
基于教育大数据挖掘的大学生学业预警研究
2020-05-11 11:49吴修国孙涛
中国教育信息化·高教职教 2020年4期
吴修国 孙涛
摘 要:教育大数据挖掘通过对教育领域的各种海量数据进行分析,发现其中存在的规律,从而指导教育教学管理水平。文章在对现有研究存在的问题进行分析基础上,首先给出教育大数据挖掘的学业预警研究框架;之后,通过对大学生在校成绩数据进行整合管理,基于关联规则算法给出大学生不及格课程之间的关联关系,以此为大学生学业提出预警(课程不及格以及留级)提示。研究结果表明,该方法为管理者有针对性地对预警学生进行帮助和干预提供了数据支撑,具有较强的应用价值,可有效提升高校教学管理水平和管理质量。
关键词:教育大数据;数据挖掘;关联规则;学业预警
中图分类号:G642.47 文献标志码:A 文章编号:1673-8454(2020)07-0055-04
一、引言
近年来,随着高校规模不断扩大以及外界因素的影响,大学生的学习能力与素质基础出现了不同程度的下降。据统计,每年各高校都有部分学生因为课程挂科等原因,无法顺利毕业,对学生个人、家庭以及学校而言都是难以挽回的损失。学业预警是学校对在校大学生的学业表现(包括成绩、出勤、作业情况等)进行评估之后,根据其学业表现情况,对学生下一步的学习进行及时提醒的一种监督管理制度。一方面,学业预警可以帮助学生合理规划后续课程的学习;另一方面,也可以有效提升教育教学管理水平,促进和谐高校质量建设。与此同时,随着教育信息化的不断深入,各个高校都开发了相应的教学管理信息平台,存储了大量与教学相关的数据(比如上课出勤情况、去图书馆自习时间等),称为教育大数据(Education Big Data,EBD)。[1]如何找到隐藏在这些数据中的某些关联关系、挖掘出有价值的信息,从而对以后的教学活动提供有效指导,不论对学习者还是教学管理者来说都具有十分重要的意义。目前,学生以及教学管理人员,可以通过校内的信息管理平台方便地查找到每个人的课程成绩情况,然而,这仅仅属于教育数据利用的初级阶段。对隐藏在数据中的价值没有进行充分的利用,难以对学生学习以及教师的教学活动进行有效指导。例如,对学生而言,无法得到下一步课程学习的有效建议;而对教学管理者而言,也不能根据现有的成绩,对任课教师的教学方法、教学内容、教学模式给出指导性意见,没有数据的支持,無法确保建议的有效性和合理性,因此无法保证教学的效果。[2]
数据挖掘技术的发展为教育大数据的研究与应用提供了重要的工具。越来越多的研究者从不同视角、利用不同方法逐渐展开数据挖掘的研究,他们提出了许多数据挖掘方法与技术,同时也为不同领域的决策者提供了决策依据。然而,数据挖掘在教育领域尚未得到广泛应用。作为教育管理者,通过对学生历史数据的分析,一旦发现学生某门课程的成绩出现问题时,要及时对他进行提醒,并采取有效措施避免问题的发生,而不是等到问题发生后再去采取措施进行补救,这是我们教育的本质所在。由此可见,在进行基本的教学信息管理时所产生的教育大数据,不管是涉及学生还是教学管理者,重心应该是发现隐藏其中的有价值信息,为决策提供数据支持,这相比过去只靠经验并进行判断而言,无疑是一个重大创新。可见,大数据不仅是技术手段,更是一种思维方式,为教育带来深刻变革。[3]为此,本文通过整合管理学生在校成绩数据,基于关联规则算法给出大学生不及格课程之间的关联关系,以此为大学生学业提出预警(课程不及格以及留级)提示。
二、基于教育大数据挖掘的大学生学业预警研究框架
1.问题分析
学业预警是高校加强学生学习管理、提升教育教学管理水平的重要手段。国外的研究始于20世纪90年代,目的是帮助在校学生按时完成学业。美国的普渡大学(Purdue University)、宾州滑石大学(Slippery Rock University of Pennsylvania)将学生在校表现情况作为学业预警的数据来源,取得了不错的效果。相比较而言,我国的大学生学业预警研究起步较晚,早期的研究主要以制度创新来应对学生学业问题。近年来,有部分研究者依据大学第一学期的成绩以及高考成绩,预测和解释有学业风险的学习表现,从而帮助实施学业预警。[3][4]总体来看,目前的预警研究尚存在以下一些问题:①预警的方法、机制比较简单。往往以学生成绩作为预警的重要依据,对课程之间的关系考虑较少。②缺乏相应的数据支撑,预警效果一般。预警没有考虑学生成绩之外的学业表现,比如课堂出勤情况、图书馆借书情况等。③没有对学业问题进行深入分析。往往是就事论事,没有从全局的视角对学生学业进行客观评估。
基于教育信息化技术的发展,在进行数据管理的同时,也能保存大量与学业相关的信息,通过这些信息可以对学生学习进行可靠评价,为教育和管理者提供服务,帮助管理者做出科学的决策。[4][5]当前许多研究者以教育数据为基础提出了许多建设性成果,但直接将其应用在学业预警研究中,尚存在以下问题:①缺乏个性化的学业预警,只依赖于当次考试成绩进行粗放式预警的方法,无法有效地对学生学业进行指导。对每个学生而言,知识背景、学习能力、兴趣点等存在很大差异,需要有个性化的预警措施。②不论在模型上还是算法上,尚没有基于数据挖掘的预警研究,尤其是针对管理学科偏重于理论这一特点,使现有的数据挖掘工具无法直接应用,迫切需要结合学生专业特点,从多个维度挖掘分析学生学业数据,特别是那些学业成绩不良的数据,从而为高校人才培养提供决策支持。③缺乏针对管理学科学业的预警机制,一旦发现问题不知道如何及时有效地补救。科学合理的预警对于可能会出现学业或就业困难的学生而言,可以起到预警作用;而对于未来发展可能比较好的学生,学校可以提前有意识地培养。
基于上述分析,本文针对大学生教育多年来积累的大量数据信息,引入数据挖掘技术中关联规则、聚类分析、决策树等挖掘算法,对学生课程、学业计划、课程成绩等数据间的相关性和依存性进行分析,挖掘出的结果将为学生学业预警等提供有效的决策支持。
2.基于教育大数据挖掘的大学生学业预警研究框架
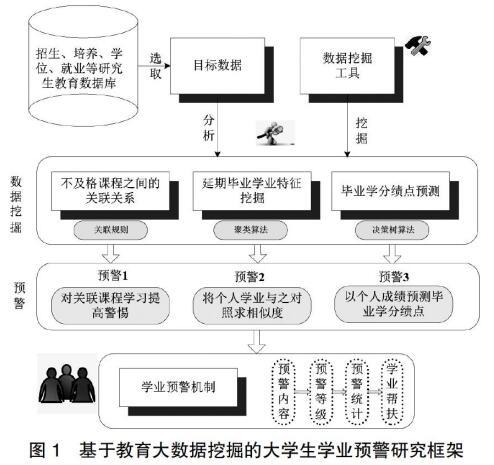
基于教育大数据挖掘的大学生学业预警研究,主要包括不及格课程之间的关联关系挖掘、延期毕业学生特征挖掘以及毕业学分绩点预测等。如图1所示。
(1)首先,提出大学生学业的综合评价考核体系的指标模型(基本属性、学习情况属性、社会活动情况属性、主观评价属性等);其次,根据不同复杂程度和目标,选取相应的数据挖掘方法,比如关联规则、决策树等;最后,提出大学生学业预警机制模型,对出现的预警及时进行处理。
(2)基于教育大数据的大学生学业预警算法设计,主要包括:①以教学运行数据为基础,利用数据挖掘中的关联规则方法,对学生教学成绩库进行挖掘作业,从而发现课程之间,尤其是先导课程与后续课程之间的成绩相关性,特别是那些一旦先行课程没有学好、势必会影响后续学习的课程,及时对学生学习提出预警。②以学生基本属性数据、社会行为数据、学业成绩等为基础,运用K-Means聚类算法进行挖掘,总结延时毕业学生的总体特征。③以已经毕业学生学业数据、课堂表现数据等为基础,利用决策树分类理论分析出学生学分绩点特征,对现有在校学生的未来毕业学分绩点进行大体上的预测,对达不到毕业学分要求的学生进行预警。高校大学生学业预警机制与援助保障体系构建主要包括预警与援助机制建设、援助工作方案、预警平台发布以及反馈保障等。[6]
(3)大学生学业预警系统设计。基于Java平台设计并实施基于数据挖掘的大学生学业预警平台设计,基本功能模块包括数据预处理、关联课程学习预警、延时毕业学生预警、毕业学分绩点预警、精准个体帮扶等。
(4)高校大学生学业预警机制与援助保障体系构建。主要包括预警与援助机制建设、援助工作方案、预警平台发布以及反馈保障等。
三、基于教育大数据挖掘的不及格课程关联规则分析
关联规则是由Agrawal等人在1993年提出的,用于发现大量数据中项集之间的重要关联或相关联系。[7][8]本节以山东财经大学管理科学与工程学院大学生挂科课程数据为挖掘对象,利用关联规则挖掘找出课程之间的隐含联系,为后续课程学习提供预警信息。
1.数据预处理
本研究主要通过对学生挂科课程进行数据分析,目的是发现它们之间存在的相互联系,以此对学生课程学习进行有效指导。主要的研究数据是从学校教务处教务管理信息系统数据库中获取学生历史成绩数据,该数据包含大量编码,需要借助于相关编码表进行解析。原始数据如表1所示。
学生历史成绩表包含字段较多,本文只选取了一些关键字段,分别是考试学年、考试学期、取得学年、取得学期、姓名、学号、课程代码、课程名称、考试成绩以及课程标志。其中的考试学年、考试学期、取得学年、取得学期反映了大学生考试的通过情况:考试学年和考试学期表示该学生第一次参加该门课程考试的学年和学期(1表示第1学期;2表示第2学期);取得学年、取得学期表示学生最后一次参加该课程考试的学年和学期。考试成绩分为百分制和五级制两种方式。课程标志包括正常、重修、补考、缓考和缺考等。
在数据预处理阶段,主要包括数据清理、数据整合、数据转换、数据规约以及数据离散化和概念分层等几个部分。在数据清理阶段,主要是将异常数据和重复数据清除,以解决孤立点和数据不一致等情况带来的问题。对一些由于退学、休学等原因造成学生数据缺失等情况,采用了人工填补、平均值和牛顿差值等方法进行数据补充,保证数据完整性。
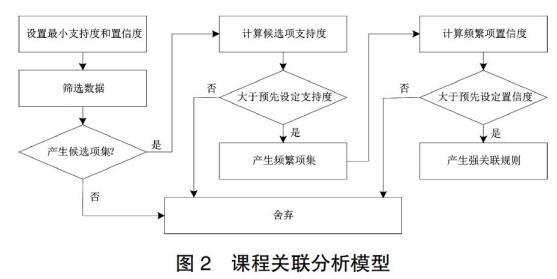
2.挂科课程关联挖掘框架设计
图2给出了基于FP-Growth算法的大学生课程关联规则挖掘模型。算法的基本过程主要包括频繁模式挖掘以及关联规则发现。在频繁模式挖掘阶段,将每一门不及格课程作为一个项,所有学生的不及格课程构成项集;将每个学生的不及格课程作为一个事务,利用关联规则的两个测度,度量最小支持度和最小置信度,对得到的频繁项集和关联规则进行筛选。在这个过程中,链接和剪枝是两个重要的操作。
3.挖掘结果与分析
通过FP-Growth算法得到频繁项集如表2所示。以第一行为例,Key=C06310002表示该课程号的频繁项集,([C06310081],13)表示C06310081共出现了13次,([C06330085,C06340068],7)则表示C06330085和C06340068一共出现了7次。
快速发现感兴趣的关联规则还是比较困难的;同时,大量的频繁项集中必然夹杂很大比例的无效关联规则和弱关联规则,需要对挖掘到的频繁项集进一步处理。合并所有键值相同的对,去掉大部分无效关联规则和弱关联规则;同时,在保留有限关联规则前提下,将支持度设为0.12,置信度设为0.6,对挖掘到的频繁模式进行处理,共筛选出120条规则,部分如表3所示。
由以上规则可以看出哪些课程不及格,容易导致其他相关课程也出现不及格的情况,比如[数据结构]→[运筹学],支持度表示数据结构和运筹学均出现不及格的情况占总体不及格课程的16.1%,置信度表示数据结构出现不及格情况的学生中80%的学生运筹学课程也出现了不及格情况。究其原因,一方面可能是学生的学习态度不端正,放松了对专业知识的学习,这就需要专业教师加强学生基础知识的教学,辅导员及时督促学生掌握理论基础知识;另一方面可能数据结构作为先导课程有一定难度,学校可尝试适当调整培养方案,巩固基础知识,加深学生对专业知识的理解。[9-11]
参考文献:
[1]顾云锋,吴钟鸣,管兆昶等.基于教育大数据的学习分析研究综述[J].中国教育信息化,2018(7):5-10.
[2]周庆,肖逸枫.基于数据挖掘技术的高校学生学业预警分析[J].中国教育技术装备, 2018(6):42-45.
[3]Delen D. A comparative analysis of machine learning techniques for student retention management[J].Decision Support Systems,2010,49(4):498-506.
[4]Hu Y H, Lo C L, Shih S P. Developing early warning systems to predict students online learning performance[J].Computers in Human Behavior,2014(36):469-478.
[5]蘇兆兆,栾静.高校本科生就餐数据挖掘分析[J].电脑知识与技术,2018(5):24-26.
[6]边高峰.基于数据挖掘的普通高校受资助学生精准识别研究及对策[J].科教导刊(下旬),2018(5):183-184.
[7]赵峰,刘博妍.基于改进Apriori算法的大学生成绩关联分析[J].齐齐哈尔大学学报(自然科学版),2018(1):11-15.
[8]陈喜华,黄海宁,黄沛杰.基于Apriori算法的学生成绩分析在课程关联性的应用研究[J].北京城市学院学报,2018(4):66-71.
[9]傅亚莉.基于Apriori算法的高职院校课程相关性分析[J].长春工程学院学报(自然科学版),2013(4):108-111.
[10]方毅,张春元.基于数据挖掘的多策略研究生教育课程成绩分析方法研究[J].计算机工程与科学,2009(6):106-108.
[11]袁路妍,李锋.改进的关联规则Apriori算法在课程成绩分析中的应用[J].中国教育信息化,2017(17).
(编辑:王天鹏)
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
