
多目标/多类型恐怖袭击风险评估模型研究
2020-05-15 09:23:38朱炎峰卢树华
中国人民公安大学学报(自然科学版) 2020年1期
朱炎峰, 管 涛, 卢树华
(中国人民公安大学警务信息工程与网络安全学院, 北京 102600)
0 引言
当今世界,恐怖主义袭击频繁发生,造成大量的人员伤亡和财产损失,严重威胁着社会的公共安全,引起各国政府和学术界高度重视[1-4]。历史上美国9·11恐怖袭击事件,震惊世界,造成惨烈的后果。近期,2019年4月斯里兰卡爆发连环炸弹恐怖袭击事件,据官方统计,共致253人遇难,超过500人受伤。因此,研究恐怖主义袭击风险评估、态势感知等可为防范和打击恐怖主义提供参考,具有重要的理论和现实意义。
国内外诸多研究机构和学者对恐怖主义袭击定量风险分析进行了深入的研究,取得了较好的成果[1-15]。其中传统的风险评估方法主要有德尔菲法[1,5]、层次分析法[6]、风险矩阵法[7]等。近年来,机器学习[8-13]和大数据分析[14]等方法在恐怖袭击的风险评估和预测预警领域被广泛地运用。上述方法都为恐怖主义袭击风险评估的研究奠定了良好的基础。目前风险评估工作较多集中于对机场[5,12]、铁路车站[15]等较为具体的城市重点目标[6]进行分析,亦有针对恐怖袭击风险态势的整体性分析研究[10]。此外,多袭击目标(multi-target)/多袭击类型(multi-attack type)的风险评估和反恐资源配置也引起广泛关注,如Zhang等[17]针对多袭击目标/不同袭击类型会导致不同的袭击成功概率和后果的恐怖袭击进行研究,利用博弈论的思想对防御资源分配的有效性进行分析。
K-means++是一种无监督机器学习算法,广泛应用于无标签数据的聚类分析,具有操作简单、分类准确的优点,特别是对于数据属性不清晰的样本进行关联和聚类分析,效果较好,相较于K-means算法,K-means算法初始聚类中心点需要人为干预。K-means++在选择初始中心点前先计算整体数据,选择互相远离的中心点为初始聚类中心点,可以减少随机性,改善初始聚类中心的选择,提高计算结果的准确性[18]。Aubaidan等[19]在犯罪领域对K-means++和K-means两类聚类算法进行比较,得出在确定最佳初始聚类中心方面,前者工作效率明显优于后者。目前K-means已成功运用于民航恐怖风险评估等课题[12],而利用K-means++算法对多目标/多类型公布袭击风险评估研究较少。故采用K-means++算法构建风险评估模型具有较好的研究意义。
本文根据全球恐怖主义数据库(Global Terrorism Database, GTD)中恐怖袭击事件,包括袭击目标、袭击方式、人员伤亡等数据,基于K-means++聚类分析算法,采用Python语言编程,将全球范围2002~2016年期间恐怖袭击事件数据作为训练数据,建立多目标/多类型风险分析和风险等级划分模型,以2017年数据作为测试数据对模型进行验证,检验该方法风险等级划分的准确性,并与其他算法进行对比分析。
1 本文原理
1.1 恐怖袭击风险评估原理
关于恐怖袭击风险评估的定义和方法,是较为复杂的问题,尚未有统一的标准[20,21]。本文借鉴Zhang等[17]的多目标/多袭击类型风险函数并适当修改,如式(1),(2)所示:
(1)
s.t. 0≤ri,j≤1,∀i=1,…,n;j=1,…,m
(2)
式(1),(2)中,U是多目标/多类型风险评估的总目标函数,Ui是某种受害目标的风险指数,数值越高表示风险越高,ri,j表示威胁的概率,越接近1表示威胁发生概率越大,ci表示第i个指标的防御资源,Pi,j∈[0,1]表示袭击发生时成功的概率,Di,j∈[0,1]表示袭击成功造成的总损失(一般指人员伤亡和财产损失,由于经济损失数据缺失较多,本文主要选取死亡人数和受伤人数作为总损失的参考,数值越大损失越大),i是袭击目标的标号,j是袭击类型种类编号,n、m分别是袭击目标和袭击方式类型的总数。ri,j和Pi,j不仅与袭击者的动机、手段或能力相关,还与防御者的反恐怖资源配置有很大关系,故比较难以确定,为简化计算,可以通过历史数据进行测算[22]。
1.2 K-means++聚类分析算法
本文采用K-means++聚类分析算法,将所有评估对象进行聚类分析。聚类分析中为了度量对象的相似性,将相似性定义为距离的倒数。本文使用的距离度量是欧氏距离d,如公式(3)所示:
(3)
式(3)中,下标索引j为样本点x和y的第j个维度(特征列)。SSE意为簇内误差平方和,K-means++算法相当于一个优化算法,通过不断地迭代使得簇内误差平方和最小。SSE的计算公式如下:
(4)
式(4)中的上标i为样本索引,上标j为簇索引,簇μ(j)为簇的中心点,x(i)为样本点。若样本点x(i)属于簇j,则w(i,j)=1,否则w(i,j)=0。
K-means++算法聚类中心点初始化过程中的基本原则是使得初始的聚类中心点之间的相互距离尽可能远,计算过程见文献[21]所示。首先,需先初始化一个空的集合M,用于储存选定的k个中心点,随后输入样本中选定的第一个中心点,并将其加入到集合M中;对于集合M外的任一样本点x,通过计算找到预期平方距离最小的样本,然后使用加权概率分布来随机选择下一个中心点,不断地重复以上步骤直到确定了k个中心点,最后基于选定的中心点执行K-means算法[18]进行计算。
2 风险评估建模
2.1 数据预处理
风险函数计算的原始数据来源于美国马里兰大学开发的全球恐怖主义数据库(简称GTD),该数据库为开源数据库,被广泛应用于恐怖袭击的风险评估,具有较好的代表性。本文选取GTD 2002~2016年间恐怖主义事件数据,期间全球共发生恐怖袭击97 235起,共造成232 887人死亡,334 474人受伤[4]。将“威胁”根据不同的袭击类型和袭击目标(表1所示)进行分类,分别计算所有类型的恐怖袭击事件发生的概率和成功率,作为“威胁”和“脆弱性”的属性。同时,根据数据库的完整性和有效性分别选择死亡人数和受伤人数作为衡量“损失”的属性。
依据GTD数据库2002~2016年发生的97 235起恐怖袭击事件,通过两个步骤进行数据预处理: (1)计算恐怖袭击的发生概率和成功率。通过计算GTD历史数据得出采用不同攻击类型针对不同目标进行的恐怖袭击发生的概率和成功率,其中rij表示平均一年时间内发生1 000起该类恐怖袭击的概率,Pij表示该类恐怖袭击在发生条件下的成功率,如表2所示。通过分析可知,以公民自身和私有财产、军事与警察为目标的恐怖袭击是发生概率最高的3类袭击,武装袭击和轰炸/爆炸袭击是所有袭击手段中被使用最多的两种类型。(2)计算恐怖袭击的损

表1 袭击目标类型对照(左)/袭击方式类型对照(右)
失数据。为了降低数据维度和计算复杂度,借鉴文献[17]思想,将22类袭击目标在9大类袭击类型下发生概率和成功率,分别乘以相应的死亡人数和受伤人数,来表示各类袭击的死亡情况指数和受伤情况指数,指数越大表示损失越严重,结果如表3所示。
2.2 风险评估模型计算流程
基于K-means++算法,使用Python编程语言,根据GTD数据,建立恐怖袭击风险评估算法流程,如图1所示:
第一步:读取2002~2016年GTD的恐怖主义相关数据,进行数据预处理;
第二步:以2002~2016年数据作为训练集,构造风险评估函数,将表3中的22类受害目标和9类袭击类型作为死亡人数和受伤人数二维空间中的198个数据点,运用K-means++进行风险聚类;
第三步:合并聚类结果,并划分风险等级;

表2 GTD 2002~2016年采用不同袭击类型针对不同目标袭击发生概率和成功率统计表
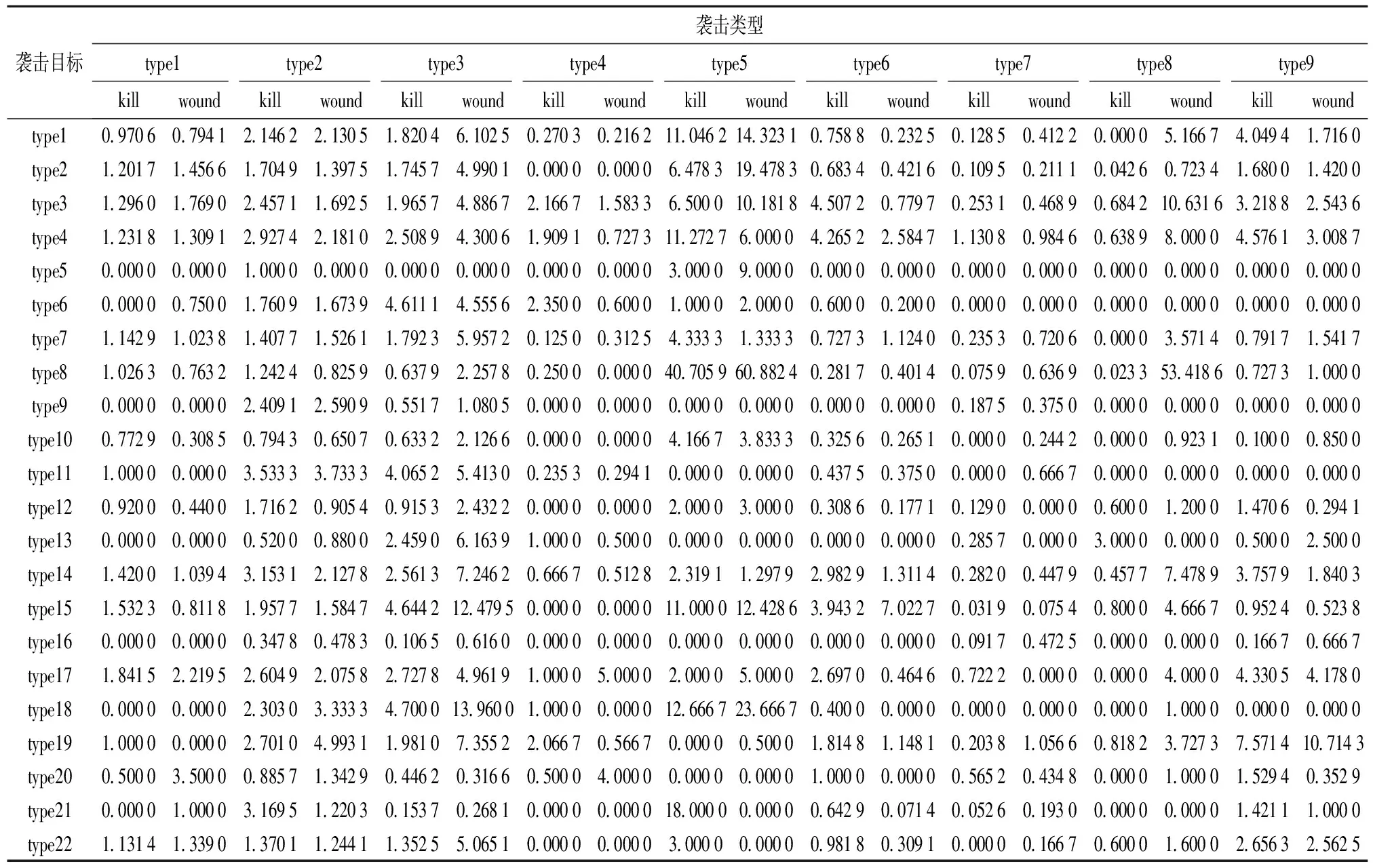
表3 GTD 2002~2016年采用不同袭击类型针对不同目标造成死亡和受伤严重程度统计表
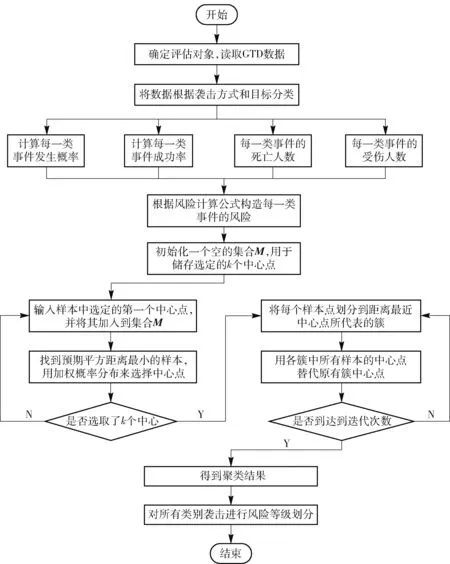
图1 恐怖袭击风险评估算法流程图
第四步:以2017年数据为测试集,运用K-means++进行风险评估等级划分测试。
3 结果分析与讨论
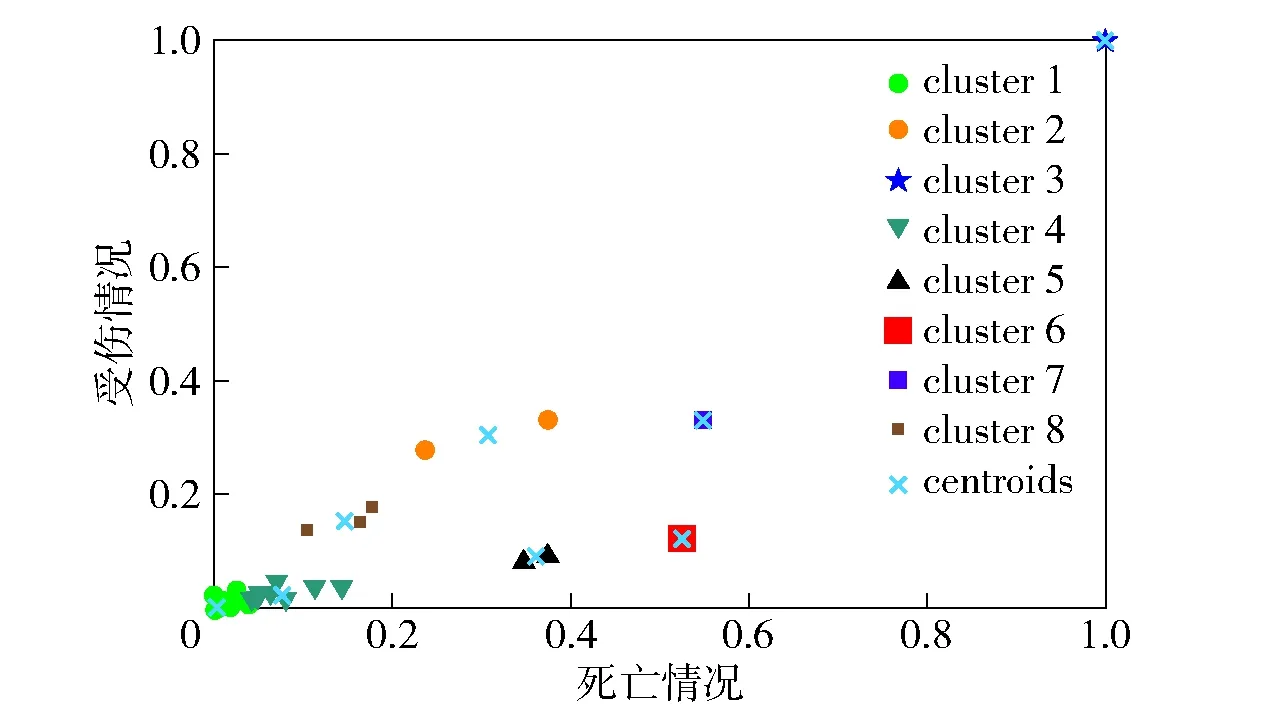
图2 K-means++聚类分析结果图
经过K-means++聚类分析,我们可得到8个聚类中心点,如图2所示,其坐标分别是(0.003 1, 0.001 7)、(0.306 3, 0.305 6)、(1, 1)、(0.076 7, 0.024)、(0.361 3, 0.091 7)、(0.524 0, 0.125 0)、(0.547 3, 0.331 6)、(0.147 3, 0.156 0),与原点的距离分别为0.003 5、0.432 7、1.414 2、0.080 5、0.372 7、0.538 7、0.639 9、0.214 6。由于K-means++聚类分析使聚类中心点之间尽可能互相远离,所以得到了8个聚类中心点。聚类中心点与原点距离越大的聚类表示该聚类代表的袭击风险越大。鉴于常用的风险等级划分做法[1],同时为了增强风险评估的直观性,文章将部分区分度较小的聚类合并。由于第6个和第7个聚类中心点都仅代表一个样本点,且两个聚类中心点距离原点的距离也比较接近所以将其作为一个风险等级,同理第2个聚类中心点、第5个聚类中心点与第8个聚类中心点所代表的点也作为同一风险等级处理。因此,根据聚类中心点距离原点的远近,我们将所有的恐怖袭击事件按照风险由高到低分为A、B、C、D、E 5个等级,如表4所示。

表4 2002~2016年采用不同袭击类型针对不同目标袭击风险等级对照表
由表4可知,风险等级在D级及以上的恐怖袭击在模型中共有18类。采用轰炸/爆炸袭击方式的恐怖袭击中有8类的风险等级在D级及以上,其中针对公民自身和私有财产采用轰炸/爆炸袭击方式的恐怖袭击是唯一风险等级为A级恐怖袭击类别。此外就袭击目标而言,公民自身和私有财产有两个风险等级处于A,B风险级别。
为检验本文方法的可靠性,以2017年GTD的恐怖主义数据作为测试数据,使用同样的数据处理方法对结果进行检验,经过风险分析,2017年恐怖主义风险评估等级如表5所示。对比分析表4、5,我们发现准确率为94.44%。为了和常用的机器学习算法进行比较分析,本文基于SPSS软件,分别运用K-means,BP神经网络和决策树算法对2017年数据进行运算并同表5结果进行对比,结果及算法相关参数如表6所示。

表5 2017年采用不同袭击类型针对不同目标袭击风险等级对照表

表6 各算法相关参数统计表
K-means++和K-means是非监督学习算法,可以直接对没有标签的数据进行聚类分析,并进行恐怖袭击的风险等级划分,经过对比发现K-means++算法较K-means在聚类中心点和准确率上有更好的表现。相对而言,BP神经网络和决策树属于监督学习算法,需要人工标注相应的数据标签方可进行分析,而GTD的数据本身并无风险等级的划分标签,由此可见,本文基于K-means++的多目标/多类型恐怖袭击风险模型相较于其他模型算法准确率较高,且运算较为简单。
4 结语
本文根据全球恐怖主义数据库中恐怖袭击事件属性数据,利用Python语言编程,基于K-means++聚类分析方法对多目标/多类型恐怖袭击进行了风险评估,以2002~2016年数据作为训练数据,建立了风险评估模型,利用2017年数据进行测试,测试结果表明,2017年的恐怖袭击的风险等级与2002~2016年训练集的结果基本吻合,准确率为94.44%,相较于K-means,BP神经网络和决策树等常用机器学习算法具有较好的准确率和可操作性,表明K-means++聚类分析方法用于恐怖袭击风险评估具有一定的参考意义。
猜你喜欢
英语文摘(2021年1期)2021-06-11 05:46:56
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
刑法论丛(2018年3期)2018-10-10 03:35:30
邢台学院学报(2016年4期)2016-02-28 19:54:25
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
科普童话·百科探秘(2015年4期)2015-05-14 07:13:54
方圆(2014年7期)2014-05-30 10:48:04
留学(2014年20期)2014-04-29 00:44:03
