
一种改进的卷积神经网络的室内深度估计方法
2020-06-04 03:33:52张金铭
天津大学学报(自然科学与工程技术版) 2020年8期
梁 煜,张金铭,张 为
一种改进的卷积神经网络的室内深度估计方法
梁 煜,张金铭,张 为
(天津大学微电子学院,天津 300072)
针对单幅图像的室内深度估计缺少显著局部或全局特征问题,提出了一种基于多种网络(全卷积网络分别与通道注意力网络、残差网络结合)构成的编码器解码器结构.该网络采用端到端的学习框架.首先使用全卷积网络与通道注意力网络结合的全卷积通道注意力网络模块作为编码器,通过信道信息获取全局感受野,提高特征图精度,并适当地将全连接层改为卷积层以达到减少网络参数的目的.然后将全卷积网络与残差网络结合构成的上采样模块作为解码器,利用ResNet的特点——跳层连接,将解码器网络加深,提高深度图的精度,将卷积网络与残差网络结合,实现端对端,并减少网络运行所用时间.最后,使用1损失函数优化模型.在公开数据集NYU Depth v2的测试下,实验结果表明,和现有的其他单目深度估计方法相比,本文所提出的网络模型不仅精简了繁琐的精化粗图的过程,而且所预测的深度图精度更高,阈值精度的提升不少于0.5%,运行网络结构的平均用时21ms,为实现实时性奠定了基础,具有一定的理论研究价值和实际应用价值.
机器视觉;卷积神经网络;室内深度估计;单目图像;深度学习
在计算机视觉领域中,二维图像的深度估计是场景理解与重建至关重要的一步,而且在面对某些深度不可测的情况下,深度估计有着重要的研究意义.早期的工作重点是通过开发几何约束的算法,从立体图像中估计深度,这些算法依靠图像和三角测量之间的点的对应关系来估计深度.在单视图情况下,大多数方法依赖于运动或不同的拍摄条件(不同的拍摄角度等).尽管缺乏几何约束这类信息会导致深度图产生一定的模糊度,但受人类单眼对深度感知的类比启发,对单个RGB图像的深度图预测也进行了研究.
近年来,深度学习在图像领域上的成功应用,使得人们开始研究并提出大量用于深度估计的网络结构,从一定程度上解决了单目深度估计的问题.但是,由于神经网络中的一系列下采样操作,导致深度图的分辨率比输入图的分辨率低很多,现今大部分的研究致力于解决该问题.如:2016年Laina等[1]提出一个新的上采样模块——up-projection,可以使高级特征信息在网络中更有效率地传播.2017年Dharmasiri 等[2]使用联合学习,通过一个简单的网络,同时学习3种不同的变量(深度,表面法向量,语义标签)也得到了不错的效果.2018年Fu等[3]为了减少网络训练、节约计算空间,引入了一个新的网络结构——空洞卷积,避免了冗余的下采样,并且在不用跳层连接的前提下,捕获了多尺度信息,将深度估计的精确度推向新高.
此外,越来越多的深度卷积网络被提出并用于深度估计.全卷积网络[4]早先应用在语义分割领域,用卷积层代替传统卷积网络中的全连接层,可以令参数数量急剧下降,降低大量的计算内存,而且全卷积网络可以接收任意尺寸的输入图像,并统一输出经过下采样的特征图,实现端对端的传输方式.目前全卷积网络也应用于一些深度估计的网络上.ResNet是由He等[5]首次提出.他们在研究中分析模型衰减、梯度消失的原因,引入了跳层,该层绕过两个或多个卷积,然后对通过跳层和卷积的结果求和输出.按照这种设计,可以避免模型退化或梯度消失的情况,创建更深层的网络.另外,最新实验研究表明[6],SENet通过将“注意力”学习机制集成到神经网络中,可以得到不错的增强特征的效果,改善特征图的质量,有助于恢复信息并捕获特征间的空间相关性.在神经网络的每一个卷积层中,大量的卷积核会表现出相邻空间的连接属性,沿着输入通道,并在局部的感受野中,融合空间与通道的像素信息.
同户外场景相比,室内场景通常缺少显著的局部或全局视觉特征,但是深度估计标签又具有信息密度大、细节繁杂等问题,因此,本文针对以上两个问题设计了一种网络模型,将三者——全卷积网络、SENet、ResNet,结合在一起搭建本文所使用的网络,主要包含3个过程:①设计一种端对端的网络结构,融合全卷积网络、SENet和ResNet 3种网络,充分利用3种网络的优越性实现深度估计;②使用由全卷积通道注意力网络(fully convolutional squeeze-and-excitation networks,FCSE)构成的FCSE_block模块作为编码器,目的在于增强网络提取室内场景特征的能力,改善特征图的质量;③将全卷积残差网络(fully convolutional residual networks,FCRN)构成的Trans模块作为解码器,将下采样后的特征图进行上采样,输出成原始图像尺寸大小的深度预测图,减少深度估计原本需要的巨大参数量.本文通过结合3种网络,发挥三者的优势,提高深度估计图的精确度.
1 网络结构提出
为捕获更多的全局信息,几乎所有的深度网络模型都是通过大量的普通卷积和池化操作来实现收敛,赋予高级神经元更大的感受野,但这样同时会使输入图的分辨率降低.而深度估计是一个回归问题,此类问题的期望输出是高分辨率的图像.因此,经过一系列下采样操作后得到的特征图必须是高质量的高分辨率图像,故笔者将全卷积网络融入到SENet[6]中,在训练网络的过程中,进行特征重标定,通过这一过程,学习全局信息,并且重点学习信息比较丰富的特征区域.同时,为了得到高分辨率的深度图,上采样也是个重要的过程,本文利用FCRN设计了Trans上采样模块,使用深度卷积网络,提高深度估计的精度.
1.1 网络结构
本文所提出的网络结构,如图1所示,图中Conv表示卷积层,Down表示下采样卷积层,FCSE1、FCSE2、FCSE3、FCSE4分别表示提取特征层1、提取特征层2、提取特征层3、提取特征层4,Trans表示FCRN上采样模块,⊕表示连接层.采用端到端的学习方式,该框架学习从彩色图像到相应深度图像的直接映射,采用编码器-解码器结构(encoder-decoder)的网络框架.encoder部分采用10个FCSE_block模块(即图1中的FCSE)和卷积层Conv以及Down1、Down2、Down3、Down4.decoder部分采用4个Trans上采样模块.Conv1包含一个尺寸为7×7、步长为2的卷积层,一个3×3的最大池化,一个Relu层. Down1、Down2、Down3、Down4和Conv2中的是 3×3、步长为1的卷积层,同时Conv2又包含一个Relu层.首先将输入图像送入一个卷积层,和一个最大池化层,特征图尺寸变为76×57×64.受文献[1]中up-projection模块结构的启发,将下采样模块的结构设计为Down1、FCSE1(FCSE_block×2)、Down2、FCSE2(FCSE_block×3)、Down3、FCSE3(FCSE_ block×4)、Down4、FCSE4(FCSE_block×1).FCSE_ block×2是指将特征图依次传入2个FCSE_block模块(如图2所示),FCSE1、FCSE2、FCSE3、FCSE4同理.各层输出参数如表1所示.本文所提出的深度模型中,所有的卷积层之后均连接着批量正则化层(batch normalization,BN层),文中为了简化而忽略.

图1 网络结构

图2 FCSE_block模块结构示意
表1 输出特征图的尺寸
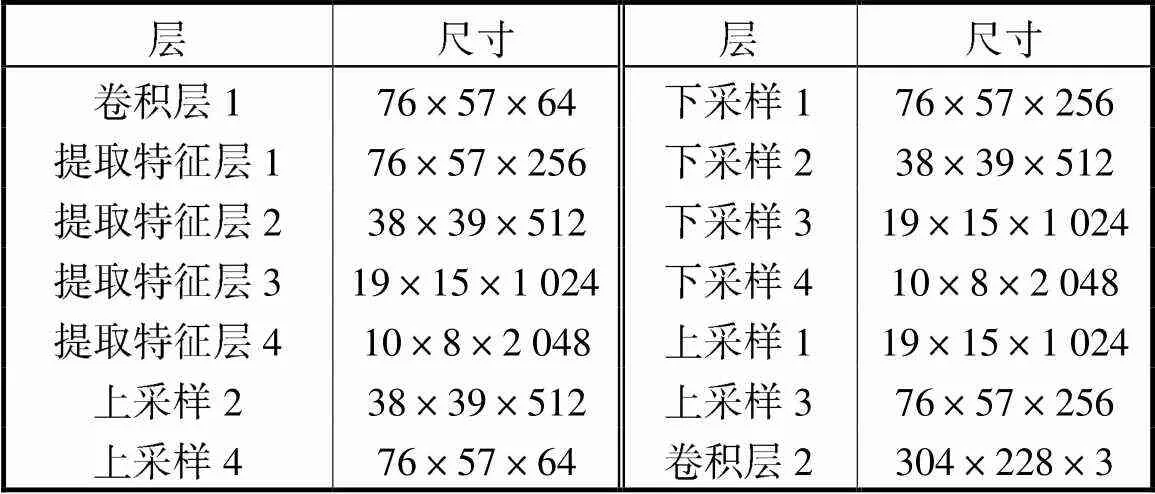
Tab.1 Sizes of output features
1.2 FCSE_block模块
深度神经网络中的每个卷积层含有大量的卷积核,会沿着输入信道表现出相邻空间的连接属性,并在局部感受野中融合空间与信道的像素信息.通过使用非线性激活函数和下采样操作等来连接一系列卷积层,获得全局感受野,可以有效解决室内场景缺乏显著视觉特征的问题.而普通的SENet模块由于其是通过全连接层进行降维,会大大提高输入网络参数.故笔者在SENet模块的基础上,将其中的全连接层进行适当地调整,合理地将卷积层替换全连接层,在提高特征图质量的同时减少训练所需的参数数量,实现端对端的学习方式.因此,本文设计了一个FCSE_block模块,如图2所示,在此结构中,全部使用卷积网络,所以该模块最后得到的是特征图而非固定长度的特征向量,从而实现端对端.

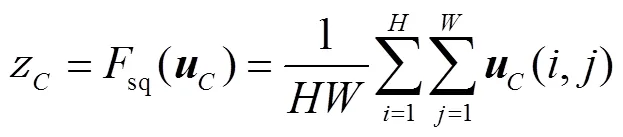
采用第2个步骤激励操作ex,以便利用压缩后的信息,这一操作目的是获取全部的信道依赖关系.要想实现这一目标,本文选用的函数必须具备两个特性:灵活性和学习非互斥的能力,因为必须确保多个信道均被强化.为了满足这些要求,本文在此选用一个简单的门函数以实现激励过程:

1.3 全卷积上采样Trans模块
当卷积网络应用于深度估计课题时,特征图像一定会通过上采样操作,如果仅使用简单的上采样模块,如双线性插值,又会丢失很多信息.为了改善这一情况,卷积神经网络的深度是至关重要的.大量的研究工作表明,VGG-16网络比较浅层的AlexNet的性能更为优越.但是,简单地叠加更多的层数,会出现梯度消失等严重问题,妨碍训练时的收敛.而ResNet通过引入跳层连接,解决了这一问题.深度残差网络不是直接地学习一些堆积层的底层映射,而是学习残差映射,这样原始映射可以通过具有“跳层连接”的前馈神经网络实现.另外,为了实现数据端对端的传输,接收任意尺寸的特征图像,以及提高室内深度估计的精度,故将全卷积网络与ResNet的跳层有机结合,用卷积层代替全连接层,在加深网络的同时,减少网络模型运行的时间,实现端到端的学习方式.因此本文使用FCRN构成Trans上采样模块,恢复特征图的信息.
从Trans1模块开始,就是本文网络的解码器部分.除了最后的卷积层Conv2(一个3×3的卷积层),其他所有在解码器中的都是残差层.前4层Trans1、Trans2、Trans3、Trans4中,第1层Trans1上采样模块对特征图以因数2进行上采样,将特征图的长和宽增加2倍.在解码器中上采样块Trans1有2个连续的卷积层用于残差计算,如图3(a)所示,其中,卷积[(3×3),1,*1]是指卷积核为3×3、步长为1、特征信道变为原来的1/2.Trans2以因数4进行上采样,有4个连续的卷积层用于残差计算,将特征图的长和宽增加4倍,特征信道变为原来的1/4. Trans3、Trans4同理.定义为
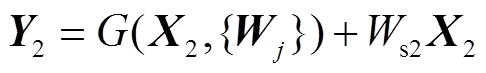
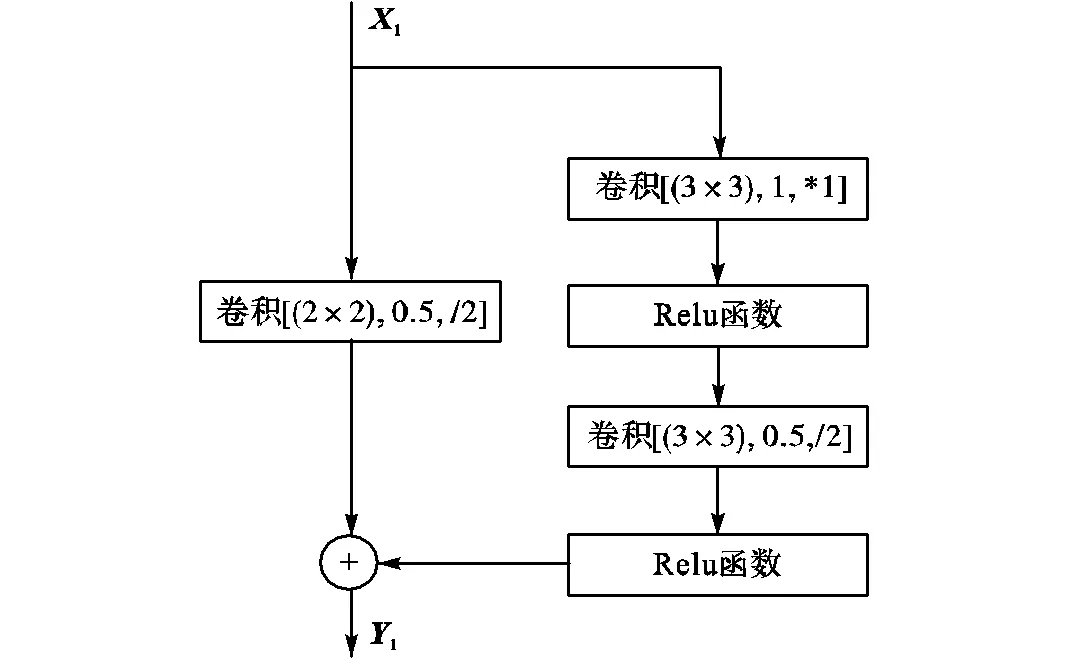
(a)Trans1模块
(b)Trans2、Trans3、Trans4模块
图3 Trans上采样模块结构示意
Fig.3 Diagram of the Trans module

1.4 损失函数
在回归问题上,一般用于优化训练效果的标准损失函数有3种:均方误差函数2(mean square error,MSE)、BerHu[7]函数、平均绝对值误差函数1(mean absolute error,MAE).一般默认选择2函数作为回归问题的优化函数,因为2对训练数据的异常值十分敏感,而且其惩罚体制比其他两种更为严格.但笔者经过大量实验,实验结果如表2所示,发现使用1函数作为损失函数,所产生的最终结果比其他两种更好,故选择1函数作为本文的默认损失函数.
表2 损失函数对比实验的深度估计结果

Tab.2 Depth estimation results of the loss function comparison experiment
2 实验及数据对比
2.1 数据集
本文的结果评估是基于最大RGB-D数据集之一的NYU Depth v2[8]数据集,该数据多用于室内深度估计,由于室内场景缺乏显著的局部和全局视觉特征,而且室内场景标签密集复杂.故而模型中使用了使用FCSE提取室内场景特征,卷积网络与ResNet进行了降低参数,提高精度处理.本文采用官方训测比,共464个场景,将249个场景用于训练,215个用于测试,并随机选择图像以减少同一场景的图像相似性.本文先对原始尺寸为640×480的图像进行下采样,大小为304×228.训练时,使用795对训练图像,将深度图下采样至适合输出的尺寸.测试时,使用654对图像.在前人的研究[9]中,数据增强有助于提高精度,同时可以避免过拟合.因此,本文使用相同的方法增加训练数据多样性:水平翻转、平面旋转、颜色抖动(亮度、对比度、饱和度).
2.2 训练细节
本文对深度学习模型的训练与测试实验都是基于pytorch环境,在一个具备12GB的TITAN Xp GPU的计算机上完成的,批尺寸为16,训练60代.网络的训练是基于RGB的输入,用对应的Ground Truth深度进行训练.下采样部分的权重是由ResNet-50模型初始化的,新增加的上采样部分的层经初始化为从具有零均值和0.01方差的正态分布中采样的随机滤波器,每层的学习速率为0.001,随着代的叠加,学习速率会逐渐减小,直到最优解出现,冲量为0.9.
2.3 评价标准
本文将预测深度图与Ground Truth(原图的深度标签)作对比,参照文献[10]使用4个评价指标比较提出的算法与现有方法的精度:平均相对误差、平均对数误差、均方根误差和阈值精度threshold(<1.25、<1.252、<1.253).阈值精度公式为

2.4 测试结果评价分析
表3将本文提出的方法与现有的方法在4个常用的评价标准上进行了比较.由表3可知,对于室内单目深度估计问题,本文的网络模型所计算出的精度相比于其他网络模型的是有更大的提升.又对网络结构的运行时间进行了实验,预测一张深度图的平均用时为21ms,与近期文献[1]相比具有明显优势.
表3 数据集NYU Depth v2的深度估计比较结果

Tab.3 Comparisons of different depth estimation methods on the NYU Depth v2 dataset
而且,通过消融实验的方法来论证所提出的FCSE_block和Trans模块的优势,为本文所提出的方法.先将4个常规的卷积层以及池化层和本文解码器部分构成的卷积神经网络称为方法1,再将本文编码器部分与4个普通的反卷积层组合一起的神经网络称为方法2.表4为本文消融实验的结果.
表4 消融实验深度估计结果

Tab.4 Depth estimation results of the ablation experiments
将表4中本文方法的实验结果与方法1的实验结果进行比较可得,在使用相同解码器结构的情况下,本文所使用的FCSE_block和Down作为编码器的主体部分构成的网络的方法要优于卷积层加最大池化的组合网络的方法1.同样地,将本文采用的方法与方法2的实验结果对比,可以发现在使用相同编码器结构的情况下,本文使用Trans作为解码器的主体部分所构成的卷积网络的方法比仅仅使用双线性插值作为上采样的神经网络的方法2更优.实验结果如图4所示.

图4 NYU Depth v2数据的实验结果
3 结 语
本文针对室内深度估计问题,设计了一种端对端传输的网络结构,将全卷积网络与SENet结合作为网络结构的编码器部分,该模块主要使用特征信道信息,获得全局感受野,提高了室内场景特征图的质量;将由全卷积网络与ResNet结合组成的Trans模块作为解码器部分,提高了网络从特征图恢复深度信息的能力,改善了前人研究中上采样深度信息大量损失的情况,实现了端到端的数据传输方式,大大缩短模型运行所需的时间;本文将3种网络结合,不仅简化现有的网络模型,减少繁琐的精化粗深度图的过程,而且实验结果表明,本文所提出的方法在NYU Depth v2数据集上取得了较为理想的效果.但仍有许多方面需要改进,如:设计一种网络模型使其对室内及户外场景具有普适性,找出深度预测图与深度之间的具体联系;实现深度测量的实时性等.
[1] Laina I,Rupprecht C,Belagiannis V,et al. Deeper depth prediction with fully convolutional residual networks[C]// 2016 4th International Conference on 3D Vision. Stanford,CA,USA,2016:239-248.
[2] Dharmasiri T,Spek A,Drummond T. Joint prediction of depths,normals and surface curvature from RGB images using CNNs[C]// 2017 IEEE International Conference on Intelligent Robots and Systems. Vancouver,BC,Canada,2017:1505-1512.
[3] Fu H,Gong M,Wang C H,et al. Deep ordinal regression network for monocular depth estimation[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA,2018:2002-2011.
[4] Shelhamer E,Long J,Darrell T. Fully convolutional networks for semantic segmentation[J]. IEEE Transac-tions on Pattern Analysis and Machine Intelligence,2017(39):640-651.
[5] He K M,Zhang X Y,Ren S Q,et al. Deep residual learning for image recognition[C]//2016 IEEE Confer-ence on Computer Vision & Pattern Recognition. Las Vegas,NV,USA,2016:770-778.
[6] Hu J,Shen L,Albanie S,et al. Squeeze-and-excitation networks[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA,2018:7132-7141.
[7] Owen A B. A robust hybrid of lasso and ridge regression[J]. Contemporary Mathematics,2007(443):59-71.
[8] Silberman N,Hoiem D,Kohli P,et al. Indoor segmentation and support inference from RGBD images[C]// 2012 IEEE European Conference on Computer Vision. Florence,Italy,2012:746-760.
[9] Eigen D,Puhrsch C,Fergus R. Depth map prediction from a single image using a multi-scale deep network [C]// 2014 Conference and Workshop on Neural Information Processing Systems. Montreal,Canada,2014:2366-2374.
[10] Hu J,Ozay M,Zhang Y,et al. Revisiting single image depth estimation:Toward higher resolution maps with accurate object boundaries[C]//. Waikoloa Village,HI,USA,2019:1043-1051.
[11] Liu F,Shen C,Lin G. Deep convolutional neural fields for depth estimation from a single image[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA,USA,2015:5162-5170.
[12] Xu D,Ricci E,Ouyang W,et al. Multi-scale continuous crfs as sequential deep networks for monocular depth estimation[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA,2017:161-169.
[13] Zhang Z,Xu C,Yang J,Gao J,et al. Progressive hard-mining network for monocular depth estimation [J],IEEE Transactions on Image Processing,2018,27(8):3691-3702.
[14] Liu J,Wang Y,Li Y,et al. Collaborative deconvolutional neural networks for joint depth estimation and semantic segmentation[J]. IEEE Transactions on Neural Networks and Learning Systems,2018,29(11):5655-5666.
An Improved Indoor Depth Estimation Method Using Convolutional Neural Networks
Liang Yu,Zhang Jinming,Zhang Wei
(School of Microelectronics,Tianjin University,Tianjin 300072,China)
There exists a general lack of significant local or global features for the indoor depth estimation of a single image. To address this,an encoder-decoder structure based on multiple networks(full convolutional networks (FCN),SENet and ResNet)was proposed. This network adopted an end-to-end learning framework to construct the model. First,the fully convolutional squeeze-and-excitation net(FCSE_block)module,consisting of the fully con-volutional networks and SENet,was used as the encoder. The global receptive field was obtained by channel informa-tion to improve accuracy of the feature map,and the fully connected layers were replaced by the convolutional layers to reduce the network parameters. Then the up-sampling module composed of fully convolutional networks and Res-Net was used as the decoder. The decoder network was deepened,and accuracy of the depth map was improved using ResNet’s characteristic,skip-connection. The convolutional network and ResNet were combined to realize an end-to-end learning framework. Finally,the1loss function was used to optimize the proposed network architecture. Under the test of the open data set NYU Depth v2,the experimental results showed that,compared with other existing mo-nocular depth estimation methods,the proposed network model not only simplified the tedious process of refinement of rough maps,but also had higher accuracy in predicting depth maps. The improvement in threshold accuracy was not less than 0.5%. Moreover,the average running time of the network structure was 21ms,which laid the founda-tion for realizing real-time performance and had certain theoretical research and practical application value.
computer vision;convolutional neural network;indoor depth estimation;monocular image;deep learning
the National Key Research and Development Program(No.2018YFC0807605-4).
TP391
A
0493-2137(2020)08-0840-07
10.11784/tdxbz201906008
2019-06-04;
2019-08-12.
梁 煜(1975— ),男,博士,副教授,liangyu@tju.edu.cn.Email:m_bigm@tju.edu.cn
张 为,tjuzhangwei@tju.edu.cn.
国家重点研发计划资助项目(2018YFC0807605-4).
(责任编辑:王晓燕)
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
计算机应用(2019年3期)2019-07-31 12:14:01
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
