
具有拒识机制的分类器在人脸识别中的应用
2020-05-12 09:09杨国为
小型微型计算机系统 2020年3期
孙 玥,杨国为,2
1(青岛大学 电子信息学院,山东 青岛 266071)
2(南京审计大学 信息工程学院,南京 210000)
E-mail:yue_er94@163.com
1 引 言
在通过生物特征对人脸认证识别时,往往需要引入合适拒识机制[1-3],以便分类器工作时,要么拒识,要么分类绝对正确.也即要求:1)拒识率(在公共测试样本库中,拒识的样本个数与测试样本库的总样本个数之比)很小;2)正确识别率(在去掉拒识的样本之后的测试样本库中,正确分类样本个数与总样本数的比例)逼近100%.若拒识率较大,则分类器的实用范围和场合受到限制.若正确识别率不能逼近100%,则不能直接用该识别器去认证一些特别重要场合.显然拒识率小与正确识别率高是矛盾事件,解决该矛盾十分困难.
要做到拒识率小、正确识别率高实际上就是要设计识别器,使该识别器确定的同w类样本的特征区域(把区域内的任一点视为w类样本点,而把区域之外点视为别的类点或拒识点)几乎包含了w类所有样本点形成的实际特征区域(几乎不损失自己领域),同时几乎不侵占别的已知类的特征区域和未知可能类的特征区域.
系列有代表性超球支持向量机(超球SVM)分类算法思想[4-7]是将所有特征向量映射到一个很高维的空间里,在这个空间里建立一个满足某种约束的半径最小超球面,超球面包裹几乎所有同类样本点.该超球面或同心超球面对应的原始空间曲面就是分类决策面.但是超球SVM分类决策面包裹区域侵占了未知类别的特征区域,即分类决策面没有紧密包裹同类样本实际特征区域.在以上超球SVM分类器中也存在问题:
1)没有引入合适拒识机制:因为不方便确定恰当的拒识区域,或者勉强确定了拒识区域,但并不一定带来正确识别率提高;
2)分类决策面包裹区域侵占未知类的特征区域,有把未知类错判为某已知类的风险,分类器正确识别率不能逼近100%.
本文针对支持向量数据描述(Support Vector Data Description,SVDD)设计中存在的难题,提出了一种具有合适拒识机制的高正确识别率分类器设计算法—基于同类特征点集的同类特征区域紧密包裹曲面的求解算法(Closely Enveloped Surface-Support Vector Data Description,CES-SVDD),设置了所有紧密包裹面之外的公共区域为分类器的拒识区域,从而得到一种具有合适拒识机制的高正确识别率分类器设计算法.
2 相关理论与证明
2.1 SVDD分类决策面不紧密包裹同类特征的例子
如图1所示,二维平面内中,有两个区域,一个形如香蕉的区域,另一个区域是香蕉以外的小部分区域.对两区域做采样,香蕉区域采样点用*号表示,采样50个,其他区域内采样点用+表示,采样10个,分布在香蕉周围.在SVDD模型中,训练*号点集超球面,映射到原始空间得到一个如图类似圆.很明显类似圆包裹不紧密,之间有较大空隙,分类决策曲面包裹的区域侵占了未知类特征区域.
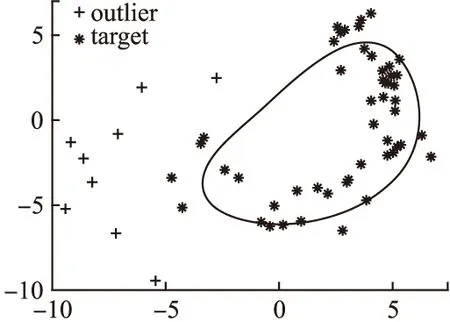
图1 分类决策结构图
2.2 同类特征集合的紧密包裹集的存在性证明


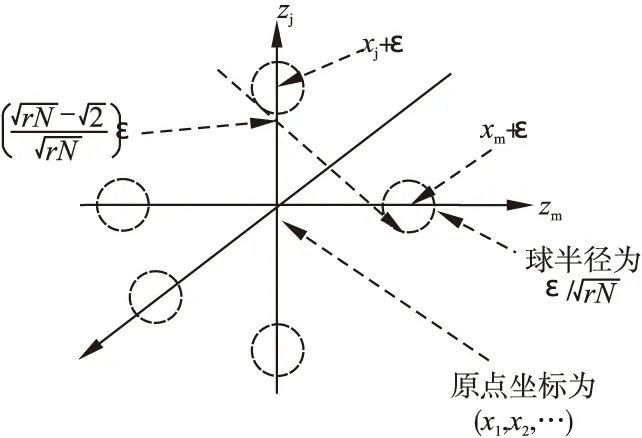
图2 坐标示意图
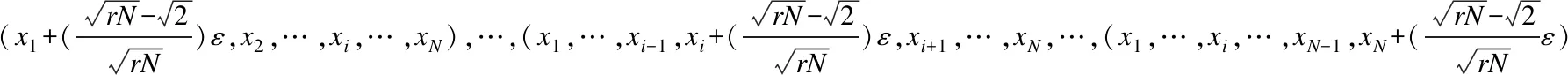
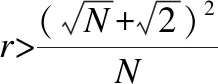
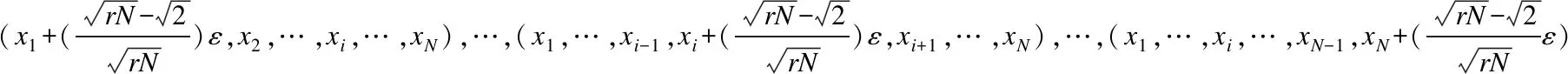

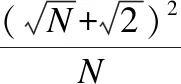
3 算法设计
CES-SVDD算法由“同类特征集合的紧密包裹集构造算法”、“基于同类特征点集和包裹点集的同类特征区域紧密包裹曲面的求解算法”、“多类分类器的合适拒识区域设置算法”组成.
3.1 同类特征集合的紧密包裹集构造算法

第二步由每一个Xj=(xj1,…,xji,…,xjN),1≤j≤M派生出2N个点(xj1,…,xji±ε,…,xjN),1≤i≤N.

由前面定理1可知,I(C)中点的个数不少于C的边界点个数.
3.2 基于同类特征点集和包裹点集的同类特征区域紧密包裹曲面的求解算法

图3 紧密包裹曲面示意图
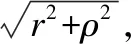
为了方便设C中有m1个点,I(C)中有m2=n-m1个点,c是高维空间的球心.我们建立以下优化模型,通过求解优化解来构造同类特征区域紧密包裹曲面.
(1)
s.t.‖φ(Xi)-c‖2≤r2-ξi, 1≤i≤m1‖φ(Xi)-c‖2-r2-ρ2+ξj),m1≤j≤n,0≤ξk,1≤k≤n
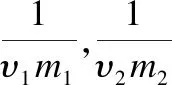
(2)
Lagrange函数的极值点应满足:
(3)
(4)
(5)
(6)
(7)
因此:
(8)
这样得对偶问题模型:
(9)
用K(Xi,Xj)替代φ(Xi)·φ(Xj),由可核函数性质知:
(10)
对偶问题是一个二次优化问题,可用二次优化问题求解方法求解[11,12].本文用经典的序贯最小优化(sequential minimal optimization,简称SMO)算法来求解.
在求解以上问题之后,为求出r、ρ2和r2+ρ2,考虑两集合:
(11)
(12)
令n1=|S1|,n2=|S2|,由KKT条件[13]知:
(13)
其中:
P1=∑xi∈S1‖φ(Xi)-c‖2
(14)
P2=∑xj∈S2‖φ(Xi)-c‖2
(15)
(16)
分类决策函数为:
f(x)=sgn(r2-‖φ(X)-c‖2)
(17)
分类决策曲面为:
r2-‖φ(X)-c‖2
(18)
该曲面(曲面上点求解可用数值计算方法求近似解)紧密包裹同类特征区域.特征区域边界到分类决策边界的坐标方向距离(投影长度)小于ε.
3.3 多类分类器的合适拒识区域设置算法
当人脸识别应用于人身份认证识别、银行储蓄认证识别、门禁系统认证识别等高正确识别率的任务时,对于无法确定的情况的出现,我们必须要设置一定的拒识机制,从而有效遏制不良情况的出现.
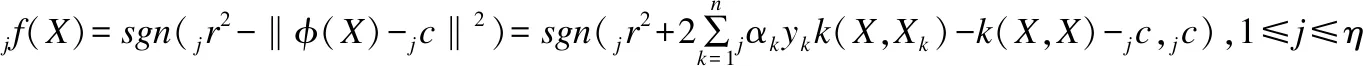
(19)
和分类决策紧密包裹曲面:
jr2-‖φ(X)-jc‖2
(20)
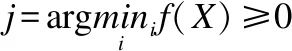
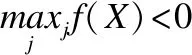
4 实验实现
4.1 人脸图像预处理
实验数据使用ORL人脸数据库和扩展Yale B人脸数据库,样例如图4和图5所示.ORL面部库存由40个人在一定的光线,表情(微笑,眨眼,闭眼等)和配件(眼镜)组成,每个都有10个图像.其中前五张为训练集,后五张为测试集.扩展Yale B包含16128张照片,包括38人在9个姿势和64个照明条件下拍摄的图像.本实验选用到的数据为30人的每人50张图像,其中前30张为训练集,后20张为测试集,未被选用到的是光照太弱的模糊不清的图像,即用到的图像总数为1500张,数据库中的图像数据都是手动对齐、裁剪的,然后重新调整到168×192大小的图像.

图4 ORL数据库样例
预处理所获取的面部图像是面部识别中的重要步骤.其目的是减小外界环境对要识别的目标图像的干扰,并且使图像达到标准化[14,15].通过预处理,可以最大限度的把干扰减到最小,并对人脸识别性能的稳定性起到一定作用.
由于主成分分析(PCA)是基于图像灰度统计的算法,因此需要对面部图像进行适当的预处理.首先,需要将彩色图像转换为灰度图像,然后通过直方图均衡化方法对直方图图像进行归一化,有效地消除了噪声对人脸图像灰度分布的影响.预处理原始图像可以有效地解决基于统计提取特征的外部干扰引起的图像差异(如照明,照片角度等与脸部图像本身(每个脸部的大小不同)之间的差异.
4.2 人脸图像特征提取
特征提取是将对分类模式识别最有效的特征提取出来,通过这一过程可以压缩模式的维数,使之便于处理,减少损失.
特征提取后的特征空间是为了分类使用的,对于相同的物体在不同的分类规则下,提取的特征必须满足某些标准下的最小分类误差.在特诊提取的同时删除贡献微弱的特征,已达到减少分类错误额目的.

图5 Yale B数据库样例
特征面部方法使用主成分分析(PCA),也称为KL变换,并且通常用于面部图像的表示和识别[16].主成分分析最早用于统计学,用来找出某一集合的主要成分.对于L×L维的面部图像,可以认为它属于图像空间,并且该图像空间可以被定义为所有尺寸L×L的一组像素矩阵.并且图像空间中的基矢量的数量是L×L,并且L×L个基矢量被任意加权和组合.您可以在图像空间中获取任何图像.假设像素的灰度级为8,则图像空间中共有256 L× L个图像,这其中人脸空间只占很小的一部分,因此,使用图像空间的基矢量来表示面部空间显然会带来冗余,以减少冗余,最合适的方法是用人脸空间本身的基向量来表示人脸.在面部空间进行KL变换以进行训练,以获得面部空间本身的基础矢量.它被称为特征向量,也称为特征面,所有特征面的集合称为特征面空间.使用这些特征向量来表示面部空间大大减少了冗余.

图6 部分特征脸
对于ORL人脸库来说,对所截取的人脸图像通过预处理后,PCA降维至20维,低维空间的图像是40*5*20的矩阵,每条线代表一个主要组件面,每个面都有20维特征.对于扩展Yale B数据库来说,对人脸图像通过预处理后,PCA降维至20维,低维空间的图像是30*30*20的矩阵,部分特征脸如图6所示.
剩余的尺寸减小的面可以由特征面线性地表示.在选择要识别的面以降低维数然后将由这些基底(特征面)形成的矩阵相乘之后,可以获得这些面在低维度上的线性表示.这些表示就是识别的依据.
4.3 CES-SVDD算法在人脸识别中的应用
将CES-SVDD算法用于人脸识别工作,并与最初的SVDD作对比,以此验证算法的有效性.对于ORL数据库使用前5张作为训练集,共有200张图片.使用矩阵表示200个映射,形成200*10304矩阵.后5张图用来当测试集,共有200张图.对于扩展Yale B数据库来说,使用前30张作为训练集,共有900张图片.使用矩阵表示900个映射,形成900*32256矩阵.后20张图用来当测试集,共有600张图.
4.4 实验评价与讨论
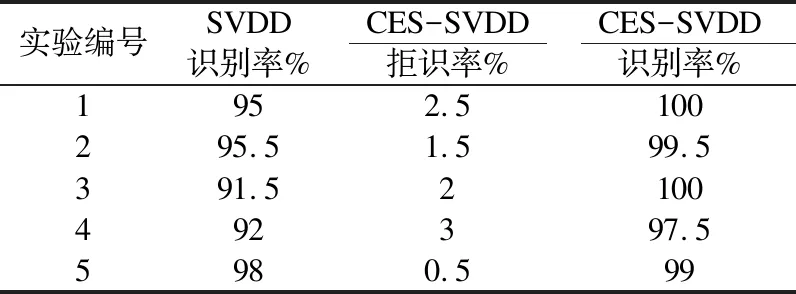
对两个测试数据处理后,分别用SVDD和CES-SVDD进行分类识别,两种方法各进行5次实验后,结果如表1和表2所示,为了更加直观的观察实验结果,将5次实验结果生成折线图,如图7和图8所示.其中,拒识率指在公共测试样本库中,拒识的样本个数与测试样本库的总样本个数之比;识别率指在去掉拒识的样本之后的测试样本库中,正确分类样本个数与总样本数的比例.
表1 ORL实验结果
Table 1 ORL experimental result
实验编号SVDD识别率%CES-SVDDCES-SVDD拒识率%识别率%1952.5100295.51.599.5391.52100492397.55980.599
表2 Yale B实验结果
Table 2 Yale B experimental result

实验编号SVDD识别率%CES-SVDDCES-SVDD拒识率%识别率% 190.2 3.399.8296.64.6100392.34.198.3491.22.399.1593.13.699.7

图7 ORL实验结果
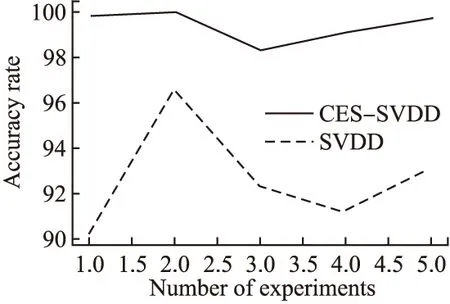
图8 Yale B实验结果
由表1、表2可以看出,对于两个数据库来说,只要拒识率合适,识别准确率都可以逼近100%,并且很明显CES-SVDD的效果比没有加紧密包裹集的SVDD的正确率高.
4.5 实用性场景应用
对于高识别率的识别器可以去认证一些特别重要场合.比如公司考勤系统,需要确保公司人员的高准确率;银行取款机,在面临大额交易下往往需要确保取款人员是否是本人,本文提出的识别方法在去除拒识图片后识别率通常都会达到100%,可以用于这类高要求的识别场合.效果如图9所示.

图9 识别效果
5 结束语
论文讨论了通过生物特征对人脸认证识别的高正确识别率分类器设计要求,指出了现有一些超球SVM分类器存在没有合适拒识机制和正确识别率不能逼近100%等问题.举除了超球SVM分类决策面不紧密包裹同类特征的实例.证明了同类特征集合的紧密包裹集的存在定理.提出了基于同类特征集合和紧密包裹集的同类特征区域紧密包裹面的求解算法.以ORL人脸库和Yale B做对比实验,实验表明本文提出的分类器设计算法是一种有效的高正确识别率分类器设计方法.今后的方向主要是对于维度比较大模糊图像的处理研究,争取在降低拒识率的基础上,提高识别的准确率.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
科学中国人(2017年30期)2017-12-28
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
儿童故事画报(2015年7期)2016-01-27
