
三维地质建模精度影响因素及质量控制
2020-06-02 00:03:54姬广军张永波朱吉祥
桂林理工大学学报 2020年1期
姬广军,张永波,朱吉祥,陆 琰
(中国地质科学院 水文地质环境地质研究所,石家庄 050061)
地质工作进行到一定程度,三维地质建模的精度对后期空间分析、储量计算、数值模拟等地质应用的影响就显得尤为重要,因而对三维地质建模精度影响因素及模型质量控制研究具有较强的现实意义。三维地质建模是定量化研究地下地质信息的有利工具,广泛应用于展示和分析地下地质结构[1]。高精度三维地质模型既是空间分析、数值模拟、资源量计算等地质应用的重要保障,又是识别与加深认识地下地质现象的重要手段,它的进步将进一步推动地球科学的发展[2-3]。
三维地质模型应客观地反映地质现象的几何特征、空间接触关系及地质体内部各属性的变化规律等信息。 但是受地下结构复杂[4]、数据难以获取[5]、计算机技术[6]等现实情况的束缚,地质学家需要借助其专业背景知识添加一系列的控制信息(如虚拟钻孔、剖面等)[7],因此其在一定程度上是地质学家内心地质概况的主观性表达[8]。 此外,虽然计算机、数学、统计学等学科的成熟与发展可以缓解模型构建、可视化等方面的困难,但仅靠先进的工具并不一定能够构建出客观反映地质现象的模型,因为地质专家始终在建模过程中起到举足轻重的作用,控制着最终的三维模型[7],此类主观性模型难免与实际地质状况有所偏差[6,9]。
三维地质建模的精度包括构造建模和属性建模的精度。构造建模包括断层网模型、地层模型和地质体模型,反映断层间、地层间以及断层与地层间的宏观拓扑关系和几何形态[10],为属性模型提供约束框架[3],其精度是由其客观表达地质对象的空间分布及拓扑关系的能力决定。属性模型是空间分析、数值模拟、资源开发等地质应用的基础,用于反映地质体内部各种属性的非均质性,其精度主要取决于其对地质体内部非均质性的客观表达能力。本文系统地阐述了影响三维地质建模精度的因素,分析了当前三维地质建模的质量控制方法,并对区域性三维地质建模质量控制方法的方向进行预测。
1 三维地质建模精度影响因素
1.1 建模数据
(1)数据的精度。 三维地质建模可用的数据包括钻孔、剖面图、地质图、地球物理数据、遥感影像、现场调查数据、DEM、地球化学、等值线等数据,这些数据具有多精度、多尺度、多来源[11]、多分辨率、多维度等特征[12-13],它们对三维地质建模产生的影响不同(表1)。
(2)数据的丰富程度、分布状况及代表性。 数据的丰富程度、分布状况及其代表性是相对而言的: 对于地质构造简单的地层,少量数据即可控制模型精度; 但是对于复杂地质结构地区,数据的丰富程度和分布状况及代表性则对模型精度影响较大[14]。 数据越丰富、分布越均匀、代表性越强时,三维地质模型的控制性数据越多,地质体形态或属性的表达更客观,模型的精度就愈高。
1.2 建模方法
根据建模使用的数据源可分为基于钻孔、剖面、离散点[11]或多源数据等多种建模方法。 建模方法对三维地质建模的影响主要表现为地质模型信息(包括地质结构和属性)偏移与失真,各种建模方法及其影响因素见表2。
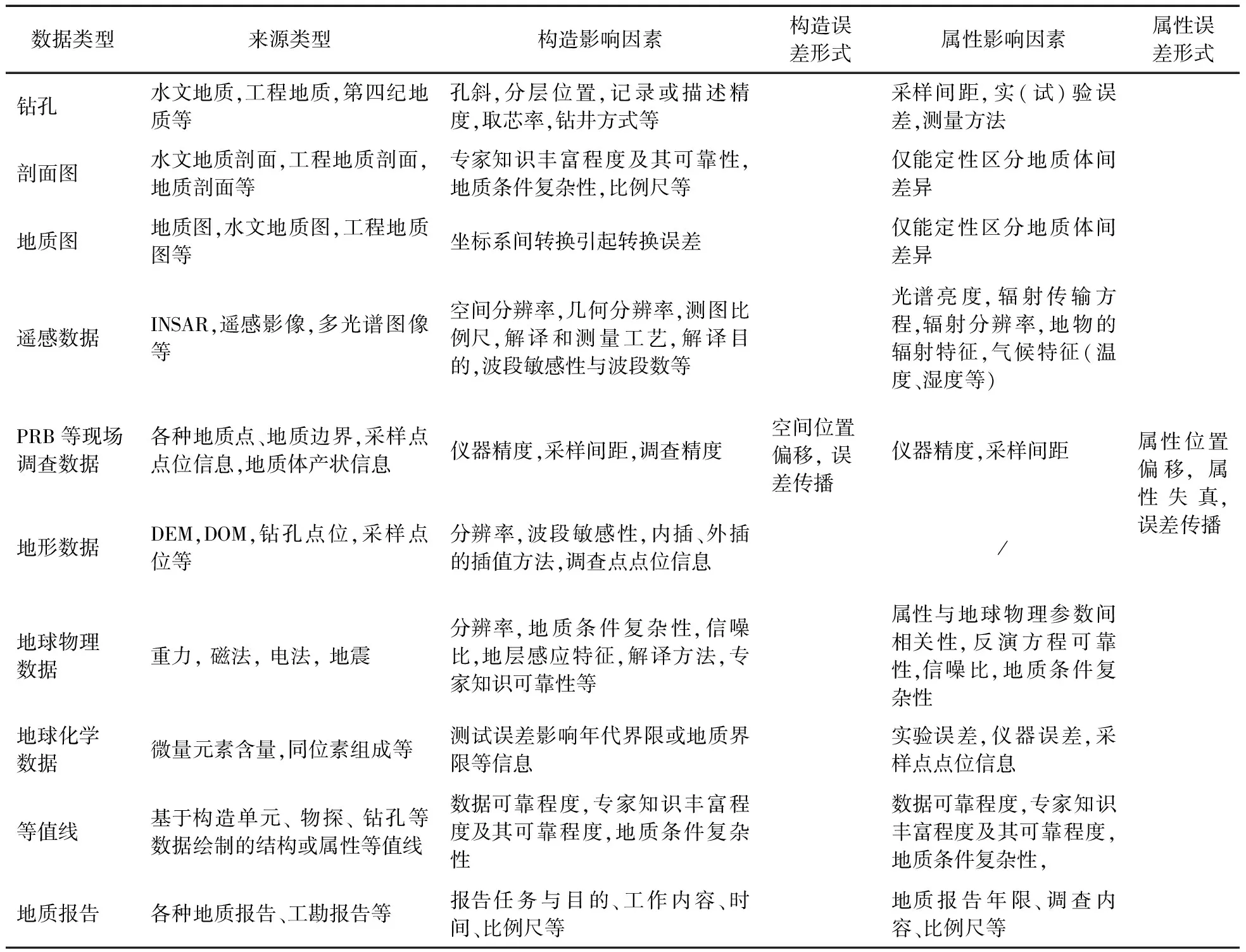
表1 可能引起误差的数据类型及影响因素Table 1 Possible error sources of different data types and influence factors

表2 不同建模方法的精度影响因素Table 2 Influence factors of different modeling methods
1.3 插值方法
(1)结构建模。在离散空间数据条件下,地质界面主要根据离散的采样点采用逼近样条曲面和插值样条曲面两种方法构建。逼近样条曲面不经过离散点,插值样条曲面则经过离散点。目前常用的逼近样条曲面的插值方法有B-Spline插值、NURBS、Bezier-NURBS、最小曲率插值(MCI)、加权最小二乘拟合法等,虽然它们可以极大限度地逼近实际的地质界面,并取得较好的光滑效果,但是其在控制点处无法保证地层界面的可靠性,也难以维持点间未知区域的精度。插值样条曲面主要包括Kriging、IDW、DSI、RBF、MCI、最邻近点(NNI)、改进谢别德(MSMI)等[15],它们能够保证控制点精度,但在控制点间未知区域的精度却得不到保障。 图1为同一组数据下,不同插值方法的插值效果。 其中距离反比插值(IDW)生成的层面有较明显的“牛眼”结构,局部多项式插值(LPI)生成的层面光滑程度最高。
目前大多数的插值方法只能处理单值面,对于倒转褶皱、逆断层等复杂情况下地层界面需要特殊处理;对于尖灭或界面分叉等复杂地质现象,插值操作通常需要人机交互才能完成。
(2)属性建模。三维构造模型为属性模型提供框架约束。网格化需在地层模型和断层模型约束下进行,该过程中网格剖分方法(比例型、剥蚀型及超覆型)[16](图2)、网格大小、网格定向[17]、网格形状及构造模型的精度等因素通过影响地质体空间分布、属性空间分布、格网剖分的精细程度及属性分布规律进而影响属性模型的精度;而采样数据、插值方法、训练图像等通过影响属性数据空间位置、分布进而影响属性模型精度。
目前常用的属性建模包括确定性建模和随机建模两种,确定性建模是指试图从具有确定性资料的控制点出发,推测出点间确定的、唯一的属性参数的方法;随机建模是指以已知的信息为基础,应用随机函数理论、随机模拟方法,产生可选的、等概率的地质体模型的方法[18]。 确定性建模中最常用的是克里金系列方法,其虽然满足无偏、最优线性估计,但都存在一定程度的平滑效应,难以精确地刻画属性数据在空间中的非均质性;常用的随机建模方法包括序贯高斯模拟、序贯指示模拟、马尔可夫随机域等,其可以重现属性的离散性与波动性,经过反复模拟则可以得到任意多个模拟实现。两者均能在观测点上保证属性数据的精度,但是点间未知区域精度仍然得不到保证,且它们都需要满足一定的前提条件,如克里金系列和基于变差函数的随机建模方法大都要求采样数据满足高斯域概率分布,否则会产生较大误差。而多点地质统计学中,训练图像和条件概率分布函数(与模拟随机路径相关)也是影响属性模型精度的重要因素,样本数据足够大时提取的训练图像虽具有一定的可靠性,但其仍不能完全反映属性的实际空间变化特征。

图2 同一地层下不同的格网剖分方案Fig.2 Different gridding methods in the same formation
受数值模拟软件的网格节点数量限制[19],地质模型可能需要进行一定程度的等效粗化,把精细网格模型转化成相对粗疏的网格模型,相应的属性数据也就需要粗化,且网格粗化和属性粗化中都需要遵循一定的粗化原则,难免会产生各种误差,从而引起属性失真,目前常用的属性粗化方法主要包括简单平均法和加权平均法[20-21]。
1.4 地质现象的复杂性与随机性
地质体是经过多期次、多体制的构造运动形成的,是高度复杂的综合整体[22]。 由于人类获取地下信息的能力有限,地质结构的复杂性与随机性对三维地质建模的影响体现在数据难以获取与辨别、计算机难以表达以及专家知识难以描述三个方面。
(1)获取地下数据的主要方式为钻探和地球物理方法(包括重、磁、电、震及其衍生方法,如AEM等)。 钻孔资料可揭示地下重要的地质构造信息,但是钻孔获取的代价较高,只能作为采样点处的控制信息; 地球物理数据中地震数据、AEM、电磁数据、测井数据等方法是获取地质构造的常用方法,但是每种方法都有各自的局限性,且具有多解性,如地震数据只有遇到波阻抗界面时才能被识别出来、重力数据仅对密度界面有所反映、磁法数据仅对铁磁性异常有所反映、电法数据仅对介质的导电性(含水性)等有所反映。 当地质结构复杂性较高时,地震数据较难反映真实的地下构造,并可能表现出一定程度的剖面漂移,目前没有成熟的正、反演算法能够无损表达地下结构。
(2)当存在倒转褶皱、逆断层和盐丘等多值界面与尖灭、复杂断层网等拓扑关系复杂的地质现象时,计算机表达相对困难。另外,复杂的地质构造会影响网格的生成及其质量,进而增加属性插值的难度、影响属性模型的建立。
(3)数据较少、结构复杂等情况下,专业人员难以刻画其内部复杂结构,仅能表示其宏观构造。
1.5 计算机限制
计算机限制包括硬件和软件方面,硬件限制包括CPU、存储结构、图形处理器等,软件限制包括数据管理软件、三维地质建模软件等。海量数据是三维地质建模的主要特点之一,受计算机硬件成本、性能等方面限制。目前,三维地质建模技术难以存储海量的数据记录,并且数据的管理与维护相对困难[23]。此外,目前绝大多数三维建模软件还难以支撑海量数据下三维地质模型构建。对三维格网模型来说,计算机可承受的网格数量有限,格网模型仅在研究区域较小的情况下才可以较优地表达地质体内部的非均质性。
1.6 地质专家与建模人员影响
地质专家以其专业知识背景为基础,借助现有的各种地质资料,对无采样点处的地质状况进行推测,这种推测结果加入了巨量的专家经验,且不同专家推测的结果可能不同[13],因而由此构建的三维地质模型可能与实际状况有偏差[14]。另外,专家推测可能忽略较小的地质构造,并进行了一些必要的模型简化(如孔间地层对比),反映的地质构造可能与实际有偏差。
建模人员对三维地质模型的精度具有一定程度的影响。 建模人员的软件操作水平、地质背景知识、对复杂构造的构建能力及对研究区的地质情况的掌握水平等都是影响三维地质建模精度的因素。
2 三维地质建模的质量控制
受上述各种因素的影响,精准地构建三维地质模型仍有相当大的挑战性,国内外研究人员提出了各种质量控制方法,在一定程度上丰富了三维地质建模的质量控制理论。
2.1 构造模型的控制
2.1.1 断层模型控制 一方面,断层破坏了地质体的连续性,改变了地层数据的原始分布格局,增加了地质结构的复杂性[24];另一方面,数据的稀疏使得断层的空间展布状况难以确定。目前主要包括两种断层控制策略。第一种为改进断层构建方法,Pillar方法利用2~5个垂向控制点描述断层形态(图3),但其难以刻画复杂产状和断层相互交叉(X型、Y型等)的情形[3];基于剖面等相关数据,徽章构造法、倾斜剪切构造法或断层弯曲褶皱理论法等可构建断层几何形态的数学模型,但是该方式需要较多的、沿断层走向或倾向上断层面深度数据和其他数据;多平面拟合法利用断层产状信息及断点数据可构建局部断面平面方程[25],但该方法影响断面间的削截;基于离散曲面方法则可较灵活地构建断层模型,且可较精准地描述复杂断层模型及其网络[26],是较优的断层构建方式。第二种是数据控制断层形态,充分利用现有数据,包括剖面、钻孔、现场调查数据,地球物理数据,虚拟控制数据及多源数据整合等[27],进而控制断层的形态。

图3 利用控制点描述的断层形态Fig.3 Fault shape described by Pillar node
二叉树方法是构造模型中断层网表达的主要方式(图4),其既可以反映断层间的空间位置关系,又能揭示断层形成的先后关系[9],但断层网的快速更新较困难。李兆亮等[26]针对复杂断层网提出一种路径切割算法,可处理各种复杂断层相交情况,并方便断层网的快速更新,但其仍然需要一定程度的人工交互。实现断层网的快速更新及高自动化仍然是亟待解决的问题。
2.1.2 地层模型控制 地层模型是三维构造模型的重点与难点之一,由于地下数据的稀疏性与地质结构的复杂性,研究人员不得不想尽各种方法提高地层模型的质量,主要包括以下几种:
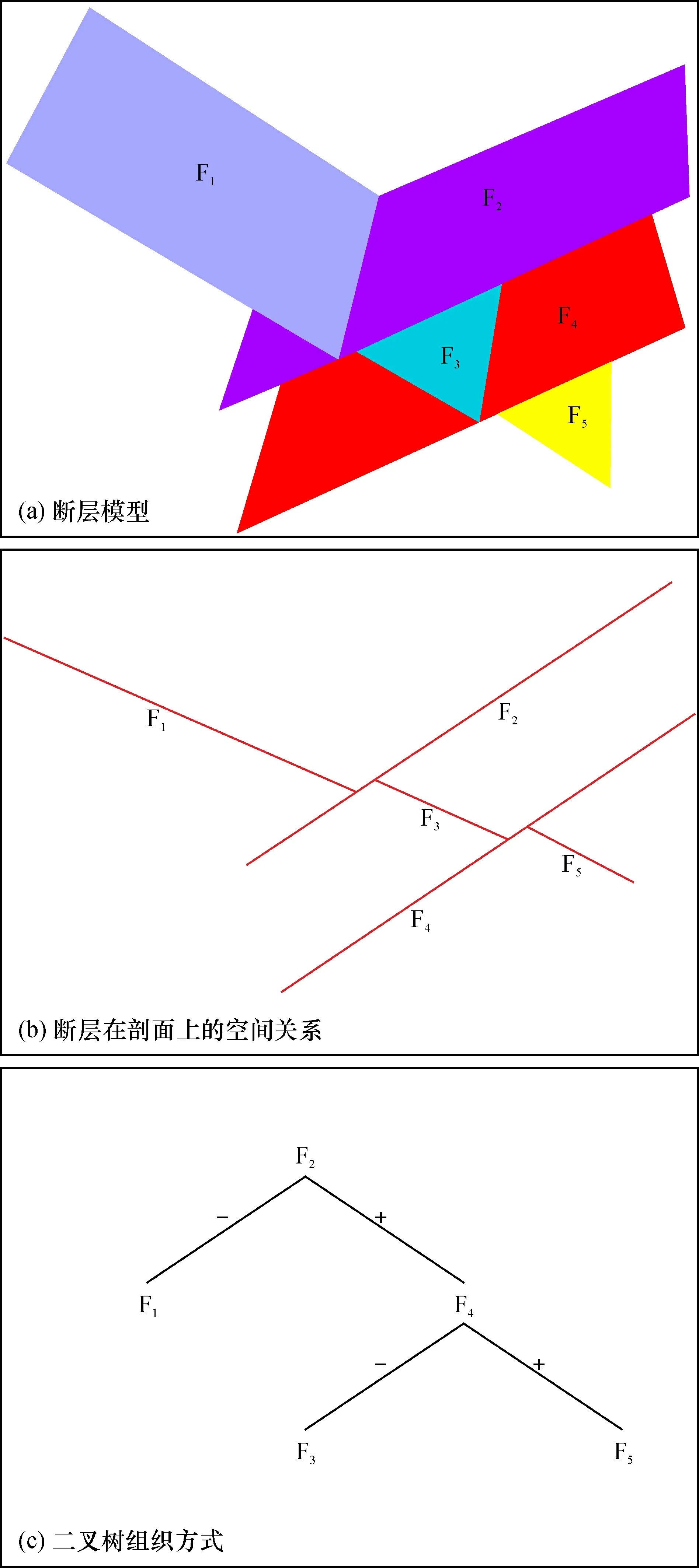
图4 断层网络二叉树组织方式Fig.4 Binary trees of faults network
(1)改进建模方法。 自三维地质建模技术提出以来,国内外推出了多种三维地质建模方法[28],在一定程度上推动了三维地质建模的发展。 早期的建模方法偏向于解决三维地质模型的构建,如基于平行剖面的建模方法[29],它们都有各自的适用范围,难以解决复杂情况下三维地质模型的构建; 近期的建模方法倾向于提高三维地质模型质量和构建复杂三维地质模型,适应较复杂地质条件情况下模型构建或整合多种建模方法的优点进而提高三维地质模型质量,如基于钻孔和交叉折剖面约束的建模方法[30]。 其中基于剖面的建模方法较明显,经历了基于平行剖面—基于含拓扑剖面[31]—基于交叉折剖面[32]—基于网状含拓扑剖面[33]的演变,一定程度上提高了三维地质模型的质量。
(2)改进插值算法。 如何根据有限的地质数据精准构建地质界面一直是三维地质建模研究者追求的目标,为提高地质界面的质量,通过引入新的插值算法或整合多种插值算法提高层面插值质量,如B-spline插值算法等,但不同地质界面插值算法具有不同的适用范围[34]。 插值虽然可以缓解数据稀少带来的问题,但并不能从根本上解决该问题,复杂情况下地质界面的构建仍是当前的难点之一。
(3)加入虚拟控制数据、专家经验[35]、多源数据融合[36]等方法。虚拟钻孔、连井剖面是最常见加入虚拟控制数据的方法,多源数据融合尽可能利用现有数据提高模型的质量,而专家经验则贯穿到建模的各个过程并控制模型的最终质量。
(4)地质规则约束[37-38],计算机表达地质体过程中遵循一定原则,如地质界面接触关系的有效性、构造模型的一致性、地质界面的不自相交性等规则[3],避免构建出违背地质规则的地质模型。
2.1.3 地层间、断层间及断层与地层间拓扑关系控制 三维地质模型在表达尖灭、盐丘、断层等地质现象时难免出现曲面相交的情况,曲面相交处理能力会在一定程度上影响无缝地质模型的构建[39]。 曲面相交处理一般包括曲面碰撞检验、计算交点位置、三角网重构与切割后处理[40]。 曲面碰撞检测研究比较成熟,一般通过缩小碰撞检测区域就可极大地提高算法效率,常见的碰撞算法有轴向方向包围盒法、空间分解法、包围球法、二叉树BSP法、固定方向凸包的包围盒法和方向包围盒法等[41]; 交点计算是曲面切割的基础,通过三角形各边与交叉三角形的相交测试,或根据确定相交的边计算出相应的交点,依次连接交点形成相交线[42]; 提取相应交线及与其相邻的地层边界线构成界面B-Rep,进而实现无缝三维地质模型的构建[39]。
曲面相交也会影响模型的网格化过程,主要包括以下两方面:(1)结构化网格:对于地质界面和断层面相交的情况,角点网格一般采用“断层绑定”思想(图5),实现与断层轨迹较优融合[43-44];正交网格则采用逼近断层轨迹线的方法进行网格化,对于尖灭、剥蚀等地层面相交情况,也采用此类逼近方法[45]。(2)非结构化网格:对于断层、尖灭、剥蚀等地质现象,非结构化网格也需作相应调整,如广义三棱柱网格在尖灭、剥蚀区退化成四面体或金字塔,退化点与尖灭线相对应[46];对于断层切割地层情况,广义三棱柱则需要分情况进行调整。
2.2 属性模型控制
属性模型的质量对后期地质分析、数值模拟等有很大的影响,而高质量属性模型及其模拟、分析结果则可协助地质专家作出更加科学的决策。 在油气、矿产、工程地质领域属性模型构建及应用已比较成熟,提出了一系列的属性模型控制策略:

图5 结构模型与格网模型拟合状态Fig.5 Fitting states of structural model(SM) and grid model(GM)
(1)地质成果约束。包括研究区地质成果约束和相似区地质成果类比两种类型,前者主要包括原始地质数据和解译数据,后者主要为成因模式类比。
第一类为研究区地质成果约束,地质专家通过对研究区钻孔、物探、试验或实验数据等资料的研究与分析,一方面,获取目标区的等时界面、成因模式、地质体空间分布、层序地层及其演化等地质成果数据;另一方面,通过对现有数据的深入研究,挖掘出其内在的价值,除对原始数据进行变差函数、统计特征等分析外,还包括利用各种方法推测或建立某种关系,推测未知区域的属性及其变化。目前许多研究者对后者作了较多的研究,如神经网络[47]、人工神经网络[48]、协同克里金、地质统计学等方法,建立采样点与地震参数(波速等)数据之间的关系,进而推测未知点处取值,它们均在各自研究区得到了实际应用并获得了满意的研究结果。
第二类为相似区类比。地质资料的稀疏条件下较难构建精准的属性模型,但地质专家可以通过相似成因区的成因模式(层序、相模式及其组合等)、构型等[49]方面进行类比分析,以在地质资料稀少的条件下尽可能提高属性模型的质量。
(2)层次建模。地质体在同一沉积相、同一岩性内属性的空间变化具有一定的规律,实现相内、岩性内插值具有一定的优势,因而层次建模由Damslesh等引入石油领域[50],之后许多更精细、复杂的层次建模方法也被引入到石油领域,并逐渐被其他领域所借鉴。 例如采用基于目标的建立河道模型,可采用序贯指示建立天然堤的分布[51]。 层次建模既符合地质现象的变化规律,也能避免大多数变量对于平稳性和均质性的严格要求。
(3)改进插值方法。Matheron和Krige在研究矿山储量时提出和发展了克里金插值方法[52-53],其考虑了采样点之间的空间相关性,对未知点进行无偏最优估计,在一定程度上提高了对地质体的非均质性的表达;后续许多的研究者又对其进行改进,提出了泛克里进、协同克里金、指示克里金等一些列的克里金插值算法,它们都在一定程度上提高了特定地质条件下地质体的非均质性表达,但是该系列的插值算法都受平滑效应[54]及局部最优估计的影响,难以满足复杂地质条件下的需求。为了有效展示地质体内部属性的随机性,多种随机模拟方法被引入到属性建模中(表3),且有各自不同的使用范围。传统的基于变差函数的地质统计学仅能考虑空间中两点之间的相互关系,因而在表达目标连续性及其结构方面具有一定局限性[55];而多点地质统计学以训练图像为基本工具,着重表达空间中多点之间的相关性,可以有效地缓解上述的弊端,但是仍难以精准再现地质体内部结构及属性的复杂性,目前多点地质统计学是储层建模的研究热点[51]。
(4)改进网格剖分方案。追求完美拟合地质结构并可获取精确数值模拟结果的格网模型是地质与三维地质建模研究者的奋斗目标。格网模型是进行空间分析、数值模拟等地质应用的基础,是属性模型的载体,因而网格模型的精细程度一定程度上影响着属性模型的质量。由于计算机技术等方面的限制,3D Grid较早引入到三维地质建模领域,其在较长一段时间内是剖分目标空间的较优格网,如今在第四系等领域仍有使用,相似网格包括Needle、Geocellular、规则网格等长方体类网格。该类网格难以精确地表达复杂地质条件的边界信息,一般只能缩小网格尺寸以较好地拟合地质构造,但会造成数据量的急剧攀升。为了克服该弊端,角点网格、截断矩形网格相继被引入三维地质建模中,它们可较好地再现地质体的构造并根据地质规则表达地质体的非均质性。目前,角点网格广泛应用于油气、矿产等领域,并获取了一系列的研究成果,虽然截断矩形网格可以无损表达地质体的界面,但其受数值模拟、使用性等方面影响并未引起足够重视。受角点网格间不正交等因素的影响,角点网格的数值模拟结果可能与实际有偏差,PEBI网格与其相比则具有正交、灵活等优势[56-57],既有利于数值模拟的进行,又可以很好地模拟非规则地质边界,但PEBI网格复杂程度较高、算法效率较低。与此相类似的发展过程还包括三棱柱—类三棱柱—广义三棱柱,这也一定程度上提高了属性模型的质量。
3 结论及发展趋势
高精度三维地质模型构建一直是地质学家追求的目标,受计算机、数据获取能力、经济等方面限制,三维地质建模的精度仍面临一些亟待解决的关键问题:1)在区域性地质建模过程中,可利用数据较少,如何在保证精度的前提下完成三维地质模型构建;2)如何在三维建模过程中添加或融入更多的地质规则约束,进而减少受主观因素的影响带来的误差;3)目前关于三维地质模型精度评估的研究较少,缺少能够被普遍接受的精度评估方法。
结合当前面临的问题,预测区域性三维地质建模质量控制的发展趋势:
(1)沉积相、成因约束建模等在石油领域应用比较成熟,并取得了较好的研究成果,但在其他地质领域研究中较少,故不能完全照搬其模式。同一沉积相中,沉积物的属性变化有一定规律,深入研究该规律,可以使三维地质建模的质量有较大提升。借助该思想,在现有数据支撑下建立沉积相模型,以相模型为约束构建岩性模型,进而进行属性插值,提高三维地质建模质量。
(2)在区域范围的三维地质建模过程中,钻孔数据(数量可能较少)是建模的重要数据源,钻孔之间对比工作量极大,且对比结果可能与实际相差较大,需要充分研究该区的沉积规律,推出岩性插值算法,减少人为划层带来的主观性,提高三维模型的质量。
(3)根据地质特征确定网格大小。在地层近水平、构造不发育的地区,规则格网剖分地质体具有一定优势,但目前没有网格大小的确定方案,运用数理统计等方法研究地层的厚度、水平延展信息,进而获取一定精度范围内的网格尺寸。
(4)高精度网格模型构建。区域规模或城市规模的三维地质模型面积较大,地质体的非均质性难以精确表达,提高其精度最根本的方法就是缩小格网粒度,然而格网粒度的缩小势必引起数据量剧增。但是,随着计算机硬件、软件的快速发展(如大数据、云计算等),海量数据存储成为可能,三维地质建模可采用分区存储、分块建模的思路进行地质数据的组织、管理,进而实现高精度格网模型的构建。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11 03:18:56
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:40
西南石油大学学报(自然科学版)(2019年1期)2019-01-28 09:33:52
北京航空航天大学学报(2017年6期)2017-11-23 05:57:36
浙江大学学报(工学版)(2016年10期)2016-06-05 09:20:56
电测与仪表(2016年10期)2016-04-12 00:26:24
电测与仪表(2016年14期)2016-04-11 12:32:48
电测与仪表(2014年11期)2014-04-04 09:21:30
河南科技(2014年18期)2014-02-27 14:14:52
河南科技(2014年7期)2014-02-27 14:11:06
