
基于混沌粒子群优化核极限学习机的变压器故障诊断方法
2020-05-11 09:02李成强许冠芝
微处理机 2020年2期
李成强,许冠芝
(西安工程大学电子信息学院,西安710600)
1 引 言
电力变压器中的任何故障都可能导致电源意外中断,同时带来巨大损失。变压器早期故障的发现,将降低非计划停电的成本,提高电力系统的可靠性和运行水平。因此,对其进行故障诊断具有重大意义[1]。电晕、电弧以及过热是变压器早期故障的主要原因。这些故障导致变压器绝缘油分解,形成不同浓度的气体,有一些技术曾被用于检测故障气体,但DGA(Dissolved Gas Analysis, 油中溶解气体分析法)是国内外公认的有效方式[2-3]。DGA 是根据气体的浓度来判断变压器故障的分析方法,特别是针对变压器内部的潜伏性故障,DGA 能够及时发现并得知故障发展的程度[4]。传统的针对变压器故障诊断的方法大多是根据导则[5],通过结合特征气体分析法[6]以及比值法[7]分析变压器内的绝缘材料和外部环境等作用下发生老化过程中所产生的特征气体(H2、CH4、C2H6、C2H4、C2H2)的体积分数或比值,进行变压器故障的诊断和分析。在实际诊断过程中当变压器发生一个或多个故障时,气体浓度存在差异且各种气体之间的关系变得过于复杂,与预先定义的值不匹配。随着神经网络[8]、遗传算法[9]以及模糊理论[10]等理论的提出和发展,人工智能[11]被应用到变压器故障诊断中。人工神经网络(ANN)[12]、支持向量机(SVM)[13]等是用于溶解气体分析的常见方法;在实际运用中取得了一定的效果,但也有不足处。如ANN 方法用于变压器故障诊断时有训练速度慢、易陷入局部最优并且在结构复杂和大样本时,极易出现过度学习或泛化能力低的缺陷。因冗余信息的影响使得SVM 在处理较大数据量训练时间过长、速度变慢,不适合大样本,其参数选取很困难[14]也降低了实用性;并且SVM 的诊断输出为硬分割边界。粒子群优化算法具有简单通用、容易实现的特点,并且几乎不涉及其调整参数,适合求解优化问题,但是对于离散化的优化问题处理不佳,容易陷入局部最优,并且在其进化后期会出现收敛速度慢等,进而发生早熟收敛。基于模糊神经的专家系统因算法本身的局限性,将其应用到变压器故障诊断中不能准确反应问题。
鉴于混沌运动具有规律性、随机性、遍历性等特点,能够用于解决算法收敛速度慢以及陷入局部极值的问题,针对上述问题,在此提出一种基于混沌粒子群优化核极限学习机的变压器故障诊断方法,引入CPSO(Chaotic Particle Swarm Optimization,混沌粒子群优化)对KELM(Kernel Extreme Learning Machine,核极限学习机)参数进行优化,将特征气体参数输入到优化后的核极限学习机分类模型中实现诊断。在弥补单一算法不足的同时提高变压器故障的分类能力以及诊断准确率。
2 KELM 介绍
ELM 算法是一种单隐藏层前馈型神经网络,模型可表示为:
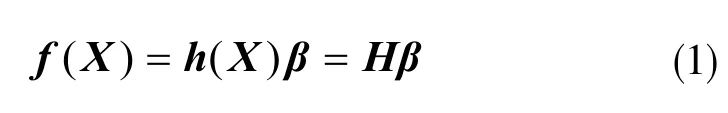
其中X 为输入;f(X)为类别向量输出结果;h(X)及H为隐藏层特征映射的矩阵;β 为输出链接的权重。计算如下式:
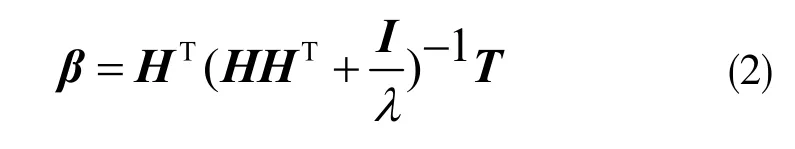
其中,T 为训练样本类向量组矩阵,λ 表示正则化系数。
KELM 是新型的单隐藏层前馈型神经网络算法。对于N 个训练样本ℑ= {(Xi,ti)|Xi∈Rd,t i∈Rm,i=1,...,N}(其中Xi为输入,ti为输出),核函数KELM 的模型可表示为:
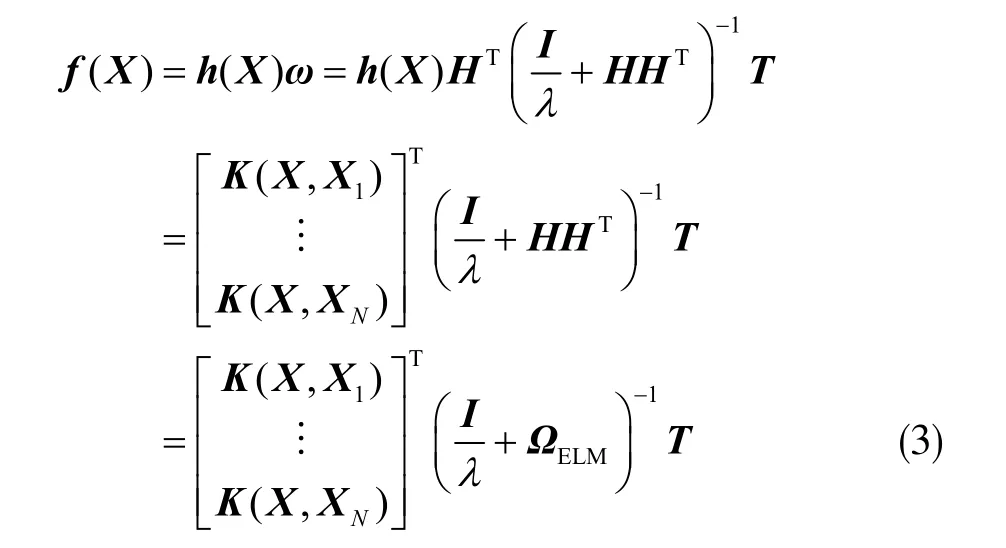
式中,f(X)表示KELM 分类结果输出;h(X)及H 为隐含层特征映射的矩阵;ω 为输出层间和隐含层的连接权值;h(X)·h(XN)=K(X,XN)为核函数;ΩKELM=HHT为核矩阵;I 为单位对角矩阵;为正则化系数;T 为期望输出的矩阵。
径向基函数(RBF)中只需确定一个参数(s)的特点对优化更有利,所以使用RBF 作为核函数,即:
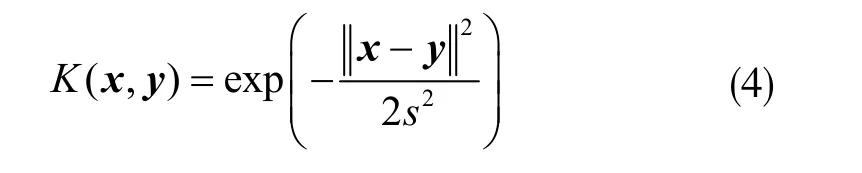
由于λ 和s 需要事先设定,因此KELM 分类器性能受其影响。
3 CPSO 优化KELM
3.1 CPSO 原理
实践证明,KELM 的分类准确率受正则化系数以及核函数参数s 设置的影响,且分类的准确率极易陷入局部最小值。因此,此处对KELM 的参数通过改进粒子群优化算法进行优化,以得到最优网络结构模型。
粒子群优化算法(PSO)建立在模拟鸟群社会的基础上,源于对鸟群捕食行为的研究[15]。粒子在搜索范围内飞行的过程中会不断地通过自己以及相邻粒子的所历经验来改变自己的位置,并在所有的位置里找出最佳值。
若粒子群由群体规模为M 的随机粒子构成,D为群体的维数,令第i 个粒子所处的位置是xi=(xi1,xi2,…,xiN)。优化问题的随机解之一就是该粒子所处的位置,再由迭代求出最优解。粒子通过跟踪该粒子的局部最优位置pbest和所有粒子的最优位置gbest,两个极值来更新自己的位置,得到两个最优值之后,由如下二式来更新粒子的速度和位置:

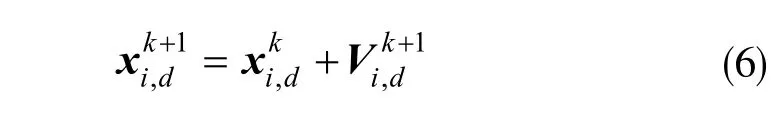
式中,k 为当前代数;i=1,2,…,M;d=1,2,…,D;是粒子的速度;pbesti,d表示粒子群的局部最优位置;gbesti,d表示粒子群的全局最优位置,r1、r2是(0,1)中的一个随机数;表示粒子当前所处的位置。
为改善收敛性,引入惯性权重因子ω 后的粒子群速度,更新公式为:
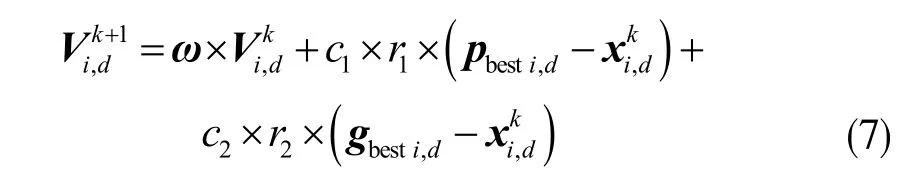
PSO 对于离散化的优化问题处理不佳,容易陷入局部最优,进化后期收敛的速度和精度都会下降,混沌搜索的引入解决了这一问题。在给定范围内混沌搜索可以按照其自身规律在每个状态只遍历一次的情况下达到所有状态。能够避免陷入局部最优的情况。因此将混沌搜索应用于神经网络的训练中,能提高收敛速度和收敛性,具有快速和全局收敛性能。同其他随机算法相比混沌搜索有更高的收敛精度[16]。
此处采用经典的帐篷(Tent)方程构成混沌序列,其数学表达式为:
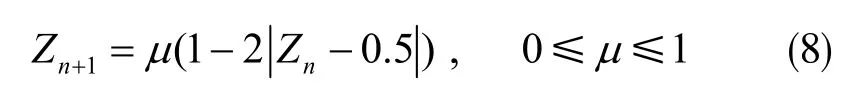
式中,0≤Zn+1≤1;μ 为控制参量,在μ=1 时,Tent 映射在[0,1]上呈现各状态历变以及完全混沌动力学特性。
若粒子群出现停滞陷入局部最优,容易导致PSO 算法早熟。利用灾变摆混合粒子群进化停顿,可加快其进化的速度。对于第n 代群体,令fm(n)为其最优适应度,fa(n)为其平均适应度,载气满足下式时,算法会出现停顿[17]:

式中,fa(n-n1)表示近期n1代平均进化速率(n >n1)。保留全局搜索的最优粒子,并对其附近的粒子给以混沌扰动[18],使粒子摆脱局部最优,提升算法的全局搜索能力。令混沌的扰动范围为[-β,β],并将各分量映射到该范围,扰动量Δx=(Δx1,Δx2,…,ΔxD),则:
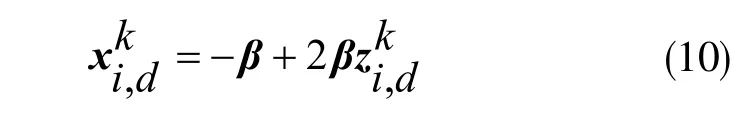
此时扰动前、后粒子的位置分别由如下二式所示:

通过计算比较这两个位置的适应值来确定是否跟新粒子的位置。混沌粒子群算法能够避免算法后期的震荡,提高了收敛性。混沌粒子群算法的具体思想归纳如下:
一、惯性权重ω
为了平衡算法的局部和全局的搜索能力,既保证其快速收敛又避免陷入局部最优,引入惯性权重,此ω 的值越大越有助于全局寻优,反之有助于局部寻优,即:

式中,ωmin、ωmax的取值范围为[0.4,0.9]。
二、加速常数c
要使算法的收敛速度得到保证,加速常数调整更新为:
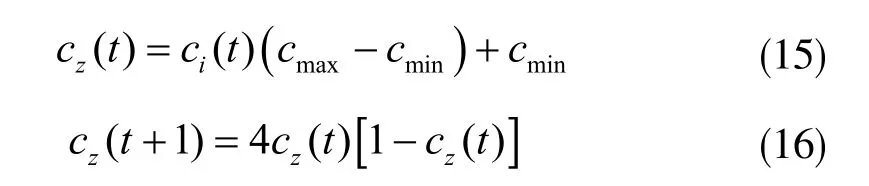
式中,z=1,2;cmin、cmax的取值范围为[1.5,2]。
三、随机数
处理随机数以保证效率,如下式所示:
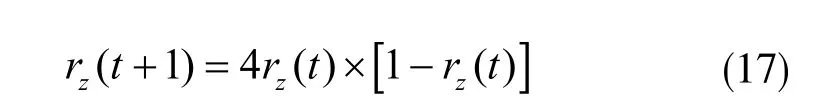
式中rz的取值范围为[0,1],z=1,2。
四、早熟处理
针对粒子群算法后期收敛速度较慢、容易陷入局部极值点从而出现早熟的问题,粒子群的适应度与于粒子的位置息息相关,通过粒子群的方差δ2来判断是否早熟,即:
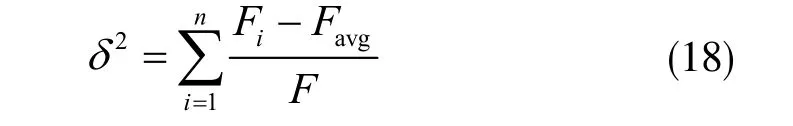
式中,Fi表示粒子的适应度;Favg表示粒子的平均适应度。
当δ2小于给定值时粒子已经进入早熟,为跳出局部最优,此时需要重新设定粒子速度和位置。图1为CPSO 与PSO 参数寻优过程中适应度值收敛曲线,从图中收敛曲线可见,与PSO 相比使用CPSO 可获得精度较高的解。

图1 适应度值收敛曲线图
3.2 基于CPSO 的KELM 参数优化
对正则化系数λ 和核函数参s 数的优化及KELM 最优参数,就是选择适当的正则化系数和核,通过矩阵运算得到最大的分类准确率。记Acc(λ,s)为KELM 的分类准确率,其最大值记为:maxAcc(λ,s),其中λ∈[0,a] , s∈[0,b]。
此处采用5 折交叉验证法(5-CV)生成随机的训练集、验证集以及测试集。在避免使用Holdout 验证泛化性能差的缺点的同时使有限的DGA 数据得以充分利用。记去掉第i 折后的分类模型为f-k(i)(xi);第i 折上分类模型验证的准确率为d[yi,f-k(i)(xi)],分类准确率平均值就是交叉验证准确率,即:
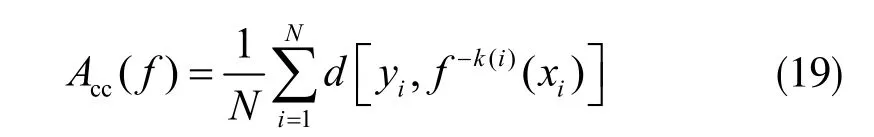
基于5-CV 和CPSO 算法结合的KELM 核函数参数优化过程归纳如下:
1)种群初始化,生成粒子群,给各粒子在搜索空间内赋予随机的位置和速度;
2)用5-CV 方法评估KELM 分类器参数;
3)是否到达终止条件4);
4)更新粒子的位置和速度并回到2);
5)根据最优参数得到最优模型。
通过CPSO 对KELM 的核函数的优化,得到优化后的KELM 分类器。
4 基于CPSO-KELM的变压器故障诊断
基于KELM 的变压器故障诊断模型,是把测试数据输入到先前所建立的变压器各故障和与之相应的状态映射模型中进行分类处理。
给定训练集,通过结合混沌粒子群算法对核函数参数进行优化,并达到模型的最优分类性能。
4.1 特征量选取
通过不同特征气体含量来反映变压器的运行状态,已得到大量理论研究和实践的证明。在油浸式电力变压器运行过程中所产生的气体对其故障诊断极具意义的有H2、CH4、C2H6、C2H4和C2H2。此处以国际电工委员会(IEC)推荐的DGA 数据中的H2、CH4、C2H6、C2H4和C2H2的溶解量作为特征量。DGA 数据分布区间大,并且数据之间有较大差异性,为降低其相互间由于量值差异造成的影响,减少计算的误差,提高诊断的精度,在将特征量输入分类器前首先要对特征气体数据进行归一化处理。令xnew为进行归一化处理之后的气体体积分数;xmin为其对应的最小值;xmax为其对应的最大值,有:
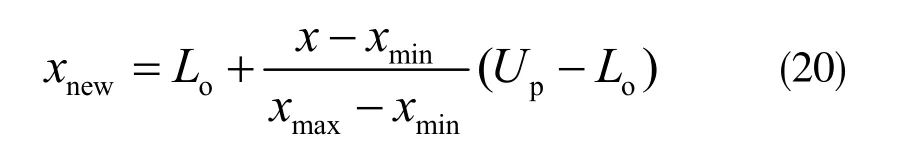
式中,Up、Lo为常数,表示气体体积分数归一化的上下限,且Up∈[-1,1] , Lo∈[-1,1]。
4.2 变压器状态编码
KELM 算法的多分类能力正好用来解决变压器故障诊断这一多分类问题,因此可以用一个分类器来辨识变压器的低能放电、高能放电、中低温过热、高温过热以及正常5 种状态。各状态编码如表1。

表1 变压器状态编码
4.3 仿真验证
此处采用5-CV 和CPSO 结合对KELM 分类器的参数进行优化,设置粒子群的大小为30,进化的迭代数为50,惯性权重为0.4,加速因子c1、c2都为常数2,其适应度函数为式(19),具体流程如3.2 节所述。
基于CPSO-KELM 算法的压器油中溶解气体预测具体实现过程如下:
①对于样本数据按4:1 分为训练集和测试集;
②选取样本数据并按公式(20)做归一化处理;
③结合粒子的位置以及参数(λ,s),训练组数据对应用了CPSO、5-CV 结合方法的KELM 进行训练;
④训练结束,归一化处理测试集数据;
⑤由公式(1)得到X 所对应的输出向量o(X)={on},n=1,2,…,5;
⑥由下式求得o(X)的编码向量T={tn},n=1,2,…,5:
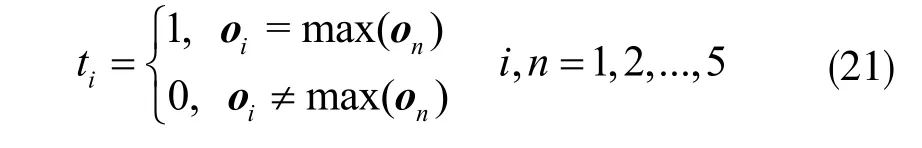
⑦对照表1 变压器状态编码获得最终分类结果。
5 实例分析
为避免样本数据选取时数据集不均衡的问题,应使各类样本数量相近。原始数据中的故障样本全部采用。选取与DT/L 722-2014《变压器油中溶解气体分析和判断导则》中所给出的气体注意值相近的样本作为正常类数据。从公开发表的刊物、资料所确定的变压器故障的DGA 样本数据中选取样本训练集与样本测试集共150 组[19-23]样本数据分别为低能放电、高能放电、中低温过热、高温过热以及正常共五组,各样本数量如表2 所示。

表2 各故障选取的样本数
样本数据中每一折数量为30,120 组训练样本集用于每次的交叉验证,30 组样本用于验证。表3为PSO-KELM 与CPSO-KELM 的诊断结果对比(对训练集进行5 折交叉验证),与CPSO-KELM 相比文中所提出的CPSO-KELM 方法训练、测试时间短且更精度高。

表3 两种方法的结果对比
为验证CPSO 优化KELM 故障诊断方法的分类性能,将同样的故障样本数据分别用CPSO-KELM、ELM 和SVM 三种不同方法进行对比试验,对于ELM 采用默认的Sigmoid 函数,隐藏层结点数为100,通过十次实验。结果列于表4,其中每一个结果均为10 次实验的平均值,对比曲线如图2 所示。
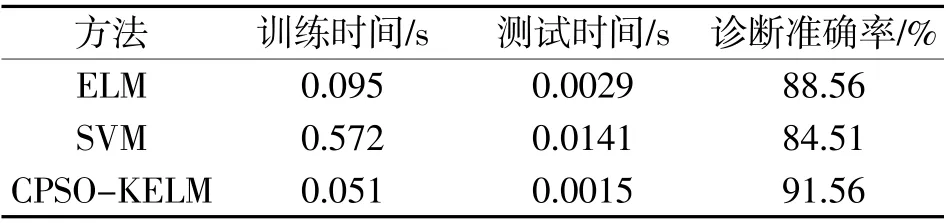
表4 三种诊断方法性能对比
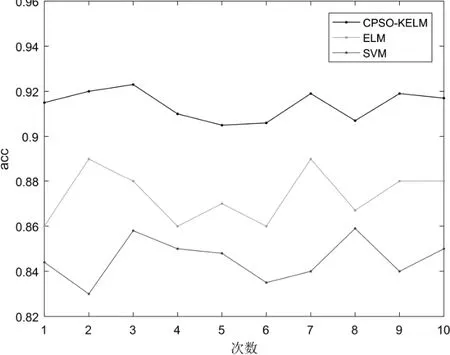
图2 三种诊断方法性能对比
可以看出,同其他两种方法相比,基于CPSOKELM 的变压器故障诊断方法需要的训练时间和测试时间更短,同时还兼有更高的准确率。从图2 中可以看出,CPSO-KELM 的性能与ELM、SVM 相比也更稳定。
6 结 束 语
将混沌理论、PSO 与核极限学习机相结合,以CPSO 优化KELM,可有效应用到变压器故障诊断当中。混沌理论与PSO 进行混合,提高了PSO 的局部能力。将混合后的CPSO 用于对KELM 参数进行寻优的神经网络训练中,可使KELM 的网络结构最优,以此提高了诊断的可靠性。结合实际数据,SVM、ELM 与所提新方法在诊断结果上的不同表现得到直观的对比。实验结果表明, 所提出的CPSO 优化KELM 的故障诊断方法具有更好的学习能力和更高的诊断精度。
猜你喜欢
汽车实用技术(2022年16期)2022-08-31
昆明医科大学学报(2022年1期)2022-02-28
一重技术(2021年5期)2022-01-18
中华书画家(2021年12期)2022-01-06
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
散文诗(2020年1期)2020-07-20
电子制作(2018年10期)2018-08-04
东方艺术·国画(2016年3期)2017-02-08
发明与创新(2016年38期)2016-08-22
