
智能搜索技术在电力企业内部审计中的应用与探索
2020-05-28 08:08王桂钦
中国管理信息化 2020年9期
陈 威,王桂钦,王 伟
(深圳供电局有限公司,广东 深圳 518000)
1 引言
随着信息系统在电网企业的全面应用,电网企业进入了数字化信息时代。审计部门作为企业内部风险监督部门,目前已基本实现信息化支撑,从审计项目管理实施到审计辅助作业都已全面实现信息化。在信息化支撑的审计项目管理实施作业模式下,审计业务部门积累了大量的审计历史发现问题,审计历史问题是审计项目实施过程中沉淀的核心审计成果数据,利用好审计历史问题数据对提升审计项目实施效率与质量都有巨大帮助。
审计历史问题包含发现问题的领域、问题表象、问题定性、违反的法规条款等核心信息,这些信息都是审计项目实施中必须输出的成果。根据对某供电企业过往10年审计发现问题的分析,当年审计业务新发现的审计问题占比为5%至10%,90%左右为过往年份已经发现过的问题,快速、准确地对过往年份发现的审计问题进行定性与问题描述是提升审计项目质量和效率的有效途径。本文主要应用智能搜索技术对审计历史问题库进行搜索匹配,让审计人员可快速定位到历史发现的类似问题,为审计问题的定性、描述、处置方式等提供参考,提升审计效率与质量。
2 技术与模型
审计历史问题库为结构化数据,在历史问题库进行搜索过程中最大的问题难点在于每个审计人员对问题的描述不一致,相同的审计问题由于描述的不一致很难用通用的关键字匹配技术实现精准定位,需通过智能搜索技术针对审计人员对审计问题的描述进行语义匹配后对历史问题库进行搜索定位,从而达到类似问题或相同问题的精准搜索。智能搜索技术包括信息检索、信息抽取、信息过滤、语义智能匹配四个方面,可以对文本数据进行快速的搜索,并可以穿透内容,精确定位搜索内容。
BIM(二元假设模型)是显示相关度的一种模型,主要用于相关性匹配与语义匹配。
模型即可以对两个因子 P(D|R)和 P(D|NR)进行估算(条件概率),举个简单的例子,文档D中五个单词的出现情况如下:{1,0,1,0,1}0 表示不出现,1 表示出现。用 pi表示第 i个单词在相关文档中出现的概率,在已知相关文档集合的情况下,观察到文档D的概率为:
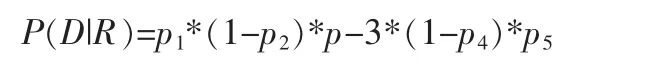
对于因子P(D|NR),我们假设用si表示第i个单词存在不相关文档集合中出现的概率,于是在已知不相关文档集合的情况下,观察到文档D的概率为:

最后可以得到以下的估算:

我们可以将各个因子规划为两个部分,一部分是在文档D中出现的各个单词的概率乘积,另一部分是没在文档D中出现的各个单词的概率乘积,于是公式可以理解为下面的形式:
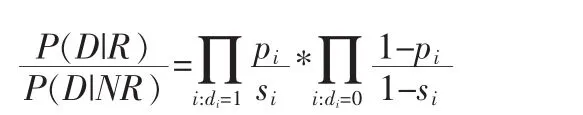
对公式进行等价变换:
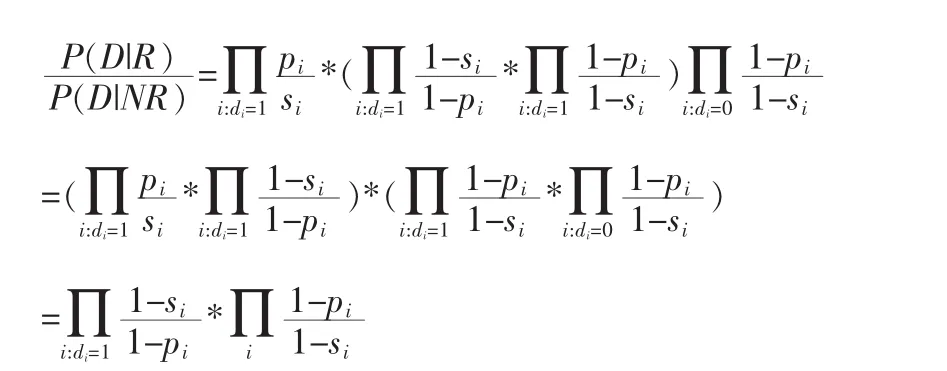
第一部分代表在文章中出现过的单词计算得到的单词概率乘积,第二部分表示所有特征词计算得到单词概率乘积,它与具体的文档无关,所有文档该项的得分一致,所以在排序中不起作用,可以忽略,所以得到最终的估算公式:
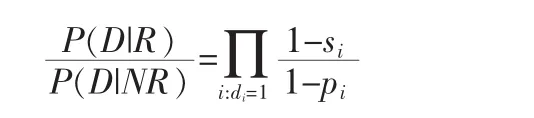
为了方便计算,对上述公式两边取log,得到:

如何估算概率si和pi呢,如果给定用户查询,我们能确定哪些文档集合构成了相关文档集合,哪些文档构成了不相关文档集合,那么就可以用如表1的数据对概率进行估算。

表1 相关文档及不相关文档数据
根据表1可以计算出pi和si的概率估值,为了避免出现log(0),对估值公式进行平滑操作,分子+0.5,分母+1.0,即:
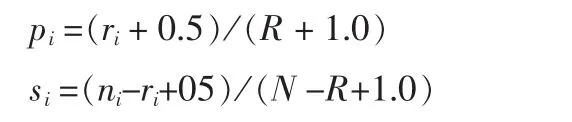
代入估值公式得到:
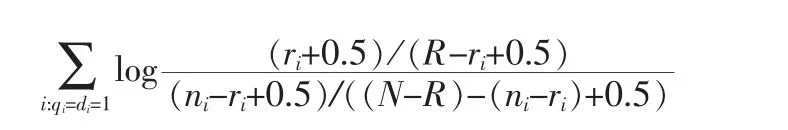
这个公式代表的含义是:对于同时出现在查询Q和文档D中的单词,累加每个单词的估值结果就是文档D和查询Q的相关性度量,在预先不知道哪些文档相关,哪些文档不相关的情况下,可以使用固定值代替,这种情况下该公式等价于向量空间模型(VSM)中的IDF因子。虽然BMI模型的实际使用中不是很理想,但它是BM25模型的基础。
3 案例介绍
我们对风险库、历史问题库这些文本库,按照审计工作的特点从业务领域和管理环节两个大的维度进行全索引 (所谓全索引就是对相关的词语进行不分词的全域搜索,建立索引)。业务领域提取了“财务管理”“招标非招标采购管理”“法律合同管理”“工程管理”“生产运行管理”“物资管理”“项目管理”“营销管理”“其他业务领域”九个维度。管理环节提取了“关联交易管理”“物资仓储管理”“物资出库及退库管理”“物资管理其他”“物资信息系统管理”“项目施工及质量管理”“资产管理”“抄核收管理”“电费回收管理”“电费资金管理”“电价政策执行管理”“电能计量管理”“项目监理管理”“项目结算及决算管理”“业扩报装管理”“营销档案管理”“营销管理其他”“营销信息系统管理”“用电检查和反窃电管理”“项目资金管理”“成本费用管理”“税务管理”共21个维度。
对这些维度进行不同组合,我们先用布尔型检索建立范围相对小的查询子集,例如用户在业务领域选择了“财务管理”,在管理环节提取“成本费用管理”,系统会对这两个维度进行布尔型检索,形成一个含有“财务管理”和成本费用管理”的文档子集,再用BIM模型在这个文档子集对所查询的词进行相关性的排序。用户就可以得到一个以查找的关键词的相关性排序的文章列表。
以历史问题库为例,假设用户需要搜索“用电客户的用电类型与电价不相符”这类历史问题,利用智能搜索技术需要通过以下几步来完成。
3.1 语义分割
对用户输入的搜索条件 “用电客户的用电类型与电价不相符”进行分词处理。根据汉语语法,这句话应该被分割成:
用电客户 /的 /用电类型 /与 /电价 /不相符
3.2 利用布尔型检索
通过第一步的语义分割,对分割出来的词语“用电客户”“用电类型”“电价”,进行判断,并确定用户要查找的问题属于“营销管理”业务域,管理环节可能属于“电费回收管理”“电费资金管理”“营销档案管理”“用电检查和反窃电管理”。系统对这几个维度进行布尔型检索,形成一个含有“营销管理”“电费回收管理”“电费资金管理”“营销档案管理”“用电检查和反窃电管理”的文档子集。
3.3 用BIM模型对文档子集进行相关性排序
首先,对历史问题库的各个维度进行权重分配,如:业务领域占5%、管理环节占5%、问题类型占5%、问题概述占10%、问题详情占20%、审计意见或建议占10%、整改措施占15%等。
然后,根据分割出来的词语分别对各个维度进行匹配,并根据匹配程度和权重算出每个维度的得分。假如总分为100分,问题概述占比为10%,则问题概述满分为10分,系统自动判断分割的分词和问题概述的匹配程度进行评分,最高评10分,最低为0分。
最后,将所有维度的评分进行求和,算出有相关性的历史问题的匹配程度得分,并按照得分高低进行降序排列,理论上得分最高的历史问题记录是用户最想查到的,如果实际中存在差异,则还需对模型进行优化。
4 结语
本文基于审计历史问题库,利用搜索模型的算法,从历史问题库的各个维度进行智能搜索匹配,快速精准地定位审计人员需要搜索的内容,通过对历史审计问题的参考,在审计项目实施过程中审计人员可以快速完成对审计问题的定性、问题描述、法规应用等工作,帮助企业审计部门提高审计工作效率与质量,提升分析问题的能力。
猜你喜欢
经营者(2023年10期)2023-11-02
中学生数理化·中考版(2022年6期)2022-06-05
客联(2022年3期)2022-05-31
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
中国新闻周刊(2021年26期)2021-07-27
中国化肥信息(2021年12期)2021-04-19
中学生数理化·中考版(2020年12期)2021-01-18
小学生必读(中年级版)(2018年10期)2019-01-04
