
基于注意力机制和特征融合改进的小目标检测算法
2020-05-16 06:33麻森权
计算机应用与软件 2020年5期
麻森权 周 克
(贵州大学电气工程学院 贵州 贵阳 550025)
0 引 言
目标检测是计算机视觉的基本任务之一,广泛应用于无人驾驶、安全系统和瑕疵检测等领域。随着卷积神经网络(CNN)的快速发展,Girshick等[1]提出了一个R-CNN框架,将目标检测问题转化为分类问题。在此框架中,使用选择性搜索[2]提取候选区域提议,然后,CNN从候选区域提议中提取特征,最后,R-CNN通过支持向量机(SVM)分类器对这些特征进行分类,并对候选区域提议执行边界框回归。R-CNN是目标检测的开创性工作。结果表明,R-CNN比使用手工设计功能的传统方法要好得多。为了提高效率并处理任何大小输入,Gir-shick进一步提出了FastR-CNN[3]框架,该框架显著提高了R-CNN的效率和准确性。FastR-CNN采用感兴趣区域(ROI)池化策略,允许网络以更快的速度提取任何大小的提议窗口上的高级特征。然而FastR-CNN也使用选择性搜索来提取候选提议,并且特征提取和对象分类的过程是分开的。Ren等[4]提出了FasterR-CNN网络,其中候选区域提议由RPN(RegionProposalNetwork)提供。该方法可以训练端到端网络,并实现更好的检测性能。但是,在一组卷积和池化层之后,FasterR-CNN中最后一个卷积层的特征映射很小。在最后的特征映射中,原始图像中的对象也小得多,难以定位,因此FasterR-CNN无法很好地解决小对象检测问题。同时,完全卷积网络(FCN)[5]已经被提出并被证明擅长语义分割任务。FCN中,结合卷积和池化的网络接收图像并输出特征图,特征图使用解卷积图层来获取与输入图像大小相同的输出图像。最后,比较输入图像和输出图像以获得基于像素的分割结果。FCN在PASCALVOC分割方面取得了良好的效果[6]。通过FCN网络,输入图像将被下采样,最后一个特征图比输入图像小32倍。因此,不可能直接进行语义分割。但是,它使用反卷积层将要素图上采样到与原始图像相同的大小。最后,它对最后一个特征图的每个像素进行分类,以获得分割结果。从FCN的网络结构中,反卷积层将恢复在提取特征的过程中容易丢失的信息。
Redmon等[7]提出了YOLO(YouOnlyLookOnce)算法,该算法是端到端网络架构,网络的输入是图像内容,输出是边界框和相关类概率的信息。YOLO的第三个版本——YOLOv3[8],将高级网络与低级网络连接起来,从高级功能和早期功能图中的细粒度信息中获取更有意义的语义信息。这种信息融合方式在一定程度上提高了小物体的检测性能。然而,这样的设计没有充分利用低级信息,并且缺乏多样的接受领域。因此,它在检测小尺寸和易于聚类的对象方面很弱。
在端到端的单级目标检测算法中,Liu等[9]提出一种SSD算法,该算法兼顾了YOLO算法的检测速度和FasterRCNN算法的检测精度。但是由于SSD使用conv4_3低级feature在应用于小目标检测时的低级特征卷积层数较少,存在特征提取不充分的问题,从而对小目标检测的效果一般。
受注意力机制[10]思想的启发,本文在DSSD算法的框架中引入注意力通道,保留更多的目标特征信息,抑制无关信息,进一步提升DSSD算法应用于小目标的检测效果。
1 SSD系列目标检测算法
1.1 SSD算法
SSD(SingleShotMultiBoxDetector)是目前较流行的检测框架之一,相比于FasterR-CNN算法在检测速度上有明显优势,而相比于YOLO又有明显的精度优势[9]。SSD网络结构如图1所示。SSD使用预先训练的VGG16神经网络作为核心,然后将具有小滤波器的卷积层添加到神经网络的顶部,因此可以使用不同的卷积操作对多个不同尺度的目标进行检测,并在SSD网络顶部的卷积层中产生固定尺度目标的预测结果。SSD算法中设计了不同宽高比的默认检测框,并应用于多个特征图中,在每个特征图中使用3×3的卷积核提取目标预测框的特征信息,其中包含类别信息和位置信息,并在网络训练过程中通过不断调整相对于默认框的类别置信度和位置偏移量,使得预测框可以更加准确地表达出预测目标的类别和位置信息。SSD算法的网络设计可以进行简单的端到端的模型训练,使得低分辨率输入的图像上也能达到很高的检测精度。
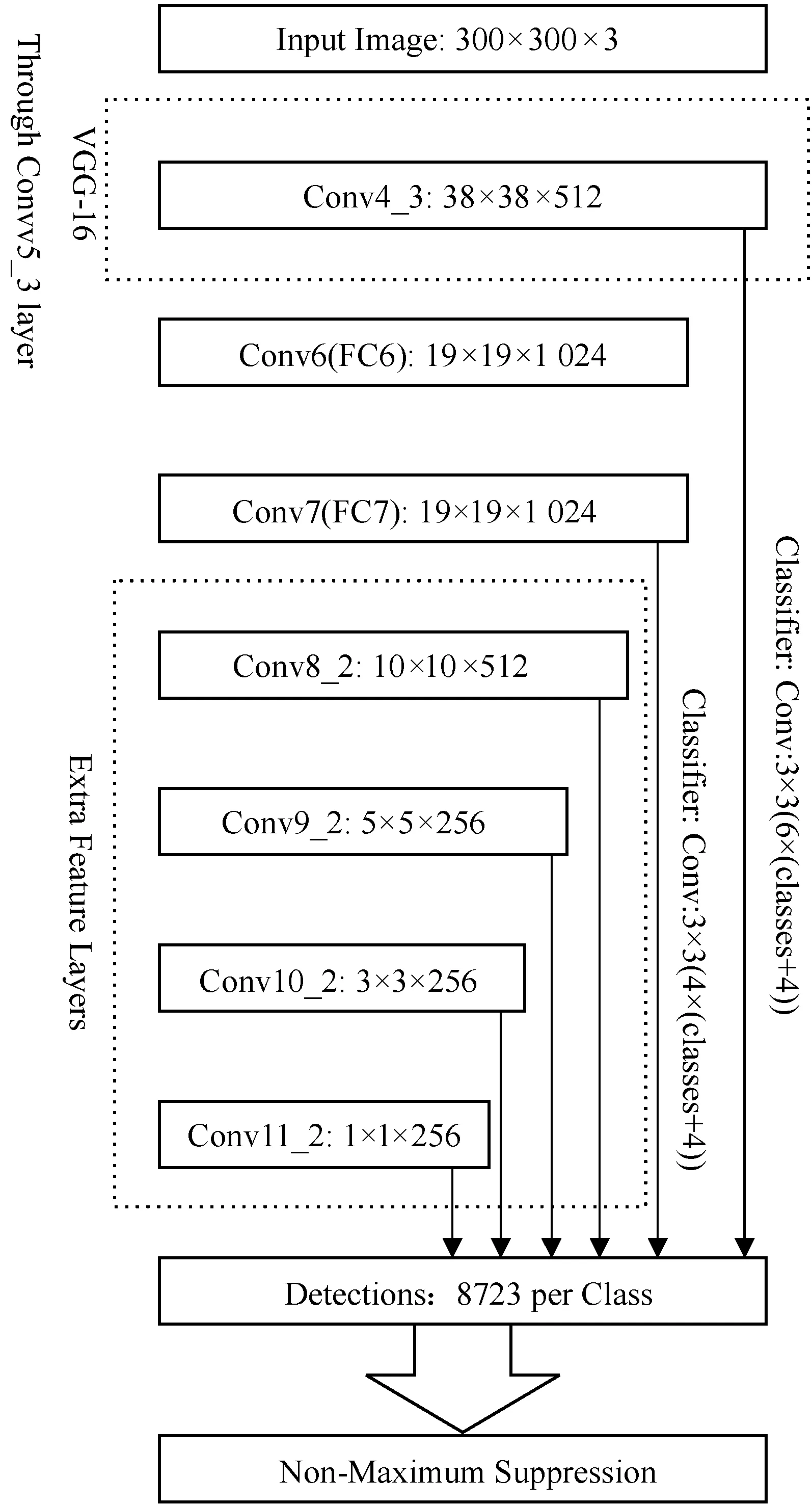
图1 SSD神经网络结构图
1.2 DSSD算法
DSSD[11]算法是对SDD算法的优化,其目的是通过解决多尺度融合问题用于快速地检测目标物体。在网络框架上,DSSD的主干特征提取网络使用ResNet替代了SSD中的VGG16网络,并且将网络层中的特征图用乘法(EltwProduct)完成信息融合,将上层特征图的语义信息与下层特征图的语义信息融合成多尺度的特征图,使得预测回归位置框和分类任务的输入特征图多样化。这不仅提高了目标检测的精度,也使得DSSD网络模型对小目标物体的检测有了一定的提升。
2 注意力机制
注意力在人类感知中起着重要作用[12]。人类视觉系统的一个重要特性是不会同时处理整个场景。相反,为了更好地捕捉视觉结构,人类利用了一系列的局部扫视并选择性地聚焦于突出的部分[13]。
最近在目标检测领域有人提出将注意力机制引入到CNN网络中来提高大规模分类任务的性能。Wang等[14]提出使用编码器式注意模块的剩余注意网络。通过细化特征图,该网络不仅性能良好,而且对噪声输入具有鲁棒性。Hu等[15]引入一个紧凑的注意力特征提取库,使用全局平均汇集特征来计算通道关注的信息权重。Woo等[16]基于一个有效的体系结构同时利用空间和通道注意模块来关注更多信息,取得了很好的效果。徐诚极等[17]将注意力机制引入到YOLO算法中,提高了检测精度。受此启发,本文结合DSSD算法的特点,引入注意力模块做进一步研究。
3 改进DSSD算法
3.1 算法框架总体结构
对于常规物体,SDD算法兼顾检测精度和检测速度,但是在对小目标低分辨率的物体检测中,SSD算法以及改进过的DSSD算法都存在漏检的情况。这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。对此本文在SSD网络框架中引入力模块,保留更多的目标特征,并且进一步通过特征融合,抑制无关信息,提高检测精度。引入注意力模块的DSSD算法的模型结构如图2所示。

图2 引入注意力特征融合模块的神经网络结构图
在该网络中,首先通过注意力模块增强低层网络的信息表征能力,使得感受野更关注目标特征,然后与高层网络中的上下文信息进行融合,增强对检测目标的定位能力。
3.2 注意力模块结构
注意力模块的结构如图3所示,主要由通道注意力和空间注意力两部分组成。

图3 注意力模块结构图
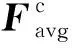
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=
(1)
式中:σ表示是Sigmod激活函数;W0和W1分别为共享全连接层MLP的权重。
第二步利用特征间的空间关系生成空间注意力特征图,空间注意力特征图主要关注目标所在位置的特征信息,它是对通道注意力特征图的一个补充。为计算空间注意力特征图,沿通道应用平均池化和最大池化操作,并将它们连接起来以生成有效的特征描述符。在信息区域中,应用池化操作可以有效地提高通道中目标特征的显著程度[18]。
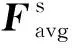
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)])=
(2)
式中:f7×7为卷积操作,卷积核为7×7的卷积层。对于一个输入特征图F∈RC×H×W,其中C、H、W表示的是特征图的长度、宽度和通道数,经过注意模块的计算过程为:
F′=Mc(F)⊗F
F″=Ms(F)⊗F′
(3)
式中:⊗表示元素乘法,在乘法过程中注意特征值被相应地传播;F″为最终确定的输出。
3.3 特征融合模块结构
参考文献[19]对DSSD网络的改进方法,本文设置三个高低层网络融合模块直接对检测目标进行分类和位置回归,以简化复杂运算,提升网络模型的效率。融合模块的结构如图4所示,以融合Conv3_3特征图和Conv15_2特征图为例,首先对Conv15_2特征图进行卷积核大小为2×2、通道数为256的上采样操作,输出结果通过卷积核为3×3的卷积层映射输出至修正激活函数层(Rectified Linear Unit,ReLU)和正则化层NB后再次卷积,为防止过拟合再进行一次正则化。Conv3_3特征图直接经过卷积、激活函数修正和正则化后与采样后的Conv15_2特征图进行求和操作(Eltw Sum),随后添加一个3×3的卷积层以确保检测的特征具有可分辨性,最后在一个ReLU层后实现融合功能。

图4 特征融合模块结构图
4 实验分析
4.1 模型训练
本文采用SDD算法的训练方式对模型进行训练,首先,将一组默认框与设定的目标真实框进行匹配,对于每个真实框,将其与最佳重叠的默认框以及JacCard系数大于阈值(比如0.5)的任何默认框匹配。然后在没有匹配的默认框中,根据置信度损失值选择某些框作为负样本,负样本与匹配框的比率为3∶1。最后将联合定位损失值(比如平滑损失函数L1)和置信损失值最小化。
模型训练在ImageNet数据集上进行预训练,该数据包含了1400万幅图像,2万多个类别,其中至少100万幅图像提供了边界框,提高模型的泛化能力。实验环境在Ubuntu16.04LTS操作系统下进行,深度学习框架为Tensorflow,开发语言为Python3.6。硬件配置包括CPU为Intel i7-7700,主频3.6GHz,内存为36GB;GPU为Nvida GTX1080Ti,显存11GB。
4.2 小目标检测效果分析
将预训练好的模型分别应用于含有大量小目标的纺织物瑕疵检测和遥感图像目标检测。纺织图片选用的TILDA数据集,其中共有3200幅图片,包括的瑕疵有污渍、破洞、断纬等。遥感图像使用的是VEDAI航拍图像数据集,图片中包括飞机、汽车等目标。对两个数据集分别随机抽取80%图像进行训练,其余20%图像进行测试,并与DSSD算法进行对比。实验中发现,影响检测效果的因素主要有两个,分别是错检和漏检。图5是在TILDA数据集上某幅图片的检测情况,其中:(a)中标注了8个待检目标;(b)为DSSD算法的检测效果,共检测出了4个目标,漏检4个目标;(c)为本文算法的检测效果,共检测出了6个目标,漏检2个目标。图6是在VEDAI数据集上某幅图片中航拍目标检测情况,其中:(a)中标注了9个待检目标;(b)为DSSD算法的检测效果,共检出了6个目标,漏检3个目标;(c)为本文本算法的检测效果,共检出7个目标,漏检2个目标,错检1个目标。

(a) 原图待检目标

(b) DSSD算法检测效果

(c) 本文算法检测结果图5 TILDA纺织物瑕疵检测效果对比图

(a) 原图待检目标

(b) DSSD算法检测效果

(c) 本文算法检测结果图6 VEDAI遥感图像物体检测效果对比图
本文实验统计了10次在进行模型测试时对小目标检测的平均检测数据,包括正确检测率、漏检率和错检率,如表1所示。本文算法相对于DSSD算法在TILDA数据集上和VEDAI数据集上的漏检率分别降低了7.8%和4.7%,有效提高了对小目标的检测效果。本文算法的不足之处是在错检率上分别有7.8%和10.9%,相比于DSSD算法增加了0.6%和1.3%。下一步将研究错检率增加的原因并通过改进来降低错检率提高算法的检测效果。
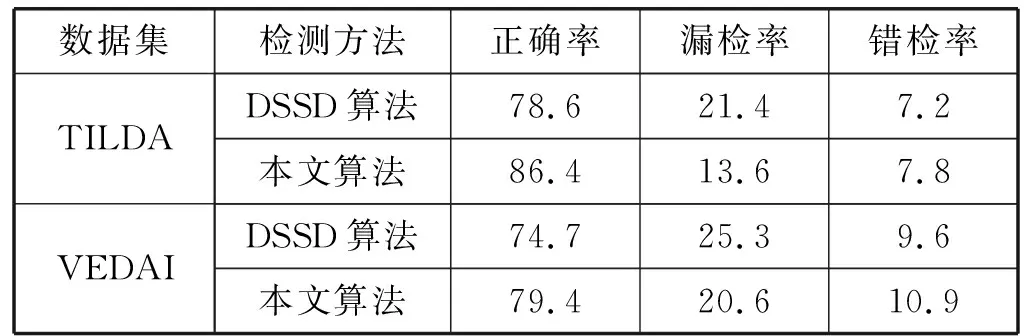
表1 10次模型测试时的小目标平均检测数据 %
4.3 算法性能评价
综合实验结果,分别在两个数据集上采用平均精度均值(Mean Average Precision,mAP)和每秒帧率(Frame Per Second,FPS)两个指标,对比评价本文算法和DSSD算法的对于包含小目标的检测精度和检测效率。各项数据如表2所示,可以看出,本文算法相对于DSSD算法在TILDA数据集和VEDAI数据集上目标检测的平均精度均值分别提高了2.5%和4.4%,每秒帧率提高了1.7和1.4。结果表明,本文算法在DSSD算法的基础上加入了注意力机制模块进行特征整合,有效提取了小目标的特征信息,提高了目标检测精度,同时提升了的检测效率。
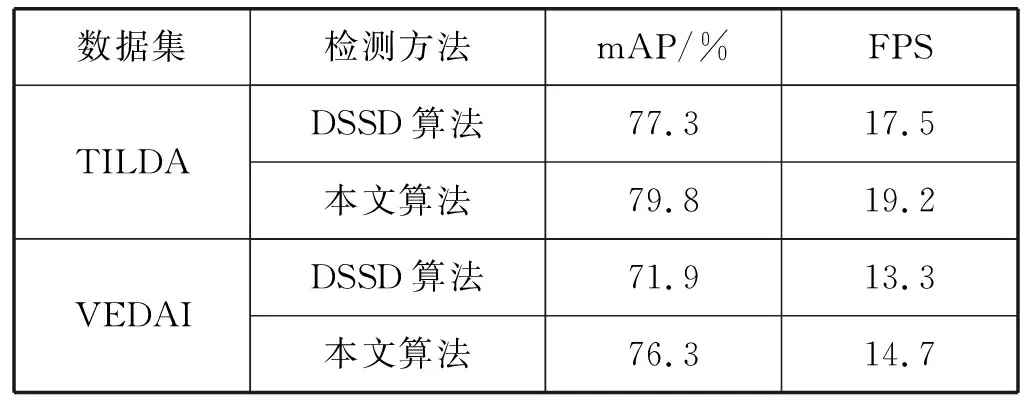
表2 评价指标对比
5 结 语
为解决SSD系列算法在检测小目标中的不足,本文在DSSD算法的框架中引入了注意力机制模块,可以有效提取小目标的特征信息,并且通过特征融合的方式对小目标进行位置回归,提高了原算法的检测精度,证明了注意力模块可以有效提升深度学习网络的性能。下一步将参考本文方法对其网络进行改进,寻找最优的网络模型用于图像中的小目标检测。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
第二课堂(课外活动版)(2016年2期)2016-10-21
读者(2015年9期)2015-05-04
意林(2011年10期)2011-05-14
