
基于Hadoop大数据挖掘斑马线机动车违章系统研究
2020-05-13 11:32黄守明
宿州学院学报 2020年2期
黄守明
铜陵学院数学与计算机学院,安徽铜陵,244000
2016年中国机动车保有量大约为1.2亿辆,预计2020年有望超过美国达到2.2亿辆[1-2]。如此多的车辆,在带来方便的同时,也制造了很多的烦恼。比如,在城市道路的很多斑马线,因为没有交通信号灯和探头,出现了机动车和行人争道的情况,给行人带来安全隐患。针对机动车遇斑马线行人通行时不停车避让的交通违章行为,目前交通巡警使用比较多的方法为:现场执法;设置立体斑马线;设置手控信号灯;设置减速带等。上述方法要么需要花费大量人力成本,要么只能靠机动车司机自觉遵守,而且当机动车辆违章时缺乏有力执法证据,使得这些方法在实际应用中收效甚微。随着大数据时代的来临,为解决上述问题,通过对Hadoop平台研究,提出了基于Hadoop的无交通信号灯斑马线机动车不文明礼让违章行为的大数据挖掘系统。采用了MapReduce构架的Apriori改进的关联新算法,通过分布式并行处理对海量数据进行快速有效的挖掘,提取机动车斑马线不文明礼让行人的违章行为。
1 Hadoop 平台及MapReduce框架
1.1 Hadoop平台
Hadoop是Apache下一个开源子项目,实现了一种分布式系统基础架构,是一个容易开发且可以并行处理大规模数据的分布式计算平台[3-4]。 Hadoop框架最核心的设计就是:HDFS和MapReduce,HDFS实现了分布式文件系统,提供以流式数据访问模式来存储超大文件[5-6]。流式数据访问允许一次写入、多次读取、顺序读取。而且,由于Hadoop的分布冗余存储数据方式的设计,使得该框架具有很高的可靠性。MapReduce为海量的数据提供了计算方法。
1.2 分布式文件系统(HDFS)
HDFS是一个基于一组特定节点的主从架构,主节点(NameNode仅一个)负责系统命名空间管理、客户端文件操作控制以及存储管理,从节点(又称数据节点 DataNode)提供真实文件数据的物理支持。在HDFS 内部,所有通信标准都基于TCP/IP 协议[7-8]。HDFS就像单机文件系统一样也有块的概念,默认块的大小为64 MB,在 HDFS上的文件被划分成多个64 MB的大块,并将它们复制到多个计算机中(DataNode)(图1)。HDFS可以运行于低廉的硬件上,具有很高的容错性,数据读写吞吐率高。
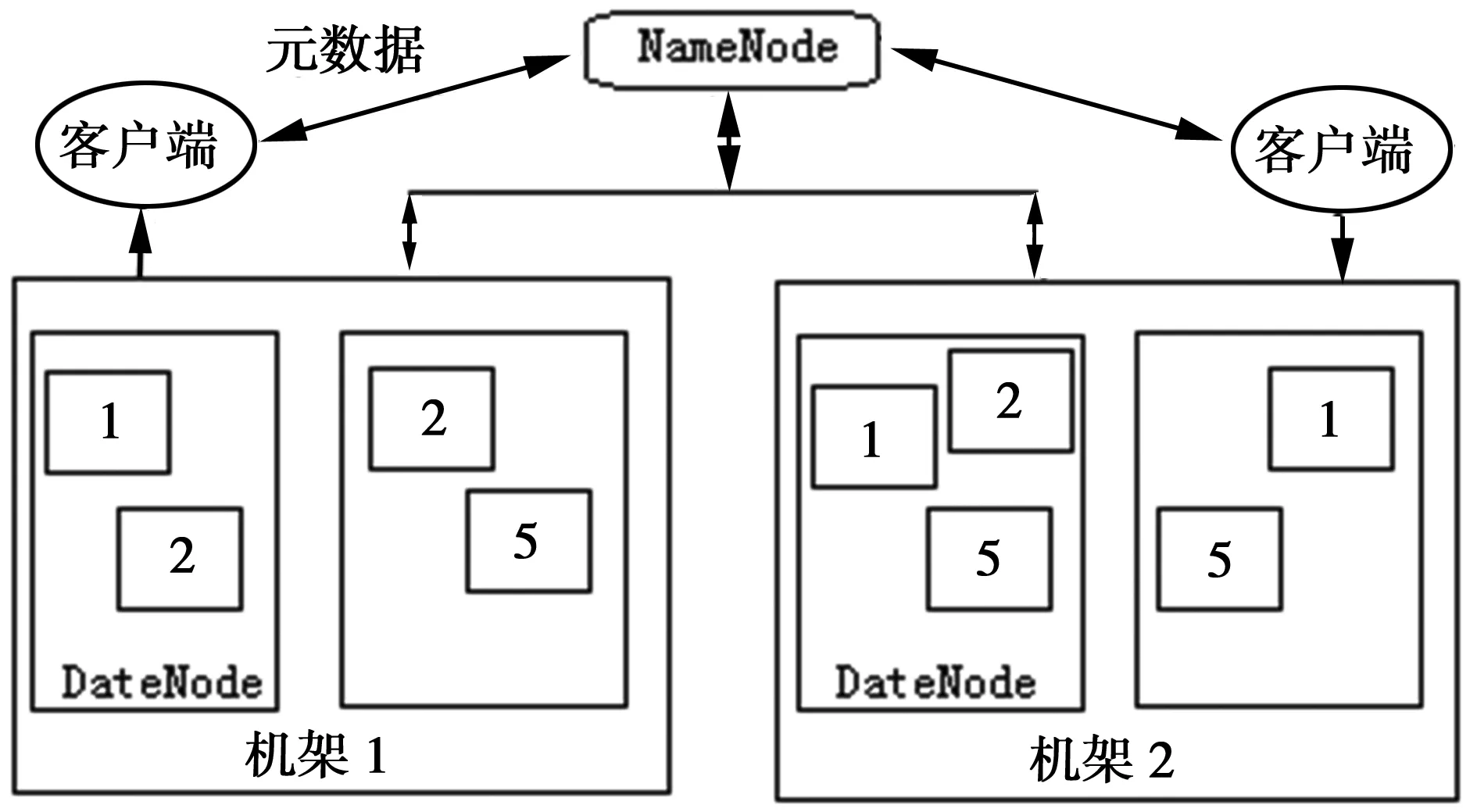
图1 HDFS结构示意图
1.3 一种分布式计算模型(MapReduce)
MapReduce由两个阶段组成:map()任务分解;reduce()结果汇总[9-10]。通常最基本的 MapReduce应用程序至少包括一个Map函数、一个Reduce函数和一个main 函数。首先用户创建一个Map函数,用于处理一个基于键值对的数据集合,输出中间的键值对的数据集合;接着创建一个Reduce函数,合并具有相同中间键值的中间值。Reduce函数接受Map函数生成的列表,然后根据它们的键值对缩小键值对列表。main函数将作业控制和文件输入/输出结合起来(图2)。MapReduce构架的程序能够在大量普通计算机上实现大数据集并行处理。
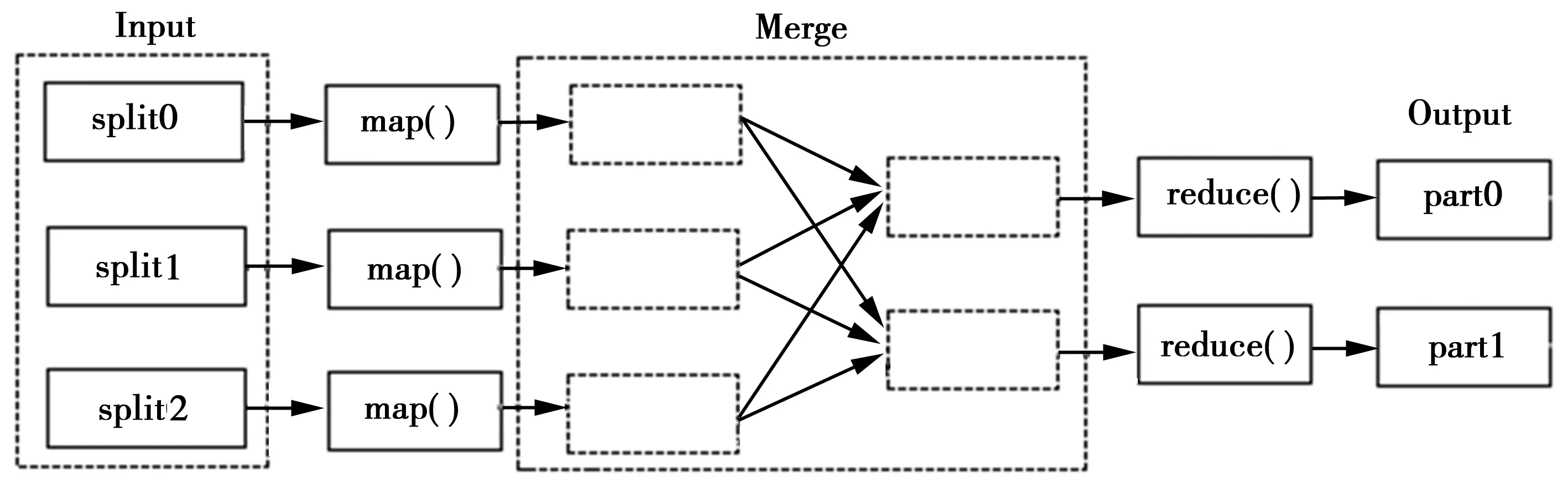
图2 MapReduce 数据处理过程
2 大数据平台构架
虽然斑马线可能没有交通探头,但可以依据强大的视频监控系统采集机动车斑马线不文明礼让的证据。比如城市街道、十字路口、市民广场和公园、商场超市、居住小区等大都安装有可见视频监控探头。只要把视频监控系统与交通系统实现信息数据共享,通过大数据挖掘技术就能迅速提取交通违章行为。但为此也产生了EB级别的海量数据,这就必须有一个能够存储海量数据的存储场所和设备,并且要具有容错性和稳定性。
使用大数据技术处理海量数据需要解决三个问题:数据存储、分析和管理问题。以Hadoop生态系统为平台的大数据系统天生就具有处理海量数据的能力,HDFS分布式文件系统以Master/Slave形式启动NameNode和DateNode进程,在NameNode运行的节点存储着文件的元数据,在DateNode运行的节点上分布式多副本存储着具体的数据,可以保证数据的安全。在数据分析上,Hadoop生态系统采用了分布式并行计算模式,并且采用了移动计算,对大数据来说,移动计算要比移动数据更经济合算。在数据管理上,Hadoop生态系统中有两个工具对数据进行整合,一个是Sqoop,一个是Hive[11-12]。通过这两个工具可以对关注的数据进行聚合和整理。
大数据技术的实时处理能力可以准确地探查到斑马线上不文明礼让行人的违章行为,结合视频监控系统、交通系统、车辆信息系统等,可以建立有效的安全模型。大数据技术以其综合处理与决策能力、快速反应能力可以大幅减少交通事故。
斑马线无交通信号灯机动车不文明礼让行为智能大数据系统包括基础层、数据分析层和信息发布层,如图3所示。
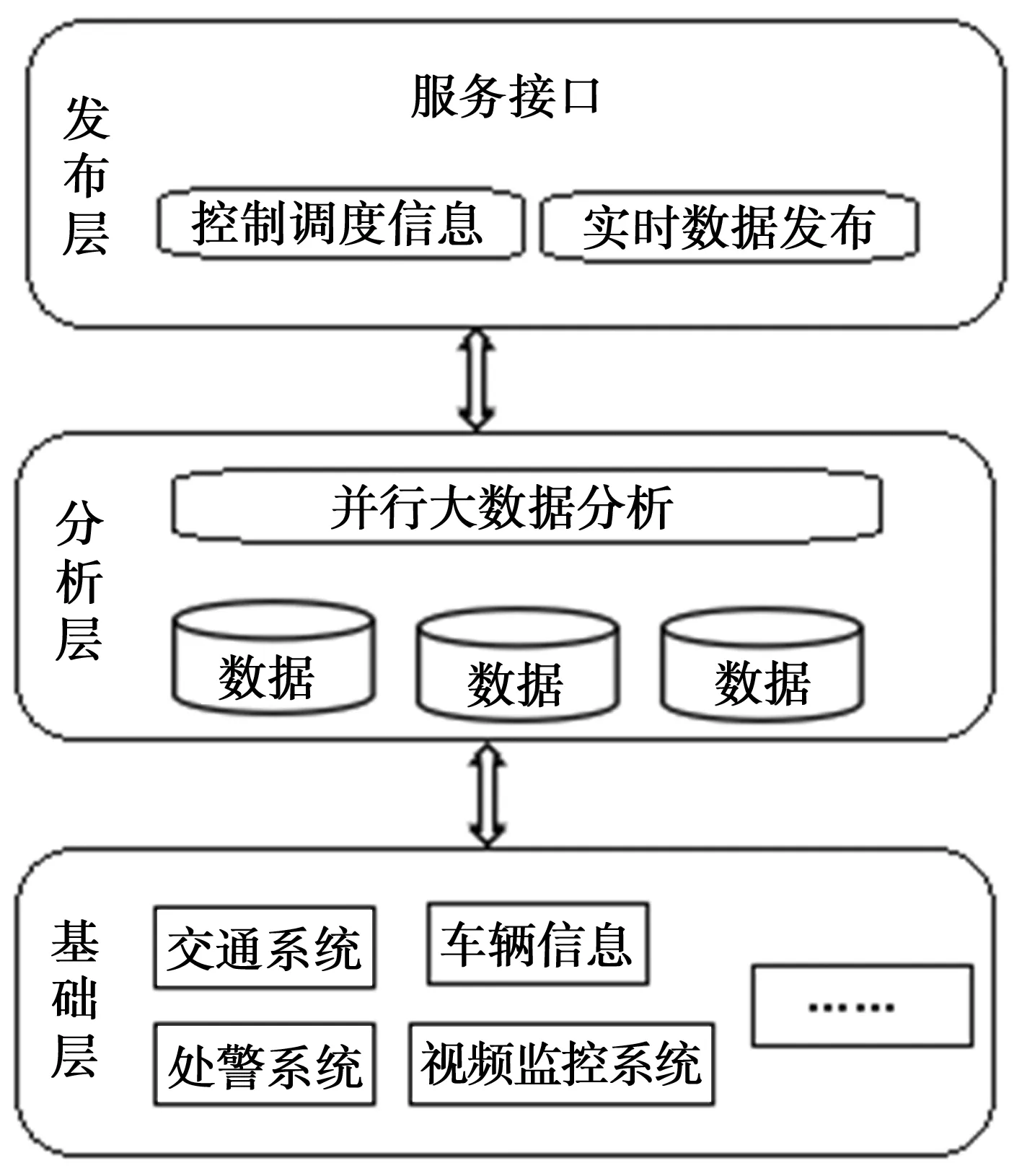
图3 大数据平台构架
基础层负责产生基础业务数据。数据的保存和处理可以采用云计算技术,既可以保证系统安全稳定,又可以提供高效的计算性能。数据分析层使用大数据技术,对下层基础数据采用数据挖掘技术进行实时有效的分析,提取交通违法行为。数据分析层是构建在Hadoop生态系统下,可以用价格便宜开源的Linux操作系统的服务器作为硬件平台,以HDFS文件系统作为大数据文件存储的基础,以MapReduce作为并行计算的模型。信息发布层是根据数据分析层的分析结果,通过互联网、移动终端交通信息平台发布违章车辆信息。
通过构建智能无信号灯斑马线机动车不文明礼让行人系统,目的在于提供一种机动车斑马线不礼让行人行为的抓拍,无需人力成本,并自动地对机动车不礼让行人的违规违章行为进行取证。利用大数据挖掘技术,对海量视频数据信息挖掘出符合机动车位于斑马线上且行人人数大于或等于预定门限时即确认为违章行为,并从中提取至少三张照片作为违章依据。
Hadoop采用MapReduce模型进行并行统计分析,统计车辆违规次数(times)、机动车在斑马线信息(JDID)、斑马线人数(PNUB),MapReduce模式下Map函数的key值为(JDI,PNB),value值为次数times。
对数据库进行简化整理,通过删除重叠属性项来缩小数据规模,产生新的数据集。 把数据集分成相当规模的多个子集,发送到网路的多个工作节点。通过Map函数对各节点的数据子集进行扫描,由 Apriori 算法计算出部分k项候选集,并产生键值对
ItemSetMap():
输入D(数据集);输出符合条件的项目集。
for each t ∈ D do //得到事务集
for each item ∈ t do //产生项目集
Content.write(item,1) //计数
End for
ItemSetReduce():
输入
Int sum=0;
for each v in values do //遍历项目集
sum += value.get() //计数
if (sum >= minSup)
context.write(key,sum) //得出符合条件的最小门限值的项集
基于磷钼酸和纳米氧化钼的复合空穴传输层材料及其在有机太阳能电池中的应用··············王宜玲 伊金垛 骆 群 谢中明 李艳青 马昌期 罗立强 (2,225)
end if
end for
产生强关联规则:
输入freqItemSets,最小门限值minConf;输出k项频繁集。
for each itemset in freqItemSets //遍历项目集
for all i-itemSet //得到非空真子集
conf = 1.0 * itemSet.getSupport() / occurrence.get(itemSet.getItems())//置信度的计算
if (conf >= minConf)
context.write(itemset,Conf) //输出满足最小门限值的项集
end if
End for
End for
3 试验测试
通过对铜陵市道路数据采集并进行试验。试验先对单机和Hadoop大数据环境速度进行比较,结果如图4所示。
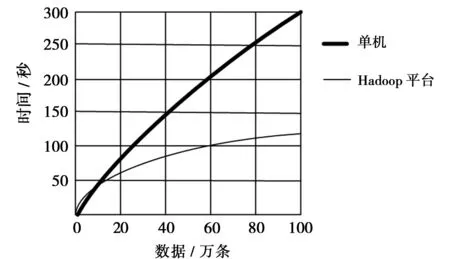
图4 单机和Hadoop平台速度对比图
图4测试结果表明:在Hadoop大数据环境下,随着数据量的增加数据处理速度越快,耗时比单机少很多,优势明显。但当数据量较少时数据处理效率远低于单机环境。由于抓拍机动车斑马线不礼让行人数据量巨大,因此,用Hadoop大数据处理非常适合。接着,通过试验Hadoop大数据平台在数据节点数(DataNode)增加所花费时间进行测试比较。取一组数据为256MB,分别测试当数据节点数为1,10,100个时耗时对比,结果如图5所示。
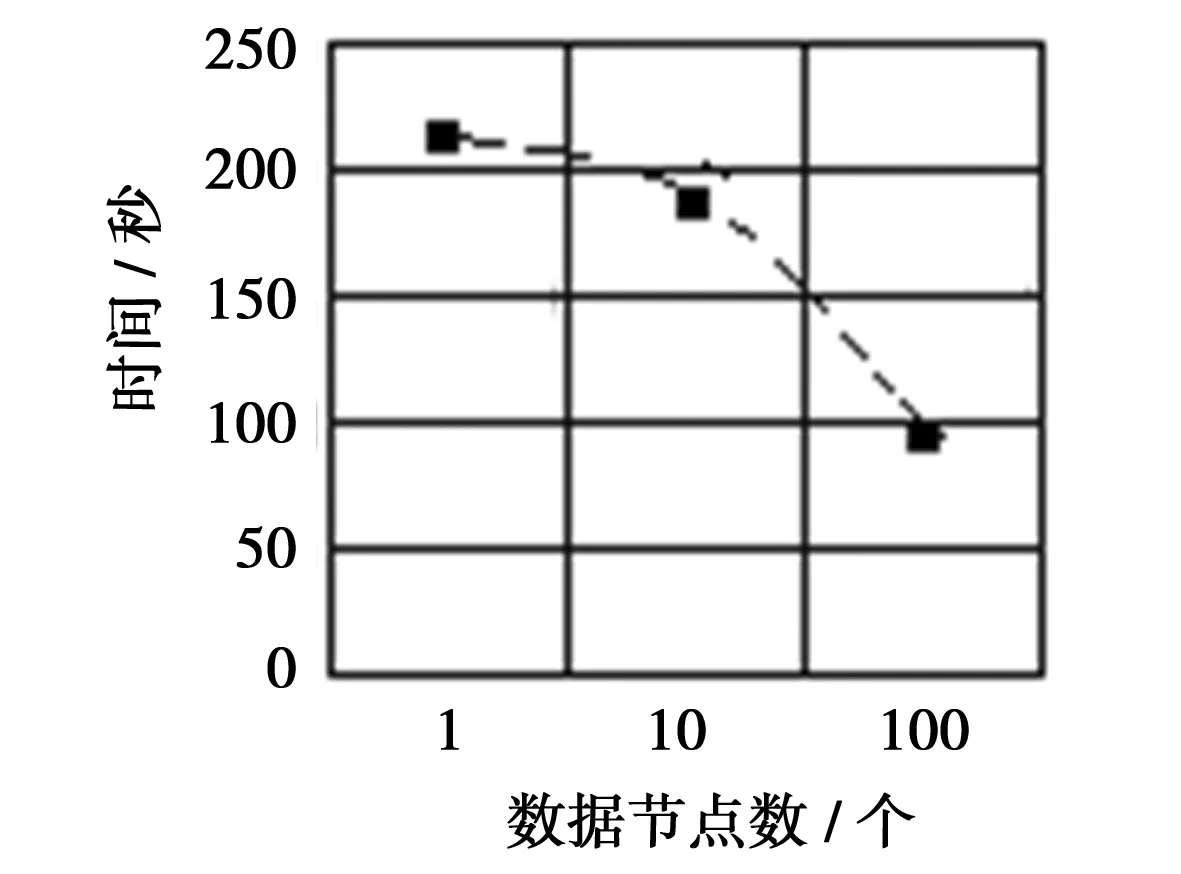
图5 节点数测试结果图
通过测试结果可以看出,当数据节点数增加时,在Hadoop大数据平台环境下处理数据所花费的时间明显减少。由此可见,Hadoop大数据平台对抓拍机动车斑马线不礼让行人这类数据巨大的处理具有很好的加速比。
4 结 语
为了使行人更安全的过马路,同时对机动车遇斑马线行人不停车避让的交通违法行为以处罚,进而起到警示作用,提高机动车驾驶员素质,设计了基于Hadoop的无交通信号灯斑马线机动车不文明礼让违章行为的大数据挖掘系统。利用Hadoop平台大数据挖掘技术,对机动车违章行为进行数据挖掘处理,准确率和挖掘效率大大提高,在现实生活中具有一定的应用价值。
猜你喜欢
品牌研究(2022年34期)2022-12-15
四川环境(2022年1期)2022-03-08
品牌研究(2022年36期)2022-01-01
电脑爱好者(2020年18期)2020-09-26
作文周刊·小学二年级版(2020年24期)2020-07-14
学生天地(2020年29期)2020-06-09
电脑爱好者(2017年9期)2017-06-01
投资北京(2017年1期)2017-02-13
中国质量与标准导报(2014年7期)2014-02-28
中国质量与标准导报(2014年1期)2014-02-28
