
基于特征融合卷积神经网络的SAR 图像目标检测方法*
2020-05-11 09:02:16刘志宏李玉峰
微处理机 2020年2期
刘志宏,李玉峰
(1.吉林航空维修有限责任公司吉航民机公司,吉林132102;2.沈阳航空航天大学电子信息工程学院,沈阳110136)
1 引 言
合成孔径雷达(Synthetic Aperture Radar, SAR)具有全天时、全天候及一定穿透能力的特点,随着SAR 技术的快速发展,其在侦查,遥感等军事和民用领域应用越来越广泛,对SAR 图像处理技术也提出了更高的要求,如何快速准确地检测出SAR 图像目标,成为SAR 图像目标检测领域需要研究的重要问题。
在传统的SAR 图像目标检测方法中,需要恒虚警率(Constant False Alarm Rate, CFAR)检测算法[1-3]应用广泛,绝大多数CFAR 算法基于局部滑动窗口对SAR 图像进行逐像素检测,判断是否超过某个门限,需要目标和背景有一定的对比度,且背景杂波有一定的统计特性,然而复杂大场景下,背景杂波较多,其统计特性难以获得,检测效果也较差。
卷积神经网络(Convolutional Neural Networks,CNN)是深度学习中的一种人工神经网络,近些年发展迅速,并引起广泛重视。其输入可以是原始图像,通过多层信息处理进行特征学习,具有极强的适应性,同时它的权值共享结构大大减少了网络权值数目,降低了计算复杂程度。
CNN 具有强大的特征提取能力,Krizhevsky[4]提出深度卷积神经网络的图像分类算法,在ILSVR C2010 比赛中取得了很好的成绩,大幅提高了图像分类的准确性,同时也提升了目标检测的准确率。在图像目标检测的问题中,Girshick[5]等人提出了RCNN 方法,采用选择性搜索策略(Selective Search,SS)选择候选区域,用CNN 对候选区域提取特征,通过SVM(Support Vector Machine, SVM)分类器对目标类别识别,并对候选区域进行边框回归,提高检测效率。He Kaiming 等人[6]提出一种SPP-net 可以生成固定长度的表示,解决了CNN 输入需固定尺寸的问题,改善了基于CNN 的图像检测方法。Girshick 等人[7]再次改进提出了Fast-RCNN 的方法,将整张图片通过CNN 之后再生成候选区域特征图,使得检测效率大幅提高,Ren Shaoqing 等人[8]再一次提出改进生成候选区域的Faster-RCNN 方法,使得检测效率又进一步提高。
CNN 应用于多种不同类型图像[9-12]都有优秀的特征提取性能,但大都基于深层卷积网络模型[13-14]。基于此,在此利用层数较少的CNN 对SAR 目标进行检测,并且在Faster-RCNN 算法的基本思想上,设计多层次卷积特征融合网络,补充复杂大场景下的SAR 目标样本,增强了传统Faster-RCNN 对于小目标检测能力。
2 特征提取网络
2.1 基础卷积特征提取网络的设计

图1 CNN 特征提取网络
不同于ImageNet,PASCAL VOC 等大样本数据集,SAR 图像数据集较小,根据实际需求与数据特点,此处采用较少层数的特征提取卷积神经网络模型,具体结构如图1 所示。该模型包括输入层、5 个卷积层、4 个池化层、输出层,在输入数据层对输入的数据进行归一化处理后,第一个卷积层放弃了多数网络在第一个卷积层使用的大卷积核,采取5×5大小的卷积核,具有更小的感受野(receptive field),其余卷积层用3×3 大小的卷积核,卷积核个数分别为64、128、256、512、512,所有的卷积核滑动步长皆为1,前4 个卷积层后每个都接一个最大池化层(max pooling)局部感受区域为2×2,步长为2,在最后一个卷积层后连接两个全连接层。每个卷积层以及第一个全连接层后都使用线性修正单元(Rectified Linear Unit, ReLU)[15]函数作为激活函数,在实验中可有效解决饱和问题。分类层用于验证设计的CNN 模型特征提取效果,当分类结果达到一定精度时,提取到的特征图才可用于后续网络。
2.2 特征融合网络设计与数据完善
传统的Faster-RCNN 只选择了最后一个卷积层的特征图,忽略了其他低层次的卷积特征图,损失了一部分目标信息。而深层的卷积特征对于图像语义特征有更抽象的表达,利于对目标分类,不利于目标定位;低层的卷积特征考虑目标局部细节纹理等,有利于定位。此处选取检测SAR 目标较小,需要在复杂场景下检测出目标。设计一种多层次卷积特征融合网络,如图2 所示,因考虑到不同层次的特征,具有更好的特征表达。
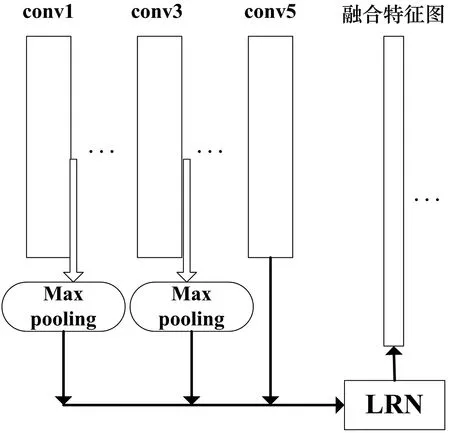
图2 多层特征融合网络
在选取第一个卷积层和第三个卷积层的特征图后,存在不同层次的特征图尺寸不一致的问题,因此对其进行最大池化层操作,得到和第五个卷积层特征图一样的尺寸。进行多层次特征融合后,不同层次的特征图的特征分辨率(feature resolution)不同,需要进行局部响应归一化(Local Response Normalization, LRN)操作。后续实验想要在复杂大场景下,如包含较多树木,草丛,麦田,建筑等较多的干扰信息检测出多种姿态的SAR 目标车辆,若要完成此任务,数据集一定要包含多种信息,且对于数量质量要求较高,因此将大场景下包含较多干扰背景的目标图像数据扩充到原来用于验证网络特征提取效果的数据集,加强网络在面对复杂大场景下对于目标的检测能力,同时采取数据增强(data augmentation)方法,对复杂背景下的目标图像进行平移,旋转等处理扩充样本。
3 目标检测网络
目标检测部分采用区域建议网络[8](Region Proposal Networks, RPN)的思想从输入的多层次融合特征图中得到目标所在位置的候选区域,之后用Fast-RCNN 中目标检测部分的网络对建议区域进分类和边框回归,检测出目标,并得到更加真实的目标区域,其中两个网络共享CNN 卷积层特征。
3.1 目标候选区域的生成
RPN 是用来直接得到所包含目标的候选区域,具体结构模型如图3 所示。其输入是图片经过2.2节多层次特征融合后的特征图,经过一个滑动窗口小网络,小网络以n×n 大小的窗口在输入的特征图上滑动,此步骤是以卷积核大小为n×n(此处选取n=3)的卷积层实现的,并映射为一个更低纬度维度特征向量,之后将此特征向量输入到两个同级的卷积层,卷积核尺寸为1×1,分别用于cls 和reg(分类和边框回归)实现对原始的目标建议区域精修。
利用RPN 生成区域建议相较于传统的selective search[5]寻找目标区域大大缩短了时间,提高了效率。在每个小滑动窗口的中心,我们通过设定3 个尺度(scales)和3 个纵横比(aspect ratios)生成9 个原始的区域,称之为anchor,鉴于此处需要检测的SAR 目标较小,舍弃原本的128/256/512 这三种尺度,将尺度重设为64/128/256,纵横比依旧为1:1/1:2/2:1。通过设定参考区域与目标真实区域的重叠部分(Intersection over Union, IOU),大于0.7 称为正标签,小于0.3 称为负标签,1:1 选取正负标签,共256 个anchor 作为一个mini-batch 拿去训练。
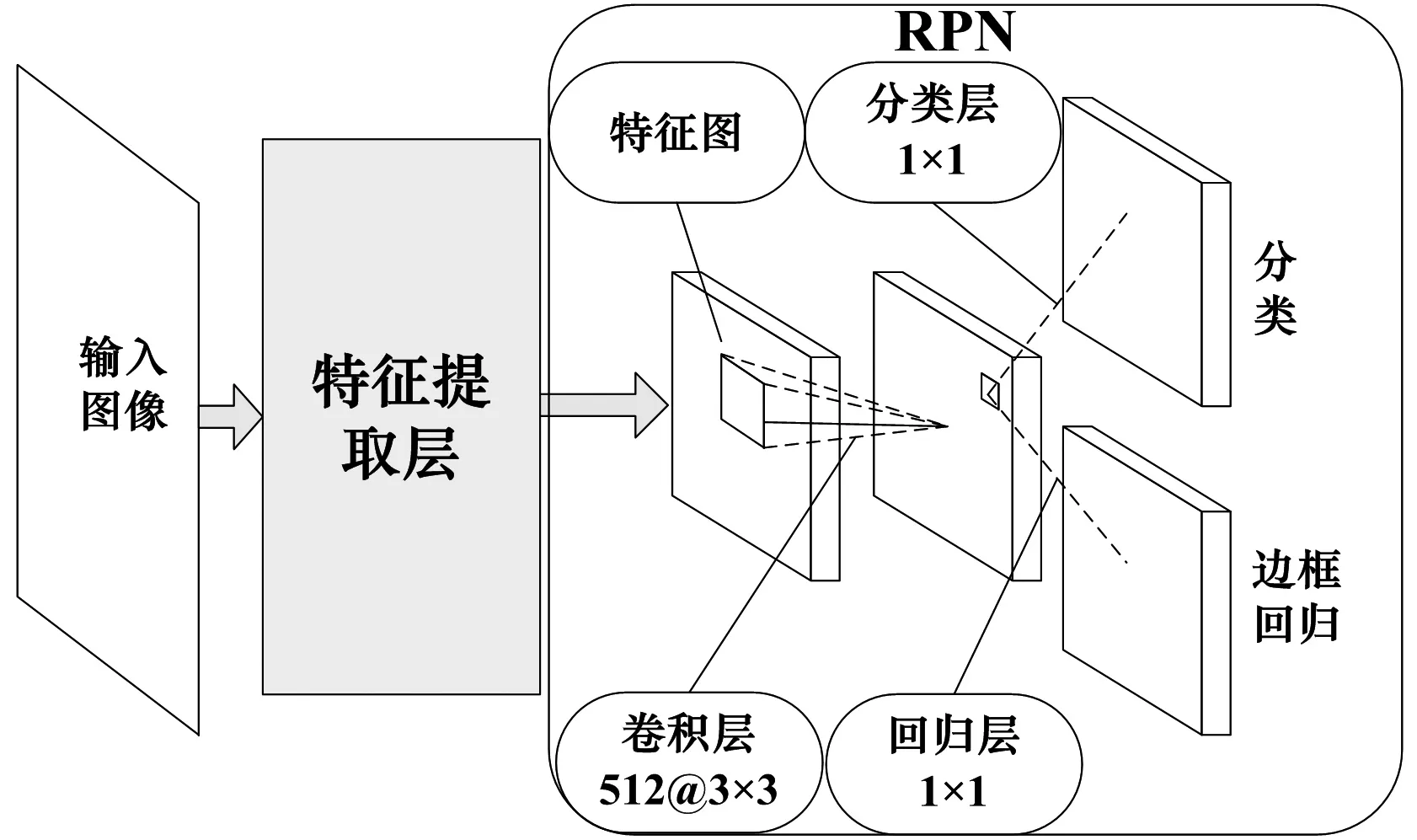
图3 候选区域生成网络
选择多任务(multi-task)损失函数如下式,进行RPN 网络的超参数优化:
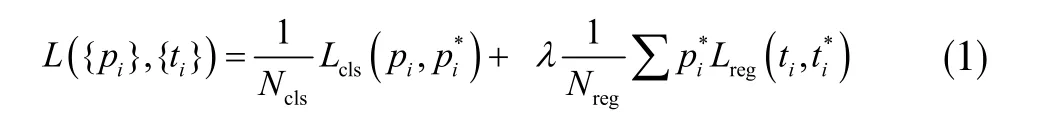
其中i 是一个mini-batch 中的目标参考区域的索引;Ncls表示其中包含的样本数,即mini-batch 的大小;Nreg表示输入网络的所有参考区域anchor 的数目;λ 则是平衡系数,用来控制两个损失函数权重;Lcls为分类损失函数,用于判断区域是否有目标,在实验中使用优化后的交叉熵损失函数,即:
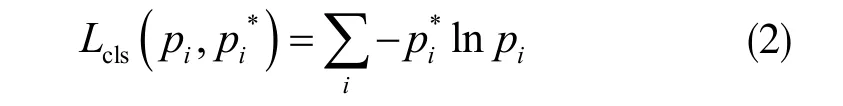
它适用于每个类别相互独立且排斥的情况;pi表示经过softmax 之后第i 个anchor 预测为目标区域的概率;pi*为参考目标区域的真实标签;Lreg为边框损失函数,即:
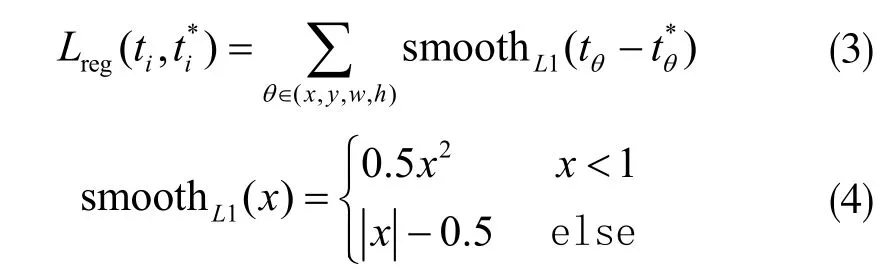
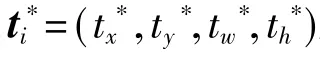
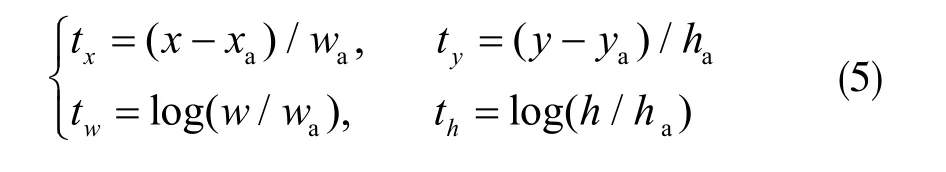
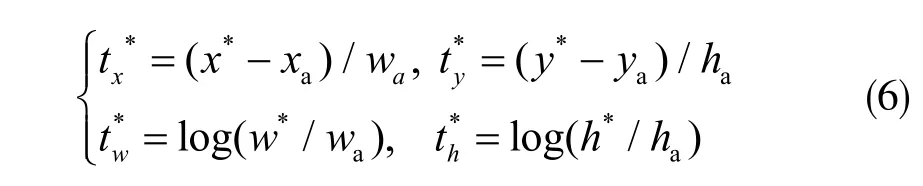
式中,x、y 表示预测区域中心点的横纵坐标,w、h 则表示宽和高,xa表示初始参考的anchor 的横坐标, x*表示真实横坐标。纵坐标、宽、高与此定义方式相同。
RPN 网络生成的建议区域存在大量重叠,对此采取非极大值抑制(Non-Maximum Suppression,NMS),筛除掉部分区域,并选取通过分类层后判断为目标区域概率最高的前N 个作为最终建议区域输出。
3.2 目标检测网络的说明
目标检测网络具体如图4 所示。经过RPN 网络生成的候选目标区域,再通过提前设置好的feat_stride 参数映射回2.1 节网络生成的卷积特征图feature map。由于anchor 的多尺度特性,得到的建议区域特征图(proposal feature maps)尺寸是不固定的,需经过ROI pooling 层实现固定尺寸输入。之后经过全连接层,映射为特征向量,此处采用高维特征向量。得到的特征向量用于之后两个并列的平级分类层(n+1 类目标)和边框回归层,前者用于目标分类,得到建议区域目标分类结果的离散概率P,分类结果相互独立排斥。后者得到目标区域四个参数化坐标,同(5)式,用于目标定位。
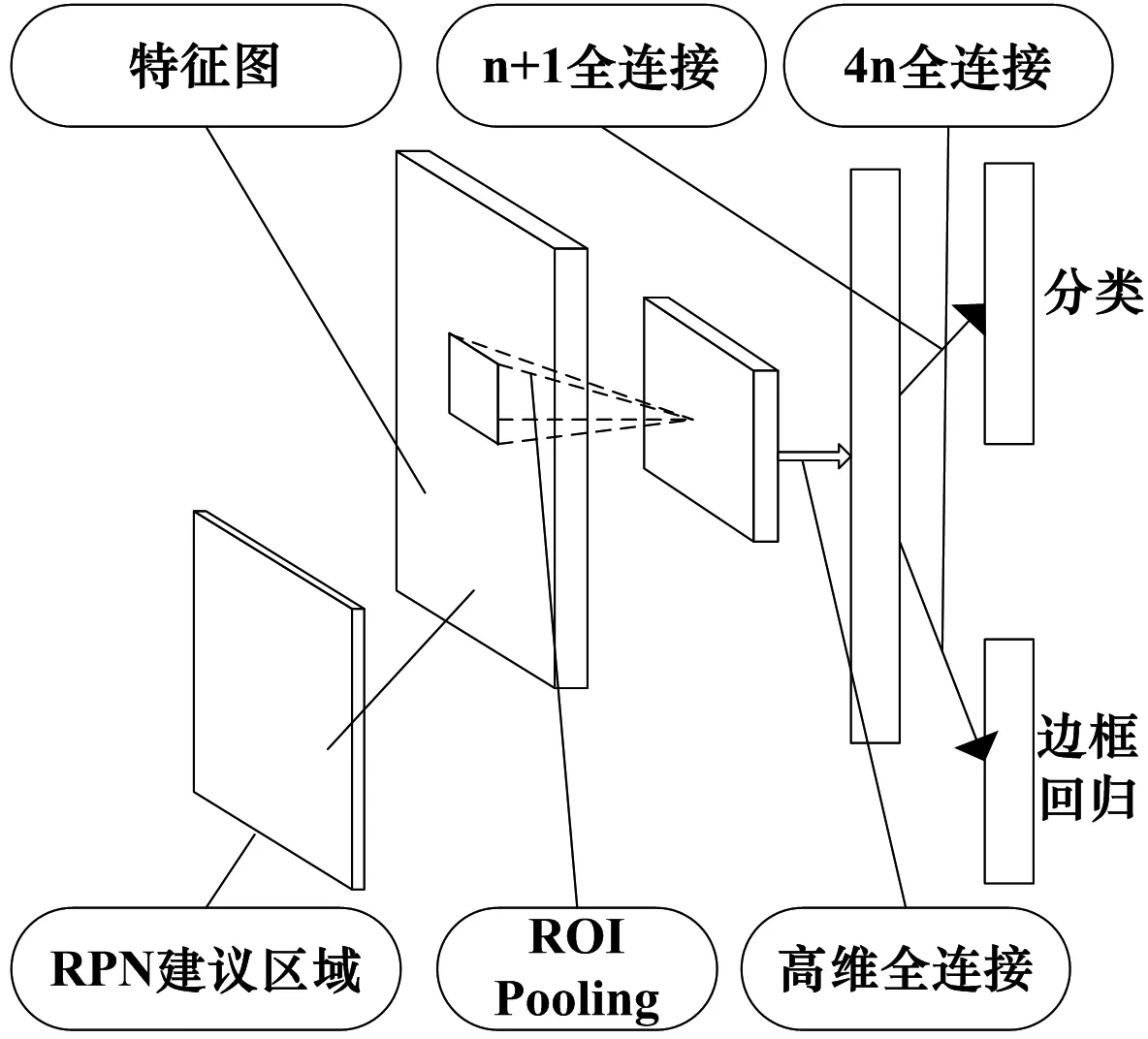
图4 目标检测网络
4 实验及结果分析
4.1 数据准备与说明
为验证本方法有效性,实验使用运动和静止目标获取与识别(Moving and Stationary Target Acquisitionand Recognition, MSTAR)数据集中的128×128大小的静止目标切片图像,包含有7 个小类,3 个大类的不同方位角下的车辆目标图像。MSTAR 同样包含有部分大小为1748×1478 的复杂大场景图像,包括麦田、草地、树木、胡泊、建筑物等,但这些图像不包含目标,因此,嵌入许多大小为128×128 的目标图像到整个场景图像中[10],这种操作是合理的,因为目标图像和场景图像都由同一的SAR 传感器获取,分辨率统一为0.3M。用此方法构建出本实验,需要m_MSTAR 数据集,并与MSTAR 数据集合并构成所用的完整数据集。经过数据增强技术后,m_MSTAR和MSTAR 数据集比例达到1:1.5,共800 张数据集图像。图5 分别给出这两个数据集的样本示例。

图5 样本数据实例
4.2 多任务网络的训练
实验时,使用近似联合训练多任务网络、共享融合后的卷积特征图、RPN 网络和Fast-RCNN 目标检测网络合并到一个训练网络,因为忽略了反向传播过程中ROI pooling 层关于区域坐标建议的导数,导致此部分权重无法更新,所以称为近似联合训练,这种方式可以节约时间成本,提高效率。
在对近似联合训练网络训练时,初始学习率设定为0.01,等损失值变化较小时再更新学习率,将学习率除以10。对于网络损失函数优化,选用带有动量(momentum)的随机梯度下降算法,在训练网络时按照高斯分布进行初始化,并不能保证使得网络的初始权值处在一个合适的状态,有可能在训练过程中陷入局部最小值,无法达到全局最优。对于高维非凸函数来,还可能出现很多鞍点,在引入动量后可以使SGD 逃离局部鞍点震荡或者不陷入局部最小值,同时起到一定的加速作用。加入动量后的SGD 权值更新为:
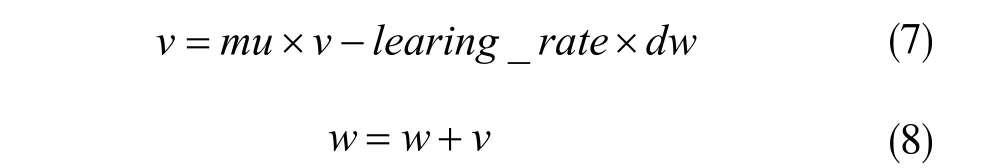
4.3 实验效果分析
4.3.1 特征提取效果分析
CNN 对于目标特征提取效果的好坏将直接影响后续网络模型的最终检测效果。为验证本设计的基础CNN 对于SAR 图像目标特征提取的有效性,单独训练此部分网络,并将训练好的网络模型结构用来分类识别,此结果能够很大程度上验证设计的网络对目标特征提取的效果。
此步骤中,训练数据样本采用的是17°俯仰角下大小为128×128 的BMP2_SN9566、BTR70_C71、T72_SN132、T72_SN812、T72_SNS7 车辆SAR 图像数据;用于测试分类效果的数据为15°俯仰角下的BMP2_SN9566、BMP2_SN9563、BMP2_C71、BTR70_C71、T72_SN132、T72_SN812、T72_SNS7。最终结果分为BMP2、BTR70、T72 三个大类。
在原图像中,目标在图像向中央位置,为了加快网络计算速度,将原图像从中心裁剪成64×64 大小,减少输入维数。模型训练足够多次迭代,调节学习率直到loss 值不再明显变化,收敛于一个较窄的范围。这一基础CNN 特征提取网络训练模型中一个输入图像以及其每层卷积特征响应图如图6 所示,对于测试数据具体分类结果如表1 所示。

图6 输入图像、Conv1-conv5 特征响应图
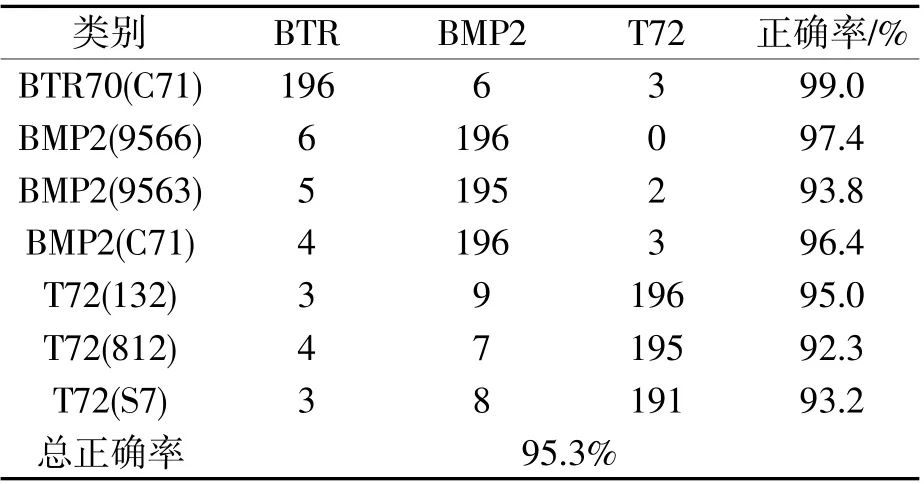
表1 基础CNN 分类结果
从表1 中实验结果可以看出,就本数据集而言,此基础CNN 在面对新测试数据时,特征提取效果较好,所得的目标分类结果准确率较高,同时没有出现过拟合的情况,具有较强的泛化效果,提取的特征图可较好地用于后续在复杂场景中的目标检测实验。
4.3.2 复杂大场景下对SAR 目标检测
本实验在Ubuntu16.04 系统环境下,基于深度学习tensorflow 框架,使用GPU 加速计算。使用新的数据验证本算法训练所得网络模型对于SAR 目标检测的效果。在目标得分阈值设置为0.8 时,选取验证数据集中如图7 所示三种复杂环境下的效果,包含不同姿态的多个待检测目标。该模型对场景1、场景3 很好地实现了不同姿态SAR 目标的自动检测,目标位置定位较为准确;场景2 有大量的树木,田地等干扰背景,虽然出现了虚检,将树木或其他干扰检测为目标,但是并没有出现漏检。后续研究中可对于虚检的目标经人工处理或进一步调整网络和优化超参数,以降低虚检率。

图7 不同场景下SAR 图像目标检测效果
VGGnet[16]是一种与它类似的特征提取网络,由牛津大学的视觉几何组(Visual Geometry Group)提出,包含16~19 层。区别在于,VGGnet 有着更深的网络结构。另一种ZFnet[17]则有5 个卷积层,3 个池化层,与此基础CNN 结构层数相近,训练难度大致相等。图8 给出相同场景下,不特征提取网络在得分阈值设置为0.8 时的目标检测效果对比。

图8 不同特征提取结构检测效果
与本方法相比,另外两种结构在作为基础特征提取网络时出现过多漏检,虚检现象。表2 给出了验证数据集中的检测结果,在本地实验环境下,对于同一张1476×1748 大小的SAR 图像,本方法检测需要用时0.324s,VGGnet 结构则需要耗时0.465s,显见检测效率相对较低。
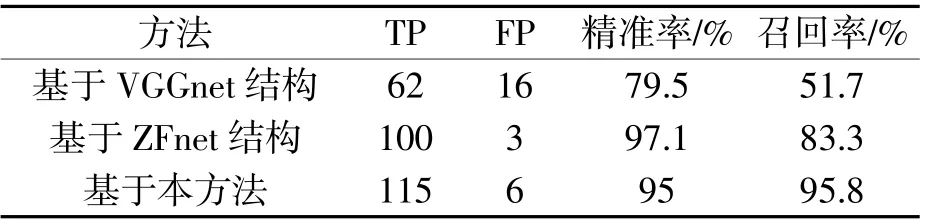
表2 不同特征提取层CNN 检测结果
其中TP 表示正确检测到的目标数,FP 表示虚检数,验证数据集需要检测的目标数目N=120。使用召回率(R)和精准率(P)来评价SAR 目标检测效果,指标具体表达式为:
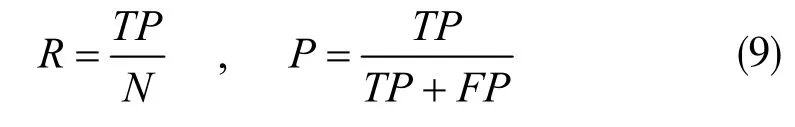
从图8 和表2 的检测结果来看,对于所使用的数据集,过于深层的VGGnet 模型结构越复杂,超参数的优化越难,越易将噪声误作为有效特征,出现较多虚检,在面对新数据时泛化能力较差。而ZFnet 检测的精准率虽然较高,出现虚检的情况较少,但是召回率不足。
鲁棒性是目标检测需要考虑的重要因素之一,验证数据集中对部分图像加入噪声密度为0.1 的椒盐噪声和均值为0、方差为65 的高斯噪声。图9 绘制了几种方法在验证数据集的的P-R 曲线。表3 给出不同方法的AP 值(Average Precision)。
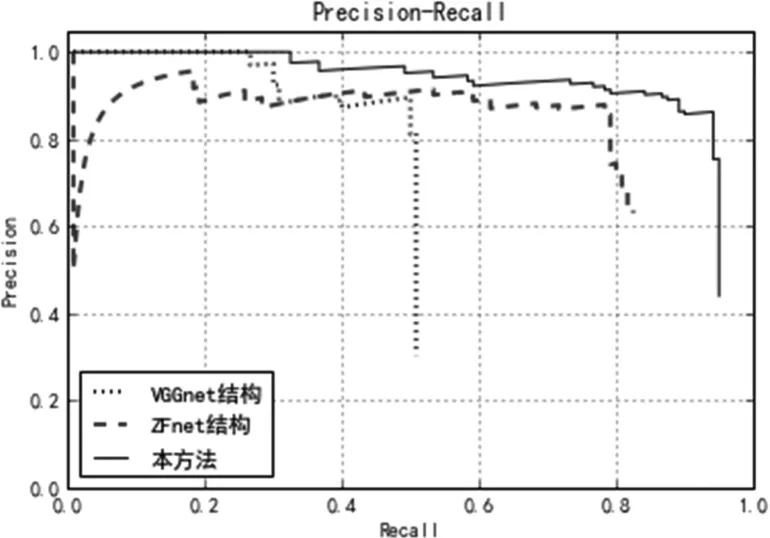
图9 各方法对比P-R 曲线

表3 不同方法的AP 值
在实验中VGGnet 在面对噪声时检测能力明显较弱,会出现在整个大场景下完全检测不到目标的情况,也会把树木等干扰杂波检测为目标,召回率比较差;ZFnet 对于目标的特征表达也不足,召回率也不太理想。本方法中基础CNN 层数适中,卷积特征提取效果较好,同时加入多层次卷积特征融合,具有更加丰富的特征表达,经过后续先得到候选目标区域再对目标进行检测这样“两步走”的网络,最终达到对大场景下较小SAR 目标的较好的检测效果。
5 结 束 语
使用较完备的SAR 数据集,同时补充复杂大场景下训练样本信息,利用CNN 优秀的特征提取能力,舍弃层数太多的CNN 结构,使用一种层数较少的基础CNN,通过多层次卷积特征融合网络,得到更加丰富的目标特征信息。经过目标检测网络,用GPU 加速优化训练后得到完整的SAR 图像目标检测模型。实验数据及结果表明所提方法具有较好的鲁棒性和泛化能力,可以实现在复杂大场景下对较小SAR 图像目标的的检测,检测效果更好。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电视技术(2014年19期)2014-03-11 15:38:20
