
基于主成分分析的雷达行为状态聚类分析方法
2020-05-18 07:38:58毕大平潘继飞陈秋菊
探测与控制学报 2020年2期
方 旖,毕大平,潘继飞,2,陈秋菊,2
(1.国防科技大学电子对抗学院预警对抗系,安徽 合肥 230037;2.电子对抗信息处理实验室,安徽 合肥 230037)
0 引言
随着相控阵技术与软件化技术的发展,雷达作为具有多功能、多任务、多种工作模式的高度智能化系统,逐渐展现出极强的灵活性和自适应能力,给雷达对抗技术带来了前所未有的挑战。主要体现在:必须具备及时准确地感知雷达内部状态动态变化的能力,才能引导对抗装备敏捷地决策出最优的对抗策略,进而实施认知对抗。尽管雷达信号多变,但信号设计与工作模式、行为意图及能力紧密关联,且雷达工作模式类型有限,这一本质特征为雷达认知对抗提供了可行性[1]。
围绕雷达实现参数级对抗向行为级智能对抗跃升的需求,专家学者积极开展雷达辐射源行为精确辨识研究。最常用的句法模型算法[2-4]依赖于时钟周期所描述的量化精度,随着时钟周期的缩短,量化精度会有所改善,但是同时会使得编码序列增加,所需工作量增大。TTP变换算法[5-6]基于TOA的脉冲序列PRI分析方法,并在此基础上利用扫描特性、PDW中的PW,RF等参数对算法进行了改进,对提高提取效率有很好的效果。文献[7]提出了通过构建CPI(相干处理周期)矩阵,并将矩阵与先前构建的雷达数据库进行关联。文献[8]利用生物信息学方法“多序列比对(MSA)”从信号中重建MFR的搜索计划,还原搜索任务。文献[9]采用了分别对脉冲组数据、工作模式分层次建模的方法,对各个层次之间的联系进行描述。
上述雷达行为识别方法普遍需要大量的雷达先验信息与完备的数据库支撑,或受限于动态表征算法的能力,无法实现较为复杂的工作状态的识别。针对这个问题,本文在小样本数据条件下,设计了一种基于主成分分析的改进型C-均值聚类算法以完成样本数据的分类方法,并根据雷达脉冲描述字及其变化规律从逻辑角度反推设计原则,进而与常见工作状态(模式)匹配。
1 雷达行为状态分析模型建立
雷达对抗侦察接收机通过侦察天线波束覆盖或频段扫描的方式接收指定雷达目标的脉冲信号,生成脉冲描述字,包括到达时间、脉冲宽度、脉冲幅度、脉冲载频、到达角、重频、波束方位等参数。雷达信号形式与其行为意图息息相关,也与工作模式存在对应关系。在不同雷达工作模式下,脉冲描述字参数表现为不同的特性[10-12]。例如,重频(PRF)通常情况下分为高重频(HPRF)、中重频(MPRF)、低重频(LPRF)。当重频足够低时,可以尽可能测量出足够大的不模糊速度和距离。在中重频状态下,雷达在旁瓣杂波区内对目标的检测性能优于高PRF,通常对目标的距离和速度都是模糊的,但可以通过不断变换PRI的形式来解决问题。中重频波形主要用于全方位的速度距离搜索,但它的远距离性能会相对较差。在高重频状态下工作的雷达主要用于速度搜索模式和边搜索边测距模式,在PRF足够高的情况下可以对所有感兴趣的目标速度都能不模糊测量,但它的缺陷是难以检测到旁瓣杂波区的目标。雷达对不同类别的目标采用不同的跟踪数据率,对处于跟踪过渡过程中的目标,用较短的采样间隔时间;对已稳定跟踪的目标,根据它的重要性及威胁等级分成若干种跟踪状态,即威胁等级高的采样间隔时间较小,等级低的采样间隔时间较大。
围绕雷达行为辨识问题,建立图1所示模型。
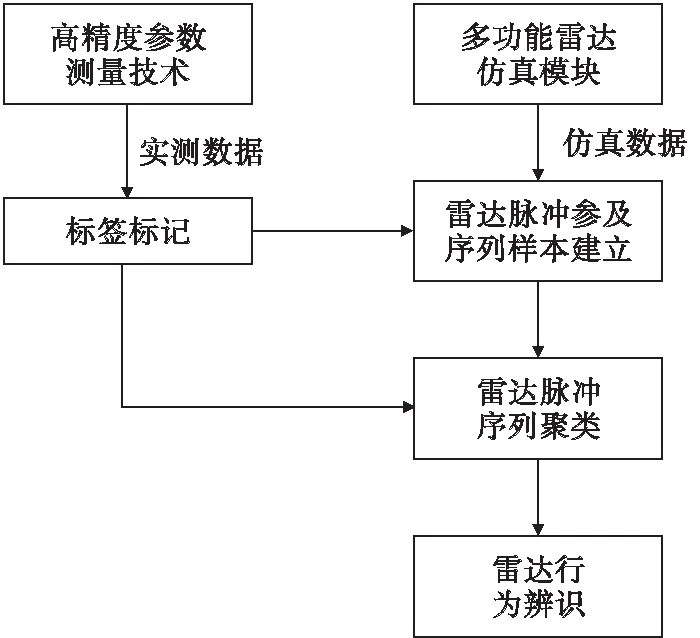
图1 雷达行为辨识模型Fig.1 Radar behavior recognition model
本文所提方法基于在系统准确区分不同辐射源信号的前提下运用。直接测量与仿真的信号数据冗长且干扰因素大,难以完成聚类分析。对所有原始数据进行处理,处理完成的雷达脉冲参数建立样本序列,并对序列聚类。最后对每一类进行识别,确定雷达行为状态。
2 基于主成分分析的样本优化
2.1 数据预处理
雷达信号特征参数的选择取决于该参数是否能够从本质上反映工作模式的行为意图。例如,对某型机载侧视雷达来说,分别工作在远区搜索、近区搜索及跟踪三种模式下时,脉宽、重频及脉压比都有较为明显的区别。远区搜索时,脉宽较另外两种模式宽,是由于对远区目标搜索时需要消耗较多的能量,而此时的重频较低,脉压比较大;近区搜索时,脉宽相较远区搜索窄,相对跟踪模式下的脉宽较宽;跟踪模式下,重频较高,便于精确瞄准目标。可以看出在不同工作模式下脉宽、重频和脉压比有明显不同。而当在跟踪模式下跟踪不同目标时,波束方位指向就具有明确的指向模式意图。因此,根据描述字对信号特征进行分析从而对工作模式进行识别,是一种行之有效的方法。
本文采取的分析方法是利用C-均值算法对特征参数聚类分析。C-均值聚类算法基于距离原则将原始数据根据到聚类中心的距离来分类,而原始数据本身量级差别很大,在对其采用欧式距离计算时会产生极大的误差,因此要对原始数据进行预处理,使C-均值聚类算法可以更好地运算以达到分类的目的。
数据归一化有多种办法:
1)线性函数归一化(Min-Max scaling):线性函数将原始数据线性化的方法转换到[0,1]的范围计算,公式如下:
(1)
2)0均值标准化:将原始数据集归一化为均值为0,方差为1的数据集,计算公式如下:
(2)
以上两种方法虽然可以把数据归一化,但是归一化之后的数据量级依然相差很大,无法满足适合C-均值聚类算法的要求。本文提出一种新的数据预处理的方法,即先将原始数据归一化,以相同比例同时缩小,然后将得到的数据取对数,这样出来的结果在量级上相差很小,方便之后进行聚类分析。但是,重频参数在初始归一化之后量级也仅相差10倍,就不再采取对数化处理。数据预处理的公式如下:
Xk′=log(max(Xk)/Xki),i=1,2,…,N
(3)
式(3)中,Xk为对数处理后的样本数据,max(Xk)为样本数据中的最大值。
2.2 基于主成分分析的样本筛选
主成分分析(Principal Component Analysis,PCA)是最常用的降维方法之一,通过线性投影,将高维的数据投射到低维的空间中,并期望在所投空间中维度上包含的信息量最大,进而使用较少的维度,也可以保留较多的原数据中的信息。本文通过主成分分析对雷达脉冲参数进一步筛选,可以减少样本数据集的大小,在有限的时间和资源下,提高分类算法的效率,以便建立更精准的雷达行为状态识别模型。
主成分分析可以由以下几个步骤完成对雷达脉冲序列特征参数的筛选:
1) 对所有特征进行中心化:去均值。对原始样本中的每个特征参数求均值,并将每一个特征减去求得的均值。
2) 求协方差矩阵。雷达脉冲序列按时间排列,每一行为一个样本,每一列为一个维度,计算公式为:
(4)
3) 求协方差矩阵的特征值和相对应的特征向量。将计算所得的特征值从大到小排列,选取最大的3个,并提出其对应的特征向量u(1),u(2),u(3),…,u(k)。
4) 将原始特征投影到选取的特征向量上,得到降维后的新3维特征。计算与之对应的主成分表达式的系数,并把系数与原始数据相乘得到分配权值之后的样本数据X′(N)={X1′,…,Xn′}。
原样本数据包含所有脉冲参数,例如脉冲宽度、重复周期、波束方位、脉压比、脉冲幅度、带宽等,有些特征参数对分类影响很大,有些特征参数对分类几乎不会产生作用,通过主成分分析,可以提取贡献率最大的三类参数构成数据集,减少数据冗余,提高分类效率。
2.2 基于均值漂移优化C-均值聚类算法
C-均值聚类算法属于动态聚类算法,即在迭代过程中,样本不会因为之前的判定而固定类别。此算法采用欧氏距离计算方法计算各个样本到聚类中心的距离,将样本归于距离最短的聚类中心所在的那一类里,并计算聚类之后的每个数值对象的平均值来获取新的聚类中心,根据前后两次的聚类中心是否变化来判定聚类是否完成,聚类中心是否选取正确[13-15]。此算法使用的聚类准则函数是误差平方和准则,即:
(4)
式(4)中,Nj为第j类样本数,mj为第j类wj,为使结果更优化,应该使Jc最小化。基本计算步骤如下:
1)已知样本X(N)={X1,…,Xn},令T表示迭代运算次数,随机挑选N个样本作为初始的聚类中心,主要看样本需求分为几类。
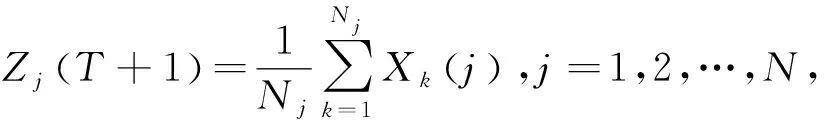
4)若Zj(T+1)≠Zj(T),j=1,2,…,N,则T=T+1,返回2),否则算法结束。
从计算方法中可以看出此种聚类方法受初始样本和随机选取的初始聚类中心影响很大,聚类结果往往与预期分类有所差别,因此在聚类之前基于均值漂移对样本数据进行优化,使得初始的中心值逼近最佳位置。
均值漂移是一种基于密度梯度上升的非参数方法[16],其核心是通过计算随机选取的中心点在一定范围内到每一点的距离平均值,将计算平均值所得到的偏移值作为中心点,重复计算,反复迭代,使中心点逐步逼近最优位置。由于每个参数对偏移值的贡献率不同,因此在均值漂移中引入核函数进行计算:
(5)
式(5)中,xi为雷达脉冲序列特征参数,h为区域半径,s(xi)为各类特征所占权重。
改进后的C-均值算法流程图如图2所示。

图2 改进后的C-均值算法流程图Fig.2 Improved C-means algorithm flow chart
改进后的C-均值算法完善了原算法对初始样本数据过于敏感的问题,在不影响每组样本数据分布的前提下,对预处理过的样本再一次通过权值分配降低分类偶然性,提高聚类分析的准确性,可以更好地对雷达信号参数特性进行分析。
聚类稳定后,提取中心点参数值,根据聚类中心参数与模式间的对应关系判定模式类别,利用了脉冲参数与工作模式之间基于雷达设计准则的逻辑关系进行判断。在缺少大数据驱动的条件下,此方法具有一定的实现价值。
3 仿真实验与分析
本文选择某型机载侧视雷达在两种情况下的信号参数,分别进行对工作模式的分类。雷达脉冲描述字序列由某型雷达对抗侦察设备侦收分选所得。为检验本文提出算法在不同行为状态的适用性,分别在两种不同行为状态的数据样本下进行实验。仿真过程中根据雷达设计原则及先验知识库,对雷达每种行为状态随机生成初始样本,每个样本为8维的数组:第一组选择在合理精度范围内的1 000组数据,其中远区搜索模式下300组数据,近区搜索模式下400组数据,跟踪模式下300组数据;第二组选择在合理精度范围内的300组数据,其中搜索模式下224组数据,跟踪1号目标37组数据,跟踪2号目标39组数据。采用准确度(Accuracy)和灵敏度(Sensitivity)两种性能评估指标对实验结果进行分析。准确度的定义为:

(7)
是所有正确分类的数据点占总数据点的百分比。但是,由于MPAR脉冲序列组并不是均匀分布的,仅用准确度来评价是不够完善的。例如脉冲数据包含10%的跟踪模式和90%的搜索模式,如果检测出所有活动都是搜索模式,那么分类准确度为90%,但此时并没有识别出跟踪模式。因此引入灵敏度概念对分类结果进行评价。灵敏度公式为:

(8)
3.1 实验一
为检验改进后算法的有效性,对样本数据分别进行原始聚类算法实验、通过归一化处理后的聚类算法实验和基于主成分分析与均值漂移后的聚类算法实验。得到图3所示结果。
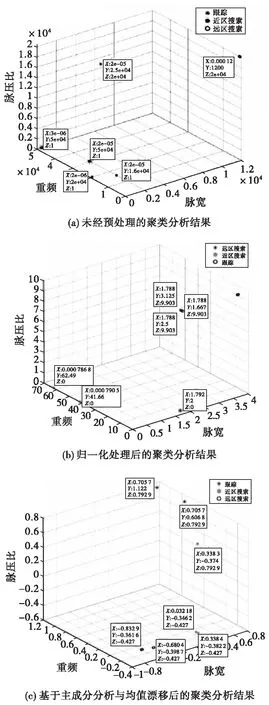
图3 三类聚类算法实验对比Fig.3 Experimental comparison of three kinds of clustering algorithms
通过三个实验结果散点图可以看出三种方法均可以完成对雷达行为状态的聚类。表1为在不同算法下多次进行聚类分析的准确率。表2为在不同算法下雷达不同行为状态的聚类灵敏度。
实验结果表明,改进后的聚类算法较之前提升了分类的准确率,总分类基本可以稳定在85%左右,能够适用于无法即刻获取大量样本数据进行数据驱动的算法识别的情况下,并达到一个较好的效果。对于第一组的雷达行为状况分析,远区搜索相较于近区搜索和跟踪状态,分类效果更好,准确率更高。产生这种现象的原因是远区搜索的重频低,脉宽宽,搜索时间长,而近区搜索和跟踪的重频高,其中跟踪要求的数据率高,因此需要高重频来保重跟踪行为的完成。
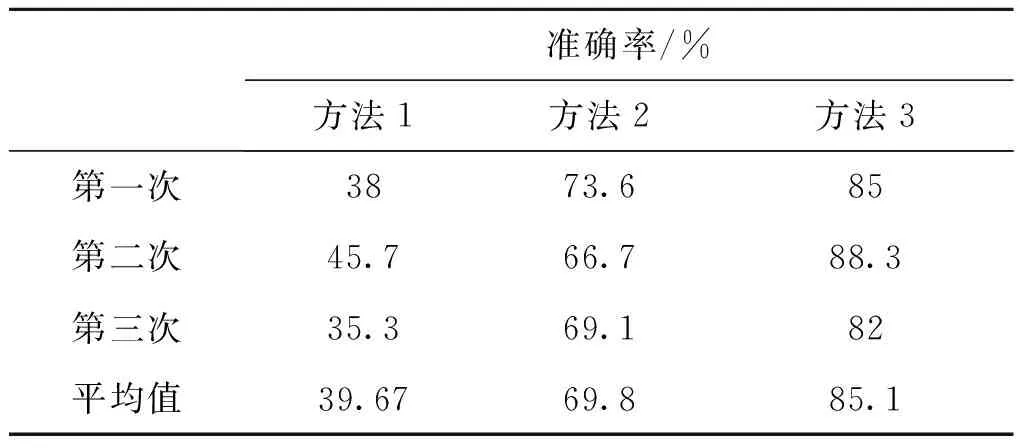
表1 聚类识别准确率

表2 各类雷达行为聚类识别灵敏度
信号参数在未经预处理的情况下使用原始C-均值聚类分析方法分类,结果容易出现类别不清、分类错误的情况。反复验证之后发现,未经处理的数据在随机选取聚类中心时,不同的聚类中心反复迭代之后的结果差别极大。数值本身的多大的量级差也使得计算欧式距离时,各点到聚类中心的距离差别不大,导致分类错误。算法的改进使得聚类初始中心点的选取对分类准确率的影响减弱。同时经过主成分分析,筛选得到的重频、脉宽和脉压比经过归一化和权值的转换,可以提升算法分类的性能,具有较好的效果。实验中,改进算法在各个行为下都以较大优势领先对比的识别算法。
3.2 实验二
为检验主成分分析对算法优化产生了积极作用,对样本数据分别在两组不同雷达行为状态的情况下进行实验,对比分类的准确率。得到如图4所示。
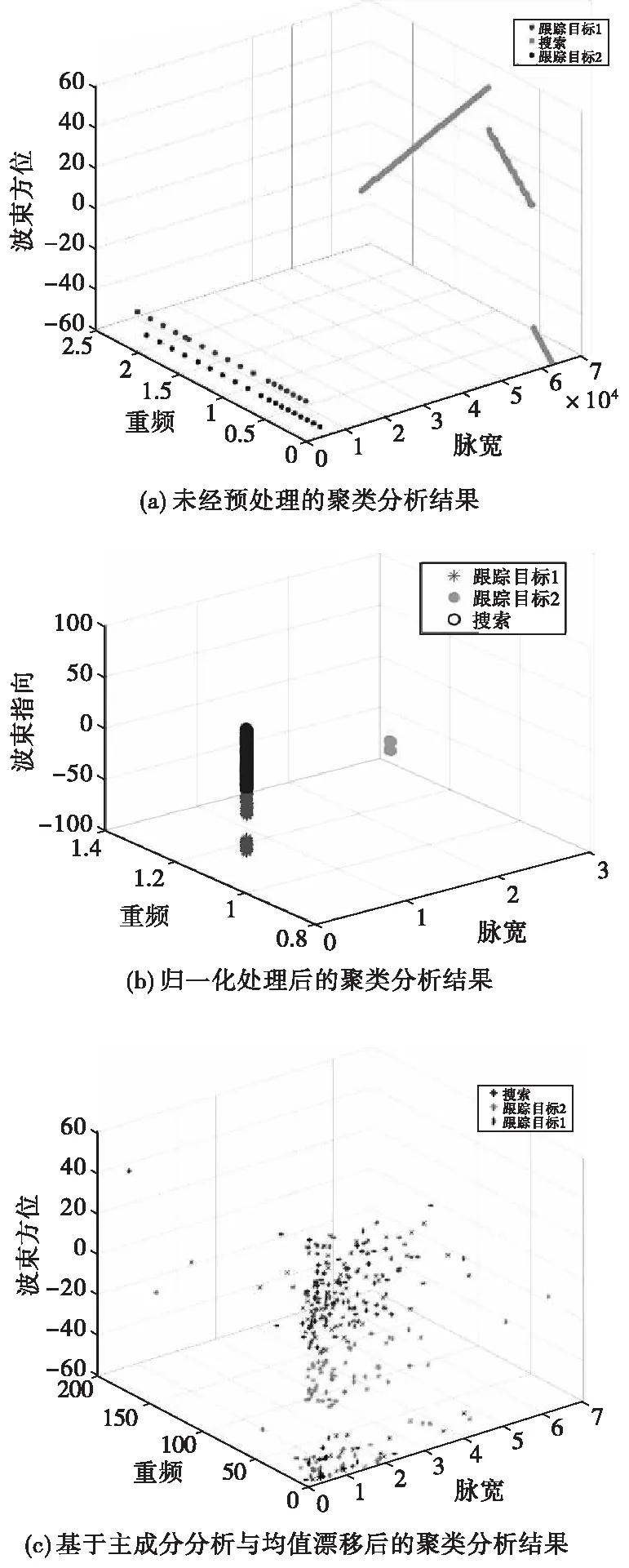
图4 三类聚类算法实验对比Fig.4 Experimental comparison of three kinds of clustering algorithms
实验结果表明,经过经过改进的样本数据更有利于聚类识别。第一组数据的搜索距离不同,使得两类搜索方式的脉宽和重复频率影响聚类的权值比重较大。第二组数据的跟踪目标不同,导致两类跟踪方式的波束方位对聚类结果影响较大。因此第一组数据筛选出的特征参数是重频、脉宽和脉压比;第二组数据筛选出的是重频、脉宽和波束方位。贡献率较大的几类参数能够缓解原始算法类中心的偏移影响问题。
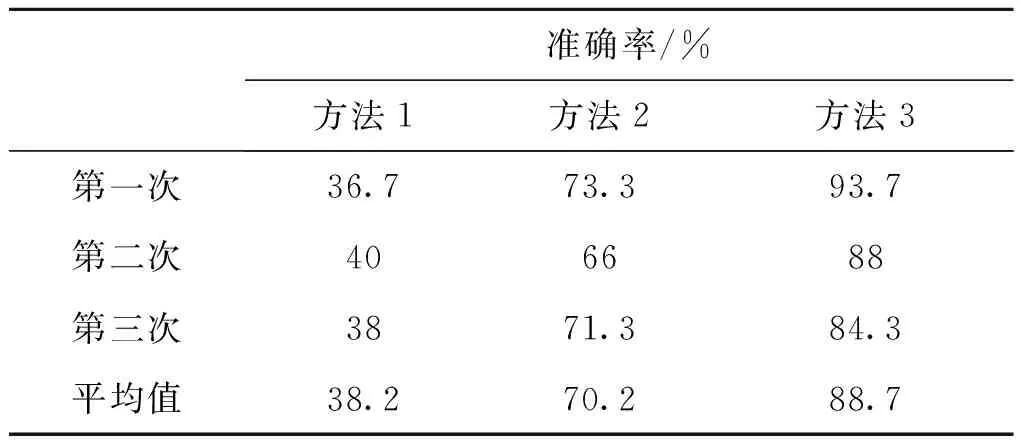
表3 聚类识别准确率
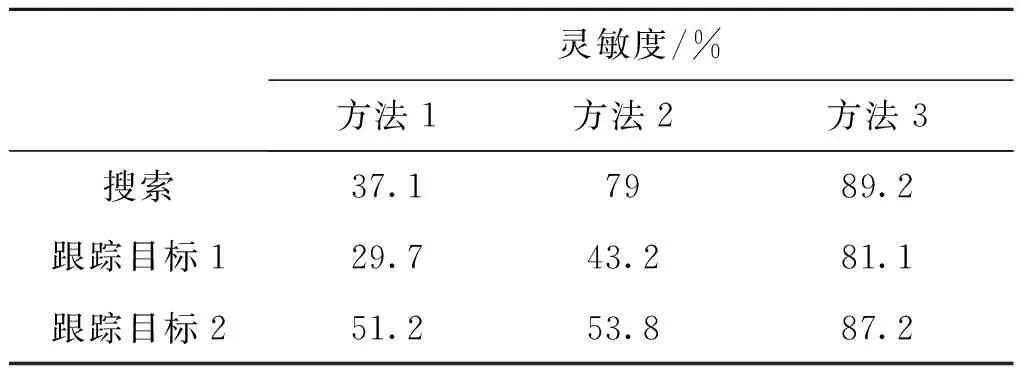
表4 各类雷达行为聚类识别灵敏度
将改进后的聚类算法与文献[7]中的CPI矩阵算法相比,CPI矩阵算法按照经验设定16个或32个脉冲序列为一组时,已经产生了一定的误差。本文算法基于雷达信号参数与工作模式间的本质联系选取特征参数,无需大量训练样本,即可获得相对较高的识别正确率。即使在侦收到少量脉冲信号的情况下也可进行识别,适用于在实际战场中突发未知雷达及信号的采取分析,判断当前雷达行为状态。
4 结论
本文提出了基于主成分分析的雷达行为状态聚类分析算法。该方法克服了现实状况下缺少大量数据样本和先验知识的驱动,无法建立神经网络等有监督识别模型的困难,在适量的样本数据条件下进行雷达行为聚类分析。该方法在使用过程中结合对数处理归一化及主成分分析和均值漂移等办法,降低了数据量级相差过大,聚类中心不稳定等问题的出现频率,可以较好地在训练样本匮乏的条件下,对雷达脉冲特征进行分析。实验表明,从雷达行为与雷达外部特征表现入手,寻找两者之间的映射关系,获取更多规律,挖掘更多信息,避免先验信息对行为识别的限制,对之后的雷达行为识别具有一定意义。显然,当雷达行为相近,雷达脉冲参数排布相似时,对聚类算法会产生一定影响,需要通过不断的研究总结,建立完善合理的雷达行为特征库,通过不断地训练,补充未知雷达行为对应的脉冲序列样式,解决这一问题。
雷达脉冲序列完成聚类后,根据标签或雷达设计准则,能够对每一类的行为状态进行判定。在后续的研究过程中,可以对大样本和小样本分别建立数据库,大样本数据能够利用神经网络、向量机等训练模型,小样本数据可以实时快速分析雷达行为状态并作出应对干扰措施。为了实现雷达的行为辨识,需要不断进行深入研究。能够结合两类识别方法,克服缺陷,达到一定可靠的识别正确率是之后学习研究的主要目标。
猜你喜欢
中学生数理化·八年级物理人教版(2023年11期)2023-12-26 07:50:10
大自然探索(2023年7期)2023-08-15 00:48:21
数学物理学报(2022年3期)2022-05-25 13:33:28
小学生学习指导(低年级)(2018年12期)2018-12-29 11:13:24
中成药(2017年12期)2018-01-19 02:06:54
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
火控雷达技术(2016年3期)2016-02-06 02:30:26
百科探秘·航空航天(2015年4期)2015-11-07 07:04:34
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
