
基于改进双流法的井下配电室巡检行为识别
2020-05-07 09:13党伟超张泽杰白尚旺龚大力吴喆峰
工矿自动化 2020年4期
党伟超, 张泽杰, 白尚旺, 龚大力, 吴喆峰
(1.太原科技大学 计算机科学与技术学院,山西 太原 030024;2.精英数智科技股份有限公司,山西 太原 030006)
0 引言
稳定的电力供应是保障煤矿安全生产的前提[1]。井下配电室是煤矿电力供应系统的重要一环,因此,需要对井下配电室进行定期巡检,及时发现隐患并进行处理[2]。当前判断人员是否按规定完成巡检任务,主要是通过检查纸质记录及监控室人工监视,存在巡检人员作弊、人工监视工作量大等问题。因此,有必要研究配电室巡检行为智能识别方法,以确保巡检人员按照规定完成巡检,保障煤矿电力系统安全。
对于煤矿井下配电室巡检行为检测来说,其主导因素是人,对人体行为的视觉分析显得尤为重要。卷积神经网络(Convolution Neural Network, CNN)[3]由于其特殊的网络结构,特别适用于计算机视觉任务。当前主流的基于CNN的人体行为识别方法主要有以下3种:① 三维卷积神经网络(3D CNN)方法。Ji Shuiwang等[4]提出了3D CNN模型,将传统的二维卷积神经网络(2D CNN)模型拓展到3D CNN模型并提取空间和时间2个维度上的特征。D.Tran等[5]在文献[4]的基础上提出了可以基于视频提取特征的 C3D网络。但是,3D CNN模型的计算量很大,且当网络深度增加时,在数据样本不够大的情况下,容易产生过拟合,人体行为识别效果不佳。② CNN与循环神经网络结合的方法。J.Donahue等[6]提出了长期循环卷积神经网络(Long-term Recurrent Convolutional Network, LRCN)。LRCN的结构包括长短期记忆网络(Long Short-Term Memory,LSTM)和CNN两部分。LRCN充分利用了视频空间维度和时间维度上的信息,但是只能避免梯度消失问题,未解决梯度爆炸问题。③ 双流CNN方法[7]。所谓双流,即网络由分别处理空间(RGB图像帧)和时间(堆叠光流帧)维度的2个CNN组成。该方法采用多任务训练方法将2个网络进行融合,获取行为特征,但是对长视频中的行为识别效果不佳。
井下配电室监控视频持续时间较长且行为类型复杂,传统双流CNN方法对此类行为识别效果较差。针对该问题,本文对双流CNN方法进行改进,提出了一种基于改进双流法的井下配电室巡检行为识别方法。首先,将每个巡检视频等分为3个部分,分别对应巡检开始、巡检中和巡检结束;采用双流CNN方法对各部分视频进行分别处理,即随机采样获取代表空间特征的RGB图像及代表运动特征的10帧X方向和10帧Y方向的连续光流图像;将RGB图像和光流图像分别输入空间流CNN和时间流CNN进行特征提取,在各自流内对等分网络的输出特征进行融合;对2个流的预测特征进行加权融合,获取巡检行为识别结果。
1 巡检行为数据集
配电室巡检行为动作由一系列简单动作组合而成,为保证每类动作分类准确,类型间差别明显,对巡检动作进行了详细分解。根据煤矿配电室巡检有关规定,巡检人员应定时认真检查各种仪表、线路、进线柜、出线柜等,以发现电力设备运行隐患,保证配电设备安全运行。巡检过程中,巡检人员除站立查看、检测外,还需下蹲检测线路、设备等,确保完成规定检测;配电室范围较大,完成整个配电室的巡检需要多次走动;完成巡检后,需按规定进行记录,一般有站立记录和坐下记录2种情况。因此,将巡检行为分为5类,分别为站立检测、下蹲检测、走动、站立记录、坐下记录。完成这5类中的4类即可认为完成了巡检行为。
巡检行为发生在背景较为固定的井下配电室,且由多个简单动作组成,完成一次巡检行为需要数分钟。使用现有公开数据集进行模型训练,巡检动作识别效果较差,准确率不高,因此,专门制作了用于配电室巡检行为识别的数据集IBDS5。IBDS5数据集采集于现有的煤矿井下配电室视频监控系统。摄像头安装于配电室入口处正上方,距地面2.5 m,光源对准配电室内部,确保能清晰地拍摄人物动作。共采集21段视频(共计10.5 h),经过人工挑选从每段视频中提取包含5类动作的样本,共计提取400个视频样本,每类动作样本数约为80个,每个视频样本长度约为5 s。巡检动作分类如图1所示。
2 巡检行为识别总体框架
站立检测和下蹲检测行为都可分为3个部分:与设备刚接触、进行设备检测和完成检测后准备离开设备。如果对整个视频进行随机帧采样,就不能很好地学习此类动作的特征。因此,将视频分割成3个等长且不重叠的视频段,对每段视频分别进行RGB图像帧和堆叠光流帧提取。将获取到的图像帧分别输入对应的空间流网络和时间流网络进行特征提取,然后在各自流内对网络输出特征进行融合,最后对2个流的预测特征进行加权融合,获取巡检行为识别结果。巡检行为识别总体框架如图2所示。

(a)站立检测

(b)下蹲检测

(c)走动

(d)坐下记录

(e)站立记录
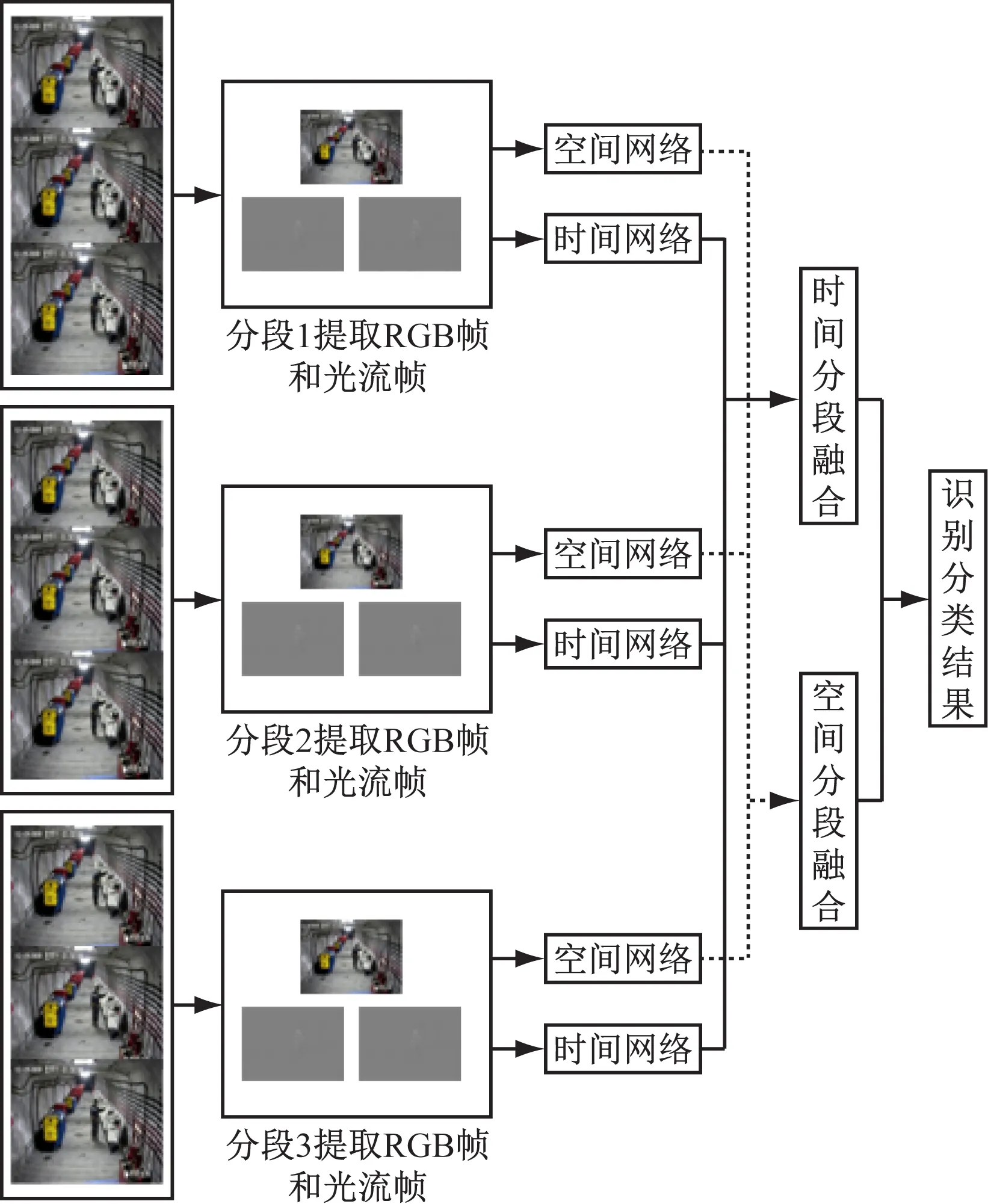
图2 巡检行为识别总体框架
将代表行为类别的视频分割为3个等长的视频段V1,V2,V3,基于分段采样的时空双通道CNN表达式为
(1)
式中:H为输出函数,用于对识别结果进行分类,得到每个行为类别的概率值,本文选用softmax函数;g为聚合函数,用于对3个分段特征以均值方法进行融合,得到空间流或者时间流的特征;Tj表示视频第j个分段的随机采样,j=1,2,3;F(Tj;W)表示用参数为W的CNN对Tj进行特征提取,时间流和空间流网络在3个视频片段上分别共享各自网络的一套参数W。
softmax函数表达式为
(2)
式中Gi为分段共识函数,Gi=g(Fi(T1),Fi(T2),Fi(T3)),i=1,2,…,C,C为行为分类的总类别数,C=5。
通过softmax函数预测得到整段视频被识别分类为每一类行为的概率。为避免训练过程太慢,结合标准分类交叉熵损失函数,得到关于分段共识函数Gi的损失函数为
(3)
式中yi为第i类行为的真实标签值。
模型是有梯度的,使用标准的反向传播算法,利用多个片段来联合优化参数W。在反向传播过程中,损失函数L(yi,Gi)对于模型参数W的梯度为
(4)
式中K为视频分段数,K=3。
网络是从3个视频段即完整的视频中学习模型参数,而不是从单一的短片段中学习模型参数。
3 巡检行为识别具体实现
3.1 空间流网络
通过空间流网络对视频中随机采样的静态RGB图像进行训练,提取巡检行为的空间特征。在静态图片识别过程中,目标物体的姿态与背景起着至关重要的作用。IBDS5数据集采集于煤矿井下,背景固定且变化较少,能更好地实现空间特征提取。
卷积网络分类器以端到端的多层方式进行集成,通过网络层数量的叠加丰富图像特征。第一代经典的LeNet网络模型集成了5层卷积层,后来逐渐发展出8层的AlexNet模型、19层的VggNet模型及22层的GoogLeNet模型。大量实验表明,卷积层数的增加可以增强网络学习能力,提高图像分类准确率。但是增加网络层数也会带来随机梯度消失问题,网络准确率达到饱和状态后会迅速下降,因此,CNN的层数最多为20。HE Kaiming等[8]提出了ResNet模型,并利用残差网络将CNN的层数增加到152,将错误率降低了3.75%。残差网络大大提高了图像识别率。ResNet网络不仅可以加深CNN的层数,而且有效解决了因层数叠加导致的训练误差增大的问题。本文采用ResNet152提取图像的空间特征。
3.2 时间流网络
视频中的运动信息对于行为识别至关重要,光流因其简单实用并能表达图像序列运动信息被广泛用于提取行为运动特征。B.K.P.Horn等[9]推导出了图像序列光流的计算公式,因光流数值接近0且有正有负,为了能够作为时间流网络通道的输入,需要对其进行线性变换,最终将X,Y方向的光流保存为2张灰度图像。本文使用TV-L1[10]方法提取视频的光流帧,提取结果如图3所示。

(a)X方向光流

(b)Y方向光流
时间流网络和空间流网络都采用ResNet152网络进行巡检行为识别。因为时间流和空间流网络都在ImageNet[11]上进行预训练,所以第1个卷积层输入的通道数为3。空间流网络输入的是RGB图像,不需要进行调整。而对于时间流来说,采用10帧X方向的连续堆叠光流帧和10帧Y方向的连续堆叠光流帧进行运动特征提取,相当于向网络输入20幅光流图像,与第1个卷积层的通道数不匹配。采用跨模态交叉预训练的方法解决该问题,即获取第1个卷积层的3个通道的权值后,取其平均值,再复制20份作为时间流网络第1个卷积层20个通道的权值,而时域网络其他层的权值与空域对应层的权值参数相同。
3.3 双通道特征融合
由式(1)可得整个空间流网络的行为识别结果Sspatial和时间流网络的行为识别结果Stemporal分别为
Sspatial=g(F(T1;W),F(T2;W),F(T3;W))
(5)
Stemporal=g(F(T1;W),F(T2;W),F(T3;W))
(6)
对Sspatial和Stemporal进行加权求和,得到最后的视频分类结果Slabels:
Slabels=k1Sspatial+k2Stemporal
(7)
式中k1,k2分别为空间流网络和时间流网络权值,均为正整数。
3.4 数据增强和迁移学习
为了得到一个好的分类模型,机器学习方法需要足够的训练样本用于学习。IBDS5数据集训练样本相对较少,为避免因训练样本数据不足造成过拟合情况,使用了数据增强和迁移学习技术。
通过数据增强技术,可扩大输入数据的规模,增加样本的差异性,并增强网络模型的泛化能力。对RGB图像帧和光流图像帧使用了角度翻转、平移变换、边角剪裁、尺度抖动[12]等数据增强方法。边角剪裁是指对输入图像的1个中心区域和边缘4个角落区域进行裁剪,裁剪后的图像与原图像差异性较大,网络输入的变化增加,因此,能有效减小过拟合的影响。尺度抖动是指将输入图像裁剪为固定尺寸,本文将输入图像从1 920×1 080修正为256×340,然后裁剪宽和高,宽和高的尺寸在{256,224,196,168}中随机采样,再将裁剪区域尺寸修正为224×224后输入对应网络进行训练。
迁移学习是指利用已有的知识来解决不同但相似的问题,即使用预训练模型来克服目标任务数据不足的缺点。对于新目标任务,需要将预训练网络模型中最后一个用于分类的全连接层替换成新的针对目标任务类别数目的全连接层。本文采用的源域数据集为UCF101行为识别数据集,目标数据集为IBDS5数据集。首先对源域数据集进行处理,构建训练集和测试集,并进行预处理;将预处理后的数据输入ImageNet网络中进行预训练,保存参数;将预训练保存的参数加载到目标域神经网络模型(本文采用VGG16,ResNet18/34/50/101/152)中,并将模型中最后一个用于分类的全连接层设置为对应的5类输出;最后对IBDS5数据集进行处理,并输入迁移后的神经网络模型中进行训练,得到行为识别结果。
4 实验分析
4.1 参数设置
基于Pytorch1.1.0深度学习框架进行实验,实验所使用的硬件及软件配置见表1。
在实验过程中,将IBDS5数据集分为训练集、测试集和验证集3个部分。这3个部分之间没有交集,数据量比例为3∶1∶1。
4.2 不同网络结构性能对比
4.2.1 空间流网络训练
将每个包含巡检行为的视频等分为3段短视频,从每段视频中随机抽取RGB图像,输入空间流网络进行特征提取,然后融合3段视频的识别结果,获得空间流网络的识别结果。

表1 实验软硬件配置
空间流网络基本参数设置:初始学习率为0.000 1,批尺寸Batch-size为16,训练2 000代,每50轮测试1次,超参数momentum为0.9。学习率是非常重要的一个超参数,甚至能左右模型性能,本文采用随机梯度下降优化算法,根据学习结果自动更新学习率。
为加快网络收敛速度并抑制神经网络过拟合现象[13],在全连接层后增加一个丢包层,对网络进行优化。在训练过程中,随机丢弃神经网络单元及其连接,抑制过拟合现象。设置空间流网络的丢失率为0.9。表2给出了网络结构为VGG16,ResNet18,ResNet34,ResNet50,ResNet101,ResNet152的空间流网络在IBDS5数据集上的准确率。其中Top-1准确率是指预测排名第一的类别与实际结果相符的概率。
从表2可看出,与其他网络结构相比,ResNet152结构的空间流网络取得了最高的行为识别准确率,Top-1准确率达到了94.47%。
4.2.2 时间流网络训练
时间流网络训练与空间流网络训练类似。将每个包含巡检行为的视频等分为3段短视频,从每段视频中随机抽取10帧X方向和10帧Y方向的连续堆叠光流帧,输入时间流网络进行学习,然后融合3段视频的识别结果,获得时间流网络的识别结果。
相对较大的初始学习率有利于网络快速收敛,因此,设置初始学习率为0.001。丢失率设置为0.8。其他参数与空间流网络参数相同。时间流网络在IBDS5数据集上的准确率见表3。
从表3可看出,ResNet152结构的时间流网络取得了最高的行为识别准确率,Top-1准确率达到了96.22%。
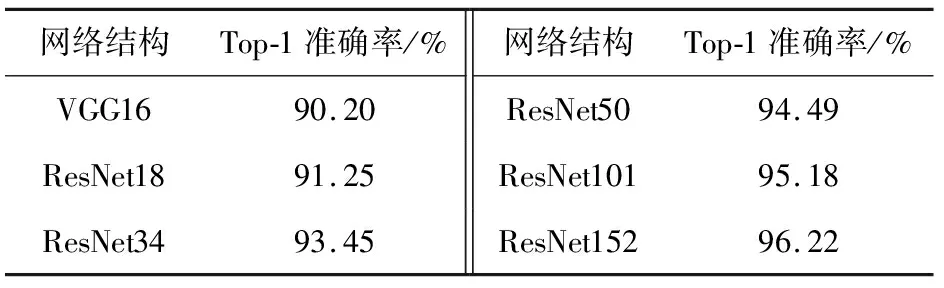
表3 时间流网络在IBDS5数据集上的准确率
4.3 权重比例确定
ResNet152结构的空间流网络和时间流网络性能最好,因此,对其进行进一步加权融合。设置多种权重比例进行实验分析,结果见表4。
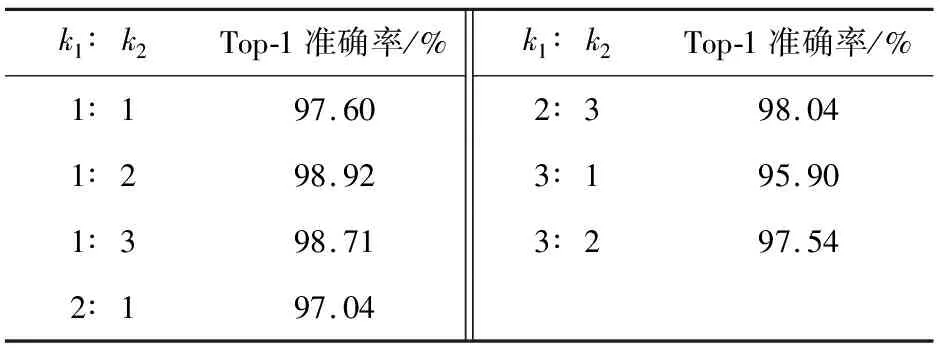
表4 双流网络在IBDS5数据集上的准确率
从表4可看出,当空间流和时间流的权重比例逐渐减小时,Top-1准确率逐渐上升,这说明时间流网络提取的运动特征对巡检行为识别有更重要的作用。当k1和k2的比例为1∶2时,Top-1准确率最高,达到了98.92%。而单独空间流网络使用ResNet152网络的Top-1准确率为94.47%,单独时间流网络使用ResNet152网络的Top-1准确率为96.22%,这说明集成双流网络的特征可以有效提升巡检行为识别性能。
4.4 不同方法性能对比
4.4.1 IBDS5数据集实验
不同方法在IBDS5数据集上的准确率见表5。3D-CNN方法的Top-1准确率为92.48%,这是由于巡检行为数据集样本较少,出现了过拟合问题,导致识别效果不佳。传统双流CNN方法的Top-1准确率为94.27%,这是由于配电室巡检监控视频持续时间较长,而传统双流CNN方法对含有复杂动作的长视频识别效果不佳。双流CNN+LSTM 方法[14]的Top-1准确率为95.86%,亦低于本文方法。

表5 不同方法在IBDS5数据集上的准确率
4.4.2 UCF101数据集实验
为了进一步验证本文方法的性能,使用UCF101数据集进行实验。UCF101数据集是目前行为识别领域应用最广泛的数据集,共包含101类动作,由25个人每人做4~7组动作,每个视频时长为2~10 s,共13 320个视频,共6.5 GB。
使用UCF101数据集训练时,采用Split1训练/测试分割方案,空间流网络和时间流网络的权重比例为1∶2,实验结果见表6。

表6 不同方法在UCF101数据集上的准确率
对比表5和表6可知,各种方法在IBDS5数据集上的识别准确率均高于在UCF101数据集上的识别准确率。其原因在于IBDS5数据集的背景较固定,而UCF101数据集的背景变化较大,且人员遮挡问题较严重。
5 结论
(1)提出了一种基于改进双流法的井下配电室巡检行为识别方法。自制配电室巡检行为数据集IBDS5,通过实验讨论并分析了不同网络结构和不同权重比例集成策略对识别准确率的影响。
(2)实验结果表明,以ResNet152网络结构为基础,且权重比例为1∶2的空间流和时间流双流融合网络具有较高的识别准确率,Top-1准确率达到98.92%;本文方法在IBDS5数据集和公共数据集UCF101上的识别准确率均优于3D-CNN、传统双流CNN等现有方法。
(3)本文方法仍存在以下不足:当多个巡检人员同时巡检时,巡检人员之间可能出现相互遮挡的情况,造成误识别和未识别问题。下一步工作将在多人巡检行为识别方面进行研究,以满足实际应用需求。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中小学校长(2022年7期)2022-08-19
冶金设备(2020年2期)2020-12-28
高原山地气象研究(2020年3期)2020-07-16
中小学校长(2019年10期)2019-11-07
通信电源技术(2018年5期)2018-08-23
工业设计(2016年4期)2016-05-04
通信电源技术(2016年3期)2016-03-26
智能建筑电气技术(2015年1期)2015-03-01
中北大学学报(自然科学版)(2014年3期)2014-11-22
