
基于卷积神经网络的多尺度Logo检测算法
2020-05-12 09:04江玉朝吉立新高超李邵梅
网络与信息安全学报 2020年2期
江玉朝,吉立新,高超,李邵梅
基于卷积神经网络的多尺度Logo检测算法
江玉朝,吉立新,高超,李邵梅
(国家数字交换系统工程技术研究中心,河南 郑州 450002)
针对自然场景图像中多尺度Logo的检测需求,提出了一种基于卷积神经网络的多尺度Logo检测算法。该算法基于两阶段目标检测的实现思路,通过构建特征金字塔并采取逐层预测的方式实现多尺度候选区域的生成,通过融合卷积神经网络中的多层特征图以增强特征的表达能力。在FlickrLogos-32数据集上的实验结果显示,相比基线方法,所提算法能够提升生成候选区域的召回率,并且在保证大中尺度Logo检测精度的前提下,提升小尺度Logo的检测性能,验证了所提算法的优越性。
Logo检测;卷积神经网络;多尺度;区域生成网络;特征融合
1 引言
在计算机视觉领域,多尺度目标检测一直是一项具有挑战性的基础课题。近年来,随着卷积神经网络(CNN,convolutional neural network)的发展,针对大中尺度的目标检测取得了重大突破,而对于小目标,由于受到小目标像素少、分辨率低、背景干扰等因素的影响,相应算法的检测性能仍十分受限。作为目标检测的一个特例,Logo检测在品牌趋势预测、商标产权保护、车辆标志识别等领域有广泛的应用[1-3]。
当前,基于CNN的多尺度目标检测主要有以下两类实现思路[4]:一类是以Faster R-CNN[5]为代表的两阶段方法,此类方法首先生成一定数量的候选区域集合,然后使用分类算法对提取的候选区域进行类别判定和位置精修;另一类是以SSD[6]为代表的单阶段方法,此类方法直接在CNN的多尺度特征图上预测目标类别和边界框回归参数。与两阶段方法相比,单阶段方法在设计之初主要侧重于优化检测的速度,在算法精度方面始终与两阶段方法存在一定差距。因此,本文基于两阶段的实现思路研究自然场景图像中多尺度Logo目标的检测问题,即第一阶段利用候选区域生成算法提取出场景图像中可能包含Logo目标的子区域;第二阶段对该子区域进行类别判定并做进一步的位置精修。显然,对于这样的检测流程,第一阶段生成候选区域的优劣将直接影响检测算法的性能。
作为两阶段目标检测的代表方法,Faster R-CNN[5]通过构建区域生成网络(RPN,region proposal network)生成候选区域。具体而言,RPN在基础特征提取网络之后的单尺度特征图上通过预定义的多尺度锚点(anchor)进行密集采样得到初始候选区域集合,而后经前景分类筛选、边界框回归、非极大值抑制等步骤得到最终的候选区域。这其中存在两个问题:①单尺度特征图的感受野难以适应多尺度目标,造成与感受野尺度不匹配目标的检测性能受限;②预定义的锚点尺度未能适应小目标,导致小目标在RPN训练阶段生成的正负样本数量严重不平衡。
为解决上述问题并适应Logo检测应用场景,本文提出了一种基于CNN的多尺度Logo检测算法。算法在Faster R-CNN的基础上,通过构建特征金字塔并采取逐层预测的方式实现多尺度候选区域的生成,利用理论感受野指导特征金字塔层级的设计,结合有效感受野[7-8]以及Logo对象的先验知识指导预定义锚点的设计,使特征金字塔的每层用于生成特定尺度的候选区域。此外,本文借鉴现今流行的多尺度特征融合思想,在基础网络和目标检测网络之间增加了多尺度特征融合网络,用于融合多层次特征以增强目标检测网络输入特征的表达能力。实验方面,本文在Logo检测的benchmark数据集FlickrLogos-32[9]上进行了详细的算法验证,相比于基线方法[10],本文算法的实验结果取得了明显优势(mAP 85.7% VS 81.1%[10]),验证了本文算法的优越性。
2 相关工作
2.1 多尺度目标检测
现阶段存在很大一部分工作致力于解决多尺度目标的检测问题。图像金字塔思想通过对原始图像进行简单缩放构造图像的多尺度副本,进而实现多尺度目标检测[11-13],通常构造图像金字塔能够显著提升算法的检测精度,但与之而来的庞大内存和时间开销往往令许多实际应用难以承受。鉴于CNN的层次结构本身具有天然的多尺度金字塔形状,一些方法[6,14]选择直接在特征金字塔各层上预测特定尺度的目标,此类单阶段方法一般在速度上具有明显优势,但浅层的高分辨率特征通常难以支撑细粒度的目标分类,导致针对小目标的检测效果一般。因此,文献[15-16]采用多尺度特征融合的方式弥补小目标检测性能的不足,此类算法通过融合语义信息丰富的高层特征和高分辨率的浅层特征,提升了多尺度目标检测的整体性能。
2.2 Logo检测
随着CNN在计算机视觉领域取得的革命性突破,一些研究学者开始将CNN应用在Logo检测任务中。Iandola等[17]较早地开展了这项工作,通过Fast R-CNN[18]建立了使用CNN进行Logo检测的精度基准。Zhang等[3]提出多尺度平行卷积网络用于车辆Logo的识别。为了促进深度学习方法在Logo检测问题中的研究,Hoi等[19]构建了大规模Logo检测与商标识别数据集LOGO-Net。文献[10,20]则从大规模合成Logo图像的角度缓解训练样本缺乏的问题。Christian等[21]通过改进Faster R-CNN中候选区域的生成机制,有针对性地提升了小尺度Logo的检测性能。
3 基于CNN的多尺度Logo检测算法
图1给出了本文基于CNN的多尺度Logo检测算法的整体框架,该框架源于两阶段目标检测的实现思路,算法主要分为基础特征提取网络、多尺度区域生成网络、多尺度特征融合网络、目标检测网络4个部分。其中,图示基础特征提取网络为经典VGG16的全部特征提取层,多尺度区域生成网络负责生成输入图像中可能包含Logo目标的候选区域,多尺度特征融合网络用于整合多层次特征以增强特征的表达能力,目标检测网络实现针对候选区域的类别预测和边界框回归。
3.1 多尺度区域生成网络
从结构上来说,本文算法中多尺度区域生成网络为多级二分类回归的全卷积网络(如图1所示),在层次结构上与SSD[6]、S3FD[14]等相似,均在基础特征提取网络后添加了额外的卷积层,并选取不同尺度的特征层预测特定尺度的目标。不同的是,SSD各预测层直接进行多类目标检测,而S3FD针对的是人脸检测。对于Logo目标,本文算法在设计多尺度区域生成网络时考虑了两个因素:①多层CNN的感受野与Logo目标尺度的适应关系,这直接关系到网络层次结构的设计;②预定义锚点与Logo目标尺度的适应程度,这直接关系到网络的精度和收敛速度。
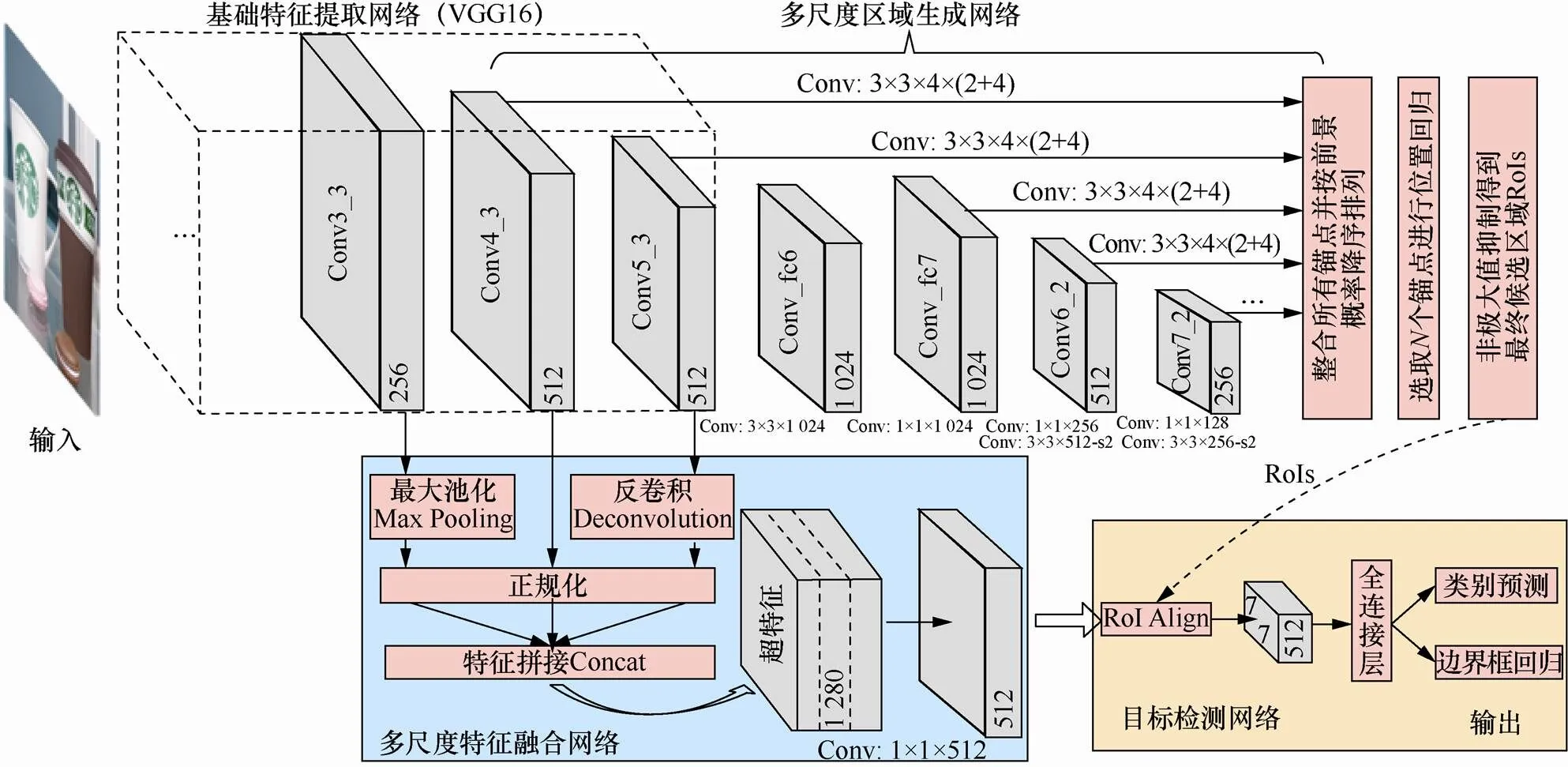
图1 基于CNN的多尺度Logo检测算法
Figure 1 Multi-scale Logo detection algorithm based on CNN
根据CNN感受野理论,CNN某层单位感受区域之外的任何位置都不会影响该层相应单元的输出结果。因此,在设计多尺度区域生成网络时,最后一层卷积特征图上预测单元所对应的理论感受野应当覆盖绝大多数尺度的目标,此项约束实际上也决定了基于CNN的目标检测算法所能预测的目标尺度上限。表1中计算了本文多尺度区域生成网络各预测层经过3×3卷积操作之后的理论感受野,显然经过一系列卷积和池化操作,高层的理论感受野逐步增大。图2给出了FlickrLogos-32数据集对象大小的整体分布情况,结合表1中相关参数可以看出,预测层Conv7_2的理论感受野能够覆盖该数据集中绝大多数尺度的目标,这在理论上保证了本文所设计的多尺度区域生成网络与数据集的目标尺度相适应。

表1 本文多尺度区域生成网络各预测层的相关参数

图2 Flickrlogos-32数据集对象大小分布
Figure 2 Distribution of object instance sizes in Flickrlogos-32
在确定网络层次结构的基础上,算法进一步考虑各预测层上预定义的锚点尺度和高宽比。根据CNN的有效感受野理论[7-8],CNN的有效感受野满足高斯分布,仅占据理论感受野中心区域的较小部分(如图3所示,整体黑色区域为理论感受野,而白色点云区域为有效感受野,图片引自文献[7])。本文为各预测层预设的锚点尺度如表1所示,所设置的锚点尺度均在一定程度上小于相应层的理论感受野,同时采取S3FD中锚点设置的等比例间隔策略,即相应预测层的锚点尺度与该层的步长始终保持等比例,该策略能够保证不同预测层的锚点具备同样的空间密度分布。
生态循环经济的最终目的在于经济发展,作为一项系统化的经济开发活动,它已经不再通过单一的模式来让人们理解和认知经济发展、保护环境与经济发展的系统化融合,主要强调了遵循生态系统的自然规律,注重经济效益的“质量化”增长。因此,在这一经济理念的影响下,国家逐渐形成了良性发展结构、管理机制创新和人文内涵特色化的生态文明。

图3 理论感受野与有效感受野关系
Figure 3 Relationship between theoretical receptive fields and effective receptive fields
在锚点高宽比的设置方面,图4展示了Flickrlogos-32数据集中32类Logo的官方示例,表2近似统计了该数据集中32类官方Logo以及所有Logo对象的高宽比,本文发现,仅从官方Logo的统计层面就能够对锚点的高宽比设置产生较强的指导意义。事实上,由于Logo对象平面性的设计原则,自然场景图像中出现的Logo通常具备较稳定的高宽比。进一步考虑实际场景中Logo目标可能存在旋转、扭曲等情况,本文预设的锚点高宽比如表2所示。

图4 FlickrLogos-32官方Logo示例
Figure 4 Exemplar images of Logo classes from the FlickrLogos-32

表2 Flickrlogos-32中官方Logo以及所有Logo对象高宽比的近似统计
因此,本文选择采取与SSD类似的粗放式正负样本生成策略,即对于正样本,算法允许任意标记样本在网络产生的全体锚点范围内进行匹配操作。具体而言,算法首先为每个真值框(ground truth)匹配与之IoU(intersection over union)值最大的锚点作为正样本,然后在剩余锚点中挑选与任一真值框IoU值高于0.5的也作为正样本。对于负样本,算法依据常用的难分负样本挖掘方法,首先筛选出与任意真值框IoU值都低于0.3的锚点子集作为初始负样本集合,接着按照预测背景概率由低到高的顺序对集合中的所有锚点进行排序,选取概率较低的锚点作为最终的负样本,并限制最终选定的正负样本数量之比不超过1:3,以保证网络的快速收敛[6,14]。
在训练目标方面,本文基本沿用原始RPN[5]中定义的多任务损失函数。由此,对于单个训练样本,本文多尺度区域生成网络的损失函数定义为

3.2 多尺度特征融合网络
在原始Faster R-CNN框架中,RPN生成的每个候选区域在特征层Conv5_3上完成位置映射后,由RoI pooling操作产生固定尺寸的特征图,而后送入目标检测网络得到最终的检测结果。为了进一步提升多尺度Logo检测算法的整体性能,本文借鉴现今流行的多尺度特征融合思想[23-24],在基础网络与目标检测网络之间增加了多尺度特征融合网络。如图1所示,网络选定Conv4_3作为特征融合的基准层,因为该层相对于Conv5_3具有更小的步长,更有利于小目标的检测。同时,网络使用最大值池化(max pooling)实现针对Conv3_3特征层的下采样,使用文献[25]中的反卷积(deconvolution)实现针对Conv5_3特征层的上采样,并保证采样后的特征图均与基准层Conv4_3的大小相同。
由于特征层Conv3_3、Conv4_3和Conv5_3三者的特征尺度差异很大[24],直接融合将导致特征尺度较大的层对于后续的预测结果产生支配性的影响,而这些特征层本身并不能保证良好的检测性能,相反会增加后续参数学习的难度。因此,网络在对采样后的多层特征图进行融合前,先分别对Conv3_3、Conv4_3和Conv5_3层实施文献[24]中引入的L2正则化操作,并相应扩大各层特征的初始L2范数值为10、8、5,以提升网络的训练速度[14]。
3.3 目标检测网络与联合训练
作为两阶段目标检测的第二阶段,目标检测网络针对候选区域做进一步的类别判定和位置精修。如图1所示,本文目标检测网络仍基于Faster R-CNN中实现,即利用全连接层产生最终的分类和回归结果。不同的是,为了缓解原始RoI pooling操作[5]在候选区域映射过程中两次离散性的量化造成的区域不匹配问题[26],本文使用文献[26]中提出的RoI Align代替RoI pooling操作,这在一定程度上减轻了候选区域映射过程产生的位置偏差对于小目标检测的影响。
在多网络的联合训练方面,本文基于候选区域生成先于目标检测的顺序流程,参考Faster R-CNN中提出的四步交替训练方法,将本文多网络的联合训练过程分为以下4个阶段。①单独训练区域生成模块,该模块包括基础网络和多尺度区域生成网络,其中基础网络、Conv_fc6以及Conv_fc7基于ImageNet预训练模型初始化[6],其他新添加层使用标准差为0.01的零均值正态分布进行随机初始化。②单独训练目标检测模块,该模块包括基础网络、多尺度特征融合网络和目标检测网络,其中基础网络以及目标检测网络同样基于ImageNet预训练模型初始化,多尺度特征融合网络中的反卷积层基于双线性插值法初始化[25],降维卷积核参数使用标准差为0.01的零均值正态分布进行随机初始化,训练所需的候选区域由区域生成模块提供。③再次训练区域生成模块,其中基础网络由第二阶段训练所得的对应参数初始化,并保持其参数在训练过程中固定,只更新区域生成模块的独有部分。④再次训练目标检测模块,固定第三阶段区域生成模块的所有参数,只更新目标检测模块的独有部分。
4 实验与结果分析
4.1 数据集与评价指标
本文实验采用的数据集源自奥格斯堡大学多媒体计算和计算机视觉实验室维护并公开的FlickrLogos-32[9],作为Logo检测的benchmark数据集,其通常用于评估多类Logo检测/识别以及真实图像上的Logo检索方法。FlickrLogos-32共有8 420张图像(包含6 000张不含Logo的图像),分为32类Logo,每类为70张且均具有较为平坦的表面。图2给出了该数据集对象大小的整体分布情况,不难发现:①该数据集对象具有较大的尺度变化范围,适用于评估检测算法的尺度不变性;②该数据集对象的平均尺度较小,适用于检验算法在小目标检测方面的性能。
在实际训练过程中,本文按照该数据集的官方划分标准,为每类Logo划分40张图像用于训练,剩余30张用于测试。由于本文算法中多尺度区域生成网络采取粗放式的正负样本生成策略,该策略下网络的充分训练无疑对训练样本的数量和质量均提出了较高要求,因此,本文在将训练样本送入网络训练之前,预先对每张训练图像随机采取如下数据增强操作:①直接使用原始图像;②对原始图像随机进行2倍或4倍的下采样,原图范围内的剩余区域全0填充;③对原始图像随机进行1.5倍或2倍的上采样,并使用边长为600px的正方形区域对采样后的图像进行随机裁剪,同时保证裁剪后子图像中包含的任一真值框区域与上采样后真值框的面积之比不低于0.8。
目标检测任务通常需要一定的评价指标来评估检测算法的性能,Logo检测领域中常用的评价指标是平均精度均值(mAP,mean average precision)。mAP综合表征了准确率(precision)和召回率(recall),其值越大,表明算法性能越好,本文中使用mAP值评估检测算法的整体性能。此外,本文使用召回率均值(mR,mean recall)评估算法中多尺度区域生成网络的有效性,该指标计算一组实验条件下多类目标召回率的算术平均值,能够反映区域生成网络为多类目标生成高质量候选区域的平均性能。
4.2 对比实验与分析
本文算法基于深度学习框架PyTorch实现,从节约内存和便于实现的角度出发,每批次只训练一个样本,使用随机梯度下降算法优化神经网络参数,同时为了节约显存,基础网络中的前四层卷积层的学习率设为0。对于多网络的联合训练,本文区域生成模块每阶段迭代6×104次,目标检测模块每阶段迭代4×104次,初始学习率均为0.001,学习率衰减步长为4×104,衰减系数为0.1。
表3列出了4种不同算法在FlickrLogos-32数据集上的实验结果,可以看出,与基线方法Faster R-CNN[10]相比,本文算法取得了明显优势(85.7% VS 81.1%)。在基线方法的复现过程中,本文基于VGG16和RoI Align[26]的实验配置,得到了与其相近的实验结果,这表明本文算法相对于基线方法的性能提升直接来源于本文算法的改进部分,即多尺度区域生成网络和多尺度特征融合网络。
在不同尺度目标的检测性能评估方面,本文统计了FlickrLogos-32测试集中每类Logo对象的平均尺度,然后将Logo类别按照平均尺度的降序排序,顺序选取了前、中、后各5类Logo分别作为大、中、小尺度的代表。图5直观对比了本文算法与基线方法在所选类别上的平均精度,可以发现,对于大中尺度的目标,本文算法与基线方法的整体检测性能基本相当;而对于尺度较小的目标,本文算法的平均精度明显高于基线方法,这表明本文算法在小尺度目标检测方面更加稳健。

图5 本文算法与基线方法在不同尺度类别上平均精度的对比
Figure 5 Comparison of the AP of different scale categories between our algorithm and the baseline

表3 不同算法在FlickrLogos-32数据集上的实验结果
除此之外,为了验证本文算法中多尺度区域生成网络的有效性,本文分别计算了测试集上多尺度区域生成网络与原始RPN[5]在生成单位数量候选区域条件下的召回率均值,所有召回率的计算均基于0.5的IoU阈值,即仅当某真值框与该图像中任一候选区域的IoU值超过0.5,该真值框被判定为召回。如图6所示,可观察到:①多尺度区域生成网络在任意数量候选区域条件下产生的召回率均值都明显优于原始RPN,这表明利用特征金字塔逐层预测不同尺度候选区域的做法,能够有效提升生成候选区域的召回率;②在IoU阈值0.5的设定下,两种区域生成算法的召回率均值都不高,尽管后续目标检测网络会对候选区域进行位置精修以保证最终的召回率,但目前区域生成算法的实际性能仍有进一步提升的空间,因此这方面成为下一步的研究重点。

图6 本文算法与基线方法在区域生成网络性能方面的对比
Figure 6 Comparison of the PRN performance between our algorithm and the baseline
最后,本文实验探究了多尺度特征融合网络对于算法性能的影响,替换图1中目标检测网络的输入为单特征层,其他参数保持不变,得到的检测结果如表4所示。从表4中可以看出,基于权重可学习的特征融合算法能够在一定程度上提升检测算法的整体性能。图7给出了本文基于CNN的多尺度Logo检测算法与基线方法在FlickrLogos-32部分测试实例上检测结果的对比(右侧为本文算法的检测结果),可以发现本文算法对于目标的多尺度、小尺度等情形具备更强的稳健性。

表4 多层特征融合预测与单特征层预测在检测精度上的对比

图7 本文算法与基线方法在部分测试实例上检测结果的对比
Figure 7 Comparison of the detection results of our algorithm and the baseline on some test images
5 结束语
本文针对自然场景图像中多尺度Logo的检测需求,提出了一种基于CNN的多尺度Logo检测算法。算法在两阶段目标检测模型Faster R-CNN的基础上,通过构建特征金字塔并采取逐层预测的方式实现多尺度候选区域的生成,同时增加了多尺度特征融合网络,用于整合多层次特征以增强特征的表达能力。在FlickrLogos-32数据集上的实验结果表明:①采取特征金字塔逐层预测多尺度候选区域的方式,能够有效提升生成候选区域的召回率;②基于权重可学习的特征融合做法能够在一定程度上提升检测算法的整体性能。由于目前本文区域生成算法的性能仍与设计预期存在一定的差距,提升生成候选区域的召回率是下一步的研究方向。
[1] SU H, GONG S, ZHU X. Scalable deep learning logo detection[C]//International Conference on Computer Vision Workshop. 2017: 270-279.
[2] GAO Y, WANG F, LUAN H, et al. Brand data gathering from live social media streams[C]//International Conference on Multimedia Retrieval. 2014: 169.
[3] PAN C, YAN Z, XU X, et al. Vehicle logo recognition based on deep learning architecture in video surveillance for intelligent traffic system[C]//IET International Conference on Smart and Sustainable City. 2013: 123-126.
[4] ZHANG S, WEN L, BIAN X, et al. Single-shot refinement neural network for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
[5] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//International Conference on Neural Information Processing Systems. 2015.
[6] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]// European Conference on Computer Vision. 2016.
[7] LUO W, LI Y, URTASUN R, et al. Understanding the effective receptive field in deep convolutional neural networks[C]//Conference and Workshop on Neural Information Processing Systems. 2016.
[8] ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[J]. Computer Science, 2014.
[9] ROMBERG S, PUEYO L G, LIENHART R, et al. Scalable logo recognition in real-world images[C]//ACM International Conference on Multimedia Retrieval. 2011: 25.
[10] HANG S, ZHU X, GONG S. Deep learning logo detection with data expansion by synthesising context[C]//Applications of Computer Vision. 2017.
[11] HU P, RAMANAN D. Finding tiny faces[C]//Computer Vision & Pattern Recognition. 2017.
[12] EGGERT C, WINSCHEL A, ZECHA D, et al. Saliency-guided selective magnification for company logo detection[C]//IEEE 23rd International Conference on Pattern Recognition (ICPR). 2016.
[13] MENG Z, FAN X, XIN C, et al. Detecting small signs from large images[C]//IEEE International Conference on Information Reuse and Integration. 2017.
[14] ZHANG S, ZHU X, LEI Z, et al. S3FD: single shot scale-invariant face detector[C]//International Conference on Computer Vision. 2017.
[15] CAO G, XIE X, YANG W, et al. Feature-fused SSD: fast detection for small objects[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[16] LIN T Y, DOLLÁR, PIOTR, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[17] IANDOLA F N, SHEN A, GAO P, et al. DeepLogo: hitting logo recognition with the deep neural network hammer[J]. arXiv preprint arXiv:1510.02131, 2015.
[18] GIRSHICK R. Fast R-CNN[C]//International Conference on Computer Vision. 2015.
[19] HOI S C H, WU X, LIU H, et al. LOGO-Net: large-scale deep logo detection and brand recognition with deep region-based convolutional networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 46(5): 2403-2412.
[20] EGGERT C, WINSCHEL A, LIENHART R. On the benefit of synthetic data for company logo detection[C]//The 23rd ACM International Conference on Multimedia. 2015.
[21] EGGERT C, ZECHA D, BREHM S, et al. Improving small object proposals for company logo detection[J]. arXiv preprint arXiv:1704. 08881, 2017.
[22] GIRSHICKR, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2014.
[23] KONG T, YAO A, CHEN Y, et al. HyperNet: towards accurate region proposal generation and joint object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[24] LIU W, RABINOVICH A, BERG A C. ParseNet: looking wider to see better[J]. Computer Science, 2015.
[25] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.
[26] HE K, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, (99): 1.
[27] OLIVEIRA, GONÇALO, FRAZÃO, et al. Automatic graphic logo detection via fast region-based convolutional networks[C]//International Joint Conference on Neural Networks. 2016: 985-991.
Multi-scale Logo detection algorithm based on convolutional neural network
JIANG Yuchao, JI Lixin, GAO Chao, LI Shaomei
National Digital Switching System Engineering & Technological R&D Center, Zhengzhou 450002, China
Aiming at the requirements for multi-scale Logo detection in natural scene images, a multi-scale Logo detection algorithm based on convolutional neural network was proposed. The algorithm was based on the realization of two-stage object detection. By constructing feature pyramids and adopting layer-by-layer prediction, multi-scale region proposals were generated. The multi-layer feature maps in convolutional neural networks were fused to enhance the feature representation. The experimental results on the FlickrLogos-32 dataset show that compared with the baseline, the proposed algorithm can improve the recall rate of region proposals, and can improve the performance of small Logo detection while ensuring the accuracy of large and middle Logo, proving the superiority of the proposed algorithm.
Logo detection, convolutional neural network, multi-scale, region proposal network, feature fusion
The Nature Science Foundation of China (No.61601513)
TP391
A
10.11959/j.issn.2096−109x.2020026

江玉朝(1994−),男,江苏盐城人,信息工程大学硕士生,主要研究方向为计算机视觉。
吉立新(1969−),男,江苏淮安人,博士,信息工程大学研究员、博士生导师,主要研究方向为通信与信息系统。

高超(1982−),男,河南郑州人,博士,信息工程大学助理研究员、博士生导师,主要研究方向为计算机视觉。
李邵梅(1982−),女,湖北钟祥人,博士,信息工程大学副研究员,主要研究方向为计算机视觉。
论文引用格式:江玉朝, 吉立新, 高超, 等. 基于卷积神经网络的多尺度Logo检测算法[J]. 网络与信息安全学报, 2020, 6(2): 116-124.
JIANG Y C, JI L X, GAO C, et al. Multi-scale Logo detection algorithm based on convolutional neural network[J]. Chinese Journal of Network and Information Security, 2020, 6(2): 116-124.
2019−05−29;
2019−08−11
江玉朝,jingjiujiang@qq.com
国家自然科学基金资助项目(No.61601513)
猜你喜欢
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
北京航空航天大学学报(2021年9期)2021-11-02
电子技术与软件工程(2020年22期)2021-01-30
数字技术与应用(2020年12期)2021-01-22
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
移动通信(2020年5期)2020-06-08
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
