
基于胶囊网络的三维模型识别
2020-06-07 07:06:28曹小威曲志坚徐玲玲刘晓红
计算机应用 2020年5期
曹小威,曲志坚,徐玲玲,刘晓红
(山东理工大学计算机科学与技术学院,山东淄博255000)
(∗通信作者电子邮箱lxhsdut@163.com)
0 引言
卷积神经网络(Convolutional Neural Network,CNN)不仅在传统的二维图像识别领域展现了强大的特征提取能力,在三维模型识别领域也被广泛应用:王慧[1]使用投影提取三维模型的形状特征,并使用一种可以同时计算三个侧面投影图的权值优化深度卷积网络,从而对三维模型信息进行深层次加工处理,进而对三维模型进行分类识别;侯宇昆[2]提取三维模型的12个角度视图以及全景式图,并将两种视图融合,输入到搭建好的13层的卷积神经网络中从而实现对三维模型的识别,在ModelNet10上取得了94%的平均识别准确率;Hegde等[3]融合了基于体素的V-CNNⅠ、V-CNNⅡ以及基于视图的MV-CNN(Multi-View Convolutional Neural Network),得到FusionNet,并在ModelNet10的识别中得到了93.1%的识别准确率;Bu等[4]首先将低层三维形状描述符编码成几何词袋,从中发现中层模式,探索词与词之间的几何关系。在此基础上,通过深度信念网络学习高级形状特征,实验证明该方法对三维模型分类任务具有较强的识别能力。尽管在卷积神经网络的设计中使用池化层在一定程度上增大了神经元的感受野以及降低了样本训练的开销,但是大量池化层的使用会造成原始数据结构信息的丢失,从而对最终的识别结果造成不良影响。
Hinton等[5]于2017年提出的胶囊网络创新地使用向量胶囊取代传统神经网络的标量神经元,舍弃了池化层,并提出了动态路由(Dynamic Routing,DR)算法更新胶囊之间的连接权重,从而较好地保留了特征的空间信息,在MINIST手写数字识别上达到了99.2%识别准确率。自胶囊网络诞生之后,人们将其应用到了很多领域,如人类行为识别[6]、人工声音事件检测[7]、乳腺癌识别[8]等。在三维模型识别领域,Ahmad等[9]于2018年提出了3D Capsule Networks,证明了同样深度的胶囊网络比卷积网络,不仅对于二值体素化的三维模型具有更好的识别能力,而且在使用40%的训练集进行训练时,胶囊网络也能得到91.37%的识别率。Ryan[10]将二维胶囊网络加以改变,使之能够识别三维体素化数据,通过调优,在ModelNet10的识别中达到了93%的识别准确率。在验证旋转敏感性方面,通过将测试集的体素化数据进行转置并输入训练好的胶囊网络中进行识别之后,发现胶囊网络对该测试集中的模型并不能很好地识别。然而胶囊网络利用向量的方向存储特征的相对空间信息,理论上应该对旋转模型具有良好的识别能力。此外,为了保留了特征的空间信息,现有的基于胶囊网络的三维模型识别网络通常都舍弃了池化层的设计,但是池化层本身在特征降维、压缩数据、减少过拟合、提高模型容错性等方面具有优良表现,适当地引入一层步长和较小的池化层不会导致特征空间信息的大量丢失。
本文以 Ryan[10]模型为 Basemodel,引入 VoxNet[11]作对比,从提高识别率和探索旋转敏感性两个方面作了相关研究:在提高识别率方面,本文提出了一种新的基于胶囊网络的结构3DSPNCapsNet,引入了一层步长和尺寸都较小的池化层;同时改进了动态路由协议,将向量长度加入迭代过程中,使得网络模型在ModelNet10上的识别准确率得到提高;在探索旋转敏感性方面,本文对三维模型的旋转进行了可视化,并分别在原训练集和扩充了部分旋转模型的训练集上进行训练,在旋转测试集上测试,达到了良好效果。
1 3DSPNCapsNet
CapsNet最早由Hinton提出,利用向量保存特征信息。用向量不同维度上的值分别表示不同的属性,向量的模表示这个实体出现的概率。Basemodel是对Hinton提出的二维胶囊网络的三维扩展,在两个胶囊层之前仅仅使用了一个卷积层,并没有在网络设计中增加太多的层次结构。而传统的GoogleNet具有高达22层的深度网络结构。通常情况下,更深的结构意味着网络能提取到更具有代表性的特征,然而层数过多也容易导致过拟合、梯度爆炸等情况的出现。
基于此,本文提出了一种基于胶囊网络的网络结构3DSPNCapsNet(3D Small Pooling No dense Capsule Networks),该网络由双CNN间连接一个最大池化层,以及初级胶囊层、次级胶囊层和输出胶囊层构成。与Basemodel的结构相比,3DSPNCapsNet增加了一层池化层和卷积层,在提取到更具代表性的特征的同时,利用一层步长和大小都较小的池化层减少了冗余特征。虽然池化层的引入会在一定程度上损失部分信息,不过一层步长和较小的池化层损失的信息有限,而其在扩大感知野、减少过拟合等方面的作用,会使网络学习到的特征更具有代表性。将该网络优化参数配置后用于三维模型识别,其结构如图1所示。

图1 3DSPNCapsNet结构Fig.1 Structureof 3DSPNCapsNet
如图1,体素化后大小为30×30×30的三维模型数据首先被第一个由256个三维卷积核构成,大小为9×9×9、步长为1×1×1、激活函数为Relu的卷积层提取基础特征,得到22×22×22×256的输出。经过大小为2×2×2、步长为2的最大池化层处理,将得到的21×21×21×256的结果通过第二个由大小为5×5×5、步长为1×1×1、96个卷积核构成的卷积层进行卷积操作,得到17×17×17×96的输出。然后使用32个步长为2的9×9×9×256的卷积核对其进行8通道卷积,将每个8通道卷积结果封装成8维向量,并使用Squash激活函数处理胶囊,得到7×7×7×32×8的输出,构成了初级胶囊层。Squash函数保证向量的长度在0~1,从而使向量在高维空间中的方向体现实体的不同属性,其表达式如式(1):

其中:u j为输出向量,s j为输入向量。公式右边的s j‖‖s j是单位向量。如果s j→∞,则如果s j→ 0,则这种方式增加了模长较大的向量的权重[12]。
初级胶囊层的输出向量分别与8×48的姿态矩阵W ij点积之后,得到48维的向量,如式(2):

其中:u i为初始胶囊层的输出向量;W ij为姿态矩阵,由反向传播算法训练。点积之后的48维向量与次级胶囊层的10个1×48的向量全连接,使用第2章的DRL(Dynamic Routing-based algorithm with Length information)算法对该过程的参数进行更新。得到的预测向量构成次级胶囊层,最后输出胶囊层通过计算次级胶囊层的向量长度,取其中模长最大的向量作为最终预测。
由于重构网络的损失权重只有0.005,所以本文无论是训练还是预测过程,都舍弃了重构网络以及误差,从而降低了模型复杂度,有助于提升模型的训练效率。对于有10个类别、批训练的大小为N的数据集,新的误差计算方式如式(3)、(4):
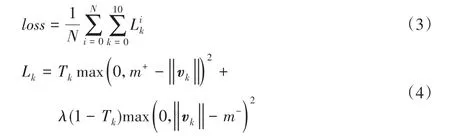
根据Hinton提出的胶囊网络,Lk为每个胶囊的margin loss,其中m-=0.1、m+=0.9、λ=0.5。当模型被正确识别为种类k时,Tk为1,否则为0。分别计算每个胶囊的Lk,再对所有胶囊的损失求和得到总体损失loss。
2 DRL算法
原有的动态路由算法仅仅使用余弦相似度来度量向量之间的相似度,但是这可能会导致网络训练时收敛速度较慢以及丢失部分信息。最近有一些胶囊网络的相关应用研究了新的动态规划算法,DRDL(Dynamic Routing-based algorithm with Direction and Length information)[13]就 是 其 中 的 一 个 。DRDL在动态路由的基础上将向量长度和方向信息引入算法中。不过将该方法引入3DSPNCapsNet后,训练结果不收敛,所以本文在其基础上做了一些修改,舍弃了其中对聚类中心向量s i取L2正则化以及使用预测向量ûj|i和目标向量v j的模长之差更新bij的步骤,提出了DRL算法。
定 义 多 维 空 间 的 两 个 向 量A=(A1,A2,…,An),B=(B1,B2,…,Bn),二者夹角的余弦:
j囊层的第j个胶囊的输出向量,bij为两个胶囊之间的连接权重。此外,Squash只在最后一轮迭代的时候使用。算法如图2所示。
首先初始化bij为0,其中bij表示上一层的胶囊i与本层的胶囊j之间的相关性,其值越大,表示两胶囊之间相关性越强。然后开始迭代,每次迭代开始时都先判断当前迭代是不是最后一轮,如果不是,就利用Softmax函数得到cij,Softmax函数如式(7):
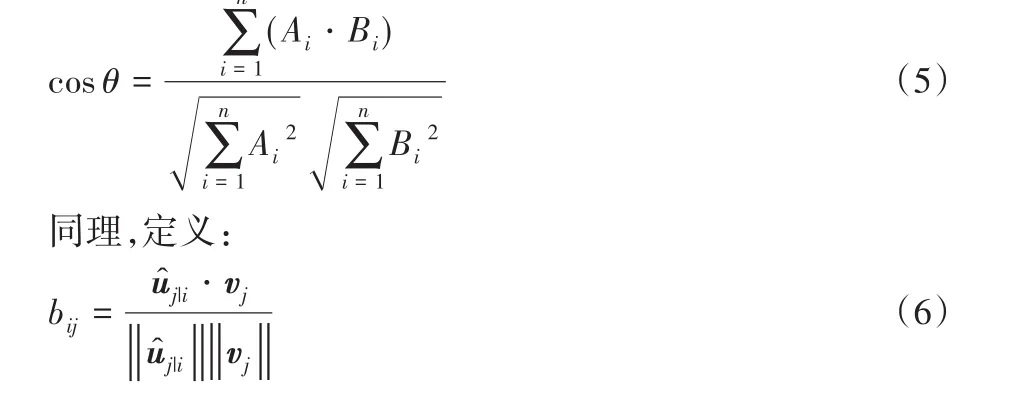

cij为动态路由过程中的耦合系数,然后对式(2)中的预测向量进行聚类,得到预测向量的聚类中心s j,并使用式(8)对bij进行更新:

如果上一层的预测向量ûj|i的单位向量与本层的聚类中心向量s j的单位向量的夹角在(-90°,90°),则bij为正;如果夹角为±90°,则bij变为0;如果夹角在(90°,270°),则bij为负。如果是最后一轮迭代,计算出聚类中心s j之后,通过Squash函数输出最终的预测向量。
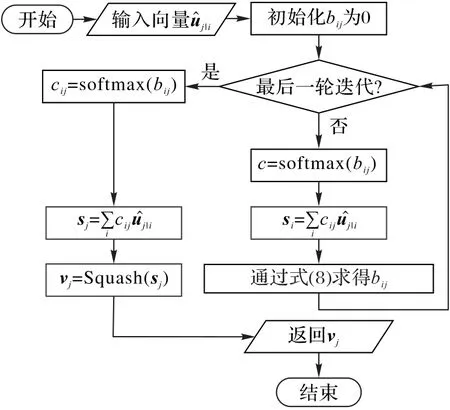
图2 DRL算法流程Fig.2 Flowchart of DRL algorithm
迭代过程结束,最后得到10个1×48的向量v j构成次级胶囊层,其长度表示实体出现的概率。
3 实验分析与结果
普林斯顿大学提供了两个大规模的标准三维模型数据集,分别为ShapeNet数据集和ModelNet数据集,其中ModelNet数据集包含了来自662类的127 915个三维模型,其子集ModelNet10包含了来自10类的4 899个三维模型。本文选取ModelNet10的模型作为实验数据库。
实验平台和开发工具有:CPU为Intel Xeon E3-1231 3.40 GHz,内存为 8 GB,显卡 Quadro K620,编程环境为Python3.5,基于Keras搭建的实验验证本文方法的有效性。
3.1 3DSPNCapsNet在标准训练集和测试集上的性能比较
本节分别使用融合了DRL算法的3DSPNCapsNet以及使用原始 DR 算法的 3DSPNCapsNet、Basemodel、VoxNet在标准的ModelNet10的训练集和测试集上训练和测试。将原始三维模型的.off文件体素化为.binvox文件,使用上采样解决类间不平衡问题之后,输入网络中使用5折交叉验证,每折训练5轮;学习率初始化为0.003,最后取交叉验证结果的平均值作为最终的识别率。训练期间根据输出胶囊的预测准确率对学习率进行动态调整,影响因子为0.5,学习率最低不小于0.000 1;batch size取10,使用1个GPU加速计算。几种方法在标准训练集和测试集上的识别率折线图如图3,融合了DRL算法的3DSPNCapsNet的混淆矩阵如图4,Basemodel的混淆矩阵如图5,使用原始DR算法的3DSPNCapsNet的混淆矩阵如图6,VoxNet的混淆矩阵如图7所示。
实验结果显示,融合DRL算法的3DSPNCapsNet平均识别率达到95%、使用原始DR算法的3DSPNCapsNet为94%、Bsaemodel为93%、VoxNet为88%,平均识别准率方面融合DRL算法的3DSPNCapsNet最高。从具体的模型识别分类来看,与Basemodel相比,融合DRL算法的3DSPNCapsNet除了sofa、table、toliet、bathtub 略低 1~3 个百分点之外,monitor、chair、bed高了 1~6个百分点,dresser、night_stand、desk高了12~18个百分点。与VoxNet相比,除了table类的识别率略低于VoxNet,其他类别的模型识别率都取得了与VoxNet相同或者更好的效果。平均识别率达到了95%以上。融合DRL算法的3DSPNCapsNet(以下简称3DSPNCapsNet)表现出了良好的特征提取能力和识别能力。
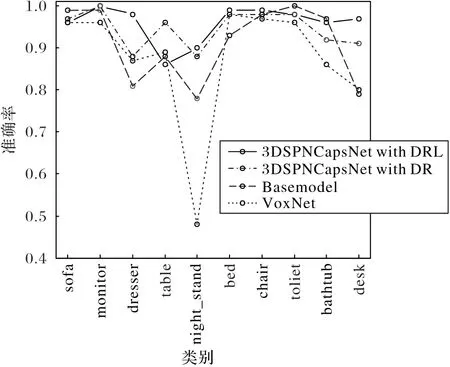
图3 使用DRL的3DSPNCapsNet与使用DR的3DSPNCapsNet、Basemodel、VoxNet的结果对比Fig.3 Resultscomparison of 3DSPNCapsNet with DRL,3DSPNCapsNet with DR,Basemodel,VoxNet
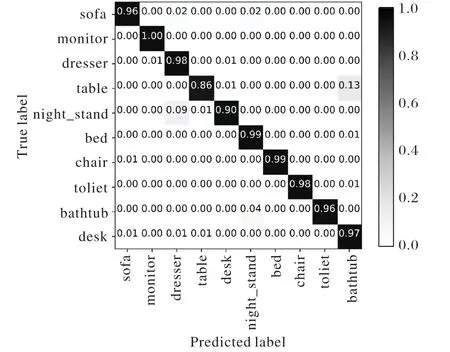
图4 3DSPNCapsNet混淆矩阵Fig.4 Confusion matrix of 3DSPNCapsNet
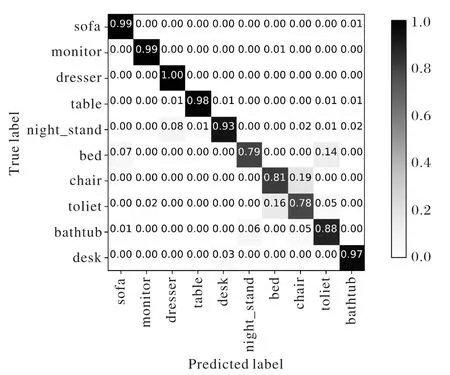
图5 Basemodel混淆矩阵Fig.5 Confusion matrix of Basemodel
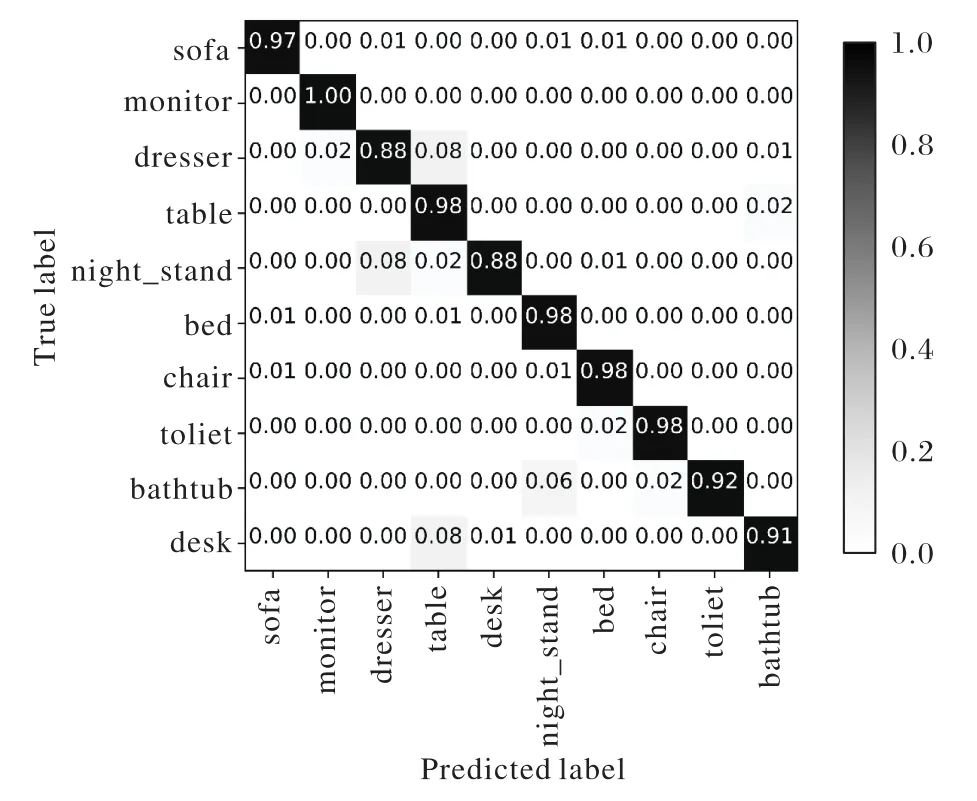
图6 3DSPNCapsNet with DR混淆矩阵Fig.6 Confusion matrix of 3DSPNCapsNet with DR
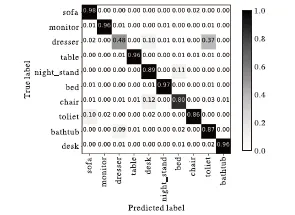
图7 VoxNet混淆矩阵Fig.7 Confusion matrix of VoxNet
3.2 3DSPNCapsNet在旋转敏感性方面的性能比较
3.2.1 不增加旋转训练集时,三种方法对旋转的敏感性对比
胶囊网络通过向量胶囊的形式既保存了特征信息,又记录了不同特征之间的空间位置信息,理论上来说对于模型的旋转应该具有较高的识别准确率。为了验证这一特点,本文使用Meshlab将测试集的模型先绕z轴分别旋转30°、60°、90°、120°、150°、180°、210°、240°、270°、300°、330°,再体素化为.binvox文件,最后使用viewvox将其可视化。使用在原始的训练集上训练的模型分别在上述旋转测试集上测试。旋转体素化结果如图8,旋转测试结果如图9。
实验结果显示,当前实验条件下,3DSPNCapsNet对原始测试集模型识别率达到95%、Basemodel为93%、VoxNet为88%。然而3DSPNCapsNet对旋转模型的识别能力并没有达到预期效果,平均旋转识别率仅48%,与Basemodel的48%以及Voxnet的49%相似。这是由于网络没有学习到相关的旋转信息。将训练集进行扩展,重新训练网络之后再在旋转测试集上测试。
3.2.2 增加旋转训练集时,三种方法对旋转的敏感性对比
将原始训练集分别旋转30°、60°、90°和原有的训练集共同组成了新的训练集,在新的训练集上使用三种方法分别训 练,并在旋转测试集测试。实验结果如图10。
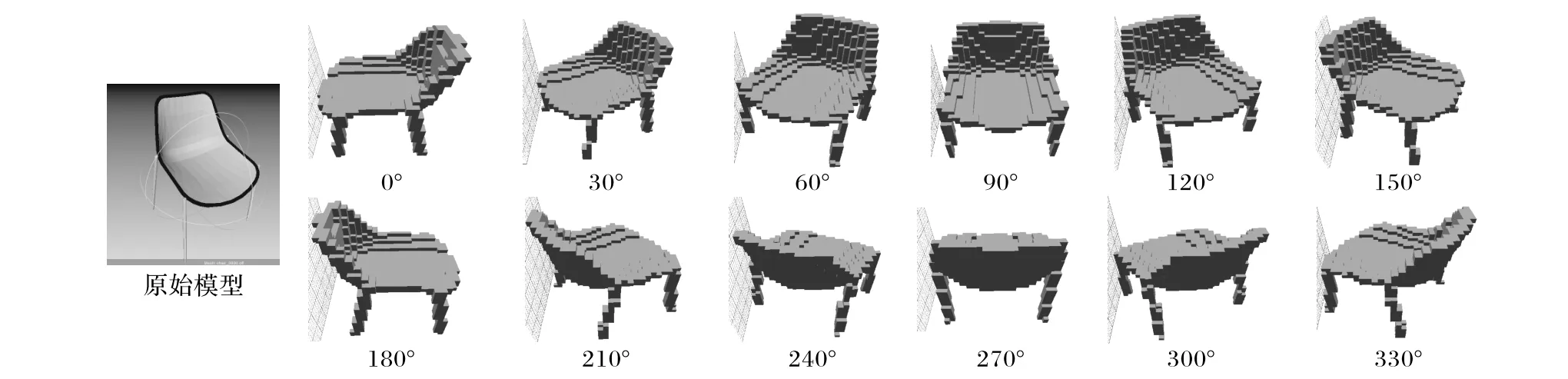
图8 先绕z轴旋转,再体素化的测试集Fig 8 Test set first rotated around the z-axis,then voxelized
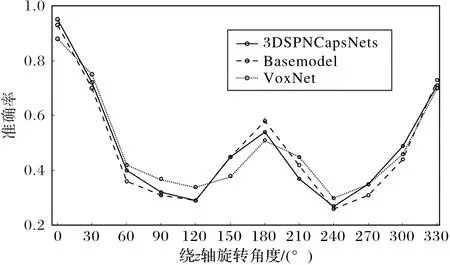
图9 在原训练集训练、旋转测试集测试的准确率比较Fig.9 Test accuracy comparison of rotation test set with original training set training
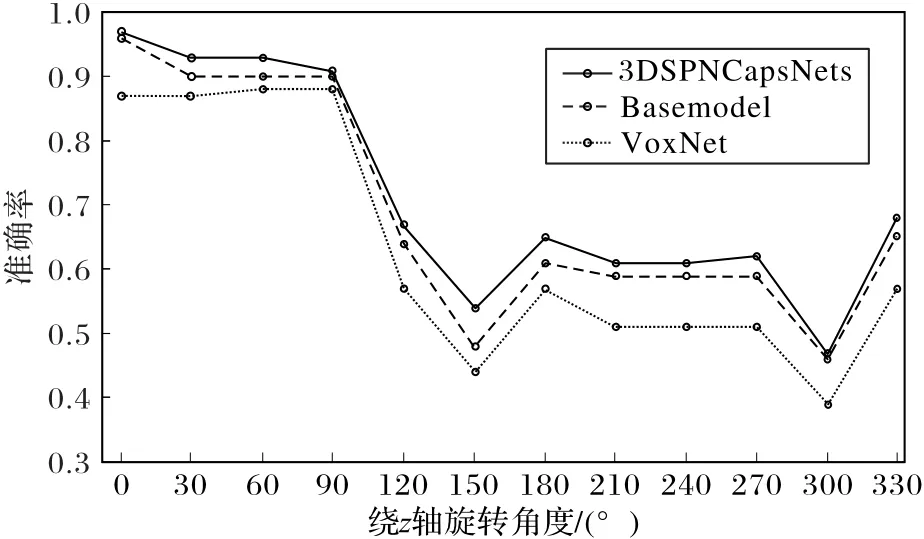
图10 在旋转训练集训练、旋转测试集测试的准确率比较Fig.10 Test accuracy comparison of rotation test set with rotation trainingset training
由图10可以直观地看出,扩展了旋转训练集之后,三种方法对旋转三维模型都表现出了更好的识别能力,其中3DSPNCapsNet在30°、60°、90°这三个角度上的旋转识别率达到了91%以上,Basemodel也达到了90%以上,VoxNet达到87%以上。相对于没有增加旋转训练集的情况,3DSPNCapsNet对于旋转模型的平均识别率提升了24个百分点,Basemodel提升了21个百分点,VoxNet提升了15个百分点。虽然3DSPNCapsNet平均达到了72%的识别准确率,但是识别率的方差偏大,数据分布不均衡,在30°、60°、90°的识别率明显高于其他旋转角度的识别率。从实验结果还可以看出,三个模型在识别率的变化趋势上保持了一致性:在120°和150°上逐渐下降,这是因为旋转角度逐渐变大时,与原有模型的差异性也逐渐增加,导致识别率下降;而180°时识别率反而提高了,并在210°、240°、270°的旋转模型上保持了几乎一致的识别率。通过多次实验发现,这种情况出现的原因是三种网络对于原始训练集具有最高的识别准确率。相对于其他旋转角度,三种网络对原始训练模型的中心对称模型也具有一定的识别能力,所以网络在旋转300°时识别率重新下降,而旋转330°时的识别率与120°的识别率相当,这是因为120°与90°的旋转训练集相差30°,同330°与原始训练集相差的角度一致。基于此,本文重新调整了旋转训练集的构成,将原始训练集分别旋转90°、150°、240°和原有的训练集共同组成了新的训练集,在新的旋转训练集上使用三种网络分别训练,并在旋转测试集测试。实验结果如图11。
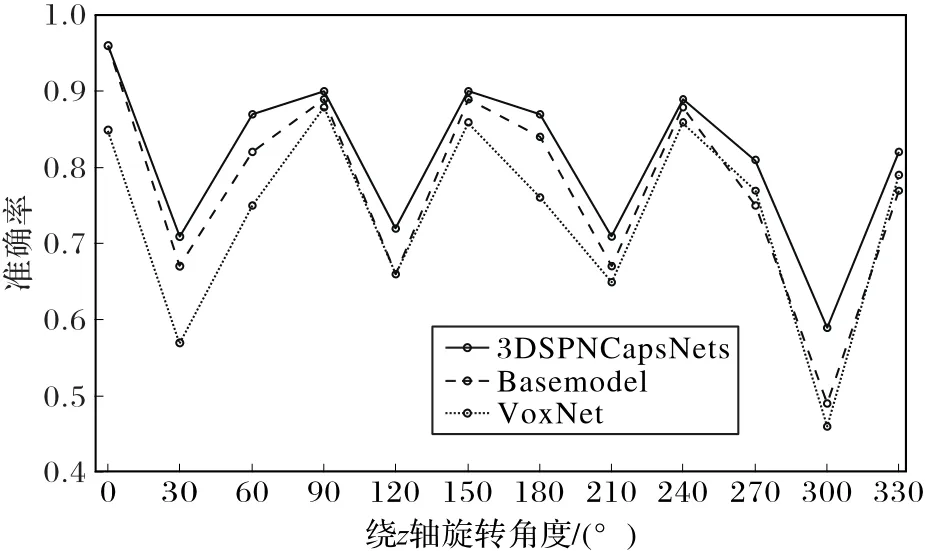
图11 在新的旋转训练集训练、旋转测试集测试的准确率比较Fig.11 Test accuracy comparison of rotation test set with new rotation trainingset training
实验结果显示,调整了旋转训练集之后,三种方法在旋转模型的识别方面整体都有了较大的提升。3DSPNCapsNet和Basemodel在原始测试集上的识别准确率都达到了96%,在其他旋转测试集上,3DSPNCapsNet的总体平均识别率达到了81%,高于 Basemodel的 78%和VoxNet的73%;相对于30°、60°、90°的旋转训练集实验,平均识别率提高了9个百分点,Basemodel提高了9个百分点,VoxNet提高了10个百分点,识别准确率方差较小,数据分布更加均衡。3DSPNCapsNet整体对于旋转模型具有更好的识别能力。
3.3 池化层对识别率的影响
Hinton提出胶囊网络的初衷是因为池化层的设计会导致特征信息的丢失,尤其是特征之间的空间位置信息很容易在池化的过程中被丢弃。基于此,本文实验比较分析了池化层对模型的旋转识别的影响。将3DSPNCapsNet的池化层舍弃,并与未舍弃池化层的网络分别在旋转训练集和测试集上训练和测试,并进行对比,实验结果如图12。
图12显示,两种方法对于旋转都具有较好的识别能力,其中有池化层的网络在原始数据集上取得了更高的96%的识别准确率,而除了在旋转210°的模型识别率上低了5个百分点,其他的角度都与无池化层的模型识别率相似,说明两种胶囊网络都具有良好的特征提取能力,而且一层大小和步长都较小的池化层的加入并不会导致特征信息的大量丢失。池化层在降维、实现非线性、扩大感知野等方面都有积极作用,所以不必在新架构的探索中完全舍弃池化层的设计,池化与胶囊网络相结合可能会有更好的效果。
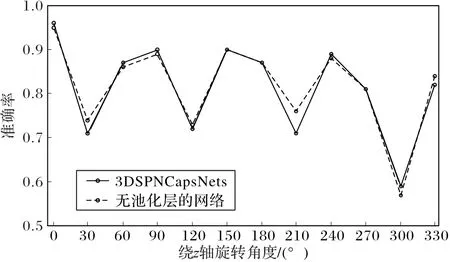
图12 池化层对旋转准确率的影响Fig.12 Effect of pooling layer on rotation recognition accuracy
4 结语
本文提出了一种基于胶囊网络的三维模型识别算法,通过在卷积网络中增加卷积层、池化层得到相对于原始网络结构更好的特征提取效果,舍弃重构网络减少参数数量,以及使用新的动态路由算法得到在原始测试集上95%的识别准确率。通过增加一定数量的旋转训练集,得到对旋转三维模型更有识别力的胶囊网络,并验证了一层大小和步长较小的池化层的引入不会损失太多的信息,反而有可能在一定程度上产生更好的结果。在后续的研究中,可以探索更深的网络结构来进一步提高识别准确率;另外还可以探索如何使胶囊网络学习到更具有旋转方面的代表性的特征,从而不需要通过扩充训练集的方式,就能对三维空间内任意方向任意角度的旋转都具有更好的识别能力。
猜你喜欢
科技创新与应用(2021年23期)2021-08-30 11:46:16
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
无线互联科技(2020年15期)2020-11-10 06:00:58
科技传播(2020年6期)2020-05-25 11:07:46
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年5期)2018-08-21 03:37:40
雷达科学与技术(2018年3期)2018-07-18 00:59:32
