
针对BitTorrent协议中Piece消息的隐写分析方法
2020-05-16 06:33邢俊俊翟江涛刘伟伟
计算机应用与软件 2020年5期
邢俊俊 翟江涛* 刘伟伟
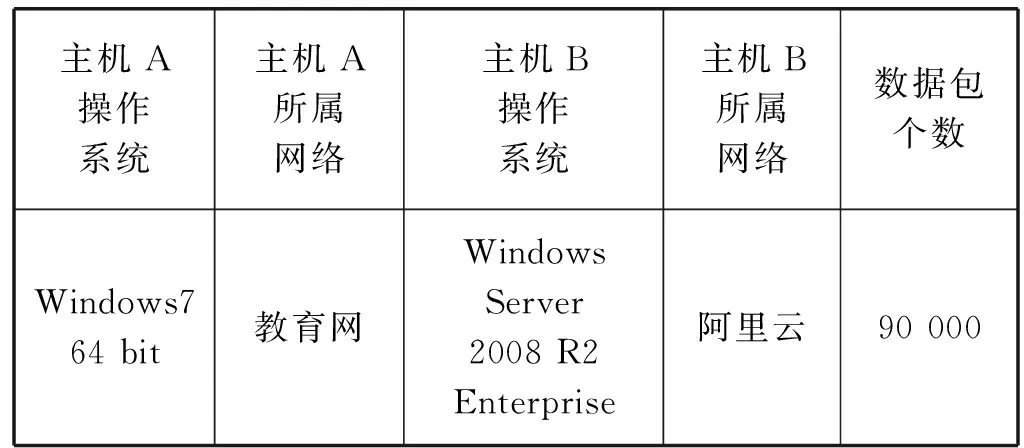
1(江苏科技大学电子信息学院 江苏 镇江 212003)2(南京理工大学自动化学院 江苏 南京 210000)
0 引 言
信息隐藏是指将秘密信息嵌入到正常通信数据流中进行隐蔽通信的一种技术[1-2]。视频、音频、文本、图像等文件都可以用来嵌入隐秘信息[3-5]。近年来,随着人们对该技术重视程度的逐渐提高,相应的检测分析也取得了很大进步,从而使得这类方法的安全性受到极大考验[6-7]。
信息隐藏所选取的载体是网络中动态生成与消失的数据包,相较于传统文件类型,这种载体具备两大优点:其一,网络中的数据包复杂多样且通信流量巨大,监控方很难在海量数据中检测含秘数据流;其二,数据包与图像等多媒体文件截然不同,它在较短的生命周期内就会消失,导致监控方难以在有效时间内对之进行取证。近年来,网络隐写作为一种新的网络隐写术[10]被提出,成为了信息安全的焦点。图1为网络隐写的示意图。
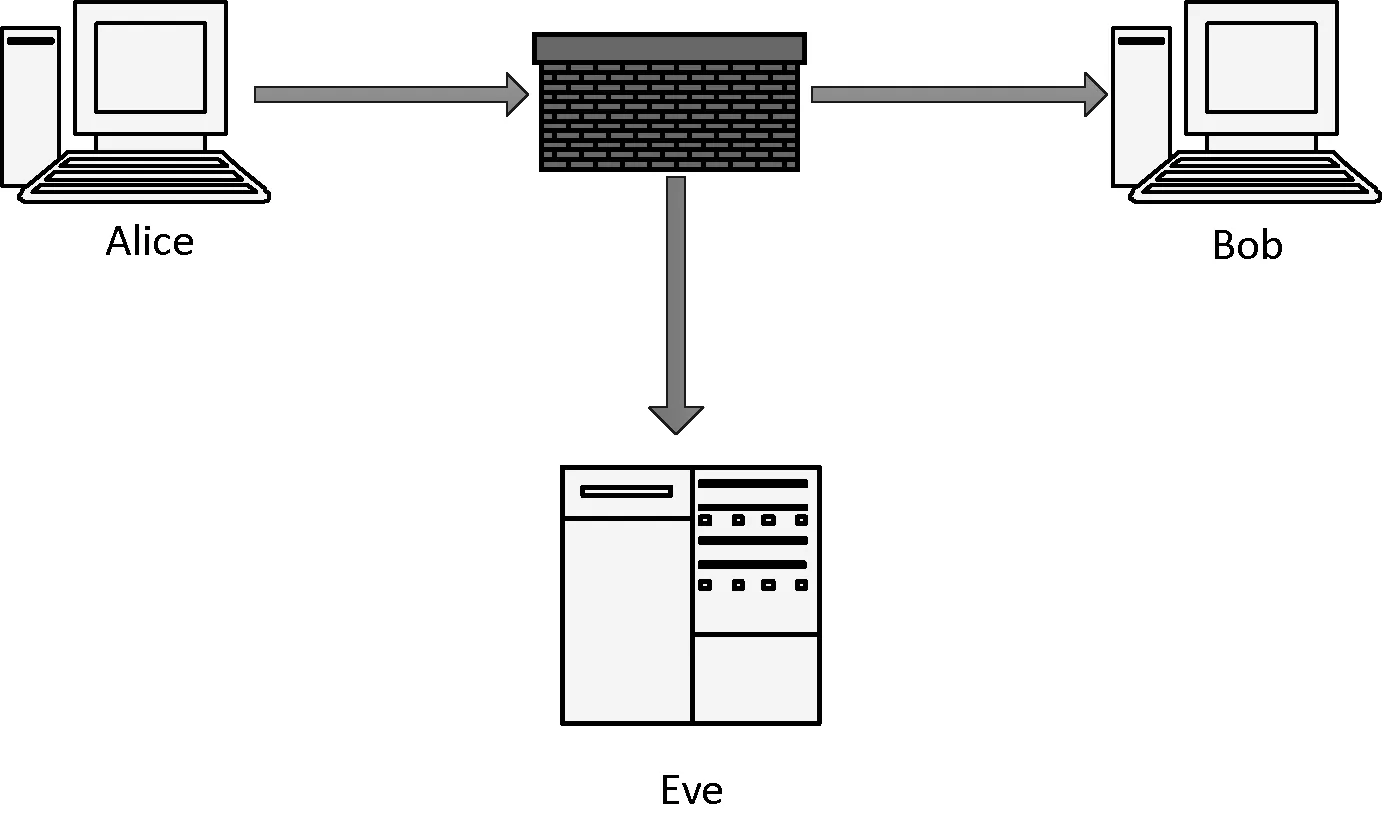
图1 网络隐写示意图
图1中,Alice发送隐蔽信息给Bob,其通信行为对网络监管者Eve来说是透明的,一旦被发现传递敏感信息其链路将被Eve切断。于是Alice将这些隐秘信息编码之后嵌入到网络流中,伪装成正常通信以躲避Eve的检查。
网络隐写可实现隐秘数据的传输,该技术如果被恶意使用,尤其是与高级持续性威胁[11-12](Advanced Persistent Threat, APT)的结合,将有效提高APT的生存能力,给信息安全带来极大隐患。从已有相关资料看,目前已发现的诸如Duqu、Stuxnet、Alureon[13-14]等APT均使用了隐写术来提高自身安全性,给网络空间安全带来了更大的威胁。为了对抗隐写术的非法使用,实现对网络的可管可控可侦,开展隐写检测技术研究势在必行。
1 相关工作
1.1 BitTorrent网络概述
BitTorrent网络是一个文件分发协议,也是经典的混合式对等网络,已经成为Internet中主要的文件共享系统。它主要由种子节点、下载节点、Web服务器和Tracker服务器组成。种子节点创建torrent文件,最后发布到Web服务器上供其他节点下载。torrent文件记录了共享文件名称、大小、校验值和Tracker服务器的IP地址等。下载节点在Web服务器上获取torrent文件,以便于下载共享文件。节点想要下载信息时,首先需要连接Tracker服务器来获取网络中下载该文件的其他节点的IP地址和端口号,从而建立连接。文件的发送与接收都是在节点之间进行,同一时刻在线的节点越多,传输速度越快。
1.2 Peer之间的通信协议
节点间协议是BT网络中通信量最大的通信协议,又称为节点连线协议(Peer Wire Protocol),它是一个基于TCP协议的应用。其正常通信过程如图2所示。

图2 BT节点间的通信时序图
首先,节点PeerA和PeerB之间进行“三次握手”,建立TCP连接;然后,两者进行“两次握手”,建立BT连接;最后,双方进行一系列的BT信息交互,完成文件共享。P2P不同于传统的C/S模式,在此网络中的节点既是资源供给者,又是资源采集者。两者对比如图3、图4所示。
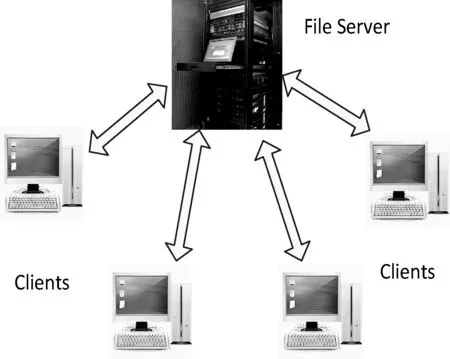
图3 Client/Server模式

图4 Peer to Peer模式
1.3 Peer之间的消息格式
常用BT消息有Keep_alive、Handshake、Choke、Unchoke、Interested、Not_interested、Have 、Bitfield、Request、Piece、Cancel,格式如表1所示。
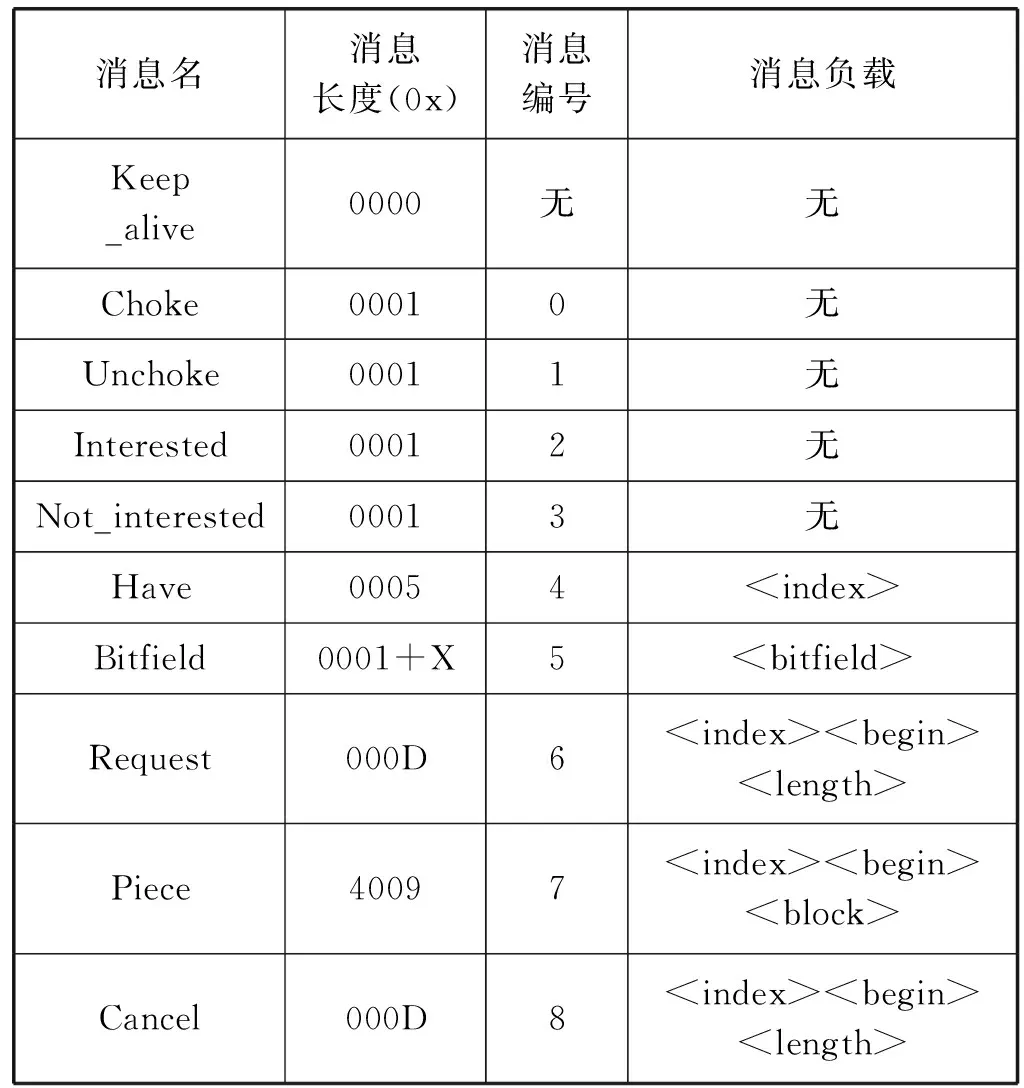
表1 BT消息格式
按照长度可将这些信息分为空消息、通知消息和数据消息,其中Have 、Bitfield、Request、Piece、Cancel属于数据消息,可用于嵌入隐蔽消息。李子帅[15]提出了一种将隐秘信息嵌入到Bitfield消息和Piece消息冗余空间的信息隐藏算法。本文针对P2P中典型的BitTorrent文件共享协议中Piece消息的秘密信息传输方法进行分析,提出一种基于SVM的分类器的隐写检测方法。实验结果表明,所提方法在检测BitTorrent协议中基于Piece消息的隐蔽通信时具有良好的效果。
2 基于Piece消息的网络隐写算法
文献[15]提出了一种基于piece消息的隐写算法,这种算法遵循“最少的优先”的原则,即优先下载占有率最低的数据块,最后利用piece消息传输含密消息和文件。
为了提高算法的鲁棒性,文件被切分为多个子片段,假设秘密信息的大小为U,而Piece消息block域固定为16 KB,则嵌入所需Piece消息数目NP为:
(1)
若待嵌入信息量超过单个数据块大小,单个Block已经无法满足嵌入要求,需要考虑多个Block配合完成信息嵌入,保证BT隐蔽通信的顺利实施。
隐藏算法的主要步骤如下:
输入:待嵌入的Piece消息P,隐秘信息明文M,密钥K。
输出:含秘Piece消息P*。
Step1S=Encrypt(M,K);对明文M加密,得到S及长度|S|。
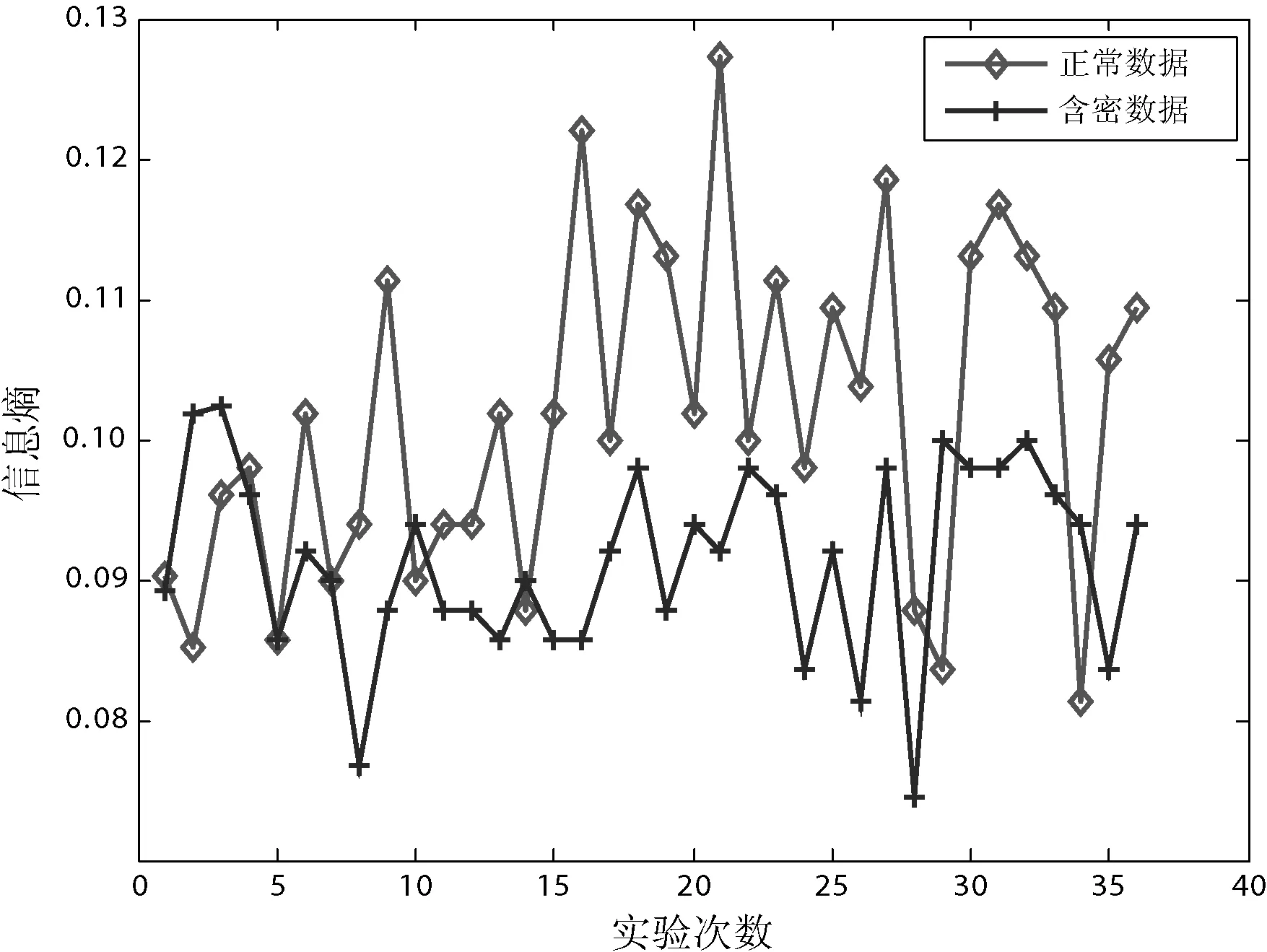
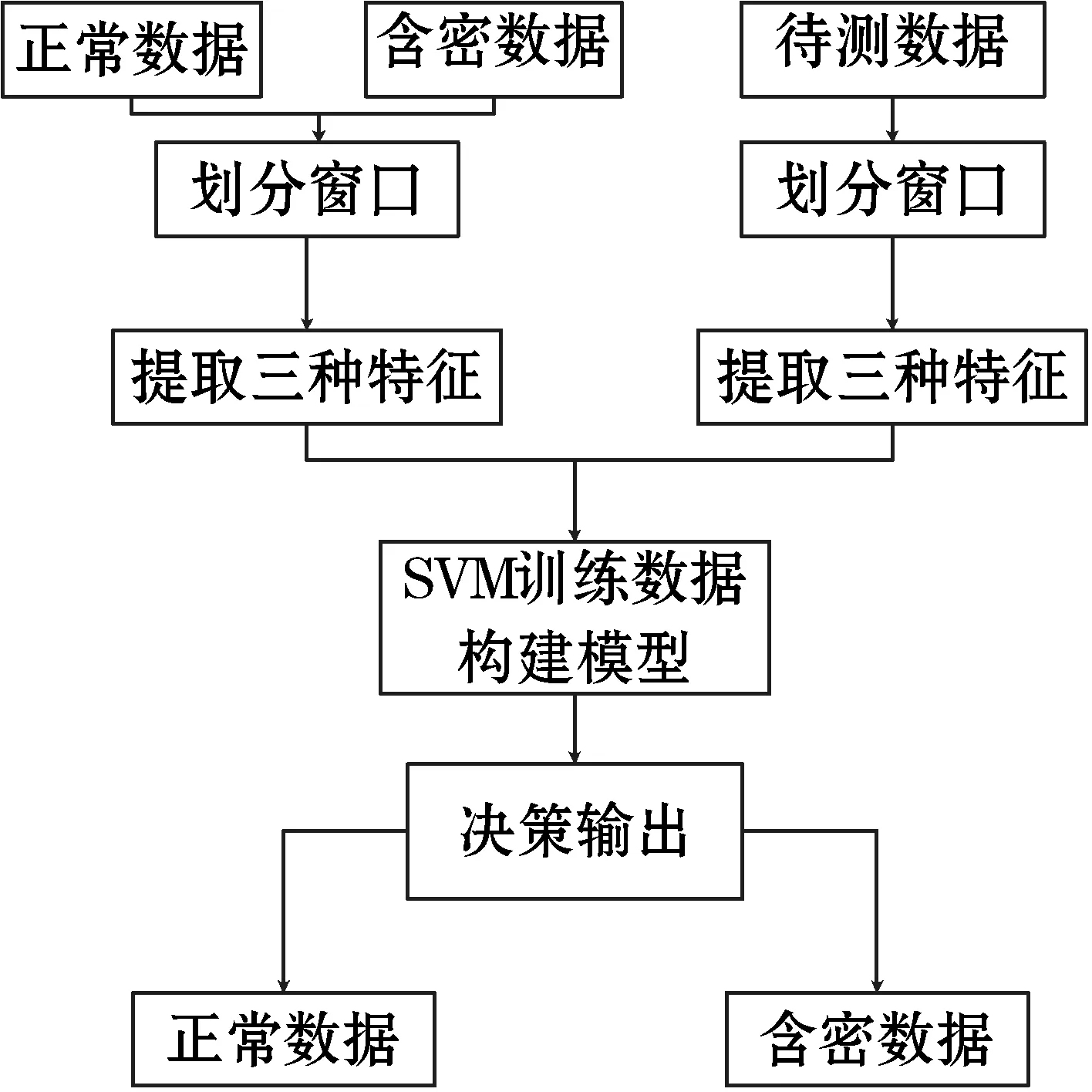
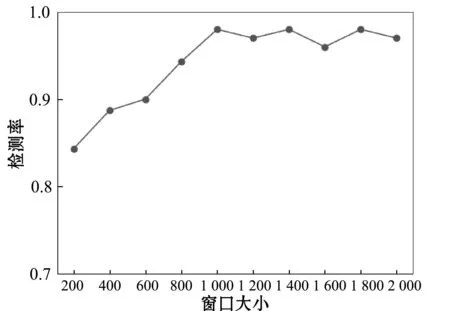
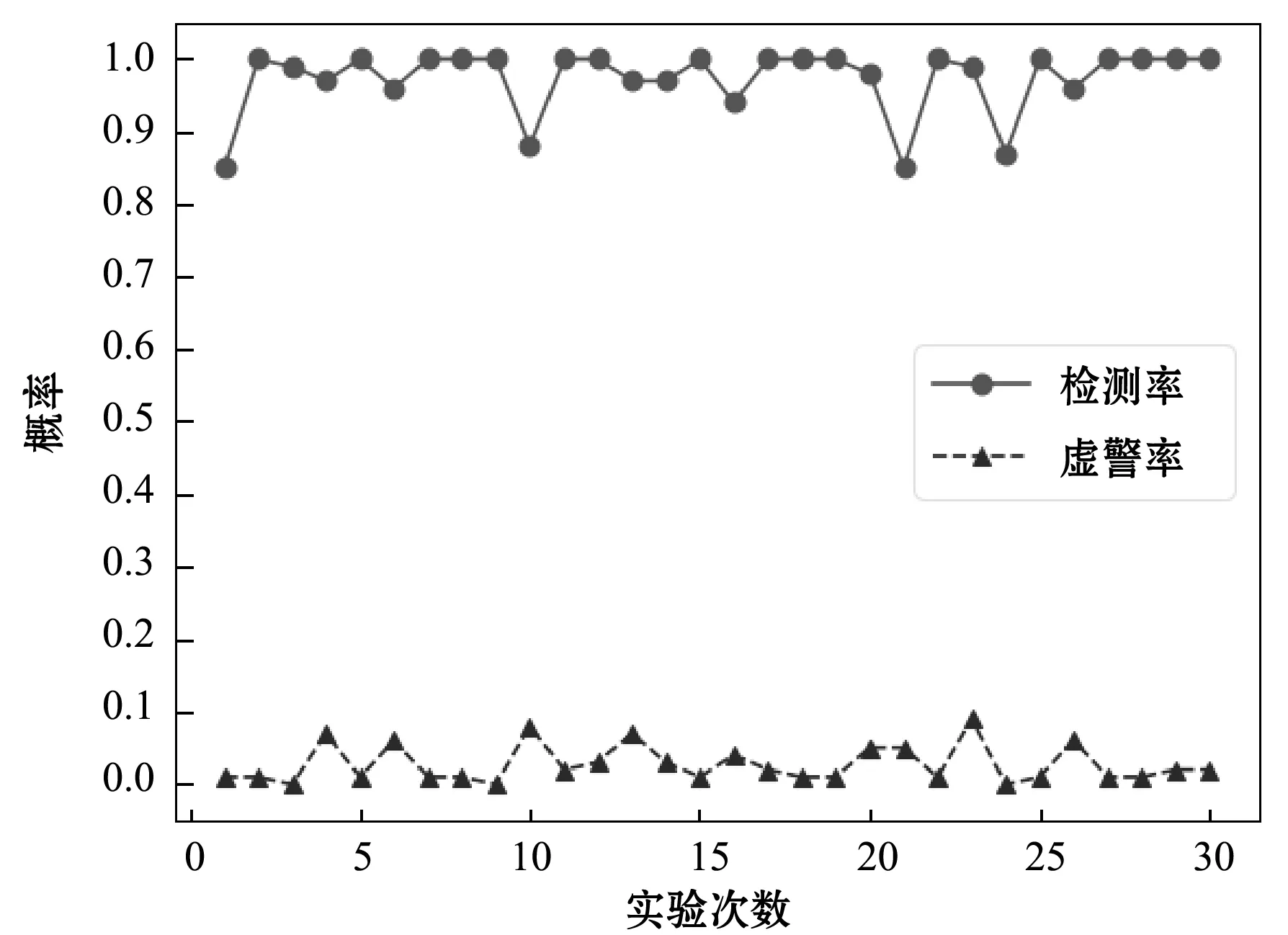
Step2 比较|S|与l,若|S| Step3 通过have消息告知其他节点含有片段P。 Step4 监听来自其他节点的 request消息。如果所请求的为片断P,转到Step5;否则,提示信息隐藏失败。 Step5 发送以S作为负载的piece消息。 Step6 输出P*。 3.1.1 信息熵 信息熵表示了某个信息量的一种期望值,也可以将其视为某个信息呈现的概率。如果系统越复杂,那么它的信息熵就相对较大。事件随机发生的可变性被称为自信息,通常用I(xi)表示。 互信息I(xi;yi)是指在事件yi确定的前提下,事件xi的不确定度的缩减量。若xi和yj为两个相关的事件,当yj发生后,xi的发生几率就会改变,那么自信息量也会随之改变,这个改变量即为互信息。 信息熵为某个事件xi与其自身的互信息I(xi;xi),也可以用H(x)表示: (2) 式中:n为样本中不同信息的数量;p(xi)为每个信息出现的概率。在本实验中,p(xi)是时延信息落在每个划分区间中的概率。 基于Piece消息的信息隐藏算法是以Piece消息中包含的文件片段数据为输入,而Piece消息以网络作为传输渠道,受网络稳定性影响较大。当网络拥塞时,可能会造成Piece消息传输延时、超时或丢失。出现异常时,数据包会被重传,从而导致等待输入信息时间延长[15]。由于网络的不稳定性,含密数据的包间时延会大于正常数据的包间时延,导致信息熵的变化。因此,信息熵可以作为区分正常数据与含密数据的特征。 [30]Mary Patricia Callahan,Making Enemies: War and State Building in Burma, Singapore: NUS Press, 2004, p.120, 166-168. 3.1.2 均值方差 在统计工作中,均值和方差是反映数据资料集中情况和离散程度的两个重要指标。由于正常数据的负载相对较小,所以传输速率更快,对应的包间时延也会更小,其均值小于含密数据。包间时延的均值可由下式计算得出: (3) 式中:n为样本包间时延总数。 因为正常通信的时间间隔不断随网络环境变化,故相对方差不断变化,而隐蔽通信的时间间隔一般固定在几个时间间隔,方差变化相对较小[16]。包间时延的方差可由下式计算得出: (4) 由于正常数据与含密数据的均值和方差存在较大的差异,所以将均值和方差作为区分数据是否含密的两个特征。 支持向量机SVM是对数据进行二元分类的线性分类器,可以使用较少的样本获得良好的实验效果。该方法不仅解决了维数灾难问题,而且训练样本少,有效地节省了时间。 假设G={(xi,yi),i=1,2,…,l}为给定的一个训练样本,每个样本xi∈Rd属于一个分类y∈{+1,-1}。分类曲线表示为: w×x+b=0 式中:w为一个权重向量,b为阈值。 上述问题可以表示为一个分类函数如下: f(x)=sgn(wx+b) (5) 分类器的最优超平面可看作以下最优化问题: (6) s.t. yi[(wxi)+b]-1≥0,i=1,2,…,l 化为对偶问题: (7) (xi,xj),s.t.yi[(wxi)+b]-1≥0 (8) 分类函数变为: (9) 如果线性不可分,可将其转化为高维问题,假设核函数为K(x,y),变换函数用Φ(x)表示,则: K(x,y)=Φ(x)Φ(y) (10) 分类函数用核函数表示为: (11) 本实验使用Vuze4.4客户端参与BT共享文件的传输。通过wireshark分别捕获正常通信与隐蔽通信两种方式下的数据包。实验环境如表2所示。 表2 实验环境 基于信息熵的检测算法是一种非常典型的方法。钱玉文等[7]使用基于信息熵的算法对几种常见的时间式隐写进行了检测,所提算法在复杂的实验条件下也有很高的检测率。基于信息熵的检测算法步骤如下: Step1 从正常数据与待测数据中获取若干数据包样本,根据一定的窗口大小w进行划分。 Step2 将正常数据的包间时延均匀切分成N块并计算包间时延落在块中的概率。 Step3 算出每组数据的信息熵。 Step4 设定含密与不含密的临界值,如果待测数据的信息熵在临界值内则含密,反之则不含密。 本实验利用Java语言编写隐写算法,使用Vuze4.4客户端参与BT共享文件的传输。使用wireshark分别捕获90 000条正常数据和含密数据,提取出两组数据的包间时延,然后求取它们的信息熵。在窗口w为2 500的情况下,选取一组正常数据与含密数据作对比,计算两组数据包间时延的信息熵,结果如图5所示。可以看出,正常数据混乱度较大,而含密数据混乱度相对较小。虽然正常数据和含密数据均有各自的特性,但很难找到一个合适的阈值来区分正常数据和含密数据,可见只用信息熵这一个特征检测不出数据是否含密。 图5 正常数据与含密数据的信息熵 经过4.2中实验可知,含密数据很难被单一的熵值特征完全检测出来。因此,本文通过提取多种特征并进行分类来达到检测实验数据是否含密的目的。多特征分类最重要的就是特征的选取,经过论证,实验选取了包间时延的熵值、均值和方差3种特征实现对正常数据和含密数据的分类。对应的流程图如图6所示。 图6 多特征分类流程 在一定的窗口下,提取正常数据和含密数据的包间时延,将其送入SVM分类器中训练,得到一个多特征模型并用其进行分类。具体检测步骤如下: Step1 窗口划分。从两组数据中混合成待测数据集,按照窗口大小w进行划分。 Step2 特征提取。提取每个窗口中包间时延的熵值、均值、方差3种特征。 Step3 模型训练。分别用标识符“1”和“0”对正常数据和含密数据进行标记。 Step4 将待测数据分割成大小为w的若干窗口,按步骤Step1-Step2提取三种特征。 Step5 用SVM分类器对待测数据进行分类。 本实验通过wireshark分别捕获90 000条正常数据和含密数据,然后提取出两组数据的包间时延混合组成训练集,按大小为w的窗口进行分割。其中70%用于训练,30%用于测试。按照前面介绍的方法,计算出不同窗口下的均值、方差及信息熵3种特征,使用SVM分类器进行训练与测试,最后得到检测结果。 1) 窗口大小w对检测率的影响。检测方法的第一步就是要划分窗口,窗口大小的变化意味着每个窗口所包含的数据包数量不同。当划分窗口大小w为1 000时,可以得到90组正常数据和90组含密数据,分别选取其中的63组数据作为训练集,余下的27组数据作为测试集。通过训练集的多特征建立模型,用标识符“1”和“0”对正常数据和含密数据进行标记。然后用SVM分类器对待测数据进行检测分类。为了分析窗口大小w对检测率的影响,分别取w在取值200、400、600、800、1 000、1 200、1 400、1 600、1 800、2 000这10种情况进行实验,对不同窗口下的检测率进行比较分析。图7即为w对检测率的影响结果。可以看出,随着窗口增大,检测率逐渐提高并趋于稳定。这主要是因为更多的数据量能够提供更为准确的特征,从而检测出正常数据与含密数据。 图7 窗口大小对检测率的影响 2) 本文方法的检测结果。以1 000个数据为窗口分割全部数据,进行30次实验,结果如图8所示。可以看出,每次实验结果略有不同,这是因为每次实验都是随机抽取70%的数据作为训练样本,从而导致训练出的模型有所不同。每次实验的样本不同会导致检测率有所波动。本文提出的基于多特征的检测算法的检测率的均值为0.947,虚警率的均值为0.05。 图8 本文方法的检测结果 本文以一种BitTorrent协议中Piece消息的隐写方法为研究对象,提出了一种基于多特征的检测方法。所提方法通过提取均值、方差和信息熵三个特征,使用SVM分类器来区分正常数据和含密数据。实验结果显示,当窗口w大于1 000时,本文所提方法对此类隐蔽通信具有较好的检测效果。 本文方法仅针对Piece隐写这类隐蔽通信,在适用性上尚需改进,未来将以BitTorrent网络为研究对象,开展适用性更强的隐蔽通信检测算法研究,以提高对BitTorrent网络窃密的防护能力。3 算法设计
3.1 特征提取
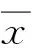
3.2 SVM分类器
4 实验与分析
4.1 实验环境
4.2 基于信息熵的检测算法
4.3 基于多特征的检测算法
5 结 语
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
电脑知识与技术(2021年22期)2021-09-14
电脑知识与技术(2021年22期)2021-09-14
现代信息科技(2021年21期)2021-05-07
喜剧世界·中旬刊(2020年10期)2020-09-10
花火B(2019年3期)2019-04-27
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
三月三(2017年4期)2017-04-25
三月三(2017年4期)2017-04-25
中国水运(2016年11期)2017-01-04
