
基于Python的MODIS卫星秸秆焚烧监测
——以哈尔滨市为例
2020-05-13 07:59周凤杰万鲁河
哈尔滨师范大学自然科学学报 2020年6期
周凤杰,万鲁河*
(1.哈尔滨师范大学寒区地理环境监测与地理信息服务黑龙江省重点实验室;2.哈尔滨师范大学)
0 引言
焚烧秸秆会在短时间内严重影响到空气质量,污染城市大气环境.2017年10月9日,哈尔滨市人民政府印发《哈尔滨市禁止野外焚烧秸秆改善大气环境质量实施方案》(以下简称《方案》),根据《方案》,哈尔滨市将建立市级领导包区县(市)、区县(市)干部包乡(镇)、乡(镇)干部包村、乡(镇)村(屯)干部包农户和地块的逐级包保责任制,形成以乡(镇)、村(屯)、农户、地块为单元的网格化管理体系.快速获取火点数据并对秸秆焚烧发生的地点进行实时核查,成为落实逐级包保责任制关键的一环.该文通过编写Python脚本,快速、实时的从MODIS卫星上获取火点数据,并自动实时生成火点分布图,从而更好地解决这一问题.
1 研究区概况
哈尔滨市处于中国东北地区、东北亚中心地带、黑龙江省南部,地跨东经125°42′~130°10′、北纬44°04′~46°40′,地势东南高,西北低.根据2018年哈尔滨市统计年鉴,2018年年末哈尔滨市占地面积为5.31万 km2,耕地面积为1.97756万 km2,约占总面积的37.24%.其中市区耕地面积为0.540434万 km2,市辖县(市)耕地面积为1.437131万 km2.如图1所示.
2 数据来源
所用的火点经纬度数据来自网站https://firms.modaps.eosdis.nasa.gov/,该网站一共提供了3种不同的数据格式,包括Google Earth KML,CSV表格,Shapefile;并且每种数据格式都提供了3种不同时间段的数据,包括24 h内的火点数据,48 h的火点数据和最近7 d内的火点数据.其中,Google Earth KML,KML 全称是Keyhole Markup Language KML,是一个基于XML语法和文件格式的文件,用来描述和保存地理信息如点、线、图片、折线并在Google Earth 客户端显示;CSV(Comma-Separated Values),逗号分隔值,是一种通用的、相对简单的文件格式,其文件以纯文本形式存储表格数据(数字和文本);Shapefile文件是描述控件数据的几何和属性特征的非拓扑实体矢量数据结构的一种格式,一个Shapefile文件至少包括三个文件:(1)主文件(*.shp),存储地理要素的几何图形的文件;(2)索引文件(*.shx),存储图形要素与属性信息索引的文件;(3)dBASE表文件(*.dbf),-存储要素信息属性的dBase表文件[1].不同的数据格式,但是都用相同的字段标识,文件中共包含13个字段Latitude,Longitude,Bright_ti4,Scan,Track,Acq_Date,Acq_Time,Satellite,Confidence,Version,Bright_ti5,FRP,DayNight;分别表示火点的经度,纬度,亮度温度I-4,沿扫描像素大小,沿着轨道像素大小,采集日期,采集时间,卫星,置信度,版本(收集和来源,其中“1.0NRT”表示收集1 NRT处理,“1.0” - 集合1标准处理)亮度温度I-5,火辐射能量,白天或晚上(其中,D表示白天火灾,N表示夜间火灾).该文以爬取24 h内的Shapefile数据为例.
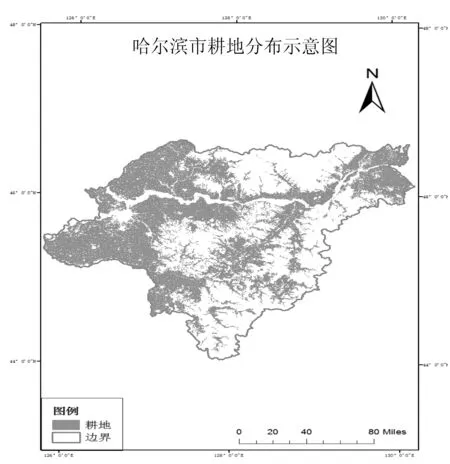
图1 哈尔滨市耕地分布示意图
3 Python简介
Python是一门解释型语言,使用专门的解释器对源程序进行逐行解释成某个特定平台的机器码,在运行时将程序翻译成机器语言,解释型语言相当于把编译型语言中的编译和解释过程混合在一起同时完成.它也常被称作胶水语言,能够把用其他语言(如C,C++等)制作的各种模块,引入到脚本中使用[2].
3.1 丰富的开源库
Python有可定义的第三方库可以使用,如ArcGIS 中自带的ArcPy 库专门用于地理处理;包括文档生成、单元测试、正则表达式、线程、数据库、CGI、网页浏览器、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作.除了Python标准库以外,还可以引用许多高质量的库,如wxPython、Twisted和Python图像库等.还可以在程序中引入深度学习的各种框架,如TensorFlow、Keras、Caffe、MXNet等[3].
3.2 可扩展性和可嵌入性
Python可以跨操作平台运行,即Python程序的核心语言和标准库可以在Linux、Windows及其他带有Python解释器的平台上无差别的运行[4].Python的标准实现是由可移植的ANSIC编写的.
3.3 代码简单易懂,可读性强
Python语法简洁清晰,突出特点之一就是强制用空白符(white space)作为语句缩进.相对于其他高度结构化的编程语言(C++或者Visual Basic)而言,Python更容易被掌握.它的语法简单,编程者将有更多的时间来解决实际问题,而不需要再学习Python语言上花费太多的时间和精力.阅读一个良好的Python程序就感觉像是在读英语一样,尽管这个英语的要求非常严格.Python的这种伪代码本质是它最大的优点之一[5].
4 Python 语言数据处理
4.1 原始数据处理
4.1.1 数据下载
Python标准库中的urllib2模块,定义了一些类和方法主要用于实现对HTTP通信协议的支持,urllib2支持HTTP代理、HTTP简单认证、跳转、Cookie等功能.urllib2 模块还支持对 HTTP请求报文的头和实体进行增改,对 HTTP 应答报文的头和正文进行读取[6].文中利用urllib2模块下载Shapefile数据格式的压缩包数据,并设置数据存储的位置.导入urllib2库下载压缩包,并导入Python标准库中的os模块,用于程序中切换文件路径、自动创建或者移除文件夹、更改文件的名字、判断指定文件夹在指定路径下是否存在等操作.
导入Python的标准库time模块获取当前日期与时间,并转换日期的格式:
(1)获取系统时间,并将日期设为全局变量,以日期命名所有下载的文件,以便以后查询相应时间段的数据:
import urllib2 , os , time
global _date
now = int(time.time())
timeArray = time.localtime(now)
_date = time.strftime("%Y%m%d", timeArray)
(2)new_path = "D:data"
_pathZipFolder = new_path + ""+zip+""
url = ′https://firms.modaps.eosdis.nasa.gov/data/active_fire/c6/shapes/zips/MODIS_C6_Russia_
and_Asia_24h.zip′
# header变量是一个包含各种浏览器信息的字典,目的是用来伪装浏览器爬取数据
header = {′User-Agent′:′Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) C hrome/31.0.1650.63 Safari/537.36′}
os.chdir(_pathZipFolder)
req = urllib2.Request(url,headers = header)
resp = urllib2.urlopen(req)
data = resp.read()
save_name = _date +"_" +"24h"+".zip"
with open(save_name, "wb") as code:
code.write(data)
上述代码在程序中下载的压缩包在计算机中的排列方式如图2所示.
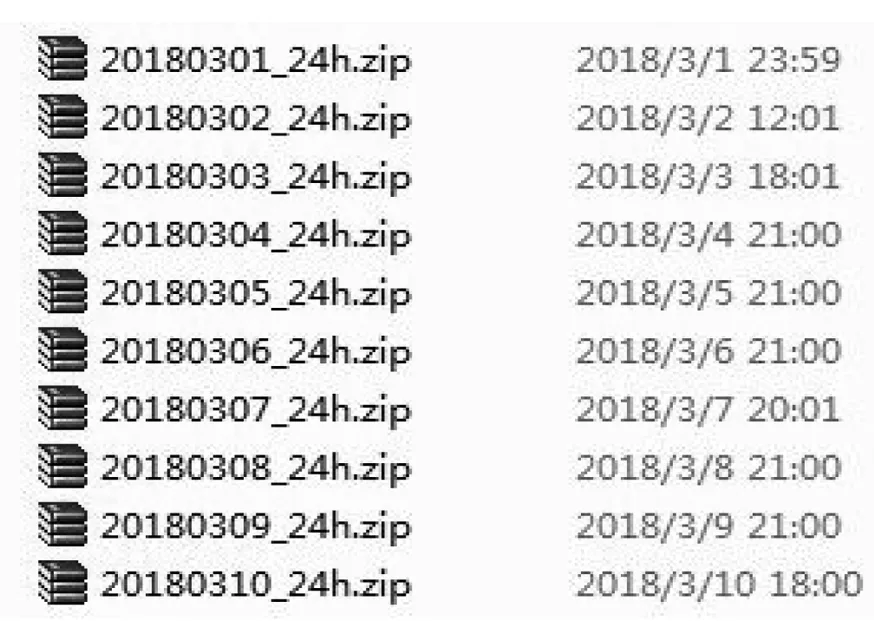
图2 压缩包在计算机中的排列方式
4.1.2 数据解压以及重命名
导入解压zip数据格式的第三方Python库zipfile将前一步骤中生成的压缩包解压到指定文件路径下,利用for循环将文件夹中的所有压缩包解压并更改解压后原来文件的命名,以日期加上下载数据的时间段命名的方式代替,方便以后研究使用对应日期的数据,如20180301_24h.shp.由于解压后的数据没有prj格式的数据,即Shapefile数据的空间参考文件,所以最后解压完成后需要将研究区耕地矢量数据中的空间参考文件拷贝到解压后的指定目录下,并且文件的命名方式与解压更改的命名保持一致,如20180301_24h.prj,拷贝文件需要用到Python自带的文件、文件夹压缩包的处理模块shutil:
(1)定义变量作为解压后文件的存储路径:
_pathShpFolder=new_path + "\"+"shp"+"\"
_pathNewDate=_pathShpFolder+"24h"+"\"
(2)判断文件路径是否已经存在,若不存在,则创建;若存在,则将解压后的文件放置在该文件目录下:
isExists=os.path.exists(_pathNewDate)
if not isExists: os.makedirs(_pathNewDate) ;
print _pathNewDate+′ directory made successfully′
else:
for file in os.listdir(_pathNewDate):
targetFile = os.path.join(_pathNewDate, file)
if os.path.isfile(targetFile):
os.remove(targetFile)
zipFile=_pathZipFolder+_date+"_"+"24h" +
".zip"
(3)切换当前路径到shp文件存储的路径下,并将耕地的空间参考信息prj文件拷贝到路径下:
os.chdir(_pathNewDate)
shutil.copyfile(_pathPrjFile,"prj.prj")
newShpDir = os.listdir(_pathNewDate)
(4)利用for循环,提取文件夹下所有数据的扩展名,在不改变文件自身的属性的条件下,改变文件命名方式:
for temp in newShpDir:
suffix = os.path.splitext(temp)[1]
new_name = _date+"_" +"24h" + suffix
os.rename(temp,new_name)
上述代码在程序中解压压缩包后的文件在计算机中的排列方式如图3所示.
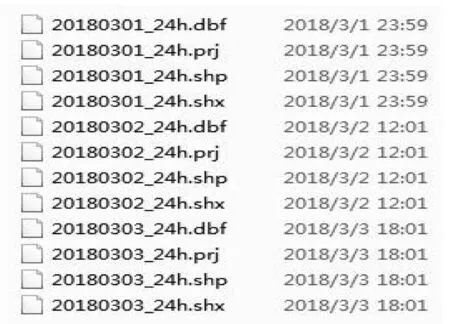
图3 解压后的文件在计算机中的排列方式
4.2 地理数据处理
ArcPy的制图模块可以根据ArcMap会话中的工作流进行工作,一个典型的工作流程包括:打开地图文档,修改数据框属性,加载图层,修改图层属性,编辑页面布局中的元素,将地图文档导出成图片格式.上述过程都可在脚本中通过调用ArcPy制图模块的函数和类来自动完成[7].
4.2.1 裁剪数据源
由于原始Shapefile中包含的是亚洲和俄罗斯的火点数据,所以需要从大量的数据中筛选出研究区的火点数据进行批量处理[8].首先以哈尔滨市的矢量边界基准,裁剪掉哈尔滨市范围外的火点数据;再利用耕地的矢量边界为基准,裁剪掉耕地范围外的火点数据.以下代码部分以裁剪掉哈尔滨市范围外的火点数据为例:
(1)将哈尔滨边界的矢量数据拷贝到与代码同一路径下,并获取其路径:
_clipShp = os.getcwd() + "\" + "border" + "\" +"border.shp"
(2)获取当前地理处理的工作路径并定义被裁减的数据路径和裁剪后输出的路径:
env.workspace = _pathNewDate
inputShp=_pathNewDate+"_"+"24h"+".shp"
outShp=_pathNewDate+"_"+"24h"+"_out.shp"
arcpy.Clip_analysis(inputShp, _clipShp, outShp)
4.2.2 修复数据链接并制图
打开一个长时间没有使用的地图文档,在通过ArcMap打开该地图文档时,ArcMap内容列表中的图层就会有一个带着红色感叹号的标记,并且数据框中不会显示任何图层.
出现这种情况是因为原来的数据链接已经断开,而造成数据链接断开的原因可能有以下几种:地图文档是以绝对路径保存,但是数据源的路径已经发生改变.例如,数据的源文件被移动到其他地方;地图文档以相对路径保存,但是.mxd文档被移动到其他地方,而数据的源文件位置没有改变;数据源的名称被修改过.
数据链接断开的情况经常发生,而且手动修复数据链接也相当繁琐.一旦确定是哪种原因造成数据链接的断开,就可以使用脚本来自动修复数据链接.脚本可以在不打开地图文档的情况下检测和修复断开的数据链接.该文中,主要是针对火点的数据链接进行修复,由于脚本运行时,每一次火点的数据源链接都在发生变化,所以下面Python代码中,主要是采用替换数据源的方式来进行修复工作.
(1)获得地图文档对象,并检测到断开的数据链接的图层,并进行修复:
_pathMxd = os.getcwd() + "\" + "mxd" +
"\" +"baseMap.mxd"
mxd = arcpy.mapping.MapDocument(_pathMxd)
brkLyrList = arcpy.mapping.ListBrokenDataSources(mxd)
fireLyr=brkLyrList[0]
fireLyr.replaceDataSource(_pathNewDate,"SHAPEFILE_WORKSPACE",_date+"_"+"24h"+"_out.shp")
(2)统计当前研究区的火点个数:
iCount=0
cursor = arcpy.da.SearchCursor(_date+"_"+
"24h"+"_out.shp", [′LATITUDE′])
for row in cursor:
iCount=iCount+1
(3)制作火点专题图,并输出到指定文件目录:
_pathJpg = new_path + "\"+jpg+"\"
title = arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT")[1]
title.text=datetime.datetime.now().strftime("%Y-%m-%d")+"(24小时)"
fireCount=arcpy.mapping.ListLayoutElements(mxd, "TEXT_ELEMENT")[0]
fireCount.text=str(iCount)+"个火点"
_pathNewDateJpg=_pathJpg+_date+"\"
arcpy.mapping.ExportToJPEG(mxd, _pathNewDateJpg+
_date+"_"+"24h"+".jpg")
上述代码运行,运行结果产生的专题图如图4所示,表示的是截止2018年3月31日24 h内(左)和2018年4月1日(右)的哈尔滨市疑似火点分布图.
4.3 逆地址解析及数据存储
4.3.1 逆地址解析
(1)由4.2可知,Shapefile数据的属性数据包含经度(Latitude),纬度(Longitude),火点的发生日期(Acq_Date)和时间(Acq_Time).在脚本中,使用游标访问4.2中经过地理处理的矢量数据的属性列表中指定字段的数据.ArcPy.da模块提供了三种类型的游标,分别是搜索、插入和更新,在此过程中,程序中主要使用的是搜索游标.
cursor = arcpy.da.SearchCursor(_date+"_"+"24h"+"_out.shp", "LATITUDE","LONGITUDE",
"ACQ_DATE","ACQ_TIME"])
(2)将上一步骤中搜索到的所有数据进行for循环,获取对应火点的经度和纬度:
for row in cursor:
x = row[0]
y = row[1]
ACQ_DATE = row[2]
ACQ_TIME = row[3]
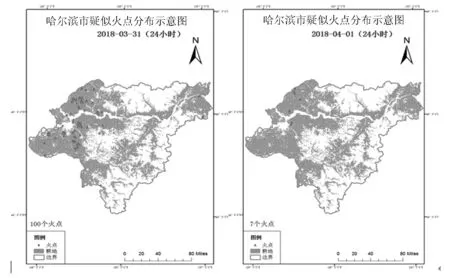
图4 哈尔滨市疑似火点分布示意图
其中,x代表的经度,y代表的是纬度.
(3)调用腾讯逆地址解析的 API接口,解析每一个火点的具体地址.该 API 接口的请求方式是GET请求,其中URL中的主要参数说明见表1.

表1 URL的主要参数说明
导入第三方库requests,它是Python实现的简单易用的HTTP库,requests.get()用于请求目标网站,类型是一个HTTPresponse类型,返回是一个具有JSON数据格式的字符串.为了更加方便的从字符串中取出地址信息,在脚本中引入JSON模块,将字符串转换成python中的字典格式的数据:
import requests,json
url = "http://apis.map.qq.com/ws/geocoder/v1/?location=" + str(y) + ","+ str(x)+"&key=
KGRBZ-CJ2WP-BKYD5-VGPJI-XELGT-5IB23&get_poi=0"
response = requests.get(url).content
results = json.loads(response)
(4)从字典中取出详细的地址信息,由于某些经纬度地址无法精确到乡、镇、街道或者村、屯,所以在脚本中需要添加判断语句,防止信息获取不完整.如果字典的键值中包含关键字"town"和"landmark_l2",则说明该经纬度能解析到乡、镇、街道,反之,则将Town变量和设置为占位符号" - "[9].村、屯信息的获取则采用正则表达式验证字典中的数据是否符合要求:
Province = results["result"]["address_component"]["province"]
City = results["result"]["address_component"]["city"]
District = results["result"]["address_component"]
["district"]
town = "town"
if (town in results["result"]["address_reference"].keys()):
Town = results["result"]["address_reference"]
["town"]["title"] else :
Town = " - "
PATTERN2 = r′([u4e00-u9fa5](?:村|屯))′
landmark_l2 = "landmark_l2"
if (landmark_l2 in results["result"]["address_reference"].keys()):
Village = results["result"]["address_reference"]["landmark_l2"]["title"].encode("utf-8")
Village = Vil.decode(′utf-8′)
pattern2 = re.compile(PATTERN2)
m2 = pattern2.search(Vil)
if m2:
V = Village
else:
V = " - "
else:
V = " - "
4.3.2 非结构化数据存储
(1)在MySQL数据库中新建数据库,在数据库下创建数据表表名设为firedata,数据库结构见表2.
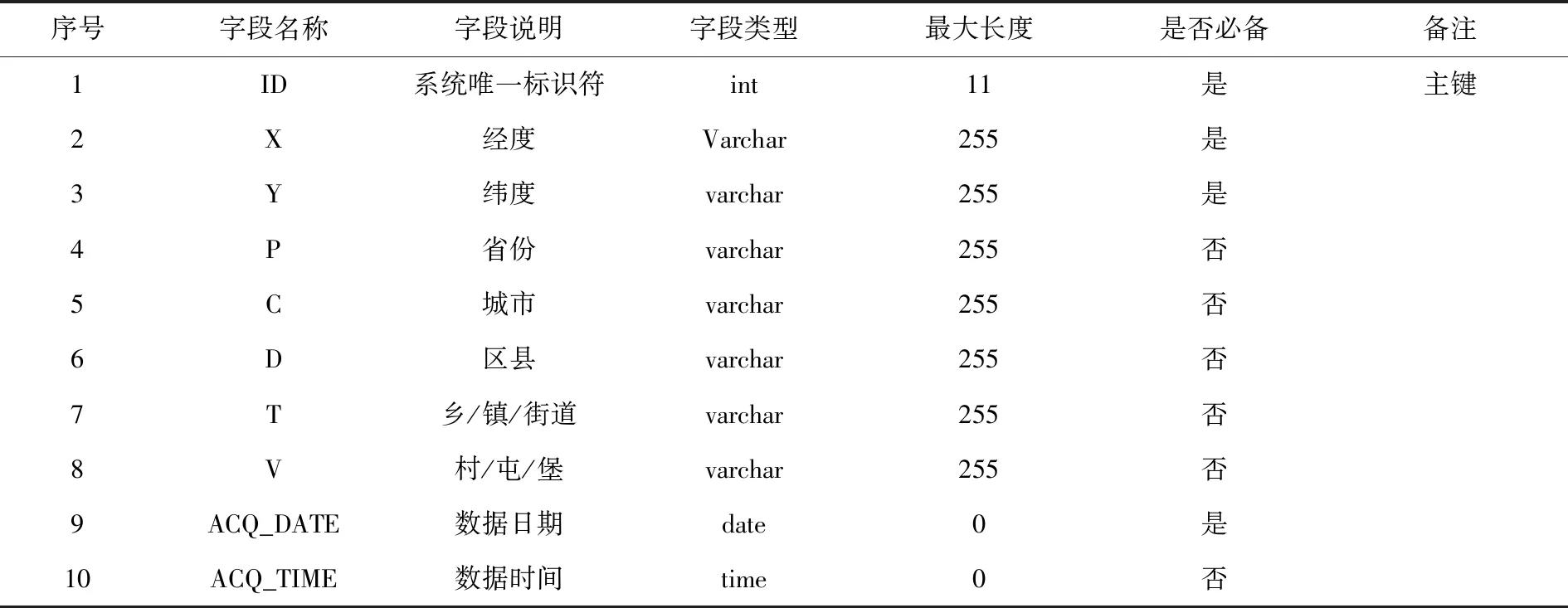
表2 数据库结构说明表
(2)导入Python第三方库MySQLdb连接MySQL数据库并获取相应的数据表的游标,准备存储数据,并在所有数据存储完成(4.3.1中for循环结束)关闭游标和数据库连接[10],防止脚本运行中出现不必要的错误:
conn = MySQLdb.connect(host="localhost",user="root",passwd="mypassword",charset="gbk")
curs = conn.cursor()
conn.select_db(′firedatabase′)
tableName="firedata"
value = [x, y, Province, City, District, Town, V,ACQ_DATE,ACQ_TIME]
curs.execute("insert into "+tableName+"(X,Y,P,C,D,T,V,ACQ_DATE,ACQ_TIME) values(%s,
%s,%s,%s,%s,%s,%s,%s,%s)" ,value)
conn.commit()
curs.close()
conn.close()
其中,host表示数据的主机名称或者IP地址;user表示用户名称;passwd表示数据库的密码;charset表示存入数据库的数据编码格式,gbk代表汉字内码扩展规范.
5 结束语
通过对脚本运行测试的结果来分析,为火点解译工作人员节省了大量的时间,而且在数据自动存储方面有利于保存历史数据,以便以后的研究人员对火点产生的原因及时间段进行研究和分析.
猜你喜欢
客联(2022年3期)2022-05-31
科学技术与工程(2022年11期)2022-05-06
冰雪运动(2021年4期)2021-11-20
口腔护理用品工业(2021年4期)2021-11-02
中国新闻周刊(2021年26期)2021-07-27
中小学校长(2021年1期)2021-03-01
家庭科学·新健康(2019年10期)2019-11-18
全球定位系统(2019年1期)2019-03-14
鹿鸣(2018年1期)2018-01-30
电脑爱好者(2017年7期)2017-05-06
