
基于强化学习Actor-Critic算法的音乐生成
2020-05-16 06:33白勇齐林帖云
计算机应用与软件 2020年5期
白 勇 齐 林 帖 云
(郑州大学产业技术研究院 河南 郑州 450001)
0 引 言
音乐作为一种表达情感的艺术形式,在市场上有着很高的需求。目前专业的音乐创作者数量有限,且音乐制作费时费力,成本较高[1]。但随着计算机技术的发展,利用神经网络自动生成音乐成为了可能,可以在降低音乐制作成本的同时提高音乐作品的生产力[2]。
如今,递归神经网络RNN和长短期记忆网络LSTM被大量应用在序列预测和音乐生成方面[3]。文献[4]使用了RNN网络结构,通过真实音乐数据集的训练实现音乐的有效生成。文献[5]基于LSTM网络进行自动作曲,LSTM很好地避免了梯度消失问题,并且能够学到音符之间的长期依赖关系。文献[6]利用LSTM网络的结构特点,学习并生成富有节奏的打击乐。以上叙述中虽然使用的网络不同,但训练RNN和LSTM生成音乐的标准方法都是在给定前一个正确音符的情况下最大化预测音符的对数似然,这种方法通常称为teacherforcing[7]。在生成时,输出通常是根据所学习到的分布近似搜索最可能的候选者来产生。在此搜索过程中,模型以其自身的猜测为条件,这可能是不正确的,从而导致错误的生成,对于较长的音乐来说,这个问题将会更加明显。由于训练和测试条件之间存在这种差异,表明teacherforcing可能不是最理想的方法[8]。
本文借鉴强化学习提出一种训练音乐生成网络的方法,旨在模拟生成阶段直接对生成策略进行改进。加入并训练一个称为Critic的附加网络来输出生成音符的价值,该价值可以定义为预期特定任务的得分。这样做能在很大程度上规范生成的音乐,生成网络将要执行下一步输出时会接受这个得分,并根据得分的大小改变自己的生成策略。
1 字符级LSTM音乐生成网络
1.1 字符级LSTM网络
递归神经网络RNN处理较长时序序列存在梯度消失的现象,以至于让网络学不到知识。为了捕捉音符之间的长期依赖关系,本文使用了LSTM网络作为音乐生成网络[9],这是RNN网络的改进结构,引入了带有门控制结构的简单记忆单元。这些门使LSTM网络能够在长序列中学习有用的依赖关系,其网络结构如图1所示。
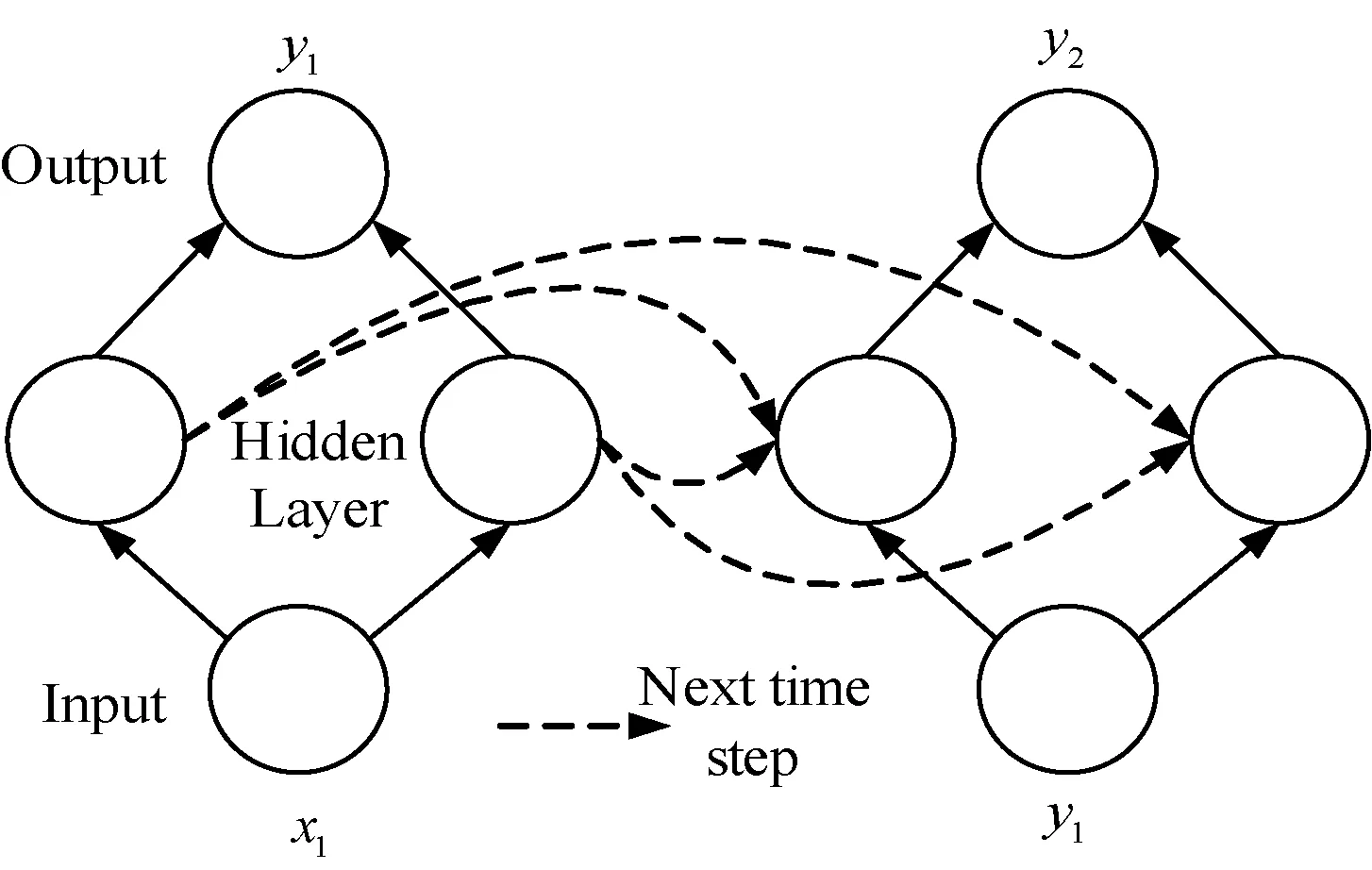
图1 LSTM网络结构
用x0,x1,…,xt表示输入序列,h0,h1,…,ht表示隐藏层数据,y0,y1,…,yt表示输出序列。U是输入权值矩阵,W是上一时刻隐藏层权值矩阵,f是隐藏层的激活函数,隐藏层的输出计算公式如下:
ht=f(Uxt+Wht-1)
(1)
有了隐藏层的输出之后,进过输出层的激活函数δ和权值矩阵V可以得到输出序列,公式如下:
yt=δ(Vht)
(2)
1.2 训练LSTM网络
本文方法的第一步是得到经过训练的LSTM音乐生成网络的权值参数,为Actor网络和Critic网络提供初始参数,目的是让二者具备经过常规训练之后LSTM音乐生成网络的权值参数。LSTM音乐生成网络分为三层:输入层、隐藏层和输出层,其中隐藏层所含神经元个数设置为512。神经网络的输入为向量形式,所以将数据预处理得到的输入向量Xn输入网络中,具体流程如算法1所示。
算法1 训练LSTM音乐生成网络
输入:训练数据
输出:网络模型参数
1.输入训练数据,设置迭代次数,批量大小,隐藏层单元数和网络层数。
2.取当前时刻神经网络的输出和下一时刻输入作交叉熵为损失函数,以此更新网络参数。
3.按照步骤2循环更新,直至迭代完成,loss值收敛。
4.输出LSTM音乐生成网络的模型参数(权值参数)。
2 利用Actor-Critic训练网络
2.1 Actor-Critic
强化学习(RL)针对的是基于弱监督的有效行动问题,其方式是对智能体(agent)的行为给予奖励,从而控制agent的行动达到最优的效果[10]。在Actor-Critic(A-C)算法中,Critic网络会根据Actor网络的输出动作给出一个任务分数,即时间差分TD。Actor网络根据TD更新自己的生成策略,从而使生成的动作更加符合当前的环境和状态[11]。
本文借鉴Actor-Critic算法的思想和术语在常规训练的基础上给予生成网络一种模拟生成阶段的训练方式。本次训练中将基于字符级LSTM音乐生成网络视为Actor网络,生成音符序列并接受设定的任务分数,根据接收的分数再次更新生成策略,优化生成结果。本文将特定的任务分数设置为时间差分TD,由LSTM网络和音乐理论规则共同构成Critic网络输出。两个网络中的LSTM网络由上文得到的权值参数进行初始化。具体流程如图2所示。
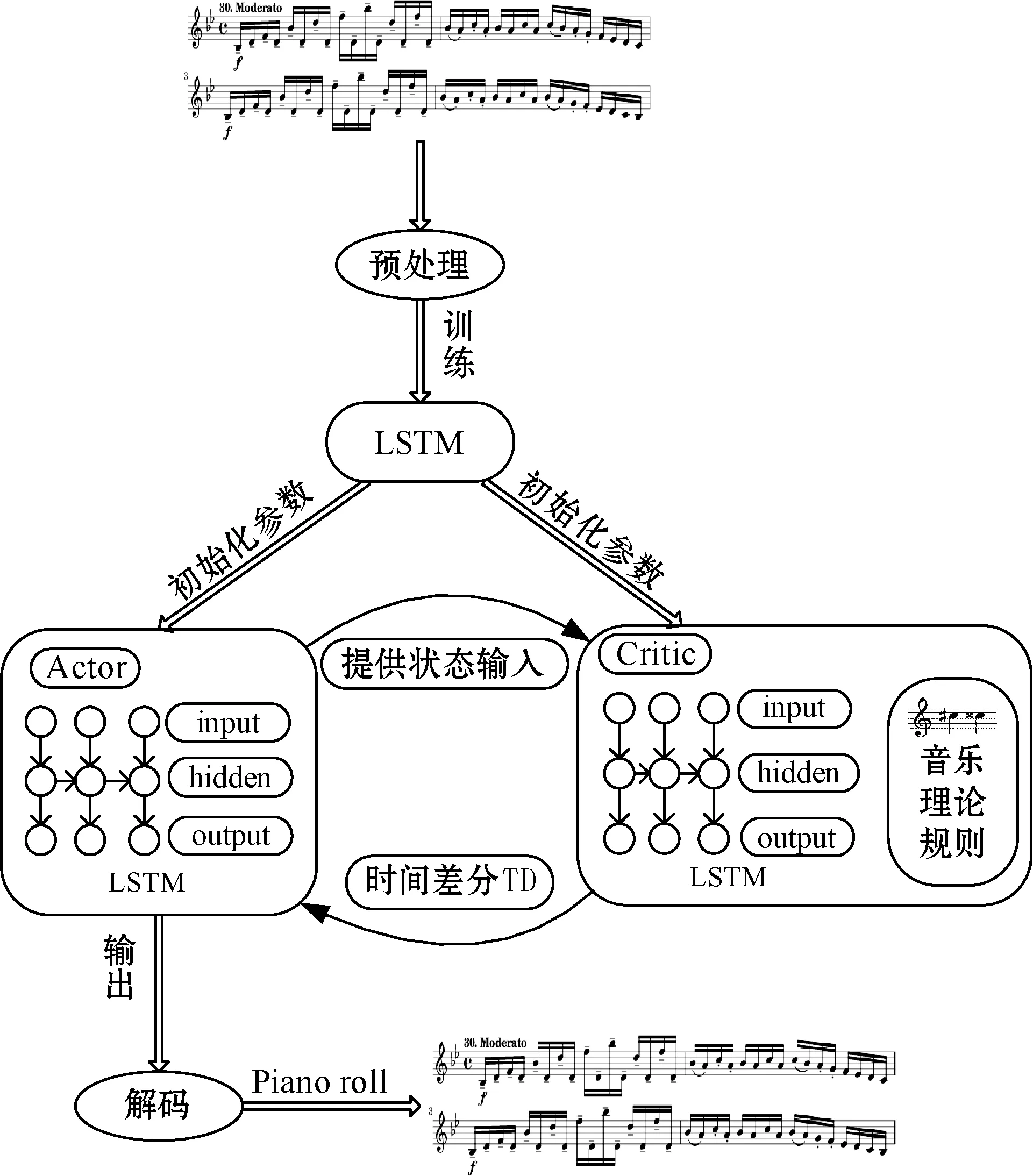
图2 本文方法流程
2.2 时间差分TD
在A-C算法中任务分数为时间差分TD,是一种无模型的强化学习方法。而本文借用其思想和术语构成基于模型的动态规划方法,利用状态价值和音乐理论规则共同构成时间差分TD。
2.2.1 状态价值
本文把已生成的音符和LSTM的内部状态即通常说的“细胞状态”看作状态st,把生成的音符看作被选择的动作at,执行该动作后进入下一时刻的状态st+1。在同一状态下每个音符被选择的概率是不同的,为了让模型更加严格的遵循从数据中学习到的规律,避免因先前错误的猜测而继续发生更大的错误,设置在同一状态下Softmax层音符被选择概率的方差为该状态的价值。设状态s下,每个音符被选择的概率为Pi,其中i=1,2…,n,EP为该状态下音符被选择概率的均值,那么由此可以得到状态s的价值V:
(3)
2.2.2 音乐理论规则
在真实的编曲过程中,作曲家是按照一定的音乐理论规则作曲的[12],为了给予更真实的生成反馈,本文在Critic网络增加了音乐理论规则部分。
音乐有着各种各样的风格,每种风格都有着各自不同的创作理论规则。古典音乐的理论经过长时间的演进已经非常成熟,所以本文参考了文献[13]定义了以下几条古典音乐的特征规则:(1) 在一首乐曲中两个相邻音符之间的音程差应小于八度;(2) 所有的音都应该在同一个调上,乐曲的开头和结尾都应该以该调的主音为主,例如,如果是C大调,那么出现在第一拍和最后四拍的音符应该是中音C;(3) 音调不能一直上升或者下降,也不能一直持续在同一个音高上;(4) 一个音符的连续重复次数不能大于4次;(5) 音乐节奏的变化不能过快;(6) 一首乐曲中最高音符是唯一的,最低音符也是唯一的;(7) 应当尽量避免切分音的出现。符合这些规则的提供奖励即得到正值,反之将受到惩罚即得到负值,最后求这些值的总和即为音乐理论规则得分Rm(a,s)。
上述的规则特征并不是详尽无遗的,但这些规则的加入会使该训练过程更加接近真实编曲,让生成的音乐更具结构性,古典风格更加明显。
2.3 Actor-Critic训练
Critic网络的模型参数在训练过程中保持不变,目的是让网络始终保持从真实音乐数据中学习到知识。得到当前状态的价值V(s)和下一时刻的状态价值V(s′)以及音乐理论规则的奖励Rm(a,s)可以构建一个时间差分TD:
TD=Rm(a,s)+εV(s′)-V(s)
(4)
式中:ε为下一时刻状态价值的折扣系数。
TD就是本文设定的任务分数,通过把TD返回给Actor网络就可以构建Actor网络的损失函数,P(a,s;θA)是该音符在状态下被选择的概率,θA为Actor网络的参数,损失函数如下:
L(θA)=E[-[logP(a,s;θA)×TD]2]
(5)
得到Actor网络的损失函数之后就可以进行训练,其训练过程见算法2。
算法2 Actor-Critic训练网络
输入:随机音符序列例子
输出:Actor网络的模型参数
1.利用1.2节算法1得到的权值参数初始化Actor网络和Critic网络。
2.向Actor网络中输入一个随机音符序列。
3.Actor网络根据输入和此刻的状态s生成音符序列a。
4.将s和a输入Critic网络得到时间差分TD。
5.Actor网络接收时间差分TD,根据式(5)更新Actor网络的模型参数θA。
6.循环执行上述步骤,直至迭代完成,loss值收敛。
3 音乐生成
经过Actor-Critic训练之后的Actor网络就可以用来生成音乐,每次读入一个音符,网络根据之前生成的音符和策略来预测下一个音符。生成算法见算法3。
算法3 音乐生成
输入:初始序列
输出:音乐片段
1.随机选择一个长度为n的初始序列作为网络的初始输入。
2.将初始序列one-hot编码成输入向量,按顺序将第一个音符向量输入到网络中。
3.初始序列输入完毕之后,将初始序列作为生成音符序列的开头部分。
4.经过前向传播从输出层得到输出向量Y,并将Y作为下一次的输入。
5.将生成向量Y解码为音符序列y,添加到生成音符序列的末尾,若没有达到指定的长度m,则循环执行步骤4-步骤5。
6.输出长度为m的音符序列。
7.将长度为m的音符序列经过反向处理转化为midi格式的音乐片段。
4 实 验
实验所用服务器配置为Intel Xeon 2640v4 2.4 GHz处理器,500 GB运行内存和12 GB显存的NVIDIA 1080Ti GPU,所用编程语言为Python 3.6.1,框架为Tensorflow。
4.1 数据库及数据预处理
实验收集了18世纪-19世纪的多个作曲家的古典音乐集并从中提取钢琴轨道旋律,得到20 000首midi格式的音乐样本。为了消除节奏和音调对音乐的影响,将节拍统一调为4/4拍,音调都转移到C大调上,时长大多集中在2~3分钟。
神经网络的输入和输出都表示为向量形式,所以需要对音乐数据进行预处理。设定时间量化为十六分音符,然后使用piano roll[14]把样本中表示音符的信息转化成序列的形式。得到音符序列之后需要用向量的形式表示这些序列,本文使用one-hot编码对音符序列进行向量处理,也可以理解为是对音符序列的标注。即把输入音符序列xn转化为输入向量Xn,midi音符的编号共有128个,因此经过编码后的输入向量Xn共有128维。其数据预处理过程如图3所示。

图3 数据预处理
4.2 不同参数对实验结果的影响
本文做了四组对比实验,测试了不同隐藏层神经元个数对实验结果的影响,结果如图4所示。
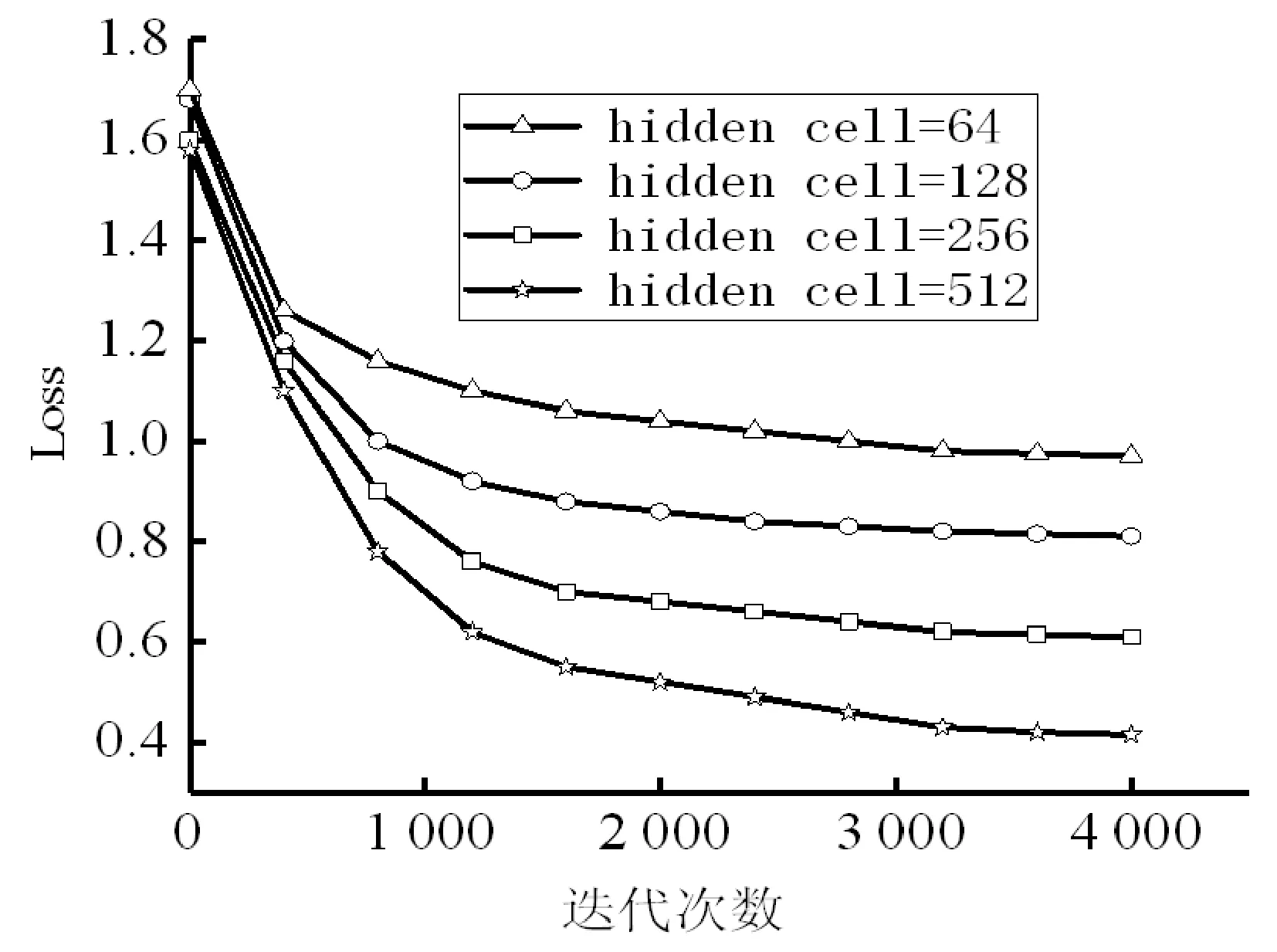
图4 不同神经元个数对训练效果的影响
从图4可以看出,神经元个数越多,网络学习数据集本质和抽象化数据特征的能力越强,越能有效地减少预测值与目标值之间的误差。隐藏层维数的大小对生成的音乐质量有非常重要的影响,但使用更深层、更宽的神经网络在训练阶段需要更多的计算量。
对于不同迭代次数生成的音乐文件,本文针对生成音乐和样本音乐做频谱分析,结果如图5所示。可以看出:迭代1 000次时生成的音乐中有很多样本音乐所不具备的频率,因此生成的音乐也是杂乱无章的;迭代2 000次时生成音乐的频谱开始出现样本音乐的频率,但生成音乐的频率中缺失了一些样本音乐中的频率;迭代达到4 000次时,生成音乐序列的频率分布总体上和样本频率分布趋于一致。可以证明迭代次数越大,权值参数学习和调整的次数就越多,在一定程度上就会提高模型的准确率。
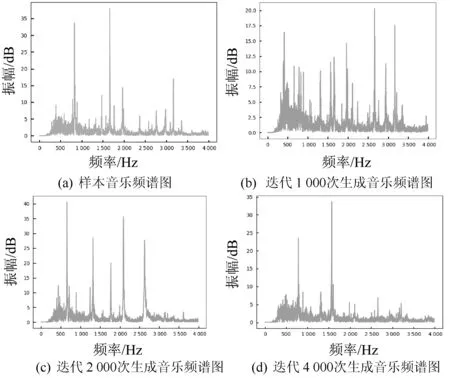
图5 生成音乐频谱图
4.3 生成音乐声谱图分析
为了比较直观地显示本文方法生成音乐的旋律特征,增加了生成音乐和样本音乐的声谱图分析,结果如图6所示。可以看出本文方法生成音乐的声谱图和样本音乐的声谱图在总体分布上很接近,因此可以验证本文方法生成的音乐具有和样本音乐相似的旋律特征。
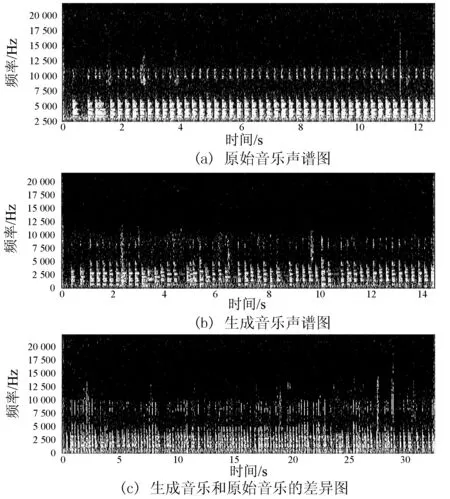
图6 生成音乐与样本音乐及差异声谱图
4.4 生成音乐对比分析
本文方法是对基于字符级LSTM音乐生成网络训练方式的改进,为了表明本文方法的有效性,本文做了两组实验,对比的网络是经过常规训练的基于字符级LSTM的音乐生成网络。该网络和本文方法通过相同的实验环境设置,各生成300首音乐作为测试样本。
4.4.1 十二平均律对比
十二平均律是一种音乐定律方法,其将一个纯八度音平均分成十二等分,每等分称为半音,是最主要的调音法[15]。提取两组测试样本中的十二平均律音符使用次数,并计算其统计分布,结果如图7所示。
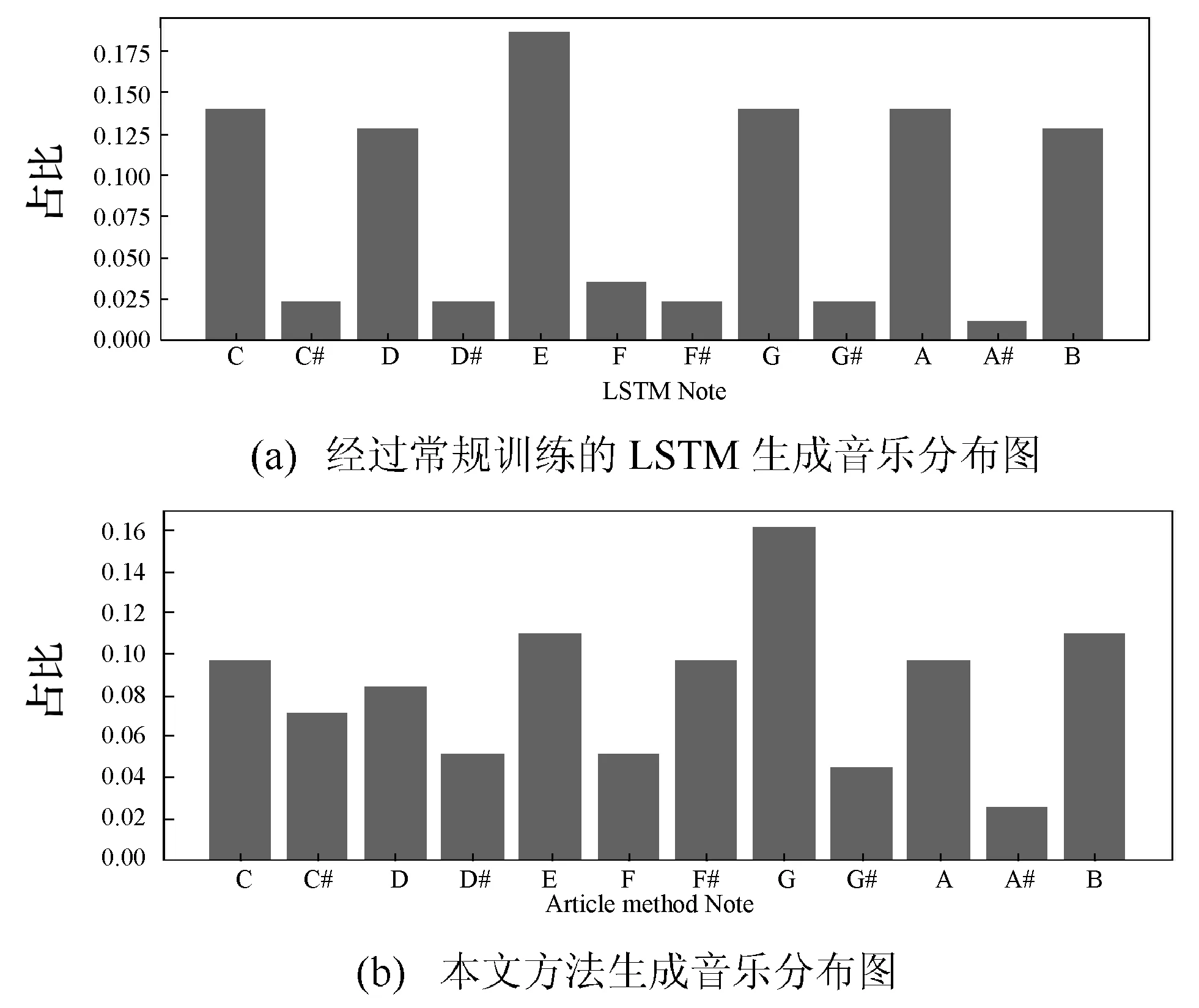
图7 十二平均律音符分布
由图7(a)可以看出,经过常规训练的LSTM生成的测试样本中C、D、E、G、A、B音出现的次数多,剩余的音符几乎没有出现,而图7(b)显示本文方法生成的音乐每个音符所占的比例相差不大。对比结果可以证明本文方法在生成音乐时选择的音符种类较多,即生成的音乐曲调更为丰富。
4.4.2 音乐特征对比
为了更进一步表明本文方法的有效性,定量了音乐理论规则的表现形式。从生成的测试样本音乐中提取七个有效的特征信息,对比已知的音乐规则,计算统计数据,结果如表1所示。
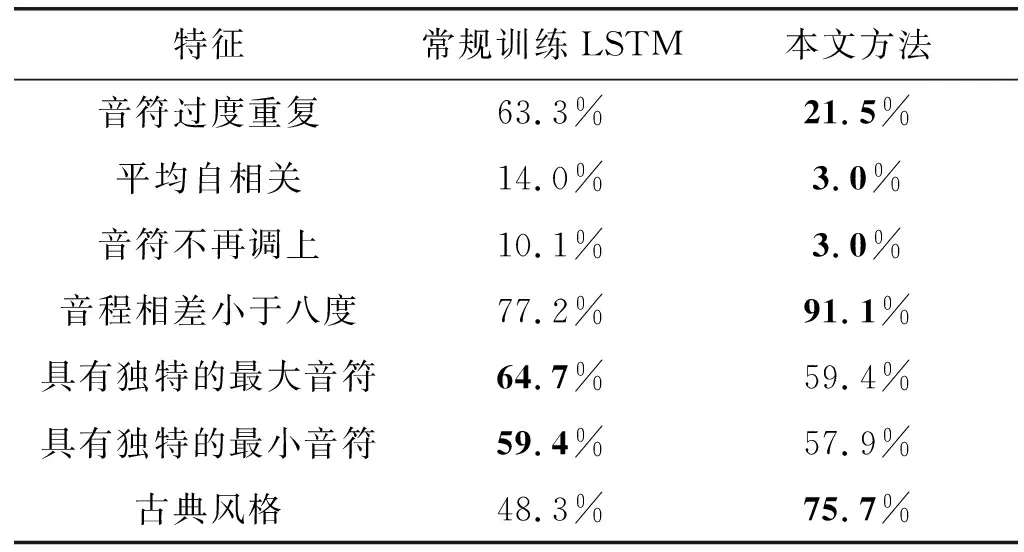
表1 音乐理论规则特征对比
可以看出,本文方法生成的音乐有效避免了音符过度重复和音程跨度过大等现象,并且生成的音乐在古典风格方面对比经过常规训练的LSTM有很明显的提升,较为符合音乐理论规则。
4.5 人耳听觉评判
本文还设计了人耳听觉判断作为实验准确度的评判标准之一。从两组测试样本以及真实样本音乐随机采样各得到30首。在完全匿名的情况下,让5名音乐学院的老师和20名音乐学院的学生从旋律、节奏、流畅度、悦耳程度以及主题性五个角度进行打分。汇总打分后,去掉一个最低分和一个最高分,对剩余的得分取均值,结果如图8所示。

图8 人耳评判对比
可以看出,本文方法生成的音乐在五个角度均高于经过常规训练的LSTM生成的音乐,虽然略低于真实音乐,但也比较接近。对比结果表明本文方法相比与经过常规训练的基于字符的LSTM音乐生成网络来说具有明显优势。
5 结 语
本文在常规训练音乐生成网络的基础上增加了基于强化学习Actor-Critic算法的训练,是一种模拟生成过程的训练方式。根据音乐理论规则和训练数据规律构造Critic网络,以给予生成网络Actor更接近真实音乐编曲的反馈,更新网络参数,提高生成音乐质量。音乐理论规则的添加促使生成的音乐更具结构,风格更加明显。由于篇幅限制本文只讨论了关于古典风格的音乐理论规则,但为其他风格的音乐生成提供了一个很好的方向。由于音乐的复杂性,本文方法生成的音乐并不能完全满足人们的实际需求,所以提高音乐生成的质量还需要进一步研究。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
阅读(低年级)(2020年10期)2020-01-07
作文大王·低年级(2019年5期)2019-06-13
海峡姐妹(2018年9期)2018-10-17
电影(2018年9期)2018-10-10
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
Coco薇(2017年11期)2018-01-03
数学学习与研究(2017年3期)2017-03-09
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
