
基于经验模态分解与深度森林的液压泵健康评估
2020-06-03 00:43:34李志远黄亦翔刘成良李彦明
机械与电子 2020年5期
李志远,黄亦翔,刘成良,李彦明,贡 亮
(上海交通大学机械系统与振动国家重点实验室,上海 200240)
0 引言
液压泵是液压系统的主要动力元件,被广泛应用于各种机械设备中。液压泵的健康状态对于液压系统的正常工作具有重要的影响,而设备运行的稳定性、可靠性和液压系统密切相关[1]。掌握液压泵健康状态也有助于视情况进行检测维修,提高经济效益。因此对液压泵进行健康状态的准确评估,对工程设备具有重要的现实意义。
目前,液压泵的健康评估主要是基于设备的振动信号进行分析的,而其他信号,比如压力、流量等信号仅仅是作为系统状态的一个参考指标,没有直接用于健康评估。Ding等[2]基于逻辑回归和Softmax回归,采集液压泵实时振动信号,进行液压泵的实时健康监测和故障诊断。Hancock等[3]基于小波包对叶片泵振动信号进行特征提取,使用自适应神经模糊推理系统进行泵的健康状态分类。Gao等[4]运用小波分析技术进行柱塞泵的实时健康诊断。郑直等[5]运用小波包技术对轴向柱塞泵振动信号进行分解重构,使用Hilbert包络解调技术提取故障信号,最终利用信息熵方法进行健康状态评估。路广勋等[6]使用云重心法进行液压泵健康状态评估。王浩任等[7]使用小波包提取柱塞泵振动信号特征,通过拉普拉斯特征映射方法实现柱塞泵健康评估。
综上所述,对于液压泵的健康评估主要采用振动信号,或者振动信号结合其他信号进行分析,而液压泵的动态压力信号,和振动信号一样,包含了丰富的状态信息,可以直接用于液压泵的健康评估中。
经验模态分解(EMD)用于处理非线性、非平稳信号,是一种自适应信号时频处理方法[8]。经过EMD分解,将原始信号分解成一组有限个本征模态函数(IMF)和一个残余分量,各IMF分量包含了原始信号不同时间尺度的局部特征,实现了非平稳信号的平稳化。相对于传统的傅里叶变换和小波变换,EMD方法具有自适应性时频分析的特性,可以很好地避免噪声信号干扰。
深度森林算法[9](Deep Forest)是周志华教授和冯霁博士提出的一种基于树的深度模型,其中提出的多粒度级联森林(gcForest)方法是一种新的决策树集成方法,是传统森林模型在广度和深度上的集成,其效果可以与深度神经网络相媲美,同时具有训练速度快、参数量少、效率高等优点。
本文提出一种基于EMD和深度森林的液压泵健康评估方法。首先,通过不同工作时间下液压泵的性能试验,采集液压泵出口压力信号。然后,使用经验模态分解将压力信号分解为一组本征模态函数(IMF),计算各IMF的能量,结合典型时域特征构成信号的特征向量。采用深度森林的方法进行健康状态监测的分类。
1 液压泵健康评估流程
随着液压泵工作时间的推移,其健康状态逐渐恶化。随着液压泵的泄露量越来越大,以及压力损失的增大,其出口压力会有显著的变换,压力变得更加不稳定。这说明不同工作时间下的液压泵出口压力包含了丰富的健康状态特征指标。因此,在试验环境下采集液压泵出口压力信号,经数据清洗和时域分割之后进行特征提取,得到对应的特征空间,最后通过深度森林评估器进行健康状态的分类评估。液压泵健康评估流程如图1所示。

图1 液压泵健康评估流程
2 EMD方法
经验模态分解可以将复杂信号分解成若干个不同频率的本征模态函数分量之和,是一种自适应的信号分析方法。其中本征模态函数必须满足:在整个时间范围内,极值点(极大值和极小值)的数目和过零点的数目必须相等或者相差不超过1个;在任意时刻,由极大值形成的上包络线和极小值形成的下包络线的均值为零。
EMD方法是通过一种称为"筛分"的过程实现对信号的分解,将原始信号分解为若干个IMF和一个残余分量rk(t),对给定信号x(t),其过程如下[10]:
a.找到x(t)的所有局部极大值并用三次样条插值拟合形成上包络线s+(t) ,找到x(t)的所有局部极小值并用三次样条插值拟合形成下包络线s-(t)。
b.计算第i次迭代的上下包络线的均值mk,i(t)为
(1)
c.用x(t)减去上下包络线的均值,得到剩余信号ck(t)为
ck(t)=x(t)-mk,i(t)
(2)
判断此时的ck(t)是否满足IMF的2个条件,若不满足,则跳过步骤d和步骤e,把ck(t)作为待处理信号,从步骤a继续进行迭代。
d.若ck(t)满足IMF的2个条件,此时的ck(t)为第k个IMF分量,得到新的剩余信号rk(t)为
rk(t)=rk-1(t)-ck(t)
(3)
其中,r0(t)=x(t)。
e.当rk(t)为单调函数或者ck(t)小于某一阈值时,循环终止。否则把rk(t)作为待处理信号,从步骤a继续进行迭代。
此时,原始信号x(t)可以表示为n个IMF分量与残余分量之和,即
(4)
c1(t),c2(t),…,cn(t)分别为各阶IMF分量,代表了信号从高到低不同频段的成分,包含了原信号不同时间尺度的局部特征。rn(t)为信号的残余分量,代表信号的平均趋势。
3 深度森林算法
近年来深度学习在各个领域取得了突飞猛进的发展,而几乎所有的深度学习的应用都是建立在深度神经网络(DNNs)的基础上。然而,深度神经网络仍然存在很多问题。比如超参数过多、结构复杂、训练困难、需要大量数据进行训练以及模型难以解释等问题。周志华等提出的多粒度级联森林(gcForest)算法,是一种非神经网络的深度模型。其超参数少,易于训练,可用于不同大小的数据集。
3.1 随机森林
随机森林是由Breiman等[11]提出的机器学习算法,随机森林算法以决策树为基学习器构建Bagging集成,是Bagging算法的扩展变体,在决策树的生成过程中引入了随机属性选择。随机森林的结构如图2所示。
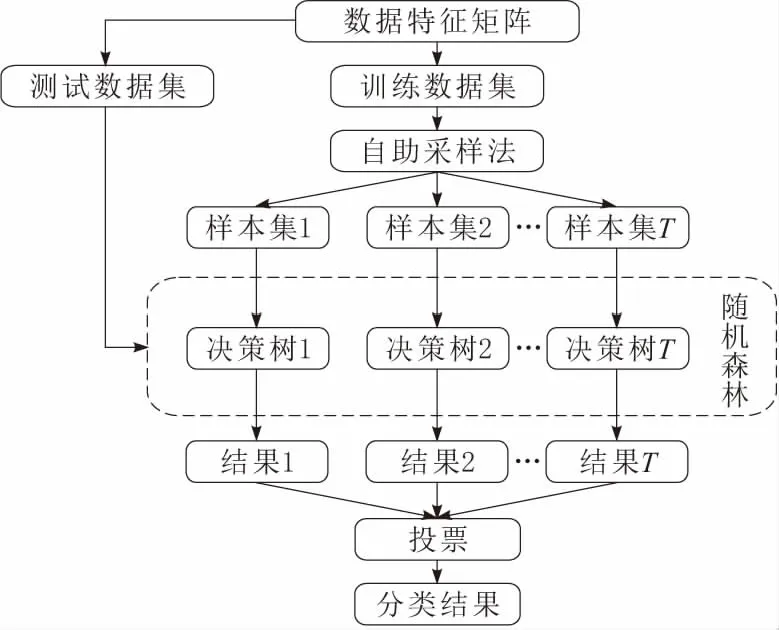
图2 随机森林结构
随机森林主要有以下几个步骤。
a.设要构建的森林规模大小为T。利用Bagging算法对训练样本集D进行重采样生成T个训练样本集D1,D2,…,DT。
b.对每个训练样本集Di(i=1,2,…,T)生成1个决策树,一共生成T个决策树。单个决策树的生长过程如下:对决策树的每个结点,先从该结点的属性集合(假定该结点有d个特征属性)中随机选择1个包含k个属性(k≪d)的集合作为备选特征,然后按照结点不纯度最小的原则从这个子集中选择1个最优特征分裂生长。重复上述操作,不进行剪枝操作,使决策树充分生长,最终使每个结点的不纯度达到最小。一般情况推荐k值取值为[9]
k=log2d
(5)
c.步骤b生成的T个决策树构成随机森林,各个决策树分别对预测集进行分类预测,分类结果进行简单投票法得到最终的结果,即得票数最多的类为预测集的最终分类结果。随机森林的投票公式为
(6)
H(x)为组合分类模型;hi为单个决策树分类器;I(·)为示性函数;Y为输出变量。
3.2 多粒度级联森林
gcForest算法主要包括多粒度扫描(Multi-Grained Scanning)和级联森林结构(Cascade Forest Structure)2个部分。
3.2.1 多粒度扫描
借鉴DNNs在处理特征关系的启发,以及类似在语音等时序信号的滑动窗口的技巧,gcForest使用多粒度扫描结构。该结构使用多种不同大小的窗口进行采样,从而获取更多差异性的子样本,然后分别使用随机森林和完全随机森林进行训练,使用输出的类别向量进行拼接得到最终的转换特征。多粒度扫描的结构如图3所示。

图3 多粒度扫描结构
使用一个滑动窗口为例,介绍具体过程。原始输入特征为d维特征向量,设使用的滑动窗口大小为k维(一般可取k为d/4,d/8,d/16等),滑动步长为s(一般取1)。则通过滑动窗口可以得到的特征子样本实例个数为
(7)
然后对每个子样本实例进行训练,分别使用普通随机森林和完全随机森林2种模型进行训练。每个森林模型训练后可以得到一个c维(c为类别数)类别概率向量,一共得到2m个类别概率向量。最后将这些类别向量拼接起来,即可以得到最终的对应于原始d维特征向量的2×m×c维转换特征向量。
3.2.2 级联森林
DNNs的表示学习依赖于特征的逐层处理,由此启发,gcForest采用和深度神经网络类似的层级结构,使用级联森林,接收森林的前一层作为输入,输出作为森林的下一层输入。级联森林的结构如图4所示。
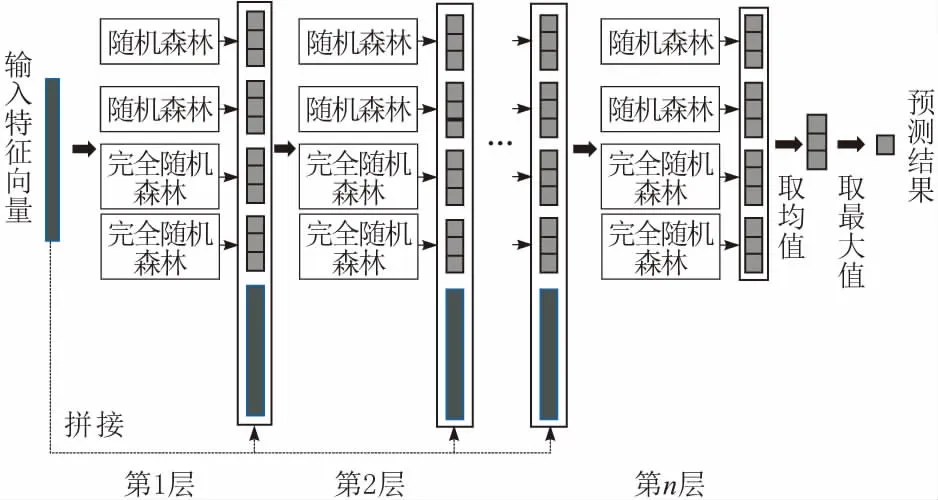
图4 级联森林结构
将上述多粒度扫描过程得到的最终转换特征向量作为级联森林的输入,并和每层随机森林的输出的类别向量结果进行拼接作为下一层的输入,依次进行有监督学习。由图4可以看出,该结构的每一层由多个普通随机森林和完全随机森林组成,同时每个随机森林又是多个决策树组成,因此这种结构是一种“集成的集成”。每层2种不同的随机森林增加了模型集成的多样性,多个森林的结合可以充分利用特征的差异和互补,更好地表征特征信息。

由上述级联森林结构可知,模型的集合能力较强,有发生过拟合的风险,因此在级联森林的每一层的每个森林的训练过程中均采用了k折交叉验证。具体来说,每个样本实例将作为k-1次训练数据、k-1次测试数据,最终会产生k-1个结果类别向量,将这些类别向量的平均值作为森林的输出结果,输出给下一级的级联结构。此外,该级联结构还可以自动确定训练层数,具体方法如下:取一定比例的样本作为训练集,其余的作为验证集。使用训练集在每层级联结构上进行训练,同时在新的级联层训练完成之后,使用验证集评估整个级联的性能,如果该层相较于前层性能有所提升,则继续进行训练,如果没有明显的性能提升,则训练过程终止,并确定前一层为最优训练层数。因此和深度神经网络层数固定不同,深度森林可以自适应地选取网络层数,适用于不同规模的数据集。
4 试验方案与数据预处理
4.1 试验方案
液压泵测试试验系统如图5所示,试验系统参考GB/T 23253—2009 《液压传动 电控液压泵 性能试验方法》国家标准进行搭建,试验装置主要包括电机、待测液压泵、溢流阀、油箱、压力传感器等,试验使用的液压泵为川崎K3V系列斜盘式轴向柱塞泵。压力传感器用于记录泵1出口压力值,采样频率为12.5 kHz,试验液压泵转速为2 200 r/min。
如表1所示,为液压泵的实际运行时间与健康状态简记代号。一共有3种不同健康状态的液压泵,分别是:全新的1#泵;使用2 000 h的2#泵;使用3 500 h即将报废的3#泵。
试验选取工作时间3 000 h以上的3#柱塞泵进行拆解,各个部件的磨损情况如图6所示。测量可知柱塞磨损量为0.06 mm,斜盘支撑座的最大磨损量为1.24 mm,最小磨损量为0.22 mm。同时可以看到,斜盘支撑座位于高压区的镀锌层磨损严重,而位于低压区的镀锌层则磨损较少。 所以由于不同工况的作用,同一部件在不同位置的磨损量也不同。

图5 液压泵测试试验系统

表1 液压泵简记代号

图6 柱塞泵部件磨损情况
4.2 数据处理
每种健康状态的液压泵试验时间约为800 s,采集压力信号样本点超过1 000万。各个液压泵的压力信号图像如图7所示。取1#泵、2#泵、3#泵数据均较平稳的一段:160~480 s,共320 s即400万数据点。每隔10 000个点作为数据样本,每种健康状态400个样本,3种健康状态一共1 200个样本。每种健康状态获取280个训练集样本,120个测试集样本,共获取840个训练样本,360个测试样本。

图7 各液压泵压力信号图像
5 液压泵健康状态评估
5.1 压力信号特征提取
分别对3种健康状态的液压泵的动态压力信号数据样本进行EMD分解,得到各个样本IMF分量IMFp={c1,c2,…,cNp},设其IMF分量个数分别为N1,N2,…,Np,取Nmin=min(N1,N2,…,Np)=8,对各组IMF分量进行截取使得IMFp={c1,c2,…,cNmin},计算截取部分占所有IMF分量能量的比例,计算各个IMF分量的能量:

(8)
计算的结果显示,绝大部分(97%以上)样本的能量占比达到98%以上,因此截取的前Nmin阶分量包含了信号的绝大部分能量,满足特征提取要求。
对计算出来的各个IMF分量分别提取特征,包括均值、峰值、峰峰值、整流平均值、均方根值、标准差、波形因子、峰值因子、脉冲因子、裕度因子、峭度、偏度共12维。结合直接计算得到的原始信号的12维时域特征一共108维特征,特征向量采用Z-Score标准化方法进行标准化处理为
(9)
将所有特征向量按列构成最终的特征空间。
5.2 基于深度森林的健康状态分类
采用深度森林算法进行最后的健康状态分类,深度森林作为一种深度模型,相比深度学习来说,具有超参数少,易于调优等优点。
5.2.1 参数设置
深度森林的多粒度扫描阶段的超参数主要有森林数量、森林类型、决策树数量、滑动窗口大小以及节点分裂最小样本数等;级联森林阶段的超参数主要有森林数量、森林类型、决策树数量和节点分裂最小样本数。首先多粒度扫描和级联森林的森林类型均选为完全随机森林和随机森林的组合,然后选取多粒度扫描森林数量为4,级联森林决策树数量为500,再调整多粒度扫描的决策树数量,最后选择为100。按照经验选取滑动窗口大小为2,4和8。最后不断调整2部分的节点分裂最小样本数,选择多粒度扫描阶段为8,级联森林阶段为7。具体参数设置如表2所示。

表2 深度森林超参数设置
5.2.2 深度森林分类器的健康状态分类
基于深度森林分类器进行健康状态分类,使用上述确定的参数,同时使用MLP,SVM和KNN等传统机器学习算法进行对比。表3、表4和表5分别为1#泵、2#泵、3#泵的分类结果,分别使用召回率、精确率和F1分数等评价指标进行评价。表6为整体分类结果,分别使用准确率、精确率、召回率和F1分数等评价指标进行评价。

表3 1#泵分类结果
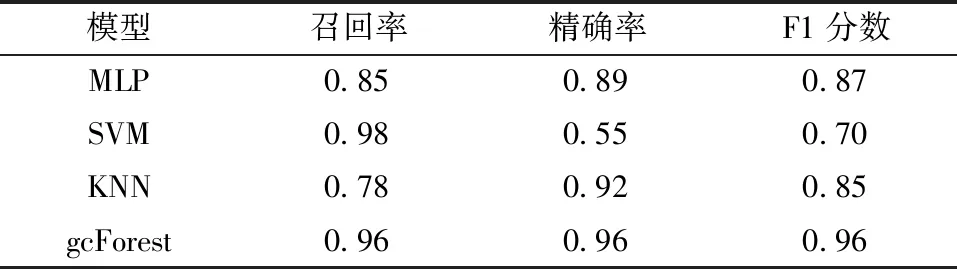
表4 2#泵分类结果

表5 3#泵分类结果

表6 整体分类结果
从分类结果可以看出,使用gcForest算法各个泵的F1分数均高于其余3种传统机器学习算法。如图8所示,将测试样本预测标签和真实标签进行对比,结果表明健康状态分类准确率为97%,明显高于传统机器学习算法。
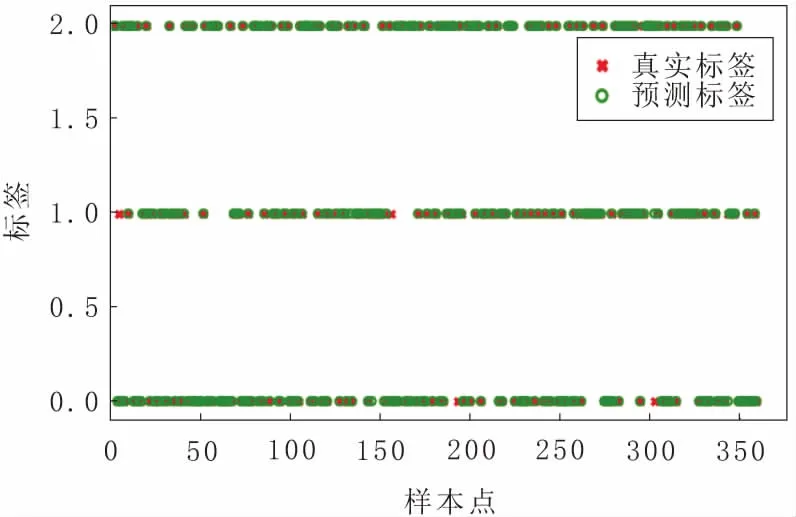
图8 真实类别与预测类别对比
6 结束语
针对液压泵健康诊断技术进行了研究,提出了一种基于经验模态分解和深度森林的健康评估方法,将深度森林算法引入液压泵健康评估领域。通过分析泵出口压力信号,通过经验模态分解进行自适应提取压力信号特征,将得到的特征向量使用深度森林算法进行分类评估,并和传统机器学习算法进行对比。试验结果表明,所提方法准确率较高,可有效提高液压泵健康状态评估的准确率,可以用来作为液压泵健康评估的方法。
猜你喜欢
现代制造技术与装备(2021年9期)2021-04-03 13:44:40
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
通信电源技术(2018年5期)2018-08-23 01:15:34
电子制作(2016年15期)2017-01-15 13:39:09
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
中国修船(2014年5期)2014-12-18 09:03:08
电测与仪表(2014年1期)2014-04-04 12:00:34
