
精神分裂症多维度信息管理系统的设计与实现
2020-05-13 00:37王凯曦窦建洪
医疗卫生装备 2020年4期
王 鹏,吴 凯,5,6,王凯曦,窦建洪
(1.华南理工大学材料科学与工程学院生物医学工程系,广州510006;2.广东省精神疾病转化医学工程技术研究中心,广州510370;3.广东省老年痴呆诊断与康复工程技术研究中心,广州510500;4.华南理工大学国家人体组织功能重建工程技术研究中心,广州510006;5.广州医科大学附属脑科医院,广州市惠爱医院,广州510370;6.华南理工大学广东省生物医学工程重点实验室,广州510006;7.南部战区总医院麻醉科,广州510010)
0 引言
精神分裂症是一种常见的重性神经精神疾病。据2018 年中国精神卫生调查显示,我国精神分裂症12 个月的患病率为0.6%,终身患病率为0.7%[1]。据世界卫生组织的调查,在全球范围内,精神分裂症疾病每年新发病例的比率约为0.22%,终身患病率为3.8%~8.4%,在15~44 岁的患者人群中,精神分裂症疾病在总的疾病中占比约为2.6%,是世界上致使残疾的第四大原因[2]。
目前,精神分裂症在临床上的诊断方法主要还是依靠经验丰富的医生对患者过往病史、家族病史进行回顾,以及对患者使用量表进行诊断和评估[3]。在研究工具的应用上,医学信息化数据管理软件以及统计分析的软件或多或少都存在一些缺陷,成熟的商业软件如SPSS 和STATA 等往往价格昂贵,开源的免费软件如Epidata 等虽然很热门,但对于数据的格式化存储以及统计分析等功能是欠缺的。且上述工具基本都是单机软件,不利于数据共享,难以开展大规模的科学研究[4]。由于精神分裂症不同研究方向的数据类型及格式差异很大,研究方法多种多样,并没有很好的专门针对精神分裂症临床大数据研究的数据管理系统及工具。
目前针对精神分裂症的各种研究有很多,如基于多模态磁共振成像的研究、基于脑电检测的研究、基于肠道菌群分析的研究、基于神经心理及认知功能测评的精神分裂症心理及认知功能特征研究等[5-8]。本文根据以上研究,设计了一个专门针对精神分裂症研究的多维度信息管理系统,以便进行数据管理、数据共享以及对相关数据的统计分析。
1 关键技术
1.1 Spring 框架
Spring[9]是由Pivotal 公司推出的一系列框架的总和,其包括Spring 项目以及Spring 子项目,用于简化Web 开发中的复杂性,可以帮助开发者轻松创建Java 企业级应用程序。
Spring 框架组中的核心项目名称亦为Spring,是所有Spring 子项目的基石,提供控制反转(inverse of control,IoC)和面向切面编程(aspect oriented programming,AOP)的核心功能。IoC 用于将创建对象的过程交由Spring 容器来完成,可以降低代码的耦合性,并且能够在使用的时候动态创建对象,简化了开发步骤。AOP 利用反射和动态代理,在不改变类的前提下,在方法中开启一个切面,能够在切面中加入新的逻辑功能,特别适用于日志、安全等使用场景,同样也能够降低代码的耦合性、简化开发步骤。Spring MVC是基于Spring 核心的MVC 框架,MVC 全称为Model-View-Controller,意为模型、视图和控制器。MVC 开发模式中,页面、数据和业务逻辑3 个部分的代码被分开组织,降低了三者之间的耦合性,当遇到修改问题时,可分别修改,降低了开发和维护的难度。Spring MVC 中一次简略请求处理工作流程如图1 所示。Spring 系列是Java Web 中的主流框架,其生态圈活跃、解决方案众多,故本系统采用Spring 作为核心开发框架,默认的Spring MVC 作为控制层框架。
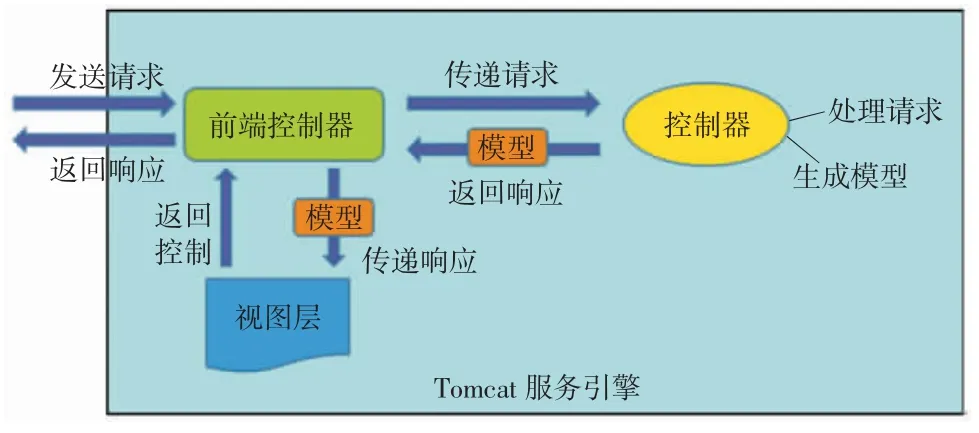
图1 Spring MVC 中请求处理流程
1.2 MySQL 数据库
MySQL[10]是一个非常流行的开源数据库,其架构可以在不同的场景中使用并发挥比较好的作用。无论是快速发展的互联网公司、技术型独立开发商还是大型企业,MySQL 都能经济且高效地提供高性能、可扩展的数据库应用程序。自其更新5.7.7 版本以后,MySQL 不仅支持关系型数据SQL,还增加了对非关系型数据NoSQL 的支持。MySQL 的文档存储为用户提供了同时开发传统SQL 关系应用程序和NoSQL 文档型数据库应用程序的可能性。
由于精神分裂症研究中的相关数据类型和格式十分复杂,关系型的结构化数据存储显然不足以满足所有的要求,而MySQL 可以让开发人员在同一个数据库中混合使用关系型和非关系型的结构化和非结构化的数据。基于这种特性,精神分裂症多维度信息管理系统采用MySQL 作为存储数据库。
1.3 Python 及其相关库
Python 是一门编程语言,由于具有简洁、开发速度快、库种类丰富等特点,Python 在人工智能和大数据时代成为了最热门的编程语言。在数据处理或数据分析领域,由于具有强大的机器学习库和数据分析库等,Python 均是首选编程语言。在医学研究中,也有越来越多的学者开始使用Python 进行数据处理和分析。本系统将使用Python 作为计算任务程序的编程语言,涉及到的相关Python 库包括pandas、Scikit-learn、SQLAlchemy 等。
2 系统设计
精神分裂症的研究是一个迫切问题,而精神分裂症研究中存在着数据管理混乱、数据分析不易等困难。对于数据存储,使用Excel、REC 文件或者纸质数据进行存储存在不可靠、不安全、冗余性高的缺点。对于数据分析使用SPSS 分析工具或统计人士帮助分析使研究较为松散,难以形成大规模有效的数据分析过程。因此,精神分裂症多维度信息管理系统的设计旨在帮助医生或相关科研人员更加便捷地管理精神分裂症的临床大数据,通过机器学习分类、机器学习回归和统计等功能,更加方便地进行数据分析。
2.1 系统功能模块
本系统包括数据分析模块、数据管理模块、系统管理模块和安全控制模块4 个部分,其功能结构如图2 所示。

图2 系统功能结构图
其中,数据分析模块分为任务管理、任务计算和结果可视化3 个子模块。任务管理模块负责任务的提交和任务记录的查看,任务计算模块执行具体的计算任务,结果可视化模块负责将任务的结果以可视化的方式展示出来。由于各种数据类型需要的功能各不相同,数据管理模块分为6 个子模块,分别为被试者基本信息、临床试验观察表(case report form,CRF)数据、MRI 特征数据、脑电图(electroencephalogram,EEG)数据、认知测评数据和肠道菌群数据管理模块。系统管理模块包括用户管理、角色管理和权限管理3 个子模块。为保证各个功能按权限执行,还需要单独的安全控制模块对所有的请求进行处理,故安全控制模块包括登录授权和权限鉴定2 个子模块。
2.2 系统整体架构设计
根据功能模块的设计,可以将系统分为基于layui 的表现层、基于SpringBoot 的服务层、基于Python 的计算层以及MySQL 数据库层。其中,表现层即用浏览器打开的前端页面,功能为与用户进行交互,包括登录页面、系统管理页面、数据表格化查看页面、数据可视化查看页面、任务提交页面、任务记录页面和任务结果页面。服务层可分为安全控制模块、系统管理模块、数据管理模块和数据分析模块。其中,安全控制模块用于单点登录、权限控制和路由转发。系统管理模块是基本功能,包括角色管理、权限管理和用户管理。数据管理模块包含数据上传、文件解析、数据查询和数据修改等功能。数据分析模块即任务管理模块,包括任务提交、结果查询和记录查询等功能。计算层是运行计算任务的地方,即数据分析模块的任务计算部分,功能主要为使用Python 中的Scikit-learn 包进行机器学习计算,包括5种机器学习分类算法和5 种机器学习回归算法。数据库层则用于存储所有的结构化及非结构化数据。
系统整体架构如图3 所示。采用浏览器/服务器(Browser/Server,B/S)架构与前后端分离模式,其表现层为一组静态页面,基于layui 的前端页面中的功能均由JavaScript 中的jQuery 实现,静态页面使用Ajax 通过超文本传输协议(hyper text transfer protocol,HTTP)与JSON 格式和后台服务层进行数据交互。
服务层中的安全控制过滤器统一接收所有前端页面的请求,并对请求进行权限判断,若有相关权限则放行,若没有权限则直接返回,以保证系统的安全性。其余模块接收到验证过的请求后,对请求进行相关处理。缓存数据库Redis 用于保存单点登录token 以及对部分查询数据进行缓存,若缓存中有对应的数据,则直接从缓存中查询结果返回;若缓存中没有数据,服务层才会进行数据库操作。服务层与数据库层交互需要通过数据访问对象(data access object,DAO),本系统DAO 采用MyBatis 框架来提供所有与数据库层相关操作的接口。
由于计算任务的响应时间与其他功能的响应时间差距较大,本系统采用生产者消费者模式。服务层数据分析模块接收任务提交的请求之后,将任务提交的参数封装在消息传入消息队列RabbitMQ 中,而计算层的Python 程序一直轮询地从消息队列中取出消息。在取得任务消息后对消息进行解析,根据任务提交的参数,从数据库中查询出计算所需的数据集,再选择对应的算法以及参数进行计算,计算完成后将任务结果与任务记录存入数据库中。若此时前端页面查询任务记录,便可从数据库中查看到已完成的计算任务,从而查询到对应的任务结果。
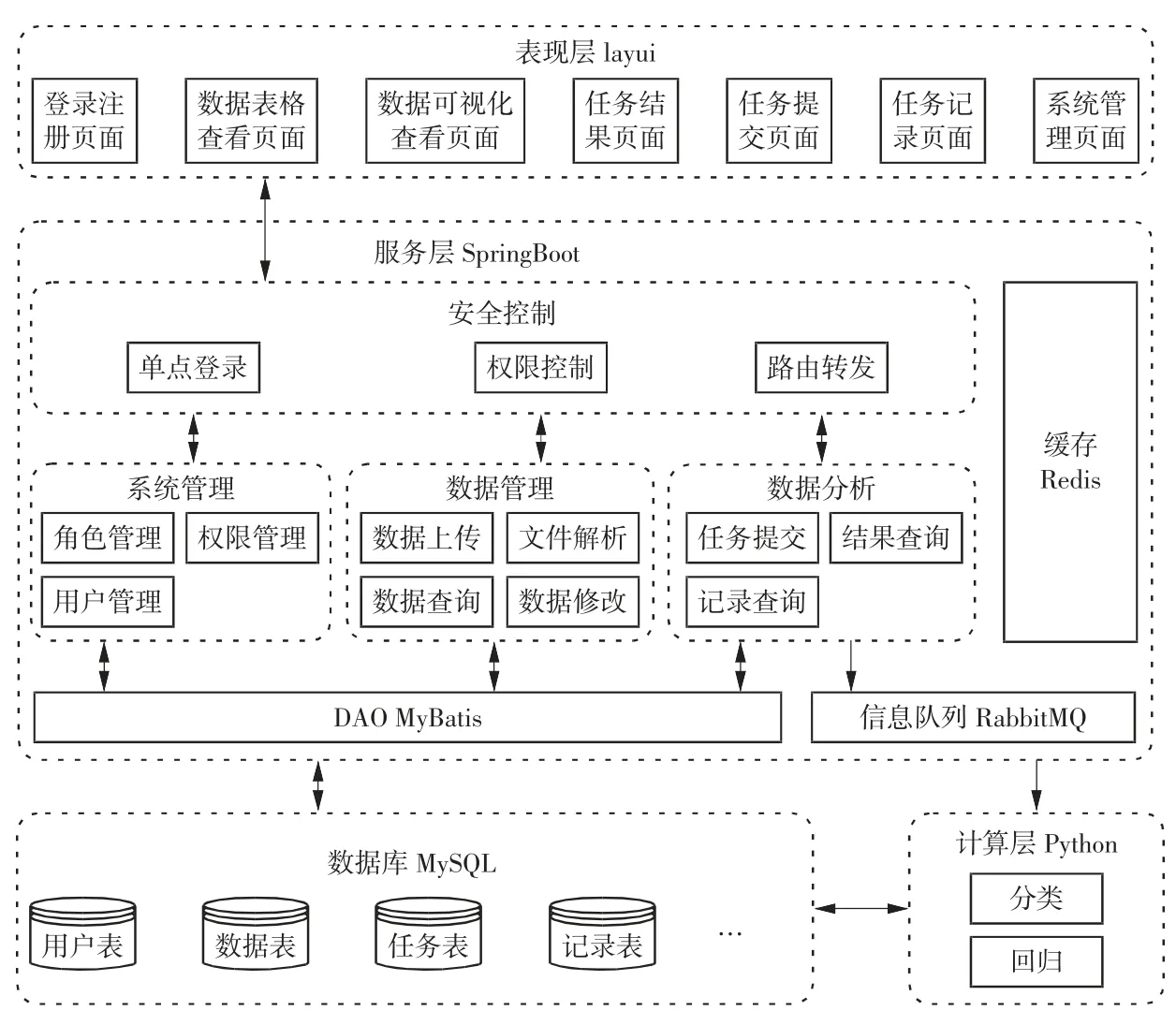
图3 系统整体架构图
2.3 系统数据库设计
本系统核心实体为用户,按照模块划分,数据库表也可分为系统管理、数据管理和数据分析3 个部分。其中,系统管理功能的数据库主表包括用户表、角色表和权限表;数据管理功能涉及的数据表包括被试者基本信息表、CRF 数据表、多模态MRI 数据表、EEG 数据表、认知测评数据表、肠道菌群数据表;数据分析功能的相关数据表包括任务记录表和任务结果表。
3 系统实现
3.1 页面结构与业务流程
系统页面主要分为数据管理、数据分析和系统管理3 个部分。页面整体结构如图4 所示,工作流程如图5 所示。
3.2 数据管理模块
数据管理模块分为被试者基本信息管理、MRI数据管理、EEG 数据管理、CRF 数据管理、认知测评数据管理和肠道菌群数据管理6 个子模块。
3.2.1 被试者基本信息管理
被试者基本信息管理的数据总览页面如图6 所示。主页面下方以表格的形式展示了所属用户的所有被试者数据总览信息,包括被试者ID、姓名、类型、实验组、入组时间以及其他数据的总览选项。主要功能包括搜索、添加、导出xls 及批量上传。表格上方选择输入被试者ID、姓名、类型和实验组即可对内容进行检索。点击“添加”按钮,输入被试者ID、姓名、类型和实验组即可新建单个被试者基本信息表,如图7 所示。点击“批量上传模板”按钮可以下载用于批量上传的Excel模板文件,填写多个被试者ID、姓名、类型和实验组后批量上传,即可一次新建多个被试者基本信息表。
3.2.2 MRI 数据管理
MRI 数据管理页面如图8 所示。上方的按钮包括搜索、导出、上传DPABI 数据、上传PANDA 数据和上传freesurfer 数据,分别可上传使用DPABI、PANDA 和FreeSurfer 计算出的多模态MRI数据。数据表格中,×表示被试者没有该类型的特征数据,90 和246 分别表示该被试者拥有该特征的解剖学自动标记(anatomical automatic labeling,AAL)模板和脑网络组图谱(brainnetome altas,BNA)模板特征数据,点击可以展开该特征的详细页面,展示其所有脑区值。
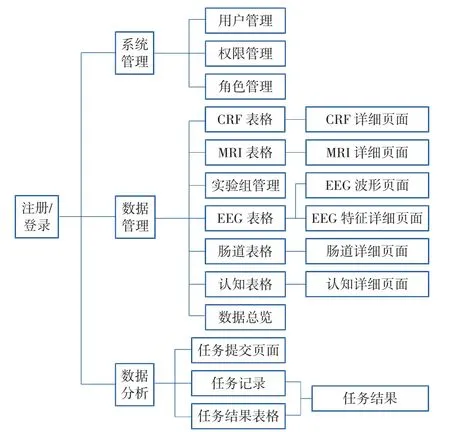
图4 系统页面整体结构
3.2.3 EEG 数据管理
EEG 数据管理页面如图9 所示,包括搜索、上传EEG 波形和上传EEG 特征等功能,表格中可以进一步展示被试者的EEG 波形和EEG 特征数据。
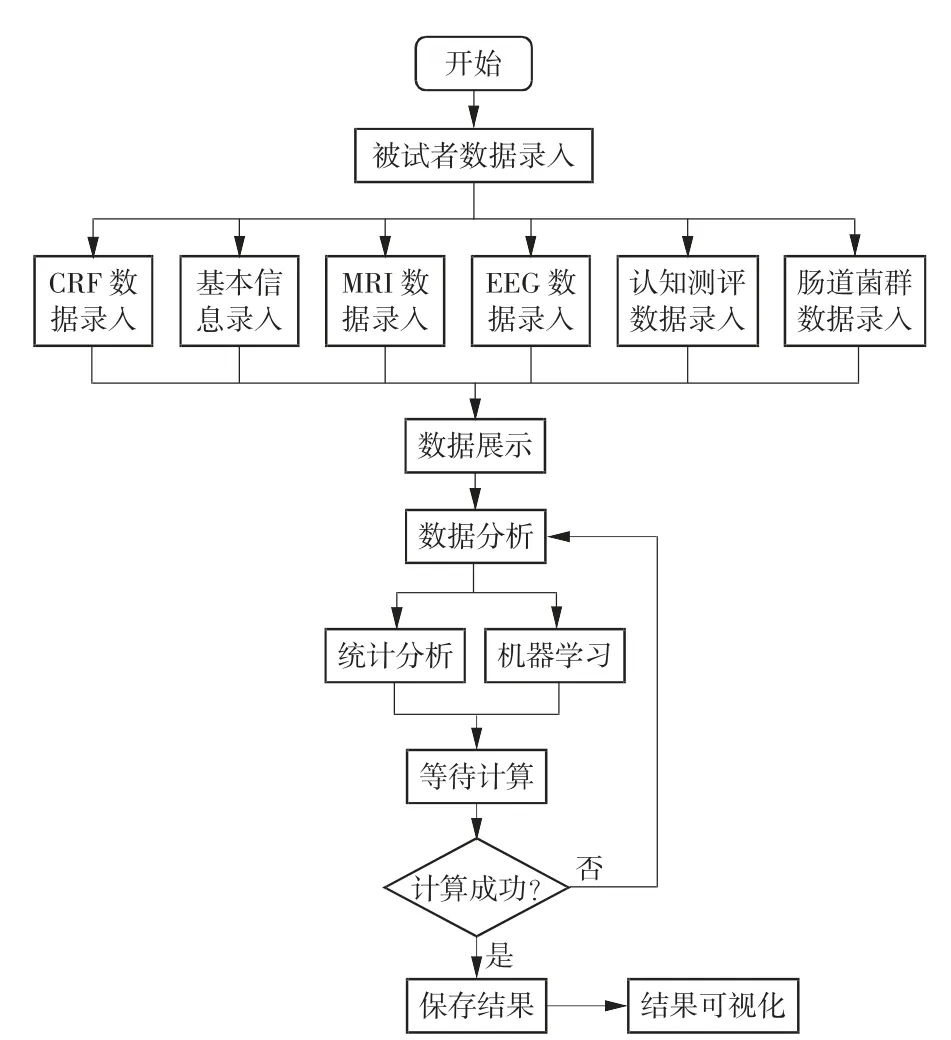
图5 系统工作流程
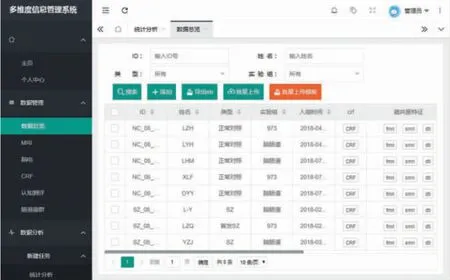
图6 数据总览页面
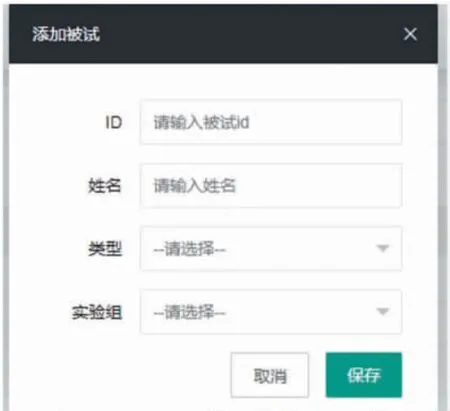
图7 新建被试者基本信息填写页面
3.2.4 CRF 数据管理
CRF 数据管理页面如图10 所示,包含搜索、导出、添加和上传Excel 等功能。数据表格中展示了被试者ID、被试者类型以及被试者是否完成了人口学资料、临床评估信息和被试者自评量表。
3.2.5 认知测评数据管理
认知测评数据管理页面如图11 所示,包括搜索、导出、添加和上传等功能,表格中显示了认知测评的全部结果。
3.2.6 肠道菌群数据管理
肠道菌群数据管理页面如图12 所示,包括搜索、导出和上传等功能,可以进行检索、xls 导出和批量上传肠道菌群数据等操作,可查看被试者的某个水平的肠道菌群物种组成详情。
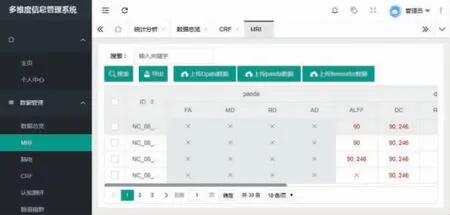
图8 MRI 数据管理页面
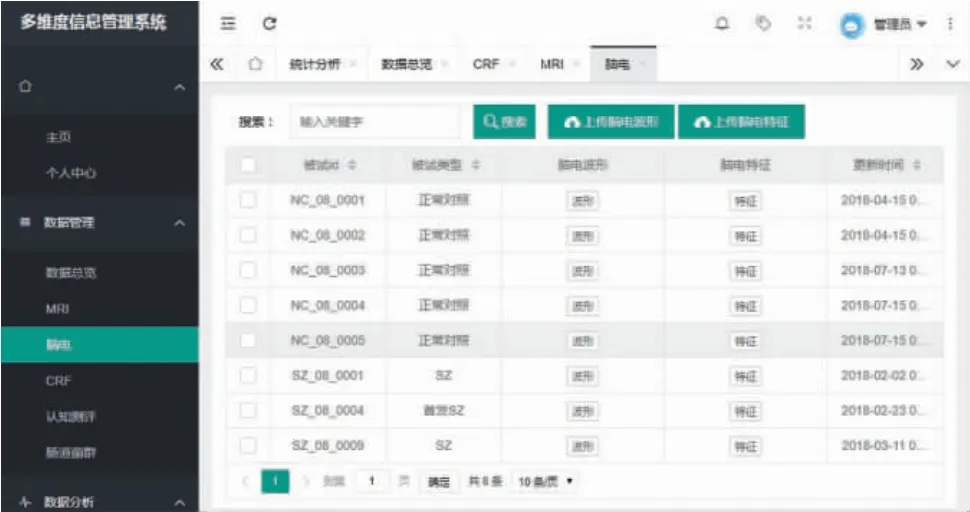
图9 EEG 数据管理页面
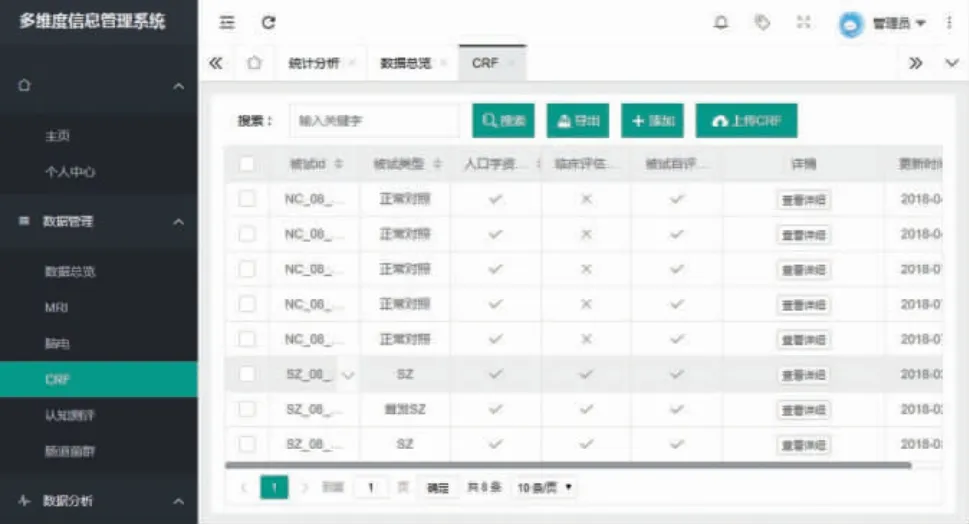
图10 CRF 数据管理页面

图11 认知测评数据管理页面
3.3 数据分析模块
数据分析模块的功能分为任务提交、任务运行、记录查看和结果可视化。操作基本流程:用户新建任务,在任务页面选择算法、参数和数据集,然后点击“提交”,等待任务执行,在任务记录查询页面可看到完成的任务;点击“结果”,可以在结果页面查看可视化的结果。

图12 肠道菌群数据管理页面
由于统计分析和机器学习需要的参数不同,所以新建任务菜单分为统计分析和机器学习2 种表单页面。
机器学习任务表单页面如图13 所示。下方为被试者表格,用于选取计算任务的被试者集合,其上方的任务类型选择框可以选择机器学习类型,包括分类和回归,算法选择框可以选择算法类型;阴性标签和阳性标签用于设置机器学习任务的标签分组依据;输入用于选择参与计算的特征种类,可以选择多种特征类型。
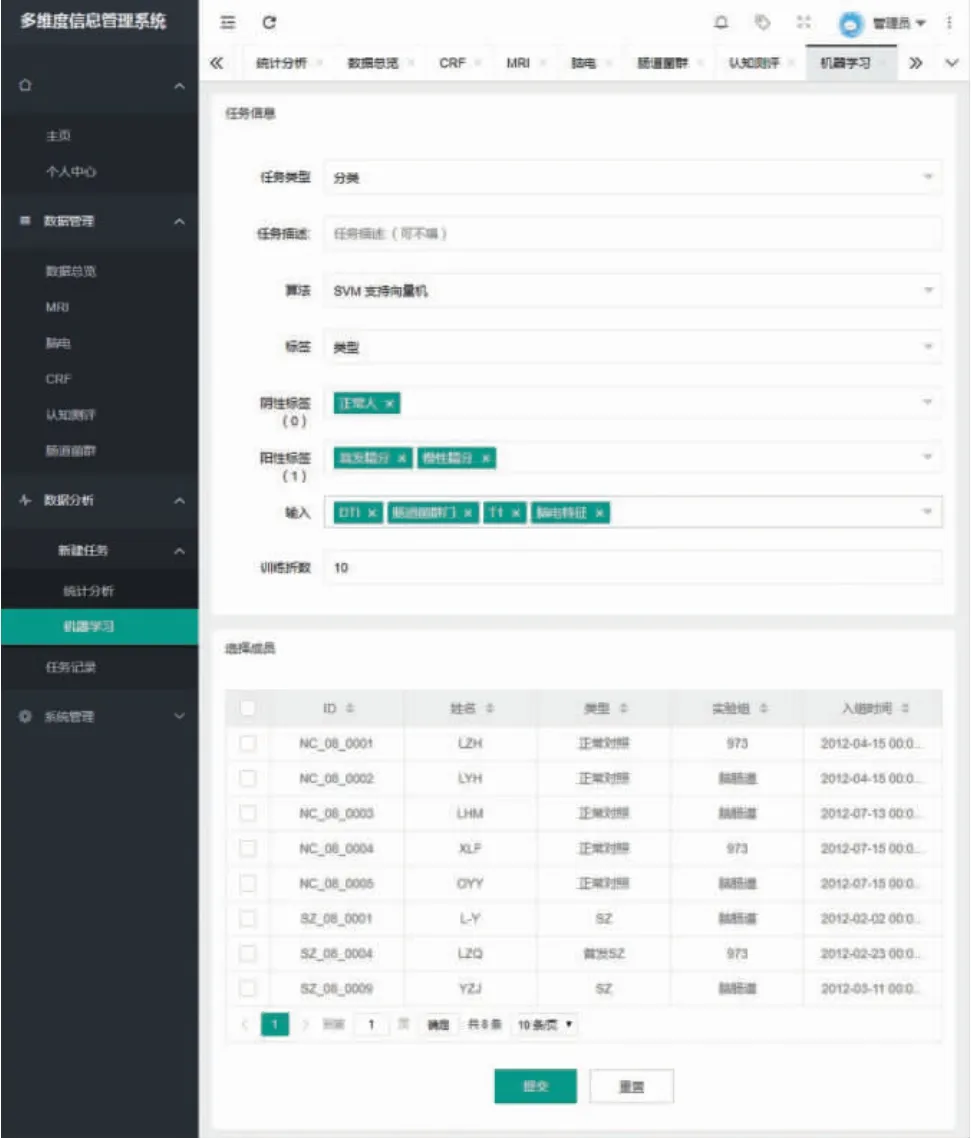
图13 机器学习任务表单页面
统计分析任务表单页面如图14 所示。与机器学习任务表单页面不同的是上方的参数选择部分,统计方法有t 检验和相关分析。选中方法时,参数选择会随之改变。如图中所示,选中t 检验后,参数可以设置校正方法、分组条件、输入特征等。
任务提交完成后,会在任务记录表中添加记录,任务参数将通过后台发送至RabbitMQ 消息队列,Python 脚本将会取出任务参数进行计算,将结果存入结果表中,并在记录表进行任务记录。任务记录以时间线的方式记录了提交的所有任务,记录分为任务提交、任务成功和任务失败3 种状态。对于任务成功的记录,可查看任务计算的结果。
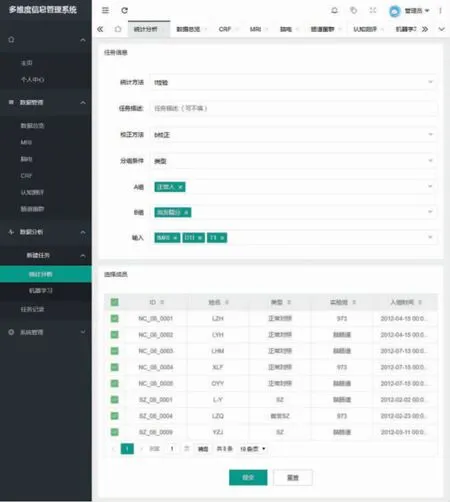
图14 统计分析任务表单页面
3.4 系统管理模块
系统管理模块包括用户管理、角色管理和权限管理3 个子模块。用户管理页面如图15 所示,角色管理页面如图16 所示,权限管理页面图17 所示。其中,用户管理子模块的功能包括添加用户和修改用户的角色;角色管理子模块的功能包括添加、删除角色,对角色的权限进行修改;权限管理子模块中列出了所有的权限接口。
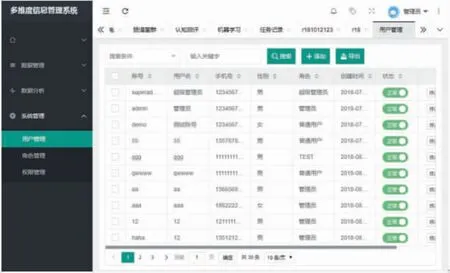
图15 用户管理页面
图16 角色管理页面

图17 权限管理页面
4 应用实例
4.1 数据来源与录入
选取58 名被试者,其中正常对照组与精神分裂症患者组各29 名。精神分裂症患者组在广州医科大学附属脑科医院招募,数据由该医院提供;正常对照组面向社会公开招募,MRI 数据在该医院进行采集,其余数据在华南理工大学大学城校区进行收集。所有被试者在接受临床试验前完全了解实验细节,并签署知情同意书。
录入系统的数据可分为两类,一类是CRF 数据,另一类是其他类型的数据。对于CRF 数据,可分为3种录入方法:(1)手动录入采集的纸质版数据;(2)直接上传录入整理好的Excel 类型的数据;(3)在线填写录入。其他类型的数据均为Excel 类型数据,如多模态MRI 数据分别使用DPABI、FreeSurfer 和PANDA进行特征提取,将提取后的Excel 文件上传至系统,最后将所有数据保存至数据库中。由此实现了稳定、可靠、简洁的数据存储,同时可通过各个数据管理模块对已保存的数据进行查看与修改。
4.2 精神分裂症多维度数据分类模型的构建与比较
对录入的数据进行精神分裂症多维度数据分类模型的构建及比较,使用的数据特征包括被试者3种模态的MRI 特征以及被试者肠道菌群物种组成。实验方案:分别使用系统中集成的5 种分类算法,以被试者是否患病为标签构建分类模型,并对比各个分类模型结果的优劣。
提交的机器学习支持向量机(support vector machines,SVM)分类模型任务页面如图18 所示。提交分类任务后,后台会自动进行参数寻优以及模型评估,使用的训练折数统一为10 折。以此类推,提交其余4 种分类算法任务表单,等待任务执行,得到SVM分类模型构建结果、随机森林(random forest,RF)分类模型构建结果、逻辑回归(logistic regression,LR)分类模型构建结果、线性判别分析(linear discrimiant analysis,LDA)分类模型构建结果和K 最近邻(Knearest neighbor,KNN)分类模型构建结果,如图18~23 所示。
图18 提交机器学习SVM 分类模型任务页面
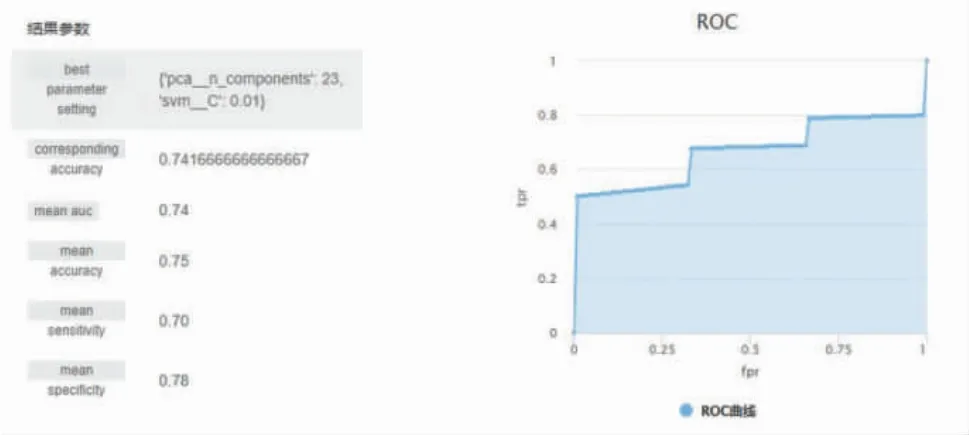
图19 SVM 分类模型构建结果
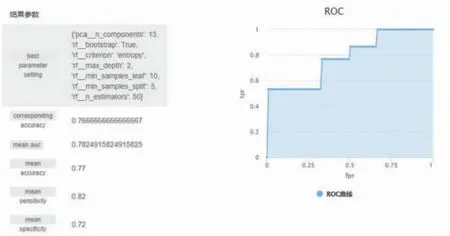
图20 RF 分类模型构建结果
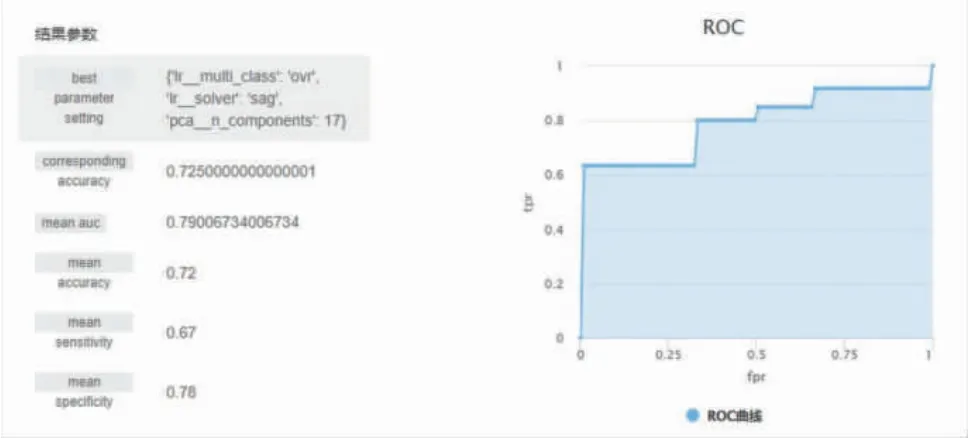
图21 LR 分类模型构建结果

图22 LDA 分类模型构建结果
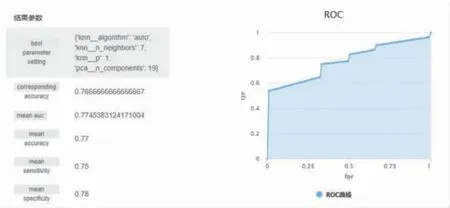
图23 KNN 分类模型构建结果
5 种分类算法结果对比详见表1。可以看出,当使用肠道菌群物种组成水平与MRI 特征进行辅助诊断分类模型构建时,RF 的效果较好,相较于其他4 种分类算法,其准确率和敏感度都有一定的优势。
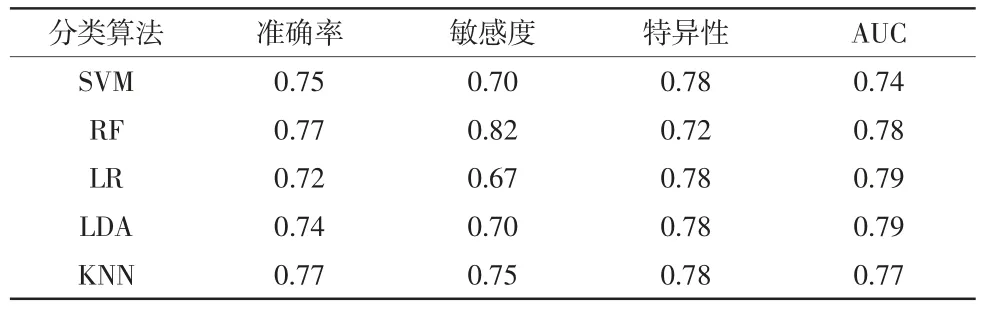
表1 5 种分类算法结果对比
从操作过程上可以看出,本系统将数据分析封装的较为封闭,相关研究人员可以很客易地进行数据分析。与临床研究上常用的SPSS 等软件相比,使用上更加方便,不需要使用者有相关的统计学及机器学习知识。同时,本系统与数据管理功能相结合,可以方便地进行大规模的数据分析。
4.3 使用评价
从以上使用过程可以看出,本系统相对于当前流行的精神分裂症数据处理及分析工具有着以下优势:
(1)数据管理。从数据录入方面来看,本系统相比于流行的Epidata,功能更加全面,不仅满足了Epidata 本有的数据录入功能,可以对已经表格化的电子数据进行批量上传,还可以让被试者直接使用本系统填写CRF 信息,省去了从纸质信息录入系统的过程。从数据存储方面来看,使用本系统录入的数据直接存储在数据库中,无论是稳定性还是安全性,相对于纸质文件、Excel 表亦或是Epidata 的REC 文件保存的数据都有显著的提升。由于本系统中的数据都与被试者ID 相对应,可以最小化地存储数据,不会有数据冗余的情况产生,节省了存储空间。从数据查看方面来看,本系统对各种类型的数据都提供了表格化查看的功能,可以进行数据检索,相对于纸质数据、REC 文件数据以及Excel 数据都有着显著的方便性。
(2)数据分析。从上述分类模型的构建及评价过程可以看出,本系统对精神分裂症的数据分析做了较好的封装。无论是进行统计、分类还是回归,只需要选择一个表格,便可自动完成计算、训练、评估等过程,不需要使用者有很高的数学水平,也不需要使用者进行编程工作。从使用方便性上来看,本系统有着一定的优势,且后台的算法流程将由专门的算法研究人员进行优化迭代,可以保证算法持续有不错的性能。
(3)多中心的扩展性。本系统为B/S 架构,这意味着只要保证网络的连通性,在任何地方打开浏览器便可直接使用。相比于当前精神分裂症的研究工具,是一个更具有前景的系统。如进行多中心的研究,即当多个医院或研究机构都使用本系统进行精神分裂症数据的研究时,方便进行科研合作以及数据共享,可以以一种统一的格式收集大量的精神分裂症多维度信息数据。当数据量增长到一定程度之后,便可扩展为精神分裂症大数据研究平台,结合大数据的算法,可以为精神分裂症提供强大而有效的研究手段。
5 结语
本文应用Spring、MySQL 等关键技术设计并实现了一个针对精神分裂症临床大数据的多维度信息管理系统,并通过实际应用验证了系统功能,可以帮助精神分裂症研究人员进行数据管理和数据分析,在数据管理、数据分析以及扩展性方面有着使用简便、安全高效、扩展性强等优势,体现了系统的创新性,为精神分裂症临床大数据的管理和研究分析提供了一个良好的平台。然而,本系统虽然达到了预期的设计目标,但还是存在一些不足,如只能上传经过计算后的MRI 特征文件、预处理过的EEG 波形,以及目前提供的算法种类只有10 种等,因此仍需要进一步迭代开发,从而提高系统的方便性和实用性。
猜你喜欢
保健医苑(2022年1期)2022-08-30
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
海洋信息技术与应用(2021年2期)2021-11-02
动漫界·幼教365(中班)(2021年4期)2021-05-23
铁道通信信号(2020年4期)2020-09-21
共产党员(辽宁)(2019年7期)2019-11-18
共产党员·上(2019年4期)2019-04-26
环球时报(2017-08-18)2017-08-18
奥秘(2016年3期)2016-03-23
