
基于注意力机制的大同方言语音翻译模型研究
2020-04-29 14:26:50刘晓峰宋文爱余本国郇晋侠陈小东李志媛
中北大学学报(自然科学版) 2020年3期
刘晓峰,宋文爱,余本国,郇晋侠,陈小东,李志媛
(中北大学 软件学院,山西 太原 030051)
0 引 言
中国幅员辽阔,有着传承千年的文化,丰富而多元,方言种类更是多种多样. 在众多的地方方言中,山西方言的种类尤其多,是名副其实的十里方言不一样. 大同市地处山西省最北部,且其地方方言属于晋语的“大包片”,与普通话有较大的区别. 大同方言包含21个声母,36个韵母,5个声调,声调分为阴平、 阳平、 上声、 去声、 入声[1],相比于普通话多出了“入声”声调,入声是古汉语的四声之一,其读音短促,一发即收,在现代普通话中已经消失,而在大同方言中,入声却是常见的发音现象[2]. 除此之外,大同方言还包括一些其他的发音特点,比如: 平舌音与翘舌音不加区分,韵母变化,后鼻音代替前鼻音等. 当地那些年纪较大的人们在年轻的时候并没有系统地学习过普通话的发音,也不了解普通话与大同方言之间的一些语法差别,所以与外地人交流时存在较大的困难[3]. 因此,大同方言语音转为普通话的任务亟待完成.
一般来说,大同方言语音转普通话的任务可归类为语音翻译(Speech Translation)任务,传统的语音翻译任务是通过将源语言上训练的语音识别系统和在目标语言上训练翻译文本的机器翻译系统之间建立联系来完成的,这种级联的模型会相互影响,降低翻译正确率. 2016年,Bérard等人尝试构建了一个端到端语音到文本的翻译系统,实验证明该方法可以很好地推广到一个新的语言的语音翻译系统的构建中[4]. 2017年,Weiss、 Chorowski等人构建的端到端的语音翻译模型在训练时直接运用输入语音对应的目标语言文本对输出序列进行监督,免去了对源语言的语言标准的依赖,其模型结构与端到端的语音识别模型大致相同,非常适合两种语言之间语音到文本的转换[5].
训练大同方言语音识别系统的必备条件是利用一套完整的、 系统的大同方言语言标准训练得到一个较为完备的大同方言语言模型来指导系统输出正确结果,但由于方言的低资源性,制定语言标准非常困难. 针对此问题,本文提出了一种结合注意力机制(Attention)的端到端大同方言语音翻译模型,在该模型的内部,语音信号特征将被映射成为一个较高维度的向量,直接与中文普通话文本建立联系,基于此模型结构,大同方言语音转为普通话文本的任务便能够摆脱制定大同方言语言标准的麻烦,相对而言,端到端的语音翻译模型也比传统语音翻译模型的复杂性更低,翻译准确度更高. 与此同时,对大同方言的语音翻译的研究也旨在克服大同人与外地人的交流障碍,促进交流与发展.
1 “编码器-解码器”模型与注意力机制(Attention)
2014年,Cho等人[6]提出了编码器-解码器模型,这种模型也被称为“seq2seq (序列到序列) ”模型,他们把用此模型计算出的短语对的条件概率作为已有对数线性模型的一个附加特征,对机器翻译系统的性能进行了改进,并通过实验证明了该模型在完成机器翻译这种输入输出都是不定长序列的任务中有着良好的效果[6].
“编码器-解码器”模型由编码器和解码器两部组成,编码器的作用是将输入序列x=(xi|i=1,2,…,I)映射成为该序列对应的隐含特征状态h=(hi|i=1,2,…,I),并将整个输入序列的隐藏状态通过q函数汇总到上下文背景向量c,大部分编码器是由一个多层感知器实现的,由于序列到序列模型需要考虑相邻时刻的状态对当前时刻状态的影响,所以编码器大都由循环神经网络(Recurrent Neural Network, RNN)来实现,但是传统的RNN存在梯度爆炸和梯度消失等问题,所以在编码器中通常采用长短时记忆网络(Long Short-Term Memory, LSTM)代替了RNN.
c=q(h1,h2,…,hi).
(1)
解码器通常也是使用RNN来实现的,它要求每一时刻的输出y=(yo|o=1,2,…,O)同时由前一时刻的输出yo-1和上下文背景向量c决定,即
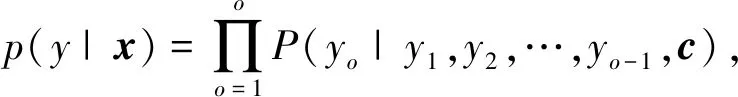
(2)
其中
P(yo|y1,y2,…,yo-1,c)=g(yo-1,so,c),
(3)
so=f(so-1,yo-1,c),
(4)
式中:so为对应于输出序列yo的隐含状态.f为一个使用重置门作为激活函数的全连接层计算,g可理解为一个由Maxout层和Softmax层组成的多层感知器. 最后通过最小化P(y|x)的负对数似然来得到最佳结果
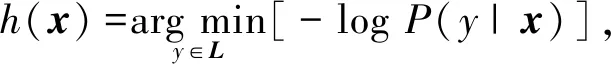
(5)
式中:L为用于组合对应于x中每个元素标签的所有字符集合. 以上是“编码器-解码器”模型的实现原理,Attention模型在“编码器-解码器”模型的基础上对c做了一些修改,在Attention模型中,c不再是一个固定的向量,而是对应于不同时刻输入序列的上下文背景向量集c=(co|o=1,2,…,O),co在此表示为
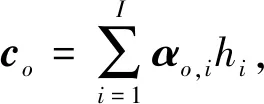
(6)
由co的定义可知,αo,i表示输入序列i时刻隐含状态的权重,即i时刻输入对输出的影响程度,模型在此便体现了“Attention”思想.αo,i利用Softmax函数输出得到:
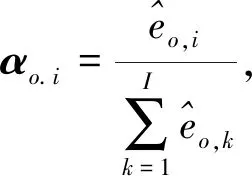
(7)
其中
eo.i=a(so-1,hi).
(8)
式中:eo,i为输出序列(so-1)前一时刻的隐含状态与当前时刻输入序列的隐含状态(hi)建立联系后的结果,通过一个多层感知器a计算得到.
这样,Attention模型的结果可表示为
最后可通过最小化P(y│x)的负对数似然来得到最佳结果
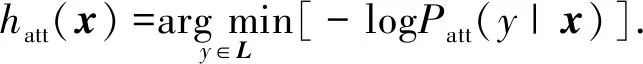
(10)
“编码器-解码器”模型与注意力机制尤其擅长完成机器翻译和语音识别这种“序列到序列”模型的任务,2014年,Bahdana和Cho等人首先将注意力机制加入到机器翻译的研究中,使机器翻译的准确率有了大幅提升[7]; 同年,Chorowski等人将Attention模型应用于语音识别,并在TIMIT数据集上做了实验,证明该模型较其他早期的语音识别模型有相对较高的识别率[8].
2 端到端的大同方言语音翻译模型
基于Attention的端到端模型分别在机器翻译和语音识别研究领域有着良好的表现,而语音翻译模型类似于基于Attention的语音识别模型,区别是在编码器中输入的是源语言的音频数据,解码器的输出域是目标语言的字符集.
方言与普通话在语调、 语序等方面有较大的差异,且两种语言一般情况下难以正常交流,所以方言与普通话在某种程度上可归类于两种不同的语言. 因此,将方言语音转换为普通话文本的任务便可以使用语音翻译技术来完成.
按照传统的方法,语音翻译这个任务是通过流水线操作完成的,即在一个使用源语言语料数据训练好的语音识别系统后连接一个机器翻译系统,语音识别系统负责将源语言音频转化为源语言文本,机器翻译系统负责将语音识别系统输出的源语言文本翻译成目标语言文本. 单独训练的语音识别和机器翻译模型可能在单独工作时表现良好,而在两者协同工作时效果却不好,因为语音识别系统并不能保证百分之百的输出正确率,输出序列可能会伴有“插入” “删除” “替换”等错误,在其后连接的机器翻译系统很有可能接收到伴有这些错误的语音识别结果,从而影响翻译结果. 不仅如此,在源语言没有系统标注规则或官方语言标准等极端的情况下,要想训练单独的语音识别系统就必须要先制订一套完整的、 系统的语言标准,仅仅这项工作就将会耗费大量的资源[2].
seq2seq这种端到端模型能够精确地模拟非常复杂的概率分布,它足以强大到将一种语言的音频直接翻译成另一种语言的文本,即在训练时,音频使用一种语言,而文本标注使用另一种语言,因为音频与文本符号之间并没有固有的联系,所以将音频抽象为高维特征向量后,可以通过神经网络映射到任意一种文本符号,且在实际应用期间,端到端模型相比于两个独立系统的级联模型延迟更低.
2.1 特征提取
语音处理的一个重要步骤是用各种特征来表征音频信号,其中梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC)特征系数的提取过程更符合人耳的听觉特性,因此在语音处理领域被广泛使用. 图1 描述了音频特征提取过程.
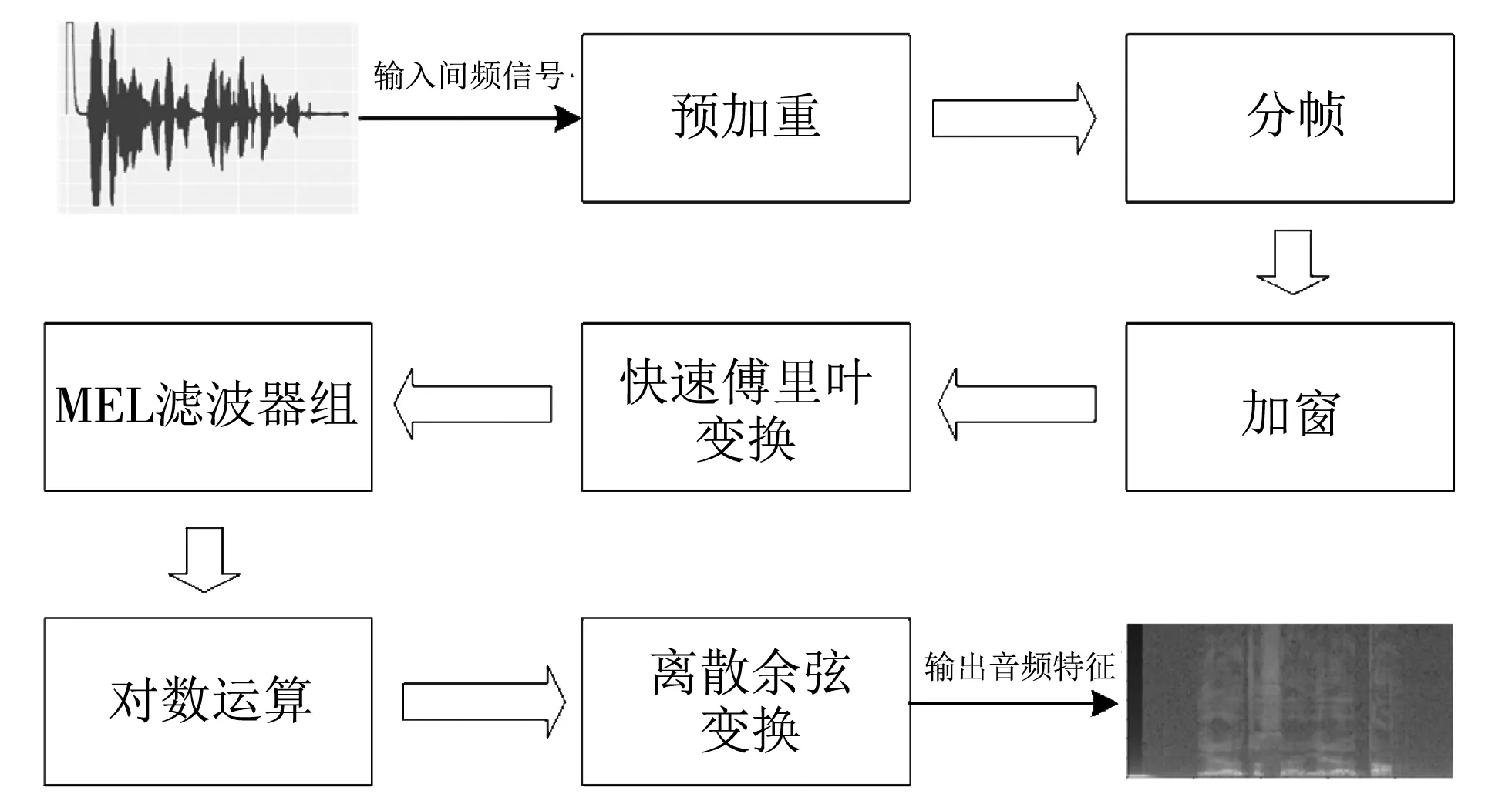
图1 音频特征提取过程Fig.1 The process of audio feature extraction
2.2 编码过程
卷积神经网络(Convolutional Neural Networks, CNN)在语音识别领域有着广泛应用,在处理音频频谱时可有效对声学模型进行建模,同时也可以减少后续层的计算量,从而减少建模时间成本[9],所以在建模时首先为编码器设置了两层卷积层来提取数据特征,并用ReLU函数激活,每层卷积层后加了池化层[10],随后将卷积层的输出向量层层传递至后续四层双向长短时记忆网络(Bi-directional Long Short-Term Memory, BLSTM),最终编码器输出上下文背景向量co,co中包含编码器生成的Attention概率αo,i,起到对齐音频与字符的作用,如图2 所示,纵坐标为目标字符,横坐标为输入的音频特征,对于一段音频,其每一帧都有一定概率对应某些字符,颜色越深,概率越大. 虽然方言与普通话的声调、 发音以及同一事物的表达方式都不尽相同,但是因为方言与普通话的语序大致相同,所以在方言语音翻译模型的Attention概率图中,音频特征与目标字符基本呈顺序对应的状态.
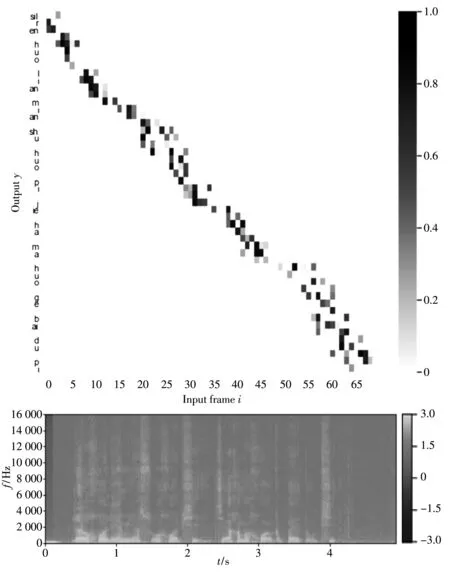
图2 语音翻译模型的Attention概率图Fig.2 Attention probability map of speech translation model
2.3 解码过程
将预先初始化后的yo-1和so-1与co连接,一起输入至解码器网络来预测当前时刻的输出字符,解码器由两层LSTM组成,最后接一层Softmax层来预测输出字符集中每个符号的概率,之后可利用波束搜索算法进行解码,得到输出序列,整个模型的训练过程如图3 所示.
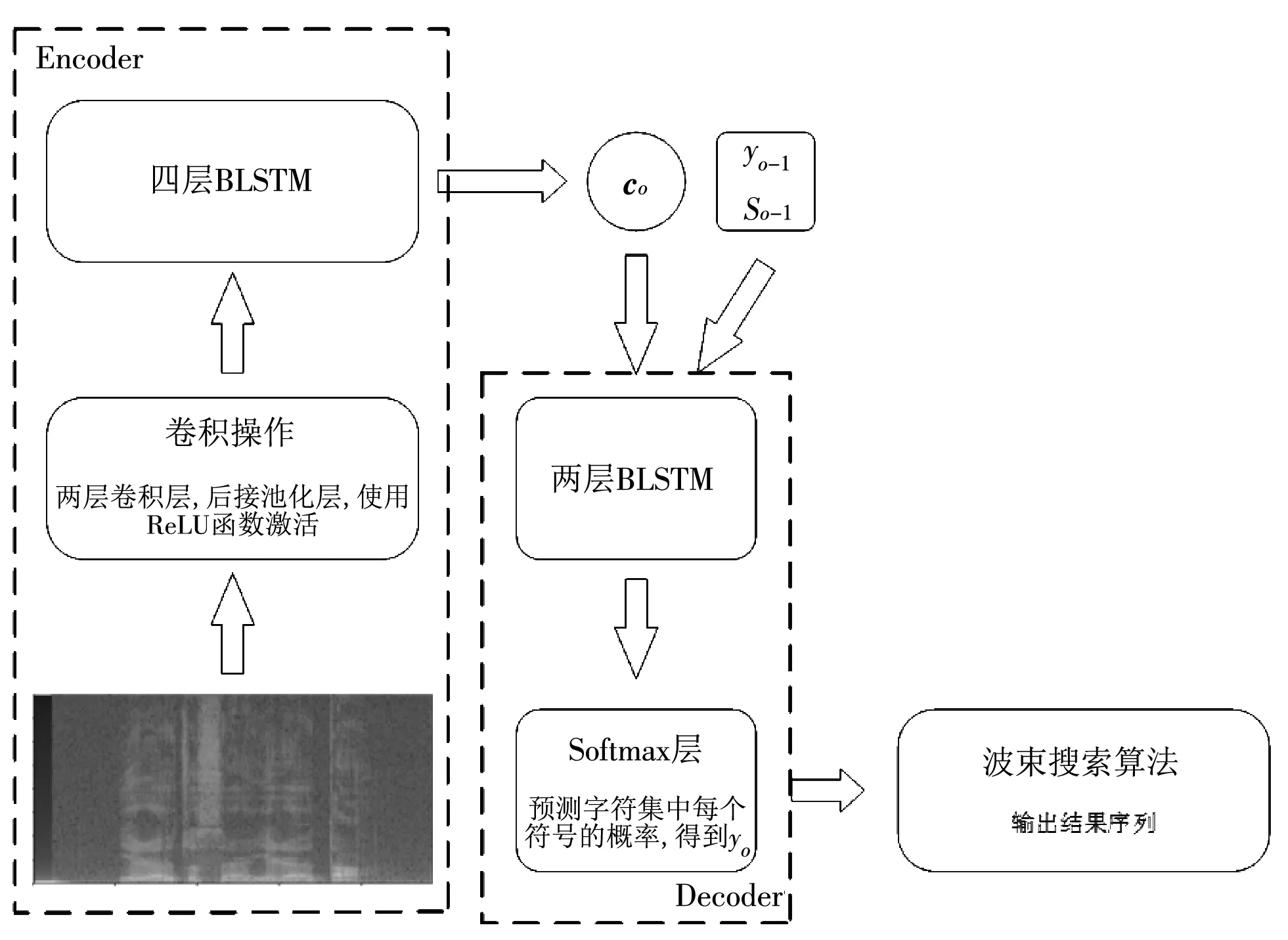
图3 基于Attention的语音翻译模型训练过程Fig.3 Attention-based speech translation model training process
3 实 验
3.1 实验数据
实验时使用先期收集到的大同方言语音语料数据,其中包含朗读语音和自然语音,在参考了一些中文语音语料库的建库方法之后,对这些语音数据做了数据清洗、 标注、 加工等工作,标注时分别为大同方言音频数据标注了普通话的拼音和大同方言的拼音,将其建立成为大同方言语音语料库[11-13],语音时长总计12 h 21 min 13 s,共8 894条,在训练基于Attention的语音翻译模型时可直接使用语料库里的数据.

表1 大同方言语音数据集
3.2 编码器解码器层数实验
双语评估替换(Bilingual Evaluation Understudy, BLEU), 是2002年Papineni等人提出的比较候选文本翻译与其他一个或多个参考翻译的评价分数,可用于翻译文本质量评估[14].
在机器翻译模型中,编码器通常是由比较深层的RNN构成,因为模型的输入序列和输出序列是两种不同的语言,所以编码器要将输入序列映射成为一个使解码器更加容易“理解”的特征向量. 由于端到端语音翻译模型直接使用带有普通话标注的大同方言语音数据对模型进行训练,而大同方言与普通话在某种程度上属于两种不同的语言,语序和语法有一些差异,所以编码器应该采用较深层次的RNN. 如图4 所示,在实验时发现,保持解码器网络层数不变,编码器中BLSTM层数在增加到四层以后,模型性能不再有大幅度提升,综合考虑训练的时间成本,将编码器中BLSTM的层数固定为4层较为合理.
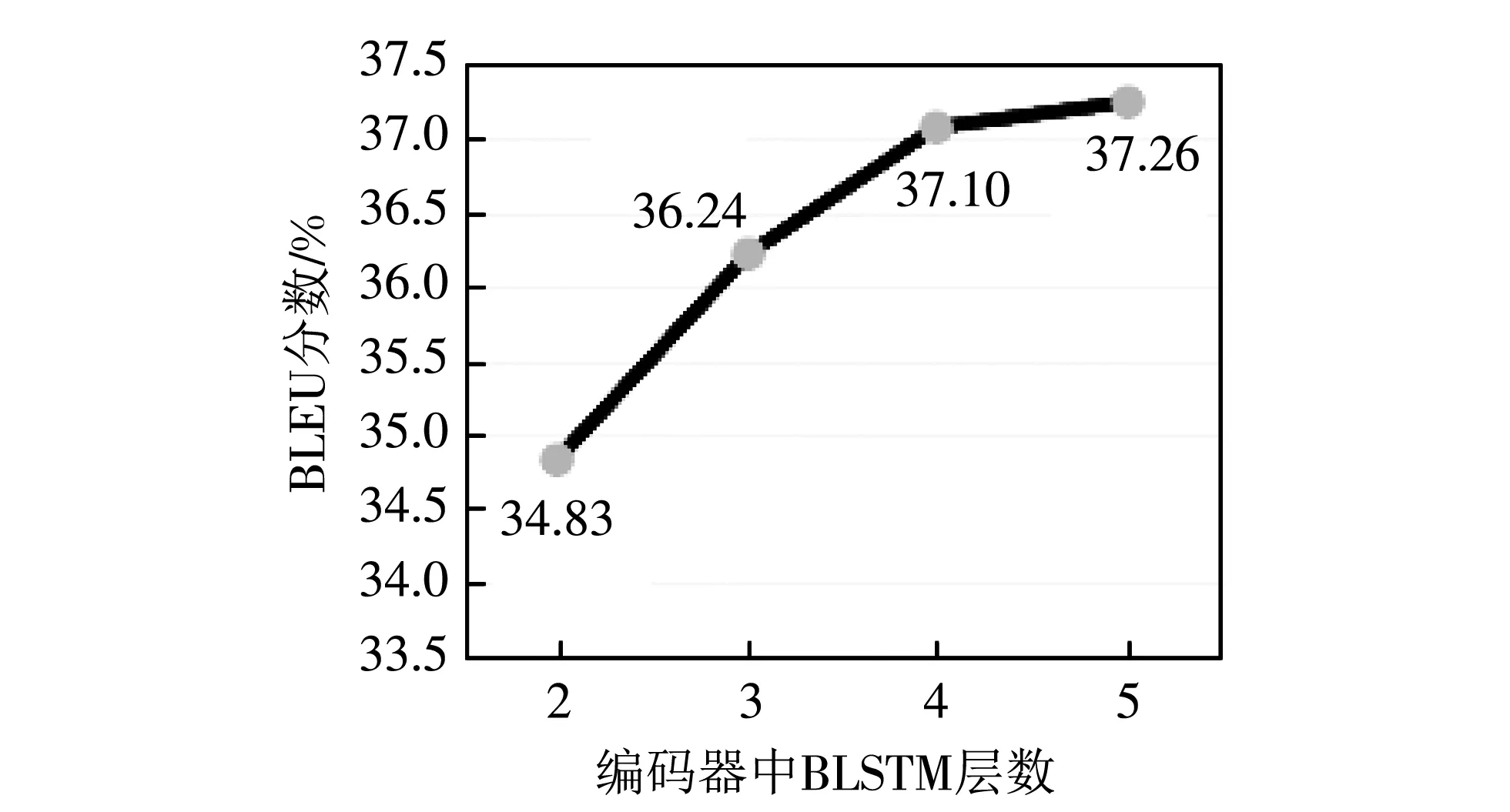
图4 编码器中BLSTM层数对BLEU分数的影响Fig.4 The effect of the number of BLSTM layers on the BLEU score in the encoder
应用于语音识别中的Attention模型通常使用层数比较少的解码器,因为在一般情况下,语音识别任务中的音频和标注文本的语序是基本一致的,而在翻译任务中,输入序列和输出序列的语序却是不同的,同时解码器是为了解决更为复杂的词汇关联问题,所以需要更深层次的解码器网络,但是大同方言与普通话同属中文语系,二者的语序在大部分情况下是一致的,所以理论上不需要设置更加深层次的解码器网络,实验结果也证明了这一观点,如图5 所示.
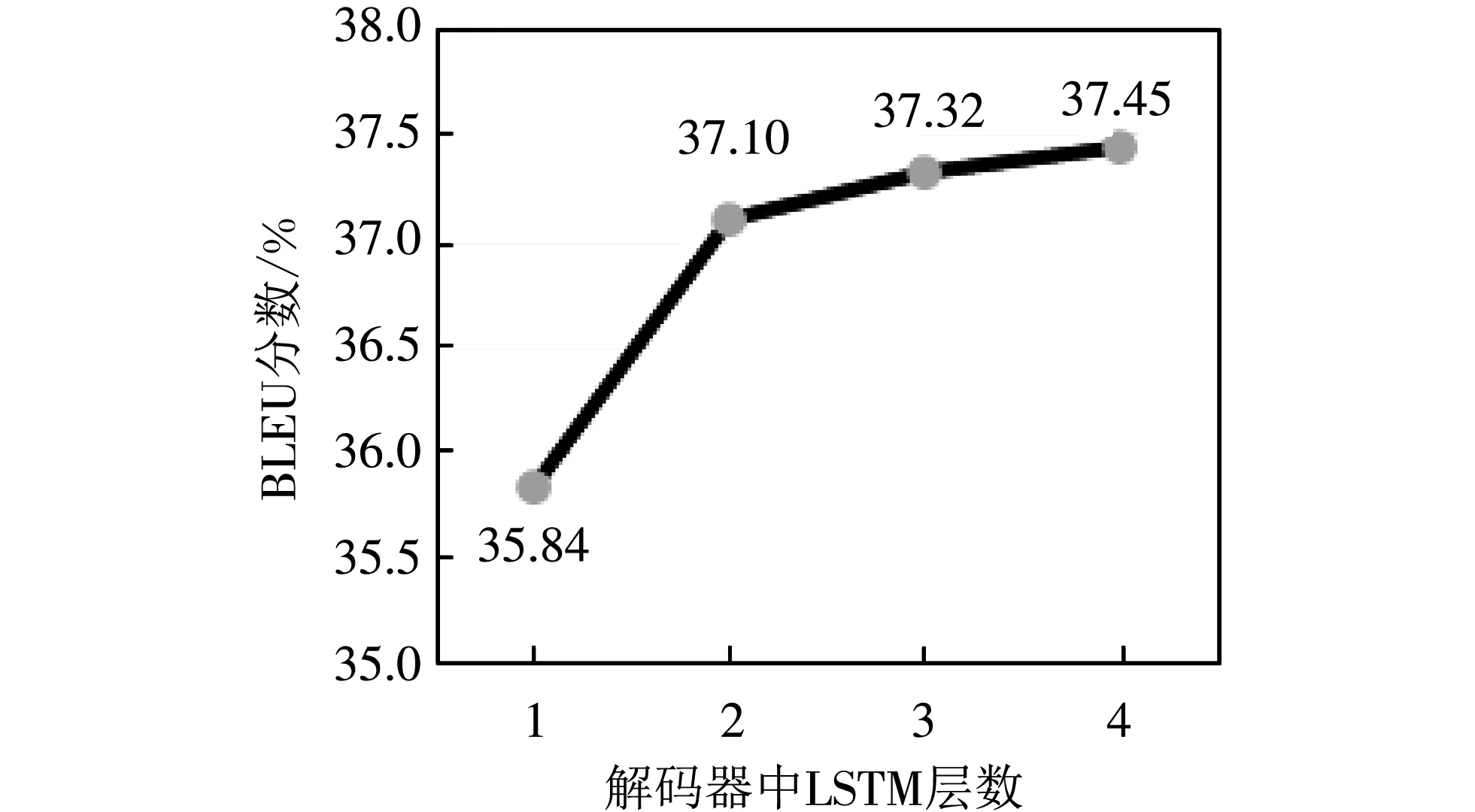
图5 解码器中LSTM层数对BLEU分数的影响Fig.5 Effect of the number of LSTM layers on the BLEU score in the decoder
3.3 语音翻译模型BLEU分数对比实验
传统的语音翻译方法是由语音识别(Automatic Speech Recognition, ASR)与机器翻译(Machine Translation, MT)级联模型来实现的. 级联模型中的语音识别模块分别可使用以下三个模型: 深度神经网络-隐马尔可夫模型[15](Deep Neural Networks-Hidden Markov Model, DNN-HMM)、 双向长短时记忆网络-连接时序分类模型[16-17](Bi-directional Long Short-Term Memory - Connectionist Temporal Classification, BLSTM-CTC)和基于Attention的语音识别模型[8]. 实验利用大同方言语音数据集对各模型进行评估,结果表明,基于Attention的语音识别模型在验证集和测试集的表现更好,词错误率(Word Error Rate, WER)更低,结果如表2 所示.
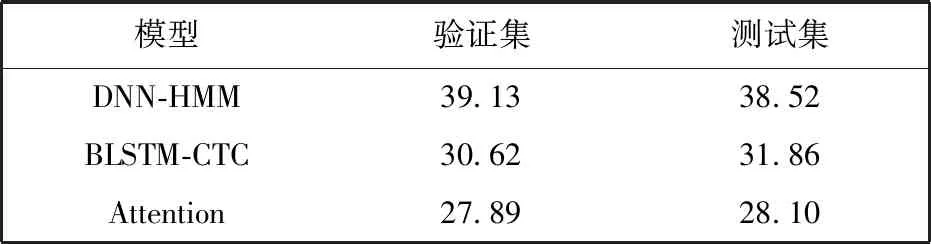
表2 级联模型中语音识别模块WER对比实验
完成语音识别模块的选取之后,利用大同方言语音数据集中包含的方言文本和与之对应普通话文本,训练并测试了基于Attention的机器翻译模块,并将其应用于级联模型中作为基线模型,与端到端的语音翻译模型的性能进行对比.
在实验中发现,级联系统中通常会因为语音识别结果的不准确而增加了机器翻译结果的错误率,这是级联系统的一个致命缺陷,反观端到端的语音翻译方法,编码器首先将语音信号映射为高维的潜在向量,解码器再拟合这些向量,输出每段语音对应的文本符号的概率,最后通过波束搜索算法得到最终输出文本序列,期间并没有利用到源语言的转录文本,也排除了多个系统不能很好地协同工作的问题.
这些模型都用大同方言语音数据集进行训练,实验对比了级联模型与端到端模型在验证集与测试集上的BLEU分数表现,结果如表3 所示.

表3 语音翻译模型的BLEU分数对比
4 结论与展望
基于Attention的端到端语音翻译模型与基于Attention的语音识别系统具有相似的模型,可以将一种语言的语音直接翻译成另一种语言的文本,这种端到端的语音翻译模型首先将语音信号通过编码器映射成一个高维的向量表示,解码时使用目标语言标签对整个模型进行有监督训练,输出每个字符的标签概率,最后通过波束搜索算法得到最终输出序列. 总而言之,编码器和解码器这两个子网络交换的信息是抽象的高维实值向量.
此外,端到端的语音翻译模型较ASR和MT级联模型有着更低的延迟,有效节约了时间成本,在大同方言语音数据集上的BLEU分数表现也有了部分提升,说明端到端的语音翻译技术更加适合完成方言语音转普通话文本的任务.
我国方言种类繁多,且编制一份系统的方言语言标准便是一项重大的工程,而语音翻译技术在整个翻译过程中没有使用源语言的转录文本对训练进行监督,对于没有标准化语言体系的语言具有良好的适应性,使研究人员的工作量大大减少,所以语音翻译技术有着极大的研究意义,在今后的工作中,应继续加强模型的研究,在不断的实践中提升模型性能.
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
河南教育·高教(2019年3期)2019-04-11 01:16:14
北方文学(2018年18期)2018-09-14 10:55:22
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
速读·下旬(2016年7期)2016-07-20 08:50:28
电子器件(2015年5期)2015-12-29 08:42:24
