
基于HEVC 帧内硬件编码器的架构及算法
2020-05-11 09:32张晓宁谭伟峰习朝辉张志峰
火力与指挥控制 2020年3期
张晓宁,王 克,谭伟峰,习朝辉,张志峰
(北方自动控制技术研究所,太原 030006)
0 引言
视频图像情报在战场侦察指挥中发挥着及其重要的作用。近年来该类情报在各作战车辆内传输的实现仍然是空白。本文重点研究了基于HEVC 的硬件视频帧内编码器。目的是提高视频情报压缩率,减少视频情报的数据量;其次是加快视频情报的编码速度,最后是搭建合适的编码器架构。
实践中,战场情报的编解码是通过硬件完成的。有研究提出了帧内预测器的硬件架构[1-6]。低数据吞吐量硬件应用于解码器[1-2],其他的嵌入到编码器中[3-6]。这些编码器中的预测器可以支持视频的分辨率为1080p@60fps。但上述架构忽略了RDO路径以及重构路径的延迟。由Zhu 等人提出的帧内编码器使用上述帧内编码器架构[13]。该编码器的数据吞吐量可以支持分辨率为1080@44fps 的视频序列,理论上,其视频编码器支持25601620@46fps。这个编码器耗费片上面积大(2 269 k 门),压缩效率却只减少了4.53%。
1 算法的改进
软件HM 中编码器使用的算法并不适用于硬件编码器[9],需要对相关算法进行改进,这些改进通常会带来视频质量的损失。将HM 软件配置为通用测试条件制定的全帧内配置RDOQ 禁用,其他设置保持不变,对6 类视频序列进行质量损失的评估。下面描述了4 种方式,使得算法适应于硬件设计。
1.1 简化码率估计
图1 统计了D 类视频序列所有的CU 块CABAC 输出的比特数与输入bin 数之比的概率密度函数。比特数与bin 关系紧密,QP 值越小,关系越紧密。将输出的比特数直接替换为输入的bin 数可以简化率估计。在相同条件下,和基于固定概率模型的码率进行比较,使用该方法的损耗更小,BDRate 和BD-PSNR 的值分别为0.79 %和-0.034 dB。当视频序列为A-C 时,帧内编码的BD-Rate 和BD-PSNR 值分别为6.27%和-0.26 dB。

图1 CABAC 输出比特与输入bin 之比概率密度函数
1.2 简化失真估计
在HEVC 中,率失真优化(RDO)使用的失真度是用原始样本和对应的重构样本的差的平方和(SSE)表示的。重构过程中涉及到逆变换的计算带来了延迟。变换域中进行失真估计可以在避免逆变换情况下得到SSE 值[7]。在码域上的RD 可以表示为如下形式:
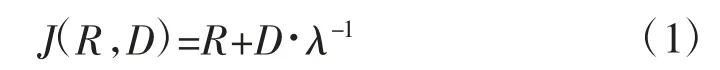
R 为码率,D 为失真度,λ 为拉格朗日乘数因子。失真度的值是由量化步长QS 以及量化余数Δ决定的:

N 为变换块的大小,2-14·N2将能量误差从变换域归一化到残差域。量化余数主要有系数Yij,量化中用到的乘法因子MFQ,偏移量f 以及量化参数QP决定。

Δij=Δ'ij如果Δ'ij<1-f
否则Δij=1-Δ'ij
在HM 中,拉格朗日乘数因子是由量化参数QP决定:

量化步长是由QP 和N 决定的:
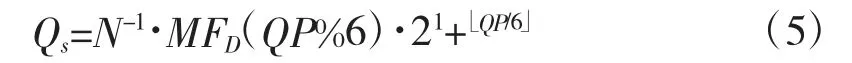
反量化过程中乘数因子MFD在一个Qs倍频范围内,是依赖于指数系数QP 的。显而易见:
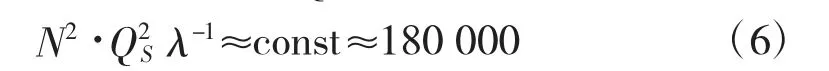
因此,在码率域的失真度独立于转换块的尺寸和量化参数。所以可得如下表达式:
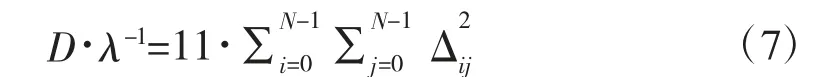
计算余数平方和时,有常数作为乘法系数,为了更好地在硬件上实现,将系数改为12,视频序列的压缩效率上升了0.15%。在该算法中,使用位级查找表(LUT)代替硬件设计中乘法器[10]。转换域以及基于LUT 近似的平方函数的损失小于0.2%。将式(7)中的系数变为12 时,该方法减少了质量损失,提高了平均结果。
1.3 预测模式的预选
为了降低编码器的复杂度,提出了3 个改进方案。第1 种,所有64×64CU 块被禁用,保证一定失真度情况下减少计算量;第2 种,RQT 被禁用,降低编码器复杂度;第3 种,对于CU/TU 的模式选择是由亮度的模式选择的结果决定的,简化色度的模式选择。模式预选步骤如下:
1)原始亮度样本每个8×8 块生成19 种预测模式。这19 种预测模式为:平面模式、DC 模式和17种编号为偶数方向的预测模式。
2)从相应的原始样本块中减去预测块,计算绝对差和(SAD)。
3)在每个8×8 块位置上,将SAD 最小的8 种模式进行基于RDO 的分析。
4)对于每一个8×8 块,建立一个序列表,根据每种预测模式的RD 的情况,对由原始样本计算出的8 种预测模式进行排序。编号为奇数预测模式位置是由其相邻偶数模式决策的。
5)在重构样本中的8×8 块,选择10 种预测模式。它们包括3 种基于熵编码最有可能预测模式(MPMs)以及7 种从序列表中选择的预测模式。这10 种预测模式进行RDO 处理。
6)重构样本生成10 种16×16 块以及4 种32×32 块预测模式,其中有3 种MPM。
7)基于SAD 的4 种16×16 以及3 种32×32块预测模式进行RDO 处理。在16×16 块中总是包含MPM。

图2 预测模式预先选择算法总体框图
8)所有色度预测模式都进行了RDO 处理,同时根据SAD 值选择了两种16×16 块预测模式,并进行RDO。
1.4 计算的可伸缩性
上一节,通过预先选择筛选出几种预测模式。在表1 中可以看出针对不同的配置文件,对于不同尺寸的亮度块以及色度块,SAD 以及RDO 可以处理的预测模式的数量。
表2 是针对不同的配置文件,各类视频序列的BD-Rate 以及BD-PSNR 的运行结果。连续的配置文件可以提高压缩效率,在配置文件4 的情况下,BD-Rate 提高了1.9%。
2 系统总体结构
所提出的帧内编码的结构如下页图3 所示。在系统结构上的创新在于两个重构回路的使用。主重构回路主要支持8×8、以16×16 及块32×32 的重构,另外一个重构回路只支持4×4 块的重构。
2.1 帧内预测
帧内预测的结构图如图4 所示。该结构嵌入了两个独立的子模块,可以在每个时钟周期并行生成两种预测模式。第1 个子模块支持4×4 块的预测模式的生成,第2 个支持8×8、16×16、32×32 块相应预测模式的生成。预测分别使用16 和64 个处理元素(PE)并行确定。每个时钟周期内,每个PE 计算一个样本。

表1 不同配置文件下使用SAD 和RDO 评估预测模式的数量

表2 不同配置文件下的压缩效率损失

图3 帧内编码器结构图
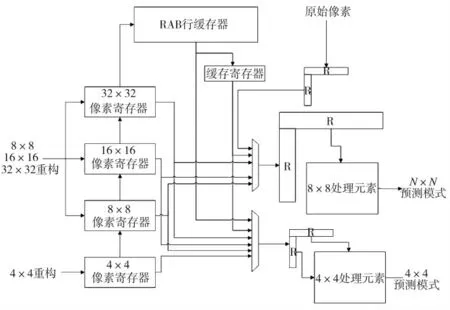
图4 帧内预测结构图
2.2 变换模块
在主重构回路中的转换模块可以支持8×8 至32×32 块的转换。该编码器融合了正变换和逆变换,在每个时钟周期可以输出4×8 以及8×2 块。4×4 转换模块嵌入到了第2 个重构回路中。它们可以重新配置,以支持正弦或者余弦变换。每一个模块包含水平处理以及垂直处理两个阶段。量化以及反量化同时存在于这两个阶段。在基础频率下,4×4 重构回路的总延迟为6 个时钟周期延迟。
2.3 模式的预选择
16×16 和32×32 块情况下,SAD 的计算是由残差决定的。从原始样本确定的8×8 预测是由SAD 评估的。在配置文件4 的情况下,可以进行20个16×16 亮度块的待预测模式预先选择。除3 种MPM,编码器对序列表中的17 个模式进行选择。在一个时钟周期内,编码器可以评估一个8×8 候选预测模式,根据候选模式的SAD,序列表中的所有条目都进行并行的更新。序列表的结构如图5 所示。

图5 序列表结构图
2.4 率估计
基于bin 数量的率估计通过分析语法元素,决定选择相应的模式组合将会生成多少个bin。它们的二值化方案随着扫描系数从高频到低频位置而在每个4×4 子块内调整。本文对原有CE 进行优化,第1 点,将每个系数与所有可能的阈值并行进行比较,将原有比较器从链中去除。第2 点,参数(莱斯、GT0_CNT)用一元码表示。优化后的CE 如图6 所示。

图6 链元素优化的实现结构图
2.5 失真估计
失真损失是基于量化余数,如果量化误差为负数,则将降档后的差翻转。平方函数的实现是由带有5 位输入的LUTs 实现的。平方差是15 bit 的小数。树形加法器进行所有的并行操作的量化单元的平方的加权和。结果用加法器执行加12 操作。
2.6 模式决策
主回路模式决策模块的结构如下页图7 所示。将连续4×8 块在率域内计算出的RD 代价累加。32×32 块所占的权重可以与其他待选择预测模式可以相互交叉处理。采用自底向上的方法对不同尺寸的PU/TU/CU 块进行比较选择。对于32×32 和16×16 块,子块的代价是由16×16 和8×8 块加权和决定的。4×4 重构回路的模式决策模块进行4×4PU/TU 块的失真度的累加以及模式决策。主模式决策模块还有另外一个模式决策CU/PU/TU,预测模式以及4×4 子块的标志。第2 种方式是由第1种方式中相应的失真代价选择决定的。

图7 主预测模式决策模块结构
2.7 熵编码器
熵编码模式只支持帧内模式,由二值化模块和CABAC 模块组成。高比特率的吞吐量可以由CABAC 模块中的比特级处理进行限制。因此,它支持4 位标志符的硬件连接处理[11]。二值化模块将语法元素二进制化,分配上下文。该模块嵌入内存缓冲区,以便保存最佳模式对应的系数块。当通过逆变换模块读取这些数据时,这些块从反量化缓冲区中提取。由于8×8 块至少要被读取两次,因此,一个时钟周期内取出32 个系数。在4×4 块的情况下取16 个系数。除了16 bit 系数,这些块还包括帧内编码器的特征系数,C1/C2 组的元素和余数标志位。它们在速率估计器中得到,并在反量化后与系数一起存储。只有当标记表明需要对系数余数进行二值化时,才会执行重新量化。
3 时序设计
不同的处理进程在使用同一硬件资源时,时序的设计必不可少。为了满足不同处理模块的时序要求,帧内编码器将交叉处理应用到两个重构回路以及RDO 路径中。
时序调度取决于从配置中选择的配置文件。每一个配置文件制定了特定模式下使用SAD 和RDO处理的候选模式的数量。编号1~4 配置文件分别建设分配给32×32 单元的时钟周期数分别为800、960、1 280、1 600。这种伸缩对应的编码器的吞吐量依次下降一半。连续配置文件中的候选模式通常与对应的模式在同一时间段进行处理。然而,32×32候选模式的正向变换在配置文件3/4 情况下扩展到了第12 个时间段。由于相应的逆变换可以晚点开始,因此,这种扩展是可以的。所需要的时钟周期在不同配置文件之间保持不变。
4 实现结果
HEVC 帧内编码器使用VHDL 语言,各模块可以通过HM 的参考模型进行验证。编码器是根据第2 部分讨论的简化模型构建的。基本时钟是由TSMC 90 nm 和Arria II GX 器件决定的,编码器可以分别在200 MHz 和100 MHz 下工作。各模块的资源消耗如下页表3 所示,大部分逻辑资源被转换模块消耗。由于逆变换的吞吐量比正向变换低两倍,所以逆变换比正向变换消耗的资源要少得多。资源消耗表明,在中成本FPGA 上实现的编码器可以支持1080p@60fps。在台积电90 nm 的实现允许处理2160p@30fps 的视频。
视频编码器的实现在文献中鲜有报道。在表4中将它们与所提议的体系结构进行了比较。Miyazawa 等人开发的编码器在定制板上用3 种FPGA 器件实现。但是,所有的模式决策都是基于SAD(严重的质量损失)做出的,没有提供资源消耗。Tsai等人提出的编码器采用28 nm 工艺流程实现,可以处理8 192×4 320@30fps 视频[6]。它支持内部和内部编码。使用固定概率模型的RDO 对有限数量的候选对象进行模式决策。只有3 种对应于不同CU尺寸的模内模式被RDO 评估。这些限制导致压缩效率的显著降低。Zhu 等人开发的帧内编码器[13]可以支持1080p@44fps 视频。该设计采用TSMC 90-nm 技术,使用了2 269 k 门数。它不包括熵编码器和内部缓冲区(如原始样本,量化系数,重建像素)。与该体系结构相比,所提议的体系结构消耗的资源要少得多,并且以类似的质量损失实现了更高的数据吞吐量。特别是,4K 视频序列和配置文件1的BD-Rate 是5.46%。编码器可以使用配置文件4处理其他序列,这提高了平均压缩效率(BD-Rate 为4.2%A-E)。
5 结论
提出的帧内编码器支持2160p@30fps 分辨率视频实时编解码,满足当前战场上各类视频情报的要求。硬件结构利用RDO 的简化以及单独4×4 重构回路和帧内预测模式的交叉处理,实现了视频数据的高吞吐量。基于原始样本生成预测模式的预先筛选与其他常规进程使用相同的硬件资源。硬件设计成本低,资源消耗低,与现有通信设备中的其他设备兼容性高。

表3 HEVC 帧内编码器资源消耗

表4 HEVC 编码器实现方式比较
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
电脑爱好者(2021年11期)2021-06-07
数字技术与应用(2021年1期)2021-03-24
——编码器
演艺科技(2020年7期)2020-08-13
电脑爱好者(2020年9期)2020-07-05
