
一种带式输送机故障诊断方法
2020-05-07 09:13张喆陶云春梁睿迟鹏
工矿自动化 2020年4期
张喆, 陶云春, 梁睿, 迟鹏
(1.中国矿业大学 电气与动力工程学院,江苏 徐州 221116;2.中国矿业大学 江苏省煤矿电气与自动化工程实验室,江苏 徐州 221116)
0 引言
带式输送机作为煤矿井下运输煤炭的核心设备,一旦发生故障会严重影响煤矿安全生产和工作效率,造成巨大经济损失。因此,对煤矿带式输送机进行故障诊断尤为重要[1-2]。目前,广义回归神经网络(General Regression Neural Network,GRNN)、概率神经网络(Probabilistic Neural Network,PNN)、极限学习机(Extreme Learning Machine,ELM)等传统浅层神经网络在故障诊断中取得了一定成果[3-5],但它们均属于浅层学习的算法结构,要在一到两层的模型结构中完成函数拟合,没有充分挖掘数据内部隐含的特征,泛化能力不强,易出现局部极值,故障诊断准确率不高,且诊断精度依赖于样本数据的分布,由于煤矿现场实际采集的故障样本数据较少,当样本数据分布不平衡时,会导致过拟合问题。鉴此,本文提出了一种基于合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)和深度置信网络(Deep Belief Network,DBN)的带式输送机故障诊断方法。该方法利用SMOTE对采集的带式输送机状态数据进行预处理,通过DBN提取数据中隐含的故障特征,可有效提高带式输送机故障诊断准确率。
1 相关原理
1.1 SMOTE
SMOTE基本思想是对少数类样本进行分析,在原始少数类样本的邻域空间中生成大量具有一定策略的新样本,以平衡样本数据分布[6-7]。
SMOTE生成新样本过程如图1所示。首先,在少数类样本中选择一个主样本xi(i=1,2,…,N,N为少数类样本个数),然后在xi的k近邻中随机选择M个样本xj(j=1,2,…,M,j≠i),最后在连接主样本xi及其主要近邻样本xj的直线的随机位置生成一个新样本[8]:
xnew(i,j)=xi+rand(0,1)(xj-xi)
(1)
式中rand(0,1)表示0~1之间的随机数。
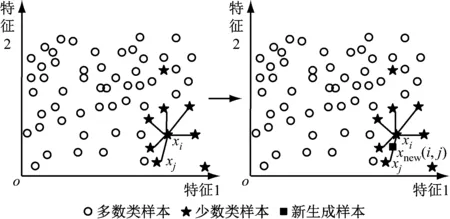
图1 SMOTE生成新样本过程
1.2 DBN
DBN由多个堆叠的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)和在最后一个RBM上增加的输出层组成[9-10]。以具有3层隐藏层结构的DBN(图2)为例,网络由3个RBM堆叠而成,每个RBM有两层,上层为隐藏层,下层为可见层。DBN训练过程包括预训练和微调2个阶段。在预训练阶段,采用逐层贪婪方法训练RBM,当前RBM训练完成,将其隐藏层作为下一个RBM的可见层,以此类推,直到最后一个RBM训练完成。每个RBM通过最大化其输入数据的概率来训练,利用对比散度(Contrastive Divergence,CD)算法更新参数。在预训练之后,将输出层添加到最后一个隐藏层,采用BP算法将误差从最后一层逐层传递到输入层,对DBN参数进行微调[11-13],从而使DBN参数达到最优。
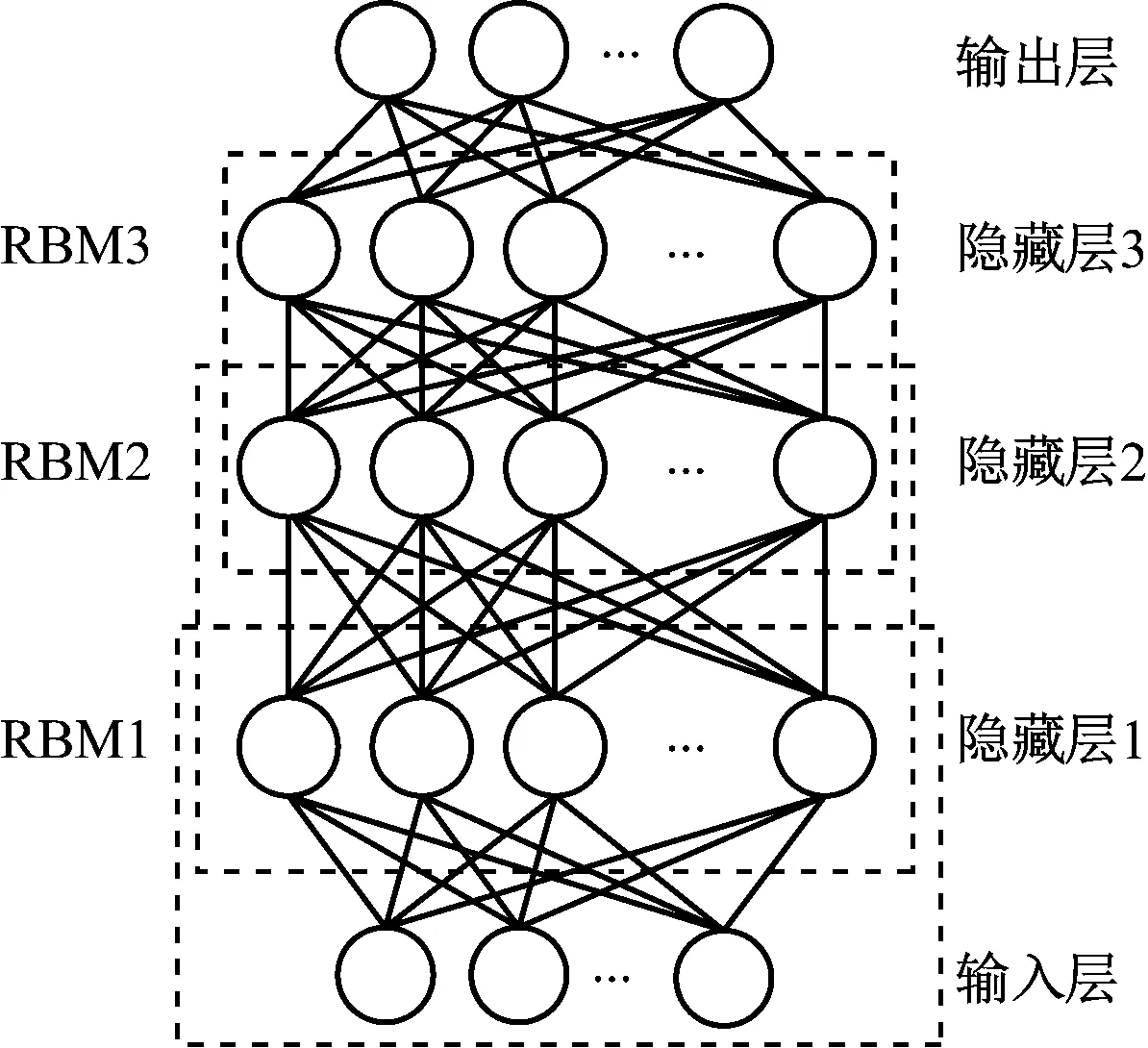
图2 DBN结构
2 基于SMOTE和DBN的带式输送机故障诊断
基于SMOTE和DBN的带式输送机故障诊断流程如图3所示,主要步骤如下。
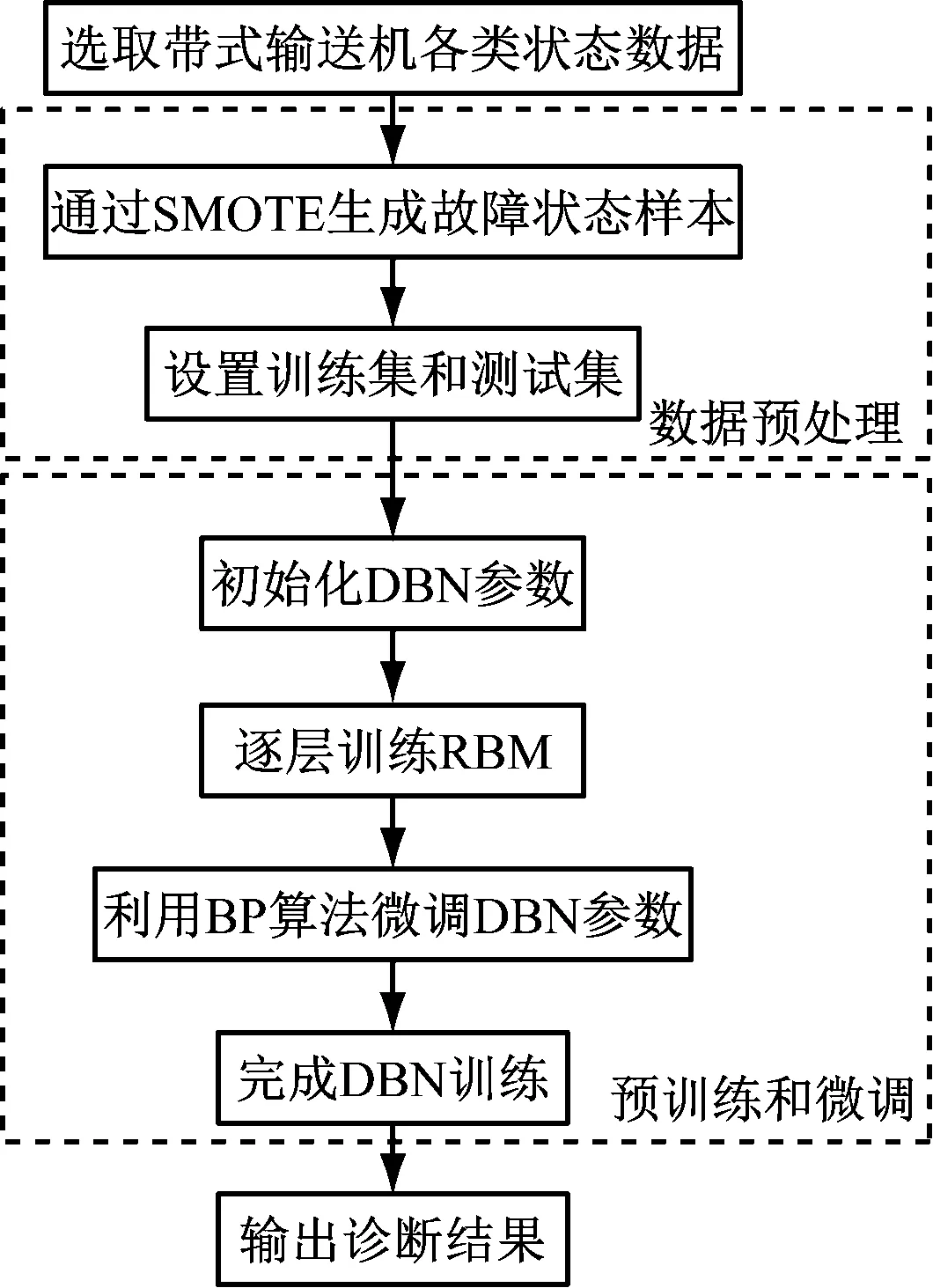
图3 基于SMOTE和DBN的带式输送机故障诊断流程
(1)获取带式输送机不同运行工况状态数据,通过SMOTE生成故障状态样本,平衡样本数据分布。
(2)确定训练集和测试集。
(3)初始化DBN相关参数,包括损失函数、RBM学习率、RBM迭代次数、网络层数、各层节点数、动量参数等,其中输入层节点数由带式输送机故障特征数量确定,输出层节点数由带式输送机状态数量确定。
(4)将训练样本作为DBN输入,以无监督方式逐层训练RBM,即将前一个RBM的隐藏层作为下一个RBM的可见层,直到完成所有RBM的训练。
(5)通过有监督方式的BP算法反向微调DBN参数。
(6)利用训练好的DBN进行带式输送机故障诊断。
3 仿真验证
3.1 数据来源
仿真使用的数据全部来自山西某煤矿现场实际采集的数据。本文选择六类典型的带式输送机故障状态(打滑、撕裂、跑偏、过载、火灾事故、电动机故障)和带式输送机正常状态进行仿真研究。选取某一段时间内该煤矿带式输送机在线监测系统采集的状态特征量,见表1。当带式输送机发生打滑故障时,电动机功率减小,改向滚筒温度明显升高,输送带张力减小;当带式输送机发生撕裂故障时,输送带张力增大,输送带速度减小,输送带偏移量增大;当带式输送机发生跑偏故障时,输送带偏移量增大,输送带速度略有增大,输送带张力和电动机功率增大;当带式输送机发生过载故障时,输送带速度明显减小,电动机功率明显增大,输送带张力增大,改向滚筒温度升高;当带式输送机发生火灾事故时,烟雾浓度明显增大;当带式输送机发生电动机故障时,电动机功率和输送带速度减小,电动机和改向滚筒温度均降低。
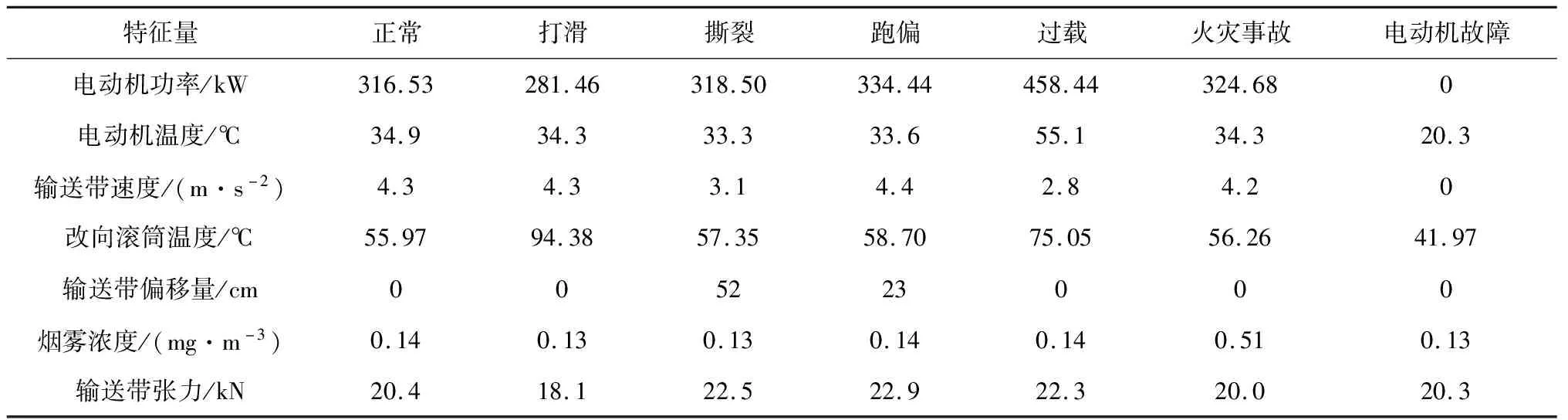
表1 不同带式输送机工况下状态特征量
将采集的410个原始样本数据经过SMOTE预处理,共获得650个样本数据,其分布见表2。选取正常状态样本中280个样本和各类故障状态样本中40个样本构成训练集,剩余样本构成测试集。
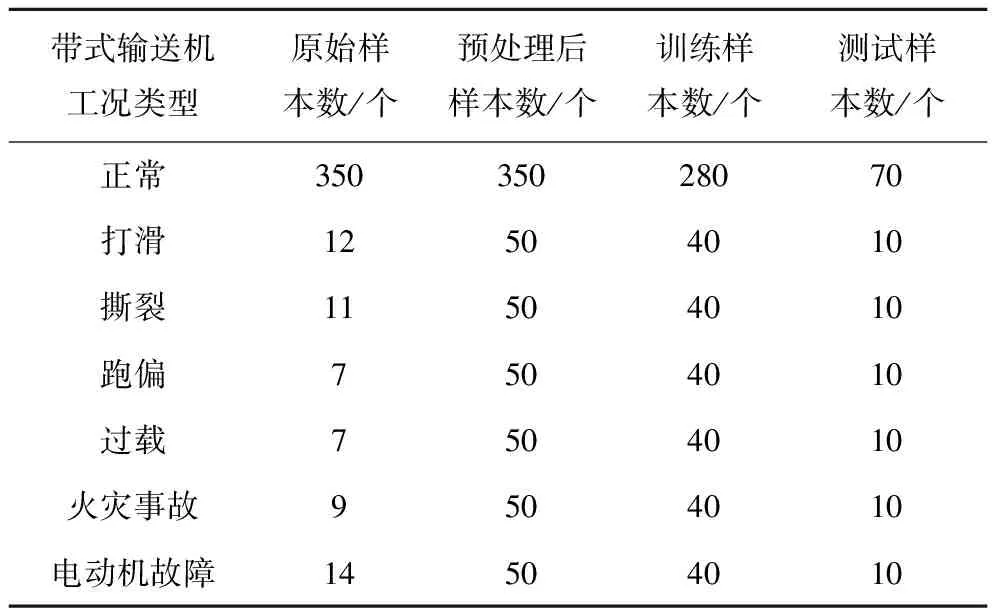
表2 带式输送机样本数据分布
3.2 参数设置
在Intel Core i7-9750H处理器、16 GB内存、64位操作系统的个人计算机上,使用Python进行仿真。
DBN输入层神经元个数为7,隐藏层神经元个数为200,输出层神经元个数为7,损失函数为均方误差函数,动量参数为0.8,RBM最大迭代次数为65,学习率为0.001,隐藏层激活函数为Sigmoid函数,输出层激活函数为Softmax函数。DBN迭代次数和隐藏层数通过实验调试来确定。
3.3 结果分析
隐藏层数设置为3时,均方误差和故障诊断准确率随迭代次数变化曲线如图4所示。可看出均方误差随着迭代次数的增加逐渐降低,训练集和测试集准确率均随着迭代次数的增加逐渐提高,因此要得到较高的故障诊断准确率,需要增大迭代次数,但会延长迭代时间;当迭代次数达到500后,均方误差和训练集、测试集准确率波动幅度较小,趋于平稳。为了缩短网络训练时间,本文选取DBN迭代次数为500。
分别构建含有1,2,3,4,5层隐藏层的DBN,迭代次数设置为500,采用相同的训练集和测试集进行仿真,故障诊断准确率随隐藏层数变化曲线如图5所示。可看出隐藏层数为 3时,故障诊断准确率最高;当隐藏层数继续增加,故障诊断准确率反而下降。因此本文选取隐藏层数为3,即DBN采用5层结构,由3个RBM组成。
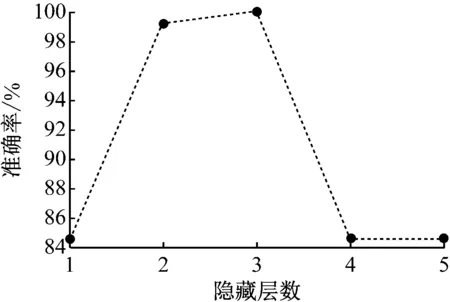
图5 故障诊断准确率随隐藏层数变化曲线
为验证DBN在带式输送机故障诊断方面的优势,与GRNN,ELM,PNN进行对比。GRNN和PNN的SPREAD参数均设置为0.4,ELM的激活函数为Sigmoid函数。4种神经网络均采用相同的训练集和测试集,对训练集和测试集进行随机排序,4种网络在训练集和测试集上的诊断结果见表3。

表3 准确率对比
从表3可看出,DBN在训练集和测试集上的准确率均较高;PNN在训练集上的故障诊断效果很好,但在测试集上的准确率明显下降;GRNN和ELM在训练集和测试集上的准确率均低于DBN。
4 结语
提出了一种基于SMOTE和DBN的带式输送机故障诊断方法。该方法利用SMOTE生成更多的带式输送机故障状态样本数据,克服了样本数据分布不平衡现象;将样本数据输入DBN,利用无监督逐层训练方式提取带式输送机运行状态数据中的故障特征,并通过有监督微调来优化故障诊断能力,避免了局部极值,提高了网络泛化能力。由于DBN结构复杂、参数较多,为进一步提高故障诊断准确率,缩短训练时间,还需要对DBN中各参数设置进行更加深入的研究。
猜你喜欢
东北水利水电(2022年6期)2022-06-28
科学技术创新(2022年15期)2022-05-18
设备管理与维修(2021年21期)2021-12-29
冶金设备(2019年6期)2019-12-25
制造技术与机床(2019年11期)2019-12-04
电子制作(2019年11期)2019-07-04
橡胶工业(2015年10期)2015-08-01
橡胶工业(2015年6期)2015-07-29
橡胶工业(2015年6期)2015-07-29
橡胶工业(2015年2期)2015-07-29
