
机器学习算法的法律规制
2020-05-06 02:08崔聪聪许智鑫
上海交通大学学报(哲学社会科学版) 2020年2期
崔聪聪 许智鑫
(北京邮电大学法律系,北京 100876)
一、引 言
随着人工智能技术的不断提升和自动化决策系统的普遍应用,机器学习算法已经给社会生活带来了实质的影响,各国的立法、执法和司法工作正受到前所未有的考验。作为人工智能的核心内容,机器学习是以数字化的手段模仿人类的学习机制:从大量的现象中提取反复出现的规律与模式。(1)周志华.机器学习[M].北京:清华大学出版社,2016.目前正在兴起的深度学习算法和人工神经网络算法同样属于机器学习算法的分支,主要致力于将认知科学引入至机器学习过程之中,以模拟生物神经系统对真实世界的交互反应,从数据中获取学习算法,进而解决实际的应用问题。(2)吴岸城.神经网络与深度学习[M].北京:电子工业出版社,2016.机器学习算法利用庞大的数据和强大的计算能力正推动着人工智能学习和认知能力的快速发展。
目前,机器学习算法的法律风险在于其基于社会因素对个人进行分类、排序和决策的机制,主要包括搜索结果竞价排序、精准营销广告、保险或贷款评定、信用评级、图像识别和数据画像等人类活动场景。个人数据无时无刻不在被广泛互联的信息系统进行传输和处理,而这类数据处理行为正逐渐依赖于机器学习算法的设计和使用。根据技术中立原则,机器学习算法不应当被完全否定,但由于其存在着潜在的负面影响,因此具有规制的必要。正如国内有学者所提出的,机器学习算法的兴起给法律规范带来了巨大挑战,主要集中在数据安全、认知歧视、不透明性等问题,至于具体的规制方法和法律制度,国内尚未有学者涉及。(3)参见陶盈.机器学习的法律审视[J].法学杂志,2018,39(9):55-63;黄武双,谭宇航.机器学习所涉数据保护合理边界的厘定[J].南昌大学学报(人文社会科学版),2019,50(2):44-52.根据文献检索结果表明,国外学术界已有H.Sunden、C.Coglianese等少数学者对机器学习算法在司法应用、公平性、透明性等特定问题进行了初步的分析或设想,但并未有系统性的研究成果。(4)See Surden H.Machine learning and law[J].Washington Law Review,2014,89(1):87-115;Coglianese C,Lehr D.Regulating by robot:administrative decision making in the machine-learning era[J].Georgetown Law Journal,2017,105(5):1147-1223.
本文通过界定机器学习算法,厘清现实中的社会问题和法律困境,提出机器学习算法不具有法律效力的特定情形,建立算法影响评估制度,建立健全算法审查的监管方案,对机器学习算法的实际应用进行规制,期冀为机器学习算法带来的社会问题和法律风险提供应对之道。
二、机器学习算法规制的必要性
(一)机器学习算法的现实应用
机器学习算法属于计算机科学的子领域,也是人工智能技术的重要分支。作为一种“学习算法,机器学习算法”能够不断从数据和经验中学习,重新构建已有知识结构以改善自身性能。(5)Russell S,Norvig P.Artificial intelligence:a modern approach(third edition)[M].New Jersey:Pearson,2010.但机器学习算法中的“学习”并不意味着计算机系统能够完全复制人类起到学习功能的高级认知系统,目前的机器学习算法仍无法达到大多数人的智力水平。(6)Witten I H,Frank E,Hall M A.Data mining:practical machine learning tools and techniques(third edition)[M].Burlington,Massachusetts:Morgan Kaufmann,2011.因此,我们可以将机器学习算法视为信息系统在特定功能上的一系列学习方法:它们能够通过经验不断改变其行为,以增强在某些任务上的表现。
机器学习算法包含了许多不同的模型,较为典型的模型包括逻辑回归、决策树、神经网络等,模型的选择取决于具体应用场景下对准确性、可用性等因素的需求,系统设计者通常使用多种模型的组合以寻求最优化的处理方式。典型的机器学习算法可被具象化地分为两部分:分类器和学习器(见图1)。(7)Burrell J.How the machine ‘thinks’:understanding opacity in machine learning algorithms[J].Big data & society,2016,3(1):1-12.分类器接受输入(特征)并产生输出(类别),例如进行疾病诊断的自动化决策系统接受(临床表现、血液检查结果等)输入信息,而输出(高血压、心脏病等)疾病诊断结果。学习器则对分类器起到反馈调节的作用,在不同的机器学习模式下,学习器不尽相同。根据训练数据是否具有标签信息,机器学习算法可分为监督学习、无监督学习和半监督学习三种不同的模式。(8)标签信息是指通过人为对训练数据的预先标注,从而预设数据分类和输出的结果;监督学习是指基于已知类别的训练数据进行学习;无监督学习是指基于未知类别的训练数据进行学习;半监督学习是指同时基于已知类别和未知类别的训练数据进行学习。在监督学习中,学习器必须根据带人为标记的数据对分类结果进行检验,以修正权重分配和模型架构,再由分类器使用新的权重矩阵以确定新输入数据的分类(例如垃圾邮件筛选器需要使用预先分类并被人为标记为“垃圾邮件”或“非垃圾邮件”的电子邮件信息进行学习训练),算法设计者可通过调整标注数据等手段控制决策系统的学习方向;非监督学习则无需依托于人工标记的数据,而是使用特定的数学方法对算法模型进行自我优化,因此导致设计者与运营者对该处理过程通常缺乏理解和控制;对于半监督学习则可将其视为监督学习与无监督学习的组合从而分别予以规制。目前,生成标注数据需要消耗大量的人力成本和时间成本且受到可用性的限制,越来越多的自动化决策系统选择对无标注数据进行无监督学习,以习得大数据中隐含的人类活动和社会规律,其往往能挖掘出超出算法设计者所预期的数据关联。
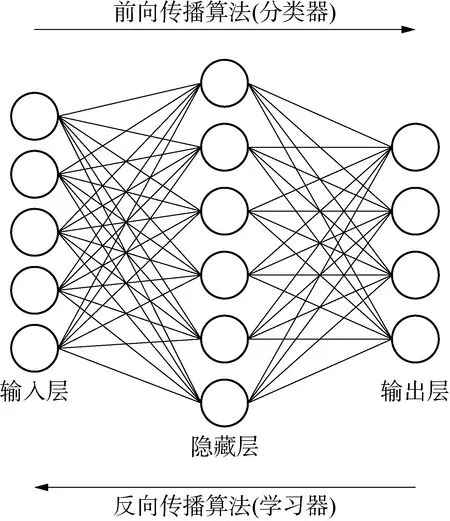
图1 基于神经网络的机器学习算法图例
尽管机器学习算法存在缺乏人为控制和不可完全预期的问题,但由于其强大的泛化能力和预测能力,相关算法已被广泛用于提取海量数据中的潜在规律和模式,以便自动执行现实中的复杂任务或者进行预判。(9)Sorkin D E.Technical and legal approaches to unsolicited electronic mail[J].University of San Francisco Law Review,2001,35(2):325-384.随着训练数据规模和可用性的持续增长,机器学习算法的准确性不断提升并逐渐成为驱动人工智能应用发展的核心技术,目前已经在网络检索、面部识别、用户画像、自动驾驶等应用场景中对人际互动和人类活动产生显著影响。可以预见的是,今后人工智能会全面进入人类社会生活的各个方面,包括但不限于家政、医疗、金融、司法等对自然人产生直接法律效力和重大影响的敏感领域。(10)曹建峰.人工智能:机器歧视及应对之策[J].信息安全与通信保密,2016(12):15-19.而人工智能时代下的机器学习算法将会成为智能社会和数字经济活动的“控制中枢”,建立对机器学习算法的规制方法将是完善人工智能法律法规和伦理规范的必要条件。
(二)机器学习算法应用产生的社会问题
使用机器学习算法的组织机构通常利用大数据进行预测分析,以判定不确定结果的可能性。(11)Maisel L,Cokins G.Predictive business analytics:forward looking capabilities to improve business performance[M].Cary:Wiley & Sons,2014.在理想状态下,机器学习算法会协助人工智能系统产生近似于在相同岗位的人所做出的结果,通常被视为“智能”的自动化结果,然而这些结果其实并不智能。人类的智能体现在行为活动中的高级认知能力,例如推理、理解、元认知或者抽象概念的语义感知,而这些行为却由机器学习算法以基于非认知方法的计算技术予以实现。机器学习算法并不需要以人类的方式理解抽象概念(例如性别、种族、职业),便可以实现特定人群的划分或者信用评级,从而向目标人群提供特定服务或订立合同。机器学习算法能够精准地实现目标,是由于其忽略了对数据内容和内涵的理解,通过数据形成的概率统计模型对数据的客观关联性进行分析和预测,最终得出与使用高阶认知方法的人在相同情景下相同或相似的结论。相较于非“智能”的普通算法,机器学习算法的执行过程缺少人为控制,若不能将预先设计的规制代码有效地加入模型系统之中,其将完全承袭训练数据中的行为习惯,包括群体可能蕴含的不公平、歧视、违法信息和其他不道德的特征。(12)通过机器学习,违法信息可能会被语音机器人、信息生成发布机器人和其他人机交互型机器人习得,并将相关内容以不同方式进行制作、复制、发布、传播。这将对个人权利和自由造成更具隐蔽性的危害。
机器学习算法产生的不公平结果通常是由于系统决策是根据有限的数据、单一的个人特征、过往的事件、已经受到伤害或被处罚的行为、不断变化的环境得出的,这种机会主义下的数据关联并不能使得相关系统得出合法且合理的结论:例如大学先前在录取申请者时对某一特定地区采用了不同于其他地区的录取比率,而在利用自动化决策系统对相关申请进行分析并做出录取或不录取的决定时又采用了这一不公平的历史数据进行训练,那么该算法便会在不断的拟合和泛化过程中将该问题固化为决策时的参数,应用至后续每一次系统的录取决定中,而系统的设计者或运营者可能未认识到这些潜在的不公平问题。(13)World Wide Web Foundation.Algorithmic accountability[EB/OL].(2017-7)[2019-4-3].https://webfoundation.org/docs/2017/07/Algorithms_Report_WF.pdf.
机器学习算法具有数据分类的功能,这将天然地存在歧视性风险。法律上受保护的个人数据特征通常包括财产交易、健康生理、生物识别、身份识别等。(14)胡文涛.我国个人敏感信息界定之构想[J].中国法学,2018(5):235-254.尽管个人敏感数据在大多数的自动化决策系统中使用都是非法的,但使用行为并不必然构成算法歧视,需要结合特定情形下的使用目的予以判定。(15)Berendt B,Preibusch S.Better decision support through exploratory discrimination-aware data mining:foundations and empirical evidence[J].Artificial Intelligence and Law,2014,22(2):175-209.现实中,医疗诊断的辅助系统将不可避免地使用健康生理和生物识别的相关数据,这类数据处理行为并不构成歧视。而当企业和政府将此类敏感数据应用于保险、贷款、求职等领域的业务决策系统中,将产生歧视性结果。(16)Davidow B.Welcome to algorithmic prison — the use of big data to profile citizens is subtly,silently constraining freedom[J].The Atlantic,2014,20(2):12-17.例如欧盟的一家连锁超市使用了Echeloon公司运营的智能相机系统作为其店内的广告系统,通过嵌入广告屏幕中的相机,系统性地识别顾客的性别、年龄、外貌、屏幕观看时间,并通过面部表情推断出顾客对当前广告表现出的情绪状态(如愤怒、快乐、焦虑等),通过机器学习算法分析推定顾客的兴趣和偏好,并通过屏幕向当前客户提供个性化广告,只是生物特征有所差异的人群将被认定喜欢不同价格、品质和类型的商品,该商业应用构成了基于敏感数据的歧视行为。(17)Bieker F,Martin N,Friedewald M,et al.Data protection impact assessment:a hands-on tour of the GDPR’s most practical tool[C]//IFIP.Advances in information and communication technology.Cham:Spring,2018:207-220.https://doi.org/10.1007/978-3-319-92925-5_13.(2018-6-9)另一典型的算法歧视案例是美国法院所使用的自动化决策算法COMPAS可对受到刑事处罚人员的再犯风险进行评估,并由此决定其刑罚,而此算法却被发现系统性地歧视了黑人:相较于白人,黑人更多地被错误认定为具有更高的犯罪风险。(18)Angwin J,Larson J,Mattu S,et al.Machine bias:there’s software used across the country to predict future criminals.And it’s biased against blacks[EB/OL].1(2016-5-23)[2019-7-23].https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing.在数字化平台提供商业服务的过程中,同样存在着基于种族、性别、年龄或其他个人敏感特征进行分析决策的算法歧视情形,例如打车软件Uber的用户评分歧视(19)Rosenblat A,Levy K E,Barocas S,et.al.Discriminating tastes:Uber’s customer ratings as vehicles for workplace discrimination[J].Policy & Internet,2017,9(6):256-279.,租房软件Airbnb的房屋价格歧视(20)Edelman B,Michael L.Digital discrimination:the case of airbnb.com[J].Harvard business school working paper,2014,14(54):1-21.,社交软件Facebook的定向广告歧视(21)BBC.Facebook charged with home discrimination through targeted ads[EB/OL].(2019-3-28)[2019-5-23].https://www.bbc.com/news/world-us-canada-47737284.等等。
随着机器学习算法被广泛地应用于各项业务的决策或决策支持系统中,其将无意或有意地造成社会危害,事实证明制造出不会因数据造成任何偏差的模型系统是不实际的。(22)Barocas S,Selbst A D.Big data’s disparate impact[J].California Law Review,2016,104(9):671-732.这些危害嵌套在一系列相关的社会问题之中,包括算法的可问责性(23)Kroll J A,Huey J,Barocas S,et al.Accountable algorithms[J].University of Pennsylvania Law Review,2017,165(3):633-705.、自然环境下的可信赖性和鲁棒性(24)Zliobaite I,Pechenizkiy M,Gama J.An overview of concept drift applications[C]//Japkowicz N,Stefanowski J.Studies in big data.Big data analysis:new algorithms for a new society.Cham:Springer,2016:91-114.https://doi.org/10.1007/978-3-319-26989-4_4.(2015-12-17)、对抗者的安全性(25)McDaniel P,Papernot N,Berkay C Z.Machine learning in adversarial settings[J].IEEE Security & Privacy,2016,14(3):68-72.、不平等的保护(26)Boyd D,Crawford K.Critical questions for big data:provocations for a cultural,technological,and scholarly phenomenon[J].Information,communication and society,2012,15(5):662-679.、隐私和正当程序风险(27)郑志峰.人工智能时代的隐私保护[J].法律科学(西北政法大学学报),2019,37(2):51-60.、大规模监控系统(28)童彬.公共视频监控图像信息利用与保护的基本法律问题与立法规制[J].重庆邮电大学学报(社会科学版),2018,30(5):55-63.。这些社会问题要求研究人员和从业人员在设计和利用机器学习算法时,尽可能地减少可能存在的盲区和风险。
三、机器学习算法规制的法律困境
(一)电子商务法的尝试及其局限性
按照功能划分,机器学习算法包含优先级排序算法、分类算法、关联度算法和过滤算法等多种类型。(29)Diakopoulos N.Algorithmic accountability:journalistic investigation of computational power structures[J].Digital journalism,2015,3(3):398-415.电子商务平台所依托的自动化决策系统往往是其中多个算法模型的组合,这类算法组合将被应用至事关用户核心服务的信息检索、个性化推荐和商品定价的电子商务经营活动之中。我国电子商务法第十八条要求平台在提供个性化推荐结果的同时,向用户提供未利用个人数据产生的自然结果。该规定认可了网络平台利用机器学习算法对特定个体进行数据画像和精准推送的合法性,但要求个性化推荐算法不能作为唯一的检索方法提供给消费者。同样的,电子商务法在第四十条要求平台应当基于价格、销量、信用等多种类型的数据提供结果排序,并需要对竞价排名结果特别标明。据此,平台在利用机器学习算法对数据进行分类、排序时,应当根据消费者的选择对不同的数据特征进行处理分析,从而保障消费者的选择权和知情权。
电子商务法采用分类界定方法对算法进行类型化的规制,其基于是否具有个人特征的使用行为将搜索算法划分为“个性化推荐结果”和“自然结果”,又根据使用的数据特征将其分为“价格排序”“销量排序”“信用排序”“竞价排序”,并针对特定类型的算法赋予平台特殊义务,以平衡网络平台与消费者之间的实力差异。可以预见的是,这种人为且较为机械的静态划分方法在实际监管的过程中会遇到多重障碍,且可能无法实现预期效果。在实践中,对算法的划分并不是二元化的“全有全无”的问题,即使是“不针对其个人特征的选项”的自然结果也将或多或少地读取地理位置、终端设备或Cookies等标识信息,否则将无法提供有效的服务内容。而数据特征间的相关性也注定了划分排序方法的复杂性,“信用排序”中“信用”的衡量标准往往不可避免地与销量、价格等数据特征产生关联,特别是当平台使用机器学习算法对数据进行处理分析时,每一项数据特征都将被系统赋予特定的权重,并将根据其准确性、泛化能力等表现效果人为或自动化地予以调整,而这一学习决策的具体计算过程我们将不得而知,也因此无法对其所真正依赖的数据类型予以判定。(30)张淑玲.破解黑箱:智媒时代的算法权力规制与透明实现机制[J].中国出版,2018(7):49-53.例如,在“魏则西事件”后,联合调查组要求百度减少商业推广信息的比例并对其标记提示,并采用以信誉度为主要权重的排序算法。(31)梁福龙.国信办联合调查组结果:百度竞价排名影响魏则西选择百度:从6方面整改[EB/OL].(2016-5-9)[2019-6-17].http://www.guancha.cn/economy/2016_05_09_359617.shtml.类似的整改要求对平台而言只是“表面文章”,由于监管者无法进入算法内部进行审查,无法了解造成危害后果的技术原因,难以提出切实有效的算法整改方案,只能在结果端予以形式上的审查,因此也难以对平台起到实质性的内部规制作用。
总体而言,电子商务法首次尝试将算法由平台内部设计的技术问题转变为法律的调整对象,并提出了电子商务平台算法事前监管的初步思路,是对数字经济时代下的平台监管问题做出的积极回应。但其未明确算法学习和决策过程中的监管方式,缺乏损害结果的问责和救济规则,特别是在机器学习算法的规制上具有相当的局限性。
(二)机器学习算法规制的“黑箱”问题
无论是采用对机器学习算法分析决策过程的监管,还是对其外部行为和结果的问责,都需要尽可能多地理解算法的内部设计和形成逻辑。基于传统的民事法律框架,在理想条件下,监管者应当能够通过机器学习算法的技术分析,判断设计者、运营者以及其他参与主体在算法系统各环节中的相关行为对系统最终的分析决策可能产生的影响,确定相应的权利与义务,制定一般性的行为规范和设计规则;根据产生结果的危害程度,判断参与主体是否履行了相应义务和规范,对行为人的心理状态(故意、过失)予以判定,确立机器学习算法活动中的主体责任。(32)有学者提出,以机器学习方法为核心的人工智能系统应当采用无过错责任,根据现行的《产品质量法》有关生产者免责事由规定,当自动化决策系统在投入流通时引起损害的缺陷尚不存在的或当时科学技术水平不能发现缺陷存在的,将免于承担赔偿责任,而采用机器学习方法恰恰就存在着缺陷随产品使用行为后天出现和结果不可预见的特点。参见胡凌.人工智能的法律想象[J].文化纵横,2017(2):108-116.
但这一理想的监管框架在面对机器学习算法的“黑箱”(black box)问题时将具较大的实现难度,甚至是无能为力。由于一个有效的机器学习算法模型通常包含数百万数据单元和数万行代码,并会随着时间的推移、模型使用者的参与、新的数据的输入,自动地调整其内在的决策模型和代码内容。在这种情况下,设计者和运营者很难确切地说明其算法是如何做出决策的,通常只能通过有限的测试用例或其他验证方法给出该模型的预期效果和准确程度。(33)Knight W.The dark secret at the heart of AI[EB/OL].(2017-4-11)[2019-6-24].https://www.technologyreview.com/s/604087/the-darksecret-at-the-heart-of-ai/.而这些有限的信息难以实现传统法律规范在算法系统的违法行为或犯罪行为中对人或参与主体的归责。(34)周铭川.论自动驾驶汽车交通肇事的刑事责任[J].上海交通大学学报(哲学社会科学版),2019,27(1):36-43.
从技术方法来说,尽管设计者和运营者能够控制算法模型所使用的训练数据,并通过监督学习对模型参数进行调整,但是他们通常无法在算法模型中预设对决策进行解释和论证的程序。(35)Kuang C.Can AI be taught to explain itself?[EB/OL].(2017-11-21)[2019-6-22].https://www.nytimes.com/2017/11/21/magazine/can-ai-be-taught-to-explain-itself.html.甚至可以说目前广泛使用的机器学习算法的特点和优势便在于其超出人类对数据的分析能力和对结果的预判能力。(36)郑戈.算法的法律与法律的算法[J].中国法律评论,2018(2):66-85.若法律强制要求设计者或运营者理解算法执行过程并探究结果原因,反而违背了该技术目前的发展目的与意义。
(三)现有算法规制方案之不足
解决算法的“黑箱”问题已成为法律界和技术界学者在机器学习算法上的新的核心问题。算法的透明性和可解释性成为众多国内外政策制定者和学者所广泛提倡的监管原则。(37)Zara C.FTC chief technologist Ashkan Soltani on algorithmic transparency and the fight against biased bots[EB/OL].(2015-4-9)[2019-7-24].http://www.ibtimes.com/ftc-chief-technologist-ashkan-soltani-algorithmic-transparency-fight-against-biased-1876177.算法透明性方案主张使用自动化决策系统的组织机构公开算法代码和底层数据,接受公众和监管机构的监督以识别出算法是否存在以及如何产生危害结果。(38)Rainie L,Anderson J.Code-dependent:pros and cons of the algorithm age[EB/OL].(2017-2-8)[2019-5-23].https://www.pewinternet.org/2017/02/08/code-dependent-pros-and-cons-of-the-algorithm-age/.算法可解释性方案则强调当自动化决策对相对人产生法律效力或重大影响时,算法使用者需向提出异议的相对人提供具体决策的解释,以阐明决策过程中算法的工作机制和合理依据,这也是欧盟《一般数据保护条例》(General Data Protection Regulation,GDPR)赋予数据主体的一项重要权利。(39)张凌寒.商业自动化决策的算法解释权研究[J].法律科学(西北政法大学学报),2018,36(3):65-74.
但是无论是算法的透明性(公开算法的代码和数据),还是可解释性(解释算法的决策过程),都存在着现实的不合理性。在目前的技术水平和社会结构下,编写和阅读代码是一项专业的技能,采用透明性方案将代码公开给一般使用者或普通公众并不能使其获得正确的理解。算法的可解释性方案同样存在技术障碍,由于机器学习算法所采用的对高维度特征的数学优化方法与人类逻辑推理和语义解释的智能活动在思想和方式上无法匹配,因此很难使用一般的语义表达方法予以说明。实际上,即使是机器学习算法模型的特定部分完全透明,但对于该部分算法的确切作用,技术领域的专家们也不能得出一致的结论。(40)Sandvig C,Hamilton K,Karahalios K,et al.Auditing algorithms:research methods for detecting discrimination on internet platforms[EB/OL].(2014-5-22)[2019-6-25].http://social.cs.uiuc.edu/papers/pdfs/ICA2014-Sandvig.pdf.从另一个角度来说,机器学习算法模型全面透彻的透明性和可解释性不仅会减损专利软件价值、影响商业秘密保护,也可能会给竞争对手、黑客等动机不良者非法地侵入、干扰、控制特定的算法系统提供可乘之机,甚至是给一些动机不良的用户规避或操纵算法进而发布违法信息或实施违法行为提供便利,使得普通的消费者最终承担这些不利后果。(41)New J,Castro D.How policymakers can foster algorithmic accountability[EB/OL].(2018-5-21)[2019-4-3].http://www2.datainnovation.org/2018-algorithmic-accountability.pdf.
尽管现有解决方案存在不足,但一味地默许和放任算法的不透明性将引发一系列的社会问题。不透明性将成为企业和组织故意违法、隐瞒真相的工具,产生欺骗执法和司法部门的潜在风险,以不透明的算法决策为幌子掩盖其故意的歧视、侵权或其他不道德、不合法的行为。(42)Atkinson R D.‘It’s going to kill us!’ and other myths about the future of artificial intelligence[EB/OL].[2016-6-10].http://www2.itif.org/2016-myths-machinelearning.pdf.当机器学习算法在“黑箱”之中创造的决策系统破坏了社会秩序的安定性,影响了人类合法的权益之时,面对算法制造的侵权和违法行为,法律必须给出对策并予以规制。面对不透明性的监管障碍,破解机器学习算法规制困境的可能路径在于确立机器学习算法的审查思路,制定具有应用限制和技术引导作用的法律制度,将具有潜在社会危害性的机器学习算法限制在能够影响人类活动的应用场景之外。通过监管者的专业审查机制实现机器学习算法在一定程度上的透明性和可解释性,引导自动化决策系统的设计者和运营者使用更可控、更有预见性的机器学习算法。
四、机器学习算法法律规制的制度设计
(一)机器学习算法系统的无效原则
在机器学习算法应用领域建立无效原则是对个人权利和自由的基本法律保障,以赋予被作出决策的数据主体反对特定的机器学习算法(无监督学习)和自动化决策(完全自动化决策)的权利。从技术角度而言,监督学习模式下的机器学习算法能够通过处理带有标注内容的训练数据在人的引导下习得一个由输入至输出的映射模型,并通过特定的误差准则不断地、有监督地调整参数直至寻找到一个最优的模型。(43)王天一.裂变[M].北京:电子工业出版社,2018.因此,有监督的算法往往意味着设计者和运营者能够控制决策系统的学习方向和预期结果,而无监督的算法则无法预设和控制其输出结果。(44)无监督学习算法中较为典型的是对没有标记的数据集进行分类的聚类算法,其主要应用于对特定数据单元的自动化划分,以揭示数据之间潜在的性质差异。通常,学习效果较好的机器学习算法都难以脱离监督学习的作用,即使是号称“自学成才”的AlphaGo Zero,其训练过程也要受人为设置的围棋胜负规则的限制。(45)Silver D,Schrittwieser J,Simonyan K,et al.Mastering the game of Go without human knowledge[J].Nature,2017,550(7676):354-359.由此可见,只有在监督学习模式下的机器学习算法,才能够使得法律法规和伦理规范以人为干预的方式得以从始至终地遵守,而没有可控性和可预期性的无监督学习往往难以通过事先编程的静态方式实现复杂应用场景下动态地合规性和合伦理性。
当无监督学习的机器学习算法应用至自动化决策系统之中,将会产生对个人具有实质影响的完全自动化决策。为此,GDPR赋予了数据主体免受完全自动化决策约束的权利。(46)参见GDPR第22条第1款:数据主体有权免受完全自动化决策(包括数据画像)的约束,当该决策对个人产生法律效力或类似重大影响时。此处的“完全”意味着在决策过程中没有人为活动的参与,且不能通过故意制造人为活动的参与以规避无效情形的规定。数据控制者应当确保所有的“人为干预”都是有意义的,且由有相关能力和相应权限改变决策结果的专业人员执行此过程。若完全自动化决策系统对数据主体产生了法律效力或重大影响,相对人可拒绝算法结果并免受其影响。
“人工”建设的重要性,不亚于“智能”建设的重要性,人类在人工智能应用中的作用不容忽视。(47)程金华.人工、智能与法院大转型[J].上海交通大学学报(哲学社会科学版),2019,27(6):33-48.就目前而言,影响人类活动的自动化决策系统所依赖的机器学习算法原则上应当是处于监督学习或半监督学习状态下的,确保人对人工智能系统前进方向的正确引导。为此,依赖于无监督学习算法的完全自动化决策系统应当加入有实质意义的人为可控模块,以供专业人员对已部署的系统进行有效的定期检查和修正,否则只能应用至科学研究、电子游戏等不影响人类现实活动的应用领域,或是满足法律规定的豁免条件而准予使用。(48)WP29.Guidelines on automated individual decision-making and profiling for the purposes of regulation 2016/679[EB/OL].(2018-8-22)[2019-6-30].https://ec.europa.eu/newsroom/article29/item-detail.cfm?item_id=612053.
具体而言,若想在人类现实活动中合法有效地部署应用完全自动化决策系统,需满足以下三种豁免情形之一:合同订立和履行之必要、用户明确同意、法律法规授权的特定应用。(49)参见GDPR第22条第2款规定的免受自动化决策权例外情形:(a)当决策对于数据主体与数据控制者的合同签订或合同履行是必要的;(b)当决策是欧盟或成员国的法律所授权的,控制者是决策的主体,并且已经制定了恰当的措施保证数据主体的权利、自由与正当利益;(c)当决策建立在数据主体的明确同意基础之上。例如,企业在进行招聘时收到数以万计的申请,此时如果不通过完全自动化决策的方式筛选不相关的申请就难以确定合适人选,在该情况下,企业为了与数据主体订立合同而使用无监督学习算法属于“合同订立和履行之必要”的豁免情形;在欧盟一家连锁超市使用Echeloon开发的基于情绪解析的个性化广告系统的案例中,尽管超市在入口处贴出公告以告知客户店内存在视频监控并附上相关条款,但这一方式并未明确介绍自动化决策系统(智能相机系统)的处理方法、目的、范围等信息,并且未获得数据主体以显而易见的方式提出的书面形式的同意(包括纸质、电子邮件、数字签名等方式),因此无法构成“用户明确同意”的豁免情形;“法律法规授权的特别应用”可通过监管机构制定的正面清单予以明确说明,通常包括使用完全自动化决策系统以监控或防止欺诈和逃税,或为确保数据控制者提供具有安全性和可靠性的产品或服务。
随着人工智能技术的不断发展,完全自动化决策系统的应用将是大势所趋,过于宽泛的无效原则将不利于机器学习算法的实际应用。我国应当建立健全自动化决策系统的应用限制和豁免情形的法律规定,授权监管机构制定相应决策系统的白名单制度,体现我国安全与发展并重的互联网治理准则,实现技术便利与社会安定的双重期待。
(二)机器学习算法影响评估制度
1.建立算法影响评估制度的必要性
由于法律具有概括性、滞后性和稳定性的特点,因此技术的监管不能只通过机械地执行法律条文的内容,对其实际应用进行“一刀切”式地限制或放任,否则就会掉入“一管就死,一放就乱”的怪圈。科技法律的核心作用在于规范技术的实际应用,最大限度地防范不可避免的社会风险,达到最佳的安全状态。(50)陈景辉.捍卫预防原则:科技风险的法律姿态[J].华东政法大学学报,2018,21(1):59-71.不同于传统算法受限于代码中固定的结构和内容,机器学习算法能够通过闭环反馈(Feedback Loop)方法和不断增长的数据动态且持续地进步而不仅仅局限于预先的编程内容,因此无法只通过代码的事先审查方法实现持续性的安全保障。
当法律面对机器学习算法这一人工智能时代的必要性技术,应当避免使用僵化的法律文本带给新技术及其行业过度的伤害,需要在遵循技术中立原则给予其足够发展空间的同时,在相对静态的无效原则之外建立一套完善的影响评估机制以应对不断变化的复杂风险环境。算法影响评估制度(Algorithmic Impact Assessment,AIA)可作为机器学习算法设计者和运营者的风险管理工具,而并非自上而下式的一般监管方法,其旨在描述自动化决策系统的内部设计和处理活动,分析潜在或先前发生的危害事件,利用其专业性和技术能力对算法风险进行系统性评估,对是否可能造成高风险进行判断,并设计相应的方案以减轻此类风险。算法影响评估既可以是事前预测,侧重于前瞻性分析,也可以事后进行,侧重于连续性和历史性的分析。(51)AI Now Institute.Algorithmic impact assessments:toward accountable automation in public agencies[EB/OL].(2018-2-22)[2019-7-1].https://medium.com/@AINowInstitute/algorithmic-impact-assessments-toward-accountable-automation-in-public-agencies-bd9856e6fdde.
2.算法影响评估制度的目标
AIA要求使用机器学习算法的组织机构提高内部的算法管理能力。相关组织通过分析制定自动化决策系统的潜在风险和计划方案,为监管者提供全面的算法影响评估结果,并赋予相关算法系统的访问权限,以协助监管者对算法的工作情况进行系统性监督。由于算法系统的复杂性和动态性,影响评估分析和持续性的监督需要监管者和第三方机构的共同努力,不同系统中存在的风险和危害需要跨学科研究人员的合作研究。算法系统的控制者应当设置适当的访问规则,以保证不同身份的外部监督人员能够对其算法系统中的输入数据、输出内容、系统源代码进行安全、充分、合法地访问。
AIA的另一目标在于向公众提供有关影响其个人权利和自由的自动化决策系统信息,并确保相关个人能够获得对算法系统提出异议的机会。不同于监管者获得的完整评估报告,使用机器学习算法的组织只需要公开列明和描述所有现有和计划的自动化决策系统,包括其使用目的、范围和对可识别个人或群体的潜在影响。对于算法系统给个人带来严重危害或未能遵守算法影响评估结果的组织,在规定的问询期内未获得合理回应的,AIA将为相关公众提供救济途径以寻求监管机构或法院的帮助。
3.应用领域的划分
AIA对于是否可能造成高风险的判断需要充分考虑算法活动的性质、范围、背景和目的,并将高度依赖于其具体的应用领域。某个算法系统在一个特定应用领域中可以适用,但在另一领域可能并不有效或不可取。因此在算法评估的过程中需要结合特定领域对安全风险的敏感性以进行技术分析。对于机器学习算法系统,我们可按照对人类安全的影响划分成禁止、限制和自由三个等级的应用领域。
禁止领域包括危害大范围人群或人类整体健康和生存的技术应用(例如人类基因编辑技术、智能杀伤性武器),使用机器学习算法将会进一步增加这一领域的不可控性。监管机构应当出台禁止应用领域的负面清单,对负面清单上的内容全面地禁止机器学习算法的使用,组织机构在算法影响评估时应当重点判断是否涉及此类领域,只有在得到法律特别授权的情况下才得以使用。
限制领域包括可能影响一定范围或特定类型人群权利、自由、生命、健康、情感的技术或商业应用。机器学习算法使得某些重要的人类活动的控制权转移至智能系统手中,对于影响人类上述权益的算法系统的最终决策权是否能够赋予机器,需要审慎地考虑。对于限制领域的应用,监管机构应当出台安全标准和许可机制,只有符合要求的应用才能够实际投入使用。除法律明确限制应用和禁止应用的领域之外,均应以自由生产为原则,允许组织自由应用机器学习算法。(52)张敏,李倩.人工智能应用的安全风险及法律防控[J].西北工业大学学报(社会科学版),2018(3):108-115.
4.设置新的职位体系
如同欧盟数据保护影响评估制度(Data Protection Impact Assessment)中数据保护官所扮演的重要角色一样,AIA同样需要设立新的专业职位来实现其目标,他们可以被称为“算法师”。(53)WP29.Guidelines on data protection impact assessment(DPIA)and determining whether processing is “likely to result in a high risk” for the purposes of Regulation 2016/679[EB/OL].(2017-10-13)[2018-12-4].https://ec.europa.eu/newsroom/article29/item-detail.cfm?item_id=611236.算法师具体可分为两种:组织内部的工作人员——内部算法师;以及组织外部工作的独立实体——外部算法师。(54)[英]维克托·迈尔-舍恩伯格,肯尼思·库克耶.大数据时代:生活、工作与思维的大变革[M].杭州:浙江人民出版社,2013.
内部算法师负责监督所在组织的算法活动,对算法的公平性、准确性、可控性和可预见性进行审查,任何认为遭受其组织算法系统危害的个人都应当与内部算法师取得联系。内部算法师需要定期公布组织的算法影响评估报告,为了避免受到组织内部利益的制衡,他们需要拥有充分的自由和资源。外部算法师则扮演公正的审计员的角色,常常作为中立的第三方研究机构或评估机构出现,当算法系统设计者或运营者以及监管者提出进行第三方的算法影响评估要求时,他们需要根据法律法规对算法进行审查,利用专业知识对算法系统的安全风险进行分析和评估。
(三)机器学习算法的监管措施
1.数据审查之路径
尽管机器学习算法所依托的决策模型和代码内容会持续更新而使得代码审查失去价值,但是机器学习算法所依托的训练或测试数据通常是相对静态且可被审查的。数据是现实社会的反映,社会的歧视或违法现象将可能转变为歧视性或有瑕疵的训练数据被机器学习算法所使用,从而产生大量歧视性和不公平性问题。(55)张凌寒.风险防范下算法的监管路径研究[J].交大法学,2018(4):49-62.在欧洲范围内,非歧视和数据保护是欧盟基本权利宪章明确的基本权利,两者都与机器学习算法应用中固有的不公平风险有关,GDPR更是特别要求组织机构应当使用基于公平意识的数据挖掘技术和组织管理措施。(56)参见GDPR序言第71条。
近年来,科学界提出了一些防止机器学习算法使这些社会偏见固化的计算技术,它们改变了一般的数据处理过程,尝试在预处理、处理中和处理后三个不同阶段对数据中的偏见进行纠正,目标是在训练数据存在瑕疵的情况下,引导机器学习算法不会导致歧视性的决策。(57)Hajian S,Domingo-Ferrer J.A methodology for direct and indirect discrimination prevention in data mining[J].IEEE transactions on knowledge and data engineering.2013,25(7):1445-1459.但现实中人们衡量歧视与公平的方式并不唯一,技术模型通常无法同时满足社会对公平的多重需求及其产生的约束条件,根据应用场景对特定的敏感数据特征进行过滤筛选仍然是目前更为可行的选择。(58)Berk R,Heidari H,Jabbari S,et al.Fairness in criminal justice risk assessments:the state of the art[EB/OL].(2017-5-28)[2019-7-1].http://arxiv.org/abs/1703.09207.
在监督学习模式下的机器学习算法对标注数据有很大的需求,通常这些数据是从先前的人为决策行为中获得,如果这些历史数据反映了社会中的错误判定,那么机器学习算法将会再现这些问题。而无监督学习使用的无标注数据将客观地反映数据潜在的关联性,即也存在着歧视性分类的风险。基于这些歧视性的逻辑,即使分析预测客观准确也难以被社会所接受。并且训练数据在数量和质量上的不足也会使得同一算法系统产生完全不同的效果,而这些差异都将会隐藏在由数据驱动的决策结果之中。
目前,使用机器学习算法的组织机构对于训练数据中歧视性特征或标签的判断只能依赖于根据数据保护相关法律法规中敏感数据的界定作出的相似理解,但并不足够。(59)Veale M,Binns R.Fairer machine learning in the real world:Mitigating discrimination without collecting sensitive data[J].Big data & society,2017,4(2):1-17.由于机器学习算法的表现效果高度依赖于数据的数量和质量,监管者应当设定机器学习算法训练数据的最小数量规模和合理采集方式,出台自动化决策系统的训练数据质量标准,限制歧视性和违法性数据的使用,采用严格的数据审查方法,以防范机器学习算法在实际应用中的社会风险。
2.规范嵌入之路径
在规范嵌入的监管思路下,机器学习算法可分为两种形态:基于机器学习算法的算法模型控制着自动化决策系统的大部分处理活动,可称为“一阶算法”,它们是技术规制的基础性内容;与“一阶算法”对应的“二阶算法”则由嵌入的数字化社会规范构成,它们能够依据人的需要筛选掉算法系统的不合理输出。“一阶算法”体现的是技术中立性,作为技术方案,原则上法律不予以评价。“二阶算法”则应当作为法律规制的对象,其通常并不是一成不变的技术方案,而是政府、用户、公众等不同的利益相关方不断商议的内容。(60)Denardis,L.Hidden levers of internet control[J].Information,communication & society,2012,15(5):720-738.被监管的组织机构往往可以根据社会环境和技术条件的变化,更新和修改“二阶算法”。相较于稳定的法律规范,这类算法规范往往具有极高的动态性和可塑性。虽然技术中的规范不可避免地受到法律制度的影响,但它们往往在很多方面与相应的法律要求并不一致。(61)例如Facebook,Twitter等社交平台关于发布言论的规则与美国宪法第一修正案或其他国家的宪法中关于言论自由的规定几乎没有关系。技术的规范框架是“社会科技”的产物,只有通过人类与技术的互动才能充分理解它,而不仅仅拘泥于法律条文本身。(62)Brey,P.Artifacts as social agents[C]//Harbers H.Inside the politics of technology:agency and normativity in the co-production of technology and society.Amsterdam:Amsterdam University Press,2005:61-84.https://ris.utwente.nl/ws/portalfiles/portal/5574352/Brey05artifacts.pdf.
“二阶算法”描述的社会规范是不可自动化的,需要对于不同的情形人为设定,而作为技术方法的“一阶算法”必然是自动化的。实际应用中,同一种“一阶算法”的普遍应用能够使得“二阶算法”具有可扩展性,这将是监管机构能够有效提升数字化技术治理能力的重要基础。通过对同类技术算法嵌入统一的社会规范,监管者不必应对个别技术案例的反复挑战,而是宏观地制定嵌入式的数字化技术标准以影响整个行业。但事实上,在很多情况下监管机构甚至都无法进入算法系统或是获得关键内容:正如2015年大众汽车公司对其发动机排放标准的操纵丑闻所表明的,通过拒绝或未能向全球相关的汽车监管机构提供关键软件和核心算法,大众汽车便能够“顺理成章”地销售不符合相关政府排放标准的汽车,此案例清楚地展示了在算法系统中嵌入社会规范的功能以及数字化技术治理机制的作用。(63)Wagner,B.Algorithmic regulation and the global default:shifting norms in Internet technology[J].Etikk I Praksis — Nordic Journal of Applied Ethics,2016,10(1):5-13.人工智能时代,机器学习算法是权力分配和再分配的关键控制点,尽管其对于公众而言仍然相对不透明,但监管者制定的算法技术标准和使用算法系统的组织机构实际嵌入了哪些数字化的社会规范将对生产控制和权力结构产生巨大影响。
3.代码驱动之路径
“代码即是法律”,机器学习算法的监管可以采用以代码为核心的监管方式,以代码规制代码,以算法对抗算法。(64)[美]劳伦斯·莱斯格.代码2.0[M].北京:清华大学出版社,2009.通过编写合规审查算法,自动化地设定大规模的测试用例,监管者能够对被审查的算法系统进行动态监控、行为修正和标准制定。代码驱动型监管主要基于“IFTTT”的条件判断方法(65)“IFTTT”是指“if this then that”(如果这样,那么就会),是计算机程序中一种常见的逻辑结构。,这种通过输入特定数据从而对输出结果进行监测的方法是相对确定且可预期的。通过将被审查的机器学习算法接入算法审查系统中,其在确切条件下所产生的结果分布应当是十分有限的,这一方法通常能够处理一个输出稳定的自动化决策系统。虽然机器学习算法的过程缺乏透明性和可解释性,但通过含有合规性判断的审查算法能够在预先设计的监管框架下一定程度地表明算法系统在运行时的逻辑架构和表现效果。(66)Surden H.Values embedded in legal artificial intelligence[J].University of Colorado Law Legal Studies Research Paper.2017,17(17):1-6.而这一审查方式的主要难点在于如何将文本的法律规范正确地被翻译成机器代码,前者往往是模棱两可的人类语言表达,而后者却是直截了当的计算输出结果。
由于被审查的机器学习算法可以是缺乏透明性的,并且基于代码的监管行为可能同样需要使用基于机器学习算法的自动化决策系统,其对前者做出的是否合法的决策过程往往也难以被合理解释。这对于监管者设计的算法审查系统以及其他智能化执法手段有着极高的合法性和准确性的要求,并且同样需要受到企业和公众的有效监督。当代码驱动的算法审查成为行政执法行为时,监管者必须对该决定的合法性负责,特别是对于被审查对象来说,他们有权知悉监管行为所根据的法律规范和适用解释。系统识别的事实错误和法律规范的转换错误将成为未来代码驱动型的监管手段需要避免和解决的问题。
五、结 语
人工智能时代的大幕已经开启。机器学习算法已被广泛应用于人工智能的各种应用中,社会公众对算法的依赖程度逐渐加深。然而机器学习算法应用作出的分析决策结果存在着不公平、不合理、甚至违法的法律风险,加之其具有不透明性的天然特点,直接影响了平等、自由、尊严、人格等人类基本价值和权利的实现,亟待法律予以回应。机器学习算法的代码即使公开也无法被普通公众理解,算法的可解释性亦存在着技术障碍,现有主流方案无法充分解决人工智能的“黑箱”问题。机器学习算法应用领域广泛、技术方案复杂,在国家治理体系和治理能力现代化的语境下,机器学习算法需要建立系统化的治理方案:明确机器学习算法禁止、限制应用的领域以及豁免情形;通过算法影响评估制度,防控机器学习算法引发的现实危害和潜在风险;通过数据审查、规范嵌入、代码驱动等监管措施,确保机器学习算法的安全可控,最终实现机器学习算法系统在复杂多变的风险环境下的安全和稳定,确保人工智能技术始终沿着为人类谋求福祉的道路发展。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
小学生学习指导(低年级)(2021年12期)2021-12-31
纺织科学研究(2021年9期)2021-10-14
阅读与作文(英语初中版)(2019年8期)2019-08-27
决策(2018年8期)2018-12-10
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
决策(2018年11期)2018-11-28
电影(2018年8期)2018-09-21

- 上海交通大学学报(哲学社会科学版)的其它文章
- 城市社区治理中个体化的重建