减少,同时由于采用改进的连接方式,使得网络内部形成了1个小残差结构,这可以让主干网络参数进行二次调参,这就是二尺度预测的残差结构.然后,我们在此基础上增加了1层更大尺度的预测输出,更高空间分辨率的特征图包含更多的空间细节信息,有利于小目标的检测,同时我们在这一层预测输出上也采用了与之前相同的跨层连接方式,形成了1个大残差结构.最后,将2个残差结构进行嵌套,使得最终网络形成了1个三尺度嵌套残差结构的交通标志快速检测算法.相对于YOLOv3-tiny检测算法来说,我们不但没有增加过多检测时间,而且还提高了算法的检测精确率与召回率.
在GTSDB与CCTSDB数据集上的实验也证明了我们的三尺度嵌套残差结构的交通标志快速检测算法可以在大部分对比算法中取得较高成绩,同时检测速度也是最快的.由于我们结合了残差块与多尺度预测的思想,在IOU阈值发生变化时,我们的模型也是最稳定的.事实上,许多场景中的目标检测都能用到本文提出的检测算法,特别是在计算能力受限且实时性要求极高的环境下,本算法可以确保实时、稳定、高效、鲁棒的检测效果.我们新版的CCTSDB数据集目前正在制作中,下一步将公开发布.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
汽车实用技术(2022年9期)2022-05-20
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
小天使·一年级语数英综合(2016年8期)2016-05-14
文苑(2015年9期)2015-09-10
小天使·一年级语数英综合(2014年7期)2014-06-26
