
基于公众情绪上下文的LSTM情感分析研究
2020-06-01 08:15陈凌宋衍欣
现代情报 2020年6期
陈凌 宋衍欣

摘 要:[目的/意义]近年来,由于微博等社交媒体的活跃,其在事件时空建模的潜在用途受到了广泛关注。在新媒体环境下研究用户情感可以分析用户情感的演变,将会帮助有关部门采取针对性的措施控制舆情。[方法/过程]本文构建了一种用于分析用户情绪上下文的长短期记忆模型(LSTM),对网络舆情用户情感倾向性和公众情感趋势进行分析与预测。[结果/结论]以新浪微博中,台风“利奇马”事件的相关推文为研究对象,通过多层次时间序列分析,验证社交媒体在自然灾害之前、期间和之后所扮演的角色;继而通过剖析用户情感演化规律,力图为合理控制舆情信息传播提出相应建议。
关键词:LSTM模型;情感分析;台风“利奇马”;新浪微博
Abstract:[Purpose/Significance]In recent years,due to the activeness of social media such as Weibo,its potential use in event space-time modeling has received widespread attention.Studying user sentiment in the new media environment can analyze the evolution of user sentiment and will help relevant departments take targeted measures to control public opinion.[Method/Process]This paper built a long-short-term memory model(LSTM)for analyzing the users emotional context,and analyzed and predicts the online public opinion users emotional tendency and public emotional trend.[Results/Conclusion]Taking the relevant tweets of the Typhoon“Lichma”incident on Sina Weibo as the research object,through multi-level time series analysis,verified the role of social media before,during and after natural disasters;By analysing the evolution of users emotions,they tried to put forward corresponding suggestions for the reasonable control of the spread of public opinion information.
Key words:LSTM model;sentiment analysis;super typhoon“Lekima”;Sina Weibo
隨着互联网的发展,越来越多的用户喜欢在社交媒体上发表自己的观点,分享生活中的小事,以及诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐、批评以及赞扬等,因此网络产生了大量的由用户发布的主观性文本。由于主观性文本应用价值的广泛性,情感分析近年来引起了很多研究人员的兴趣。
文本情感分析(Sentiment Analysis)又称意见挖掘,是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程[1]。简而言之,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,情感分析主要可以分为基于词典的分类方法和基于机器学习的方法。最早从事情感分析研究的Pang等将文本的N元语法(N-Gram)和词性(POS)等作为情感特征,使用有监督的机器学习的方法将电影评论分为正向和负向两类。结果显示支持向量机在几种分类方法中效果最好,分类准确率达到80%[2]。长短期记忆网络LSTM(Long Short-Term Memory)是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件,它成功地克服了原递归神经网络的缺陷,成为目前最流行的递归神经网络[3],在语音识别、NLP等领域取得了良好的效果。
本文将采用长短期记忆神经网络(LSTM)作为情感分析模型,对近期发生的重大突发事件进行网络舆情用户情感分析,并构建了一种用于分析用户情绪上下文的LSTM模型,对模型的有效性进行了一系列的评价,发现LSTM在句子表示方面表现较好,并将情感方面和极性的推理过程进行建模,关注目标表达中情感突出的部分,并生成对文本情感更准确的表示。从庞大嘈杂的微博流中识别出与灾害相关的微博信息,对所有与灾害相关的微博情绪进行分类识别。将长短期记忆神经网络模型引入微博情感分析阶段,探索与灾害相关的情绪有关的信息,并关注舆情生态系统下的用户负面情绪,以期为舆情生态系统的治理提供及时有效的帮助,加强舆情灾害管理能力。
1 分析用户情绪上下文的LSTM模型构建与实现
1.1 数据准备
本文中选取台风“利奇马”事件为例。2019年8月4日,第九号台风“利奇马”诞生于西北太平洋洋面上,经过3天的海上“流浪”,成长为超强台风并加速了靠近我国的步伐。10日凌晨,“利奇马”以超强台风姿态登陆浙江,中心附近最大风力16级(52米/秒),在浙江停滞20小时后,穿过江苏移入黄海,成为滞留浙江时间最长的超强台风。11日夜间,再次登陆山东,中心附近最大风力9级(23米/秒,热带风暴级),迅速穿过山东半岛后进入渤海,继续它的海上流浪。自登陆以来,它共在陆地停留44个小时,是个相当长寿的台风。超强台风“利奇马”两次登陆我国,两次入海,最终在渤海缓缓结束一生。它登陆强度强、陆地滞留时间长、降雨强度大且极端性显著、大风影响范围广且持续时间长,使华东及环渤海等地遭受严重风雨影响,浙江、安徽、江苏、山东等地均出现不同程度的城乡积涝、中小河流洪水、山洪和滑坡等灾害。
因其造成的影响巨大,因此我们选取了事件发生前后2019年8月4日至8月18日之间微博用户发表的数据信息,此时间段在政府微博和微博大V的转发评论等多方面因素的影响下,网民讨论和转发活跃度极高,部分读取数据如表1所示。為了提取这些信息,本文基于keras框架开发了Python脚本,爬取到20 258条数据,包括发表用户、时间、转发量以及评论数等数据信息。
1.2 数据预处理
数据爬取完毕后,共得到20 258条相关评论信息。对这些信息进行繁体字简化、删除垃圾广告、无效评论等数据清洗工作,最后得到20 038条有效数据,使用结巴分词,去除停用词等。预处理包括以下内容:1)所有HTML标签,使用“Beautiful Soup”Python库删除标点符号。2)此外,数字和链接分别由标签NUM和LINK代替。3)使用结巴分词删除停用词。4)每个单词的词形还原。
单词嵌入的起源可以追溯到1986年,称为Hinton提出的分布式表示。通过词嵌入模型以无监督学习方式得到作为文本特征的词向量,可避免人工设计特征的缺点[4]。单词嵌入能够将单词更改为低维实数向量,并允许我们基于余弦方法发现单词的相似性。Mikolov T等[5]在他的研究中提出了CBOW和Skip-gram。它不仅可以简化复杂性并缩短计算时间,还可以将数万亿个单词转换为单词嵌入。词袋模型(Bag-of-words)模型是信息检索领域常用的文档表示方法。单词嵌入技术是目前将文本表示为数字向量的最佳技术之一。它是一种习得的表示法,在这种表示法中,具有相似含义的单词被赋予相似的表示法。因此,本文使用BOW将文本向量化,之后基于Onehot提取文本特征。最后,将每个单词映射到向量,对于一个文档,我们得到一个N维向量序列,作为LSTM递归神经网络的输入。
1.3 模型构建
众公民作为社会的传感器,是分析灾害管理情绪的重要因素。社交媒体信息的传播总是比官方新闻报道更深入、更快。但是,社交媒体信息更难处理,社交媒体是一种独特的灾害事件信息。可见,情绪分析为传统的调查方法解释公众对自然灾害的意见提供了一种实用的方法。
因此本文将数据集包括两个类别:
积极的
消极的
我们使用人工标注验证集数据作为本文数据集的预培训。具体来说就是我们将模型中第一次验证的数据拟合到第二个验证数据的预培训中,然后将第二个验证数据拟合到同一个模型中。这种预培训是为了检验,在独立情绪分析数据上进行预培训是否有用,即使标签不匹配。
本文使用人工标注的微博语料数据集,其中正向和负向评论各20 000条,我们将其分成训练集和验证集。之后将预先训练好的字向量输入到长短期记忆神经网络中,得到的准确率为95%。LSTM是一种时间递归神经网络,是RNN用于解决消失梯度问题的方法。RNN的基本结构如图1所示,其中(a)是简单的RNN,(b)是LSTM网络。LSTM仅使用一个LSTM网络以形成单词的上下文表示。最后一个隐藏的向量用作句子表示,并输入Softmax函数来估计每个情感标签的概率。
在实验中,我们在递归神经网络(RNN)中使用LSTM模型来模拟微博评论的观点趋势。首先,我们需要通过词袋模型将语料库更改为嵌入词。之后,我们根据正面和负面训练建立预测模型。表2显示了语料库的分布情况。可以看出,使用各20 000条正向和负向训练分类器,使用20 000条正向和负向测试建立的模型。深度学习情感分析的实验结果达到了85%的准确率。
我们在基于LSTM神经网络模型上进行了一系列实验。我们使用相同的训练数据集(见表2)共有9 640条评论。分类是使用另一个包含2 785条评论的数据集独立进行的,这些评论在培训期间没有使用。因此,为了不使用基于模型的不同数量的训练周期,我们决定使用一个固定的数字—10,随着训练时间的延长,损失值并没有显著提高。
1.4 模型实现
情绪分析的主要目的是通过确定主观性、极性(正负)和极性的程度,然后对主题进行分类,从而量化文本中潜在情绪的强度。情感分析依赖于语言资源的使用,为每个词赋值。然后,机器学习技术通过允许计算机根据可用数据对行为建模来确定文本主体的情感[6]。下面的数字直观地反映了在正面和负面评论中出现频率最高的词语,通过分析图2和图3,我们可以看到,有些词可以清楚地识别出两极分化的情绪。然而,这并不适用于许多其他单词,这些单词有时甚至包含在具有完全相反含义的评论中。因此,仅仅根据某些词语的出现与否对评论进行简单的分类是不够的,这时需要机器学习技术(如本文使用的技术)来分析词语之间的关系。
基于词云,生成情绪文本可视化,如图4、图5所示。从图4中我们可以看出,救灾、山东、浙江、救援、安全等词被用来表示用户非常关注台风的进程。一线、志愿者、香港等词则表达了对台风
受灾地区和邻近地区的关注和关心。图5显示的是台风“利奇马”事件中的负面情绪词语,像出现频次较高的像损失、受灾、暴雨、死亡等词大多数用来表述台风来临时的恐惧和对生活环境的担心。除了对台风的关注和对生活环境的担心外,我们还发现了一些有趣的模式,例如,所挖掘的句子结构包括“正在…”、“希望…”和“祝福…”等通常用于表达期望和愿望,例如“危险”这样的附加问句是对这一事件的强烈不满。这些研究发现,情感分析为用户更好地理解公众意见的语义提供了一种有效的方法。
根据实验结果得到的情感状态分布如图6所示,可以看出,台风来临前后公众对台风的情绪,大多是负面情绪,表示对受灾地区和人民的担心;当地居民对出行、生活环境的担忧;以及对地标性建筑毁坏的唏嘘。关注公众的负面情绪有助于及时有效地引导舆情朝良好的方向发展。
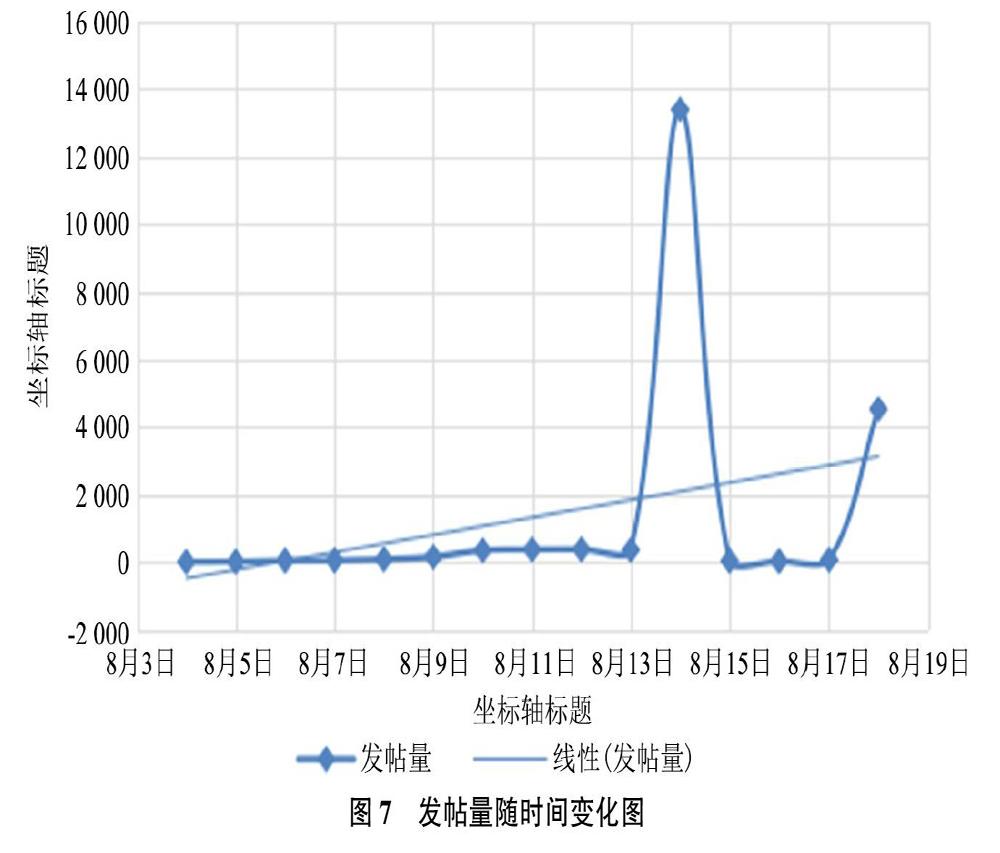
台风来临前后,公众对台风的关注程度也是不同的。从发帖量(见图7)可以看出,8月4日,第9号台风“利奇马”在菲律宾以东洋面生成,于6日加强为强热带风暴级,各类媒体开始报道“台风即将来临”,并请“各单位做好防范准备”,公众这时对台风事件关注度较低;8月10日凌晨,台风登陆浙江中北部,受此影响,8月11日,“利奇马”携带大量水汽北上,山东和江苏将成为大暴雨的核心区域,多处铁路出现列车停运状况,公众关注度开始上升,并达到第一个小高峰;8月12日到14日,北方的一股冷空气正好和台风“利奇马”迎头相撞,环渤海区域的京津冀和辽东半岛,山东半岛暴雨如注。8月13日,中央气象台发布消息称,“利奇马”减弱为热带低压,并于当日14时停止编号。8月14日,公众的发文量达到最高点,超出之前的发文量10倍之多,根据8月14日的情绪强度,多数微博用户表达了负面情绪。这是因为用户可能会在台风过后在微博上讨论与灾难有关的其他问题,例如新闻机构和普通用户在微博上讨论了台风对当地居民的不利影响。随着时间的推移,人们表达了复杂的情绪(包括积极的和消极的);一些人在微博上谈论台风的后果,而另一些人则对当地政府和志愿者的活动表示总体满意,他们能够为当地人民筹集资金,为他们提供食物和水等等。8月15日后发帖量逐步减少,说明公众情绪得到平复,各方单位应对有效,到8月18日,公众关注度又达到了一个高点,这时的公众大多关注在台风引起的各种生活上的不便,感慨生活,希望灾后生活便利。从情感分析结果来看,从灾害发生到结束期间,公众的负面情绪不断扩散,而且占超过一半的比重,因此我们应重点关注灾害期间公众的负面情绪。
2 结果与建议
社会化媒体用户在进行评论时的情绪状态往往受突发公共事件驱动,许多研究发现在不同突发事件中民众表达的情绪具有差异,开始重点分析事件特性与情绪类型之间的关联[7]。在研究中发现在可预见性和可控性都比较强的危机情境下,社交媒体用户主要表达愤怒情绪;在可预见但不可控的危机情境下主要表达悲伤情绪;在不可预见且不可控的情境中恐惧情绪占据主导,在可预见性低但可控性强的危机情境下主要体现焦虑情绪。
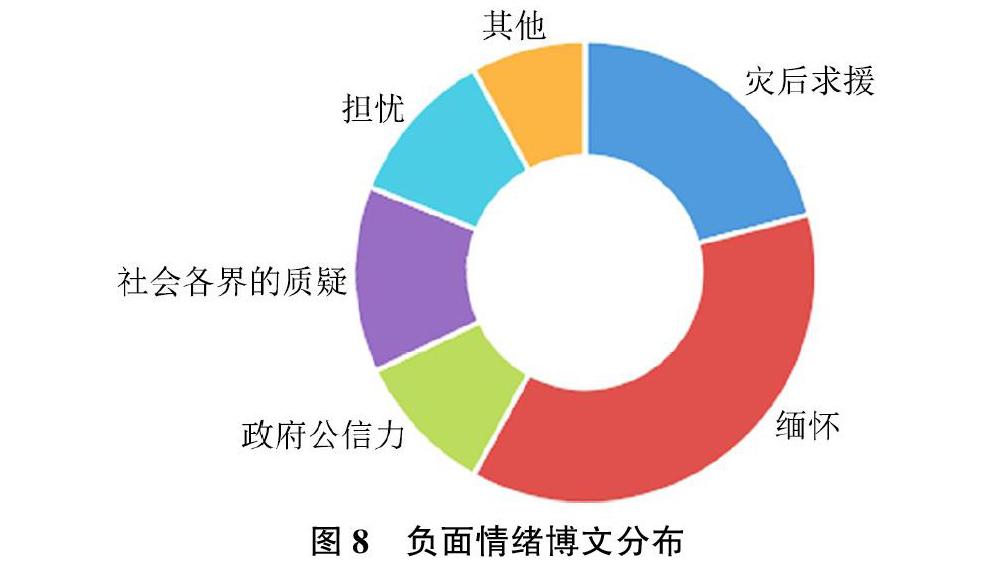
网民负面情感在网络舆情事件发展过程中有着至关重要的影响[8],若不加以调节,任其发展,不仅可能引发新的舆情事件,甚至激起现实社会更极端的群体行为[9],如埃及、摩洛哥、乌克兰等国家的颜色革命。突发事件发生后,很多人会不明真相,因而个人舆论观点严重受到网络中其他人的感情色彩的影响而表现一定的倾向性[10],因此平复民众负面情绪是应急管理的重要工作,对民众负面情绪实时监控预警是防止衍生群体事件发生的关键[11]。从上文的分析结果中,我们可以看出,在灾害发生前后,公众的负面情绪占绝大部分,而且对社会安全,生活环境与周围人的生命健康尤其担忧。图8显示了负面情绪博文的分布情况,可以看出对周边生活环境和周围人的担忧占绝大部分,其次是对于灾后救援工作的关注,同时也有很多人因为灾害的来临,对政府公信力和社会业界的救援工作产生了质疑,这些负面情绪如果不能得到很好的控制,很可能会影响政府灾害救助工作和经济社会的稳定。
通过新浪微博搜索API进行收集,并对灾后公众行为和响应数据进行汇总分析。我们对台风“利奇马”期间微博上的用户发帖进行了情感分析,并将这些情绪可视化。我们展示了用户的情绪是如何变化的,灾害发生时公众的情感发生了怎样的变化,以及负面情绪波动。对来用户推文进行识别,并对最常出现的词汇进行排名。结果表明,这些数据揭示了在危机事件期间用户组的兴趣、需求和关注的重要信息。从微博发布内容数量的时间变化可以看出,随着时间的推移,公众的注意力发生了转移,有助于理解危机期间的公众行为和反应。最后,在整个观察期间进行情感分析。
随着信息普及、环境意识和媒介素养的强化,公民既是日趋理性的环境保护者又是意见和情绪的表达者。情感分析的一个重要结果是由于灾难性事件,人们更容易表达消极的态度,这时候需要引导公众以更积极的情绪看待对地方政府的作为和志愿服务活动。负面情绪的大肆传播不利于政府形象的建立,政府应该从以下几个方面努力:坚持公信力,即公共机构应该时刻尊重公众的知情权和表达权,公正公开地传播真实有效的信息,获得公众的信任和信心;更加理性对待环境群体性事件中的网络舆情,不应将网民情绪表达进行过度解读;充分尊重公民参与公共事务的权利。
既然网络舆情信息的不可控性的确对于社会信息发展形势具有一定的负面干预作用。那么政府机关便应该尽量在网络舆情形成前,对网络中的不良信息加以控制和抵制[12]。在群体性事件爆发时,政府、相关机构和企业要因地制宜地进行危机传播管理,认真听取公众建议,积极落实措施和政策,保持信息渠道畅通,提供信息咨询服务和政策支持;强化新媒体在舆论引导中的作用。运用新媒体对热点事件及时公布,强化公正公开透明的信息管理,引导合法有效的舆情抗争。
3 总 结
网络舆情生态是一个复杂多变的社会生态系统,系统内舆情主体因素、舆情客体因素及舆情环境因素相互影响、相互作用、相互制约,发生着多维度、多层次、立体化的互动。健康的舆情生态系统应该是特定网络舆情各构成要素间、网络舆情间、网络舆情与外部环境间相互关联制约而达到的一种具有相对平衡的结构状态的复杂系统[13]。社交媒体作为舆情生态系统中的重要组成要素,通过对其合理监督和控制能够有效提高舆情生态系统平衡指数。
基于舆情生态系统,利用情绪分析来发现大型非结构化数据集的极性已成为自然语言处理研究领域的热点,我们发现社交媒体是围绕灾难事件的丰富数据来源。越来越多的人在灾难发生之前、期间和之后使用社交媒体来描述他们的经历、表达他们的需求,并与其他受影響的人交流。这种在线讨论模式是一个丰富的信息宝库,如果及时有效地采取相应措施,可能有效地控制舆情的散播并对灾害应对起到积极作用。由于社交媒体的性质,信息贡献者不再是旁观者。识别用户的情绪变化,有助于了解灾难期间大型社交媒体信息传播的情感类别,并能更好地为应急管理人员以最快的方式接触最广泛的受众提供最佳决策。
笔者将在后续的研究中收集更多来自其他类型的具有更大影响的灾难(如飓风、海啸)的数据,并测试频繁使用的词汇、发布内容的时间变化和用户情绪。这一新的方向将有助于更好地了解危机情况下的公众情绪,并帮助应急管理人员采取必要的措施控制灾害舆情。另外集成更复杂的模型或设计新的模型来改进情绪分类以及细粒度的情绪检测将是非常有必要的,并且可以关注地理地图情绪分析如何在灾难中发挥不同作用的,了解情绪波动如何影响在灾难事件期间社交媒体上的信息,并以此传递对紧急响应人员和地面人员有用的信息。
参考文献
[1]Deng S,Sinha A P,Zhao H.Adapting Sentiment Lexicons to Domain-specific Social Media Texts[J].Decision Support Systems,2017,94:65-76.
[2]Davidov D,Tsur O,Rappoport A.Enhanced Sentiment Learning Using Twitter Hashtags and Smileys;Proceedings of the Proceedings of the 23rd International Conference on Computational Linguistics:Posters,F,2010[C]//Association for Computational Linguistics.
[3]Hochreiter S,Schmidhuber J.Long Short-term Memory[J].Neural Computation,1997,9(8):1735-80.
[4]Collobert R,Weston J,Bottou L,et al.Natural Language Processing(Almost)from Scratch[J].Journal of Machine Learning Research,2011,12(8):2493-537.
[5]Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].arXiv Preprint arXiv:13013781,2013.
[6]Hijazi M H A,Libin L,Alfred R,et al.Bias Aware Lexicon-based Sentiment Analysis of Malay Dialect on Social Media Data:A Study on the Sabah Language;Proceedings of the 2016 2nd International Conference on Science in Information Technology(ICSITech),F,2016[C]//IEEE.
[7]唐雪梅,朱利麗.社会化媒体情绪化信息传播研究的理论述评[J].现代情报,2019,39(3):115-121.
[8]Choi Y,Lin Y-H.Consumer Responses to Mattel Product Recalls Posted on Online Bulletin Boards:Exploring Two Types of Emotion[J].Journal of Public Relations Research,2009,21(2):198-207.
[9]李勇,蔡梦思,邹凯,等.社交网络用户线上线下情感传播差异及影响因素分析——以“成都女司机被打”事件为例[J].情报杂志,2016,35(6):80-5.
[10]王雪猛,王玉平.基于情感倾向分析的突发事件网络舆情预警研究[J].西南科技大学学报:哲学社会科学版,2016,33(1):63-6.
[11]刘志明,刘鲁.面向突发事件的民众负面情绪生命周期模型[J].管理工程学报,2013,(1):15-21.
[12]段亚楠.群体性突发事件的网络舆情问题及政府治理策略[J].湖北函授大学学报,2018,31(18):114-5.
[13]李昊青,兰月新,张鹏,等.网络舆情生态系统的失衡与优化策略研究[J].现代情报,2017,37(4):20-6.
(责任编辑:郭沫含)
猜你喜欢
上海质量(2019年8期)2019-11-16
治淮(2019年9期)2019-10-09
山东煤炭科技(2019年8期)2019-09-07
传媒评论(2019年10期)2019-06-05
预测(2016年5期)2016-12-26
今传媒(2016年8期)2016-10-17
