
基于CIBERSORT预测乳腺癌浸润性免疫细胞比例及亚型预后分析
2020-04-30 01:49:34余彩裙裴晶晶
云南民族大学学报(自然科学版) 2020年1期
余彩裙,裴晶晶
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
乳腺癌是目前女性最常见的恶性肿瘤.据统计,2018年乳腺癌占美国癌症第1位,女性患癌死亡率第2位[1].在我国,乳腺癌也成为女性发病率第1的癌症,每年新复发的人数约为26.9万人[2],并且逐年呈现年轻化的的趋势,因此对乳腺癌患者的预后估计尤为重要.在肿瘤免疫治疗中,肿瘤浸润性免疫细胞在肿瘤的控制和对治疗的反应中起到重要的作用,实时了解免疫细胞在肿瘤中的浸润情况是指导临床治疗的一个非常重要的指标[3-4].
近年来,研究者发现有众多因素影响乳腺癌患者的预后水平,大致可分为3类:① 遗传学特征,如是否携带乳腺癌易感基因、癌细胞DNA倍体状态等;② 病理特征,如肿瘤的大小、位置、生长速度、组织学分级情况等;③ 治疗方案,如化疗、免疫治疗等.目前,越来越多的学者尝试利用统计学方法、机器学习等方法对上述的影响因素进行研究,以此来判断这些因素对患者预后的影响.如You等[5]从具有不同分子预后生物标志物状态的受试者的图像中获得体素不相干运动(IVIM)和非高斯扩散参数,通过Mann-Whitney U检验比较了IVIM和非高斯扩散参数,并计算Spearman相关系数,以分析临床肿瘤结节转移(TNM)阶段和Ki67与IVIM和非高斯扩散参数的相关性.结果显示IVIM和非高斯扩散模型的体积病变直方图分析可用于提供有关人表皮生长因子受体2(HER2)阳性乳腺癌的预后信息,并可能有助于制定针对性的抗HER2靶向治疗计划.杜婧等[6]首先利用逻辑回归方法估计乳腺癌患者总体的阳性淋巴结比率(LNR),其次建立了基于贝叶斯方法的的动态COX回归预后模型,研究表明使用LNR总体估计值的动态COX回归模型数据拟合效果较好,与其他模型相比,该模型对总体的生存率预测准确度最高.尽管利用这些方法能较好的判断乳腺癌患者的预后因素,但大多数研究仅考虑了上述的影响因素,并没有考虑到免疫细胞的浸润情况以及不同亚型对患者预后的影响.因此,本文利用了CIBEROST算法[7]和一致聚类方法[8],结合临床生存数据对不同亚型的乳腺癌样本进行了预后分析,结果显示不同的亚型对肿瘤预后有显著的差异,说明运用此方法具有一定的合理性,为临床上乳腺癌患者的治疗和预后提供理论依据.
1 数据来源及数据预处理
数据主要来源于The Cancer Genome Atlas (TCGA)数据库,包括两部分:① 乳腺癌转录组数据, 1 100 个癌症样本和121个癌旁样本;② 真实的乳腺癌患者临床数据(部分数据见表1).从https://www.nature.com/articles/nmeth.3337下载的由22种免疫细胞构成的基因表达标签矩阵(LM22).在TCGA数据库下载的乳腺癌数据,是经过FPKM标准化的,以此消除批次或文库大小带来的差异.
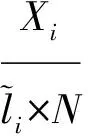
(1)
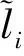

表1 部分临床样本数据表
表1中,生存状态0代表活着,1代表死亡;days_to_death表示完全数据,是样本从观测的时间起到出现结局事件所经历的时间;造成截尾的原因有失访、退出和终止,失访和退出是在试验还没有结束时,研究者已经追踪不到数据了,终止是指研究已经结束仍未观察到样本的结局.
2 预测乳腺癌样本中不同免疫细胞浸润比例
目前,很多反卷积方法可用于预测复杂组织样本中的细胞类型及比例信息[9-13].虽然这些方法在预测具有明确定义的样本(例如血液)中不同细胞类型比例的准确性较高,但是对于具有未知含量和含有噪声的样本(例如实体瘤)的预测效果却不太好.而CIBERSORT[7]算法是一种基于线性支持向量回归(SVR)且对噪声具有高度鲁棒性的机器学习方法,该算法在噪声,未知混合物含量和密切相关的细胞类型方面都优于其他方法.因此,本文采用CIBESORT算法来预测乳腺癌样本中不同免疫细胞的比例.本文的总体研究路线如图1(a)示,CIBERSORT算法具体流程策略如图1(b)所示.

CIBERSORT算法数学表示如下:
Mij=∑rk=1SicFcj,
(2)
其中,Mij表示基因i在混合样本j中的表达水平,是其在r细胞类型中的表达总和.Sik是标签矩阵(即LM22矩阵),表示基因i在免疫细胞中的基因表达水平.Fcj表示混合样本j中细胞类型的比例,即为最终所需的结果.
LM22称为免疫细胞基因表达标签矩阵.它包含547个基因,可区分22种人类造血细胞表型.将 1 100 个乳腺癌样本 (M)和LM22矩阵(S)数据作为CIBERSORT算法的输入,最终可得到22种免疫细胞在乳腺癌样本中所占的比例,从而量化了乳腺癌中参与应答的细胞组成.部分免疫细胞的比例(%)如表2所示,其中对于每个肿瘤样品,评估的22中免疫细胞所占的比例之和等于 1.22种不同免疫细胞在乳腺癌样本中所占的比例(F)分布如图2所示.

表2 部分免疫细胞的比例数据

由上图可知,在 1 100个肿瘤样本中,CD4幼稚T细胞、活化肥大细胞和嗜酸性粒细胞的比例较低,这些低比例的免疫细胞,能在预防疾病的进展中起到重要作用,可作为乳腺癌风险的标志物.而未分化的巨噬细胞所占的比例最大,其次是替代性活化巨噬细胞,表明巨噬细胞在乳腺癌组织中高表达,这与临床统计结果[14]一致,说明运用CIBERSORT算法估计免疫细胞的比例具有一定的合理性.
3 一致性聚类
根据上述的免疫细胞比例,对样本进行聚类,将其分为不同的亚型,从而进一步探讨不同亚型对乳腺癌患者预后的影响.传统的聚类方法需要预先给定一个聚类的数目,在比较不同聚类数目下的分类结果时没有一个统一的标准(比如K-means聚类),而且聚类的合理性和可靠性无法进行验证.一致聚类[8]是一种无监督聚类分析,通过基于重采样的方法来验证聚类的合理性,其主要目的是评估聚类的稳定性.在癌症诊断中的预后分析和治疗中具有潜在的高回报.
一致聚类又称为共识聚类,在聚类算法多次运行的过程中,保证了算法的一致性,以此来确定数据中的聚类数量,从而评估聚类方法的稳定性.算法的过程如下.
1) 首先输入一个需要聚类的数据集D={e1,e2,…,eQ},聚类的目标就是将观察到的数据划分为一组能够列举和非重叠的聚类.将D分为K簇的矩阵定义为V={V1,V2,…,VK},满足
∪Ki=1VK=D
(3)
且Vi∩Vj=∅,∀i,j∈K,i≠j.同时,还需选择聚类算法,有K-means聚类、层次聚类、PAM聚类等方法,选择重采样方案,输入重采样循环次数H和聚类试验数目集合K.
2) 选择重采样方案和聚类方法后,为了表示和量化聚类运行对扰动数据的一致性,定义一个Q×Q的连通矩阵.令D(1),D(2),…,D(H)是数据集D中通过重采样获得的H个扰动数据集的列表.令R(h)表示对应于数据集D(h)h次迭代的连通矩阵.最后会得到将数据集D(h)聚成K类的结果.连通矩阵定义如下:

(4)
生成H个扰动集和一个连通矩阵R.
3) 令I(h)为N×N指标矩阵,使得如果i,j都属于数据集D( h )时,则(i,j)为1,否则为0.然后可以将连通矩阵R定义为所有扰动数据集{D( h )∶h= 1,2,…,H}的共识矩阵的适当归一化的和:

(5)
4) 根据连通矩阵,定义IK为集群K的项的索引集,即IK={j∶ej∈K}. 定义一致矩阵TK:

(6)
也就是说属于同一集群的所有项目对之间的平均共识指数.生成K下的一致矩阵TK.
5) 基于TK划分样本集合D进入K个聚类中,最后返回划分P和K下的一致矩阵TK.
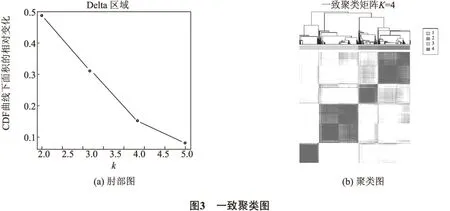
根据得到的Delta area图,就可确定最佳的聚类数K值.
本文使用R语言平台(Windows系统3.6.1版本)下的Bioconductor生物信息分析软件中的ConsensusClusterPlus软件包对CIBEROSORT预测出的22×1 100比例矩阵进行了一致聚类分析.在聚类过程中,采用兰氏距离来确定样本间的距离,公式如下[15]:
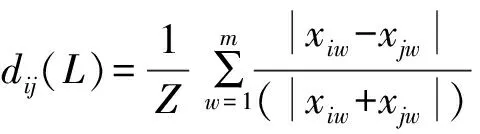
(7)
结果如图3所示,当K=4时,其不同类别数之间的差异趋于平缓.因此,选择K=4作为最佳分类结果,即可将 1 100 个乳腺癌样本划分成4种不同的亚型.
4 预后分析
预后分析是对疾病发病后发展为各种不同结局的预测,根据疾病的不同亚型,结合临床数据,进而判断疾病的预后.预后分析有许多不同的评价指标和方法,其中生存分析是预后研究中最常用的统计学方法.因此为了进一步探讨不同亚型对乳腺癌患者的预后影响,本文主要进行生存分析.生存分析是研究影响因素对生存时间和结局关系的一种方法,生存概率是指某段时间开始时存活的样本至该时间结束时仍然存活的可能性大小.生存概率可以表示为:
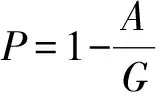
(8)
其中,P表示生存概率,A表示活过某段时间的人数,G表示该时段初期观察人数.本文采用乘积极限法(Kaplan-Meier survival estimate, K-M法)对乳腺癌4种不同的亚型进行生存分析,生存曲线如图4所示.运用对数秩检验探究不同时期4种亚型的生存率差别是否有统计学意义.若P值<0.05,认为多组总体生存曲线差异显著,有统计学意义.
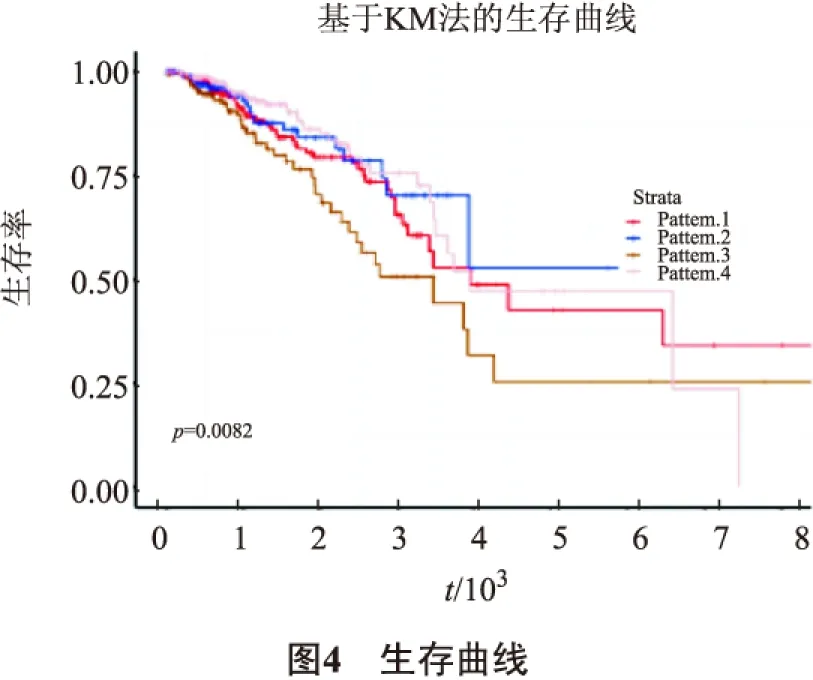
由图4可知,随着随访时间的增加,生存率从1逐渐下降.Pattern 2这组的生存率大概达到55%趋于稳定,且随着随访时间的增加生存曲线比较平缓,说明Pattern 2这组有较高的生存率.Pattern 1和Pattern 3两组相对于Pattern 2的生存率较低一些,说明Pattern 1和Pattern 3两组都有较长生存期,且Pattern 1的生存期比Pattern 3的要长.但是Pattern 4这组随着随访时间的增加,生存率越来越低,生存曲线也越来越陡峭,说明Pattern 4这组的患者生存率较低.且p值(0.008 2)<0.05,表明4种不同亚型的总体生存曲线差异显著,具有统计学意义.进一步说明应用一致聚类分析方法进行亚型分类,研究乳腺癌患者的预后具有一定的合理性.
5 结语
本文主要针对不同亚型的肿瘤样本对患者的预后影响展开研究.主要包括以下3方面的工作:① 首先利用CIBEROST算法预测 1 100 个乳腺癌肿瘤样本中不同免疫细胞的浸润比例情况;② 然后根据免疫细胞的比例应用一致聚类方法对肿瘤样本进行亚型分类,将样本划分为4种不同的亚型;③ 最后进行预后分析,发现不同的亚型对乳腺癌患者的预后有显著差异(p值为 0.008 2,小于0.05).研究表明本文应用CIBERSORT算法和一致聚类方法,对不同亚型的患者进行预后分析是合理的.因此临床上正确鉴定不同乳腺癌亚型,对于后续的诊断和指导用药具有重要的意义和价值.
猜你喜欢
小学生学习指导(高年级)(2021年3期)2021-04-06 08:49:44
电子测试(2017年15期)2017-12-18 07:19:27
红土地(2016年7期)2016-02-27 15:05:54
智能系统学报(2015年4期)2015-12-27 09:38:39
中国病理生理杂志(2015年8期)2015-12-21 12:38:10
中国当代医药(2015年30期)2015-03-01 02:08:19
电子设计工程(2015年6期)2015-02-27 12:04:53
中国卫生(2014年7期)2014-11-10 02:33:04
癌变·畸变·突变(2014年2期)2014-03-01 04:39:41
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
